Reasoning-based Techniques for Dealing with
Incomplete Business Process Execution Traces
Piergiorgio Bertoli1, Mauro Dragoni2, Chiara Ghidini2 and Chiara Di Francescomarino2
1
SayService, Trento, [email protected]
2
FBK—IRST, Trento, Italydragoni|ghidini|df mchiara@f bk.eu
Abstract. The growing adoption of IT systems to support business activities, and
the consequent capability to monitor the actual execution of business processes, has brought to the diffusion of useful business analysis monitoring (BAM) tools, and of reasoning services standing on top of them. However, in the majority of real settings, due to the different degrees of abstraction and to information hiding, the IT-level monitoring of a process execution may only bring incomplete infor-mation concerning the process-level activities and associated artifacts. This may hinder the ability to reason about process instances and executions, and must be coped with. This technical report presents a novel reasoning-based approach to recover missing information about process executions, relying on a logical formu-lation in terms of a satisfiability problem, and leveraging on model and domain knowledge. The approach is implemented in a Java prototype application; our experiments on two non-trivial case studies show the promising potential of the approach, and point to directions of extensions.
1
Introduction
The last decades have witnessed a rapid and widespread adoption of Information Tech-nology (IT) to support business activities in all phases. IT systems are used to record and store documents; different systems are aligned via automated communication protocols; and so on. This is true in large organizations, such as in the Public Administration, large companies, but as well in SMEs.
This gives the potential to leverage IT techniques to also monitor the actual execu-tion and progress of (instances of) business processes. This may bring several remark-able advantages, as for example:
– to allow business analysts to observe the current evolution of ongoing processes
– to allow for statistical analysis on past executions
– to identify bottlenecks and opportunities of improvement of processes
– to identify discrepancies between the way processes have been designed, and the way they are really executed
In fact, a variety of Business Intelligence tools have been proposed, even by major vendors, that aim at supporting business activity monitoring (BAM), and hence the activities above, to different extent; for instance, Engineering’s eBAM3, Microsoft’s
BAM suite in BizTalk4, Oracle’s BAM5, Polymita, IBM’s business monitoring into WebSphere6just to name a few.
However, business activity monitoring must deal with a significant difficulty, namely that the observation of process executions may bring, in the vast majority of cases, only partial information, in terms of which process activities have been executed and what data or artifacts they produced so far, none of the proposals above has been capable to address this, rather relying on the strong assumption of being able to fully monitor the business activities and data.
The partiality of monitoring information in real settings comes from two sources. First, the definitions of business processes often integrate activities that are not sup-ported by IT systems, such as human-driven interactions; this is natural, since the def-inition of a business process must span its whole cycle, regardless of the nature of activities, and since the abstraction level at which the modeling of a business process is conducted is much higher than the level of implementation. Indeed, the most widely adopted business process modeling formalisms such as BPMN allow a clear distinction between e.g. IT-supported and human-realized activities. Given this, even being able to fully trace the behavior of IT systems would not map to a complete knowledge over business process execution. Second, further to this, IT systems may expose only partial information about their workings and the data they produce. While IT instruments for intercepting and interpreting the evolution of systems are actively developed, they must only partially relief this situation, as in any case they require that the system exposes externally some form of outcome.
As a result, the execution traces that can be extracted from observing the execution of IT systems realizing a business process may be incomplete, and indeed, in the ma-jority of real cases, they are. Hence, we face the challenge to monitor process execution in the face of execution traces being incomplete.
In this paper, we tackle the problem in the specific setting of business process anal-ysis, proposing, implementing and experimenting a novel reasoning-based method that leverages on model knowledge to reconstruct, as much as possible, the missing infor-mation from partial execution traces, enacting better business process analysis. While conceptually inspired by work on research areas connected to monitoring and recon-structing of information starting from incomplete available data, such as game theory, learning, planning, fault diagnosis and analysis, our work differs in key assumptions and choices; more specifically, this work brings the following contributions:
– a novel, reasoning-based method to recover missing information about process ex-ecutions, based on the automated derivation of a set of logical rules out of the business process model, which we regard as a BPMN modeling possibly enriched with information about the lifecycle of documents. Intuitively, such rules serve to describe “what can be implied from observing (or not) a certain report about an 4 https://www.microsoft.com/biztalk/en/us/business-activity-monitoring.aspx 5http://www.oracle.com/technetwork/middleware/bam/overview/ index.html 6 http://www-142.ibm.com/software/products/us/en/business-monitor
activity/document”. Such rules are encoded and fed, once for all, to a reasoning en-gine; then, for every actual (and incomplete) execution trace, the reasoning engine derives (a) whether the trace is compliant with the model, and (b) a set of possible completions for the missing information. While such completions are maximally useful if they cover all missing information and do it uniquely, even partial recon-struction of executions is to be regarded as an added value given the input.
– a realization of this approach as an effective prototype that encompasses the adop-tion and integraadop-tion of satisfiability solving engines as part of its architecture.
– the experimentation of our approach over two case studies, taking different hypoth-esis on the amount of information injected (and exploited) in the process model. As we will observe, there is a natural trade-off among the amount of such information, and the ability to reconstruct partial information.
The technical report is structured as follows: Section 2 provides some background and situates the problem at hand; Section 3 describes technically the problem and our approach to it; Section 4 describes an experimental evaluation, paving the way to a discussion of findings in Section 5. Finally, Section 6 and Section 7 discuss related and future work.
2
Background
The reconstruction of flows of activities of a model given a partial set of information on it can be closely related to several fields of research: for instance, game theory, fault diagnosis and isolation, learning and planning under uncertainty. In all these cases, the dynamics of a system under observation are perceived only to a limited extent, and hence it is needed to reconstruct missing information, either as a final goal, or as an intermediate step to achieve some final results (e.g. to devise a winning strategy in spite of limited knowledge).
In this respect, most of those approaches share common conceptual grounds, i.e., the view that a model is taken as a reference to construct a set of possible model-compliant “worlds” out of a set of observations that convey limited data. Still, even with these common conceptual grounds, several technical approaches have been proposed and re-alized, based on different hypothesis concerning the kind of available observations, and the kind of model information. In particular, a high-level classification relevant to our purposes distinguishes among qualitative and quantitative approaches to partial infor-mation.
The former, typically based on Partially Observable Markov Decision Models, rely on the availability of a probabilistic model of execution and knowledge. Hence, the outcomes of executions are specified in terms of likelihood measures, and as a con-sequence, the knowledge about the world amounts to a probability distribution. This can be used e.g. to devise “optimal strategies” whose executions, driven by the limited available feedback information from the environment, maximize some reward value in a statistical way.
The latter approaches stand on the idea of describing “possible outcomes” regard-less of likelihood; hence, knowledge about the world will consist of equally likely “al-ternative worlds” given the available observations in time. In this way, one e.g. devises
strategies that guarantee that a given goal is achieved considering all such alternative worlds; still, it is possible to conceive different strategies that give different guarantees to achieve such goal, e.g. “the goal is achieved in a finite number of actions for any world”, “the goal is achieved in a finite number of actions in some world”, “the goal is achieved for any world, but in a possibly infinite number of steps” and so on.
In terms of modeling, quantitative approaches require injecting probabilistic knowl-edge into the model, while qualitative approaches do not; hence, the latter are more light-weight and require information much closer to that made available in BP models, where e.g. alternate courses of activities exist but no likelihood measure is given on them. For this reason, we will take inspiration from the latter, and leave the former to further consideration.
Under this sense, many approaches can be conceived, and have been actively devel-oped and tested, to model sets of possible worlds, ranging from tree-based representa-tions (BDDs) [1,2] to logical formulae whose satisfaction models implicitly represent the worlds [3,4]. We take the latter choice, which brings to a natural connection of our challenge to one of the core problems in AI, that is the satisfiability problem (or SAT). In a nutshell, in satisfiability, given a modelM encoded as a set of logical formulae over a given set of predicates, and given a partial assignmentAto such predicates, one aims at obtaining all (or at least some)completeassignments to the predicates that is consistent with the modelM and supersedesA- or to know that no such assignment exist, meaning thatAis inconsistent withM.
Unsurprisingly, many of the higher-level problems mentioned above, such as plan-ning [5,4] or fault diagnosis of dynamic systems [6], can be recast in terms of satis-fiability by appropriate logic encodings; for instance. In these cases, the dynamic of systems are encoded as logic rules that, intuitively, describe the connections among the state of the system at successive steps of the execution, in terms of what changes due to actions (action axioms) and what is left unaffected (frame axioms). In this respect, different encoding styles have been thought of and devised, e.g. ranging from classic encodings that describe in a direct way the effects of actions over the domain, to ex-planatory axioms that trace back executed actions from observing the changes in status, and so on; see [7] for a survey.
In our approach, we will take inspiration by the above ideas and concepts, but we will adapt and simplify them to our purposes with the aim to devise an effective mean to reconstruct missing portions of an executed trace: if we assume the state of the model to consist of the traversed activities and available documents, then once all the model-implied connections among data and activities of possible executions are described, a SAT engine can extract all the assignments that correspond to the deduced “gaps”.
While satisfiability is known to be NP-complete, several effective implementations are available that, on top of the classic [8] backtracking-based algorithm for it, enact several optimizations in terms of sub-result caching, search heuristics and so on. Indeed, the wide availability of effective tools for solving SAT is one of the key reasons for the success of SAT-based approaches e.g. in planning or diagnosis.
3
Problem and approach
At a high level, our problem can be formulated as follows: “taking as input a
busi-ness process modelM, some domain-specific knowledgeK and a partially specified
execution traceT, produce all the execution traces{T1, . . . , Tn}that subsumeT and
are compliant withM andK; if no such trace is produced, this denotes thatT is not
compliant withM andK”. We remark here that, while in the ideal casen= 1andT1
is a complete trace, even withn >1and/or incomplete output traces, the partial com-pletions ofTare an added value in terms of knowledge on the model behavior. Hence, the input to our problem consists of an instance-independent portion, that comprises the business process model and the domain knowledge, and an instance-specific portion re-lated to the input trace. Specifically, in the static portion, the business process model
M consists of a notation such as BPMN, that specifies both the flow of activities7and
their related data objects, while the domain knowledgeKrefers to the structure of data objects, to how they evolve in time and how their content are related. In detail, data object are generic data structures, organized intofields, andKdescribes how activities affect their content bycreatingthem or writing certain fields as theiroutput; further, different fields of different data objects may be associated together by means of a
map-ping functionthat defines a commonsemantic field. This way, if we assume that data
objects are used to represent document forms, it is possible to describe that the “Fiscal Code” field of a “birth act” document maps to the “FC” field of the aggregated record “Personal details” of the document “FC Form”. Given this, the instance-specific input is a trace consisting of a set of time-stamped activity instances and associated output data object instances, which does not describe in full a path of the business model (and its related data objects).
The output is either (a) the notification that the partial trace is inconsistent with the model, or (b) a set of partial or full traces that supersede the input partial trace, completing it partially or in full. Of course, in the ideal case, the output is a single fully specified trace; but outcomes with lesser precision and recall can still be valuable for the analysis of process executions.
Hence, our starting point is conceptually close to that of model-based approaches to reasoning under uncertainty of [6,5,9,10]: given a trusted model, and a set of partial informations about it, we attempt at reconstructing knowledge about it (namely about its behavior).
Specifically, in our case, we assume that our available input information is purely qualitative: the dynamics of the process may be undetermined but no statistical data is available about it; and the executed trace purely reports available data, and does not provide any fuzzy measure of likely behavior. This makes the situation close to that of qualitative model-based approaches, where logical encodings of the problem are adopted to detect (sets of) possible solutions, see [5,3,4,11].
At this stage, it is clear how the problem is associated to one of SAT, where, given the model composed byMandK(in symbolsM∧K), and a partial assignmentT(the 7In this paper we use the term activity to refer both to BPMN activities and events described in a business process diagram and to the events related to the activity execution logged in an execution trace.
partially specified execution trace), one aims at obtaining all (or at least some)complete
traces consistent withM ∧Kthat supersedeT - or to know that no such assignment exist, meaning thatT is inconsistent withM. In symbols, given
M ∧K|=T (1)
we aim at identifying all complete models ofT. It is also clear how our problem relates to SAT-based approaches to reasoning under uncertainty, e.g. in planning [3,11], where for some form of requirementρ, the problem is recast into a SAT problemM |=ρ.
In the context of modeling system dynamics, several SAT-based encodings have been devised, for example in the context of planning or model-checking. In these cases, logical rules that define the dynamics of the system are “unfolded”, that is instantiated for each step of the execution, to obtain an overall set of constraints that describe how the dynamics of the system can evolve in a given (fixed) number of execution steps. This allows inquiring the possible behaviors over such number of steps, and for instance to detect, given additional constraints that describe facts to be achieved, the possible strategies to do so.
While having to deal with the specification of flow dynamics, our situation is how-ever different, as we start from a dynamics of known length (where we may need to reconstruct “gaps” of missing information). As such, our encoding, exploits this knowl-edge to avoid the unfolding of rules, and to describe in a more direct way the depen-dency among subsequent activities (possibly deriving them from the witness of knowl-edge about data objects, or lack thereof). In detail, the SAT input model will contain the instance-independent encoding of the process model and domain knowledge in the form of implication rules related to the flow, and the domain knowledge on data; this will be complemented by the instance-dependent encoding of the trace as assertions of process activities and data logged in the trace file; the discussion of such encoding is the subject of the following section.
3.1 SAT Input Model Encoding
Given a process model defined in the BPMN notation, a specific domain knowledge, and a partially specified execution trace (defined in terms of time-stamped activities and associated output), the purpose of this section is describing how to encode such a knowledge in the form of an input SAT model. In other words, how to obtain the sets of boolean formulaeM,K, andT described in the formula (1).
Before doing that, we start with a general consideration. Examining the specific type of knowledge we can observe in the execution traces (i.e., activities and associated output), we focus our attention on what we defined process modeldata flow objects, i.e., BPMN Flow Objects having associated output data, and on stateful data object
fields, i.e., informative portions of BPMN Data Objects having different states in their
lifecycle, that is, at different points of the process execution. Here on we denote with the termfieldasemantic field, i.e., a field (data object portion)Fand all the fieldsF˜ ∈
mappings(F)with the same semantics and hence conveying the same knowledge (see example at the end of Section 2). We also denote withFXa stateful fieldFin the state (immediately after the execution of adata flow object)Xsuch thatF∈output(X).
Given these premises, the model has been encoded by representing all process modeldata flow objectsand data object field states as boolean predicates. Logical for-mulae, in the form of implication rules have then been defined on top of these predicates, to represent the model.
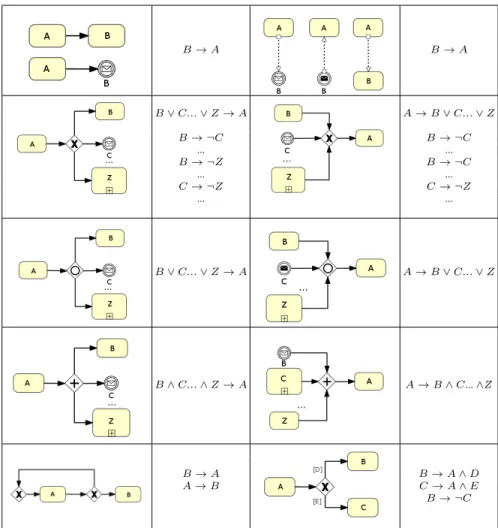
We start with the definition ofM, which encodes, as a set of implication rules, the control flow derived by locally analyzing the process model. In detail, the overall idea is that the occurrence of adata flow objectimplies the occurrence of itsprecedingdata
flow object, i.e., thedata flow objectthat is connected to the currentdata flow object
via sequence flow in BPMN. Similarly, the occurrence of adata flow objectreceiving a messageimplies the occurrence of a senderdata flow object. Slightly more complex is the case of split and merge flow points. In this case, indeed, according to the different semantics of the control flow node, different implication rules can be generated. Table 1 reports the translation of the main control flow basic patterns (described in BPMN) into implication rules. Cycles are treated similarly (see last row, left in Table 1), with the only exception that, in case the cycle is introduced by a mutual exclusion, the mutual exclusion part of the rule is omitted. Finally, conditions on executed activities can also be encoded adding conditions as further “consequences” of thedata flow object execu-tion. The last row of Table 1, right, in which conditions related to past executions of
data flow objectsare depicted among square brackets, reports a pattern example and the
corresponding implication rules. In case of nested structures, e.g., when a branch of a gateway is, in turn, a gateway itself, possibly of a different type, the same typology of pattern is recursively applied.
Focusing onK, two types of knowledge related to data are encoded in the SAT input model: (i) the one related to thecreatesrelationships betweendata flow objects
and fields, which intuitively represents the fact that a field is filled with a value for the first time immediately after the execution of a certain action; and (ii) the one related to the relationshipamong data, obtained combining knowledge on mappings among fields, knowledge ondata flow objectoutput and knowledge on the control flow, which intuitively represents the fact that the (non) presence of a field value immediately after the execution of a certain action is connected with the (non) existence of the field value in previous steps of the process.
To this purpose, we rely on the lifecycle of each semantic fieldF. In detail the
lifecycleofF is a graph representing the flow of the field through its possible states
FX, including the empty state F∅, i.e., the starting state in which the field does not exist. The lifecycle of a fieldF can be computed by analyzing the paths of the model and combining such a knowledge with the domain knowledge.
In detail, defined:
– a pathpX1Xn from a flow objectX1 to a flow objectXn as a sequence of flow objects in the process model,hX1...Xni, such thatXi−1precedes (in the diagram)
Xiwithi∈[1, n];
– a subpath ofpX1Xn,pXiXj, a subsequencehXi...XjiofhX1...Xni, such thati, j∈
[1, n]andi <=j;
– theinversepath of a pathpX1Xn=hX1...Xni, instead, is defined as the sequence
B→A B→A B∨C...∨Z→A A→B∨C...∨Z B→ ¬C B→ ¬C ... ... B→ ¬Z B→ ¬C ... ... C→ ¬Z C→ ¬Z ... ... B∨C...∨Z→A A→B∨C...∨Z B∧C...∧Z→A A→B∧C...∧Z B→A B→A∧D A→B C→A∧E B→ ¬C
Table 1: Diagram Translation Rules.
– PFX = S p−1X ∈InverseP aths(X){p− 1 XY|p− 1 XY = shortestSubP ath(p− 1 X )∧ Y ∈
DF OF}, whereDF OFis the set ofdata flow objectshaving as output the fieldF, as the shortest inverse subpath fromXto adata flow objectY having as output the fieldF; and
– target(PFx) = S
p(XY)∈PFXY as the set of targetdata flow objects(having as
output the fieldF) of the shortest inverse subpaths fromX;
the lifecycle of a fieldF can be built creating (i) an initial empty node F∅; and (ii) a
nodeFXfor each field stateFXconnected to each of the nodes intarget(PFX)and/or toF∅if thedata flow objectXcreatesF.
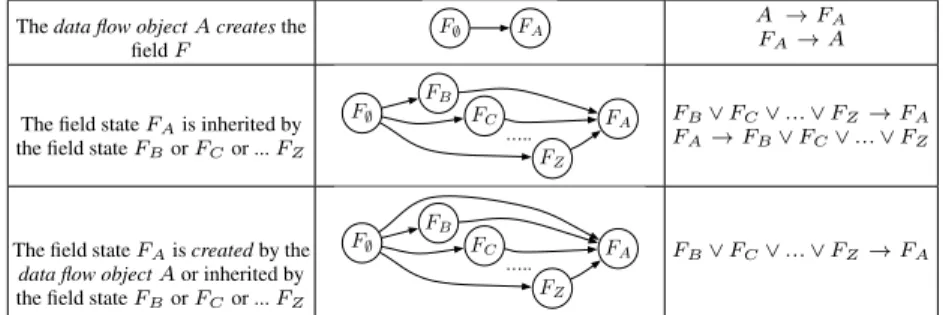
Table 2 reports the implication rules for relationships on data (related to theFA
field state). Note that the encoding provided in Table 2 is restricted to the case in which fields can be created, updated, but never deleted. While this is a limitation of our current
Thedata flow objectAcreatesthe fieldF
F; FA AF →FA
A→A
The field stateFAis inherited by
the field stateFBorFCor ...FZ
….. FA F; FB FC FZ FB∨FC∨...∨FZ→FA FA→FB∨FC∨...∨FZ
The field stateFAiscreatedby the
data flow objectAor inherited by the field stateFBorFCor ...FZ
….. FA F; FB FC FZ FB∨FC∨...∨FZ→FA
Table 2: Data Translation Rules
work, this is an assumption which holds in a vast range of cases, whose generalization we leave to future works.
In detail, for eachcreatesrelationship, between adata flow objectAand a fieldF
(represented in theFlifecycle reported in the first row of Table 2 as a direct connection betweenFA and the empty starting stateF∅), a bidirectional implication rule can be
defined. It intuitively suggests that, if a fieldF is created by a givendata flow object
andF exists in its stateA, then thedata flow objectcreatingF has been executed as well. Similarly, ifX is executed and it createsF, thenFAhas to exist.
Starting from the field lifecycle, implication rules for the relationships among data can also be derived. Intuitively, recalling the assumption that fields can be created and updated but never deleted, the existence of a fieldF in a given state (FA) implies, if the field is not created by thedata flow objectA(i.e., it is not directly connected to the
F∅state in theF lifecycle) its existence in at least one of its preceding states (i.e., the field is inherited by its preceding states). Similarly, under the same assumptions, the non-existence of the field in the stateFAimplies its non-existence in all the preceding field states (row 2 in Table 2). When, instead, the field stateFAcan be either inherited by the preceding fields or created by thedata flow objectA(i.e., it is directly connected to the empty initial stateF∅), as reported in the last row of Table 2, nothing can be said
on the non-existence ofFA.
Finally, for each trace, the (incomplete) knowledge it contains is also described in terms of partial assignments, in order to obtainT. In detail, for each activityX with associated data occurring in the analyzed process trace, the corresponding data flow
objectpredicate
T RU E→X (2)
is asserted, i.e., defined as a true predicate. Similarly, for each data object fieldF occur-ring in the trace as output of a given activityX, the corresponding stateful data object field predicate
T RU E→FX (3)
is added to the rules as a true predicate. Moreover, for every non-occurring fieldFof a data object occurring as output of the activityX, the corresponding predicate is added
Model encoder
Process model encoder
Domain knowledge encoder
Trace encoder
SAT4J decoder Model
Process model (.json) Domain knowledge proper=es Incomplete trace Set of completed traces
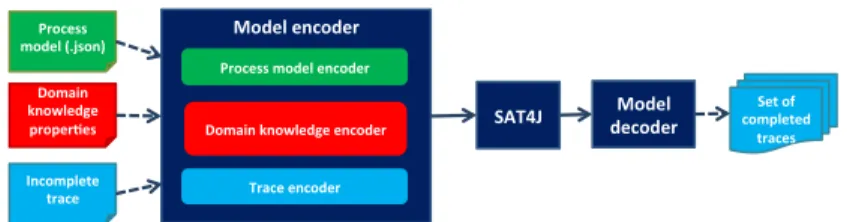
Fig. 1:SATFILLERarchitecture.
3.2 TheSATFILLERtool
The approach has been implemented in theSATFILLERtool.SATFILLERis a Java appli-cation taking in input a process model (in the .json format), knowledge on the domain as well as an incomplete trace, and returns either (i) the notification that the input trace is inconsistent with the model or (ii) one or more possible completions for the input trace. Figure 1 provides an overview of theSATFILLERarchitecture; it is composed of three main modules: aModel encoderfor encoding the input knowledge into a SAT model, theSAT-reasonerand aModel decoder, for decoding the output of the reasoner. In detail,SATFILLERuses SAT4J8, a Java library for solving boolean satisfaction and
optimization problems. TheModel encoderis composed of three submodules for the semi-automatic encoding of the three types of input knowledge (process model, do-main knowledge and traces) in the SAT4J format, i.e. the common Conjunctive Normal Form (CNF) Dimacs format. Finally, theModel decoderautomatically translates the SAT4J output into a (set of) trace(s) completing the incomplete input one.
4
Evaluation
In this section we evaluate the proposed SAT-based approach both in terms of its
effec-tivenessand itsusability. In other terms we are interested in answering the following
two research questions:
RQ1Is the SAT-reasoning based approacheffectivefor filling incomplete traces? That is, is it capable to fill significantly incomplete traces?
RQ2Is the SAT-reasoning based approachusablefor facing the issue of incomplete traces? That is, is it capable to provide users with a reasonably small number of alter-native solutions?
The first question aims at evaluating the effectiveness of the approach in terms of its capability to complete partial traces. The second, instead, aims at providing an evalua-tion of the the usability of the SAT-based approach in terms of its capability to provide users with a reasonable number of returned solutions (complete traces), i.e., to reduce the solution space.
To answer these questions and to evaluate how the results of the approach vary when the amount of knowledge encoded in the SAT model varies, we applied the approach to two non-trivial case studies, which we purposely chose with different characteristics
both in terms of process models, as well as of type and management of data. In the rest of the section we introduce the case studies (Subsection 4.1), the experimental procedure (Subsection 4.2) and the results (Subsection 4.3).
4.1 Case studies
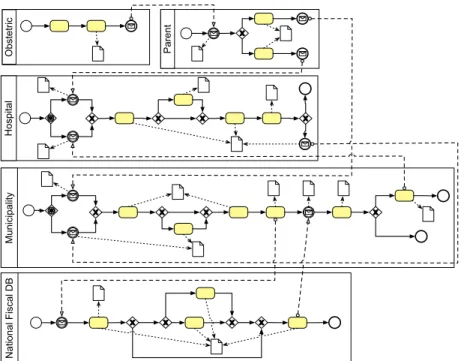
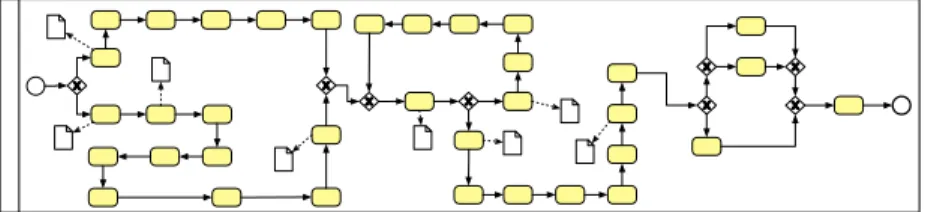
As introduced above, for the evaluation of our approach we have selected two different case studies, described in the paragraphs below, related to two different processes of the Italian Public Administration. The first one is related to the birth management, while, the second, concerns the tender adjudication process for the supply of services and materials. The process models of the two case studies, whose simplified BPMN view is shown in Figure 2 and Figure 3, are reported in the Appendix of this technical report.
Birth Management Process When a new baby is born, a process is started whose aim
is to record the birth both as a resident person (locally in the municipality and in the central national database), and as a user of the national welfare system. This in turns requires the coordination of several actors, and generating some crucial data that will become part of the personal data of the newborn - e.g. his/her ID. Specifically, the process involves five actors: the Ostetrician giving birth, who is in charge of generating an official birth act ; one of the parents, who has to contribute information and takes an active role in signaling the birth to the Munipality or Welfare System; the Municipality, who, through his officer, is in charge of subscribing the new born as a local resident, associating him/her to the family; the Welfare System, who must store the new born and subscribe him to the welfare services; and the Ministery of Interior, who has to be informed about the newborn person, and may take an active role in generating some of his/her personal data.
In a nutshell, the process is triggered by the Ostetrician, who provides the parent with the birth act; the parent may then decide to present it to the welfare system, or to the municipality; in both cases, these two actors will reciprocally signal the other, at the end of their process, about the new birth, so ultimately the information will reach both of them. The Municipality must store the new resident in its database; it must signal it to the Ministery, and record and handle possible mistakes and misalignments in the data (e.g. if a module is compiled wrongly and the hence some parent cannot be traced in the Ministery’s DB). The Welfare System must also store the newborn in its own DB, handling possible mistakes and associating it with specific features that decide which wlefare services are available for the newborn. Finally, the Ministery is in charge of verifying the data in its central DB, and also to spread the information to further actors (which for ease of discussion we will not consider here).
During this process, several decision and join points are traversed, since the par-ent has some freedom in deciding the way the procedure proceeds, and further, since the same personal data of the newborn can be generated by different actors, and no overwriting is allowed. Further, a variety of documents are produced, reflecting the fact that every PA actor maintains a separate storage to record the event, and makes use of different documents to record different phases in the evolution of the process (e.g. sep-arate “request”, “record” and “outcome” documents are managed by the municipality, all linked by an assigned protocol number).
Tender Adjudication Process The second use case concerns the modeling of the pro-cedure about how the Public Administration in the Trentino local government manages the providing of services and materials.
This process contemplates two different phases: in the first one the offers are eval-uated based on the possibility of having anomalies in the forms compilation or not; while, in the second phase, the process goes through the fine-grained evaluation of the valid offers and establish which is the offer winner of the tender.
During the first phase, if it is admitted the management of offers containing anoma-lies, the process creates the report of them, and this document goes through the entire work-flow for its registration, classification, sign, and forward to the person in charge of archive it. At the end of this branch, it is created a report of the all accepted offers; indeed, after the verification of the anomalies contained in each offer, this one may be accepted or rejected. In this report, the offers are ranked by their suitability with respect to the number and the type of anomalies. On the contrary, if it is not permitted the ac-ceptance of offers containing anomalies, the process directly goes through the creation of the result reports in which all offers are judged as suitable or not with respect to the parameters described in the tender announcement. Also in this case, the offers are ranked by there suitability.
In the second phase, the ranked list of all offers is checked. The first offer in the rank is selected in order to verify if it satisfies all the requisites required by the local government or not. If not, the process goes through the creation of a letter containing the request of providing the necessary clarifications. This letter is then sent to the recipient of the offerer. This check is done for all the ranked offers until it is found an offer that satisfies all the requisites.
After the decision related to which offer is the winner of the tender, the adjudication announcement is prepared. This document follows the internal work-flow and, based on the type of the tender, it is published on different places.
The two case studies differ both in terms of process model structure and data. The first case study involves 5 different actors and its BPMN model contains 18 tasks, 21 gateways, and 13 kinds of data objects (including in total 321 fields and 75 semantic fields) distributed across the 5 pools. The BPMN model of the second case study, in-stead, includes only one pool, that contains 35 tasks, 8 gateways, and 8 kinds of data objects (exposing in total 26 fields and the same number of semantic fields) and con-tains a cycle. Relevantly for our analysis, while the 13 different data objects of theBM
process are characterized by a high number of relationships among fields, no mapping among fields exists in theT Aprocess.
4.2 Experimental Setup
The evaluation process used in our work has been set up by following the steps de-scribed in the paragraphs below.
Path Extraction Both case studies contain more than one viable path that has to be
analyzed. By analyzing the processes with the domain experts, we have extracted all feasible paths in order to study the effectiveness of the SATFILLER tool in different
O bst et ric Pa re nt H osp ita l Mu ni ci pa lit y N at io na l F isca l D B
Fig. 2: A simplified view of the BPMN process model of theBMcase study.
contexts. In particular, we have extracted 4 paths from the Birth Management (BM) process, and 3 paths from the Tender Adjudication (TA) one. According to the BPMN models shown in Figure 2 and 3, the extracted paths are structured in the way explained below, based on some critical decisions that may occur during the execution of the processes:
– BM1: after performing the tasks related to the “Obstetric” pool, in the “Parent” pool, the path follows the upper branch. Therefore, the path continues in the “Mu-nicipality” pool and it finally enters in the “National Fiscal DB” pool. After the execution of the “National Fiscal DB” tasks, the path continues coming back to the “Hospital” pool.
– BM2: this path is a variant on a XOR gateway of the “Hospital” pool.
– BM3: this path follows the lower branch in the “Parent” pool and it executes the “Hospital” pool before the “Municipality” one, where it ends.
– BM4: this path is a variant of the previous one, on a XOR gateway.
– T A1: this path follows the upper branch of the first “XOR” gateway, it does not enter into the loop and it goes directly in the final part of the process.
– T A2: follows the same branch ofT A1but it executes the loop before going into the final part of the process.
– T A3: this path follows the lower branch of the first “XOR” gateway, it executes the loop, and then it ends.
Fig. 3: A simplified view of the BPMN process model of theT Acase study.
Trace Generation In order to evaluate the proposed approach, we generated, for each
path, the associated complete trace and a set of traces identical to the complete one but incomplete, reflecting missing knowledge at different points. In detail, defined aholean executed activity (with associated output) missing/not logged in a trace, for each path, we injected holes in the corresponding complete trace and generated incomplete traces with different missing (with respect to the complete trace) activities. Assuming that a complete trace of a given pathPcontains a number of traceable activities equal tok, we generatedk−2sets of traces, such that theithset containsiholes inserted randomly,
wherei= 1...(k−1).
Metrics Computation In order to answer the research questions introduced at the
be-ginning of this section, we analyzed, for each incomplete trace extracted as reported above, two main factors: the number of filled holes (RQ1) and the number of solutions returned by theSATFILLER(RQ2). For both of them we computed precision and recall. In detail, to answer the first research question we computed precision and recall for evaluating the capability ofSATFILLERto fill holes in a trace as follows:
ph=
#CORRECTLY FILLED HOLES
#FILLED HOLES
rh=
#CORRECTLY FILLED HOLES
#HOLES TO BE FILLED
To answer the second research question, instead, we computed precision and recall for evaluating the capability ofSATFILLERto retrieve possible complete traces (solu-tions) as follows:
ph=
#CORRECTLY RETRIEVED SOLUTNS
#RETRIEVED SOLUTNS rh=
#CORRECTLY RETRIEVED SOLUTNS
#CORRECT SOLUTNS
In both cases we used as gold standard the complete initial trace, in which we ran-domly injected holes, as explained above, for the specific evaluation purpose. Since, once correctly formalized, the approach either is able to correctly fill the holes, or it is not able to fill them at all,phis assumed to be1by construction. Similarly since only one correct solution is possible for our case studies, therswill also be 1 by construction.
4.3 Results
Table 3 and Table 4 report the results obtained for the BM and T Aprocesses, re-spectively. For each group of traces with the same number of holes, they provide the average values of (i) the number ofdata flow objects; (ii) the min, max and average
window size (i.e., number of consecutive missingdata flow objects) per trace; and (iii) the SATFILLER precision of solutions and recall related to holes. For the sake of the
discussion, we will consider 0.7 as a meaningful threshold forrh, representing the fact that, on average,SATFILLERis able to fill at least 70% of the initial holes; and 0.5 as a meaningful threshold forps, representing the fact that, on average,SATFILLERis able to return at most two alternative completions of the partial trace.
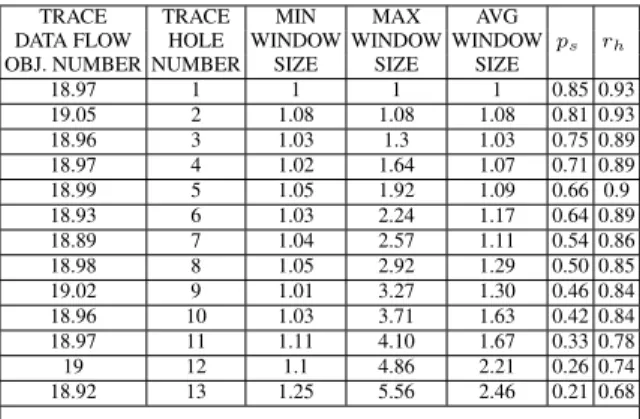
In detail, Table 3 shows that meaningful results in terms ofrhcan be obtained with traces containing up to 12 holes (about 63% of alldata flow objectsin the complete trace) and with, on average, more than 2 consecutive missing data flow objects. The values related to the precision of the returned solutions are overall lower than those related to therh.SATFILLERindeed is able to provide a meaningful number of solutions for traces containing up to 8 (possibly non-adjacent) holes (i.e., a number of missing
data flow objectsequal to about the 42% of the complete trace). Moving thepsthreshold
for the meaningful value from 0.5 to 0.33 (i.e., three alternative assignments are returned bySATFILLER), the meaningful number of solutions is also extended to traces with up to 11 missingdata flow objects(about 58% of the complete trace).
TRACE TRACE MIN MAX AVG
ps rh
DATA FLOW HOLE WINDOW WINDOW WINDOW OBJ. NUMBER NUMBER SIZE SIZE SIZE
18.97 1 1 1 1 0.85 0.93 19.05 2 1.08 1.08 1.08 0.81 0.93 18.96 3 1.03 1.3 1.03 0.75 0.89 18.97 4 1.02 1.64 1.07 0.71 0.89 18.99 5 1.05 1.92 1.09 0.66 0.9 18.93 6 1.03 2.24 1.17 0.64 0.89 18.89 7 1.04 2.57 1.11 0.54 0.86 18.98 8 1.05 2.92 1.29 0.50 0.85 19.02 9 1.01 3.27 1.30 0.46 0.84 18.96 10 1.03 3.71 1.63 0.42 0.84 18.97 11 1.11 4.10 1.67 0.33 0.78 19 12 1.1 4.86 2.21 0.26 0.74 18.92 13 1.25 5.56 2.46 0.21 0.68 ...
Table 3:Birth Management Processresults
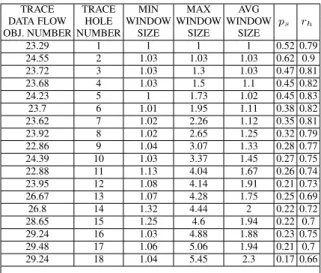
Table 4 shows that, also in case of theT Aprocess, meaningful values (higher than 0.7) ofrhcan be reached with a number of holes in the original trace up to 17 (about 57% of the wholedata flow objectsin the trace) and with average hole window sizes slightly greater than 2. The precision of the provided solutions, instead, is low: in order to get a meaningfulps (i.e.,ps > 0.5) no more than 2 (almost always non-adjacent) holes should occur in the trace; SATFILLER, instead, ensures a precision higher than 0.33 for traces with up to 7 holes. These low precision values can be mainly explained with the presence of cycles in the model that can be omitted in the execution. This is because, in such cases, one cannot distinguish, from the monitored data, whether the missing data flow objects in the cycle are due to a sequence of holes, or to the actual non-execution of the cycle. Omitting the traces following the path that does not
execute the cycle (T A1) and repeating the analysis above, we obtained improved results.
SATFILLER, indeed, returns on average 2 solutions (ps>0.5) for traces containing up
to 8 missing data flow objectsand three alternative solutions (ps > 0.33) for traces containing up to 11 holes (i.e., for traces missing about 30% and 38%data flow objects
with respect to the complete trace, respectively).
Summarizing, it seems that for a number of missingdata flow objectsin a trace up to about 60% of the whole number ofdata flow objects(in the trace) and for average hole windows size of about 2, theSATFILLERapproach is able to fill up to the 70% of initial holes. It is hence possible to positively answerRQ1: the SAT-reasoning based approach is effective in filling incomplete traces.
The answer to the second research question is instead more critical. It is possible to positively answerRQ2under the condition that mutual exclusive restrictions can be imposed on the model (e.g., the model does not contain cycles that can be factually omitted in the execution, or inclusive gateways). In this case, indeed, a meaningful number of alternative solutions is returned by theSATFILLERapproach. Results show
that with traces missing about the 30% and 40% of data flow objects for BM and
T A, respectively, theSATFILLERapproach is able, on average, to reduce the space of the returned solutions to 2; with traces missing more than half of thedata flow objects
(58%) forBMand almost 40% forT A, the number of solutions returned bySATFILLER
is on average 3.
It is interesting to notice that, even leaving out the structural differences due to cy-cles, differences still exist in the precision of the two case studies. Manually inspecting the traces, we found that such a difference stems from the greater amount of knowledge available in theBM process as a consequence of the higher number of relationships among data objects fields.
TRACE TRACE MIN MAX AVG
ps rh
DATA FLOW HOLE WINDOW WINDOW WINDOW OBJ. NUMBER NUMBER SIZE SIZE SIZE
23.29 1 1 1 1 0.52 0.79 24.55 2 1.03 1.03 1.03 0.62 0.9 23.72 3 1.03 1.3 1.03 0.47 0.81 23.68 4 1.03 1.5 1.1 0.45 0.82 24.23 5 1 1.73 1.02 0.45 0.83 23.7 6 1.01 1.95 1.11 0.38 0.82 23.62 7 1.02 2.26 1.12 0.35 0.81 23.92 8 1.02 2.65 1.25 0.32 0.79 22.86 9 1.04 3.07 1.33 0.28 0.77 24.39 10 1.03 3.37 1.45 0.27 0.75 22.88 11 1.13 4.04 1.67 0.26 0.74 23.95 12 1.08 4.14 1.91 0.21 0.73 26.67 13 1.07 4.28 1.75 0.25 0.69 26.8 14 1.32 4.44 2 0.22 0.72 28.65 15 1.25 4.6 1.94 0.22 0.7 29.24 16 1.03 4.88 1.88 0.23 0.75 29.48 17 1.06 5.06 1.94 0.21 0.7 29.24 18 1.04 5.45 2.3 0.17 0.66 ...
5
Findings
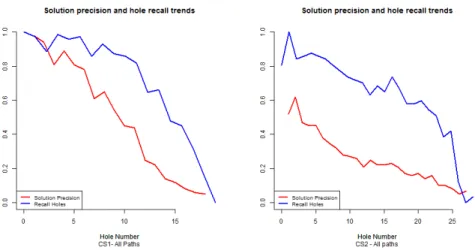
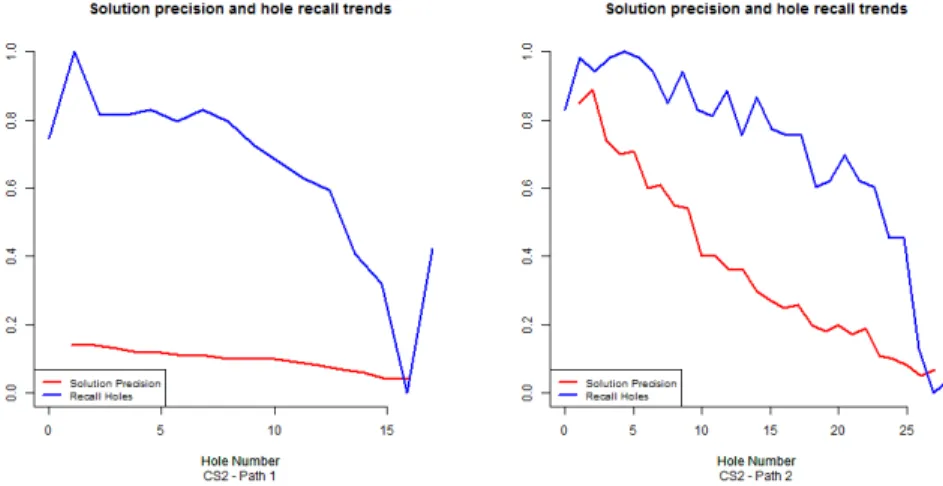
Figure 4 reports, for both the case studies, the trends ofpsandrhat increasing number of missingdata flow objectsin the trace. Differences in the effectiveness ofSATFILLER
in completing partial traces between theBMand theT Aprocesses are quite evident. The reasons behind these differences can be tracked to the differences between the two processes, both related to the process model control flow and to the management of data (as described in Section 4.1).
Fig. 4: Trends ofpsandrhinCS1andCS2
In detail, the impact of the cycle on such a difference can be grasped by looking at the trends ofpsandrhfor two different paths ofT A, both executing the same activities except for the cycle. Figure 5 shows the pair of trends for the two paths, on the left those of the path omitting the cycle and on the right those of the path executing the cycle. It is clear that, in case of models with cycles that can potentially be omitted, the precision is lowered down.
A further difference between the two case studies impacting on the overallpsand
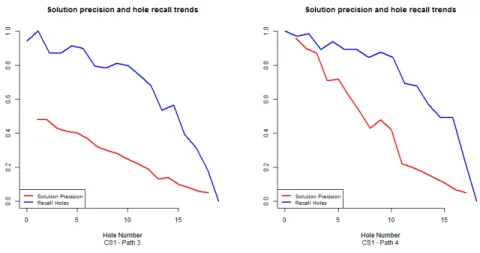
rh of solutions can be found in the relationships among data. Indeed, comparing the trends ofpsandrhofBM(Figure 4, left) with those of the only paths ofT Aexecuting the cycle at least once (Figure 6), still differences exist among the two case studies.
Besides these two aspects, other factors can influence the capability of the approach to complete partial traces and to reduce the solution space. Figure 7 reports the trends ofpsandrhof two different paths ofBM (BM3andBM4). The difference between the two paths relies on the execution of thedata flow objects in charge of generating the ID (fiscal code), that in theBMprocess model are two: “Generate ID APSS” and “Generate ID municipality”. In one path the first of them is not executed and the fiscal code is generated by the second. In the second path instead, the firstdata flow object
Fig. 5: Trends ofpsandrh: path without and with cycle execution
is executed and the fiscal code generated, while “Generate ID municipality” is not ex-ecuted. While in case the ID is not generated by the firstdata flow object,SATFILLER
is able to understand that, if the ID exists, it should have been generated by the second
data flow object, in the second case,SATFILLER, lacking the domain knowledge that
the ID can be generated by only onedata flow object, is unable to understand whether the seconddata flow objecthas been executed or not. Being aware of such a knowledge about the exclusiveness of the ID generation would have avoided the decrease inpsin the example.
This last example suggests the need to retrieve the critical points in the process that require acquiring knowledge, that cannot be obtained by only looking at the model, but that needs to be gathered from the experts of the domain.
Fig. 7: Trends ofpsandrh: paths differing for the execution of twodata flow objects
Summarizing, our experiments give some lessons about the applicability of the pro-posed SAT-based reasoning approach to the problem of completing partial traces:
– Process model structure impacts on the effectiveness and usability of the approach. Indeed, process models in which mutual exclusion constraints can be imposed per-mits to reach interesting results both in terms ofpsandrh (whileph=rs= 1 by construction). In the opposite case, when optional execution branches (be they due to loops or to alternatives) are not observed at all, less precise results are produced. This is just natural since, in this latter case, it is impossible to distinguish whether the branch has not been executed, or it has but all its observations are missing; our complete approach hence proposes both. Several mitigations are possible and left for future investigations.
– Data management impacts on the effectiveness and usability of the approach. Pre-cision related to returned solutions and recall in terms of filled holes are higher in processes with highly related data objects (as in the case ofBM).
– Extra knowledge gathered from domain experts may have a significant positive impact on the effectiveness and usability of the approach, increasing both theps
andrhvalues.
Moreover, the approach provides a preliminary step towards the definition of a framework on top of which building thresholds and empirical measures for evaluat-ing how good models and data are for completevaluat-ing traces. Indeed, the results of the two case studies suggest only preliminary thresholds (about 60% of trace incompleteness and at most 8 missingdata flow objects) that need of course to be validated by further analyses and case studies.
6
Related Works
In this work, we deal with the monitoring of activities of business processes, tackling the issue of incompleteness of the information made available from the IT implemen-tation of processes. As such, our work is near to industrial approaches to BAM such as those implemented in the Oracle, IBM, Eclipse suites. As discussed in the introduction, however, all of these tools simply discard the issue, and assume that the business ana-lyst can link directly IT information to business process activities. While this lends to a simple model and design, of course, it is an unsatisfactory response to the actual issue. The problem of incomplete traces has been faced also in the field of process mining and in particular of process discovery. The notion of incompleteness of traces, firstly introduced by van der Aalst et al. [12] as the “lack of sufficient information to derive the process”, has been evolved e.g., introducing notions of global and local complete-ness [13] (requiring that all possible behaviours are recorded in logs or demanding for other specific assumptions on completeness, respectively) and still represents one of the challenges in the process mining field [14]. Although most of the process discov-ery algorithms make assumptions on the (global and/or local) completeness [13] of the logs, some approaches have been proposed to deal with incomplete logs. For exam-ple, De Medeiros et al [15] apply genetic process mining in order to be able to deal with noise and incompleteness. More recently, the interest for the evaluation of log completeness, in the perspective of the applicability of process discovery techniques, has been growing [16,17,18]. Some of the works deal with global incompleteness [16], while others [17,18] propose probabilistic approaches to local completeness estimating the degree of completeness [18] of logs. However, the goal of our work is not process discovery, but completing traces to e.g., make them available for statistical analysis on past executions, and therefore it is based on a different notion of incompleteness of traces.
At the technical level, our approach can be percived as an application of satisfia-bility checking, and bears conceptual commonalities both to works in the area of SAT modulo theory, and to SAT-based planning [4,3]. However our SAT encoding has spe-cific features that differ from those adopted in planning. They stem, in part, from the different view of system dynamics given by the problem: while in the case of planning the task is to build an unknown dynamics (of unknown bounded length), in our case, the task is to complete a given partial dynamics obeying given constraints. This brings to a simplified and effective encoding where no rule unfolding is considered. Further,
the injection of domain knowledge that originates from the relatinship amon (stateful) documents has no direct correspondence in the abovementioned approaches, while it is a core part of ours.
7
Conclusion
This technical report aims at supporting business analysis activities by tackling the lim-itations due to the partiality of information often characterizing the business activity monitoring. To this purpose, a novel reasoning method for reconstructing incomplete execution traces, that relies on the formulation of the issue in terms of the satisfiability problem, is presented. The approach, implemented in theSATFILLERtool, has been ap-plied to two different case studies. The lessons learned from the evaluation (i) suggest that the proposed approach is viable; (ii) relying on the implemented framework, pro-vide a first set of thresholds and empirical measures for evaluating how good models and data are for completing traces with a SAT-based technique.
In the future, we plan to improve the proposed approach by extending it to fur-ther data relations (e.g., dependencies among data) and to consider also data deletion operations. Another interesting area of research may address the problem of optional execution branches. Here, we aim at investigation how to mitigate the problem of dis-tinguishing whether the branch has not been executed, or it has but all its observations are missing in various ways, e.g. by taking the assumption that whole process branches should be at least partially observable, with a trade-off on the set of traces we are able to deal with, or by adding heuristics on the optional executions, with a trade-off on the completeness of the produced models. Moreover, we would like to exploit the eval-uation framework applying it to other case studies in order to provide more detailed guidelines for identifying good trade-offs between types of model and data knowledge and the effectiveness of the approach.
References
1. Cimatti, A., Pistore, M., Roveri, M., Traverso, P.: Weak, strong, and strong cyclic planning via symbolic model checking. Artif. Intell.147(2003) 35–84
2. Bertoli, P., Cimatti, A., Roveri, M., Traverso, P.: Planning in nondeterministic domains under partial observability via symbolic model checking. In: Proc. of the 17th Int. joint conference on Artificial intelligence - Vol. 1. (2001) 473–478
3. Rintanen, J., Heljanko, K., Niemel¨a, I.: Planning as satisfiability: parallel plans and algo-rithms for plan search. Artif. Intell.170(2006) 1031–1080
4. Kautz, H.A., Selman, B.: Pushing the envelope: Planning, propositional logic and stochastic search. In Clancey, W.J., Weld, D.S., eds.: AAAI/IAAI, Vol. 2, AAAI Press / The MIT Press (1996) 1194–1201
5. Bertoli, P., Cimatti, A., Roveri, M., Traverso, P.: Strong planning under partial observability. Artif. Intell.170(2006) 337–384
6. Yan, Y., Dague, P., Pencol´e, Y., Cordier, M.O.: A model-based approach for diagnosing fault in web service processes. Int. J. Web Service Res.6(2009) 87–110
7. Ernst, M.D., Millstein, T.D., Weld, D.S.: Automatic sat-compilation of planning problems. In: Proc. of the 15th Int. Joint Conference on Artificial Intelligence. (1997) 1169–1177
8. Davis, M., Putnam, H.: A computing procedure for quantification theory. Journal of the ACM7(1960) 201–215
9. Bonet, B., Geffner, H.: Planning with Incomplete Information as Heuristic Search in Belief Space. In: Proc. of AIPS’00. (2000) 52–61
10. Bacchus, F., Petrick, R.: Modeling an Agents Incomplete Knowledge during Planning and Execution. In: Proc. of KR’08. (2008) 432–443
11. Kautz, H.A., Selman, B.: Planning as satisfiability. In: ECAI. (1992) 359–363
12. van der Aalst, W.M.P., Weijters, A.J.M.M.: Process mining: a research agenda. Comput. Ind.53(2004) 231–244
13. Dongen, B., Alves de Medeiros, A., Wen, L.: Process mining: Overview and outlook of petri net discovery algorithms. In Jensen, K., Aalst, W., eds.: Transactions on Petri Nets and Other Models of Concurrency II. Volume 5460 of Lecture Notes in Computer Science. Springer Berlin Heidelberg (2009) 225–242
14. Aalst, W.M.P.v.d.e.a.: Process mining manifesto. In: BPM 2011 Workshops, Part I. Vol-ume 99., Springer-Verlag (2012) 169–194
15. Medeiros, A.K.A.D., Weijters, A.J.M.M.: Genetic process mining. In: Applications and Theory of Petri Nets 2005, volume 3536 of Lecture Notes in Computer Science, Springer-Verlag (2005) 48–69
16. H. Yang, A.H.M. ter Hofstede, B.v.D.M.W., Wang, J.: On global completeness of event logs. (Technical report)
17. Van Hee, K., Liu, Z., Sidorova, N.: Is my event log complete? - a probabilistic approach to process mining. In: Research Challenges in Information Science (RCIS), 2011 Fifth Inter-national Conference on. (2011) 1–12
18. Yang, H., Wen, L., Wang, J.: An approach to evaluate the local completeness of an event log. In: Data Mining (ICDM), 2012 IEEE 12th International Conference on. (2012) 1164–1169
![{2,7 Diethoxy 8 [(naphthalen 1 yl)carbonyl]naphthalen 1 yl}(naphthalen 1 yl)methanone](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)