CHAPTER 2
D
IRECT
M
ETHODS FOR
S
TOCHASTIC
S
EARCH
•Organization of chapter in ISSO
–Introductory material –Random search methods
•Attributes of random search •Blind random search (algorithm A)
•Two localized random search methods (algorithms B and C)
–Random search with noisy measurements
–Nonlinear simplex (Nelder-Mead) algorithm
•Noise-free and noisy measurements
Slides for Introduction to Stochastic Search and Optimization (ISSO) by J. C. Spall
Some Attributes of Direct Random Search
with Noise-Free Loss Measurements
• Three random search algorithms discussed in ISSO— algorithms A (blind random search), B, and C—share desirable attributes:
• Ease of programming
• Use of onlyLvalues (vs. gradient values)
– Avoid “artful contrivance” of more complex methods
• Reasonable computational efficiency • Generality
– Algorithms apply to virtually any function
• Theoretical foundation
2
2-3
Formal Convergence of Random
Search Algorithms
• Well-known results on convergence of random search
– Applies to convergence of and/or L
– Applies when noise-freeLmeasurements used in algorithms
• Algorithm A (blind random search) converges under very general conditions
– Applies to continuous or discrete functions
• Conditions for convergence of algorithms B and C somewhat more restrictive, but still quite general
– ISSOpresents theorem for continuous functions – Other convergence results exist
• Convergence ratetheory also exists: how fast to converge?
– Algorithm A generally slow in high-dimensional problems
2-4
Algorithm A:
Simple (“Blind”) Random Search
Step 0 (initialization) Choose an initial value of inside of . Set k= 0.
Step 1 (candidate value)Generate a new
independent value new(k+1) , according to the chosen probability distribution. If L(new(k+1)) < set = new(k+1). Else take
Step 2 (return or stop) Stop if maximum number ofL
evaluations has been reached or user is otherwise satisfied with the current estimate for ; else, return to step 1 with the new k set to the former k+1.
0
ˆ
ˆ
(
k),
L
ˆ
12-5
First Several Iterations of Algorithm A on
Problem with Constraints and Quadratic
Loss Function (Example 2.1 in ISSO)
Iteration k new(k)
T
L(new(k)) ˆTk L(ˆk)
0 [2.00, 2.00] 8.00
1 [2.25, 1.62] 7.69 [2.25, 1.62] 7.69
2 [2.81, 2.58] 14.55 [2.25, 1.62] 7.69
3 [1.93, 1.19] 5.14 [1.93, 1.19] 5.14
4 [2.60, 1.92] 10.45 [1.93, 1.19] 5.14
5 [2.23, 2.58] 11.63 [1.93, 1.19] 5.14
6 [1.34, 1.76] 4.89 [1.34, 1.76] 4.89
• Simple quadratic loss function L() = Ton domain = [1,3][1,3]
– Unique value = [1,1]Twith L() = 2.0
Global Convergence of Algorithm A
• Theorem 2.1 (Sect. 2.2 of ISSO) shows almost sure (a.s.) convergence of algorithm A to under three key conditions
– Theorem uses concept of infimum(inf) of a function: greatest lower boundon specified domain
4
2-7
(a)Continuous L(); probability density for
newis > 0 on = [0, )
(b)Discrete L(); discrete sampling for newwith P(new= i) > 0 fori = 0, 1, 2,...
(c)Noncontinuous L(); probability density for new is > 0 on = [0, )
Functions for Convergence and
Nonconvergence of Algorithm A
(Blind Random Search)
• Functions that do ((a) and (b) below) or do not ((c) below) satisfy condition (2.2) of Theorem 2.1:
2-8
Algorithm B:
Localized Random Search
Step 0 (initialization) Choose an initial value of inside of . Set k= 0.
Step 1 (candidate value)Generate a random dk. Check if
. If not, generate new dkor move to nearest valid point. Let new(k+1) be or the modified point.
Step 2 (check for improvement) If L(new(k+1)) < set = new(k+1). Else take = .
Step 3 (return or stop) Stop if maximum number ofL
evaluations has been reached or if user satisfied with current estimate; else, return to step 1 with new kset to former k+1.
0 ˆ
ˆ
(
k),
L
ˆ 1
k
ˆ
k
d
k
ˆ
k
d
k
ˆ
k
d
k
ˆ
12-9
Comments on Algorithm B
• Algorithm B useful in many practical problems: easy to apply with reasonable efficiency when p> 1 (even p >> 1)
• Relative to algorithm A, search in algorithm B more localized in neighborhood of current estimate
– Better exploitation of information acquired about shape of L()
– “Localized” terminology not to be confused with global vs. local algorithms discussed in Chapter 1
• Algorithm B finds global optimum (“in probability”) per Theorem 2.2 in ISSO
• User free to set distribution of deviation vector dk although
N(0,2I
p) is most common in continuous problems
– Distribution should have mean zero and each component should have variation (e.g., standard deviation) consistent with magnitudes of corresponding components in
• Often better if variability of dk reduced as k increases
Algorithm C:
Enhanced Localized Random Search
• Similar to algorithm B
• Exploits knowledge of good/bad directions
• If move in one direction produces decreasein loss, add bias to next iteration to continuealgorithm moving in “good” direction
• If move in one direction produces increasein loss, add bias to next iteration to move algorithm in oppositeway
6
2-11
Examples 2.3 and 2.4 in ISSO:
Comparison of Algorithms A, B, and C
• Relatively simple p= 2 problem used elsewhere (Styblinski and Tang, 1990) to test simulated annealing algorithms
– Quartic loss function (plot on next slide)
• One global solution; several local minima/maxima
• Started all algorithms at common initial condition and compared based on common number of loss evaluations
– Algorithm A needed no tuning
– Algorithms B and C required “trial runs” to tune algorithm coefficients
2-13
Examples 2.3 and 2.4 in ISSO (cont’d):
Sample Means of Terminal Values
– L
(
)
in Multimodal Loss Function
(with Approximate 95% Confidence Intervals)
ˆ
(
k)
L
Notes:
Each sample mean is from 40 independent runs of relevant algorithm
Confidence intervals for algorithms B and C overlap slightly since 0.51 < 0.67
Examples 2.3 and 2.4 in ISSO (cont’d):
Typical Adjusted Loss Values ( – L
(
)
)
and Estimates of
in Multimodal
Loss Function (One Typical Run)
ˆ
(
k)
8
2-15
Random Search Algorithms with Noisy
Loss Function Measurements
• Basic implementation of random search above assumes perfect (noise-free) values of L
• Some applications require use of noisymeasurements:
y() = L() + noise
• Simplest modification is to form average of y values at each iteration as approximation to L
• Alternative modification is to set threshold > 0 for improvement before new value is accepted in algorithm • Thresholding in algorithm B with modified step 2:
Step 2 (modified) If y(new(k+1)) < set = new(k+1). Else take = .
• Very limited convergence theory with noisy measurements
– In fact, random search generally nonconvergentwith noisy loss measurements
ˆ
(
k)
,
y
ˆ
1k
ˆ
k1
ˆ
k2-16
Nonlinear Simplex (Nelder-Mead) Algorithm
• Nonlinear simplex method is popular search method (e.g., fminsearch in MATLAB)
• Simplex is convex hullof p + 1 points in p
– Convex hull is smallest convex set enclosing the p + 1 points – Forp= 2 convex hull is triangle
– For p= 3 convex hull is pyramid
• Algorithm searches for by moving convex hull within
• If algorithm works properly, convex hull shrinks/collapses onto
• No injected randomness (contrast with algorithms A, B, and C), but allowance for noisy loss measurements
2-17
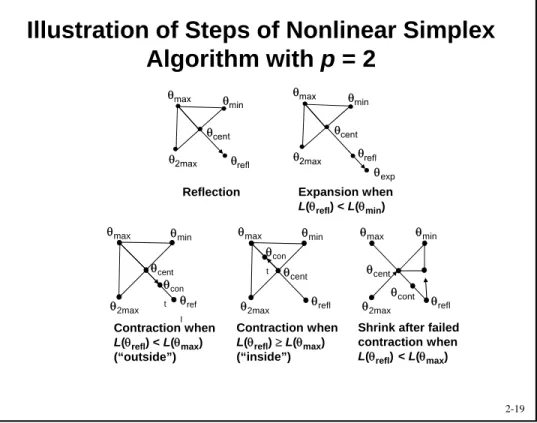
Steps of Nonlinear Simplex Algorithm
Step 0 (Initialization) Generate initial set of p+ 1 extreme points in p, i(i= 1, 2, …,p + 1), vertices of initial simplex
Step 1 (Reflection) Identify where max, second highest, and min loss values occur; denote them by max, 2max, and min, respectively. Let cent = centroid (mean) of all i except for
max. Generate candidate vertex reflby reflecting max through
cent using refl= (1 + )cent max (> 0).
Step 2a (Accept reflection) If L(min) L(refl) < L(2max), then
reflreplaces max; proceed to step 3; else go to step 2b.
Step 2b (Expansion) If L(refl) < L(min), then expand reflection using exp= refl+ (1 )cent, > 1; else go to step 2c. If
L(exp) < L(refl), then expreplaces max; otherwise reject expansion and replace max by refl. Go to step 3.
Steps of Nonlinear Simplex Algorithm (cont’d)
Step 2c (Contraction) If L(refl) L(2max), then contract simplex: Either case (i) L(refl) < L(max), or case (ii) L(max)
L(refl). Contraction point is cont= max/refl+ (1 )cent, 0
1, where max/refl= reflif case (i), otherwise max/refl= max. In case (i), accept contraction if L(cont) L(refl); in case (ii),
accept contraction if L(cont) < L(max). If accepted, replace
maxby contand go to step 3; otherwise go to step 2d.
Step 2d (Shrink) If L(cont) L(max), shrink entire simplex using a factor 0 < < 1, retaining only min. Go to step 3.
Step 3 (Termination) Stop if convergence criterion or
10
2-19
Illustration of Steps of Nonlinear Simplex
Algorithm with p = 2
Reflection
exp Expansion when
L(refl) < L(min)
max min
cent
refl
con t
max min
refl
cont
cent
2max
Contraction when
L(refl) L(max) (“inside”)
Shrink after failed contraction when
L(refl) < L(max)
con t
max min
cent
ref l
Contraction when
L(refl) < L(max) (“outside”)