RULE BASED CLASSIFICATION OF
ISCHEMIC ECG BEATS USING
ANT-MINER
*S. Murugan*
Assistant Professor, Department of ICE, Arulmigu Kalasalingam College of Engineering, Krishnankoil-626190, Srivilliputhur, TamilNadu, India.
E-mail: [email protected]
* Corresponding Author www.kalasalingam.ac.in Dr.S. Radhakrishnan
Senior Professor and Head, Department of CSE, Arulmigu Kalasalingam College of Engineering, Krishnankoil-626190 Srivilliputhur, TamilNadu, India.
E-mail: [email protected] www.kalasalingam.ac.in
Abstract:
Myocardial ischemia is the most common cardiac disease and is characterized by a high risk of sudden cardiac death. The accurate ischemic episode detection, where a sequence of cardiac beats is assessed, is based on the correct detection of ischemic beats. In this paper, a data mining approach, association rule based classification using Ant-Miner algorithm is proposed for automatic detection of ischemic ECG beats. The proposed work has two steps: initially the noise is removed and the features are extracted from the ECG signals. With these features, the Ant-Miner is applied to extract the rules. European Society of Cardiology ST-T database of ECG beats is used to analyze the performance of our proposed method with the existing. The greater accuracy of the proposed method shows its high performance than the existing.
Keywords: Ant-Miner algorithm, data mining, Myocardial ischemia and ECG beats
1. INTRODUCTION
common being the neural and the rule-based ones. Neural-based approaches have resulted in high performance but they do not provide explanations for the classification decisions. Rule-based approaches exhibit the highly desirable feature of interpreting the decisions but their performance is reduced.
Data mining and more precisely classification using association rules [18] is a methodology with high accuracy and interpretability. Association rules [19] have been utilized for the extraction of knowledge from medical history, laboratory and demographic data [20]–[28] and for the analysis of medical signals [29], [30]. Classification using association rules [18] has been used for medical image categorization [31], analysis of hospitalized patient flows [32] and electroencephalographic transient event detection and classification [33]. [43] proposed a novel classification framework using association rules is proposed for the ischemic beat detection as a three step process: feature extraction module, module for discretizing the continuous feature values, and module for classification using association rules. The equal depth binning and the modified classification tree algorithm (CT-disc) were tested for discretization, while Classification Based on Associations (CBA), Classification based on Multiple-class Association Rules (CMAR), Classification based on Predictive Association Rules (CPAR), and Apriori-Total From Partial Classification (Apriori-TFPC) algorithms were tested for classification using association rules. In this paper, we have proposed Ant-Miner for generating association rules. And the performance is compared with the above said classifiers.
The paper is organized as follows: the following section presents the feature extraction and discretization step. Section 3 explains the Ant-Miner algorithm for association rule generation. Section 4 discusses the results obtained from the existing and the proposed method. Section 5 concludes the work.
2. FEATURE EXTRACTION AND DISCRETIZATION
The feature extraction and discretization were performed as discussed in [43]. First, the preprocessing of the recorded ECG signal was performed (for both leads) in order to eliminate noise distortions (e.g., baseline wandering, A/C interference and electromyographic contamination). Noise elimination was achieved by filtering each recorded cardiac beat separately using ECG filtering [17]. In brief, baseline wandering was removed by subtracting from the recorded signal the first-order polynomial that best fits the cardiac beat. A/C interference and electromyographic contamination were not removed from the recorded signal but were handled properly for the detection of the J point. More specifically, for these two types of noise, a 20 ms averaging filter was applied around J. The exact location of the J point was detected using a technique based on an edge-detection algorithm [40]. After noise removal and J point detection, the following features were extracted from each cardiac beat, (Fig. 1).
F1 – ST segment deviation [Fig. 1(a)] F2 – ST segment slope [Fig. 1(b)] F3 – ST segment area [Fig. 1(c)] F4 – T-wave amplitude [Fig. 1(d)] F5 – T-wave normal amplitude.
In addition to these 5 features a sixth one (F6: age of the patient) was employed. This feature was given in the demographic data provided by the ESC ST-T database.
According to the ESC recommendations [41], the ST segment changes were measured either 80 ms after the J point (J80) (heart rate 120 beats/min), or 60 ms after the J point (J60) (heart rate > 120 beats/min). The ST segment deviation refers to the amplitude deviation of the ST segment from the isoelectric line, which is the line defining the level of zero amplitude.
The ST segment slope is the slope of the line connecting the J and J80 (or J60) points. The ST segment area is the area between the ECG trace, the isoelectric line and the points J and J80 (or J60). The T-wave amplitude is the amplitude deviation of the T-wave peak from the isoelectric line. The T-wave normal amplitude together with its respected polarity refers to the amplitude and polarity of normal beats for a specific ECG lead. It is calculated using the first 30 s of each recording and is computed by the mean value of the T-wave amplitudes at this interval. T-wave amplitude and T-wave normal amplitude are merged into a single new feature, merged into a single feature, F4,5: T-wave – T-wave normal amplitude, which is the difference between features F4 and F5. It should be mentioned that the whole procedure described above is applied in each lead separately.
The dataset was sampled and the 2.5% of it (as mentioned before 1936 beats) was used for training while the rest (75 053 beats) for testing. All the five features were continuous valued, so discretization was applied in the second stage of the methodology as discussed in [43]. The CT-disc and the equal depth binning algorithms were used. For the equal depth binning the number of bins was set to 10, so each bin had approximately 194 samples (number of beats in the training set/number of bins). The equal depth binning technique could not be applied properly in the F6 feature. Having 10 patients, two of them with the same age, created eight bins (the number of distinct age values), each one containing samples with the same age. In the case of CT-disc, after some experiments, the maximum number of nodes are set to 9 for feature F1, to 12 nodes for feature F2, to 6 nodes for feature F3, to 11 nodes for feature F4,5 and to 7 nodes for feature F6. These features are given to Ant-miner to generate association rules for classification.
3. ANT-MINER
An Ant Colony Optimization algorithm (ACO) is essentially a system based on agents which simulate the natural behavior of ants, including mechanisms of cooperation and adaptation. In solving the optimization problems with ACO we have three major functions. Choosing these functions appropriately helps the algorithm to get faster and better results. The first function is a problem-dependent heuristic function (η) which measures the quality of items that can be added to the current partial solution. The heuristic function stays unchanged during the algorithm. A rule for pheromone updating, which specifies how to modify the pheromone trail (τ), and a probabilistic transition rule based on the value of the heuristic function and on the contents of the pheromone trail that is used to iteratively construct a solution [42]. The procedure is given below:
WHILE (No. of cases in the Training set > Max-uncoveredcases) i=0;
REPEAT i=i+1;
Ant i incrementally constructs a classification rule; Prune the just constructed rule;
Update the pheromone of the trail followed by Ant i; UNTIL (i ≥ No-of-Ants)
Select the best rule among all constructed rules;
Remove the cases correctly covered by the selected rule from the training set; END WHILE
Ant-Miner may be considered as running iterations with a population size of one ant. During an AntRun each ant starts with an empty rule, i.e. no term in its rule antecedent, and adds one term at a time. The choice of a term to be added to the current partial rule antecedent depends on both the heuristic value (based on term entropy) and the pheromone level associated with each term. The choice is made probabilistically but is biased towards terms that have relatively higher heuristic and pheromone values. A term is not considered for inclusion in the current partial rule if it has already been previously selected, or if its associated attribute is already present in the rule antecedent due to another term having been previously selected.
An ant will stop building a rule antecedent if it has selected one term from each of the available attributes, or if whichever term that may be added next would reduce the number of training instances covered by the current rule antecedent below a predetermined threshold, called minInstPerRule. This criterion acts as a control on the amount of overfitting allowed to the training data; the greater the value of this threshold, the more general the rule antecedents created by ants are forced to be. Once an ant has stopped building a rule antecedent a rule consequent is chosen. This is done by assigning to the rule consequent the class label of the majority class among the instances covered by the built rule antecedent.
Pheromone Initialization
The initial amount of pheromone deposited at each path is inversely proportional to the number of values of all attributes, and is defined by the following equation:
Where 'a' is the total number of attributes, 'bi' is the number of values in the domain of attributes i.
Transition Rule
Let termij be a rule condition of form Ai=Vji, where Ai is the ith attribute and Vij is jth value of domain of Ai. The probability that termij is chosen to be added to the current partial rule is given by the following equation:
α and β are two adjustable parameters that control the relative weight of the heuristic and pheromone values respectively And as noted before η is a problem-dependent heuristic value for termij, and τij is the amount of pheromone currently available (at time t) on the connection between attribute i and value I is the set of attributes that are not yet used by the ant. For adding exploration of new terms we define a constant 0 < q0 < 1 which defines the percent of exploration in the algorithm. q is random number with uniform distribution in [0,1] interval.
choose according to Pij q ≥ q0 term with max (Pij) q < q0
Heuristic function
Where W is the class attribute (i.e., the attribute whose domain consists of the classes to be predicted). k is the number of classes. P(w|Ai=Vij) is the empirical probability of observing class w conditional on having observed Ai=Vij. Therfore, the proposed normalized, information-theoretic heuristic function is:
Rule Pruning
Rule pruning is a necessary process to avoid overfitting to noisy training data. Incremental pruning as each rule is simplified immediately after it has been generated by the induction algorithm. Pruning could increase the comprehensibility and accuracy of the rule. After the pruning step, the rule may be assigned a different predicted class based on the majority class in the cases covered by the rule antecedent. The rule pruning procedure iteratively removes the term whose removal will cause a maximum increase in the quality of the rule. The quality of the rule is defined by:
Q = (TP/ (TP + FN) ) * (TN / (TN + FP) ) =sensitivity ∗ specificity
where TP is the number of cases covered by the rule that have the class predicted by the rule; FP is the number of cases covered by the rule that have a class different from the class predicted by the rule; FN is the number of cases that are not covered by the rule but have the class predicted by the rule; TN is the number of cases that are not covered by the rule and that do not have the class predicted by the rule. Sensitivity is the accuracy among positive instances, and specificity is the accuracy among negative instances
Pheromone Update Rule
When a rule is constructed by an ant and it is pruned, the amount of pheromone in all segments of all paths must be updated. Pheromone updating for a termij performed based on the following equation:
τij (t+1) = τij (t) + τij (t) Q, i, j R
where R is the set of terms occurring in the rule constructed by the ant at iteration t. The above equation only adds the pheromone of the terms used in the rule. For adding the evaporation effect the amount of pheromone is done by normalizing τ at the end of updating procedure. Increasing and decreasing of the pheromone of each term has been decoupled in Predictive accuracy, also called generalization, is a measure of how well the model built by the rule induction algorithm performs in classifying previously unseen instances.
4. EXPERIMENTS AND RESULTS
In order to construct the dataset for training and testing our classification methodology, 11 h of two-channel ECG recordings from the European Society of Cardiology (ESC) ST-T data base [39] were used. Those contain the whole e0104 recording and the first hour of the e0103, e0105, e0108, e0113, e0114, e0147, e0159, e0162, and e0206 recordings. Each recording was sampled at 250 samples/s with 12-bit resolution over a nominal 20 mV input range. The sample values were rescaled after digitization with reference to calibration signals in the original analog recordings, in order to obtain a uniform scale of 200 analog-to-digital converter units/mV for all signals. These 10 recordings were selected because their ischemic ECG beats were characterized by significant waveform variability, which was observed by visual inspection of the above 10 recordings. This subset of the ESC ST-T Database has been previously used for ischemic beat detection [7], [16], [17]. Three medical experts annotated independently each beat as normal, ischemic or artifact. In case of disagreement the three medical experts reviewed the relevant beat and a decision was taken by consensus. This resulted in a dataset of 86 384 cardiac beats (half from every channel) annotated as normal, ischemic or artifact. After removing the artifacts and the mis-detected beats, the final dataset contained 76 989 cardiac beats, diagnosed as normal or ischemic. From those, 1936 beats (982 normal beats and 954 ischemic) were used to find the discretization intervals and for rule mining (training) while the rest (38 344 normal beats and 36 709 ischemic) for testing the performance of the classification methodology. It must be noted that the training set was constructed by selecting iteratively the first beat out of a sequence of 40 ones.
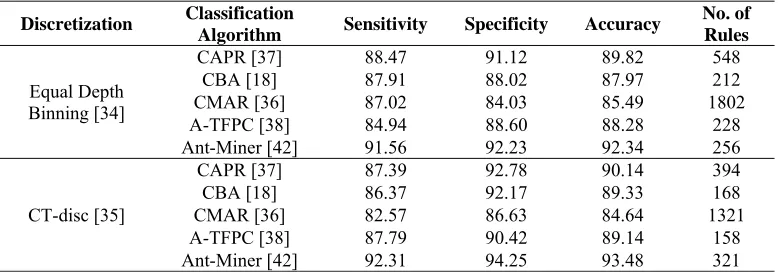
Table 1. Classification Results
Discretization Classification
Algorithm Sensitivity Specificity Accuracy No. of
Rules
Equal Depth Binning [34]
CAPR [37] 88.47 91.12 89.82 548
CBA [18] 87.91 88.02 87.97 212
CMAR [36] 87.02 84.03 85.49 1802
A-TFPC [38] 84.94 88.60 88.28 228
Ant-Miner [42] 91.56 92.23 92.34 256
CT-disc [35]
CAPR [37] 87.39 92.78 90.14 394
CBA [18] 86.37 92.17 89.33 168
CMAR [36] 82.57 86.63 84.64 1321
A-TFPC [38] 87.79 90.42 89.14 158
Ant-Miner [42] 92.31 94.25 93.48 321
5. CONCLUSION
We presented a novel methodology for the automated detection of ischemic beats that employed classification using association rules. The main advantage of the proposed methodology is the combination of high accuracy with the ability to provide interpretation for the decisions made, due to the employment of association rules for the classification. The performance of our approach compares well with previously reported results using the same subset from the ESC ST-T database and indicates that it could be part of a system for the detection of ischemic episodes in long duration ECGs. Clinical testing, however, is needed in order to be fully evaluated.
REFERENCES
[1] M. J. Goldman, Principles of Clinical Electrocardiography, 11th ed. Los Altos, CA: LANGE Medical, 1982.
[2] A. Taddei, G. Distante, M. Emdin, P. Pisani, G. B. Moody, C. Zeelenberg, and C. Marchesi, “The European ST-T database: standard for evaluating systems for the analysis of ST-T changes in ambulatory electrocardiography,” Eur. Heart J., vol. 13, pp. 1164–1172, 1992.
[3] R. Silipo, P. Laguna, C. Marchesi, and R. G. Mark, “ST-T segment change recognition using artificial neural networks and principal component analysis,” Comput. Cardiol., pp. 213–216, 1995.
[4] T. Stamkopoulos, K. Diamantaras, N. Maglaveras, and M. Strintzis, “ECG analysis using nonlinear PCA neural networks for ischemia detection,” IEEE Trans. Signal Process., vol. 46, no. 11, pp. 3058–3067, Nov. 1998.
[5] F. Jager, R. G. Mark, G. B. Moody, and S. Divjak, “Analysis of transient ST segment changes during ambulatory monitoring using the Karhunen-Loeve transform,” Comput. Cardiol., pp. 691–694, 1992.
[6] F. Jager, G. B. Moody, A. Taddei, and R. G. Mark, “Performance measures for algorithms to detect transient ischemic ST segment changes,” Comput. Cardiol., pp. 369–372, 1991.
[7] C. Papaloukas, D. I. Fotiadis, A. Likas, and L. K. Michalis, “An expert system for ischemia detection based on parametric modeling and artificial neural networks,” in Proc. Eur. Med. Biol. Eng. Conf., 2002, pp. 742–743.
[8] Pitas, M. G. Strintzis, S. Grippas, and C. Xerostylides, “Machine classification of ischemic electrocardiograms,” in Proc. IEEE Mediterranean Electrotechnical Conf. (MELECON), Athens, Greece, 1983.
[9] L. Senhadji, G. Carrault, J. J. Bellanger, and G. Passariello, “Comparing wavelet transforms for recognizing cardiac patterns,” IEEE Eng. Med. Biol. Mag., vol. 14, no. 2, pp. 167–173, Mar./Apr. 1995.
[10]C. Papaloukas, D. I. Fotiadis, A. P. Liavas, A. Likas, and L. K. Michalis, “A knowledge-based technique for automated detection of ischemic episodes in long duration electrocardiograms,” Med. Biol. Eng. Comput., vol. 39, pp. 105–112, 2001.
[11]C. Papaloukas, D. I. Fotiadis, A. Likas, C. S. Stroumbis, and L. K. Michalis, “Use of a novel rule-based expert system in the detection of changes in the ST segment and the T wave in long duration ECGs,” J. Electrocardiol., vol. 35, pp. 27–34, Jan. 2002.
[12]C. Papaloukas, D. I. Fotiadis, A. Likas, and L. K. Michalis, “An ischemia detection method based on artificial neural networks,” Artif. Intell. Med., vol. 24, pp. 167–178, 2002.
[13]N. Maglaveras, T. Stamkopoulos, C. Pappas, and M. Strintzis, “ECG processing techniques based on neural networks and bidirectional associative memories,” J. Med. Eng. Technol., vol. 22, pp. 106–111, 1998.
[14]S. Papadimitriou, S. Mavroudi, L. Vladutu, and A. Bezerianos, “Ischemia detection with a self-organizing map supplemented by supervised learning,” IEEE Trans. Neural Netw., vol. 12, no. 3, pp. 503–515, May 2001.
[15]N. Maglaveras, T. Stamkopoulos, C. Pappas, and M. G. Strintzis, “An adaptive backpropagation neural network for real-time ischemia episodes detection: development and performance analysis using the European ST-T database,” IEEE Trans. Biomed. Eng., vol. 45, no. 7, pp. 805–813, Jul. 1998.
[16]Y. Goletsis, C. Papaloukas, D. I. Fotiadis, A. Likas, and L. K. Michalis, “A multicriteria decision based approach for ischemia detection in long duration ECGs,” in Proc. IEEE EMBS 4th Int. Conf. Information Technology Applications in Biomedicine (ITAB 2003), 2003, pp. 230–233.
[17]——, “Automatic ischemic beat classification using genetic algorithms and multicriteria decision analysis,” IEEE Trans. Biomed. Eng., vol. 51, no. 10, pp. 1717–1725, Oct. 2004.
[19]R. Agrawal, T. Imielinski, and A. Swami, “Mining association rules between sets of items in large databases,” in Proc. 1993 ACM-SIGMOD Int. Conf. Management of Data, May 1993, pp. 207–216.
[20]J. Balter, A. Labarre-Vila, D. Ziebelin, and C. Garbay, “A knowledgedriven agent-centered framework for data mining in EMG,” Crit. Rev. Biol., vol. 325, pp. 375–382, 2002.
[21]P. C. Pendharkar, J. A. Rodger, G. J. Yaverbaum, N. Herman, and M. Benner, “Association, statistical, mathematical and neural approaches for mining breast cancer patterns,” Exper. Syst. with Applicat., vol. 17, pp. 223–232, 1999.
[22]S. P. Imberman, B. Domanski, and H. W. Thompson, “Using dependency/ association rules to find indications for computed tomography in a head trauma dataset,” Artif. Intell. Med., vol. 26, pp. 55–68, Sep./Oct. 2002.
[23]L. Ma, F. C. Tsui, W. R. Hogan, M. M. Wagner, and H. Ma, “A framework for infection control surveillance using association rules,” in Proc. Am. Medical Information Association, 2003 Annu. Symp., 2003, pp. 410–414.
[24]S. Doddi, A. Marathe, S. S. Ravi, and D. C. Torney, “Discovery of association rules in medical data,” Med. Inf. Internet. Med., vol. 26, pp. 25–33, Jan.-Mar. 2001.
[25]S. M. Downs and M. Y. Wallace, “Mining association rules from a pediatric primary care decision support system,” in Proc. Am. Medical Information Association, 2000 Ann. Symp., 2000, pp. 200–204.
[26]D. Gamberger, N. Lavrac, and V. Jovanoski, “High confidence association rules for medical diagnosis,” in Proc. 4thWorkshop Int. Data Analysis in Medicine and Pharmacology (IDAMAP 99), 1999, pp. 42–51.
[27]S. Stilou, P. D. Bamidis, N. Maglaveras, and C. Pappas, “Mining association rules from clinical databases: an intelligent diagnostic process in healthcare,” Medinfo, vol. 10, pp. 1399–1403, 2001.
[28]C. Ordonez, E. Omiecinski, L. DeBraal, C. Santana, N. Ezquerra, J. Toboada, D. Cooke, E. Krawczynska, and E. Garcia, “Mining constrained association rules to predict heart disease,” in Proc. IEEE Int. Conf. Data Mining, ICDM, 2001, pp. 433–440.
[29]J. Bourien, J. J. Bellanger, F. Bartolomei, P. Chauvel, and F.Wendling, “Mining reproducible activation patterns in epileptic intracerebral EEG signals: application to interictal activity,” IEEE Trans. Biomed. Eng., vol. 51, no. 2, pp. 304–315, Feb. 2004. [30]S. Konias and N. Maglaveras, “A rule discovery algorithm appropriate for ECG signals,” Comput. Cardiol., vol. 31, pp. 57–60, 2004. [31]M. Antonie, O. R. Zaoane, and A. Coman, “Associative classifiers for medical images,” in Lecture Notes in Artificial Intelligence,
2003, vol. 2797, Mining Multimedia and Complex Data, pp. 68–83.
[32]T. Dart, Y. Cui, G. Chatellier, and P. Degoulet, “Analysis of hospitalized patient flows using data-mining,” Stud. Health Technol. Inf., vol. 95, pp. 263–268, 2003.
[33]T. P. Exarchos, A. T. Tzallas, D. I. Fotiadis, S. Konitsiotis, and S. Giannopoulos, “A data mining based approach for the EEG transient event detection and classification,” in Proc. 18th IEEE Int. Symp Computer-Based Medical Systems, Dublin, Ireland, 2005, pp. 35–40. [34]J. Catlett, “On changing continuous attributes into ordered discrete attributes,” in Proc. 5th Eur. Working Session on Learning, 1991,
pp. 164–178.
[35]L. Breiman, J. H. Friedman, R. A. Olsen, and C. J. Stone, Classification and Regression Trees. Monterey, CA: Wadsworth & Brooks, 1984.
[36]W. Li, J. Han, and J. Pei, “CMAR: accurate and efficient classification based on multiple class-association rules,” in Proc. 2001 IEEE International Conf. on Data Mining, San Jose, CA, Nov. 2001, pp. 369–376.
[37]X. Yin and J. Han, “CPAR: classification based on predictive association rules,” in Proc. 3rd SIAM Int. Conf. Data Mining (SDM’03), San Francisco, CA, May 2003, pp. 331–335.
[38]F. Coenen, 2004, The LUCS-KDD Group, Department of Computer Science, The University of Liverpool, UK [Online]. Available: http:// www.cSc.liv.ac.uk/~frans/KDD/
[39]European Society of Cardiology, Pisa, Italy, European ST-T database directory 1991.
[40]K. Daskalov, I. A. Dotsinsky, and I. I. Christov, “Developments in ECG acquisition, preprocessing, parameter measurement, and recording,” IEEE Eng. Med. Biol., vol. 17, no. 2, pp. 50–58, Mar./Apr. 1998.
[41]A. Taddei, A. Benassi, M. G. Bongiorni, C. Contini, G. Distante, L. Landucci, M. G. Mazzei, P. Pisani, N. Roggero, M. Varanini, and C. Marchesi, “ST-T changes analysis in ECG ambulatory monitoring: a European standard for performance evaluation,” Comput. Cardiol., pp. 63–68, 1988.
[42]R.S. Parpinelli, H.S. Lopes, and A.A. Freitas,, Data mining with an ant colony optimization algorithm, Evolutionary Computation, IEEE Transactions, 6(4):321 – 332, 2002.
[43]T.P. Exarchos, C. Papaloukas, D.I. Fotiadis, and L.K. Michalis, An Association Rule Mining-Based Methodology for Automated Detection of Ischemic ECG Beats, IEEE Transactions on Biomedical Engineering, vol. 53, no. 8, pp. 1531-1540, 2006.
Biographical notes: S. Murugan received his MTech in Biomedical Engineering from Indian Institute of Technology, Madras in 2002. He is currently working as an Assistant Professor in the Department of Instrumentation and Control Engineering, Arulmigu Kalasalingam College of Engineering, Krishnankoil, Srivilliputhur (via), Virudhunagar District, Tamil Nadu, India. His current research interests include biomedical instrumentation, bio-signal processing and analysis.
S. Radhakrishnan received his PhD in Biomedical Engineering from Banaras Hindu University in 1993. At present he is working as a Senior Professor and Head, Department of Computer Science Engineering, Arulmigu Kalasalingam