Probabilistic Inference for Cold Start Knowledge Base Population with
Prior World Knowledge
Bonan Min and Marjorie Freedman and Talya Meltzer∗ Raytheon BBN Technologies
10 Moulton St, Cambridge, MA 02138, USA
{bonan.min, marjorie.freedman}@raytheon.com
Abstract
Building knowledge bases (KB) automat-ically from text corpora is crucial for many applications such as question an-swering and web search. The problem is very challenging and has been divided into sub-problems such as mention and named entity recognition, entity linking and relation extraction. However, com-bining these components has shown to be under-constrained and often produces KBs with supersize entities and common-sense errors in relations (a person has multi-ple birthdates). The errors are difficult to resolve solely with IE tools but be-come obvious with world knowledge at the corpus level. By analyzing Freebase and a large text collection, we found that per-relation cardinality and the popular-ity of entities follow the power-law dis-tribution favoring flat long tails with low-frequency instances. We present a proba-bilistic joint inference algorithm to incor-porate this world knowledge during KB construction. Our approach yields state-of-the-art performance on the TAC Cold Start task, and 42% and 19.4% relative improvements in F1 over our baseline on Cold Start hop-1 and all-hop queries re-spectively.
∗
The third author is currently with The Affinity project. This work was done while she was at BBN.
This work was supported by DARPA/I2O Contract No. FA8750-13-C-0008 under the DEFT program. The views, opinions, and/or findings contained in this article are those of the author and should not be interpreted as representing the official views or policies, either expressed or implied, of the Defense Advanced Research Projects Agency or the De-partment of Defense. This document does not contain tech-nology or technical data controlled under either the U.S. In-ternational Traffic in Arms Regulations or the U.S. Export Administration Regulations.
1 Introduction
Automatically transforming a large corpus into a structured knowledge base (KB) has long been a goal of information extraction (IE) research. KB population incorporates many IE tasks including named entity recognition, entity linking and rela-tion extracrela-tion, each of which rely on deeper lin-guistic analysis, e.g., syntactic parsing or anaphora resolution. Since 2012, NIST 1 has run an open
shared task in KB population (KBP) under TAC2.
Most participating systems (Mayfield et al., 2014; Min et al., 2015; Roth et al., 2015; Angeli et al., 2014; Nguyen et al., 2014; Monahan and Carpen-ter, 2012) combine many independent components to perform the full task.
As will be familiar to most IE researchers, the individual components are not perfect. When combined into a pipeline, errors compound. We found that a KB produced with a simple combina-tion of state-of-the-art IE components (Ramshaw et al., 2011) is very sensitive to component-level errors (Grishman, 2013).
Table 1 illustrates a real entity coreference mis-take. Barack ObamaandEhud Barakwere incor-rectly linked because of ambiguous context and high lexical overlap. The mistake leads to er-rorful facts about employment, familial relations, etc. We see additional mistakes when we review the names in those entities with the most men-tions: the U.S. entity contains more than 20,000 mentions. 85% are correct (e.g., United States, U.S.), but there is a long tail of incorrect yet infre-quent(each accounting for<1%) mentions linked to the entity e.g.,North America, Latin American. We also see counter-intuitive errors in relation ex-traction: 5% of person entities have multiple birth-dates; the KB asserts 8 spouses for an infrequently
1U.S. National Institute of Standards and Technology 2Text Analysis Conference:www.nist.gov/tac/
mentioned entity. Similar errors have been re-ported in (McNamee et al., 2013) and (Singh et al., 2013b).
Named mentions of PER:Barack Obama: Barack,Barack Obama,Ehud Barak, Barak Text: BarakendorsesBarack, ... Defense Min-isterEhud BaraksaidBarack Obamahas been the most supportive president on Israeli security
Table 1: Example of entity linking errors. Analyzing these errors suggests a limitation of performing KB population solely with IE tools. These mistakes only become obvious in the con-text of external world knowledge with the full set of facts extracted from many documents, e.g. when applying our expectations about the cardi-nality of a relation. With just a single document, resolving these mistakes requires challenging in-ference (Ji et al., 2005).
In this paper, we present a probabilistic frame-work to incorporate real-world knowledge into Cold Start KB population. Our contributions in-clude:
• Identifying from real world datasets that en-tity popularity and each relation’s cardinality follow the power-law distribution with long tails of low-frequency instances.
• Defining a corpus-level joint objective for KBP that incorporates multiple IE compo-nents and prior world knowledge on entity popularity and per-relation cardinalities, and showing the prior knowledge helps to reduce errors.
• Outperforming the top-ranked entry in Cold Start 2015.
The paper is organized as follows: we first in-troduce the Cold Start KBP task, then present the joint probabilistic framework, followed by anal-ysis of the world knowledge and how to incor-porate it. We then describe our inference algo-rithm. Lastly, we present experimental results, re-lated work, and conclude with suggestions for fu-ture research.
2 Cold Start KBP
The schema consists of 3 entity types (person, organization, and GPE) and 42 slots (relation classes)3. Systems start with an empty KB (cold
start) and populate it according to the schema with 3We will useslotandrelationinterchangeably in this
pa-per.
information extracted from the corpus. All facts in the KB must be grounded with justifying text from the corpus.
A KB entity is defined as a cluster of mentions that refer to the same real-world entity, e.g.,Smith, John Smith, andJohn H Smithare 3 mentions for the entityJohn H Smith. Every named mention of an entity is recorded. A relation is a triplet (sub-ject, slot, object), wheresubjectandobjectare en-tities,4 andslotis the relation between them. For
example,(Bart Simpson, per:siblings, Lisa Simp-son) is the relation Bart Simpson is a sibling of Lisa Simpson. A relation’s provenance points to up to 4 snippets in the corpus that justify the re-lation. The evaluation process is described in the Experiments Section.
3 A Probabilistic Framework
Following most Cold Start KBP systems (May-field et al., 2014; Min et al., 2015; Roth et al., 2015; Angeli et al., 2014; Nguyen et al., 2014; Monahan and Carpenter, 2012), our baseline uses a cascade of NLP components from document-level analysis to corpus-document-level aggregation. We run BBN’s SERIF (Ramshaw et al., 2011) for men-tion, value and name tagging, coreference resolu-tion, sentence-level relation extracresolu-tion, alongside other analysis such as syntactic parses. Then we aggregate entities with entity discovery and link-ing and relations with relation extraction.
Given a set of pre-trained NLP components, the process is essentially an inference task. We intro-duce the following notation:
• Mis the list of mentions
• Eis the set of entities to populate the KB
• Ris the set of relation types.
• xiis the observed text for mentioni,xi∈M
• uiis entity ID from the KB assigned to men-tioni,i∈ {1,2, ...,|M|},ui ∈ {1,2, ...,|E|}
• zi,j = r indicates the relation r between a pair of mentions xi, xj ∈ M and r ∈ RS{Other}
• yr
i,j is an indicator variable: yi,jr = 1 if a relation r ∈ R exist between entity pair < ei, ej >,i, j∈ {1,2, ...,|E|}, and0 other-wise.
The key steps in the pipeline are the following:
Mention extraction: We use a structured per-ceptron model (Ramshaw et al., 2011) to extract named mentionsM.
4A small number of the relations take values not entities.
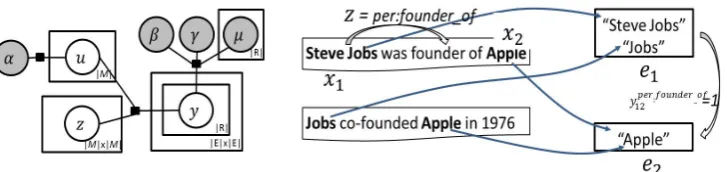
Figure 1: A simplified plate model of the probabilistic model(left), and an example (right) illustrates the KB construction process with aligned variables. The plate model only shows RE and EDL factors, and factors incorporating world knowledge. The example(right) compensates by showing the process without priors.
Entity Discovery & Linking (EDL): This step creates a candidate entity set E for the KB and infers which document entity (represented by its named mentions) is associated with which KB en-tity , i.e. assigning values for {ui}. We use a sieve-like (Raghunathan et al., 2010) algorithm for in-document coreference. For simplicity, we only model EDL of names5.
We define potential functions over variables
{ui}for each pair of mention xi and the jth en-tityej:
ΨEDLi (ui =j|xi) =exp(Σkθkφk(ui=j|xi))
The baseline system solves the EDL problem by inferringu∗
i = arg max ΨEDLi (ui). It uses a name database collected from Freebase (Bollacker et al., 2008) and GeoNames 6. First, it clusters novel
names to create new candidate entities in addition to entries in the name database. A novel name is defined as a name that could not be resolved to a database entry. It then rescans the corpus and links each document-level entity to a corpus-level entity (an entry in the name database or a novel name). The EDL modelΨEDL uses features such as string edit distance and indicators representing whether appearing in the same name variant set.
{θk}and{φk} are the weights and feature func-tions respectively.
Mention-level Relation Extraction (MRE): This step infers which relation zi,j = r(r ∈ RS{Other}) exists between each pair of men-tions< xi, xj >, we define potential functions:
ΨMRE
i,j (zi,j=r|xi, xj) =exp(Σkθk0φ0k(zi,j=r|xi, xj))
We run several relation finding algorithms (Min et al., 2015) , including statistical models trained 5Decisions made for named mentions will be applied to
the corresponding document-level entities.
6www.geonames.org
from ACE7relation annotation and distant
super-vision (Mintz et al., 2009) in which we align Free-base pairs into Gigaword (Parker et al., 2011) to generate training examples, and a pattern matcher with a few hand-written patterns that capture local contexts.
To train a log-linear modelΨMRE for combin-ing these algorithms and to tune the confidences of their extractions, we follow (Viswanathan et al., 2015) and train a stacked classifier using out-put and confidences of the extractors. We use as-sessment datasets from TAC Cold Start KBP 2013 and 2014, and Slot Filling evaluations in 2013 and 2014. The features we used are: source algorithm name, slot, confidence score (if exists), argument mention level (pronoun, name, or nominal), lexi-cal sequence between pair of arguments, proposi-tional path between the pair of arguments. {θ0
k} and{φ0
k}are the weights and feature functions re-spectively.
Relation Extraction (RE): This aggregation step infers which relations exist between each pair of entities at the KB level, i.e. assigning values for
{yr
i,j}. We define the potential functions over the indicator variables{yr
i,j}, by looking at all pairs of mentionsxm, xn ∈ M, their potential to have a relation r and likelihood to be associated with entitiesei, ej ∈E:
ΨRE
i,j,r(yri,j = 1|x) =
max
<m,n>(Ψ EDL
m (um =i|xm)ΨEDLn (un=j|xn)
ΨMRE
m,n (zm,n=r|xm, xn))
andΨRE
i,j,r(yri,j = 0|x) = ΨRE0 where ΨRE0 is a
deanu et al., 2012) and supports overlapping re-lations (Hoffmann et al., 2011; Surdeanu et al., 2012).
The joint distributiondefined over the full set of variablesu, yis:
P r(u, y|x)∝Y
m
ΨEDL
m (um|xm)·
Y
i,j,r
ΨRE i,j,r(yijr|x)
The Cold Start KBP problem can be seen as finding the maximum a posteriori (MAP) config-uration:
(u∗, y∗) = arg max
(u,y)P r(u, y|x)
The baseline system approximates the solu-tion by solving in 2 separate stages: solve EDL by fixing u∗
m = arg max1≤i≤|E|ΨEDLm (um = i|xm)for allxm, then solve RE by fixingyi,j∗r =
arg maxδ∈{0,1}ΨRE
i,j,r(yri,j =δ|x, u∗)for alli, j, r. The potential ΨRE
i,j,r(yri,j = 1|x, u∗) is a relaxed form forΨRE
i,j,r(yri,j= 1|x):
ΨRE
i,j,r(yi,jr = 1|x, u∗) =
max
m,n:
(u∗m,u∗n)=(i,j)
(ΨEDLm (u∗m=i|xm)ΨEDLn (u∗n=j|xn)
ΨMREm,n (zm,n =r|xm, xn))
In the relaxed form, the optimization problem required for estimating the potential ofy∗r
i,j is lim-ited to search only over pairs of mentionsxm, xn which are now associated with the entitiesei, ej, i.e. um = i andun = j, instead of enumerat-ing over all pairs of mentions. This can be done efficiently.
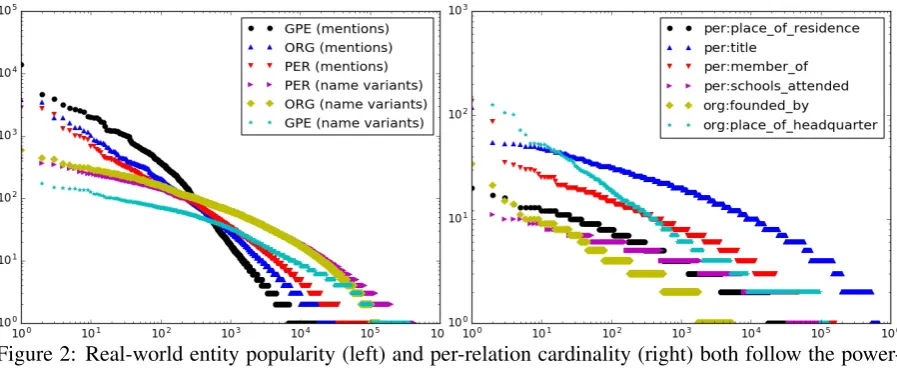
4 Incorporating World Knowledge We incorporate world knowledge related toentity popularityand a set ofper-relation cardinalitiesas additional factors in the objective. To learn these factors’ form, we analyze real-world datasets and find that both factors follow the power-law distri-bution with long tails of low-frequency instances.
4.1 Entity Popularity
We define entity popularity (EP) as the number of mentions of an entity in a corpus. Entities vary in popularity– famous people (e.g. politi-cians, athletes), countries, and large organizations will be mentioned frequently in news, while other entities– a small city, the local valedictorian may only be mentioned a few times. Ideally, we would
model the EP distribution with counts from a large corpus annotated for names and cross-document entity coreference. As we are not aware of any such resource, we look at two approximations:
Name variants (NV): We collect name variants (e.g.,UN and United Nations) for PER and ORG from Freebase and for GPE from GeoNames.
Name Mentions (NM): From a 50K document
sample of Gigaword, for each entity, we search for exact matches to its name variants, and count these matches to estimate the number of entity men-tions.
Figure 2 (left) plots the per-entity relationship between the count of NM and NV with rank. Both follow the power-law distribution (i.e. the plots are close to straight lines in a log-log scale). In other words, most entities have only a small num-ber of variants and are mentioned only a few times. A handful of popular entities are mentioned fre-quently and have many variants 8. The size of
entities in the Kripke (Finin et al., 2014) system follows power-law distribution, further supporting our findings.
Formally, we define forith entity the popularity variableqi(u) = ΣmI(um =i)and the potential for EP factorΨEP
i (u)as follows:
ΨEP
i (u)∝exp(θEP(qi(u)))
in whichθEP(qi(u)) =αln(qi).
The parameterα > 0is initially fit from Free-base entities and then finetuned with TAC 2014 dataset to reflect real-world distributions. The EP term favors EDL solutionsuwith a popularity dis-tribution that follows a power-law with a long tail of low-frequency entities.
4.2 Relation Cardinality
We define relationr’scardinality regarding ei as the number of entities or values associated withei throughr. For example, ifJohn Smithhas 3 chil-dren, the cardinality of r=per:children regarding ei=John Smith is 3. Formally, we notate the set of variables {yr
ij} asyir, and the cardinality of a relationrof entityeiasdri = Σjyijr.
Per-relation cardinalities (RC) often reflect real world constraints– people have at most one birth-date and typically no more than 5 siblings. To understand the cardinality constraints for the Cold Start relations, we use Freebase, a large, manually 8We confirm that a few entities have many variants e.g.
Figure 2: Real-world entity popularity (left) and per-relation cardinality (right) both follow the power-law distribution. x-axis shows ranks and y-axis shows counts (both are in log scale). The Left figure plots both numbers of name variants and numbers of mentions to ranks for PER, ORG and GPE.
curated KB. We align Freebase to the TAC schema following (Chen et al., 2010) and then generate a cardinality for each relation for all entities. The relationship between RC and RC-rank for the the
6 most frequent relations is plotted in Figure 2 (right). For these relations, RC closely resembles a law distribution. To favor both power-law and a soft size-limit on cardinality, we define the following potentials for RC factors for each relation-entity pair:
ΨRCi,r (yr)∝exp(θRC(dri))
in which θRC(dr
i)) = βln(dri) − γ(max(dri − µr,0))2 with parametersβ, γ > 0, andµr as the mean of the cardinalities of a relationr(estimated from Freebase). The first term in the potential has the power-law assumption, while the second term penalizes large cardinalities for going beyond the meanµr.
4.3 Incorporating Prior World Knowledge
Incorporating the EP and per-relation RC terms into the joint distribution, we obtain the joint ob-jective:
P r∗(u, y|x)∝P r(u, y|x)·
Y
1≤i≤|E|
ΨEP i (u)·
Y
1≤i≤|E|
r∈R
ΨRC i,r (yri)
withP r(u, y|x)as the baseline objective. A sim-plified plate diagram is shown in Figure 1.
Learning constraints for real-world corpora: As we’re not aware of any large corpus anno-tated exhaustively with entities and relations, we fit the parameters of the constraints initially from
Freebase entities and relations, and then fine-tune them using empirical utility maximization (Jan-sche, 2005; Ye et al., 2012) for TAC Cold Start all-hop F1 with grid search in the parameter space, using previous years’ TAC assessment. Freebase is used in initialization because of its scale while finetuning with TAC assessment ensures the fac-tors to more appropriately represent the underly-ing distribution of entity popularity and relation cardinality in a real-world corpus.
5 Jointly Inferring Entities and Relations The problem of Cold Start KBP becomes finding a MAP assignment of u and y for P r∗(u, y|x). Finding the exact solution is hard, as many terms in the objective involve large groups of vari-ables. We propose Algorithm 1 as an approximate heuristic. Line 1 generates an initial KB by ap-proximating a solution for the baseline objective P r(u, y|x)(Section 3), but tends to overlink enti-ties and over-aggregate relations. Lines 2-8 itera-tively refine the KB by searching over the(u, y) -space using operation o ∈ {SplitE, PruneR}. At t-th iteration, it performs the operationowith the highest potential gain∆ lnP r∗(o(ut, yt)|x). The process is repeated until the gain is smaller than a very small value.
SplitE: splits an entity ei into two entities. Since there are an exponential number of pos-sible SplitE actions, we uses the following two heuristics: 1) cluster name mentions by their string forms, and find an “outlier” cluster of mentions, 2) rank ei’s mentions {xm : u∗m = i} by their local EDL potential ΨEDL
find-Input :x, α, β, γ, µrforr ∈R
Output:u, y
1 (u0, y0) = arg max(u,y)P r(u, y|x) 2 t←0
3 repeat
4 o= arg maxo∆ lnP r∗(o(ut, yt)|x) 5 ifo! =nullthen
6 (ut+1, yt+1)←Execute(o(ut, yt))
7 t←t+ 1
8 until∆ lnP r∗(o(ut, yt)|x)< ;
Algorithm 1:The MAP inference algorithm
ing an “outlier” mention cluster of ei, we divide it into two entities: eg with the “core” mentions, andeh with the “outlier” mention cluster. We re-peat the process to find all outlier entities and sepa-rate them from the entity. Relation arguments will be reattached to the new entities accordingly. We only consider a short list of most popular entities and split each using the heuristics described above.
PruneR: removes a batch of relations (Y =
{yr
i,j}) by setting0: yri,j ← 0 for eachyri,j ∈ Y. The batch is generated with the following steps: first select a set of entity-relation pairs(ei, r)with the highest cardinalitydr
i =Pjyri,j, then repeat-edly select the associated relation with the low-est potential j∗ = arg minj:yr
i,j=1ΨRE(yri,j|x).
Eachyr
i,jwill be added into the batch until its size reaches 50.
We define the gain for SplitE and PruneR as:
∆ lnP r∗(SplitE(eg, eh←ei)|x)) =
Σm(ln ΨEDLm (g) + ln ΨEDLm (h)−ln ΨEDLm (i))
+ Σr∈R(ln ΨREg + ln ΨREh −ln ΨREi
+ ln ΨRC
r (y0r)−ln ΨRCr (yr))
+ ln ΨEP
g (u0) + ln ΨEPh (u0)−ln ΨEPi (u)
∆ lnP r∗(P runeR(Y)|x) =
Σr∈R(ln ΨRCr (y0r)−ln ΨRCr (yr))
+ Σyr
i,j∈Y(ln ΨRE0 −ln(Ψi,j,rRE(yijr = 1|x)))
in whichΨEDL
m (i)is short forΨEDLm (um=i|xm) with m ranges over IDs of mentions in ei, and
ΨRE
i is the sum of the RE factors which are re-lated to entityei. y0, u0are the assignment toy, u if a SplitE or a PruneR operation is executed. We also use the short form ΨRC
r (y0r) as the sum of the RC factors which have changed because of a SplitE or a PruneR operation.
Since the gain is only computed for the short-listed entities and relations, and we only
calcu-late the subset of factors (EDL, RE, RC, and EP) related to the operation,∆ lnP r∗(SplitE|x) and∆ lnP r∗(P runeR|x) can be calculated effi-ciently.
6 Experiments
We evaluate our system with resources provided to TAC 2015 participants, including 1) a source corpus of 50,000 documents from newswire and discussion forums, 2) a query set consisting of 317 hop-0 entities (expanded to 1,148 hop-0 entry-point mentions and 8,191 hop-1 queries), 3) LDC9
assessment of participant responses from auto-matic submissions10and a manually created
sub-mission11, and 4) software that retrieves answers
from a KB and measure performance with the as-sessment. Additionally, we use TAC 2013 and 2014 datasets for tuning parameters and training stacked classifiers.α= 10, β= 5, γ= 0.1are set empirically following Section 4.3. We run each experiment 20 times and average the scores.
6.1 Queries, Assessment, and Scoring
We briefly describe the evaluation process and scoring metrics. More details appear in (May-field, 2014). The Cold Start evaluation mea-sures KB-quality by probing the KB with two types of queries. The queries are either at hop-0 (e.g., which organization(s) is(are) founded by Bill Gates?) or hop-1 (e.g., in which city(-ies) the organization(s) founded by Bill Gates is(are) headquartered?). More formally, the evaluation software tries to find an entitye0in the submitted
KB that covers the entry-point mention of a hop-0 queryq0, then finds all relational triples matching
(e0, r1,?).X, the set of entities matching the open
variable, is reviewed by annotators for: (a) assess-ment of correctness and (b) the identification of non-redundant subsetX0. The software generates an hop-1 queryq1 =x0for eachx0 ∈X0, finds the
entitye1 that aligns withq1, and then finds triples
matching(e1, r2,?). This results in response set
Y, the set of entities matching the second open variable. Set Y is assessed by LDC in the same manner as SetX. The process is performed over all submitted KBs12. The answers inX (hop-0)
9https://www.ldc.upenn.edu/
1020 teams participants in the task with>50 KBs
submit-ted.
11created by time-limited LDC annotators
12LDC generates the time-limited manual run directly
Systems Hop-0 CS-SF Hop-1 Hop-0CS-LDC-MAXHop-1
P R F1 Ign P R F1 Ign P R F1 Ign P R F1 Ign
TAC rank1 48 30 37 0 31 17 22 0 50 35 40 0 28 20 23 0
offset-based 50 31 38 64 31 18 23 23 52 35 42 19 30 21 24 6
string-match 49 31 38 13 32 19 24 11 52 36 42 6 29 21 25 3
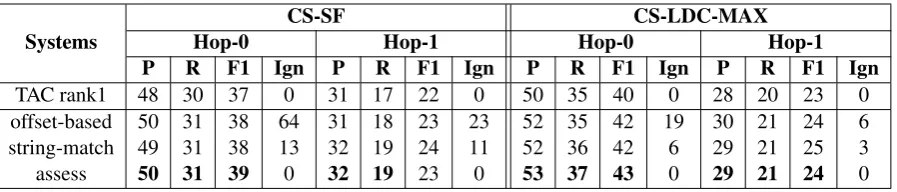
[image:7.595.78.527.61.157.2]assess 50 31 39 0 32 19 23 0 53 37 43 0 29 21 24 0
Table 2: CS-SF and CS-LDC-Max micro-averaged precision, recall and F1 of hop-0 and hop-1 queries for the TAC 2015 top-ranked KB submission (Min et al., 2015) and our KBC+E+R system (3 bottom rows) using various post-hoc scoring techniques (offset-based, string-match and assess).Ignis the num-ber of unassessed answers.
are correct when when sufficiently justified in the source corpus. The answers inY (hop-1) are cor-rect only if both the element ofX that generated the response is correct and the response in Y is justified in the text.
NIST reports two metrics, CS-SF and CS-LDC-MAX, which differ in the treatment of mul-tiple entry-point mentions for a single real-world entity. CS-SF treats each distinct mention as an independent query. CS-LDC-MAX takes only the entry-point mention which maximizes system per-formance for a given query-entity (i.e. either the responses for Bill Gates or William Gates). For both metrics, NIST calculates micro-averaged pre-cision, recall, and F1 over all queries. As men-tioned above, the official evaluation is a human post-hoc assessment of KB output. A system de-veloped outside of the evaluation window, e.g., our proposed algorithm, will likely include re-sponses for which truth is not known, which are ignored by the scoring software. Table 2 compares the TAC top-ranked system to our full configura-tion using three post-hoc scoring strategies: strict
offset-basedmatch,string-matchmatch, and as-sessin which we apply the offset-based metric us-ing additional internally performed assessments. For the ablation study in Table 3, we use the of-ficial scorer’sstring-matchmode. A small num-ber of responses are ignored (Ign) even in string-match mode. We further account for these re-sponses by re-estimating precision for hop-0 and hop-1 assuming that the precision of the ignored responses at hop-1 is the same as the hop-0 preci-sion13. When this optimistic estimate differs from
reported precision, we report it in parentheses.
13This overestimates the hop-1 precision which is lower
than hop-0 precision because of error compounding.
6.2 Results and Discussion
Table 2 compares our full system (KBC+E+R) to the top performing system in TAC Cold Start 2015 using three different approaches to post-hoc scoring. Without manual effort, our joint model-ing approach exceeds the performance of the top-ranked system, which uses a cascade of manually-specified rules (Min et al., 2015). Our system ob-tains 5.4% and 4.8% relative improvement in hop-0 and hop-1 CS-SF F1 over the top-ranked system. Improvement is observed in both hop-0 and hop-1 and with both CS-SF and CS-LDC-MAX show-ing that the improvement is robust. A sign test shows that the improvements are significant with p <0.01.
Systems P Hop-0R F1 P Hop-1R F1
KBC 45 33 37.9 14(16) 21 17
KBC+E 45 32 37.9 18(21) 21 19
KBC+R 49 32 38.2 27 19 23
KBC+E+R 49 31 38.4 32 19 24
Table 3: CS-SF scores (string-match) for differ-ent priors: KBC (baseline: no world knowledge), KBC+E (only entity-based factors), KBC+R(only relation-based factors), KBC+E+R(both sets of factors). Numbers in parentheses indicate the op-timistic estimate when it differs from the number reported by the scoring software.
[image:7.595.307.528.448.594.2]impact than adding the entity factors because our splitting of entities is conservative (only affects < 0.1%entities) while relations’ factors removes 7.3% relations. The two classes of factors ap-pear to have largely independent impacts– com-bining them yields a large improvement. In to-tal, adding prior world knowledge yields relative improvements of 9% in hop-0 precision, 131% on hop-1 precision, 42% on hop-1 F1, and 19.4% on all-hop F1 over the baseline. A sign test shows the improvements are significant withp <0.01.
Reduction of errors: With relation factors added (KBC+R and KBC+E+R), 7.3% relations (out of 243K) are removed byPruneRwith min-imal recall loss. The median number of fillers for relations for the top 1% entities drops, e.g. per:titlefrom 7 to 5,per:employee or member of from 5 to 2, andper:city of birthfrom 3 to 1. In-spection shows that our approach addresses many obvious mistakes: U.K.is removed as a response to (Securities and Exchange Commission(SEC), org:country of headquarters, ?) while U.S. re-mains. The error, caused by UK’s SEC which means UK’s analog to the SEC of US, is very hard to resolve without world knowledge. With cardinality constraints that favor only one coun-try of headquarters for an ORG and U.K has a lower confidence than U.S.as a filler, the model identifiesU.K.as an incorrect answer.
With entity factors added (KBC+E+R and KBC+E), the model favors a larger amount of smaller but more precise entities. It generates4%
new entities (out of 212K) by splitting the largest < 0.1% entities with the SplitE heuristics de-scribed in section 5. For example, the entity Aus-traliais splitted into 3 entities,Australia and two outliers West Aussie and Australian Capital Ter-ritory. It also singles out entities such as South America,Idaho,Coloradofrom the giantU.S. en-tity with>20,000mentions. When querying the KB facts related to U.S., erroneous answers that would otherwise be reported through relations as-sociated withSouth Americaor theU.S.states will be removed.
7 Related Work
Cold Start KBPThe TAC Cold Start KBP work-shop has attracted many text-based KBP sys-tems (McNamee et al., 2012; McNamee et al., 2013; Mayfield et al., 2014; Min et al., 2015; Roth et al., 2015; Angeli et al., 2014; Nguyen et al., 2014; Monahan and Carpenter, 2012).
KELVIN (Mayfield et al., 2014) and BBN sys-tem (Min et al., 2015) both use hand-crafted rules to limit the number of fillers, e.g., remove less pre-cise relations if apersonhas more than 8 (current and ex-) spouses. (Wolfe et al., 2015) and (He and Grishman, 2015) proposed interactive tools for KB construction with human guidance.
Knowledge Base Completion With the
re-cent popularity of structured KBs such as Free-base (Bollacker et al., 2008), YAGO (Suchanek et al., 2007) and above-mentioned KBP tech-niques, there is a growing interest in complet-ing a partially-complete KB with tensor decom-position (Chang et al., 2014), matrix factoriza-tion (Riedel et al., 2013), graph random walk (Lao et al., 2011; Lao et al., 2012; Gardner et al., 2014), neural networks (Socher et al., 2013; Neelakantan et al., 2015; Dong et al., 2014) and others (Guu et al., 2015; Gardner et al., 2013; Das et al., 2016). Knowledge Vault (Dong et al., 2014) pushes it fur-ther by combining many extraction components while estimating the confidence of their extrac-tions and scales it to the Web. Model combi-nation (Viswanathan et al., 2015) and confidence estimation (Wick et al., 2013; Li and Grishman, 2013) is related to our model for combining ex-traction components. The work described here dif-fers from KB completion tasks in its requirement that the initial KB is empty and that all informa-tion in the KB be grounded in a text corpus.
inference for IE is not comparable but comple-mentary to our method, therefore can be incorpo-rated into our system for further gain.
8 Conclusion and Future Work
We present a joint probabilistic framework for end-to-end Cold Start KBP with prior world knowledge. Experiments show it surpassing the best-performing system at the NIST TAC 2015 Cold Start evaluation. We plan to investigate addi-tional world knowledge in the near future.
Acknowledgments
The authors would like to thank Scott Miller, Ralph Weischedel, and the anonymous reviewers for their very helpful comments on improving the paper.
References
Gabor Angeli, Sonal Gupta, Melvin Johnson Premku-mar, Christopher D Manning, Re Christopher, Julie Tibshirani, Jean Y Wu, Sen Wu, and Ce Zhang. 2014. Stanford’s Distantly Supervised Slot Filling Systems for KBP 2014. In Text Analysis Confer-ence, Gaithersburg, Maryland.
Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a col-laboratively created graph database for structuring human knowledge. InProceedings of the 2008 ACM SIGMOD international conference on Management of data - SIGMOD ’08, page 1247, New York, New York, USA. ACM Press.
Kai-Wei Chang, Wen-tau Yih, Bishan Yang, and Christopher Meek. 2014. Typed Tensor Decom-position of Knowledge Bases for Relation Extrac-tion. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1568–1579, Doha, Qatar, oct. As-sociation for Computational Linguistics.
Zheng Chen, Suzanne Tamang, Adam Lee, Xiang Li, Wen-Pin Lin, Javier Artiles, Matthew Snover, Marissa Passantino, and Heng Ji. 2010. CUNY-BLENDER TAC-KBP2010 Entity Linking and Slot Filling System Description. InText Analysis Con-ference, Gaithersburg, Maryland.
Liwei Chen, Yansong Feng, Jinghui Mo, Songfang Huang, and Dongyan Zhao. 2014. Joint Inference for Knowledge Base Population. InProceedings of the 2014 Conference on Empirical Methods in Nat-ural Language Processing (EMNLP), pages 1912– 1923, Doha, Qatar, oct. Association for Computa-tional Linguistics.
Rajarshi Das, Arvind Neelakantan, David Belanger, and Andrew McCallum. 2016. Incorporating Se-lectional Preferences in Multi-hop Relation Extrac-tion. InProceedings of the 5th Workshop on Auto-mated Knowledge Base Construction, pages 18–23, San Diego, CA, jun. Association for Computational Linguistics.
Xin Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, and Wei Zhang. 2014. Knowl-edge vault: a web-scale approach to probabilis-tic knowledge fusion. In Proceedings of the 20th ACM SIGKDD international conference on Knowl-edge discovery and data mining - KDD ’14, pages 601–610, New York, New York, USA. ACM Press. Tim Finin, Paul McNamee, Dawn Lawrie, James
May-field, and Craig Harman. 2014. Hot stuff at cold start: HLTCOE participation at TAC 2014. InText Analysis Conference, Gaithersburg, Maryland. Jenny Rose Finkel and Christopher D Manning. 2009.
Joint Parsing and Named Entity Recognition. In
Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Lin-guistics, pages 326–334, Boulder, Colorado, jun. Association for Computational Linguistics.
Jenny Rose Finkel, Christopher D Manning, and An-drew Y Ng. 2006. Solving the Problem of Cas-cading Errors: Approximate Bayesian Inference for Linguistic Annotation Pipelines. InProceedings of the 2006 Conference on Empirical Methods in Nat-ural Language Processing, pages 618–626, Sydney, Australia, jul. Association for Computational Lin-guistics.
Matt Gardner, Partha Pratim Talukdar, Bryan Kisiel, and Tom Mitchell. 2013. Improving Learning and Inference in a Large Knowledge-Base using Latent Syntactic Cues. In Proceedings of the 2013 Con-ference on Empirical Methods in Natural Language Processing, pages 833–838, Seattle, Washington, USA, oct. Association for Computational Linguis-tics.
Matt Gardner, Partha Talukdar, Jayant Krishnamurthy, and Tom Mitchell. 2014. Incorporating Vector Space Similarity in Random Walk Inference over Knowledge Bases. InProceedings of the 2014 Con-ference on Empirical Methods in Natural Language Processing (EMNLP), pages 397–406, Doha, Qatar, oct. Association for Computational Linguistics. Ralph Grishman. 2013. Off to a Cold Start: New York
University’s 2013 Knowledge Base Population Sys-tems. In Text Analysis Conference, Gaithersburg, Maryland.
Kelvin Guu, John Miller, and Percy Liang. 2015. Traversing Knowledge Graphs in Vector Space. In
318–327, Lisbon, Portugal, sep. Association for Computational Linguistics.
Yifan He and Ralph Grishman. 2015. ICE: Rapid Information Extraction Customization for NLP Novices. InProceedings of the 2015 Confer-ence of the North American Chapter of the Asso-ciation for Computational Linguistics: Demonstra-tions, pages 31–35, Denver, Colorado, jun. Associa-tion for ComputaAssocia-tional Linguistics.
Raphael Hoffmann, Congle Zhang, Xiao Ling, Luke Zettlemoyer, and Daniel S Weld. 2011. Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations. In Proceedings of the 49th Annual Meeting of the Association for Com-putational Linguistics: Human Language Technolo-gies, pages 541–550, Portland, Oregon, USA, jun. Association for Computational Linguistics.
Martin Jansche. 2005. Maximum Expected F-Measure Training of Logistic Regression Models. In Pro-ceedings of Human Language Technology Confer-ence and ConferConfer-ence on Empirical Methods in Nat-ural Language Processing, pages 692–699, Vancou-ver, British Columbia, Canada, oct. Association for Computational Linguistics.
Heng Ji, David Westbrook, and Ralph Grishman. 2005. Using Semantic Relations to Refine Coreference De-cisions. InProceedings of Human Language Tech-nology Conference and Conference on Empirical Methods in Natural Language Processing, pages 17–24, Vancouver, British Columbia, Canada, oct. Association for Computational Linguistics.
Rohit J Kate and Raymond Mooney. 2010. Joint Entity and Relation Extraction Using Card-Pyramid Parsing. InProceedings of the Fourteenth Confer-ence on Computational Natural Language Learning, pages 203–212, Uppsala, Sweden, jul. Association for Computational Linguistics.
Ni Lao, Tom Mitchell, and William W Cohen. 2011. Random Walk Inference and Learning in A Large Scale Knowledge Base. InProceedings of the 2011 Conference on Empirical Methods in Natural Lan-guage Processing, pages 529–539, Edinburgh, Scot-land, UK., jul. Association for Computational Lin-guistics.
Ni Lao, Amarnag Subramanya, Fernando Pereira, and William W Cohen. 2012. Reading The Web with Learned Syntactic-Semantic Inference Rules. In
Proceedings of the 2012 Joint Conference on Empir-ical Methods in Natural Language Processing and Computational Natural Language Learning, pages 1017–1026, Jeju Island, Korea, jul. Association for Computational Linguistics.
Xiang Li and Ralph Grishman. 2013. Confidence Estimation for Knowledge Base Population. In
Proceedings of the International Conference Recent Advances in Natural Language Processing RANLP 2013, pages 396–401, Hissar, Bulgaria, sep. IN-COMA Ltd. Shoumen, BULGARIA.
Qi Li and Heng Ji. 2014. Incremental Joint Extrac-tion of Entity MenExtrac-tions and RelaExtrac-tions. In Proceed-ings of the 52nd Annual Meeting of the Associa-tion for ComputaAssocia-tional Linguistics (Volume 1: Long Papers), pages 402–412, Baltimore, Maryland, jun. Association for Computational Linguistics.
James Mayfield, Paul Mcnamee, Craig Harman, Tim Finin, and Dawn Lawrie. 2014. KELVIN: Extract-ing Knowledge from Large Text Collections. In
AAAI Fall Symposium on Natural Language Access to Big Data, Arlington, Virginia.
James Mayfield. 2014. Cold Start Knowledge Base Population at TAC 2014. InText Analysis Confer-ence, Gaithersburg, Maryland.
Andrew Mccallum and David Jensen. 2003. A Note on the Unification of Information Extraction and Data Mining using Conditional-Probability, Rela-tional Models. InIJCAI-2003 Workshop on Learn-ing Statistical Models from Relational Data, Aca-pulco, Mexico.
Paul McNamee, Veselin Stoyanov, James Mayfield, Tim Finin, Tan Xu, Douglas W. Oard, and Dawn Lawrie. 2012. HLTCOE Participation at TAC 2012: Entity Linking and Cold Start Knowledge Base Con-struction. In Text Analysis Conference, Gaithers-burg, Maryland.
Paul McNamee, Tim Finin, Dawn Lawrie, and James Mayfield. 2013. HLTCOE Participation at TAC 2013. In Text Analysis Conference, Gaithersburg, Maryland.
Bonan Min, Marjorie Freedman, and Constantine Lig-nos. 2015. BBN’s 2015 System for Cold Start Knowledge Base Population. InText Analysis Con-ference, Gaithersburg, Maryland.
Mike Mintz, Steven Bills, Rion Snow, and Daniel Ju-rafsky. 2009. Distant supervision for relation ex-traction without labeled data. InProceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, pages 1003–1011, Suntec, Singapore, aug. Association for Computational Linguistics.
Makoto Miwa and Yutaka Sasaki. 2014. Modeling Joint Entity and Relation Extraction with Table Rep-resentation. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Pro-cessing (EMNLP), pages 1858–1869, Doha, Qatar, oct. Association for Computational Linguistics. Sean Monahan and Dean Carpenter. 2012. Lorify:
A Knowledge Base from Scratch. InText Analysis Conference, Gaithersburg, Maryland.
Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 156–166, Beijing, China, jul. Association for Computational Linguis-tics.
Thien Huu Nguyen, Yifan He, Maria Pershina, Xiang Li, and Ralph Grishman. 2014. New york university 2014 knowledge base population systems. InText Analysis Conference, Gaithersburg, Maryland. Robert Parker, David Graff, Junbo Kong, Ke Chen, and
Kazuaki Maeda. 2011. English Gigaword Fifth Edi-tion. LDC2011T07.
Hoifung Poon and Pedro Domingos. 2007. Joint in-ference in information extraction. In Proceedings of the 22nd national conference on Artificial in-telligence - Volume 1, pages 913–918, Vancouver, British Columbia, Canada. AAAI Press.
Hoifung Poon and Lucy Vanderwende. 2010. Joint Inference for Knowledge Extraction from Biomed-ical Literature. InHuman Language Technologies: The 2010 Annual Conference of the North Ameri-can Chapter of the Association for Computational Linguistics, pages 813–821, Los Angeles, Califor-nia, jun. Association for Computational Linguistics. Karthik Raghunathan, Heeyoung Lee, Sudarshan Ran-garajan, Nate Chambers, Mihai Surdeanu, Dan Ju-rafsky, and Christopher Manning. 2010. A Multi-Pass Sieve for Coreference Resolution. In Proceed-ings of the 2010 Conference on Empirical Meth-ods in Natural Language Processing, pages 492– 501, Cambridge, MA, oct. Association for Compu-tational Linguistics.
Lance Ramshaw, Elizabeth Boschee, Marjorie Freed-man, Jessica MacBride, Ralph Weischedel, and Alex Zamanian. 2011. SERIF language processing ef-fective trainable language understanding. Springer-Link : B{¨u}cher. Springer New York.
Sebastian Riedel and Andrew McCallum. 2011. Fast and Robust Joint Models for Biomedical Event Ex-traction. InProceedings of the 2011 Conference on Empirical Methods in Natural Language Process-ing, pages 1–12, Edinburgh, Scotland, UK., jul. As-sociation for Computational Linguistics.
Sebastian Riedel, Limin Yao, and Andrew McCal-lum. 2010. Modeling Relations and Their Mentions without Labeled Text. In Joint European Confer-ence on Machine Learning and Knowledge Discov-ery in Databases, pages 148–163, Barcelona, Spain. Springer, Berlin, Heidelberg.
Sebastian Riedel, Limin Yao, Andrew McCallum, and Benjamin M Marlin. 2013. Relation Extraction with Matrix Factorization and Universal Schemas. InProceedings of the 2013 Conference of the North American Chapter of the Association for Computa-tional Linguistics: Human Language Technologies, pages 74–84, Atlanta, Georgia, jun. Association for Computational Linguistics.
Dan Roth and Scott Wen-tau Yih, 2007. Global In-ference for Entity and Relation Identification via a Linear Programming Formulation, pages 553–580. MIT Press, nov.
Benjamin Roth, Nicholas Monath, David Belanger, Emma Strubell, Patrick Verga, and Andrew McCal-lum. 2015. Building knowledge bases with univer-sal schema: Cold start and slot-filling approaches. In Text Analysis Conference, Gaithersburg, Mary-land.
Sameer Singh, Karl Schultz, and Andrew McCal-lum, 2009. Bi-directional Joint Inference for Entity Resolution and Segmentation Using Imperatively-Defined Factor Graphs, pages 414–429. Springer Berlin Heidelberg, Berlin, Heidelberg.
Sameer Singh, Sebastian Riedel, Brian Martin, Jiaping Zheng, and Andrew McCallum. 2013a. Joint infer-ence of entities, relations, and coreferinfer-ence. InThe 3rd Workshop on Automated Knowledge Base Con-struction, pages 1–6, New York, New York, USA. ACM Press.
Sameer Singh, Limin Yao, David Belanger, Ari Ko-bren, Sam Anzaroot, Michael Wick, Alexandre Passos, Harshal Pandya, Jinho Choi, Brian Mar-tin, and Andrew McCallum. 2013b. Universal Schema for Slot Filling and Cold Start: UMass IESL at TACKBP 2013. In Text Analysis Conference, Gaithersburg, Maryland.
Richard Socher, Danqi Chen, Christopher D Manning, and Andrew Ng. 2013. Reasoning With Neural Ten-sor Networks for Knowledge Base Completion. In C J C Burges, L Bottou, M Welling, Z Ghahramani, and K Q Weinberger, editors, Advances in Neural Information Processing Systems 26, pages 926–934. Curran Associates, Inc.
Fabian M. Suchanek, Gjergji Kasneci, and Gerhard Weikum. 2007. Yago: a core of semantic knowl-edge. InProceedings of the 16th international con-ference on World Wide Web - WWW ’07, pages 697– 706, New York, New York, USA. ACM Press. Mihai Surdeanu, Julie Tibshirani, Ramesh Nallapati,
and Christopher D Manning. 2012. Multi-instance Multi-label Learning for Relation Extraction. In
Proceedings of the 2012 Joint Conference on Empir-ical Methods in Natural Language Processing and Computational Natural Language Learning, pages 455–465, Jeju Island, Korea, jul. Association for Computational Linguistics.
Ben Wellner, Andrew McCallum, Fuchun Peng, and Michael Hay. 2004. An integrated, conditional model of information extraction and coreference with application to citation matching. In the 20th conference on Uncertainty in artificial intelligence, pages 593–601, Banff, Canada. AUAI Press. Michael Wick, Sameer Singh, Ari Kobren, and Andrew
McCallum. 2013. Assessing confidence of knowl-edge base content with an experimental study in en-tity resolution. InProceedings of the 2013 workshop on Automated knowledge base construction - AKBC ’13, pages 13–18, New York, New York, USA. ACM Press.
Travis Wolfe, Mark Dredze, James Mayfield, Paul McNamee, Craig Harman, Tim Finin, and Ben-jamin Van Durme. 2015. Interactive Knowledge Base Population. CoRR, abs/1506.0.
Limin Yao, Sebastian Riedel, and Andrew McCallum. 2010. Collective Cross-Document Relation Extrac-tion Without Labelled Data. In Proceedings of the 2010 Conference on Empirical Methods in Natu-ral Language Processing, pages 1013–1023, Cam-bridge, MA, oct. Association for Computational Linguistics.
Nan Ye, Kian M Chai, Wee S Lee, and Hai L Chieu. 2012. Optimizing F-measure: A Tale of Two Ap-proaches. In John Langford and Joelle Pineau, ed-itors,Proceedings of the 29th International Confer-ence on Machine Learning (ICML-12), pages 289– 296, New York, NY, USA. ACM.