SPEECH PROCESSING –AN
OVERVIEW
A.INDUMATHI
Asst. Professor, Dept. Of Computer Applications (MCA), Dr.SNS Rajalakshmi College Of Arts & Science,
Coimbatore,Tamilnadu ,641049, India [email protected]
Dr.E.CHANDRA
Dean,School of Computer Studies, Dr.SNS Rajalakshmi College Of Arts & Science,
Coimbatore, Tamilnadu ,641049, India [email protected]
Abstract :
One of the earliest goals of speech processing was coding speech for efficient transmission. Later, the research spread in various area like Automatic Speech Recognition (ASR), Speech Synthesis (TTS), Speech Enhancement, Automatic Language Translation (ALT).Initially, ASR is used to recognize single words in a small vocabulary, later many product was developed for continuous speech for large vocabulary .Speech Synthesis is used for synthesizing the speech corresponding to a given text Speech Synthesis provide a way to communicate for persons unable to speak. When Speech Synthesis used together with ASR, it allows a complete two-way spoken interaction between humans and machines. Speech Enhancement technique is applied to improve the quality of speech signal. Automatic Language Translation helps to convert one language into another language. Basic concept of speech processing is provided for beginners.
Keywords : Automatic Speech Recognition (ASR) ,Text To Speech (TTS) ,Speech Enhancement, Automatic Language Translation (ALT)
INTRODUCTION
Digital speech processing plays a vital role in modern speech communication research and applications. The fundamental purpose of speech is communication. It means transmission of message between human and machine. This field is too broad and too deep.
Objective of this article is to provide an up-to-date overview about this fascinating field and its application. The speech processing can be categorized as [1]
1. Speech Synthesis
2. Speech Recognition
3. Speech Enhancement
4. Automatic language Translation
I. SPEECH SYNTHESIS
Speech synthesis enables voice output by machines or a device that is converting the text information into
speech [2]. Hence speech synthesis can be called as Text-to-Speech Synthesis (TTS). Nowadays, a TTS system has wide use in assistive technologies, telecommunications, entertainment and education.
Input text
Tagged Text
Tagged phones
Sequence of sound, duration, pitch
Speech
Figure: 1 Component of TTS System
The basic components [2] of a TTS system can be listed as
1. Text processing
2. Phonetic analysis 3. Prosodic analysis
4. Acoustic processing.
1. TEXT PROCESSING
This component deals with low-level text- processing issues such as sentence segmentation and word segment.
1.1 Document structure detection
Document structure detection [7] can be as generalized as - interpreting punctuation marks
- filtering out email headers - Paragraph formatting
Document structure detection is to simplify the input document/text into standard generalized markup language (SGML) [2].Where SGML is an international standard for device independent, system independent systems of representing text in electronic form.
Basic Text Processing - Document structure - Text Normalization - Linguistic Analysis
Phonetic Analysis -Homograph Disambiguation -Grapheme to Phoneme
Prosodic Analysis - Pitch & Duration Rules - Stress & Pause Assignment
Acoustic Processing - Articulatory Synthesis - Formant Synthesis
1.2 Text normalization
Text normalization [2] handles abbreviation and acronyms. The goal of normalization is to match the text and how an educated human reader would render the input text.
For example,
(i) ‘St’ could be rendered as Street or as Saint, (ii) ‘Dr ‘could be rendered as Driver or Doctor.
Proper normalization makes the TTS output as good.
1.3 Linguistic Analysis
Linguistic analysis [6] [7] includes a morphological analysis for proper word pronunciation and a syntactic analysis to facilitate accenting and phrasing and to handle ambiguities in the written text.
2. PHONETIC ANALYSIS
It focuses on the phone level within each word. Each phone is tagged with information about what sound to produce and how to produce for example speaking style and emphasis.
2.1 Grapheme -to-phoneme conversion
Exact pronunciation of each word of the input sentences is determined [2].
2.2 Homograph disambiguation
Figuring out whether input sentences use the present tense or the past tense version of the word [2].
Example: Read
to identify the tense, TTS system depends on dictionary.
3. PROSODIC ANALYSIS
Prosodic Analysis [6] determines the progression of intonation, Speaking rate and loudness across an utterance which are ultimately represented at the phoneme level as pitch (fundamental frequency), duration and amplitude.
The intonation and timing determine the rhythm of a sentence in addition to syllabic stress. Repetition of rhythm and stress patterns across sentences makes the listener fatigue. Hence proper prosody is important.
3.1 Acoustic processing
Symbolic prosody data is used to synthesize speech using a specific synthesis method. Traditionally we use
(i) Rule based synthesis
(ii) Corpus –based synthesis
The former include Articulatory synthesis and Formant synthesis. While later was almost synonymous with concatenative synthesis.
3.2 Articulatory synthesis
3.3 Formant synthesis
This synthesis [3] aiming to reproduce input/output characteristic in the form of formant filters.
3.4 Concatenative synthesis
Concatenative synthesis [3] employs segments of recorded speech from a prerecorded inventory (voice database).
II. SPEECH RECOGNITION
Speech recognition is the capability of a software or machine to recognize a language and axiom in spoken language and translate them to a machine-readable format. The goal of speech recognition is to transform the speech content into knowledge that forms the basis for linguistic or cognitive tasks such as translation into another language. Most systems are “trained “for set of words that are frequently used. The sample words are digitized, stored in the computer and used to match against future words.
The terms “speech recognition" and "voice recognition”[1] appears as the same they differ in their meaning. Speech recognition is used to recognize words in spoken language. Voice recognition is also called as speaker recognition which recognizes the speaker voice.
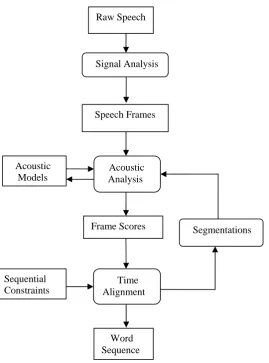
Speech recognition system is shown below.
Figure 2: Components of Speech Recognition Raw Speech
Signal Analysis
Speech Frames
Acoustic Analysis
Frame Scores
Time
AlignmentWord
Sequence AcousticModels
Sequential Constraints
1 . Speech
A raw speech (or) a raw audio signal [2] is received from a digitized microphone or telephone with high frequency that is 16Hz over a microphone or 8 Hz over a telephone
2. Signal Analysis
Raw Speech is compressed to seize data without losing important information [2]. Commonly used techniques are
(i) Fourier analysis (FFT) .
(ii) Perceptual Linear Prediction(PLP) (iii) Linear predictive Coding (LPC) (iv) Cepstral Analysis
3. Speech frames
The end result of signal analysis is a series of speech frames at regular time interval.
4. Acoustic models
Acoustic models are used to examine the speech frame for their acoustic content. [4]There are several types of acoustic models, varying in their illustration, granularity, context dependence and other goods. Most popular acoustic models are
(i) Template
A word can be accepted by simply evaluating it against all well-known templates and finding the closest match[7].
(ii) State
Each word is representation by a series of trainable states and each state denote the sounds that are likely to be heard in that section of the speech using a probability distribution over the acoustic space [7].
5. Time alignment
An isolated word sample is compared against a number of stored word pattern and conclude which is the “best match”[2]. This can perform by using Algorithms like Dynamic Time Warping, HMM etc..,
III.SPEECH ENHANCEMENT
Speech Enhancement [8] is the technique in which the speech signal subject to certain degradations (for example, additive noise, interfering talkers) is processed to increase its intelligibility and its quality.
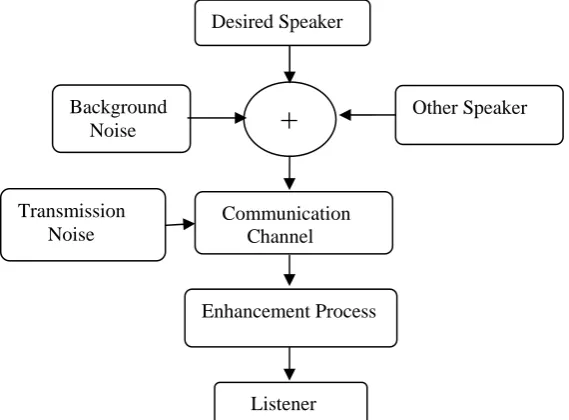
Figure 3 : Components of Speech Enhancement
Various degradations that corrupt the speech signals [9] are ,
(i) Additive acoustic noise
Additive acoustic noise occurs due to background noise of an environment when recording takes place.
(ii) Acoustic reverberation
Occurs due to multiple reflections of an acoustic signal (iii) Convolutive channel effects
Occurs,due to improper modeling of communication channel for the channel equalizer to eliminate, the channel impulse response.
(iv) Electrical interference
(v) Distortion introduced by recording apparatus, due to poor response of Microphone.
These degradations can be avoided to the maximum by applying Speech Enhancement Techniques before it reaches listener. The below figure shows how the speech signal is degraded by noise and how speech signal is preprocessed by speech enhancement algorithms before it reaches the listener.
The aim of speech enhancement [8] varies widely according to the application. It may comprise,
(i) To improve the intelligibility of speech to human listeners. (ii) To improve the good quality of speech that make it more
acceptable to human listeners.
(iii)To improve performance of automatic speech or speaker recognition systems by modifying the speech
(iv)Modifying the speech in order to make the encoded speech more effectively for storage or transmission.
Though various variety of theoretical and effective techniques are available to reduce the noise ,the trouble of cleaning noisy speech still poses a big challenge to the area of speech processing. Eradicating noise is hard due to the random nature of the noise and the inherent complexities of speech.
Background
Noise
+
Transmission Noise
Other Speaker
Communication Channel
Enhancement Process
IV . AUTOMATIC LANGUAGE TRANSLATION
Automatic language translation [2] is computer software that translates input text from one language to another while maintaining the original document format.
Automatic language translation software stores frequently used terms, sentence and axiom in a database that is accessed when any information wants to translate. The machine translation [7] uses quantity linguistic techniques to translate idioms and phrases. This technology requires speech synthesis systems that work in both languages along with speech recognition that also works for both languages.
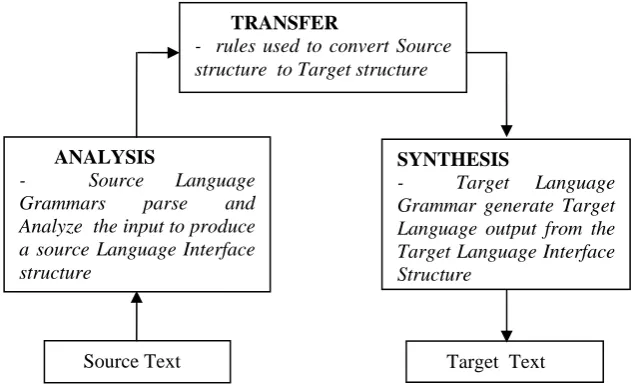
Figure 4 : Components of language Translation
1. Analysis
Analysis is a process of producing structure for source language from input text. It uses dictionary and grammar to produce a structure.
2. Transfer
Set of rules is applied for the conversion of source structure to target structure.
3. Synthesis
Synthesis is a process of producing target language from target structure.
In recent years, automatic translation software has become accepted product in international business. And also used for communication by people who work for worldwide companies.
V. CONCLUSION
Speech processing enjoys wide use in Assistive technologies, Telecommunications, Entertainment, and Education. This article, tried to present the most important area of Speech Processing. It should be noted that Speech processing is still far from delivering perfect output. Future research should focus on improving speech processing by giving a special focus on automating and streamlining most of the tedious manual processes involved in creating high quality systems.
References
[1] L.R.Rabiner,R.W.Schafer,“Digital Processing of Speech signals”,Prentice Hall,Englewood Cliffs 1978. [2] J.Benesty,M.M.Sondhi,Y.Hurang,”Introduction to Speech Processing”,Springer HandBook of Speech Processing.
[3] Banat Karima,EI-Imam Yousif A,”Text-to-Speech conversion on a personal computer”.IEEE Micro,Vol.10,Issue 4,pp 62-72. [4] B.Gold,N.Morgan,”Speech and Audio Signal Processing”,Wiley,Newyork 2000.
[5] L.R.Rabiner,B.-H.Juang,”Fundamentals of Speech Recognition”,Prentice-Hall,Englewood Cliff 1993 [6] T.Dutoit,”An Introduction to Text-To-Speech Synthesis”.
[7] Douglas,O.shaughnessy, ”Speech Communications, Hunman and Machine”,Second Edition
TRANSFER
- rules used to convert Source structure to Target structure
ANALYSIS
- Source Language Grammars parse and Analyze the input to produce a source Language Interface structure
SYNTHESIS
- Target Language Grammar generate Target Language output from the Target Language Interface Structure
[8] Vijay madisetti and Douglas Williams,”The Digital Signal processing Hand Book”. [9] Philipos C.Loizou,”Speech Enhancement Theory and Practice”.
[10] J.L.Flanagan,”Speech Analysis, Synthesis and Perception”.
[11] Sebastian staker,Kevin Kilgourand Florian Kraft,”Quaero 2010 Speech-to-Text Evaluation Systems”,Springer –Verlag Berlin Heidelberg 2012.
[12] Sen.A,”Speech Synthesis in India”,IETE Technical Review 24,pp343-350.