3896
Data Privacy Preservation In Cloud Using
Mapreduce
S. Nagajothi, G. Ignisha Rajathi, M.Manikandan, J.Boopala
The Anonymization of Information is widely incorporated for safeguarding of the data with protection in non-interactive data business venture and sharing circumstances. Mainly explains the movement personality and additionally delicate data for property holders of information. The non-open information record is shared in its most explicit state represents a risk to singular security. These types of protection of a private are successfully saved while positive blend data is presented to information clients for diversified investigation and analysis. This can mostly examine the drawback of the quality of huge scale information anonymization. Data sets territory unit summed up in a top-down traversal until k-obscurity is profaned in this way on visibility, showcased to be the most extreme utility. This Specialization is prudent for prime quality and security issues. An impactfully ascendable two-stage top-down way to deal with the misuse of anonymizes bulk volumes of information which scales back is anticipated.
Keywords: Big Data, Anonymization, MapReduce, K-anonymity, Generalization, Top-Down Specialization
————————————————————
1 INTRODUCTION
Distributed computing is believed to be an unsophisticated blend of a progression of advancements, setting up an interesting plan of action by giving IT administrations and exploitation. Numerous organizations or associations are relocating or incorporating their business with cloud on
account of privacy and security protection [1][2]. Individual data sets like electronic and finance managing records are commonly esteemed uncommonly touchy however this data can give noteworthy points of interest in which that they're broken down and merged through mining. For instance, Microsoft Health Vault which is a web cloud well-being supervisory plan adds data from customers and offers the data with explored examinations. This will bring solid fiscal hardship or genuine social name deterrence to information house proprietors. Consequently, data protection issues must be obliged to be tended to rapidly perform, before information collection are inspected or
shared on cloud [1]. Data sets turned out to be henceforth amending that anonymizing such informational indices is changing into a huge test for old anonymization computations to investigate the quantifiability pitfalls of plethora of information anonymization. Enormous scale preparing systems like MapReduce are incorporated with cloud to give amazing calculation ability to applications. In our investigation, we will in general influence MapReduce, a broadly received parallel preparing structure, to deal with the downside of the adaptability or versatility of the TDS approach for epic size of data anonymization. It also offers an open exchange between information utilization and information consistency being widely connected with data anonymization. Most of the calculations pertaining to TDS have been incorporated which winds up in their deficiency in dealing with huge scale informational collections.
In spite of the fact that some conveyed calculations are
proposed [20][22]. For most of the part, they represent considerable authority in secure anonymization of information sets from various gatherings, apart from the quantifiability feature. In this technique, an incredibly ascendable two-stage technique for information is maintained with MapReduce technology. The parallel capacity of MapReduce required in accomplice degree system they are sorted into 2 stages. First, unique data collections are confined into a gaggle of humbler data records, and these informational indexes are anonymized simultaneously, conveying a result of moderate outcomes. Second, the prompt results are consolidated together as one, and can anonymize information indices to recognize with k- anonymity. A collection of data set are planned to scale back its employments to perform specialization cooperatively. Methodologies which are available to protect information sets in cloud platform basically incorporate mystery composing and anonymization. Current security defensive methods like speculation will face most protection assaults on one single data set, while saving security for numerous informational collections keeps on being a difficult drawback. Along these lines, for defensive protection of large scale information, it first tries to anonymize all information before sharing them in cloud. More often than not, the measure of middle of the road data sets is huge. Hence, we will in general contend that encoding all middle of the road data sets can bring about high and low proficiency after they are accessed or handled. All things considered, we will in general propose to write in code a piece of immediate information sets for
reducing privacy expenses [2]. A tree model has been verified from age associations of widely appealing informational indexes to analyze and dissect security proliferation of informational indexes. Bolstered with such an imperative rule, we will in general model the issue of sparing protection saving cost as a focused one on the downside of progression. This drawback is then isolated into preparation based on the sub-issues by disintegrating safekeeping surge limitations. This paper is composed as pursues: following area surveys associated work, and examines the quantifiability drawback in existing TDS calculations. In Section three, we will in general without further ado blessing two-stage TDS approach. Segment four plans top-down Specialization and explain recursive
___________________________________________
S. Nagajothi1, G. Ignisha Rajathi2, M.Manikandan3, J.Boopala4 1,3,4Assistant Professor, Department of Computer Science and
Engineering, Sri Krishna College of Engineering and Technology, Coimbatore [email protected], [email protected], [email protected]
subtleties of MapReduce employments. Area five is usage of this methodology. We tend to by experimentation evaluate our trial brings about Section 6. At last, in section 7 will talk about future work and conclusion
2 PROBLEM ANALYSIS
In this (TPTDS), mainly it deals with the direct calculation as it required in TDS. MapReduce could be a programming model for procedural and massive informational indexes by both disseminated and parallel algorithmic standard on a group. A MapReduce algorithm comprises of a Map() technique that performs sifting followed by arranging, (for instance, arranging under-studies by forename into lines as with allotting of one line for each name) and a Reduce() method that plays out a framework activity, (for instance, examination the amount of understudies in each line, yielding name frequencies). The MapReduce Scheme organizes by marshaling the disseminated servers through parallel and dealing with interchanges and also data sets moves between the differed segments in the framework. It gives repetition and adaptation to internal failure to by and
large administration of the total strategy. In the work[2], a few anonymization methods like speculation are intended to protect security yet these methodologies alone neglect to determine the matter of safeguarding protection for various data sets. The fundamental methodology coordinates anonymization with mystery writing to accomplish protection of large scale data sets. Also it includes the security compensation in distributed systems. In distributed systems and anonymization data has turned into a fundamental interest in consideration framework the board. Be that as it may, improper sharing and utilization of social insurance information may compromise patient's security. It adds data and privacy needs together to centralized and distributed anonymization to establish the key challenges. Additionally, it recommends a substitution security model called LKC- protection to overcome and achieve privacy protection in each incorporated and circulated situations. Tests on genuine information exhibit the anonymization calculations will adequately hold the basic information in unknown data for data examination and is versatile for anonymizing enormous datasets. Two-Phase Top-Down Specialization (TPTDS) approach to deal with manage direct counts required in TDS during an incredibly versatile and effective style. Here it follows two parallel systems provisioned by MapReduce using cloud, i.e., job level and assignment level. To make high versatility and parallelizing different employments of information segments inside the underlying part anyway the resultant anonymization levels are not indistinguishable. Atlast predictable mysterious learning sets, the ensuing stage is vital to incorporate the immediate ouputs and whole informational indexes are further anonymized. All prompt levels are converted into a single in the consequent stage. All the existing areas esteem and that satisfies anyone conditions. At embark, we officially exhibit the plausibility of guaranteeing security spillage prerequisites without encoding all the intermediate data’s are encrypted and consolidated with this technique to safeguard protection. Then a heuristic calculation to distinguish the informational indexes must be constrained to be encoded for defensive security. At last, test results exhibit that our methodology can fundamentally lessen protection safeguarding the
expenses over already available methodologies is also very helpful for the cloud clients United Nations organization use cloud benefits in a compensation as-you-go style. This paper is an essentially improved rendition of [1][2]. In view of [1], we scientifically demonstrate that our
methodology can guarantee security safeguarding prerequisites. Further, the heuristic calculation is upgraded by thinking about more factors. We broaden tests over genuine informational indexes. In the k-anonymity donside, there are two models. One is worldwide recoding and other is close by recoding. Each trait has a relating applied speculation progressive system or scientific classification tree. A lower level area in the chain of command gives a larger number of subtleties more than the highest area. Example, lower level area is Zip Code 148 and higher level area is postcode 14*. The expectations of these chains are importance for numerical traits as well. Particularly, different leveled forms potrayed, where worth is the rough information, interim is the scope of the unredined information and * is an image speaking to any traits. Speculation replaces lower level area with more elevated level area.
3
CENTRALIZED
AND
DISTRIBUTED
ANONYMIZATION
Both the system has "coordinate at that point sum up" approach any place the focal government wellbeing organization starting incorporates the data from various medical clinics at that point performs speculation. In this methodology the circulated anonymization drawback has 2 noteworthy difficulties moreover to high spatiality. Initially, the data utility of the mysterious coordinated information should be as great in light of the fact that the quality of data made according to the unified rule. Next the technique, the standard mustn't uncover extra explicit information than a definitive unknown incorporated table.
4 TOP-DOWN SPECIALIZATION
In this Specialization, the esteems are instated to starting estimation of the chain tree. The specialization is carried out continuously over the property estimations till k - anonymity is found.
Algorithm : SKETCH OF TWO-PHASE TDS (TPTDS).
Input : Data set D, namelessness parameters k, kI and the quantity of segments p.
Output : Anonymous informational index D*.
1.
Partition D into Di ,1< p2.
Execute MRTDS(Di , kI , AL0 ) AL0 I , 1<i < p in parallel as numerous MapReduce employments.3.
Merge all middle of the road anonymization levels into one, ALI .4.
Perform MRTDS as ALI .5.
AL* indicates output D4.1BALANCED SCHEDULING
3898 higher power. Be that as it may, to the best of procured
information, essential points of internment of MapReduce figuring bunches with information area, including the bound locale and hypothetical limits on the postpone execution have not been considered. In this research, it tends to handle these issues from a stochastic system point of view.
4.2 PARTITING OF DATA
The information collection is done on the cloud platform. Then it gathers the enormous amount of informational indexes. It is part of large into little informational collections. At that point gives the irregular no to every datum sets. Dividing is the way of reducing example will get which halfway keys and values. Each agent ought to affirm for the majority of its yield (key, esteem) sets which reducer will get them. It is vital that for any key, despite that representative occurrence produced it, the goal segment is that the equivalent. In the event that the key feline is created in 2 isolated (key, esteem) sets, the two of them must be decreased together. It is additionally significant for execution reasons that the mappers have the option to segment information autonomously they ought to never need to trade data with each other to decide the parcel for a specific key. It is important that for any key, despite that agent case produced it; the goal parcel is the equivalent. On the off chance that the key feline is created in 2 independent (key, esteem) sets, the two of them must be diminished together. It is likewise significant for execution reasons that the mappers have the option to segment information autonomously they ought to never need to trade data with one another to work out the segment for a specific key.
4.3 MERGING OF DATA
Middle levels are merged together in the subsequent stage and these anonymization levels is finished by Cuta in AL'a and Cutb in AL'b To guarantee the blended middle level it never damages protection needs, a ton of one is picked as the consolidated one, for instance, qa will be chosen if qa is more broad than or indistinguishable from qb.
4.4BIG DATA ANALYTICS SPECIALIZATION
It is a study to address rare issues with every one of those measurements. For example, it is not exceptional to store terabytes and petabyte of information in many information vaults supporting a large number of utilizations. Keeping up such information archives requires learning in ultra-enormous scale circulated frameworks, virtualization innovations, distributed computing, unstructured and semi- organized information the executives, improvement strategies dependent on information replication and information relocation, just as in cutting edge information security methods. The exponential development of the measure of information calls for skill in cutting edge dynamic information preparing systems incorporates versatile information handling strategies and advancements, information stream the executives and huge scale procedure checking, demonstrating and mining. So as to extensively examine such volumes of data from unique and different orders, data experts should ace propelled information mix procedures and business insight devices, publicly supporting innovations, huge scale data combination, information concentrated calculation and
semantic information the executives. After finding the merged result and applies anonymization technique on the final information.
Algorithm MAP -REDUCE.
Input: Record of information, Anonymization level AL*.
Map: build r* = a1, (a2,… .,am,sv), ai , 1 ≤ I ≤ m discharge (r*, check).
Reduce: For r*, tally to whole
Output: Record (r*, tally).
4.5ANONYMIZATION TECHNIQUE
Anonymizing the information is relieving the protection and security and consent to lawful necessities. Anonymization isn't safe countermeasures that bargain Current anonymization systems can uncover ensured data in discharged elements. After receiving individual informational collections it applies the anonymization which proposes that stow away or remove the touchy field in informational indexes. At that point it gets the middle of the road result for the little informational indexes. The middle of the road results are employed for the specialization procedure.
5.
IMPLEMENTATION
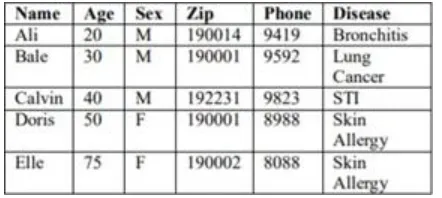
The NAME property is removed in below table. The table suppressed as
Anonymizing the information through TDS estimation property, then table becomes as taxonomy tree The information in the above table is security saved, however the information detailes is low. The information is profoundly anonymized.
The TDS Algorithm iterates and the property estimates till the table is anonymized
6.
RESULTS AND DISCUSSION
The analyses of this segment assess adequacy and proficiency. In TPTDS - CentTDS says the view of adaptability and productivity. In the next, the exchange among adaptability and information utility by means of altering arrangements. The execution time frame and ILoss are completed by these components: an information collection size (S), data distribution quantity (p), and the transitional secrecy parameter (kI).
In this technique, it notifies the difference in execution time and TTP for S at p = 2. The size S differs from 100 MB to 5.0 GB. The informational collections are sufficient to assess the adequacy as far as information volume or the
quantity of information records. ILCent = ILTP on the grounds when p = 1. The changes are principally brought about by the substance of informational collections. TCent floods from several instants fairly, to almost 10,000 seconds, whereas TTP increment somewhat. The emotional increment of TCent, outlines the overheads caused by keeping up linkage structure and refreshing measurement data rise extensively when information dimensions increments.
In these analyses, CentTDS is in insufficient memory when information size is more than 5000 MB. Henceforth, CentTDS has versatility issue for huge information. To assess further the efficiency and adaptability of TPTDS, it runs over informational indexes with large amount of sizes.
7.
CONCLUSIONS
In this paper, adaptability issue of large set of data anonymization and the approach of Top Down Specialization utilized and explored with MapReduce in cloud technology. Large scale information’s are anonymized and apportioned in parallel and immediate results are combined to create reliable k- unknown informational indexes. In cloud condition, the protective safeguarding for information examination, sharing and mining are difficult because of the bulks of informational indexes. It is versatile security protection mindful investigation promotion planning and improved adjusted booking systems toward generally adaptable security conservation.
8. REFERENCES
[1] Xuyun Zhang, Laurence T. Yang, Senior Member, IEEE, Chang Liu, and Jinjun Chen, Member, IEEE, "A Scalable Two-Phase TopDown Specialization Approach for Data Anonymization Using MapReduce on Cloud", IEEE exchanges on parallel and appropriated frameworks, vol. 25, no. 2, february 2014.
[2] X. Zhang, C. Liu, S. Nepal, S. Pandey, and J. Chen, "A Privacy Leakage Upper-Bound Constraint Based Approach for CostEffective Privacy Preserving of Intermediate Data Sets in Cloud," IEEE Trans. Parallel and Distributed Systems, to be distributed, 2012
3900 [4] Roy, S.T.V. Setty, A. Kilzer, V. Shmatikov, and E.
Witchel, "Airavat: Security and Privacy for Mapreduce," Proc. Seventh USENIX Conf. Organized Systems Design and Implementation (NSDI '10), pp. 297-312, 2010.
[5] N. Mohammed, B. Fung, P.C.K. Hung, and C.K. Lee, "Unified and Distributed Anonymization for High-Dimensional Healthcare Data," ACM Trans. Information Discovery from Data, vol. 4, no. 4, Article 18, 2010.
[6] S. Chaudhuri, "What Next?: A Half-Dozen Data Management Research Goals for Big Data and the Cloud," Proc. 31st Symp. Standards of Database Systems (PODS '12), pp. 1-4, 2012.
[7] M. Armbrust, A. Fox, R. Griffith, A.D. Joseph, R. Katz, A. Konwinski, G. Lee, D. Patterson, A. Rabkin, I. Stoica, and M. Zaharia, "A View of Cloud Computing," Comm. ACM, vol. 53, no. 4, pp. 50-58, 2010.
[8] L. Wang, J. Zhan, W. Shi, and Y. Liang, "In Cloud, Can Scientific Communities Benefit from the Economies of Scale?," IEEE Trans. Parallel and Distributed Systems, vol. 23, no. 2, pp.296-303, Feb. 2012.
[9] H. Takabi, J.B.D. Joshi, and G. Ahn, "Security and Privacy Challenges in Cloud Computing Environments," IEEE Security and Privacy, vol. 8, no. 6, pp. 24-31, Nov. 2010.
[10]D. Zissis and D. Lekkas, "Tending to Cloud Computing Security Issues," Future Generation Computer Systems, vol. 28, no. 3, pp. 583-592, 2011.
[11]L. Hsiao-Ying and W.G. Tzeng, "A Secure Erasure Code-Based Cloud Storage System with Secure Data Forwarding," IEEE Trans. Parallel and Distributed Systems, vol. 23, no. 6, pp. 995-1003, 2012.
[12]N. Cao, C. Wang, M. Li, K. Ren, and W. Lou, "Security Preserving Multi-Keyword Ranked Search over Encrypted Cloud Data," Proc. IEEE INFOCOM, pp. 829-837, 2011.
[13]P. Mohan, A. Thakurta, E. Shi, D. Tune, and D. Culler, "Gupt: Privacy Preserving Data Analysis Made Easy," Proc. ACM SIGMOD Int'l Conf. The board of Data (SIGMOD '12), pp. 349-360, 2012. [14]B.C.M. Fung, K. Wang, R. Chen, and P.S. Yu,
"Security Preserving Data Publishing: A Survey of Recent Devel-opments," ACM Computing Surveys, vol. 42, no. 4, pp. 1-53, 2010.
[15]X. Xiao and Y. Tao, "Life systems: Simple and Effective Privacy Preservation," Proc. 32nd Int'l Conf. Large Data Bases (VLDB '06), pp. 139-150, 2006.
[16]K. LeFevre, D.J. DeWitt, and R. Ramakrishnan, "In secret: Efficient Full- Domain K-Anonymity," Proc. ACM SIGMOD Int'l Conf. The executives of Data (SIGMOD '05), pp. 49-60, 2005.