45
Abstract—
Cloud Computing technology has been emerged to manage large-scale data efficiently. And due to rapid growth of data, large scale data processing is becoming a focal point of information technique. To deal with this advancement in data collection and storage technologies, designing and implementing large-scale parallel algorithm for Data mining is gaining more interest. In this paper we design Association Rule based parallel data mining algorithm which deals with Hadoop cloud, a parallel store and computing platform. Moreover we have introduced cloud inter operation between Hadoop and Sector/Sphere Cloud which allows the same Hadoop MapReduce application to be run against data in either Hadoop Distributed File System or Sphere File System.
Index Terms—Association Rule; Cloud Computing; Data mining MapReduce; Parallel.
I. INTRODUCTION
Nowadays huge amount of data are created every day. With this rapid explosion of data we are moving towards the terabytes era to petabytes era. This trend creates demand for advancement in data collection and storing technology. Hence there is a growing need to run data mining algorithm on very large datasets.
Cloud computing is a new business model containing pool of resources constituting large number of computers. It distributes the computation task to its pool of resources so that application systems can obtain variety of software services on demand. Another feature of cloud computing is that it provides unlimited storage and computing power which leads us to mine mass amount of data.
Hadoop [2, 3] is the software framework for writing applications that rapidly process vast amounts of data in parallel on large clusters of compute nodes. It works on MapReduce programming model. MapReduce is a generic execution engine that parallelizes computation over a large
Manuscript received 22 May, 2012.
Nirali R. Sheth, Computer Department, L. D. College of Engineering, (e-mail: [email protected]). Ahmedabad, India.
J S Shah, Computer Department, L. D. College of Engineering, (e-mail: [email protected]). Ahmedabad, India.
cluster of machines.
Sector/Sphere [4] is an open source cloud written in C++ for storing, sharing and processing large datasets. Sector is a distributed file system targeting data storage over a large commodity computer. Sphere is the programming framework that supports massive in-storage parallel data processing for data stored in sector.
Based on the increasing demand for parallel computing environment of cloud and parallel mining algorithm, we study different mining algorithms. Association rule based algorithm, Apriori algorithm, is improved in order to combine it with the MapReduce programming model of cloud and mine mass amount of data.
With emerging trends in Cloud Computing, data mining enters a new era, which can have a new implementation. We can use cloud computing techniques with Data mining to reach high capacity and high efficiency by using parallel computational nature of the cloud. As MapReduce provides good parallelism for the computation, it is very suitable for us to implement data mining system based on MapReduce.
The rest of paper is organized as follows. In Section II we described Related Work, including Hadoop and Sector/Sphere cloud and Apriori data mining algorithm. Section III presents Improvement in Apriori Algorithm and explains about applying improved Apriori algorithm on MapReduce. Section IV shows the cloud inter-operability between Hadoop and Sector/Sphere cloud. Section V analyzes the experimental results and Section VI concludes the paper.
II. RELATED WORK
MapReduce is a distributed Programming Model intended for large cluster of systems that can work in parallel on a large dataset. Figure 1 shows the working of MapReduce model. As shown in the figure, the Job Tracker is responsible for handling the Map and Reduce process. The tasks divided by the main application are firstly processed by the map tasks in a completely parallel manner. The MapReduce framework sorts the outputs of the maps, which are then input to the reduce tasks. Both the input and output of the job are stored in the file system.
Implementing Parallel Data Mining Algorithm
on High Performance Data Cloud
Figure 1: MapReduce Model
Due to parallel computing nature of MapReduce, parallelizing data mining algorithms using the MapReduce model has received significant attention from the research community since the introduction of the model by Google. In [5], The MapReduce model based on Hadoop is examined for applicability in the field of Data Mining.
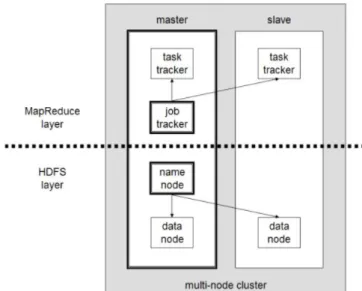
Hadoop is an open source implementation of MapReduce Programming model which relies on its own Hadoop Distributed File System. HDFS replicates data blocks in a reliable manner and places them on different nodes; computation is then performed on these nodes. Figure 2 shows the architecture of Hadoop MapReduce cloud. Hadoop consists of Hadoop common, which provides access to the file system supported by Hadoop. Hadoop cluster include a single master and multiple worker nodes. The master node consists of task tracker, job tracker, name node and data node. A slave node acts as both a task tracker and data node.
Figure 2: Hadoop Architecture
Sector/Sphere is a software platform that supports very large distributed data storage and simplified distributed data processing. The system consists of Sector, a distributed storage system, and Sphere, a runtime middleware to support simplified development of distributed data processing. Figure 3 shows Sector/sphere architecture. Sector/Sphere consists of four components. The security server maintains the system security policies such as user accounts and the IP access control list. One or more master servers control operations of the overall system in addition to responding to various user requests. The slave nodes store the data files and process them upon request. The clients are the users' computers from which system access and data processing requests are issued.
Figure 3: Sector/Sphere Architecture
Data mining technology is widely used in the large scale data applications. Data mining technology contains classification algorithms, clustering algorithm and association algorithm. Association rule mining is an important research topic of data mining. Its task is to find all the frequent subsets of items and relationship between them. Association rule mining is performed in two phases: The establishment of frequent item sets and the establishment of association rules.
Among all association rule mining algorithms, Apriori algorithm is the most classic and most widely used algorithm for mining frequent item sets which generates Boolean association rules. This algorithm uses iterative method to generate (k+1) itemsets from k itemsets.
47 algorithm; it partitions the data sets and the candidate item
sets reasonably at the same time, so that each node can work independently.
We will design a strategy of parallel association rule mining for Hadoop cloud computing environment by taking partially reference of the ideas of above algorithms. Hadoop is a pure java implementation. It offers the ability to access other file systems allowing them to be used as the backing store for the MapReduce applications. So here we will create an implementation of the Hadoop file system abstraction for the sector file system. This allows the same Hadoop MapReduce application to run against data in the either Hadoop Distributed file system or Sector file system.
III. IMPROVED APRIORI ALGORITHM WITH MAPREDUCE
A. Improvement in Apriori Algorithm
Apriori algorithm finds all frequent itemsets by scanning the database time after time. This algorithm wastes a lot of time and memory space so to introduce parallelization in Apriori algorithm, an improved Apriori algorithm is proposed which is shown below.
a. For making parallel scan, we first divide the transaction database horizontally into n data subsets and distribute it to m nodes.
b. Then each node scans its own data sets and generate set of Candidate itemset Cp. The support count of each Candidate itemset is set to 1.
c. This Candidate itemset Cp is divided into r partitions and sent to r nodes with their support count. d. r nodes respectively accumulate the support count of
the same itemset to produce the final practical support, and determine the frequent itemset Lp in the partition after comparing with the minimum support count min_sup.
e. Finally merge the output of r nodes to generate set of global frequent itemset L.
From the above improved Apriori algorithm we can considerably reduce the time as in this algorithm we are getting frequent itemsets by traversing transaction database only once [8].
B. Combining improved Apriori Algorithm with MapReduce
The above showed improved Apriori algorithm is implemented with MapReduce Programming model as shown below [8].
a. Partitioning and Distributing data
Transaction database is divided into n subsets by MapReduce Library and are sent to m nodes executing Map tasks.
b. Formatting the data subsets
Format n data subsets as <key1,value1> pair where key is transaction id.
c. Execute Map task
The task of Map function is to scan each record of the input item subset and generating Candidate item set Cp.
d. Operate Combiner option
Combiner function firstly combines the Map function outputs in the local and outputs <itemset,support_count> . Combiner function then uses partition function to divide the intermediate pairs generated by combiner function into r different partitions.
e. Execute Reduce task
At Reduce function, the key itemsets are first sorted. After sorting the Reduce function add up the support count of the same candidates and get the actual support count of the candidate in the whole transaction database. Then comparing it with the minimum support count and getting the frequent itemsets Lp.
IV. INTEROPERATION BETWEEN HADOOP AND SECTOR/SPHERE CLOUD
Sector is an open source cloud written in C++ for storing, sharing and processing large data sets. Sector is broadly similar to the Google File System and the Hadoop Distributed File System, except that it is designed to utilize wide area high performance networks. Thus Hadoop/HDFS and Sector/Sphere are software frameworks and distributed file systems designed to allow users to store and process extremely large data sets.
Hadoop offers the ability to access other file systems, allowing them to be used as the backing store for MapReduce applications. This requires creating a custom implementation of the Hadoop file system abstraction. The MapReduce processing still runs within the Hadoop framework, with the alternative file system implementation providing the bridge between MapReduce and the backing file system. W e will create an interface to Sector which uses the Java Native Interface to allow applications written in Java to access the Sector file system written in C++. To illustrate using this JNI component to access Sector from a Java application, and to provide an example of interoperability between cloud systems, we will create an implementation of the Hadoop file system abstraction which allows Sector to be used as the backing file store for Hadoop MapReduce applications. This allows the same Hadoop MapReduce application to be run against data in either the Hadoop distributed file system or the Sector file system.
components [5]:
1. The interface to Sector is implemented using the Java Native Interface (JNI). The Java Native Interface is a framework that allows Java code to call native applications written in languages such as C or C++. Sector is implemented in C++, so this layer is necessary to allow Java code to access Sector.
2. Data reads and writes between the systems use Java NIO (New I/O) which uses direct-mapped byte buffers.
3. Access to the Sector JNI Bridge goes through a custom implementation of the Hadoop File System interface on the Hadoop side.
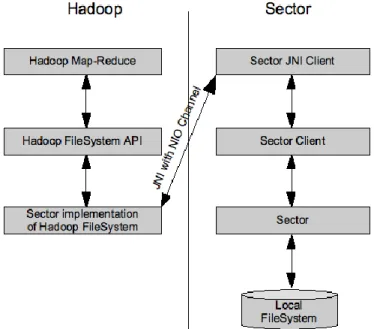
From these components we can describe the Software Architecture view of the interface implementation between Hadoop and Sector file system. Figure 4 shows this Software Architecture view.
Figure 4: Software Architecture for the interface implementation of Hadoop and Sector
As the figure shows, many components are there who participates in this inter operability. Sector is the primary infrastructure which controls access to data stored in the Sector file system. Sector Client is client API, implemented in C++, which allows client applications to access Sector data. This API provides standard file system operations such as opening files, reading and writing to files, retrieving directory listings, etc. SectorJNIClient is the JNI component contributed to Sector. It is a custom implemented component that provides access to the Sector Client API. This component uses the Java Native Interface (JNI) to allow Java applications to access the Sector C++ client. This component has two primary pieces: One is
SectorjniClient.cpp, which acts as the translation layer
between the Sector C++ client and Java. This code is compiled into a shared object, and another is
SectorjniClient.java, which loads the C++ shared object and provides an interface between Java clients and the C++ layer. Note that this class mainly acts as a bridge to the C++ layer which manages all access to the Sector client API, translation between C++ objects and Java objects.
Hadoop MapReduce is The Hadoop implementation of MapReduce. This is the infrastructure provided by Hadoop to implement and manage MapReduce processing. HadoopFileSystem is The Hadoop abstraction that defines the interface between Hadoop applications and an underlying file system. This interface must be implemented for each files system that Hadoop will access. Hadoop includes several standard implementations of File System such as LocalFileSystem and DistributedFileSystem, which access the local file system and Hadoop distributed file system respectively. Sector implementation of Hadoop File system is A custom implementation of the Hadoop File System interface which provides access to Sector through the SectorJniClient.java class associated with the event.
V. EXPERIMENTS & RESULTS
In order to test the performance of the parallel data mining strategy, first experiment has done on Hadoop platform. Experiment has been performed with at least 10 PCs with the software environment having Hadoop installed on Ubuntu.
Fig 5 shows the time effect of the parallel algorithm on Hadoop. As shown in the figure, under the cloud computing environment, the parallel algorithm has better performance on mining frequent itemsets from the mass data.
49 Figure 5: Experimental Results
This performance degradation with Sector file system can be due to I/O Overhead where there is a great deal of file transfer between the distributed and local file system. Another issue can be JNI Overhead as it faces difficulty while going through JNI Layer to access Sector.
VI. CONCLUSION
In this paper, we have studied parallel association rule mining strategy in the cloud computing environment; implemented the improved Apriori Algorithm on MapReduce programming model on the Hadoop platform. Also created interface between Hadoop and Sector file System which allows all Hadoop application to run on Sector data. The results shows that the parallel mining algorithm performs effectively on Hadoop cloud computing environment. The same can also perform on Sector file system but have degraded performance due to I/O and JNI overhead.
REFERENCES
[1] Yunhong Gu and Robert L. Grossman “Sector and Sphere: The Design and Implementation of a High Performance Data Cloud”.
[2] Apache hadoop. http://hadoop.apache.org.
[3] Dhruba Borthaku. “The hadoop distributed file system: Architecture and design”.
[4] Yunhong Gu and Robert L. Grossman “Sector and Sphere: The Design and Implementation of a High Performance Data Cloud”.
[5] Wikipedia,
http://code.google.com/p/cloud-interop/wiki/SectorFil eSystem
[6] Jianzong Wang, Jiguang Wan, Zhuo Liu, Peng Wang, “Data Mining of Mass Storage Based on Cloud Computing”
[7] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. “The Google File System”. In SOSP, 2003.
[8] Lingjuan Li and Min Zhang, The Strategy of Mining Association Rule Based On Cloud Computing, 2011 IEEE International Conference on Business Computing and Global Informatization.
[9] Lei Zhang, Kaiping Li, Bin Wu, Beijing Key Laboratory of Intelligent Telecommunications Software and Multimedia, “The Research and Design of SQL processing in a data-mining system based on mapreduce”.
[10]Robert L. Grossman and Yunhong Gu “Data Mining using high performance data clouds: Experimental Studies using Sector and Sphere”. Retrieved from http://sector.sourceforge.net/pub/grossman-gu-ncdm-t r-08-04.pdf.
[11]R. Agrawal and J.C. Shafer. Parallel mining of association rules. IEEE Transactions on Knowledge and Data Eng., 8(6):962–969, December 1996.
[12]Gillick, D., Faria, A., DeNero, J., MapReduce: Distributed Computing for Machine Learning, Berkeley (2006)
[13]Lei Zhang, Kaiping Li, Bin Wu, “THE RESEARCH AND DESIGN OF SQL PROCESSING IN A
DATA-MINING SYSTEM BASED ON
MAPREDUCE”, Proceedings of IEEE CCIS2011
[14]“Top 10 algorithms in data mining”, © Springer-Verlag London Limited 2007
[15]Jiong Xie, Shu Yin, Xiaojun Ruan, Zhiyang Ding, Yun Tian, James Majors, Adam Manzanares, and Xiao Qin, “Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters”, IPDPS Workshops'2010