1
International Journal in Management and Social Science http://ijmr.net.in, Email: [email protected] BIOINFORMATICS USING DATA MINING TECHNIQUES AND ITS CHALLENGES:A STUDY
Alok Gupta1, Dr. Vijay Pal Singh2 Department of Computer Science
1,2
OPJS University, Churu (Rajasthan)
Abstract
Data mining techniques are computerized methods for diminishing the unpredictability of data in enormous bioinformatics databases and of finding significant and valuable examples and relationships in data, advances, and challenges related with data mining in bioinformatics. Bioinformatics, the investigation of how information is spoken to and transmitted in biological systems, is a data-concentrated field of research and improvement. It envelops networking, databases, representation techniques, web crawler structure, statistical techniques, demonstrating and recreation, AI and related example coordinating, and (the subject of this article) data mining. Recent advances in bioinformatics and their application to medical informatics were the subjects of this conference, which brought together speakers from many disciplines, including computer science, molecular biology, medicine and physics. The major theme of the conference was that future efficient discoveries in molecular biology require work on data integration. Effective integration of data from the disparate sources in biology can be divided into three challenges: infrastructure, data models and predictive analytical models.
1. OVERVIEW
In bioinformatics, data mining is worried about finding how basic base sets can be joined in various ways, huge numbers of which are obscure, to give the structure and capacity of the bigger structure squares of life. Acing this biological data—including finding a considerable lot of the underlying guidelines, relationships, and implications—requires human intelligence and instinct, utilized by computer-based tools. On account of computerized gene sequencing machines and new worldwide action in the field, both trial (wet lab) and computer-generated data are expanding at an exponential rate. There are more data to manage today since present day researchers are utilizing computer-empowered, data-driven, high-throughput processes, for example, robotized sequencing machines, and microarrays.
2
International Journal in Management and Social Science http://ijmr.net.in, Email: [email protected] around the globe concentrated on foreseeing protein structure from arrangement data, rather than the conventional tedious strategy for direct perception. Getting at the hard-won grouping and structure data in molecular science databases and the user data in the online biomedical literature is convoluted by the size and intricacy of the databases [1-6].Thoroughly looking for the crude data and playing out the change and controls on the data through manual tasks is frequently unreasonable. In any case, notwithstanding when computer assets are accessible, the time and computational assets required to find and control the data are restricting variables. Accordingly, executing comprehensive, non-coordinated looks for potential connections is absurd. Without an arranging topic, the billions of data focus from genomic or proetomic considers are of little esteem. Notwithstanding whether this classification is at the base pair, chromosome, or gene level, a sorting out subject is basic since it disentangles and diminishes the multifaceted nature of what could somehow, or another be a surge of immeasurable data.
2. DATA MINING AND BIOINFORMATICS
Data mining is the extraction of hidden predictive information from large amount of data. It is also becoming an increasingly significant tool to transform this data into information. Data mining is commonly used in areas such as Marketing, Surveillance, Fraud Detection, and Scientific Discovery. Data mining for Bioinformatics enables researchers to meet the challenge of mining vast amount of bio-molecular data to discover real knowledge. Bioinformatics and Data Mining provide exciting and challenging research and application areas for Computational Sciences. Data mining commonly involves the following four classes of tasks:
Classification:
Classification consists of predicting a certain outcome based on a given input. In order to predict the outcome, the algorithm processes a training set containing a set of attributes and the respective outcome, usually called goal or prediction attribute. The algorithm tries to discover relationships between the attributes that would make it possible to predict the outcome. Secondly, the algorithm is given a set of patterns called prediction set, which contains the same set of attributes, except for the prediction attribute. The algorithm analyses the input and produces a prediction. The prediction accuracy determines the performance of the algorithm.
Clustering:
3
International Journal in Management and Social Science http://ijmr.net.in, Email: [email protected] amount of data collected in database, cluster analysis has recently become an active topic in data mining research. Cluster analysis includes two major aspects: Clustering and Cluster validation. Clustering is a process to group similar items together into groups according to certain criteria. These grouped objects are called clusters. The quality of clusters is then evaluated using cluster validation techniques.Regression:
Regression is a data mining function that predicts a number. A regression task begins with a dataset in which the target values are known. During training process, a regression algorithm estimates the value of the target as a function of predictors for each case in the built data. The relationship between predictors and target are summarized in a model, which can then be applied to a different dataset in which target values are known. It is an attempt to find a function which models the data with least error.
Association rule learning:
It is a popular method for discovering interesting relationship between variables in large databases. Here, hidden relationships are expressed as a collection of association rules and frequent item sets. Frequent item sets are simply a collection of items that frequently occur together and association rule suggests a strong relationship that exists between two items. Association rule mining has become an important data mining technique due to its descriptive and easily understandable nature of rules. It has proved to be useful in many domains, for instance, microarray data analysis, recommender systems and network intrusion detection.
3. MACHINE LEARNING AND DATA MINING IN BIOINFORMATICS
Machine learning is one of the most established subfields of artificial intelligence and is worried about the plan and advancement of computational systems that can adjust and learn. The most well-known machine learning algorithms can be either administered or unsupervised. Managed learning algorithms generate a capacity that maps contributions to wanted yields, based on a lot of models with known yield (named precedents). Unsupervised learning algorithms discover examples and relationships over a given arrangement of sources of info (unlabeled precedents). Different classifications of machine learning are semi-directed learning, where an algorithm utilizes both named and unlabeled models, and fortification learning, where an algorithm learns a strategy of the proper behavior given a perception of the world.
4
International Journal in Management and Social Science http://ijmr.net.in, Email: [email protected] computers. It is an interdisciplinary area of research that has its underlying foundations in databases, machine learning, and measurements and has commitments from numerous different areas, for example, information recovery, design recognition, perception, and parallel and disseminated registering.4. BIOLOGICAL SEQUENCE ANALYSIS
The same number of genome sequencing projects has been finishing; there is the need to comment on those genomes. The watched change in perspective from static auxiliary genomics to dynamic functional genomics and the task of functional information to realized successions is considered especially significant. Gene prediction is worried about the distinguishing proof of stretches of DNA that are biologically functional. It is the next advance after the sequencing and is especially significant for the explanation and understanding of a genome.
Gene prediction is anything but a clear task, particularly for eukaryotic genomes, that are progressively unpredictable. For instance, eukaryotic genes comprise of coding parts (exons) that are isolated by mediating non-coding successions called introns. Introns are expelled from the translated RNA by the process of grafting. A standout amongst the most significant biological issues that request the development of prescient data mining or machine learning models is the recognition of the join locales, in particular, the limits between nearby exons and introns.
5 CHALLENGES IN BIOINFORMATICS FOR STATISTICAL DATA MINERS
Statistics is the science of "learning from data." It incorporates everything from getting ready for the accumulation of data and ensuing data management to stopping point exercises, for example, drawing deductions from numerical certainties called data and introduction of results. Statistics is worried about a standout amongst the most essential of human needs: the need to discover increasingly about the world and how it works in the face of variety and vulnerability. In light of the expanding utilization of statistics, it has turned out to be essential to understand and rehearse statistical reasoning.
5
International Journal in Management and Social Science http://ijmr.net.in, Email: [email protected] That is the reason we need statistics and statistical reasoning. Statistics emerged from the need to put knowledge on a systematic proof base. Data mining has been characterized by numerous points of view as there are writers who have expounded on it. Since, it sits at the interface between statistics, computer science, artificial intelligence, machine learning, database management and data representation (to name a portion of the fields), the definition changes with the point of view of the user. Here is a not all that arbitrary example of a couple: ―Data mining is the process of exploration and analysis, by automatic or semiautomatic means, of large quantities of data in order to discover meaningful patterns and rules.‖
―Data mining is finding interesting structure (patterns, statistical models, relationships) in databases.‖
―Data mining is the application of statistics in the form of exploratory data analysis and predictive models to reveal patterns and trends in very large data sets.‖
Predictive analytic models
Data mining, or the automated unsupervised acquisition of knowledge from large data sets, is already an important technique in bioinformatics and is used for hypothesis generation. In this type of discovery science, research is first undertaken in silico to discover significant biological associations that are most likely to be validated in the biological laboratory. In this methodology, many distributed autonomous processes (the ants) try to reach the solution (the food) within a search space. Each ant marches back home once it finds the food.
6 APPLICATION OF DATA MINING TECHNIQUES IN BIOINFORMATICS
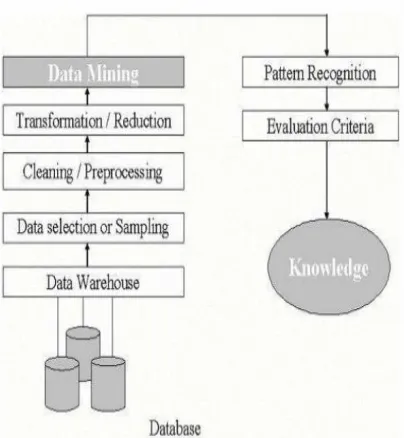
6
International Journal in Management and Social Science http://ijmr.net.in, Email: [email protected]Figure 1: An Overview of the Steps Comprising the KDD Process
The iterative process consists of the following steps:
1. Data cleaning: Also known as data cleansing, it is a phase in which noisy data and irrelevant data are removed from the collection.
2. Data integration: At this stage, multiple data sources, often heterogeneous, may be combined in a common source.
3. Data selection: At this step, the data relevant to the analysis is decided on and retrieved from the data collection. Data mining: It is the crucial step in which clever techniques are applied to extract data patterns potentially useful.
4. Pattern evaluation: In this step, strictly interesting patterns representing knowledge are identified based on given measures.
5. Knowledge representation: It is the final phase in which the discovered knowledge is visually represented to the user. This essential step uses visualization techniques to help users understand and interpret the data mining results.
7. CONCLUSION
7
International Journal in Management and Social Science http://ijmr.net.in, Email: [email protected] sensational changes the science. The growth of huge, unstructured datasets is driving the improvement of new advances for discovering things of enthusiasm for biological data. In light of the gigantic development of data from DNA sequencing, bioinformatics has turned into a functioning area of research in the super processing network. Like this processing of huge data is viewed as most valuable towards biological issues. Biological databases assume a significant job in bioinformatics to give wide information’s on one stage.In summary, we consider data mining as the process of distinguishing substantial, novel, conceivably helpful, and at last understandable examples or models in data to settle on significant choices. "Legitimate" implies that the examples hold in general, "novel" that we didn't know the example previously, and "understandable" implies that we can decipher and fathom the examples. Henceforth, similar to statistics, data mining isn't just the displaying and prediction steps, or an item that can be purchased, however an entire critical thinking cycle/process that must be aced, and is (nearly) dependably collaboration. Undoubtedly, data mining is the center part of the supposed "knowledge discovery in databases" (KDD) process. For learning from data to occur, data from numerous sources ("databases") should initially be assembled and composed in a steady and helpful manner ("data warehousing").
The test for researchers looking in the exponentially expanding amounts of microbiology data for assumed and obscure relationships can be imposing. Indeed, even basic questions may include making generally entangled, computationally concentrated participates to make sees that support given speculation of how data are connected. What's more, regardless of whether the technology is accessible that enables a researcher to indicate any theoretical question, the potential for finding new relationships in data is a component of the bits of knowledge and predispositions forced by the researcher. While these confinements might be dangerous in moderately little databases, they might be terrible in databases with billions of interrelated data components
REFERENCES
[1]. Ramsden, J. (2015). Bioinformatics: An Introduction. 1st ed. Springer.
[2]. Quackenbush J. Computational analysis of microarray data. Nat Rev Genet 2001;2:418–27 [3]. Bruggeman FJ, Westerhoff HV. The nature of systems biology. Trends Microbiol 2007;15:45–
50.
[4]. Mohri M, Rostamizadeh A, Talwalkar A. Foundations of Machine Learning. Cambridge, MA: MIT Press, 2012.
[5]. van ’t Veer LJ, Dai H, van de Vijver MJ, et al. Gene expression profiling predicts clinical outcome of breast cancer. Nature 2002;415:530–6.
[6]. Encode Consortium. Machine learning approaches to genomics. 2012.