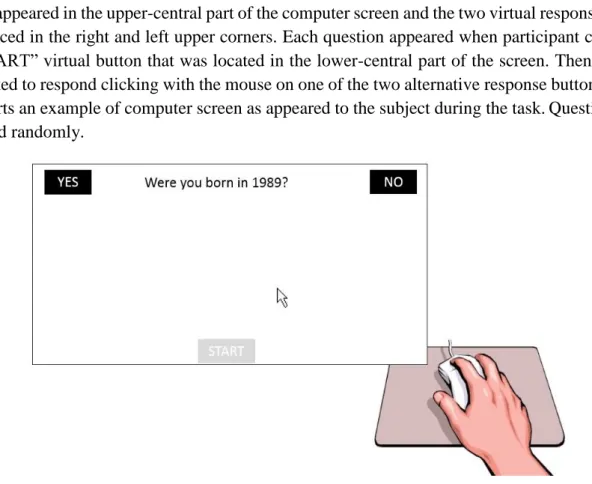
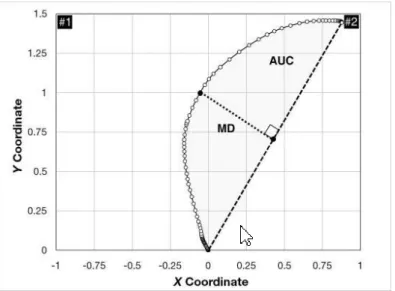
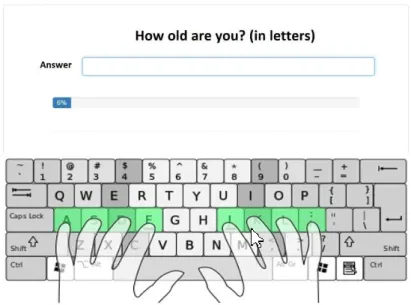
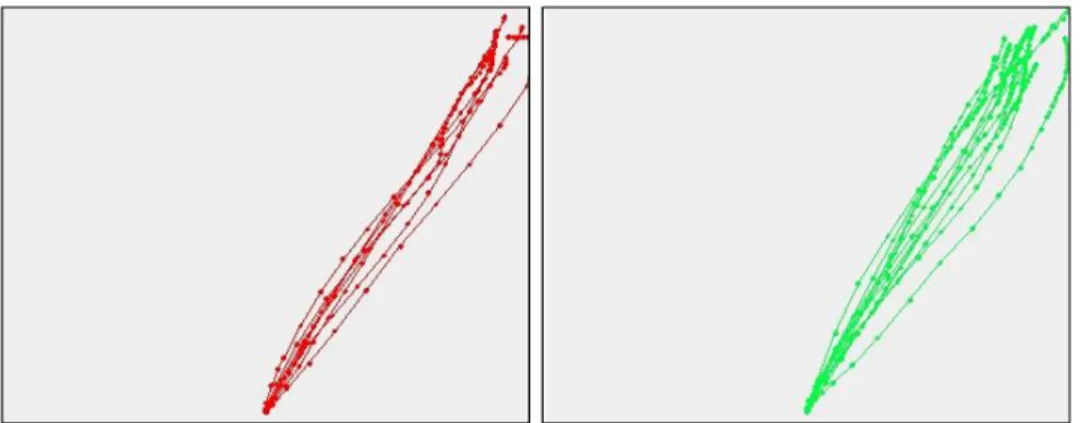
Università degli Studi di Padova Human Inspired Technology Research Centre
PHD COURSE IN BRAIN, MIND AND COMPUTER SCIENCE XXX CYCLE
LIE DETECTION IN THE FUTURE:
THE ONLINE LIE DETECTION VIA HUMAN-COMPUTER INTERACTION
Director: Ch.mo Prof. Giuseppe Sartori
Supervisor: Ch.mo Prof. Giuseppe Sartori
Co-Supervisor: Ch.mo Prof. Mauro Conti
Acknowledgements
First, I am immensely grateful to my supervisor, prof. Giuseppe Sartori, for sharing his pearls of wisdom with me during the course of these three years of research. Thanks for giving me this opportunity and for following my training and progress with passion and interest.
I thank my computer science colleagues, who provided insight and expertise that greatly assisted the research. In particular, Riccardo Spolaor and Qian Qian Li, who collaborated to the development of some experiments, Mirko Polato and Nicolò Navarin for their assistance in machine learning issues. I would also like to show my gratitude to all the bachelor’s and master’s students who gave a contri-bution to the collection of data, which are included in this manuscript (Angelica Bollini, Marta Businaro, Francesca Fugazza, Chiara Galante, Alessandra Guiotto, Sara Marcon, Ilaria Zampieri, Francesca Zecchinato).
Moreover, I thank the reviewers for their comments that, I am sure, will greatly improve this manu-script.
I thank Andrea Zangrossi for his important backup and all people of Sartori’s group that contributed to make enjoyable the work environment.
Then, I’d like to thank my co-supervisor, prof. Mauro Conti, and prof. Luciano Gamberini for their valuable support, as well as all the people that have worked to improve my experience in BMCS PhD course.
Finally, the most special thanks are due to my family and friends that always supported my choices and encouraged me to get on my way.
ii
Abstract
Half the people in the Planet Earth are now on internet, surfing the web, keeping connection with the outside world, using online services and interacting in social networks. However, the spread of internet is going hand in hand with the growing malicious use of it. Creating fake social network profiles, wide spreading fake news, posting fake reviews, identity theft to perpetuate online financial frauds are only few examples. To face these problems, all the big internet companies, like Google and Facebook, are now taking the direction towards the online lie detection research. The present work is a contribution to online deception detection through the study of computer-user interaction. After a brief review of the current lie detection methods, focusing on their advantages and disad-vantages for online application, a series of proof of concept experiments are reported. Experiments were conducted measuring indices deriving from three different tools of human-computer interaction: reaction times on keyboard, keystroke dynamics and mouse dynamics. Two strategies were used to increase liars’ cognitive load and facilitate the observation of distinctive features of deception: unex-pected questions and complex questions. Experiments focused on the deception about identity, as it is a very hot issue and represents a current challenge for companies that provide online services. Participants were asked to respond lying or truth telling to questions that appeared on the computer screen, typing the response, clicking on it with the mouse or pressing one of two alternative keys on keyboard. Data collected from liars and truth-tellers’ responses were analyzed and used to train ma-chine learning classification models. Classification accuracies in distinguishing liars from truth-tell-ers ranged from 80% to 95%, depending on the deceptive task. Results have proved that it is possible to spot liars analyzing their interaction with the computer during the act of lie. In particular, we demonstrated that keystroke dynamics is a very promising tool for covert lie detection and it is easily integrable with the online existing applications. Moreover, we confirmed that the cognitive complex-ity of the deceptive task increases the possibilcomplex-ity to detect deception.
Keywords
Contents
Acknowledgements ... i Abstract ... ii Keywords ... ii Introduction ... 9 1.1 Fake Identities ... 9 1.1.1 Fake profiles ... 10 1.1.2 Fake chatting ... 11 1.1.3 Fake VISA ... 121.1.4 Online banking and other financial services ... 12
1.2 Fake News ... 13 1.3 Fake Reviews ... 14 Related works ... 17 2.1 Linguistic Approach ... 18 2.2 Behavioral Approach ... 20 2.2.1 Mouse tracking ... 22 2.2.2 Keystroke dynamics... 24
2.3 Strategies to Increase Cognitive Load ... 25
2.3.1 Unexpected questions ... 26
2.3.2 Complex questions ... 27
Materials and Methods ... 29
3.1 Participants ... 29
3.2 Experimental Design and Procedures ... 29
3.3 Data Collection ... 29 3.3.1 Reaction times ... 30 3.3.2 Mouse tracking ... 31 3.3.3 Keystroke dynamics... 33 3.4 Data Analysis ... 35 3.4.1 Feature selection ... 35
3.4.2 Descriptive and statistical analysis ... 35
3.4.3 Machine learning models ... 36
Experiments ... 39
4.1 The Detection of Faked Identity with Unexpected Questions and Mouse Dynamics ... 39
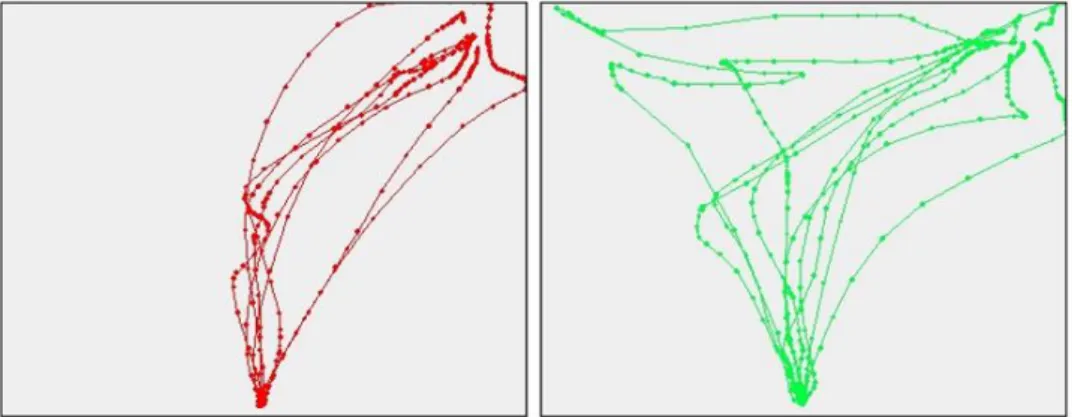
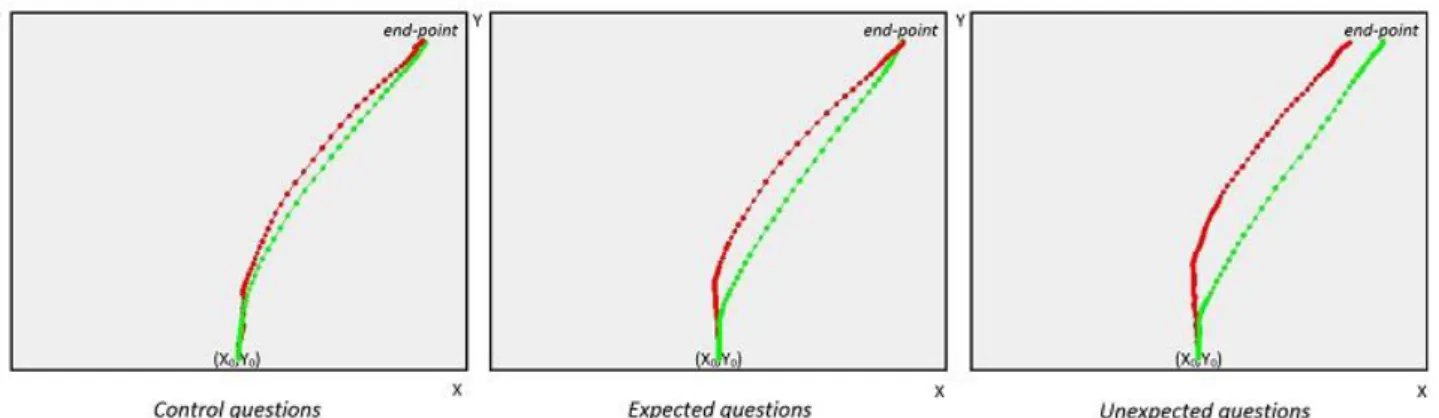
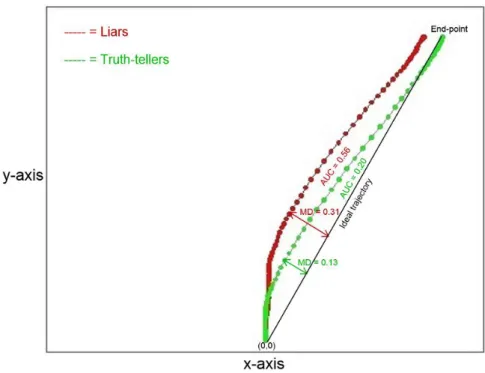
Contents iv 4.1.2 Experimental procedure ... 39 4.1.3 Stimuli ... 40 4.1.4 Collected measures ... 41 4.1.5 Analysis of trajectories ... 42 4.1.6 Feature selection ... 44 4.1.7 Descriptive statistics ... 44
4.1.8 Machine learning models ... 46
4.1.9 Can we detect liars also when they respond truthfully? ... 49
4.1.10 Generalization to different cultures ... 51
4.1.11 The resistance to countermeasures ... 52
4.1.12 The use of changing labels ... 55
4.1.13 The use of negative questions ... 58
4.1.14 Discussion ... 61
4.2 The Detection of Faked Identity with Unexpected Questions and Choice Reaction Time ... 63
4.2.1 Participants ... 63 4.2.2 Experimental procedure ... 63 4.2.3 Stimuli ... 63 4.2.4 Collected measures ... 63 4.2.5 Features selection ... 64 4.2.6 Descriptive statistics ... 65
4.2.7 Machine learning models ... 65
4.2.8 Discussion ... 66
4.3 The Detection of Faked Identity with Unexpected Questions and Keystroke Dynamics ... 67
4.3.1 Participants ... 67 4.3.2 Experimental procedure ... 67 4.3.3 Stimuli ... 67 4.3.4 Collected measures ... 68 4.3.5 Feature selection ... 68 4.3.6 Descriptive statistics ... 69
4.3.7 Machine learning models ... 70
4.3.8 Can we detect liars also when they respond truthfully? ... 71
4.3.9 Analysis on normalized predictors ... 72
4.3.10 Countermeasures and alternative efficient models ... 73
4.3.11 Classification of liars using only data from truth-tellers ... 73
4.3.12 Application of the paradigm to online form ... 74
4.3.13 Discussion ... 76
4.4 The Detection of Faked Identity with Complex Questions and Choice Reaction Time ... 77
4.4.2 Experimental procedure ... 77
4.4.3 Stimuli ... 77
4.4.4 Collected measures ... 78
4.4.5 Descriptive statistics ... 79
4.4.6 Feature selection ... 80
4.4.7 Machine learning models ... 81
4.4.8 Analysis on normalized predictors ... 81
4.4.9 Analysis by stimuli... 82
4.4.10 Discussion ... 83
4.5 The Detection of Faked Identity with Complex Questions and Mouse Dynamics ... 85
4.5.1 Participants ... 85 4.5.2 Experimental procedure ... 85 4.5.3 Stimuli ... 85 4.5.4 Collected measures ... 85 4.5.5 Analysis of trajectories ... 85 4.5.6 Feature selection ... 87 4.5.7 Descriptive statistics ... 87
4.5.8 Machine learning models ... 88
4.5.9 Countermeasures and alternative efficient models ... 88
4.5.10 Discussion ... 89
4.6 The Detection of False Autobiographical Events with Complex Questions and Mouse Dynamics 91 4.6.1 Participants ... 91 4.6.2 Experimental procedure ... 91 4.6.3 Stimuli ... 94 4.6.4 Collected measures ... 95 4.6.5 Analysis of trajectories ... 96 4.6.6 Feature selection ... 97 4.6.7 Descriptive statistics ... 98
4.6.8 Machine learning models ... 100
4.6.9 Discussion ... 100
4.7 Can mouse dynamics and complex questions generalize from a topic to another? ... 102
4.7.1 Detection of liars about autobiographical events using a model about identity ... 103
4.7.2 Detection of liars about identity using a model about autobiographical events ... 103
4.7.3 Discussion ... 104
Conclusion ...105
5.1 Main Results ... 105
5.2 General Conclusions ... 106
Contents vi 5.4 Limitations ... 108 5.5 Future Directions ... 109 References ...111 Annex 1 ...125 Annex 2 ...127 Annex 3 ...131 Annex 4 ...134 Annex 5 ...137
Introduction
The International Telecommunications Union reports that on June 2017 the 51% of the world's population is on internet [1] that corresponds to 3,885,567,619 of users [2]. From 2010 to 2017, the global internet usage has grown by 976.4% and, at the same time, the number of users in social networks has exponentially increased. In June 2017, Facebook counted 2.01 billion monthly active users, whereas in 2010 they just achieved the threshold of 500 million of active people [3]. Five new Facebook profiles are created each second and every 60 seconds 510,000 comments are posted, 293,000 statuses are updated and 136,000 photos are uploaded [4]. A similar increment has been reported also for other socials, such as Twitter, Instagram, Snapchat, YouTube, Pinterest [5], [6].
But are all these activities related to real people and real experiences? The answer is no.
In 2012, in a report for the United States Securities and Exchange Commission, Facebook declared that about the 8.7% of the worldwide active users are actually duplicate or false accounts [7], [8]. During the last year Facebook, as well as Google, have intensified their actions against the fake online news [9]. To guarantee the economic interests of their millions of customers, companies like Amazon, TripAdvisor and Yelp are facing the problem of fake reviews [10]. Moreover, for a large number of others online services, such as e-commerce and online banking, the verification of the truthfulness of the information provided by the users is currently a key issue [11].
In short, the problem of online deception and its detection seems to be real and all the big companies that provide online services are moving in this direction. In the next paragraphs, a review of the most relevant issue about online deception is presented alongside their consequences for society and econ-omy.
1.1
Fake Identities
In the current historical and cultural framework, the identity verification is an increasingly urgent problem [12]. Faked identities are used for a wide range of criminal purposes, both in the real word and in the internet environment. Oversimplifying, a faked identity may be defined as an alteration of demographic information in legal documents. For example, terrorists use false passports to enter Eu-ropean and US borders [13], [14], making this a big deal for physical security.
Concerning online security, the scenario of the fake identities becomes more intricate. Three main specific issues can be identified: the identity alteration, the identity theft and the identity fraud. The first consists in the modification of one ore more user’s demographic information, which is really common in social networks profiles [15] and it is not clearly legally regulated. For example, a man who declared to be a woman, a boy who claims to be younger than he actually is or an underage girl who says to be adult. Identity alteration can be done for different reasons, but in most cases it has
Introduction
10
social purposes, such as attracting the attention [16] or the sympathy of the other people (e.g., groom-ing) [17] or avoiding the direct exposure to shameful situations [18]. To support the creation of fake accounts there are some online services, which automatically generate completely fake profiles, in-cluding address, employment, tracking numbers and financial information [19]. Completely invented accounts, especially fake email accounts, are also commonly used for economic aims and scams, such as spamming and phishing.
Conversely, the identity theft consists in the deliberate use of someone else’s identity [20] and in most States it is punished with compensation or prison [21]. Motivations are usually social (e.g., pranks, cyberbullying) or related to business (e.g., to increase the visibility of posts and fan pages, manipulate votes or the number of visits, junk emails or advertisement inducing customers to pay for clicks) [22]. Finally, identity fraud is a crime where one person uses another person’s personal data, without au-thorization, to deceive or defraud someone else [23]. Identity fraud can occur with or without identity theft, such as in the case where the fraudster has been given someone's identity information for other reasons but uses it to commit fraud. Motivations for online identity frauds are mainly financial crimes, such as open a credit card account without permission or stolen online banking credentials.
In the following, some statistics about the spread of the mentioned above phenomena are reported, describing their social and economic impact and quoting examples.
1.1.1 Fake profiles
As previously anticipated, in 2012 Mark Zuckerberg reported that around the 9% of Facebook ac-counts are fake or duplicate [7], that means about 83 million profiles [8]. Similar percentages were reported for Instagram, with the 10% of false profiles, and Twitter that counts approximately the 8.5% of fake accounts [24].
There are a mixture of innocent and malicious reasons for fake profiles, including professionals doing testing and research, and people who want to segment their Facebook use more than is possible with one account. Facebook has classified the fake accounts into three categories: duplicate accounts, mis-classified accounts and undesirable accounts [8]. In 2012, duplicate profiles covered up to 4.8% (45.8 million) of Facebook’s total active members. According to the social network’s terms of service, users are not allowed to have more than one Facebook personal account or make profiles on behalf of other people (e.g., parents creating Facebook accounts for their young kids). Misclassified accounts are personal profiles that have been made for companies, groups or pets. Those types of profiles (22.9 million in 2012) are allowed on Facebook, but they need to be created as pages. For this reason, the company provides the opportunity to convert these accounts into approved pages without losing in-formation. In 2012, Facebook estimated that 2.4% of its active accounts belonged to non-humans. Some pets, such as Boo, the “world’s cutest dog”, are typically categorized as public figures. The third category, undesirable accounts, includes fewer (just the 1.5% of all active accounts), but it is the most troublesome. On 2012, there were 14.3 million of undesirable accounts that Facebook believes have been created to violate the companies terms, like spamming.
Between malicious motivations of faked profiles, one of the most dangerous is the child grooming. A study conducted in Germany in 2011 on a sample of 518 students, aged between 10 and 16, reveals
that the 21.4% of participants, or rather two out of ten adolescents, had been cyber-grooming victims over the last year [25]. Most of the cyber-grooming victims report negative consequences, specially psychological, such as embarrassment, depression or self-harm [26]. They show difficulties in estab-lishing new relationships, loss of trust in other people, afraid for ridicule and feeling of helplessness. Finally, they develop a sense of insecurity, given that the abuse has been perpetrated, through the network, within the home.
1.1.2 Fake chatting
The use of faked profiles to catch the attention of the other people is also spread amongst adults searching for other adults. This issue has been the focus of a very famous criminal case known as “tallhotblond” [27]. Tallhotblond is the story of Thomas Montgomery, a 46 years old man, and Mary Shieler a 45 years old woman, who met in a chatroom. He presented himself as a young 18 years old marine, whereas she stole the identity of her eighteen daughter. They had a chat-based love story for two years, until Mary discovered the real identity of Thomas and decided to break up with him and hang out another man. Montogomery became jealous and, finally, he killed the new lover of Mary. After the crime, he realized that the woman for whom he murdered did not really exist. This is only an example to demonstrate that what happens in the web, including relationships, may not correspond to the reality, and could have dangerous consequences.
Fake chatting refers to the phenomenon of have a chat conversation pretending to be a person with demographic characteristics different from the actual ones. Generally, it happens using a false chat account. But why people chat under false account? John Suler, professor of psychology at Rider Uni-versity, speaks of “online disinhibition effect” [18]. In the virtual environment, we do not interface directly with other people but with accounts, that are usually usernames, sometimes associated with photos. The psychological distance, due the physical lack of the interlocutor, makes the user does not feel the restraints that he experiences when communicating in person. In the web-chat space, people say and do things that they would not say and would not do in face-to-face contexts. They relax and express themselves more openly. Anonymity, asynchronous communication, and empathy deficit contribute to online disinhibition. This disinhibition can be positive when it leads the user to display unusual kindness and generosity, whereas it become dangerous when it causes violent behaviors, such as foul language, demonstrations of hate, anger and threats.
The online disinhibition effect facilitates the phenomenon of sexting as well [28]. The term is a port-manteau of “sex” and “texting” and it consists in sending, receiving, or forwarding sexually explicit messages, photographs or images, via any digital device. A survey on 1,496 adolescents between 12 and 18 has shown that about the 10% of them have received sexual messages or videos via mobile phone, while the 6.7% sent these kind of messages to friends and adults, including strangers [29]. Two more recent investigation, which have been conducted by an Italian organization for the chil-dren’s rights and the American Academy of Pediatrics, reported that the 22% of the adolescent had sexting, also with strangers [30], in the last six months [31]. Moreover, it emerged that there is a positive correlation between sexting practice and risky sexual behaviors in real life, with a higher level of risk for those who shared photos in addition to text messages. Concerning photos, one of the most popular social networks based on photo sharing is Snapchat. The principal concepts of Snapchat is that pictures and messages are only available for a short time before they become inaccessible [32].
Introduction
12
As consequence, users become more involved in exchanging images of all kinds, including sexual photos. However, a screenshot is enough to keep the image from the recipient and share it with other users. In fact, in Instagram there is the “#snapchat” hashtag where all the images taken by Snapchat are posted unbeknownst to the victim [33]. These images are also sold, fueling the pornography and child pornography market. To partially solve this problem, companies such as Instagram and Twitter are developing specific algorithms to ban inappropriate content (e.g., photos containing female nip-ples) [34].
1.1.3 Fake VISA
Consequences related to the use of false identities that are different from those described above con-cern VISA and passports. Numerous countries, including USA, provide travel VISA through elec-tronic systems, such as the Elecelec-tronic System for Travel Authorization (ESTA) [35]. International travelers are asked to compile an online form entering their biographical information and, after some checks of the databases, the access to the country is approved or denied. However, most of the crim-inals, including people working for terrorist organizations, are unknown and their information are not included in the databases [36].
Faked personal identity is a major issue in security in Europe as well [12]. Especially in the last years, a large number of migrants from the Middle East are entering Europe without documents, and some-times is enough to self-declare the identity information to obtain a European passport [37]. Among them, there are often Islamist militants involved in terror attacks, as occurred recently in Paris, Brus-sels and Berlin [38], [39], [40], [41]. For example, the perpetrator of the Berlin attack on December 19, 2016 was an undocumented immigrant from Tunisia who entered Germany from Greece and then Italy using several false identities [39]. One of the terrorists involved in the Brussels airport suicide bombing on March 22, 2016 was using the identity of a former Inter Milan football player [13] to travel around Europe. The security measures adopted by the border patrol include mainly biometric passports and the cross-checks of information contained in databases (e.g., wanted lists, fingerprints). But in cases as those mentioned above, biometric identification tools (e.g., fingerprints) could not be applied as most of the suspects were previously unknown. So, despite the attempts by governments to increase security measures [42], the issue remains open.
1.1.4 Online banking and other financial services
Finally, the identity fraud is an urgent problem for financial online services, such as online banking and e-commerce. Even if online banking is an easy way to access bank services, it is enough to steal the credentials of a user to access his bank account.
As anticipated above, identity fraud is defined as the use of another person’s identity without author-ization to deceive or defraud someone else (e.g., the bank) [23]. An example is the use another per-son’s information to open a credit card account without permission, and then charge merchandise to that account. Identity fraud does not occur when a credit card is simply stolen; that may be consumer fraud, but is not identity fraud. Conversely, identity fraud is a synonym of unlawful identity change. It refers to the specific crime activity of use the identity of another person or of a non-existing person fraudulently. In fact, identity fraud does not necessarily involve colluding or theft of another’s person information; it can involve the use of a fake name as well. The false identity is generally created
combining faked and actual information (e.g., a real social security number along with a fake address) [43]. The fraudster can then use the fake identity, to create a credit card or other accounts with finan-cial purposes. The generation of false finanfinan-cial accounts is often very simple, as sometimes it is enough to scan the documents and send them to the bank. The scan documents may be easily falsified. It is estimated that the economic losses due to this criminal activity in US are around billions each year [44]. Equifax reported that about the 80% of all credit card frauds are due to identity fraud accounts [45]. One famous case of identity fraud affected the PlayStation [46]. In 2011, the PlayStation Network was hacked into, and the information from everyone who had his credit card coordinates installed on the Network were stolen. The Sony needed three months to fix the problem. With approximately 77 million of compromised accounts, it was one of the largest data security breaches in history and cost hundreds of thousands of dollars to the Sony [47].
However, the losses are not just financial. Oftentimes, falsified or forged documents are used to pur-chase tobacco or alcohol as a minor, to acquire driver’s licenses, as well as to continue playing on a certain sports team or organization when that person is really too old to compete [48]. Criminals can use the social security numbers of children to apply for government benefits, apply for loans or utility services, or rent a place to live. Children are targets of identity theft because the crime can go unde-tected for years, often until the child applies for his or her first credit card or mobile phone account. This phenomenon is called “runway” and it is estimated that between 140,000 and 400,000 children become victims of identity theft every year [49].
1.2
Fake News
Fake news are defined as articles drawn up with invented, misleading or distorted information, made public with the deliberate attempt to misinform or spread jokes through traditional media or via the internet, through the social media [50]. Fake news are often published with the intention of attracting the reader and finally to obtain financial or political gains. A separate global study published by Edelman in 2016 found that for news and information people trusted the search engines (63%) more than the traditional media, such as newspapers and television (58%) [51].
On December 2016 the CNBC listed the biggest fake news stories of 2016 [52], most notably the title “Pope Francis shocks world, endorses Donald Trump for president, releases statement”. In few weeks the fake news reached 960,000 Facebook engagements. When, on November 8, 2016 Donald Trump became the new US president, Facebook was accused of have influenced the election outcome through the propagation of the fake news. To defend his Social, on November 10, 2016 Mark
Zuck-erberg released a declaration: “Personally I think the idea that fake news on Facebook ... influenced
the election in any way — I think is a pretty crazy idea. Voters make decisions based on their lived experience”.He also stated that more than 99% of what people see in his Social Network is authentic [53],
Other fake news titles of 2016 included “Trump offering free one-way tickets to Africa & Mexico for those who wanna leave America”, “ISIS leader calls for American Muslim voters to support Hillary Clinton” and “FBI agent suspected in Hillary email leaks found dead in apparent murder-suicide” [52]. According to Buzzfeed [54], these stories boasted nearly two million Facebook engagements,
Introduction
14
while in the same period the top performing Facebook story from the New York Times racked up just over 370,000. An investigation traced some of these fake publishers to Veles, a small town in Mace-donia, where it has been discovered that over 140 fake news sites are based. In January 2017, Google and Facebook took the first concrete steps to curb the number of false news articles propagated across their sites [9].
1.3
Fake Reviews
Lust but not least, another serious problem related to online deception concern fake reviews [55], an issue that companies like Amazon, TripAdvisor and Yelp are now facing to guarantee the economic interests of their millions of customers [10]. Fake reviews refer to contents created by users and posted in internet where they express a false opinion about a product or a service. A 2013 European Con-sumer Centres’ Network web survey showed that the 82% of respondents read conCon-sumer reviews before shopping [56].
An yearlong investigation has discovered different companies, which were located in Bangladesh, Philippines or Eastern Europe, where fake-review operators produced, for as little as a dollar, amazing comments for places that they had never seen in countries where they had never been [57]. The fraud-ulent reviews were posted on sites like Google, Yelp, Citysearch and Yahoo. A fake review of a restaurant may lead to a bad meal, which is disappointing, but the investigation uncovered a wide range of services buying fake reviews that could do more permanent damage, such as dentists, law-yers, even an ultrasound clinic.
Reviews can be categorized in three groups: positive reviews, negative reviews and neutral reviews. All these three types of reviews can be faked, especially positive and negative. In fact, a company could create a positive review to increase the number of its costumers or a negative review to decrease the number of the competitor’s costumers.
In a recent study, the authors investigated the economic and business incentives to commit review fraud on the popular review platform Yelp [58]. They found that a restaurant is more likely to commit review fraud writing false positive posts when its reputation is weak (e.g., when it has few reviews, or it has recently received bad reviews), whereas it is more likely to leave reviews for competitors and when it faces increased competition. Chain restaurants, which benefit less from Yelp, are gener-ally less likely to commit review fraud. Moreover, they estimated that about the 16% of the restaurants reviews on Yelp are faked.
The economic damage caused by faked reviews is huge, so much so that on October 2015 the Euro-pean Parliament released a briefing on this specific issue, assuming some possible line of action to
fight it [56]. The report stated that “the problem of fake online reviews not only concerns individual
consumers; it can lead to an erosion of consumer confidence in the online market, which can reduce competition. To deal with this issue, some guidelines have already been adopted by consumer en-forcement bodies, regulators and other stakeholders, in the EU and internationally. Enen-forcement actions have also been taken. Fake online reviews should be taken seriously, as more and more con-sumers buy online, and the practice is becoming increasingly sophisticated”.
In conclusion, is it possible to prevent the fake news posting and block it before they are write? Is it possible to identify fake reviews and black it out? Is it possible to detect people subscribing a website or a social with a fake identity? At date, these are not still effective possibilities, but research on online lie detection is going in this direction.
This work is a contribution to online lie detection. The main purpose is to investigate the possibility to detect deception analyzing the interaction between user and computer. In the next chapters, an exhaustive review of the current lie detection methods, focusing on their advantages and disad-vantages for online application, is reported. Then, we present a series of proof of concept studies aimed to expand the scientific knowledge about human-computer interaction during the act of lie.
Related works
The psychology of lying is one of the topics that have interested the researchers in the last century
[59]. According to Abe, deception is a “psychological process by which one individual deliberately
attempts to convince another person to accept as true what the liar knows to be false, to gain some type of benefit or to avoid loss” [60].
The first scientist who attempted to create a lie detector was Vittorio Benussi. First professor of ex-perimental psychology at University of Padova, Benussi proposed to identify deceptive responses based on the subject’s psychophysiological measures, especially the breathe [61]. The instrument that he used to record the breath was called pneumograph, which consisted in a thoracic band that allowed to record respiratory movements and therefore to calculate the duration of inspiration and expiration. The basic idea was that when a person is lying his expirations become longer, whereas inspirations are shorter. Conversely, a truth-teller show an inverse inspiration-expiration duration pattern.
Lie detection techniques based on psychophysiological measures, like the pneumograph of Benussi, are known as emotion-based lie detection techniques [62]. Emotion-based lie detection highlights deception through the physiological reactions (arousal) that are induced by lying. These are the best known lie detection techniques and the most widely-used. In this category fall the famous polygraph [63], which is commonly associated with the Control Questions Technique (CTQ) [64] or the Guilty Knowledge Test (GKT) [65]. The emotion-based techniques are very diverse, according to the indices that are measured: heart rate analysis [66], eye tracking [67], thermography [68], voice stress analysis [69], facial expression analysis [70]. However, the link between deception and arousal has been ques-tioned, in particular because an person’s physiological activation can be explained by many reasons and because not all the individuals are aroused when they produce deceptive responses [71]. More recently, researchers began to study the neural correlates of deception, using event-related potential (ERP) [72] or functional magnetic resonance imaging (fRMI) [73] as lie detectors. The basis of ERP techniques is the fact that recognition of infrequent and familiar events (e.g., crime scene details) modulates brain potentials such as the P300 or that the response conflict (e.g., the inhibition of an honest response while producing a deceptive one) modulates the amplitude of medial frontal nega-tivities. The use of fRMI in the lie detection is aimed to obtain measurements of cerebral blood flow (a marker for neuronal activity) in individuals engaged in deception, showing differences in brain activity between deceptive and truthful responding.
As we are interesting in the problem of online deception, here we not further discuss the psychophys-iological lie detection techniques. In fact, they are not currently usable to spot online lying, as they require very specific instrumentation and are not easily accessible to the average user who navigates in internet (they are very expensive, require a very specific expertise and take a lot of time to be set up).
Related works
18
Currently, the lie detection approaches that could be used to address the problem of online deception are essentially two: the linguistic approach and the behavioral approach. In the following paragraphs, a description of these approaches is reported, as well as the state of the art about their application to detect lies.
2.1
Linguistic Approach
Different studies have demonstrated that liars utilize language differently than truth-tellers and some linguistic cues can predict which speeches or texts may contain deception [74]. For example, Newman et al. [75] tried to distinguish true and false stories extracting linguistic features. They demonstrated that compared to truth-tellers liars showed lower cognitive complexity, used fewer self-references and other-references, and used more negative emotion words. According to these features, a com-puter-based text analysis program correctly classified liars and truth-tellers with an accuracy around 65%.
The verbal approach is widespread in the forensic environment to distinguish true from false state-ments made by crime victims [76]. One method, which falls under the verbal approach to lie detection, is the scientific content analysis (SCAN) [77]. The SCAN is the most frequently used verbal credi-bility assessment method [78]. This technique analyses the words that people use to try to determine if what they said is accurate. The basic idea is that liars and truth-tellers differ in the type of language that they use. Following this hunch, the SCAN proposes a list of linguistic criteria that could assist the examiner in differentiating between true and false statements [79]. However, at date there are no scientific evidence that confirm the discriminative power of the SCAN [76], [80].
Another linguistic technique to analyze the words that people say during their declarations is the statement validity assessment (SVA) [81]. It was originally designed to determine the credibility of child witness testimony in trials for sexual offences. The core of the SVA is the criteria-based content analysis (CBCA), which is aimed to distinguish true and false declarations [82]. The theory under the CBCA is that children’s statements about true events differ in content and quality from their state-ments about fabricated events. Based on these differences, a list of criteria to evaluate the credibility of witness testimonies have been developed [83]. CBCA criteria are of two types: cognitive and mo-tivational criteria. The first are likely to indicate true statements, as they are typically too difficult to fabricate (e.g., details about time and place). Conversely, motivational criteria refer to how the wit-ness presents the statement: as liars focus on making a credible impression, they leave out from their stories the information that may cause damages (e.g., admitting lack of memory) [84]. However, numerous studies have shown that CBA is usefulness with adult victims and eyewitnesses [85], [76]. Vrij et al. [84] reported that the CBCA has an accuracy ranging from 55% to 90%, with an average accuracy of 70%.
A third verbal lie detection technique is the reality monitoring technique (RM) [76]. The rationale behind the RM is that memories of true events will differ in quality and content from fabricated memories [86]. The criteria to difference true and false statements include different aspects, such as realism, details about space and time, sensory information and clarity or vividness [87]. Some studies demonstrated that the RM has a comparable accuracy to that of CBCA, with percentages of accuracy ranging from 61% to 83%, with an average of 69% [78].
More recently, the linguistic approach has been applied also to online texts, especially reviews.
For example, Moilanen et al. [88] developed a software, named TheySay, which is able to measure the sincerity of a written text based on the textual sentiment analysis. Mihalcea and Strapparava [89] collected deceptive and truthful opinions on different issues, such as abortion and death penalty, from Mechanical Turk participants. In particular, for each topic, they solicited one truthful and one decep-tive instance. Using a classifier based on psycholinguistic analysis, the authors classified true and false statements with an accuracy around 70%. Ott et al. [90] asked Mechanical Turk participants to generate a 400 positive faked reviews on a set of hotels. Then, fake reviews were combined with 400 positive truthful reviews from TripAdvisor on the same hotels. The text of true and false reviews were used to train a machine learning classifier based on three different approaches: genre identification, psycholinguistic analysis and text categorization using n-gram features. Results indicated that decep-tive and truthful reviews were identify with an accuracy of 90%. Comparing the fake reviews obtained by Ott et al. [90] with the reviews classified as faked by the Yelp’s filtering, Mukherjee et al. [91] observed hat the false statements produced by Turkers’ participants were not representative of the real-life fake reviews. For this reason, they concluded that the linguistic approach is not really effec-tive in the real-life setting, which is what has been shown by studies where participants are instructed to lie.
Some authors in literature have argued that lie detection would be most accurate if both verbal and nonverbal indicators of deception are taken into account [92]. Following this line of thought, several studies have focused on both linguistic and behavioral features, trying to improve the performance in classification of a text as genuine or faked. For example, Zhou [93] and Derrick et al. [94] investigated whether linguistic and behavioral indicators can be used for deception detection in instant messaging. Zohu [93] explored different nonverbal and verbal behaviors (participation level, discussion initia-tion, cognitive complexity and non-immediacy of sentences, frequency of spontaneous corrections, lexical and content diversity) during a chat discussion between participants, showing that these indi-ces could significantly differentiate deceivers from truth-tellers. Derrick et al. [94] submitted the par-ticipants to a computer-mediated chat-based. They were instructed to be sincere or liars in response to each question according to a prompt given by the system. The system captured four kind of fea-tures: response time, number of edits (basic keystrokes, such as backspace and delete keys), word count and lexical diversity. Results showed that deception was positively correlated with the response time and the number of edits and negatively correlated to the word count.
The linguistic approach, combined with other behavioral elements, is now beginning to be used also from companies, like Google and Facebook to recognize the fake news [9]. One of the first online service that applied it to the detection of false online information was Yelp, which from 2005 use a filter to remove suspicious or fake reviews [95]. The Yelp’s algorithm is trade secret, but recently some authors tried to speculate about it functioning [91], [96]. Darnell Holloway, senior manager at
Yelp, declared: “Yelp has software that evaluates every single review based on quality, reliability and
user activity on Yelp” [97]. Quality refers to the fact that reviews must have new, helpful and pertinent
Related works
20
the opportunity to give Yelp personal information, such as date of birth and city. The more infor-mation Yelp has about a user, the more “reliable” he is considered. Finally, the third parameter regards the activity performed by the user: users with less activity, fewer friends or fewer reviews are less likely to have their review recommended.
This declaration seems to be coincide with the results of an exploratory study conducted by David Kamerer [96]. The author performed a content analysis of a subset of Yelp restaurant and religious organization reviews, unfiltered and filtered, exploring signals from the reviews or the reviewers that might explain the filtering process. The study found that factors intrinsic to the review itself are not related to filtering, but factors related to the reviewer are strong predictors. According to Kamerer, the Yelp system is much more likely to filter reviews from occasional, isolated reviewers than from prolific, socially connected reviewers. Mukherjee et al. [91] used a linguistic n-gram based approach to classify filtered and unfiltered Yelp’s reviews, discovering that it was not effective in detecting fake reviews. They observed that fake (filtered) and non-fake (unfiltered) reviews from the same user were linguistically similar, which explains why fake review detection using n-grams was not effec-tive. However, they noticed that the spammers left behind some specific psycholinguistic footprints, which were indicators of deception. Then, authors have supposed that Yelp’s filtering algorithm is correlated with abnormal spamming behaviors, founding that the behavior analysis was highly effec-tive in detecting fake reviews than the linguistic n-grams approach.
2.2
Behavioral Approach
The last emergent approach in the study of lie detection is the behavioral one. It consists in the ob-servation of the nonverbal behavior of the suspect while he is producing a deceptive or truthful re-sponse [92]. For example, in online context it would be possible to observe the interaction between the user and the computer or the user’s behavior in the navigation space while he is posting a faked post on a social network.
One behavioral response feature, which is commonly used as lying index, is the reaction time (RT). RT-based lie detection techniques are based on the response latencies to a stimulus of interest [98]. In particular, it has been demonstrated that people manifest a lengthening of RT and an increase in error rate when they lie in response to questions [99]. This techniques find their roots on the cognitive load theory, according to which lying is cognitively more demanding than truth-telling and this higher cognitive complexity reflected itself in a number of indices of cognitive effort, including, for exam-ple, reaction times [100].
The deception production is a complex psychological process in which cognition plays an important role [101]. During the generation of a false response, the cognitive system does not simply elaborate a statement, but it carries out several executive tasks: it inhibits the true response and, subsequently, it produces a false response [102]. Moreover, the generation of a lie requires to monitor the reaction of the interlocutor and to adjust the behavior congruently to the lie [103]. All these mental operations cause an increase in cognitive load and, generally, a greater cognitive load produces a bad perfor-mance in the task the participant is carrying out, in terms of timing and errors [104]. This phenomenon has been observed by studying the RTs in double choice tasks: the choice between two alternatives becomes slower in the deceptive response than the truthful one [105].
According to the functioning of our cognitive system, behavioral-based lie detection tools have been proposed to identify liars, as the RT-based Concealed Information Test (CIT-RT) [106], the Timed Antagonistic Response Alethiometer (TARA) [107], the a Sheffield lie test [108], and the more recent autobiographical Implicit Association Test (aIAT) [109]. All these techniques are computerized task in which subjects are asked to respond to the stimuli, which are presented on the computer screen, pressing one of two alternative keys on keyboard.
The autobiographical Implicit Association Test (aIAT) is a variant of the IAT by Greenwald, McGhee, and Schwartz [110]. It is used to detect autobiographical memories encoded in the respond-ent’s mind. In particular, it determines which one of two alternative memories is true and, conse-quently which one is false. During the task participants have to classify stimuli as quickly as possible in four different categories using two keys on keyboard:
two target concept categories (e.g., China vs. Tuscany, example of stimuli: “I went in China for
Christmas” vs. “I went in Tuscany for Christmas”)
Two attribute categories (true vs. false, example of stimuli: “I am in front of computer” vs. “I am
climbing a mountain”).
Then, in one combined block, two categories (one from the target concept and one from the attribute dimension) are mapped on the same response key. In a reversed combined block, participants have to classify the same four categories reversely paired, so that both target concept categories are paired with both attribute categories. The IAT effect is expressed as the difference between the combined and reversed combined blocks. In the block where two associated concepts require the same motor response, RT will be faster than in the block where the same two concepts require different motor responses [111].
The Sheffield lie test consists in presenting autobiographical questions to which participants have to provide “yes” or “no” responses using one of two different response keys [112]. Questions can appear in two different colors: participants are instructed to lie if the sentence is presented in the one color (lie-trials) and to tell the truth if the sentence is presented in the other color (truth-trials). Experiments that applied this paradigm found that liars had slower RT and made more errors on lie-trials compared to truth-trials.
The TARA requires subjects to classify a succession of mixed statements as true or false, as quickly and accurately as they can, by pressing one of two keys. Specifically, it requires to truth-tellers to complete two alternating tasks using the same strategy, but requires liars to complete them using contradictory strategies. The faster they do so, the more likely they are to be telling the truth; the slower they do so, the more likely they are to be lying. Experimental studies reached an accuracy rate around 85% in detecting liars [107].
Finally, the CIT-RT applies the theoretical framework of CIT (previously known as Guilty Knowledge Test) to reaction times. It consists in presenting the critical information within a series of very similar, noncritical sources of distractor information. For example, if the concealed knowledge about a murder weapon is under scrutiny, a gun (the known murder weapon) will be presented to-gether with distractors that are also potential murder weapons (e.g., a knife, etc.). For the innocent
Related works
22
subjects, the response is expected to be similar to all stimuli. By contrast, for the guilty subject (with guilty knowledge for the weapon), longer responses for the critical item are expected (e.g., the gun) [113].
To the best of our knowledge, there are not online applications of lie detection which are based on RT. The first researchers who have proposed the RT-based lie detection for the web are Bruno Verschuere and Bennett Kleinberg [114]. Through a web platform, the authors applied the CIT to the identity detection [115]. Participants were asked to compile a first online form with their personal information. Secondly, they were asked to learn a false identity and to perform the CIT task pretend-ing that the learnt identity was their real one. Results showed that the CIT identified the true identities of the participants with an accuracy ranging from 86% to 94%.
The efficiency of the behavioral lie detection techniques has been proved. However, there are some limits in the online practical application. First, all these methods require a prior knowledge about the information that has to be checked as true or false. In fact, they require that the true information (or the true memory) is available, while in most real applications this is unknown to the examiner. For example, if we want to check the truthfulness of the user identity, all these techniques require that the true identity is available. Nevertheless, in some cases, such as the Facebook’s users, the true identity is unknown. This means that given two alternative information these techniques can say which is true and which one is false, but they can’t say in absolute terms whether the reported information is true or false. Secondly, RT based techniques only study the response latency, therefore liars have just to check a unique parameter to fake the lie detector. Even though RT are implicit measures, during the aIAT or CIT examination the lie detection purpose is explicit (overt detection of deception). Both the science and the everyday practice, show that the best indices of lying are implicit behaviors that the subject puts into action automatically. For this reason, the ideal situation to detect deceits is realized when the examinee is not aware about the lie detection purpose and about the parameters that are collected (covert detection of deception). Finally, all the above mentioned RT-based lie detection techniques are conceived for the application in court or in other face-to-face situations. Thus, they do not follow the natural flow of the online activities. Finally, they administration is pretty long, and sometimes the instruction to complete the test, such as in the case of aIAT, are very complex. In other words, they are difficult to be integrated in the current online services.
2.2.1 Mouse tracking
Latency measures can be collected not only using two alternative (yes/no) response buttons, but can be embedded in more complex measures. It has been proposed that kinematic indices or keystroke characteristics provide a clue to recognize the deceit during human-computer interaction [116], [117]. In this and in the next paragraph, a description of these techniques and their application in detecting lies are reported.
Recently, researchers found as a simple hand movement can be used to study the continuous evolution of the mind processes underlying a behavior [118]. Especially, the hand motor response has been tracked during computerized multiple-choice choice tasks to understand the dynamics of a broad range of psychological processes [119]. Results have shown that hand-tracking can provide an
high-fidelity real-time motor trace of the mind [120]. Differently from RT, hand movement is not a static index resulting from a cognitive operation, but it is an online measure of the entire process.
A very easy way to capture the hand movements during the subject’s response on computerized tasks is to track mouse dynamics [121]. Mouse dynamics refers to all the information that describe a mouse movement in terms of spatial and temporal features. This procedure has recently been applied to a large number of fields and has proved to be useful in highlighting the cognitive complexity of the subjects’ responses. Mouse tracking has been used to investigate the cognitive processes of negative sentence verification [122], racial attitudes [123], perceptions [124], prospective memory [125], and lexical decisions [126].
Applying this evidence to the study of lie, Duran, Dale & McNamara published the results of the first work in which hand movements were used to distinguish deceptive responses to the truthful ones [116]. During the task, participants were instruct to answer “yes” or “no” questions about autobio-graphical information. Questions appeared on a screen and participant were asked to respond using the Nintendo Wii controller. For each participant, half of the trials required to response truthfully and the other half required a false response, according to a visual cue that appeared on the screen along with each question. Results interdicted that deceptive responses could be distinguished from truthful ones based on several dynamic indices, such as the overall response time, the motor onset time, the arm movement trajectory, the velocity and the acceleration of the motion.
Hibbeln and colleagues studied the mouse movements in an insurance fraud online context [127]. During the task, participants were asked to claim damages to their car by compiling an online insur-ance claim form. In particular, they had to indicate the repair costs and the locations of the damage. Some participants were advise to declare a higher number of car damages in order to obtain a greater compensation by the insurance. Results suggested that being deceptive increased the normalized dis-tance of movement, the speed of movement, the response time, and resulted in a higher number of left clicks.
Similar results have been obtained by Valacich et al. [128] who proposed a pilot study to identify guilty individuals involved in specific insider threat activities. They analyzed mouse movements while participants compiled an online survey similar to the CIT. Their preliminary observations showed that guilty insiders had a different mouse movement pattern when answering to key-item as compared to non-key-items.
At date, these are the only studies that investigate the effect of deception on mouse dynamics. There are also several studies in literature that applied mouse movement analysis to the problem of the user authentication or identification. However, the main limitation of these methods is that they require necessarily a certain level of knowledge about the alleged user, and a specific training, in order to be able to recognize the intruder. In other words, they are not lie detection techniques, but biometrics techniques similar to finger print and face recognition. Once again, these methods cannot be used to spot fake identities in absence of a ground truth.
Related works
24
2.2.2 Keystroke dynamics
Keystroke dynamics is the detailed timing information about human typing rhythm: it describes ex-actly when each key is pressed and released, while a person is typing at a computer keyboard, a mobile phone or a touch screen panel [129], [130]. It has been widely used as a biometric measure for user authentication [131], [132] but, similar to mouse dynamics authentication, it requires a prior knowledge about an alleged user to recognize him.
Concerning the application of keystroke dynamics to lie detection, only few studies focused on it, and the majority of these principally used a linguistic approach to deception detection or they considered only some simple features of the text rather than the rhythm of typing (see section 2.1).
The first authors who proposed to apply keystroke dynamics to were Grimes,Jenkins and Valacich
[117]. They conceived the Keystroke Dynamics Deception Detection model to explain the relation-ship between deceptive behavior and keystroke dynamics. According to this model, the production of a falsehood may cause an increase both in emotional arousal and in cognitive load. These incre-ments may result in a consequent change in the fine motor control, which in turn results in a deviation of the typing ability, affecting the keystroke dynamics personal baseline. The Keystroke Dynamics Deception Detection model was tested in a pilot study. Each subject shared three statements, two truthful and one falsehood, on a web page. Keystroke characteristics were captured by a JavaScript based web application. In this paper, the authors did not discuss the results, but they brought some limitations of the study that could be a good point for future developments.
Banerjee et al. analyzed different keystroke parameters to improve the performance of a classifier in distinguishing truthful and deceptive writers of online reviews and essays collected via Amazon Me-chanical Turk [133]. Each Turker wrote a truthful and a deceptive text about three topics (restaurant review, gay marriage and gun control); the order of the true/false texts was balanced between subjects. Mouse and keyboard events (KeyUp, KeyDown and MouseUp) for all texts were captured. Moreover, the authors considered the following features: editing patterns (e.g., number of deletion keystrokes, number of MouseUp events, number of arrow keystrokes), temporal aspects as writing speed and pauses (e.g.,. timespan of entire document, average timespan of word plus preceding keystroke, av-erage keystroke timespan, avav-erage timespan of spaces, avav-erage timespan of non-white spaces key-strokes, average interval between words) and writing speed variations over word categories (e.g., nouns, verbs, adjectives, function words, content words). They implemented a binary SVM classifier, which achieved a baseline average accuracy of 83.62% on linguistic features. Introducing keystroke features, they obtained a statistically significant improvement of the deception detection classifier, ranging from 0.7% to 3.5%.
To conclude, although keystroke dynamics are mouse dynamics are promising technique for online deception detection, the literature on these topics is not enough. For this reason, we have looked at the matter further through the experiments that are reported in Chapter 4.
2.3
Strategies to Increase Cognitive Load
In sections 2.1 and 2.2, we analyzed different methodologies (RT, mouse dynamics and keystroke dynamics) to record the distinctive features of the deception. The present paragraph focuses on how it is possible to increase the liars’ identifiability.
We argued that there is evidence that the process of inhibiting the truthful response and substituting it with a deceptive response may be a complex cognitive task, which results in an increase of response time. However, in some instances, responding with a lie may be faster than truthfully responding [112]. In fact, distinct types of lies may differ in their cognitive complexity and may require different levels of cognitive effort. For example, the cognitive effort may be minimal when the subject is simply denying a fact that actually happened [134] or when the lie has been overlearned [135]. In other words, when the response is automated the liar’s cognitive load remains intact and his response be-comes indistinguishable from the response of a truth-teller. This evidence, anticipated by previous literature [135] [136], it was found also in our experiments (see paragraph 4.3.8).
To overcome this issue, authors in literature have proposed different strategies, which are usually used in police interrogations, and which allow increasing cognitive load of liars, keeping unaltered the cognitive load of truth-tellers [101].
A first strategy to increase the cognitive load during an interview consists in asking the subject to perform a second task at the same time as the interview. This allows minimizing the cognitive re-sources of the subject, which are destined to the lie, rising clues of deceit. Liars, who are already partially committed to lying, should find the additional task as particularly exhausting [137].
Similar to dual task, is the introduction of task switching. Task switch can be can be understood as continuously move from a task (e.g., lying) to another (e.g., counting) or switch up from lying to truth telling [138]. In this second sense, some authors have proposed to manipulate the proportion of lie/truth-trials across participants, to investigate how the continuous change from truth to lie telling would affects the cognitive load and, consequently, the subject performance [136]. A research has shown that the cognitive cost of deception decreases when people frequently respond deceptively, while it increases when people rarely respond deceptively. People who often responded deceptively are faster and made fewer errors than people who only occasionally responded deceptively.
Another efficient technique to increase the cognitive load is the time restriction of the response [139]. This strategy consists in ask the examinee to answer questions as quickly as possible. This limits opportunity for liars to self-monitor and control the response. The high cognitive load of rapid re-sponding questions may increase the number of deception cues, such as voice pitch elevation, pupil dilation, reduced blinking, long response times, accidental blurting of the truth because of the and may increase.
Soliciting surprise drawings is another efficient strategy to spot liars. In fact, Vrij et al. observed that truth tellers’ drawings of their workplaces contained more plausible details, especially those involv-ing their coworkers, than liars doinvolv-ing the same [140].
Related works
26
Virij at al. proposed to impose cognitive load asking participants to keep the eye contact with the examiner during an interview. The half of participants were asked to maintain the eye contact during the entire interview, whereas the other half responded to the examiner’s questions without any spe-cific instruction. Results showed that liars were more detectable when were obliged to keep eye con-tact than in the control condition.
Another technique used by Vrij and colleagues to improve cognitive load, is to ask subjects to recall their stories in an inverse order [141]. Asking interviewees to report their stories in reverse order is already practiced in police interviews in several countries. The basic principle under this strategy is that recalling an event starting from the end interrupts the prepared sequence of false events and requires activating the working memory to manipulate the recall and monitor its coherence. An ex-periment confirmed that instructing interviewees to recall their stories in reverse order facilitated detecting deception. Half of participants were asked to reports their stories in reverse and the other half in chronological order. They were video recorded and observed by police officers, who identified the liars with an accuracy above the chance level.
However, some authors tried to warn researchers against the possibility that in some situations these cognitive strategies could be challenging for truth-tellers as well. For example, recalling very distant memories or future intentions may be overloading in terms of cognitive effort. As consequence, the differences between liars and truth-tellers become minor [142].
In the following subsections, two more strategies to increase liars’ cognitive load are describe in more detail, since they have been included in the experiment presented in Chapter 4.
2.3.1 Unexpected questions
The strategy of asking unexpected questions was pioneered by Vrij and co-workers [143]. Unex-pected questions are questions to which liars cannot prepared their response in advance. On the con-trary, expected questions are those questions to which liars have fabricated the response previously. Imaging a person who decided to lie about his identity on a social network. An example of expected questions is “which is your date of birth?”, whereas an unexpected question could be “which is your zodiac?”. As liars are not prepared to answer unexpected questions, they are forced to generate new details that were not part of their original script. In the specific example, when a user subscribes a website he knows that the date of birth is one of the information commonly asked. Conversely, the zodiac sign is not frequently asked. Thus, the liar has to fabricate the false response in real time, checking the congruency of the response with the other faked information and maintaining his cred-ibility and consistency [144]. Liars give their planned responses to expected questions easily and quickly, but they need to fabricate plausible responses in the case of unexpected questions, and this yields an increase in the cognitive load. By contrast, truthful responses are not plagued by the side effects of the cognitive load as they are quite automatic and effortless for both expected and unex-pected questions.
The technique of unexpected questions was originally applied to in investigative interviews [145]. The procedure commonly provides that the examiner initially ask anticipated questions and then he switch to unanticipated questions. Such questions may relate to particular spatial or temporal aspects of the recalled event. In a first experiment, Vrij et al. [143] interrogated couples of liars and
truth-tellers about a lunch that they had together at the restaurant. The couples of truth-truth-tellers really ate out together at the restaurant, whereas liars were instructed to pretend to had lunch together. During the interview the examiner asked questions about temporal and spatial features of the lunch-event (e.g., who finished to eat first? Where was your table located?). Comparing the responses to unexpected questions of the two member of each couple, liars were identified with an accuracy of 80%. The classification was based on the discrepancies reported by the two persons at the same questions. Then, a second experiment was run by Lancaster et al. [146], investigating the power of unexpected ques-tions in a between subjects experimental design. This time participants were not paired, but the single subject was asked to lie or tell the truth. Results showed a good classification rate for both truth-tellers (78%) and liars (83%). The authors observed that liars, with respect to truth-truth-tellers, reported many more details to the expected questions versus the unexpected questions, and the lie detection could be based on this difference.
2.3.2 Complex questions
Unexpected questions are a powerful tool for uncovering deception, but they cannot be used in every condition. When responding to unexpected questions, liars have to process the information in the questions in real time as quickly as possible so that cognitive processing load is combined with time stress in the performance of the task. Within the cognitive load approach to lie detection, one unsolved problem is the identification of a liar when unexpected questions are not available. Typical conditions
when unexpected questions cannot be used are in the so-called “lies of omission” [147], which consist
in denying something that did happen (“I did not do it” type of lies). For example, if a guilty subject is denying any wrongdoing (in a “Did you do it?” type of question), it is difficult to create an unex-pected question that efficiently uncovers his deception.
In this work, we present a new technique for detecting lies when unexpected questions cannot be crafted. The technique consists of presenting complex sentences. We have named “complex ques-tions” the sentences that contain more than one information in the same phrase. For example, to in-vestigate the identity one could ask a question about the name (e.g., Is Alice your name?) and a question about the place of birth (e.g., Were you born in Montréal?). A complex question encom-passes both this information in the same sentence (e.g., Are you Alice born in April?).
Asking complex questions is very closed to increasing the number of response alternatives among which the liar has to choose. Williams et al. [148] stated that when questions involved more than one possible lie response, liars reveal a greater response latency. By contrast, the authors found that the number of alternatives did not significantly affect response times when individuals told the truth. In fact, in real life situations, the subject has to choose one lie in a range of endless possibilities, deciding which the better one is according to the context. The greater number of alternatives requires more cognitive effort by liars who need to monitor the plausibility of more than one information.
Our hypothesis is that complex questions require greater cognitive resources compared to simple questions, because they require subjects to analyze each information one by one and labelling it as true or false. In other words, the subject has to monitor the plausibility of more than one information and retain it in working memory to, finally, decide if the entire sentence is true or false. While truth-tellers can speedily carry out this sequence of mental operations, liars need more time to match the
Related works
28
plausibility of each information with the lie they told [102]. As result, we expected that liars have a bad performance, compared with truth-tellers, when they are involved in a decision task, making a greater number of errors and showing slower reaction times. This hypothesis is investigated in the experiments reported in sections 4.4, 4.5 and 4.
Materials and Methods
In this chapter, a general description of methods and materials is reported. These were sim-ilar for all the experiments that are presented in next chapter, except when specified.
The general experimental procedure was approved by the Ethics Committee for psychological re-search – Padova University Psychology Department, and it was in accordance with the relevant guide-lines and regulations [149].
3.1
Participants
A total number of 640 healthy participants took part to the experiments. They were volunteers, mostly recruited among students of Padova University. All participants were over 18 and provided the in-formed consent before the experiment. Subjects did not receive any compensation for participation. Exclusion criteria have not been applied, except for language. In fact, it was required that the subject’s mother tongue was the same of the experiment. It was to avoid an influence in response times due to comprehension difficulties. Moreover, each subject participated to just one experiment, to avoid that his performance could be compromised by a previous knowledge of the experimental procedure. Data of subjects who did not understand the task were removed before the analysis.
3.2
Experimental Design and Procedures
All the experiment were built according to a between subject experimental design. Participants were always randomly assigned to one of two experimental groups: liars or truth-tellers. Liars were partic-ipants instructed to lie about a topic (e.g., their identity), whereas truth-tellers were subjects who where asked to respond truthfully. Every experiment counted at least 40 participants, 20 for each experimental condition. The sample size is similar to other lie detection researches based on response latencies [111]. It has been calculated that a sample size = 40 is enough to have a statistical power
(1-β) = 0.8, given a significance level (α) = 0.05 and a medium effect size (d) = 0.5 [150]. Moreover, for
each experiment we confirmed that the two experimental groups were similar in terms of age, gender and schooling (p>.05 both for age, gender and schooling).
3.3
Data Collection
All the experiments took place in the laboratories of the Department of General Psychology – Uni-versity of Padova.
Experiments were conducted measuring indices deriving from three different tools of human-com-puter interaction: reaction times (RT) on keyboard, keystroke dynamics and mouse dynamics. In the following, the materials used to collect data are summarized and all the indices deriv