© 2018 IJSRCSEIT | Volume 3 | Issue 5 | ISSN : 2456-3307
Black-box Optimization for Information Retrieval through
Dynamic Parameter
V. Vinay Kumar1, K. Niharika chowdhary2, P. Pavani Reddy2, B. Varsha2 1Assistant Professor, Department of CSE, Matrusri Engineering College, Saidabad, Telangana, India
2Students, Department of CSE, Matrusri Engineering College, Saidabad, Telangana, India
ABSTRACT
The retrieval function is a standout amongst the most critical parts of an Information Retrieval (IR) framework, since it decides to what degree some data is applicable to a user query. Most retrieval capacities have "free parameters" whose esteem must be set before retrieval, essentially influencing the viability of an IR framework. Picking the ideal esteems for such parameters is along these lines of foremost significance. Be that as it may, the ideal must be found after a computationally costly process, particularly when the speculation mistake is evaluated by means of cross-approval. In this paper, we propose to decide free parameter esteems by taking care of an improvement issue went for amplifying a measure of retrieval adequacy. We employ the black-box optimization paradigm, since the investigative articulation of the measure of viability concerning the free parameters is obscure. We consider distinctive strategies for taking care of the block box optimization issue: a basic network search over the entire area, and more complex systems, for example, line query and surrogate model based algorithms. Trial comes about on a few test accumulations give valuable understanding about viability, as well as about proficiency: they demonstrate that with proper optimization strategies, the computational cost of parameter improvement can be significantly lessened without trading off retrieval adequacy, notwithstanding when considering.
Key words: Information Retrieval, Optimization, Parameter Estimation
I.
INTRODUCTION
Information Retrieval (IR) is the complex of exercises that speak to data as information and recovers the information speaking to data applicable to the client's data needs. An IR framework is a PC framework performing indexing and recovery exercises. Current innovation requires a recovery model to be powerful and permit forecast. A recovery show is an arrangement of arithmetical structures that portrays documents and queries. The model's center is a recovery function that maps these data structures to the numeric genuine field. Picking the correct model is subsequently a key advance of the arrangement of
recovery capacities are the λ-parameter when performing smoothing with the Jelinek-Mercer technique, the µparameter in the Dirichlet smoothing strategy, the parameter in Information-based Models, or the α, β, γ parameters in the Rocchio Feedback Model. Another generally utilized recovery work is Best Match 25 (BM25). The last capacity specifically has a few free parameters, and is appropriate for the examination of algorithms to set free parameters. IR scientists regularly contrast parameter configurations and battle with acquire the best configuration. We assert that efficient algorithms to choose free parameters of recovery capacities are required in a few essentially applicable situations. We now give cases of such situations. A parameter configuration that performs well can typically be found by testing numerous esteems for each parameter on some preparation set, and choosing the qualities that expand a specific recovery measure. To this end, a typical approach is to isolate every parameter run into numerous equivalent size sub-ranges and pick one incentive from each sub range. Investigating every one of these qualities is called framework look. In the event that the sub ranges are little, the network is fine-grained and this sort of hunt is very comprehensive. Despite the fact that lattice scan for the ideal parameter esteems may progress toward becoming inefficient, it has two primary favorable circumstances: it is easy to actualize, and it can be connected to any recovery capacity and recovery viability measure. The issue is that the level of inefficiency develops exponentially with the quantity of parameters, since isolating n parameters into k-sub ranges would require testing O (KN) diverse configurations. This can be extremely inefficient for as meager as three parameters. Truth be told, considers in machine learning uncover that even arbitrary query (testing a few irregular esteems inspected from a uniform appropriation) can work superior to anything network look. Besides, parameters are normally improved just at the season of development and ordering of the report accumulation, however optimization ought to be
performed at whatever point archive accumulations develop, or questions advance from one style to the next: for instance, three query styles – enlightening, navigational and value-based – were found with regards to the Web. In this manner, the general adequacy of a recovery framework is hurt by the inefficiency of performing rehashed parameter enhancement for each circumstance, i.e., gathering or question set. At long last, to address the fast development of information and variety of accumulations and queries, parameter esteems ought to be picked considering speculation execution, to abstain from overfitting. Speculation can be evaluated e.g., utilizing cross-approval. Tragically, cross-approval com-pounds the issue of inefficient looks for parameter values of the recovery work, expanding the computational exertion required. Every one of these illustrations supports our claim that efficient algorithms to choose free parameters of recovery capacities are required. This paper intends to address the essential issue of efficiently finding the parameter estimations of recovery works that yield the best framework. The primary commitment of this paper comprises in throwing the parameter advancement issue as a scientific program understood by block box optimization strategies that don't require a diagnostic portrayal of the goal work, and in observationally demonstrating that (i) black-box optimization is significantly more efficient than grid search on a benchmark set, and (ii) black- box optimization reliably and efficiently (i.e., in a brief
span) finds viable parameter esteems
notwithstanding when speculation is a necessity and additionally the recovery work has numerous parameters.
II.
RELATED WORK
enhanced based on the user's criticism. A confinement of such algorithms is the difficulty of arrangement with expanding number of parameters: there could be the same number of parameters as the records evaluated by users, and improving numerous parameters may prompt computational in-efficiency, in this way making the considered algorithm too expensive for functional applications. Another constraint is the danger of overfitting, because of the computational weight of surveying speculation. Hence, despite the fact that the accentuation of optimization with regards to IR has been viability as opposed to efficiency, the last has turned into a vital angle to consider when managing complex retrieval capacities. A case of the significance of this viewpoint is found with regards to programmed
query development. A pivotal advance of
programmed query extension is the positioning of competitor development highlights: at an abnormal state, an algorithm for programmed query development has three parameters, in particular the quantity of records that give terms, the quantity of terms gave by each archive, and the quantity of terms identified with each term. Indeed, even with only three parameters, assessing every one of their mixes so as to find the ideal one would be too computationally difficult. Another conspicuous application space of advancement in IR is that of parametric retrieval capacities. Most retrieval capacities have parameters that come from plan decisions or numerical properties. For instance, dialect displaying comprises of positioning archives by a blend of probabilities introduced by method for parameters. Paired independence retrieval models are upgraded by smoothing parameters that lessen the reactions of absence of term-event measurements, e.g., undesired 0/0situations, as represented. On account of Bernoulli or binomial retrieval works, these smoothing parameters might be beta irregular factors. At the point when in view of most extreme probability, advancement can use the progression of retrieval capacities. In any case, in every single important case the suspicion of progression does not
hold; a case is enhancement in view of most extreme retrieval adequacy, which is a discrete capacity and requires algorithms, for example, those showed. The development of figuring out how to-rank raised the issue of parameter improvement at a scale bigger than that experienced in specially appointed retrieval. A fascinating utilization of figuring out how to-rank identified with our function is exhibited, where the creators propose a technique to advance the configuration of an IR framework and to manage discrete esteems for framework setting, while in this paper, we manage ceaseless esteems. The approach can pick esteems in a continuous space just seeing that a finite set of conceivable esteems for the constant is preselected, for instance by means of discretization. The point of our paper is to
contemplate the characteristic parameter
enhancement of a retrieval display (e.g., BM25) as opposed to the entire IR framework. Be that as it may, these methodologies might be incorporated to additionally enhance the general performance.
III.
OVERVIEW OF THE SYSTEM
In the proposed framework we address the essential issue of productively finding the parameter estimations of retrieval works that yield the best framework. The fundamental commitment of this paper comprises in throwing the parameter advancement issue as a scientific program tackled by block box improvement strategies that don't require a systematic depiction of the goal work, and in exactly demonstrating that (I) block box optimization is essentially more productive than lattice search on a benchmark set, and (ii) block box enhancement dependably and proficiently finds compelling parameter values notwithstanding when speculation is a prerequisite as well as the retrieval work has numerous parameters. Modules:
Modules Description:
of block box improvement issues, since it just requires zero-arrange data (i.e., it doesn't require slopes.
Optimization utilizing a RBF surrogate model Optimization algorithms in light of surrogate models normally work, at each significant emphasis, a model of the obscure target work utilizing the focuses assessed up until now. In the particular approach utilized in this paper, and in a few others talked about in the writing, this interpolant is worked by methods for RBFs.
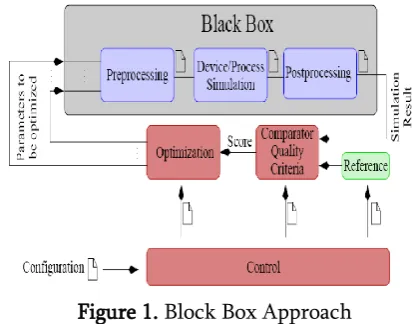
Retrieval Functions with Free Parameters The block box enhancement system comprises of issues.
Figure 1. Block Box Approach
We now practice it to the improvement of retrieval capacities, talking about a few decisions for the target work f of Problems of black-box with regards to retrieval capacities with free parameters.
IV.
METHODOLOGY
Surrogate-based strategies In this paper, we will focus on another approach which seems, by all accounts, to be extremely fruitful at taking care of block box optimization issues that depends on building surrogate (additionally called reaction surface, meta or inexact) models. The primary thought behind these techniques is to iteratively develop surrogate models to estimated the block box capacities and utilize them to scan for ideal arrangements.
A typical approach (in its least complex frame) for
• Phase 1 (plan): Let k := 0. Select and assess a set S0 of beginning stages.
• While (ceasing criteria are not met):
Phase 2 (show): From the information {(x, f(x)) | x ∈
Sk}), build a surrogate model sk(.) that approximates the block box work.
Phase 3 (search): Use sk(.) to scan for another point to assess. Assess the new picked point, refresh the informational collection Sk. Relegate k := k + 1.
Phase 1 is normally alluded to as examining or design of experiment (DOE). Its motivation is to locate an arrangement of focuses consistently spread over the space, so that, on the off chance that we assess the capacity at these focuses, we may acquire a worldwide photo of its. Thus, we regularly require a capacity to quantify the consistency of each point set: the bigger the measure, the more uniform the point set moves toward becoming. Our normal examining is then found by amplifying this measure (i.e. the outline issue).
In Phase 2, different models can be utilized to inexact block box capacities. A current pattern in block box enhancement is to utilize various surrogate
models in the meantime. This approach
Phase 3 is the significant advance in the methodology. Given the data from the present surrogate model, we have to choose which point(s) ought to be assessed in the consequent advance. There are numerous techniques to do that, and without a doubt they speak to the fundamental component recognizing distinctive surrogate-based improvement strategies. The most widely recognized thought of these systems is to characterize a legitimacy (or cost) capacity of hopeful point that predicts the goal as well as model exactness change in the event that we assess the black-box there. We select the following point for assessment to be the one that boosts (or limits) the legitimacy work (resp. cost work). Diverse legitimacy capacities and
techniques for comprehending going with
enhancement sub problems will be presented in Section 4. With the accentuation on costly capacities, the entire procedure for tackling block box improvement issues is regularly overwhelmed by the quantity of capacity assessments. We regularly measure how great an algorithm is by the quantity of assessments required until a satisfactory (worldwide) arrangement is found. Truth be told, it might likewise be utilized as a ceasing measure in block box advancement: we stop when we achieve a specific number of assessments
V.
RESULT AND DISCUSSION
We realize that by limiting (or amplifying) legitimacy work over hunt areas, we will acquire next hopeful focuses for assessment. In the past subsections, we have presented different options for such legitimacy capacities and query districts. Presently we will talk about how to comprehend these assistant sub problems.
On a basic level, these assistant sub problems can be composed expressly as NLPs; in this manner we can understand them by a non specific solver. Also, we can misuse subsidiary data, which is accessible in a large portion of cases, to make utilization of
established techniques. Nonetheless, because of the high nonlinearity and multi-methodology of some legitimacy capacities (e.g. Expected Improvement), these sub problems are some of the time still hard to explain. In addition, it is faulty whether we ought to take care of these issues to optimality or just surmised arrangements are adequate. Legitimacy capacities are developed in light of estimated models of the genuine capacity, which may be off base. Consequently, it is unsafe on the off chance that we invest excessively energy to illuminate the helper sub problems, since by and large; it is the nature of the model that issues. Hence, surmised arrangements (even arrangements that are genuinely great) are adequate.
VI.
CONCLUSION AND FUTURE SCOPE
In this Project, we found on the issue of consequently tuning the free parameters of retrieval capacities with the point of enhancing the viability of an IR framework. We tended to this issue as far as scientific enhancement with a process able however not diagnostically accessible target work. Subsequent to contrasting the performance of a few enhancement ways to deal with tackling this issue, we demonstrated that there is little – if any – opportunity to get better with regards to distinguishing more successful parameters of the retrieval work by utilizing more advanced algorithms.
VII.
REFERENCES
[1]. Y. Ji, S. Kim, and W.X. Lu. A new framework for combining global and local methods in black box optimization. Optimization Online, paper 3977, 2013.
[2]. M.E. Johnson, L. M. Moore, and D. Ylvisaker. Minimax and maximin distance designs. Journal of Statistical Planning and Inference, 26:131–148, 1990.
[4]. D.R. Jones, M. Schonlau, and W.J. Welch. Efficient global optimization of expensive black-box functions. Journal of Global Optimization, 13:445–492, 1998.
[5]. J. Koehler and A. Owen. Computer
experiments. In S. Ghosh and C.R. Rao, editors, Handbook of Statistics, 13: Design and Analysis of Experiments, pages 261–308, 1996.
[6]. H.J. Kushner. A new method of locating the maximum point of an arbitrary multipeak curve in the presence of noise. Journal of Basic Engineering, 86:97–106, 1964.
[7]. S. Le Digabel. Algorithm 909: NOMAD:
Nonlinear optimization with the MADS algorithm. ACM Transactions on Mathematical Software, 37(4):1–15, 2011.
[8]. S. Le Digabel. Efficient global optimization algorithm assisted by multiple surrogate techniques. Journal of Global Optimization, 56(2):669–689, 2013.
[9]. C. Lizon, C. D’Ambrosio, L. Liberti, M. Le Ravalec, and D. Sinoquet. A mixed-integer nonlinear optimization approach for well placement and geometry. Proceedings of ECMOR XIV - 14th European conference on the mathematics of oil retrieval, Catania, Italy, 2014.
[10]. M.D. McKay, R.J. Beckman, and W.J. Conover. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics, 21:239–245, 1979.
[11]. J. Mockus. Application of bayesian approach to numerical methods of global and stochastic optimization. Journal of Global Optimization, 4:347–365, 1994.
[12]. R. Stocki. A method to improve design reliability using optimal latin hypercube sampling. Computer Assisted Mechanics and Engineering Sciences, 12:393–412, 2005. [13]. V. Torczon. On the convergence of pattern
search algorithms. SIAM Journal on
Optimization, 7:1–25, 1997.
[14]. E.L. Vazquez and J. Bect. Convergence properties of the expected improvement algorithm with fixed mean and covariance functions. Journal of Statistical Planning and Inference, 140:3088–3095, 2010.
[15]. FelipeA.C. Viana, RaphaelT. Haftka, and Jr. Steffen, Valder. Multiple surrogates: how crossvalidation errors can help us to obtain the best predictor. Structural and Multidisciplinary Optimization, 39(4):439–457, 2009.
[16]. K.Q. Ye, W. Li, and A. Sudjianto. Algorithmic construction of optimal symmetric latin hypercube designs. Journal of Statistical Planning and Inference, 90:145–159, 2000. [17]. A. Zilinskas. A review of statistical models for
global optimization. Journal of Global Optimization, 2:145–153, 1992.
About Authors:
V.Vinay kumar is currently working as an Asst.Professor in the department of Computer Science and Engineering at Matrusri Engineering College Saidabad Hyderabad..
K.Niharika chowdhary is currently pursuing B.Tech in CSE Department at Matrusri Engineering College Saidabad.
P.Pavani Reddy is currently pursuing B.E in CSE Department at Matrusri Engineering College Saidabad Hyderabad.