Approximation Error Based Suitable
Domain Search for Fractal Image
Compression
VIJAYSHRI CHAURASIA
Research Scholar
Electronics and Communication Engg. Dept Maulana Azad National Institute of Technology
AJAY SOMKUWAR
Associate Professor
Electronics and Communication Engg. Dept Maulana Azad National Institute of Technology
Abstract
Fractal Image compression is a very advantageous technique in the field of image compression. The coding phase of this technique is very time consuming because of computational expenses of suitable domain search. In this paper we have proposed an approximation error based speed-up technique with the use of feature extraction. Proposed scheme reduces the number of range-domain comparisons with significant amount and gives improved time performance. Key words: - Feature extraction, feature vector, domain block, range block, suitable domain search.
1. Introduction
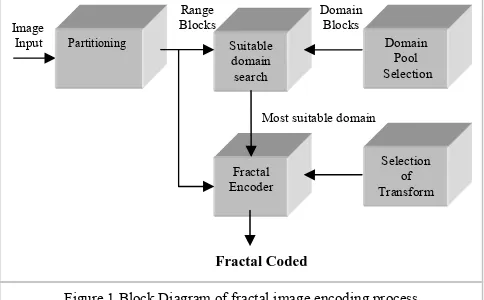
Fractal image compression is based on fractals rather then pixels. M. Barnsley introduced the fundamental principle of fractal image compression in 1988 [2]. Fractal image compression is also called as fractal image encoding because compressed image is represented by contractive transforms [1], [2], [10] and mathematical functions. These transforms are composed of the union of a number of affline mappings on the entire image, known as iterated function system (IFS) [1], [2], [8]. A.E. Jacquin gave first publication on Fractal image compression with partitioned IFS (PIFS) in 1990 [1], [4], [5]. In Jacquin’s method the image is partitioned in sub images called as ‘Range blocks’ and PIFS are applied on sub-images, rather than the entire image. Locating the range blocks on their respective position in image itself forms the entire image. Temporary images used to form range blocks are known as domain blocks.
Figure 1 shows the whole process of fractal image encoding. In any Fractal compression system the first image is partitioned to form of range blocks [9]. Then domain blocks are selected [9]. This choice depends on the type of partition scheme used. The domain pool in fractal encoding is similar to the codebook in vector quantization (VQ) [13], referred as virtual codebook or domain codebook [5]. Then set of transformation are selected which are applied on domain blocks to form range blocks and determines the convergence properties [1], [2] of decoding.
Domain Pool Selection
Selection of Transform Image
Input
Fractal Coded Partitioning Suitable
domain search
Fractal Encoder
Most suitable domain Range
Blocks Domain Blocks
Searching of suitable candidate from all available domain blocks for any particular range block, is computationally very expensive. This computational requirement is the biggest limitation of fractal encoding. A wide variety of techniques have been proposed to fasten the process [6], [9], [11]. A.E. Jacquin gave basic approach for suitable domain search in 1990 [3]. These approaches are addressed as Speed-up-Techniques for fractal image compression and broadly classified as; Domain Classification Based Methods and Feature Vector Based Methods.
The remainder of the paper is organized as follows: Section (2) gives a proposed technique to improve time performance of suitable domain search. Section (3) describes its implementation; Section (4) illustrates the experimental results. Finally conclusion is made in Section (5).
2. Proposed Algorithm
The technique proposed in this paper is based on feature extraction [12]. In this scheme whole process of suitable domain search is based on approximation error. Firstly the image is partitioned in sub-images to form range blocks. Then domain blocks are selected with the double size as that of range blocks. An average block (Ā) is computed, which is equal to the average of all range blocks (r), then a few number of features (mean, variance, skewness, kurtosis) of image blocks are extracted and feature vector (f [m, v, s, ku]) for range, domain and average blocks are formed. Further operations of desired task are performed on these feature vectors. The range-domain comparisons are done in two parts; the domain and range feature vectors are compared with average feature vector separately.
The mean value of image gives the measure of average greylevel of image (m), standard deviation (v) defines the dispersion of its greylevel from mean. Skewness (s) describes existence of symmetry/asymmetry from the normal distribution in image. Skewness come in the form of negative skewness or positive skewness, depending on whether data points are skewed to the left (negative skew) or to the right (positive skew) of the data average. Kurtosis (ku) characterizes the relative peakedness or flatness of a distribution compared to the normal distribution. Positive kurtosis indicates a relatively peaked distribution where as negative kurtosis indicates a relatively flat distribution of greylevels in the image [14]. These features are computed with the use of histogram.
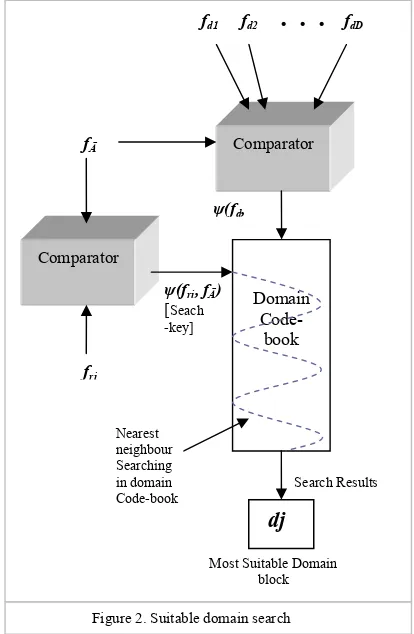
Secondly domain feature vectors (fd) are compared with average feature vector (fĀ), difference between these vectors is computed, which is equal to the Euclidian distance [15] between the vectors. This set of error is stored as an array and called as domain code-book, then range feature vector (fri) corresponding to the ith range block is compared
with average feature vector (fĀ) and Euclidian distance between them is calculated. This error value is used as search key for nearest neighbor search [7] which is applied in domain code-book. The domain block corresponding to the
Comparator fd1 fd2
. . .
fdDComparator fĀ
fri
Domain
Code-book
ψ(fd,
ψ(fri, fĀ)
[Seach -key]
dj
Nearest neighbour Searching in domain Code-book
Most Suitable Domain block
Figure 2. Suitable domain search
nearest error value shows maximum similarity with the particular (ith) range block and assigned to it for encoding.
Figure 2, represents the process of suitable domain search in domain code-book. This search process is repeated for each range block. In this way the suitable domain block corresponding to every range block is searched.
3. Implementation
The proposed algorithm is implemented using MATLABTM version 7.5. Coding simulations have been tested on
five 8-bit/pixel greyscale JPEG images of size 256x256, as shown in figure 3.
(a) (b) (c) (d) (e)
Figure. 3. Greyscale test images of 8bits/pixel of size 256x256: (a) Lenna, (b) cat, (c) Peppers, (d) Retina and (e) Terrain
In pre-processing, the image to be encoded is partitioned in fixed size non-overlapping rectangular parts to form range blocks. This is done to increase the amount of self-symmetry. We have used the range blocks of four sizes 32x32, 16x16, 8x8 and 4x4. average block is also have same size as rang blocks. The domain blocks are formed by partitioning the image in overlapped blocks of double size as that of range blocks.
Algorithm
Compute the average image (Ā), equal to the average of all range images.
R
r
A
Ri i
/
1
(7) Extract features (Mean (m), Standard deviation (v), Skewness (s), Kurtosis (ku) of domain, range and average images.
Represent images as feature vectors (f), Range feature vector = fr
Domain feature vector = fd
Average feature vector = fĀ
Calculate Euclidian distance [15] (ψ(fd , fĀ)) for all domain blocks.
2 2 2 2
( , )f fdi A (mA mdi) (vA vdi) (sA sdi) (kuA kudi)
(8)
Store these errors.
Calculate Euclidian distance (ψ(fri , fĀ)).
2 2 2 2
( , )
f f
ri A(
m m
A ri) (
v v
A ri) (
s
As
ri) (
ku
Aku
ri)
(9) Search nearest value of this error in stored error.
Assign domain block corresponding to the nearest error value to the desired range block.
4. Results and Discussion
The speed-up technique proposed in this paper reported drastic reduction in time requirement of suitable domain search. In conventional method every range block is compared with all the domain blocks and approximation error between them is stored for each range block. Along with this search for least error is in done for every range block. Whereas in proposed method domain feature vectors are compared with average feature vector in domain code-book formation and each range feature vector is compared once with average feature vector to form search key. We have saved the approximation error between average and domain feature vectors and the searching is done with deferent search keys in the same error space.
Let the selected size of range blocks is SxS then the number of range blocks (R) and number of domain blocks are given by equation 10 and 11.
2
(256 / )
R S (10)
2 ( 1) ( 1)( 1)
Where
P
256 / 2
S
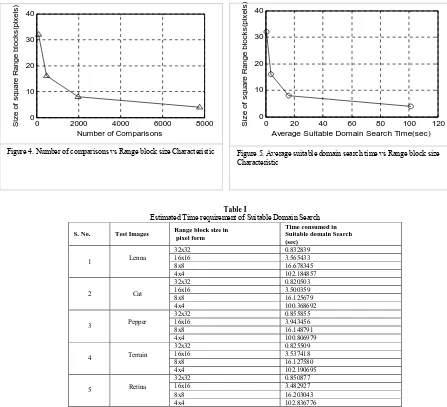
(12)In conventional suitable domain search comparisons are to be done RxD times. Approximation error to be saved and minimum value is to be searched R times. In proposed method number of comparisons are reduces to R+D, approximation errors are saved only once and nearest value is searched R times. Comparisons are done of the basis of feature vectors rather than images, it reduces complexity of computation. We have implemented the algorithm on five different images for four sizes of range blocks and time consumption of suitable domain search is computed. Table I represents the time consumed in suitable domain search for different test images. As we can see the time expenditure in search process for all the five images lies within 2 percent; it shows that the time expense is independent of complexity and depends on the size of range partitions.
The variations of number of range-domain comparisons and required suitable domain search time are shown in figure 4 and 5 respectively. As we reduce the size of range size the numbers of comparisons are increases. This increase results as increase in time utilization of suitable domain search.
0 2000 4000 6000 8000
0 10 20 30 40 S iz e of s q uar e R ange bl o cks( p ixe ls)
Number of Comparisons
0 20 40 60 80 100 120
0 10 20 30 40 S iz e of s q u a re R ang e b loc k s (pi x el s )
Average Suitable Domain Search Time(sec)
Table I
Estimated Time requirement of Suitable Domain Search
S. No. Test Images Range block size in pixel form
Time consumed in Suitable domain Search (sec)
1 Lenna
32x32 0.832839 16x16 3.565433 8x8 16.678345 4x4 102.184857
2 Cat
32x32 0.820503 16x16 3.500359 8x8 16.125679 4x4 100.368692
3 Pepper
32x32 0.855855 16x16 3.943456 8x8 16.148791 4x4 100.806979
4 Terrain
32x32 0.825509 16x16 3.537418 8x8 16.127580 4x4 102.190695
5 Retina
32x32 0.850877 16x16 3.482927 8x8 16.203043 4x4 102.836776
5. Conclusion
Proposed technique provides noteworthy reduction in the amount of computations as well as complexity of suitable domain search. Approximation error is computed on the basis of vectors instead of images; hence the total time requirement of the desired process is reduced significantly. The time requirement is independent of complexity and depends on the size of range partitions.
6. References
[1] Y. Fisher, Fractal Image Compression: Theory and Application. New York: Springer-Verlag, 1994. [2] M. Barnsley, Fractals Everywhere. New York: Academic, 1988.
[3] A.E. Jacquin, “A novel fractal block-coding technique for digital Images”, ICASSP International Conference on Acoustics, Speech, and Signal
Processing, 1990.
[4] A.E Jaquin, “Image coding based on a fractal theory of iterated contractive image transformation”, IEEE Trans. On Image Processing, vol. 1, No 1, January 1992.
[5] A.E Jaquin, “Fractal image coding: A review”, proceeding of tile IEEE, vol. 81, No.10, October 1993.
[6] R. Distasi, M. Nappi and D. Riccio, “A range/domain approximation error- based approach for fractal image compression”, IEEE Trans. Image processing, vol. 15, no. 1, pp. 89-97, Jan. 2006.
[7] E. Horowitz; S. Sahni, “Fundamentals of Data structure”, Galgotia Booksource, New Delhi, India, 1981.
[8] E.W Jacobs, Y Fisher, and R. D. Boss, “Image compression: A study of iterated transform method”, Signal Processing, Vol. 29, No 3, pp. 251-263, December 1992.
[9] B. Wohlberg and G.D. Jager, “A review of fractal image coding literature”, ”, IEEE Trans. on Image Processing, vol. 8, no. 12, pp. 1716-1729, Dec. 1999.
[10] S. Weistead, Fractal and Wavelet Image Compression Technique: PHI, India, 2005.
[11] Polvere, M.; Nappi, M, “Speed-up in fractal image coding: comparison of methods”, IEEE Trans Image Processing. Vol. 9 No. 6, pp. 1002-1009, June 2000.
[12] Mark S. Nixon, Alberto S. Aguado, “Feature extraction and image processing”, second edition, Academic Press, Oxford, 2002.
[13] B. Ramarurthi and A. Gersho, “Classified vector quantization of images”, IEEE Trans. on Communications, vol. COM-34, No 11, Nov 1986. [14] D.N. Elhance; Veena Elhance: B.M. Aggrawal, “Fundamentals of Statistics”, Kitab Mahal, India, 2000.