HIKARI Ltd, www.m-hikari.com http://dx.doi.org/10.12988/ams.2014.410802
Construction Actuarial Model for Aggregate Loss
under Exponentiated Inverted Weibull
Distribution
Osama Hanafy Mahmoud
Department of Mathematics, Statistics and Insurance Sadat Academy for Management Sciences, Egypt
Copyright © 2014 Osama Hanafy Mahmoud. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Abstract
The problem of planning reinsurance policies in property and causality insurance companies and how to estimate the loss reserve play an important role for the results of the insurance company. Also, they have past or present data for number of claims and its amounts which want to use in prediction future claim frequency and claim severity. Many statistical distribution are fitting to find an appropriate distribution to represent our data. In this paper, we introduce a statistical distribution known as Exponentiated Inverted Weibull (EIW) distribution to represent the claim amount and its characteristics for applying it in actuarial studies. Second, we test the tail weight of the distribution and maximum likelihood estimation for its parameters. we present our aggregate loss model under collective risk theory when the claim frequency distribution is Poisson or Negative Binomial distribution. Also, we present how to calculate the reinsurance pure premium in case of stop loss reinsurance. Finally, The simulation numerical example is given to represent our results.
Keywords: Exponentiated Inverted Weibull Distribution, Tail Weight of Distribution, Maximum Likelihood Estimation, Aggregate Loss Model
1. Introduction
Insurance companies need to investigate claims experience and apply mathematical techniques for many purposes such as ratemaking, reserving, reinsurance arrangements and solvency.
Many papers have been presented to aggregate losses as: Heckman and Meyers (1983) discussed aggregate loss distributions from the perspective of collective risk theory for severity and count distributions. They include examples for calculating the pure premium for a policy with an aggregate limit, calculating the pure premium of an aggregate stop-loss policy for group life insurance; and calculating the insurance charge for a multi-line retrospective rating plan, including a line which is itself subject to an aggregate limit. Venter (1983), Distribution functions are introduced based on power transformations of beta and gamma distributions, and properties of these distributions are discussed. The gamma, beta, F, Pareto, Burr, Weibull and loglogistic distributions are special cases. The transformed gamma is used to model aggregate distributions by matching moments. The transformed beta is used to account for parameter uncertainty in this model.
Robertson (1992), Provided an application of the fast Fourier transform to the computation of aggregate loss distributions from arbitrary frequency and severity distributions. Papush el al (2001), addressed the question what type of Normal , Lognormal and Gamma distributions is the most appropriate to use to approximate aggregate loss distribution. Vilar et al. (2008), described a nonparametric approach to make inference for aggregate loss models in the insurance framework by assuming that an insurance company provides a historical sample of claims given by claim occurrence times and claim sizes.
Bortoluzzo et al. (2009), aimed estimating claim size in the auto insurance by using zero adjusted Inverse Gaussian distribution. Shevchenko (2010) reviewed numerical algorithms that can be successfully used to calculate the aggregate loss distributions. In particular Monte Carlo, Panjer recursion and Fourier transformation methods are presented and compared. Also, several closed-form approximations based on moment matching and asymptotic result for heavy-tailed distributions are reviewed.
One of the most significant goals of any insurance risk activity is to achieve a satisfactory model for the probability distribution of the total claim amount. In this paper, we introduce a statistical distribution known as Exponentiated Inverted Weibull (EIW) distribution to represent the claim amount and its characteristics for applying it in actuarial studies.
This paper is organized as follows: Section 2 we presentsThe Model claim
of a distribution. In Section 3 we discuss the problem of estimating the parameters of distribution by using maximum likelihood method. Section 4 we present our aggregate loss model under collective risk theory when the claim frequency distribution is Poisson or Negative Binomial distribution. Section 5, how to calculate the reinsurance pure premium in case of stop loss reinsurance. Finally, The simulation numerical example is given to represent our results.
2. The Model under Exponentiated Inverted Weibull Distribution
Recently many studies in probability distributions and its applications presented the Exponentiated Inverted Weibull distribution as:
Flaih et al (2012), Considered the standard exponentiated inverted weibull distribution (EIW) that generalizes the standard inverted weibull distribution (IW), the new distribution has two shape parameters. The moments, median, survival function, hazard function, maximum likelihood estimators, least-squares estimators, fisher information matrix and asymptotic confidence intervals have been discussed. A real data set is analyzed and it is observed that the (EIW) distribution can provide a better fitting than (IW) distribution. Aljouharah Aljuaid, (2013), presented Bayes and classical estimators have been obtained for two parameters exponentiated inverted Weibull distribution when sample is available from complete and type II censoring scheme. Hassan (2013), dealt with the optimal designing of failure step- stress partially accelerated life tests with two stress levels under type-I censoring. The lifetime of the test items is assumed to follow exponentiated inverted Weibull distribution. Hassan et al. (2014), presented estimation of population parameters for the exponentiated inverted Weibull distribution based on grouped data with equi and unequi-spaced grouping. Several alternative estimation schemes, such as, the method of maximum likelihood, least squares, minimum chi-square, and modified minimum chi-square are considered.
If our claims amount of insurance portfolio x1,x2,x3,,xn follow the Exponentiated Inverted Weibull (EIW) distribution with parameters and in the following form for the probability density function (pdf):
0 , , ) ( ) ( ( 1) x x e x f x (1)
Therefore, its cumulative probability function (cpf) can be written in the form: 0 , , ) ( ) (x e x F x (2)
large values of the random variable. A distribution is said to be a heavy-tailed distribution if it significantly puts more probability on larger values of the random variable. We also say that the distribution has a larger tail weight. In contrast, a distribution that puts less and less probability for larger values of the random variable is said to be light-tailed distribution.
To test the tail weight of a distribution, we can use the Existence of Moments method as follows:
A distribution f(x) is said to be light-tailed if E(xr)1 for all r 0 and the distribution f (x) is said to be heavy-tailed if either ( r)
x
E does not exist for all r 0 or the moments exist only up to a certain value of a positive integer r, Finan (2014).
The rth moments of the exponentiated inverted weibull distribution is given as follows: 0 , , ) ( ) ( 0 ) 1 (
x dx x e x x E r r x This can be written as:
r x r E(x r r (1 ) , , 0 ) (3) Proof: The pdf of the EIW distribution is:
0 , , ) ( ) (x e x( 1) x f x
The rth moments function can be written in the form:
0 ) ( ) (x x f x dx E r r dx x e x x E( r) r ( x ) ( 1) 0
By taking transformation H x We can write the rth moments function as:dH H H e H x E H r r 1 1 1 ) 1 ( 0 ) (
By simplification of the above equation ,we can get dH e H x E H r r r
0 1 1 ) ( This integral known as gamma function , therefore the rth moments function is:
r x E r r 1 ) (
From the above equation, we can find to obtain the rth moment must the value of
greater than r to be exist.Since the moments are not finite for all positive r; the exponentiated inverted weibull distribution is heavy-tailed.
From the above equation, we can find the mean and the variance of EIW distribution as follows: By putting r=1 r x E(x (1 1) , , 0 ) 1 (4)
And the second moment by putting r =2 in the form:
r x E(x (1 2) , , 0 ) 2 2 (5)
Thus the variance is:
2 2 2 2 ) 1 1 ( ) 2 1 ( )) ( ( ) ( ) E x E x V(x
3. Maximum Likelihood Estimation (MLE) for parameters
Suppose that we have postulated a probability model, such as the Exponented Inverted Weibull distribution, to describe a given loss amount distribution. The next step in our procedure should be to estimate values for the parameters of the model.
We use the maximum likelihood method (MLE) for estimating the unknown parameters and of Exponented Inverted Weibull distribution, as follows:-
N 1 i ) ( ) , ( f xi L Then the likelihood function is as follows,
N i i x N N N i i x x e x e L N i i 1 ) 1 ( ) ( 1 ) 1 ( ) ( ) ( ) ( ) , ( 1 (6)
N i i N i i x x N N L 1 1 ln ) 1 ( ln ln ) , ( ln (7)So, we need to estimate the two parameters and . The first derivatives for the natural logarithm of the likelihood function with respect to and , are given by
N i i x N L 1 ) , ( ln (8)
N i i N i i i x x x N L 1 1 ln ) ln ( ) , ( ln (9)The maximum likelihood estimators of and could be obtained by equating the equations (8) and (9) by zero, and solving them simultaneously using an iterative technique. We obtain the approximate variance covariance matrix by replacing expected values by their maximum likelihood estimators and inverting the Fisher – information matrix, defined by:
2 2 2 2 2 2 ln ln ln ln L L L L I
Where, the second derivatives of the natural logarithm of likelihood function defined in equation (6) are given as follows:
2 2 2 ) , ( ln N L (10)
N i i i x x L 1 2 ) ln ( ) , ( ln (11)
N i i i x x N L 1 2 2 2 2 ) ) (ln ( ) , ( ln (12)The MLE
ˆ and
ˆ have an asymptotic variance covariance matrix obtained by inverting the Fisher – information matrix.
4. Aggregate loss model under collective Risk Theory
Suppose that portfolio has N claims in the past period of time in our experience and each unit has xi is the claim size which is independent identical distributed
exponented inverted Weibull with parameters and its p.d.f in the equation (1) and cumulative probability function in the equation (2) .
Then the aggregate losses is S where the sum of claim amounts as:
N x x x x S 1 2 3
Suppose also that the individual loss amounts
x
i are independent on the annual loss frequency N.Then it follows that:
The probability density function (pdf) of aggregate losses is
0 * ) ( ) ( ) ( k k x s S pr N k f s f (13) Where fx*k(s) is called the k th fold convolution of x1x2 x3 xNthe k th fold convolutions are often extremely difficult to compute in practice and therefore one encounters difficulties dealing with the probability distribution of S: An alternative approach is to use various approximation techniques. We consider a technique known as the Panjer recursive formula.
The mean and variance of aggregate loss distribution can get as:
( )
( ) ) ( ) ( ) ( ) ( ) ( ) ( 2 N V x E x V N E s V x E N E s E (14)The pricing problem usually reduces to finding moment of S. A common pricing formula is price E(s)k v(s)
Where the price is the expected payout plus a risk loading which k times the variance of the payout for some k.
The expected payout E(s) is also known as the pure premium and it can be shown to be E(N)E(x).
Estimation the Mean and the Variance of Aggregate losses Distribution: We will consider Poisson and Negative Binomial distributions for the frequency distribution of losses as follows:
I. Poisson Distribution
Suppose that the annual frequency of losses from a portfolio follows a Poisson distribution with parameter.
s E( ) (1 1) 1 (15) s V( ) (1 2) 2 (16) II. Negative Binomial Distribution
Suppose that the annual frequency of losses from a portfolio follows a Negative Binomial distribution with parameters rand p.
In this case the mean of the loss distribution is: p pr s E (1 1) 1 ) ( 1 (17) p p p pr s V 2 2 ) 1 1 ( 1 ) 2 1 ( 1 ) ( (18)
5. Stop Loss Reinsurance
Gauger and Hosking (2008) and Finan (2014) presented the stop loss reinsurance as:
When a deductible D is applied to the aggregate loss S over a definite period, then the insurance payment will be
D S D S D S D S S D S Max D S , , 0 ^ 0 ,the reinsurer will pay the insurer an amount equal to
SD
. The insurer's retained loss is thus S^D.The main problem is how to calculate the reinsurance pure premium?.
the reinsurance pure premium is payment as the stop-loss re insurance. Its expected cost is called the net stop-loss premium and can be computed as:
S D
F x
dx
x d
f x dx E S D D S( ) ( ) 1
(19)6. Numerical Results
In this section, we will present a numerical investigation of the maximum likelihood estimation for the parameters of and.
We need to estimate the two parameters and by using the maximum likelihood method. So, we will need to solve the three non-linear equations of
logarithm likelihood function (8) and (9) simultaneously using Newton-Raphson method .The iterative technique, can be applied as follows:
m m m m
x
C
A
x
1
1 where and 2 2 2 2 2 2 ln ln ln ln m m m m m m L L L L C
Assuming initial values for each of and, the Newton-Raphson iterative
procedure is continued until either the number of iterations will be ( 200 ) or when |Xm – Xm+1 | < 5 10-5 .
In the following table, the estimates of unknown parameters, the relative bias which is the absolute difference between the estimated parameter and its true value divided by its true value.
-ˆ Bais Re 0 0
ltiveAnd the mean square error (MSE) which is the mean square of the difference between the estimated parameter are presented for all the estimated parameters considering different initial points of the parameters.
ˆ M 2 0 N SE
where N is the number of experiments carry out . m m m m m m m m m L L A x x
ln ln , ˆ ˆ , ˆ ˆ 1 1 1Table (1)
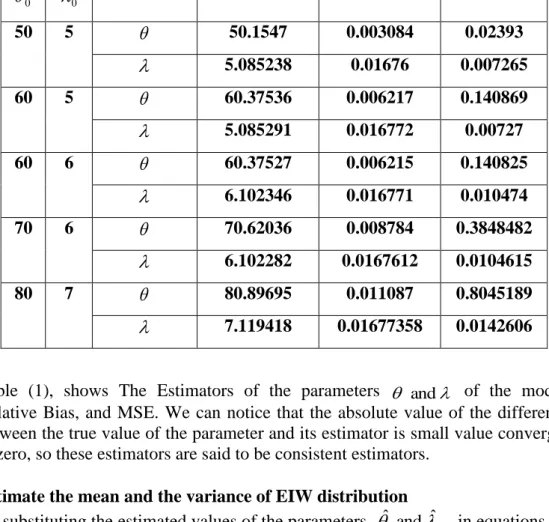
Estimators for parameters of EIW distribution, Relative Bias and MSE MSE Relative Bias Estimator Parameters 0 0 0.02393 0.003084 50.1547 5 50 0.007265 0.01676 5.085238 0.140869 0.006217 60.37536 5 60 0.00727 0.016772 5.085291 0.140825 0.006215 60.37527 6 60 0.010474 0.016771 6.102346 0.3848482 0.008784 70.62036 6 70 0.0104615 0.0167612 6.102282 0.8045189 0.011087 80.89695 7 80 0.0142606 0.01677358 7.119418
Table (1), shows The Estimators of the parameters and of the model, Relative Bias, and MSE. We can notice that the absolute value of the difference between the true value of the parameter and its estimator is small value converges to zero, so these estimators are said to be consistent estimators.
Estimate the mean and the variance of EIW distribution
By substituting the estimated values of the parameters ˆ andˆ in equations (4) and (5), we can get the mean and the variance of EIW distribution as shown in Table (2):
Table (2)
The estimated mean and variance of EIW distribution
ˆ ˆ E(x) ( 2) x E V(x) 50.1547 5.085238 2.26264 5.60568 0.486147 60.37536 5.085291 2.34661 6.029741 0.5229219 60.37527 6.102346 2.013053 4.382492 0.3301104 70.62036 6.102282 2.065445 4.613583 0.3475178 80.89695 7.119418 1.881189 3.798702 0.2598307
From Table (2), we can notice there is direct relationship between the value of ˆ and the value of the mean and the variance of distribution. Also, there is inverse relationship between the value of ˆ and the value of the mean and the variance of distribution.
Estimation the mean and the variance of Aggregate losses distribution:
When the annual frequency of losses from a portfolio follows a Poisson distribution with parameter 8 by substituting in equations (15) and (16), or the Negative Binomial distribution with parameters r 10 and p0.6 by substituting in equations (17) and (18) in table (3) as follows:
Table (3)
Estimation the mean and the variance of Aggregate losses distribution
Concluding remarks:
In this study, we address the exponentaited inverted weubil distribution issue and its empirical application of aggregate losses. By testing the tail of the EIW distribution, we find it has heavy tail. The maximum likelihood method was applied for estimating the parameters of distribution. Under collective risk model, we estimate the mean and the variance of the aggregate losses distribution where the frequency distribution for claim counts is Poisson or Negative Binomial. If we identify the aggregate losses distribution, we can depend on it to ratemaking, arrangement for stop of loss reinsurance and estimate the needed loss reserve.
ˆ
ˆ Poisson distribution Negative Binomial distribution ) (s E V(s) E(s) V(s) 50.1547 5.085238 18.1011 44.84544 33.93958 199.2747 60.37536 5.085291 18.77309 48.23793 35.19992 214.3496 60.37527 6.102346 16.10442 35.05993 30.19579 156.916 70.62036 6.102282 16.52356 36.90866 30.98168 165.1902 80.89695 7.119418 15.04951 30.38961 28.21783 136.6051
References
[1] A. Aljuaid, Estimating the Parameters of an Exponentiated Inverted Weibull Distribution under Type-II Censoring, Applied Mathematical Sciences, 7 (2013), 35, 1721 – 1736.
[2] A. B. Bortoluzzo, D. P. Claro, M. A. Caetano and R. Artes, Estimating Claim Size and Probability in the Auto-insurance Industry: the Zero adjusted Inverse Gaussian (ZAIG) Distribution, Insper Working Paper WPE: 175 (2009).
[3] M. B. Finan M. B., An Introductory Guide in the Construction of Actuarial Models, Arkansas Tech University, 2014.
[4] A. Flaih, H. Elsalloukh, E. Mendi and M. Milanova. The Exponentiated Inverted Weibull Distribution, Applied Mathematics & Information Sciences, 6 (2012), 2 , 167 - 171.
[5] M. Gauger and M. Hosking, Construction of Actuarial Models, Bpp Professional Education, Inc, (2008).
[6] A. S. Hassan, On the Optimal Design of Failure Step-Stress Partially Accelerated Life Tests for Exponentiated Inverted Weibull with Censoring, Australian Journal of Basic and Applied Sciences, 7 (2013), 1, 97 - 104.
[7] A. Hassan, A. Marwa ,H. Zaher and E. Elsherpiny, Comparison of Estimators for Exponentiated Inverted Weibull Distribution Based on Grouped Data, Int. Journal of Engineering Research and Applications, 4 (2014), 4, 77 - 90. [8] Heckman, Philip E. Meyers, Glenn G. (1983), "The Calculation of Aggregate Loss Distributions from Claim Severity and Claim Count Distributions", Proceedings of the Casualty Actuarial Society Casualty Actuarial Society - Arlington, Virginia 1983: LXX 22 - 61.
[9] Papush D. E., Pateik, G. S. and Podgaits F., (2001), "Approximations of the aggregate distributions", CAS Forum, pp. 175 - 186.
[10] Robertson John, (1992), "The Computation of Aggregation loss distributions", PCAS, pp. 57 - 133.
[11] Shevchenko P. V., (2010), "Calculation of aggregate loss distributions", The Journal of Operational Risk 5 (2), pp. 3 - 40.
[12] Venter G. (1983), "Transformed Beta and Gamma distributions and the aggregate losses" PCAS, LXX, pp. 156 – 193.
[13] Vilar J., Cao R., Ausín M. C. and C. González-Fragueiro C., (2008), "Nonparametric analysis of aggregate loss models", 2nd International Workshop on Computational and Financial Econometrics (CFE'08), Neuchatel (Suiza), 19 a 21 de junio de 2008.