RECOGNITION OF SPEECH SIGNALS:
AN EXPERIMENTAL COMPARISON OF
LINEAR PREDICTIVE CODING AND
DISCRETE WAVELET TRANSFORMS
SONIA SUNNY*
Department of Computer Science, Cochin University of Science and Technology
Kochi-682022, India
DAVID PETER S
School of Engineering,
Cochin University of Science and Technology Kochi-682022, India
[email protected] K POULOSE JACOB Department of Computer Science, Cochin University of Science and Technology
Kochi-682022, India [email protected] Abstract:
In this paper, a speech recognition system is developed using two different feature extraction techniques and a comparative study is carried out for recognizing speaker independent spoken isolated words. First one is a hybrid approach with Linear predictive Coding (LPC) and Artificial Neural Networks (ANN) and the second method uses a combination of Discrete Wavelet Transforms (DWT) and Artificial Neural Networks. Voice signals are sampled directly from the microphone and then they are processed using these two techniques for extracting the features. Words from Malayalam, one of the four major Dravidian languages of southern India are chosen for recognition. Training, testing and pattern recognition are performed using Artificial Neural Networks. The proposed method is implemented for 50 speakers uttering 20 isolated words each. Both the methods produce good recognition accuracy. But discrete wavelet transforms are found to be more suitable for recognizing speech because of their multi-resolution characteristics and efficient time frequency localizations. Keywords: Speech Recognition; Feature Extraction; Linear Predictive Coding; Discrete Wavelet Transforms; Neural Networks.
1. Introduction
and recognition are intensive areas of research due to the wide variety of applications like mobile applications, weather forecasting, agriculture, healthcare, automatic translation, robotics, video games, transcription etc [4].
Though technological advances have made much progress in the recognition of complex speech patterns, much more research and development is needed in this field especially in the area of speaker independent speech recognition. Different speech processing techniques and feature extraction methods are available. Selection of the feature extraction technique plays an important role in the recognition accuracy, since it is the main criteria for a good speech recognition system. Among the various feature extraction methods, two techniques namely linear predictive coding and discrete wavelet transforms are used here and a comparative study of these is performed here. LPC is a digital method for encoding an analog signal in which a particular value is predicted by a linear function of the past values of the signal and DWT decomposes a signal into a set of basic functions called wavelets. Multi layer perceptron architecture is used for classification and recognition.
2. Methodology
There are two fundamental operations in a speech recognition system namely signal modeling and pattern matching [5]. Feature extraction is an important part of signal modeling where speech signal is converted into a set of parameters called feature vectors. Pattern matching is the task of finding parameter set from memory which closely matches the parameter set obtained from the input speech signal also known as classification. In this work, we have divided the speech recognition process into three stages. The first stage is the creation of the database. Next one is the feature extraction stage wherein short time temporal or spectral parameters of speech signals are extracted. Minimizing the number of parameters in the speech model increases the speed of speech processing. The third module is the classification stage wherein the derived parameters are compared with stored reference parameters and decisions are made based on some kind of a minimum distortion rule. Among these three stages, feature extraction is a key, because better feature is necessary for improving recognition rate. The paper is organized as follows. The isolated spoken words database is explained in section 3. In section 4, the theory of various feature extraction techniques namely linear predictive coding and discrete wavelet transforms are reviewed. Section 5 describes the pattern classification stage using artificial neural networks. Section 6 presents the detailed analysis of the experiments done and the results obtained. Conclusions are given in the last section.
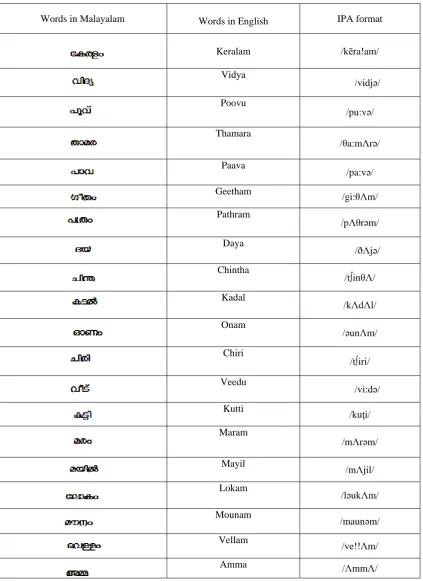
3. Words Database in Malayalam
Table I. Words Database And Their IPA Format
Words in Malayalam Words in English IPA format
Keralam /kēra!am/
Vidya
/vidjə/ Poovu
/pu:və/ Thamara
/θa:mΛrə/ Paava
/pa:və/ Geetham
/gi:θΛm/ Pathram
/pΛθrəm/ Daya
/ðΛjə/ Chintha
/t∫inθΛ/ Kadal
/kΛdΛl/ Onam
/əunΛm/ Chiri
/t∫iri/ Veedu
/vi:də/ Kutti
/kuţi/ Maram
/mΛrəm/ Mayil
/mΛjil/ Lokam
/ləukΛm/ Mounam
/maunəm/ Vellam
/ve!!Λm/
Amma /ΛmmΛ/
4. Feature Extraction Techniques Used
4.1 Linear predictive coding
LPC is one of the most powerful methods used in audio and speech signal processing which extracts speech parameters like pitch formants and spectra. It is a powerful technique used for feature extraction purpose of speech signals since it characterizes the vocal tract well. It provides a good model of the speech signal and LPC front-end processing has been used in a large number of speech recognition accuracies [6]. LPC is a relatively efficient method for computation since it allows encoding of good quality speech at a low bit rate and it also provides extremely accurate estimates of speech parameters. The LPC analysis estimates the vocal tract resonance from a signal’s waveform, removing their effects from the speech signal in order to get the source signal. The most important aspect of LPC is the linear predictive filter which allows the value of the next sample to be determined by a linear combination of previous samples [7]. At a particular time, k, the speech sample s(k) is represented as a linear sum of the n previous samples. This can be represented by the equation
S(k) = ak-1 s(k-1)+ ak-2 s(k-2) +……+ak-n s(k-n) (1)
Where S (k) is the value of the signal at time (k). The coefficients aki are called the Linear Predictive Coding Coefficients. The coefficients can be analyzed to provide insight to the nature of the signal. Another important feature of LPC is that it minimizes the sum of the squared differences between the original speech and estimated speech signal over a finite duration. It produces a unique set of predictor coefficients which are normally estimated with every frame which is of usually 20 ms to 50 ms long. The predictor coefficients are represented by ak. Another important parameter is the gain (G). The transfer function of the time-varying digital filter is given by equation 2.
Summation is computed starting at k = 1 up to p. Here LPC 10 is used. This means that only the first 10 coefficient are transmitted to the LPC synthesizer. Auto correlation formulation is used to compute the coefficients.
4.2. Discrete Wavelet Transforms
A wavelet transform transforms the signal under investigation into a representation which is more useful. Wavelet transforms were introduced to address the problems associated with non-stationary signals like speech since it provides time frequency localizations [8]. In discrete wavelet transform, the scale and position are changed in discrete steps [9]. The Discrete Wavelet Transform is a special case of the wavelet transform that provides a compact representation of a signal in time and frequency that can be computed efficiently. They are well suitable for processing non-stationary signals like speech because of its multi- resolutional, multi-scale analysis characteristics. The main advantage of the wavelet transforms is that it has a varying window size, being broad at low frequencies and narrow at high frequencies, thus leading to an optimal time–frequency resolution in all frequency ranges [10]. The Discrete Wavelet Transform is defined by the following equation
W (j, K) = ΣjΣkX (k) 2-j/2Ψ (2-jn-k) (3)
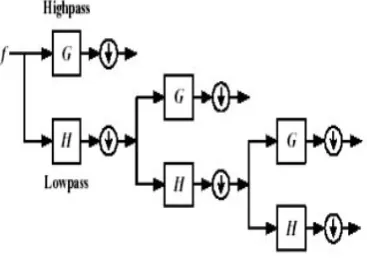
Where Ψ (t) is the basic analyzing function called the mother wavelet. Other functions are derived from this mother wavelet by translation and dilation operations. In DWT, the original signal passes through two complementary filters, namely low-pass and high-pass filters, and emerges as two signals, called approximation coefficients and detail coefficients [11]. In speech signals, low frequency components known as the approximations h[n] are of greater importance than high frequency signals known as the details g[n] as the low frequency components characterize a signal more than its high frequency components [12]. The successive high pass and low pass filtering of the signal can be obtained by the following equations.
Yhigh[k]= Σnx[n]g[2k-n] (4)
Where Y high (detail coefficients) and Ylow (approximation coefficients) are the outputs of the high pass and low
pass filters obtained by sub sampling by 2. The filtering is continued until the desired level is reached according to Mallat algorithm [13]. The discrete wavelet decomposition tree is shown in figure 1.
Fig. 1. DWT decomposition tree
5. Classification Using Neural Networks
Classification is one of the most commonly used decision making task among human beings. Speech recognition is basically a pattern recognition problem. During classification stage, the input data is trained using information relating to known patterns and then they are tested using the test data set. Pattern recognition is becoming increasingly important in the age of automation and information handling and retrieval. Since neural networks are good at pattern recognition, many early researchers applied neural networks for speech pattern recognition. In this study also, we have used neural networks as the classifier. Neural networks can perform pattern recognition; handle incomplete data and variability well. The increasing acceptability of neural network models to solve pattern recognition problems has been mainly due to its low dependence on domain-specific knowledge relative to model-based and rule-based approaches and due to the availability of efficient learning algorithms for users to implement [14].
5.1 Artificial neural networks
ANNs have been applied to an increasing number of real-world problems of considerable complexity. An artificial neural network is an information processing paradigm consisting of a number of simple processing units or nodes called neurons that is inspired by the way biological nervous systems, such as the brain, process information. It can store experimental knowledge and make it available for use. Each neuron accepts a weighted set of inputs and produces an output [15]. Neural Networks have become a very important method for pattern recognition because of their ability to deal with uncertain, fuzzy, or insufficient data. Algorithms based on Neural Networks are well suitable for addressing speech recognition tasks. Inspired by the human brain, neural network models attempt to use some organizational principles such as learning, generalization, adaptivity, fault tolerance etc. [16].
6. Experiments and Results
In the LPC method, the input signals are broken into blocks or frames. The 8000 samples in each second of speech signal are broken in to 240 sample segments. That is, each frame represents around 33 milliseconds of the speech signal. The signal is passed through a low pass filter with bandwidth 1 KHz to split up the signal in to voiced and unvoiced sound. The first ten LPC coefficients are used here. MLP architecture is used for classification and recognition purpose.
In the case of a DWT, a variety of wavelets are available for signal analysis and the choice of a particular wavelet depends on the type of application. Moreover, the choice of the wavelet family and the mother wavelet plays an important role in the recognition accuracy. The most popular wavelets that represent foundations of digital signal processing called the Daubechies wavelets are used here. Among the Daubechies family of wavelets, the db4 type of mother wavelet is used for feature extraction purpose since it gives better results [19]. The speech samples in the database are successively decomposed into approximation and detailed coefficients. Less frequency components from level 12 is used to create the feature vectors for each spoken word. The number of feature vectors obtained is 12. These feature vectors are given to neural networks for classification. Here we have divided the database into three. 70% of the data is used for training, 15% for validation and 15% for testing. MLP architecture is used for the classification purpose.
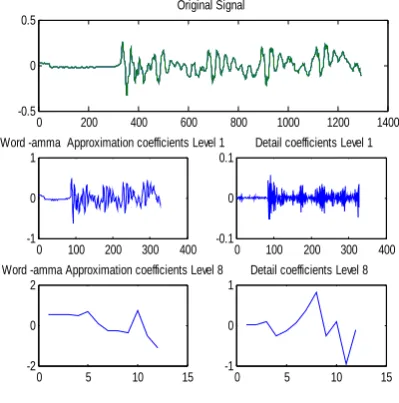
The original signal and the first and twelfth level approximation and detail coefficients of three spoken words thamara, amma and maram obtained using DWT are shown in figure 2, figure 3 and figure 4.
0 200 400 600 800 1000 1200 1400 -1
0 1
Original Signal
0 100 200 300 400 -2
0 2
Word -thamara Approximation coefficients Level 1
0 100 200 300 400 -0.5
0 0.5
Detail coefficients Level 1
0 5 10 15
-5 0 5
Word -thamara Approximation coefficients Level 8
0 5 10 15
-2 0 2
Detail coefficients Level 8
0 200 400 600 800 1000 1200 1400
-0.5 0 0.5
Original Signal
0 100 200 300 400 -1
0 1
Word -amma Approximation coefficients Level 1
0 100 200 300 400 -0.1
0 0.1
Detail coefficients Level 1
0 5 10 15
-2 0 2
Word -amma Approximation coefficients Level 8
0 5 10 15
-1 0 1
Detail coefficients Level 8
Fig. 3. Decomposition of word amma using DWT
0 200 400 600 800 1000 1200 1400
-0.5 0 0.5
Original Signal
0 100 200 300 400
-1 0 1
Word -maram Approximation coefficients Level 1
0 100 200 300 400
-0.1 0 0.1
Detail coefficients Level 1
0 5 10 15
-5 0 5
Word -maram Approximation coefficients Level 8
0 5 10 15
-1 0 1
Detail coefficients Level 8
Fig. 4 Decomposition of word maram using DWT
After classification using neural networks, both the feature extraction methods give good recognition accuracies. The overall recognition accuracies obtained using LPC and DWT is shown in table 2.
Table II. Comparison of results
Feature Extraction Method Recognition Accuracy (%)
LPC 81.20
DWT 90.00
7. Conclusions and Future Work
In this work, a speech recognition system is designed for isolated spoken words in Malayalam. A comparative study of two major feature extraction techniques such as linear predictive coding and discrete wavelet transforms is performed here. These methods are combined with neural networks for classification purpose. The performance of both these techniques are tested and evaluated. Both techniques are found to be efficient in recognizing speech. The accuracy rate obtained by using wavelet based technique is found to be more than LPC based method. The computational complexity and the feature vector size is successfully reduced to a great extent by using discrete wavelet transforms. Thus a wavelet transform is an elegant tool for the analysis of non-stationary signals like speech. The experiment results show that this hybrid architecture using discrete wavelet transforms and neural networks could effectively extract the features from the speech signal for automatic speech recognition. For future work, the vocabulary size can be increased to obtain more recognition accuracy. Though the neural network classifier which is used in this experiment provides good accuracies, alternate classifiers like Support Vector Machines, Genetic algorithms, Fuzzy set approaches etc. can also be used and a comparative study of these can be performed as an extension of this study.
Acknowledgments
I wish to express my sincere gratitude to all who have contributed throughout the course of this work
.
References
[1] Joseph P Campbell, JR; (1997): Speaker Recognition: A Tutorial, Proceedings of the IEEE, Vol. 85, No. 9.
[2] Lawrence R., (1997): Applications of Speech Recognition in the Area of Telecommunications, Proceedings of IEEE Workshop on Automatic Speech Recognition and Understanding, pp. 501-510.
[3] recognition.http://www.learnartificialneuralnetworks.com/speechrecognition.html
[4] Kuldeep Kumar, R. K. Aggarwal, (2011): Hindi Speech Recognition System Using Htk, International Journal of Computing and Business Research, , Volume 2, Issue 2.
[5] Picone J.W. (1993): Signal Modelling Technique in Speech Recognition, Proc. of the IEEE, Vol. 81, No.9, pp.1215-1247. [6] Rabiner L., Juang B. H..(1993): Fundamentals of Speech Recognition, Prentice-Hall, Englewood Cliffs, NJ.
[7] Jeremy Bradbury, (2000): Linear Predictive Coding,.
[8] S. Mallat. (1999): A wavelet Tour of Signal Processing, Academic Press, San Diego.
[9] K. P Soman, K.I Ramachandran, N.G Resmi. (2010): Insight into Wavelets From Theory to Practice, PHI Learning Private Ltd, New Delhi.
[10] Elif Derya Ubeyil. (2009): Combined Neural Network Model Employing Wavelet Coefficients for ECG Signals Classification, Digital signal Processing, Vol 19, pp.297-308.
[11] S. Chan Woo, C.Peng Lin, R. Osman. (2001): Development of a Speaker Recognition System using Wavelets and Artificial Neural Networks, Proceedings of 2001 International Symposium on Intelligent Multimedia, Video and Speech processing, pp. 413-416. [12] S. Kadambe, P. Srinivasan (1994): Application of Adaptive Wavelets for Speech, Optical Engineering , Vol 33(7), pp . 2204-2211. [13] Fecit Science and Technology Production Research Center, (2003): Wavelet Analysis and Application by MATLAB6.5 [M],
Electronics Industrial Press, Beijing.
[14] Y. Hao, X. Zhu (2000): A New Feature in Speech Recognition based on Wavelet Transform, Proc. IEEE 5th Inter. Conf. on Signal Processing,vol 3.
[15] Freeman J. A, Skapura D. M.(2006): Neural Networks Algorithm, Application and Programming Techniques, Pearson Education. [16] Economou K., Lymberopoulos D. (1999): A New Perspective in Learning Pattern Generation for Teaching Neural Networks, Volume
12, Issue 4-5, pp. 767-775.
[17] Eiji Mizutani, James W. Demmel, (2003): On Structure-exploiting Trust Region Regularized Nonlinear Least Squares Algorithms for Neural-Network Learning, Neural Networks, Volume 16, Issue 5-6, pp. 745-753.
[18] Anil K. Jain, Robert P.W. Duin, Jianchang Mao, (2000): Statistical Pattern Recognition: A Review, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 22., pp.4-37.