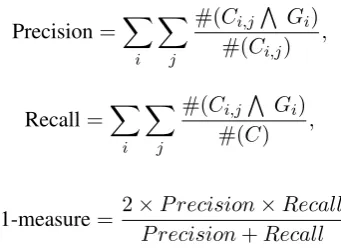Distant Supervision for Entity Linking
Miao Fan∗, Qiang Zhou and Thomas Fang Zheng CSLT, Division of Technical Innovation and Development Tsinghua National Laboratory for Information Science and TechnologyDepartment of Computer Science and Technology, Tsinghua University, Beijing, 100084, China
Abstract
Entity linking is an indispensable oper-ation of populating knowledge
reposito-ries for information extraction. It
stud-ies on aligning a textual entity mention to its corresponding disambiguated entry in a knowledge repository. In this paper, we propose a new paradigm named dis-tantly supervised entity linking (DSEL), in the sense that the disambiguated entities that belong to a huge knowledge reposi-tory (Freebase) are automatically aligned to the corresponding descriptive webpages (Wiki pages). In this way, a large scale of weakly labeled data can be generat-ed without manual annotation and fgenerat-ed to a classifier for linking more newly
dis-covered entities. Compared with
tradi-tional paradigms based on solo knowl-edge base, DSEL benefits more via joint-ly leveraging the respective advantages of Freebase and Wikipedia. Specifically, the proposed paradigm facilitates bridging the disambiguated labels (Freebase) of entities and their textual descriptions
(Wikipedi-a) for Web-scale entities. Experiments
conducted on a dataset of 140,000 items and 60,000 features achieve a baseline F1-measure of 0.517. Furthermore, we ana-lyze the feature performance and improve the F1-measure to 0.545.
1 Introduction
To build the “Digital Alexandria Library” for our human race, researchers in the NLP community
have dedicated themselves toInformation
Extrac-tion (Sarawagi, 2008) over the past decades.
In-formation extraction focuses on processing natu-ral language text to produce structured knowledge, which is usually represented as triples (two entities
and their relation) for the convenience of storage in a database, retrieval, or even automatic reason-ing. For example, if we send a natural language
sentence,Michael Jordan visited CMU yesterday,
to the pipeline of information extraction machine, it will be processed by three operations in advance, i.e.,
• Named Entity Recognition (Nadeau and Sekine, 2007): Entities should firstly be i-dentified and classified into predefined cate-gories, such as person (PER), location (LOC) and organization (ORG). The sentence will
be annotated as [Michael Jordan]/PER
vis-ited [CMU]/ORG yesterday, after being pro-cessed by this operation.
• Coreference Resolution(Ng, 2010): Some entities may have alias or abbreviations. It
is well known thatCMU is the abbreviation
forCarnegie Mellon University. The knowl-edge repository may only store the
regular-ized name, e.g.,Carnegie Mellon University,
for this named entity, so coreference resolu-tion is indeed necessary.
• Relation Extraction (Bach and Badaskar,
2007): After both of the named entities
([Michael Jordan]/PERand[Carnegie Mel-lon University]/ORG) are recognized and regularized, we begin to study on the rela-tion between them. In this case, we
extrac-t extrac-the verbvisited and map it to the relation
visit. Then the output will be a triple, i.e., (Michael Jordan [PER], visit, Carnegie Mel-lon University [ORG]).
So far, we only abstract the triple as the struc-tured knowledge from the natural language sen-tence. However, it devotes nothing to increasing the scale of the knowledge repository such as
Free-79
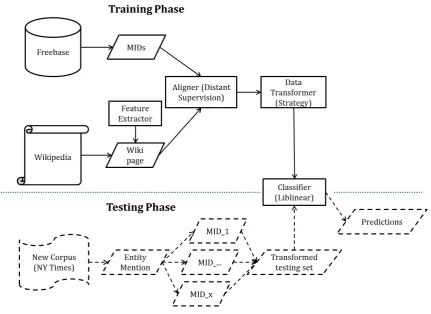
Figure 3: The architecture of DSEL system.
Sentence His biography on the National Basketball Association (NBA) website states, “By acclamation,Michael Jordanis the greatest basketball
player of all time.”
BOW (K = 1) <{acclamation},{is}>
BOW (K = 2) <{states},{acclamation},{is},{greatest}>
BOW (K = 3) <{website},{states},{acclamation},{is},{greatest},{basketball}>
WS (K = 1) <{acclamation},{is}>
WS (K = 2) <{states-acclamation},{is-greatest}>
WS (K = 3) <{website-states-acclamation},{is-greatest-basketball}>
BOW + POS (K= 1) <{acclamation/NN},{is/VBZ}>
BOW + POS (K= 2) <{states/NNS},{acclamation/NN},{is/VBZ} {greatest/JJS}>
BOW + POS (K= 3) <{website/NN},{states/NNS},{acclamation/NN},{is/VBZ},
{greatest/JJS},{basketball/NN}>
WS + POS (K = 1) <{acclamation/NN},{is/VBZ}>
WS + POS (K = 2) <{states/NNS-acclamation/NN},{is/VBZ-greatest/JJS}>
WS + POS (K = 3) <{website/NN-states/NNS-acclamation/NN},{ is/VBZ-greatest/JJS-basketball/NN}>
# of MIDs with the
2 4,467,216 5 180,489 8 60,273
3 740,530 6 134,012 9 41,256
4 440,261 7 76,459 10 33,628
Feature type Avg. F1-measure Feature type Avg. F1-measure
BOW (K = 1) 0.539 WS (K = 1) 0.544
BOW (K = 2) 0.531 WS (K = 2) 0.532
BOW (K = 3) 0.529 WS (K = 3) 0.518
BOW + POS (K = 1) 0.540 WS + POS (K= 1) 0.545
BOW + POS (K = 2) 0.532 WS + POS (K= 2) 0.531
BOW + POS (K = 3) 0.529 WS + POS (K= 3) 0.517
Table 3: The F1-measure comparison among different features.
0.42 0.44 0.46 0.48 0.5
0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95
Recall
Precison
BOW (K = 1) BOW (K = 2) BOW (K = 3)
(a) Precision-Recall curves for BOW features.
0.42 0.44 0.46 0.48 0.5
0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95
Recall
Precision
BOW + POS (K = 1) BOW + POS (K = 2) BOW + POS (K = 3)
(b) Precision-Recall curves for BOW + POS features.
Figure 4: Precision-Recall curves for the BOW-class lexical features.
0.4 0.42 0.44 0.46 0.48 0.5 0.52
0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95
Recall
Precision
WS (K = 1) WS (K = 2) WS (K = 3)
(a) Precision-Recall curves for WS features.
0.4 0.42 0.44 0.46 0.48 0.5 0.52
0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95
Recall
Precision
WS + POS (K = 1) WS + POS (K = 2) WS + POS (K = 3)
(b) Precision-Recall curves for WS + POS features.
Silviu Cucerzan. 2007. Large-scale named entity dis-ambiguation based on wikipedia data. In EMNLP-CoNLL, volume 7, pages 708–716.
Rong-En Fan, Kai-Wei Chang, Cho-Jui Hsieh, Xiang-Rui Wang, and Chih-Jen Lin. 2008. Liblinear: A library for large linear classification. The Journal of Machine Learning Research, 9:1871–1874.
Miao Fan, Deli Zhao, Qiang Zhou, Zhiyuan Liu, Thomas Fang Zheng, and Edward Y Chang. 2014. Distant supervision for relation extraction with ma-trix completion. InProceedings of the 52nd Annual Meeting of the Association for Computational Lin-guistics, volume 1, pages 839–849.
Ben Hachey, Will Radford, Joel Nothman, Matthew Honnibal, and James R Curran. 2013. Evaluating entity linking with wikipedia. Artificial intelligence, 194:130–150.
Jeff Howe. 2006. The rise of crowdsourcing. Wired magazine, 14(6):1–4.
Heng Ji and Ralph Grishman. 2011. Knowledge base population: Successful approaches and chal-lenges. In Proceedings of the 49th Annual Meet-ing of the Association for Computational LMeet-inguistic- Linguistic-s: Human Language Technologies-Volume 1, pages 1148–1158. Association for Computational Linguis-tics.
Heng Ji, Ralph Grishman, Hoa Trang Dang, Kira Grif-fitt, and Joe Ellis. 2010. Overview of the tac 2010 knowledge base population track. In Third Tex-t Analysis Conference (TAC 2010).
Paul McNamee and Hoa Trang Dang. 2009. Overview of the tac 2009 knowledge base population track. In
Text Analysis Conference (TAC), volume 17, pages 111–113.
Edgar Meij, Krisztian Balog, and Daan Odijk. 2013. Entity linking and retrieval. In Proceedings of the 36th international ACM SIGIR conference on Re-search and development in information retrieval, pages 1127–1127. ACM.
Rada Mihalcea and Andras Csomai. 2007. Wiki-fy!: linking documents to encyclopedic knowledge. InProceedings of the sixteenth ACM conference on Conference on information and knowledge manage-ment, pages 233–242. ACM.
David Milne and Ian H Witten. 2008. Learning to link with wikipedia. In Proceedings of the 17th ACM conference on Information and knowledge manage-ment, pages 509–518. ACM.
David Nadeau and Satoshi Sekine. 2007. A sur-vey of named entity recognition and classification.
Lingvisticae Investigationes, 30(1):3–26.
Vincent Ng. 2010. Supervised noun phrase corefer-ence research: The first fifteen years. In Proceed-ings of the 48th annual meeting of the association
for computational linguistics, pages 1396–1411. As-sociation for Computational Linguistics.
Delip Rao, Paul McNamee, and Mark Dredze. 2013. Entity linking: Finding extracted entities in a knowl-edge base. In Multi-source, multilingual informa-tion extracinforma-tion and summarizainforma-tion, pages 93–115. Springer.
Lev Ratinov, Dan Roth, Doug Downey, and Mike Anderson. 2011. Local and global algorithm-s for dialgorithm-sambiguation to wikipedia. In Proceed-ings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, pages 1375–1384. Associ-ation for ComputAssoci-ational Linguistics.
Sunita Sarawagi. 2008. Information extraction. Foun-dations and trends in databases, 1(3):261–377.
Cyma Van Petten and Marta Kutas. 1991. Influ-ences of semantic and syntactic context on open-and closed-class words. Memory & Cognition, 19(1):95–112.