arXiv:2012.01194v1 [math.NA] 2 Dec 2020
Deep learning based numerical approximation
algorithms for stochastic partial differential equations
and high-dimensional nonlinear filtering problems
Christian Beck
1, Sebastian Becker
2, Patrick Cheridito
3,
Arnulf Jentzen
4,5, and Ariel Neufeld
61 Department of Mathematics, ETH Zurich,
Switzerland, e-mail: [email protected]
2 RiskLab, Department of Mathematics, ETH Zurich,
Switzerland, e-mail: [email protected]
3 RiskLab, Department of Mathematics, ETH Zurich,
Switzerland, e-mail: [email protected]
4 Faculty of Mathematics and Computer Science, University of M¨unster
Germany, e-mail: [email protected]
5 Department of Mathematics, ETH Zurich
Switzerland, e-mail: [email protected]
6 Division of Mathematical Sciences, School of Physical and Mathematical Sciences,
Nanyang Technological University, Singapore, e-mail: [email protected]
Thursday 3
rdDecember, 2020
Abstract
In this article we introduce and study a deep learning based approximation al-gorithm for solutions of stochastic partial differential equations (SPDEs). In the proposed approximation algorithm we employ a deep neural network for every real-ization of the driving noise process of the SPDE to approximate the solution process of the SPDE under consideration. We test the performance of the proposed ap-proximation algorithm in the case of stochastic heat equations with additive noise, stochastic heat equations with multiplicative noise, stochastic Black–Scholes equa-tions with multiplicative noise, and Zakai equaequa-tions from nonlinear filtering. In each of these SPDEs the proposed approximation algorithm produces accurate results with short run times in up to 50 space dimensions.
Keywords: stochastic partial differential equation, numerical method, artificial neural network, nonlinear filtering, Zakai equation
Contents
1 Introduction 3
2 Derivation and description of the proposed approximation algorithm 4
2.1 Temporal approximations . . . 5
2.2 An approximate Feynman-Kac type representation . . . 7
2.3 Formulation as iterative recursive minimization problems . . . 11
2.4 Deep neural network approximations . . . 12
2.5 Stochastic gradient descent based minimization . . . 14
2.6 Temporal discretization of the auxiliary stochastic process . . . 14
2.7 Description of the proposed approximation algorithm in a special case . . . 17
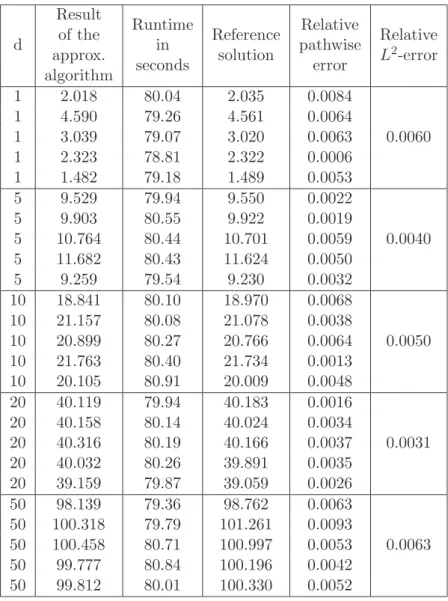
2.8 Description of the proposed approximation algorithm in the general case . 19 3 Examples 20 3.1 Stochastic heat equations with additive noise . . . 22
3.2 Stochastic heat equations with multiplicative noise . . . 23
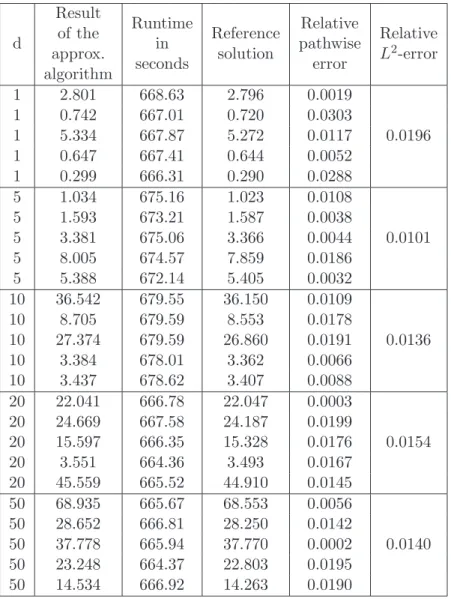
3.3 Stochastic Black–Scholes equations with multiplicative noise . . . 26
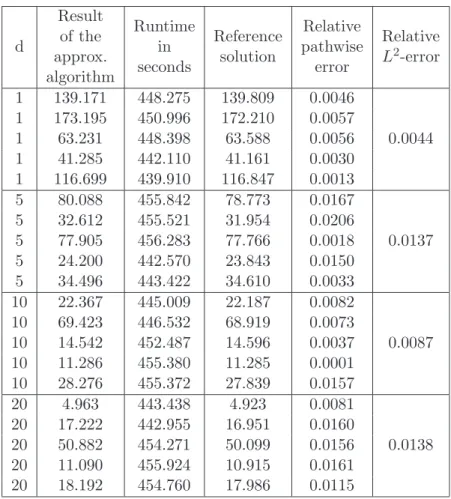
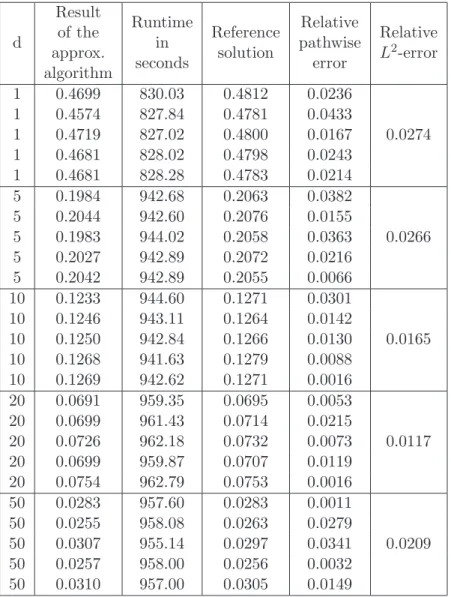
3.4 Zakai equations . . . 34
4 Python source codes for the proposed approximation algorithm 38 4.1 A Python source code associated to Subsection 3.1 . . . 41
4.2 A Python source code associated to Subsection 3.2 . . . 42
4.3 A Python source code associated to Subsection 3.3 . . . 44
1
Introduction
Stochastic partial differential equations (SPDEs) are key ingredients in numerous models in engineering, finance, and natural sciences. For example, SPDEs commonly appear in models to price interest-rate based financial derivatives (cf., for example, (1.3) in Filipovi´c et al. [34] and Theorem 3.5 in Harms et al. [49]), to describe random surfaces appear-ing in surface growth models (cf., for example, (3) in Hairer [46] and (1) in Bl¨omker & Romito [15]), to describe the temporal dynamics in Euclidean quantum field theories (cf., for example, (1.1) in Mourrat & Weber [85]), to describe velocity fields in fully developed turbulent flows (cf., for example, (1.5) in Birnir [14] and (7) in Birnir [13]), and to describe the temporal development of the concentration of an unwanted (biological or chemical) contaminant in water (e.g., in the groundwater system, in a river, or in a water basin; cf., for example, (2.2) in Kallianpur & Xiong [63] and (1.1) in Kouritzin & Long [69]). Another prominent situation where SPDEs such as the Kushner equation (cf., for exam-ple, Kushner [75]) and the Zakai equation (cf., for examexam-ple, Zakai [105]) appear is in the case of nonlinear filtering problems where SPDEs describe the density of the state space of the considered system. In particular, we refer, e.g., to [16, 21, 25, 29, 36, 37] for filtering problems in financial engineering, we refer, e.g., to [18, 24, 94, 95, 98, 103] for filtering problems in chemical engineering, and we refer, e.g., to [28, 19, 20, 23, 33, 89] for filtering problems in weather forecasting. SPDEs arising in nonlinear filtering problems are usu-ally high-dimensional as the number of dimensions corresponds to the state space of the considered filtering problem. Most of the SPDEs in the above named applications cannot be solved explicitly and for about 30 years it has been an active field of research to design and study numerical algorithms which can approximatively compute solutions of SPDEs.
In order to be able to implement an approximation scheme for evolutionary type SPDEs on a computer both the time interval [0, T] as well as the infinite dimensional state space have to be discretized. Several types of temporal discretizations and spatial discretizations have been proposed and studied in the scientific literature. In particular, we refer, e.g., to [26, 41, 52, 96, 99, 104] for temporal discretizations based on the linear implicit Euler method, we refer, e.g., to [55, 60, 81, 87, 102] for temporal discretizations based on expo-nential Euler-type methods, we refer, e.g., to [50, 51, 96, 99] for temporal discretizations based on linear implicit Crank–Nicolson-type methods, we refer, e.g., to [1, 9, 12, 35, 44, 76] for temporal discretizations based on splitting up approximation methods, we refer, e.g., to [58, 62, 71, 92, 101] for temporal discretizations based on higher order approximation methods, we refer, e.g., to [17, 38, 64, 70, 80, 99, 104] for spatial discretizations based on finite elements methods, we refer, e.g., to [45, 83, 90, 93, 96, 100] for spatial discretizations based on finite differences methods, and we refer, e.g., to [39, 51, 68, 79, 88, 86] for spatial discretizations based on spectral Galerkin methods. Moreover, the recent article [106] em-ploys deep neural networks to approximately solve some one-dimensional SPDEs. We also refer to the overview articles [42, 59] and to the monographs [61, 72] for further references on numerical approximation methods for SPDEs.
In this article we introduce and study a deep learning based approximation algorithm for approximating solutions of possibly high-dimensional SPDEs. In the proposed approxi-mation algorithm we employ a deep neural network for every realization of the driving noise process of the SPDE to approximate the solution process of the SPDE under consideration. The derivation of the proposed approximation scheme is inspired by the ideas in the articles [2, 3, 48] in which deep learning based algorithms for high-dimensional PDEs have been proposed and studied. We also refer, e.g., to [4, 11, 22, 30, 31, 32, 53, 54, 57, 91, 97] and the references therein for further articles on deep learning based approximation methods for PDEs. We test the performance of the approximation algorithm proposed in this article in the case of stochastic heat equations with additive noise (see Subsection 3.1 below), stochastic heat equations with multiplicative noise (see Subsection 3.2 below), stochastic Black–Scholes equations with multiplicative noise (see Subsection 3.3 below), and Zakai equations from nonlinear filtering (see Subsection 3.4 below). In each of these SPDEs the proposed approximation algorithm produces accurate results with short run times in up to 50 space dimensions.
The remainder of this paper is organized as follows. In Section 2 we derive (see Subsec-tions 2.1–2.6 below) and formulate (see SubsecSubsec-tions 2.7–2.8 below) the proposed approxi-mation algorithm for SPDEs. In Section 3 we test the performance of the proposed approx-imation algorithm (see Subsection 2.8 below) in the case of stochastic heat equations with additive noise (see Subsection 3.1 below), stochastic heat equations with multiplicative noise (see Subsection 3.2 below), stochastic Black–Scholes equations with multiplicative noise (see Subsection 3.3 below), and Zakai equations (see Subsection 3.4 below). In Sec-tion 4 we present the Python source codes which we have used for the numerical simulaSec-tions in Section 3.
2
Derivation and description of the proposed
approx-imation algorithm
Let T ∈ (0,∞), d ∈ N, let ϕ: Rd → R be a continuous function, let (Ω,F,P) be a
probability space with a normal filtration (Ft)t∈[0,T] (cf., e.g., Liu & R¨ockner [78,
Defi-nition 2.1.11]), let Z: [0, T]×Rd×Ω → R be a sufficiently regular random field which satisfies for every x ∈ Rd that (Zt(x))t∈[0,T]: [0, T]×Ω → R is an (Ft)t∈[0,T]-Itˆo process, let µ: Rd → Rd, f: Rd ×R×Rd → R, and b: Rd×R×Rd → R be sufficiently regu-lar functions, let σ: Rd → Rd×d be a sufficiently regular and sufficiently non-degenerate function, and let X: [0, T]× Rd× Ω → R be a random field which satisfies for every
t ∈ [0, T], x ∈ Rd that Xt(x) : Ω → R is Ft/B(R)-measurable, which satisfies for every
partial derivatives, and which satisfies1 that for everyt∈[0, T],x∈Rd it holds
P-a.s. that Xt(x) =ϕ(x) +
Z t
0
f x, Xs(x),(∇Xs)(x)
ds+
Z t
0
b x, Xs(x),(∇Xs)(x)
dZs(x)
+
Z t
0
h
1
2Trace σ(x)[σ(x)]
∗(HessX
s)(x)
+
µ(x),(∇Xs)(x)
Rd
i
ds.
(1)
Our goal is to approximately calculate under suitable hypothesis the solution process
X: [0, T]×Rd×Ω→Rof the SPDE (1).
2.1
Temporal approximations
In this subsection we discretize the SPDE (1) in time by employing the splitting-up method (cf., for example, [8, 10, 40, 43, 44, 76]) to obtain a semi-discrete approximation problem. To this end let N ∈N, t0, t1, . . . , tN ∈[0, T] be real numbers with
0 =t0 < t1 < . . . < tN =T. (2)
Observe that (1) yields that for every n∈ {0,1, . . . , N −1}, t ∈[tn, tn+1], x ∈Rd it holds
P-a.s. that
Xt(x) =Xtn(x) +
Z t
tn
f x, Xs(x),(∇Xs)(x)
ds+
Z t
tn
b x, Xs(x),(∇Xs)(x)
dZs(x)
+
Z t
tn
h
1
2Trace σ(x)[σ(x)]
∗(HessX
s)(x)
+
µ(x),(∇Xs)(x)
Rd
i
ds.
(3)
This illustrates for every n ∈ {0,1, . . . , N −1}, t∈[tn, tn+1],x∈Rd that
Xt(x)≈Xtn(x)
+
Z tn+1
tn
f x, Xtn(x),(∇Xtn)(x)
ds+
Z tn+1
tn
b x, Xtn(x),(∇Xtn)(x)
dZs(x)
+
Z t
tn
h
1
2 Trace σ(x)[σ(x)]
∗(HessX
s)(x)
+
µ(x),(∇Xs)(x)
Rd
i
ds.
(4)
This, in turn, suggests for every n ∈ {0,1, . . . , N −1}, t∈[tn, tn+1], x∈Rd that
Xt(x)≈Xtn(x) +f x, Xtn(x),(∇Xtn)(x)
(tn+1−tn)
+b x, Xtn(x),(∇Xtn)(x)
Ztn+1(x)−Ztn(x)
+ Z t tn h 1
2 Trace σ(x)[σ(x)]
∗(HessX
s)(x)
+
µ(x),(∇Xs)(x)
Rd
i
ds.
(5)
1Note that for every d, m∈N and every (d×m)-matrix A ∈Rd×m
it holds that A∗
∈ Rm×d is the transpose ofA.
To derive the splitting-up approximation let U: (0, T]×Rd×Ω → R be a random field which satisfies for every ω ∈ Ω, n ∈ {0,1, . . . , N −1} that (Ut(x, ω))(t,x)∈(tn,tn+1]×Rd ∈
C1,2((t
n, tn+1]×Rd,R) has at most polynomially growing partial derivatives, which satisfies
for everyω ∈Ω,x∈RdthatRT
0 k(HessUs)(x, ω)kRd×d+k(∇Us)(x, ω)kRdds <∞, and which
satisfies that for every n∈ {0,1, . . . , N −1},t ∈(tn, tn+1], x∈Rd it holdsP-a.s. that Ut(x) =Xtn(x) +f(x, Xtn(x),(∇Xtn)(x)) (tn+1−tn)
+b(x, Xtn(x),(∇Xtn)(x)) (Ztn+1(x)−Ztn(x))
+
Z t
tn
h
1
2Trace σ(x)[σ(x)]
∗(HessU
s)(x)
+
µ(x),(∇Us)(x)
Rd
i
ds.
(6)
Note that (5) and (6) suggest for every n ∈ {1,2, . . . , N}, x∈Rd that
Utn(x)≈Xtn(x). (7)
Next let V : [0, T] ×Rd × Ω → R be a random field which satisfies for every ω ∈ Ω,
n ∈ {0,1, . . . , N −1} that (Vt(x, ω))(t,x)∈(tn,tn+1]×Rd ∈ C
1,2((t
n, tn+1]×Rd,R) has at most
polynomially growing partial derivatives, which satisfies for every ω ∈ Ω, x ∈ Rd that
RT
0 k(HessVs)(x, ω) kRd×d +k(∇Vs)(x, ω)kRdds < ∞, and which satisfies for every n ∈
{0,1, . . . , N −1}, t∈(tn, tn+1],x∈Rd that V0(x) =ϕ(x) and
Vt(x) =Vtn(x) +f(x, Vtn(x),(∇Vtn)(x)) (tn+1−tn)
+b(x, Vtn(x),(∇Vtn)(x)) (Ztn+1(x)−Ztn(x))
+
Z t
tn
h
1
2Trace σ(x)[σ(x)]
∗(HessV
s)(x)
+
µ(x),(∇Vs)(x)
Rd
i
ds
(8)
(cf., for example, Deck & Kruse [27], Hairer et al. [47, Section 4.4], Krylov [73, Chapter 8], and Krylov [74, Theorem 4.32] for existence, uniqueness, and regularity results for (6) and (8)). Note that (6) and (8) suggest for every n ∈ {1,2, . . . , N}, x∈Rd that
Vtn(x)≈Utn(x). (9)
Combining this with (7), in turn, suggests for every n∈ {1,2, . . . , N}, x∈Rd that
Vtn(x)≈Xtn(x). (10)
Observe that the random field V is a specific splitting-up type approximation for the random field X (cf., for example, [8, 10, 40, 43, 44, 76]). In the next subsection we derive a Feynman-Kac representation for V given Z (cf., for example, Milstein & Tretjakov [84, Section 2]).
2.2
An approximate Feynman-Kac type representation
In this subsection we derive a Feynman-Kac representation forV givenZ. More specifically, for every sufficiently regular function z: [0, T]×Rd →R let V(z): [0, T]×Rd→ R satisfy for every n ∈ {0,1, . . . , N − 1} that (Vt(z)(x))(t,x)∈(tn,tn+1]×Rd ∈ C
1,2((t
n, tn+1] × Rd,R)
has at most polynomially growing partial derivatives, which satisfies for every x ∈ Rd that RT
0 k(HessV (z)
s )(x)kRd×d+k(∇Vs(z))(x)kRdds < ∞, and which satisfies for every n ∈
{0,1, . . . , N −1}, t∈(tn, tn+1], x∈Rd that V0(z)(x) =ϕ(x) and
Vt(z)(x) =V (z)
tn (x) +f(x,V
(z)
tn (x),(∇V
(z)
tn )(x)) (tn+1−tn)
+b(x,Vt(z)n (x),(∇V
(z)
tn )(x)) (ztn+1(x)−ztn(x))
+
Z t
tn
h
1
2Trace σ(x)[σ(x)]
∗(HessV(z) s )(x)
+
µ(x),(∇V(z) s )(x)
Rd
i
ds.
(11)
Note that (8) and (11) ensure that for every ω ∈Ω, t∈[0, T],x∈Rd it holds that
V(Zs(y,ω))(s,y)∈[0,T]×Rd
t (x) =Vt(x, ω). (12)
Combining this with (10) suggests for every sufficiently regular functionz: [0, T]×Rd→R
and every ω∈Ω, n ∈ {0,1, . . . , N}, x∈Rd that
V(Zs(y,ω))(s,y)∈[0,T]×Rd
tn (x)≈Xtn(x, ω). (13)
Moreover, note that (10)–(12) suggest for every sufficiently regular functionz: [0, T]×Rd → R and every n ∈ {0,1, . . . , N}, x∈Rd that
Vt(z)n (x)≈E
Xtn(x)|Z =z
. (14)
In the following we introduce additional artificial stochastic processes in order to incorpo-rate a Feynman-Kac type representation into (11). Let B: [0, T]×Ω→Rd be a standard (Ft)t∈[0,T]-Brownian motion, let ξ: Ω → Rd be an F0/B(Rd)-measurable function which
satisfies for every p ∈ (0,∞), x ∈ Rd that P(kξ −xkRd ≤ p) > 0 and E[kξk
p
Rd] < ∞,
assume that Z and (ξ, B) are independent random variables, and let Y : [0, T]×Ω → Rd be an (Ft)t∈[0,T]-adapted stochastic process with continuous sample paths which satisfies
that for every t ∈[0, T] it holds P-a.s. that Yt=ξ+
Z t
0
µ(Ys)ds+
Z t
0
σ(Ys)dBs. (15)
Note that the assumption that for every p ∈ (0,∞) it holds that E[kξk
p
Rd] < ∞ and the
assumption that µ: Rd → Rd and σ: Rd → Rd×d are sufficiently regular functions ensure that for every p∈(0,∞) it holds that
sup
t∈[0,T]
E
kYtkpRd
Moreover, observe that (11) implies that for every sufficiently regular function z: [0, T]× Rd→R and every n ∈ {0,1, . . . , N −1}, t∈(tn, tn+1),x∈Rd it holds that
∂ ∂t
Vt(z)(x)
=
µ(x),(∇Vt(z))(x)
Rd+
1
2Trace σ(x)[σ(x)]
∗(Hess
Vt(z))(x)
. (17) This, in turn, assures that for every sufficiently regular function z: [0, T]×Rd → R and every n ∈ {0,1, . . . , N −1}, t∈(T −tn+1, T −tn),x∈Rd it holds that
∂ ∂t
VT(z)−t(x)
+
µ(x),(∇VT(z)−t)(x)
Rd +
1
2Trace σ(x)[σ(x)]
∗(Hess
VT(z)−t)(x)
= 0. (18) Next note that Itˆo’s formula, the hypothesis that for every sufficiently regular function
z: [0, T]×Rd→R and everyn ∈ {0,1, . . . , N −1} it holds that (V(z)
t (x))(t,x)∈(tn,tn+1]×Rd ∈
C1,2((t
n, tn+1] ×Rd,R) (cf. (11)), and (15) guarantee that for every sufficiently regular
function z: [0, T]×Rd →Rand every n∈ {0,1, . . . , N −1}, r, t∈[T −tn+1, T −tn) with
r < t it holds P-a.s. that
VT(z)−t(Yt) =VT(z)−r(Yr) +
Z t
r
(∇VT(z)−s)(Ys), σ(Ys)dBs
Rd+
Z t
r ∂ ∂s
VT(z)−s
(Ys)ds
+
Z t
r 1
2Trace σ(Ys)[σ(Ys)]
∗(Hess
VT(z)−s)(Ys)
ds + Z t r
µ(Ys),(∇VT(z)−s)(Ys)
Rdds.
(19)
Combining this with (18) implies that for every sufficiently regular functionz: [0, T]×Rd→ R and every n ∈ {0,1, . . . , N −1}, r, t∈[T −tn+1, T −tn) with r < t it holds P-a.s. that
VT(z)−t(Yt) = VT(z)−r(Yr) +
Z t
r
(∇VT(z)−s)(Ys), σ(Ys)dBs
Rd. (20)
Hence, we obtain that for every sufficiently regular function z: [0, T]×Rd →R and every
n ∈ {0,1, . . . , N −1}, t∈(T −tn+1, T −tn) it holds P-a.s. that
VT(z)−t(Yt) =Vt(z)n+1(YT−tn+1) +
Z t
T−tn+1
(∇VT(z)−s)(Ys), σ(Ys)dBs
Rd. (21)
Furthermore, note that (16), the hypothesis that σ: Rd → Rd×d is a sufficiently regular
function, and the hypothesis that for every sufficiently regular function z: [0, T]×Rd→R and every n ∈ {0,1, . . . , N −1} it holds that (tn, tn+1]×Rd ∋ (t, x) 7→ (∇Vt(z))(x) ∈ Rd
is an at most polynomially growing function assure that for every n ∈ {0,1, . . . , N −1},
t∈(T −tn+1, T −tn) it holds that
Z t
T−tn+1
E
h
[σ(Ys)]∗(∇V
(z) T−s)(Ys)
2
Rd
i
Therefore, we obtain that for every sufficiently regular function z: [0, T]×Rd → R and every n ∈ {0,1, . . . , N −1}, t∈(T −tn+1, T −tn) it holds P-a.s. that
E
Z t
T−tn+1
(∇VT(z)−s)(Ys), σ(Ys)dBs
Rd
FT−tn+1
= 0. (23)
This and (21) demonstrate that for every sufficiently regular function z: [0, T]×Rd → R and every n∈ {0,1, . . . , N −1}, t∈[T −tn+1, T −tn) it holds P-a.s. that
E
VT(z)−t(Yt)
FT−tn+1
=E
Vt(z)n+1(YT−tn+1)
FT−tn+1
. (24)
The fact that for every sufficiently regular function z: [0, T]×Rd → R and every n ∈
{0,1, . . . , N−1}it holds that the function Ω ∋ω7→ Vt(z)n+1(YT−tn+1(ω))∈RisFT−tn+1/B(R
)-measurable hence implies that for every sufficiently regular function z: [0, T]×Rd → R
and every n∈ {0,1, . . . , N −1}, t∈[T −tn+1, T −tn) it holds P-a.s. that E
VT(z)−t(Yt)
FT−tn+1
=Vt(z)n+1(YT−tn+1). (25)
Next observe that the hypothesis that for every sufficiently regular functionz: [0, T]×Rd → R and every n∈ {0,1, . . . , N −1} it holds that (V(z)
t (x))(t,x)∈(tn,tn+1]×Rd ∈C
1,2((t
n, tn+1]×
Rd,R) has at most polynomially growing partial derivatives and the fact that for every
ω ∈Ω it holds that [0, T]∋ t7→Yt(ω)∈Rd is a continuous function ensure that for every
sufficiently regular function z: [0, T]×Rd → R and every ω ∈Ω, n ∈ {0,1, . . . , N −1} it holds that
lim sup
tրT−tn
V
(z)
T−t(Yt(ω))− VT(z)−t(YT−tn(ω))
= 0. (26)
Furthermore, observe that (11) and the hypothesis that for every sufficiently regular function z: [0, T]×Rd → R and every x ∈ Rd it holds that RT
0 k(HessV (z)
s )(x)kRd×d +
k(∇Vs(z))(x)kRdds <∞show that for every sufficiently regular functionz: [0, T]×Rd→R
and every ω∈Ω, n ∈ {0,1, . . . , N −1} it holds that lim sup
tրT−tn
V
(z)
T−t(YT−tn(ω))−
Vt(z)n (YT−tn(ω))
+f YT−tn(ω),V
(z)
tn (YT−tn(ω)),(∇V
(z)
tn )(YT−tn(ω))
(tn+1−tn) (27)
+b YT−tn(ω),V
(z)
tn (YT−tn(ω)),(∇V
(z)
tn )(YT−tn(ω))
ztn+1(YT−tn(ω))−ztn(YT−tn(ω))
= 0.
Combining this with (26) demonstrates that for every sufficiently regular functionz: [0, T]× Rd→R and every ω ∈Ω, n ∈ {0,1, . . . , N −1} it holds that
lim sup
tրT−tn
V
(z)
T−t(Yt(ω))−
Vt(z)n (YT−tn(ω))
+f YT−tn(ω),V
(z)
tn (YT−tn(ω)),(∇V
(z)
tn )(YT−tn(ω))
(tn+1−tn) (28)
+b YT−tn(ω),V
(z)
tn (YT−tn(ω)),(∇V
(z)
tn )(YT−tn(ω))
ztn+1(YT−tn(ω))−ztn(YT−tn(ω))
= 0.
In addition, note that the hypothesis that for every sufficiently regular functionz: [0, T]× Rd→Rand everyn ∈ {0,1, . . . , N}it holds that (V(z)
t (x))(t,x)∈(tn,tn+1]×Rd ∈C
1,2((t
n, tn+1]×
Rd,R) has at most polynomially growing partial derivatives and (16) ensure that for every sufficiently regular function z: [0, T]×Rd→R and every p∈(0,∞) it holds that
sup
t∈[0,T]
E
kYtkpRd
+
sup
t∈[0,T)
E
|VT(z)−t(Yt)|p
+
sup
t∈(0,T]
E
k(∇Vt(z))(YT−t)kpRd
<∞. (29) Next note that the fact that for every x ∈ R, ω ∈ Ω it holds that X0(x, ω) = ϕ(x), the hypothesis that for every sufficiently regular function z: [0, T]×Rd → R and every
x ∈ Rd it holds that V(z)
0 (x) = ϕ(x), and the hypothesis that for every ω ∈ Ω it holds
that (Xt(x, ω))(t,x)∈[0,T]×Rd ∈C0,2([0, T]×Rd,R) has at most polynomially growing partial
derivatives demonstrate that for every sufficiently regular function z: [0, T]×Rd → R it holds that (V0(z)(x))x∈Rd ∈ C2(Rd,R) has at most polynomially growing derivatives. This
and (29) imply that for every sufficiently regular function z: [0, T]×Rd → R and every
p∈(0,∞) it holds that
sup
t∈[0,T]
E
kYtkpRd
+
sup
t∈[0,T]
E
|VT(z)−t(Yt)| p
+
sup
t∈[0,T]
E
k(∇Vt(z))(YT−t)kpRd
<∞. (30) The hypothesis that f: Rd×R×Rd→R and b: Rd×R×Rd→R are sufficiently regular
functions hence proves that for every sufficiently regular function z: [0, T]×Rd →R and every p∈(0,∞) it holds that
sup
t∈[0,T]
E
h
Vt(z)(YT−t)
pi
+ max
n∈{0,1,...,N−1} E
h
Vt(z)n (YT−tn) +f YT−tn,Vt(z)n (YT−tn),(∇Vt(z)n )(YT−tn)
(tn+1−tn)
+b YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
ztn+1(YT−tn)−ztn(YT−tn)
pi
<∞.
(31)
Combining (28) and, e.g., Hutzenthaler et al. [55, Proposition 4.5] therefore demonstrates that for every sufficiently regular functionz: [0, T]×Rd→ Rand everyn ∈ {0,1, . . . , N−1} it holds that
lim sup
tրT−tn
E
h V
(z)
T−t(Yt)−
Vt(z)n (YT−tn) +f YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
(tn+1−tn)
+b YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
ztn+1(YT−tn)−ztn(YT−tn)
i
This and (25) yield that for every sufficiently regular functionz: [0, T]×Rd →Rand every
n ∈ {0,1, . . . , N −1} it holdsP-a.s. that
Vt(z)n+1(YT−tn+1)
=E
h
Vt(z)n (YT−tn) +f YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
(tn+1−tn)
+b YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
ztn+1(YT−tn)−ztn(YT−tn) FT−tn+1 i
.
(33)
The tower property for conditional expectations therefore assures that for every sufficiently regular function z: [0, T]×Rd→R and every n∈ {0,1, . . . , N −1} it holds P-a.s. that
E
h
Vt(z)n+1(YT−tn+1)|S(YT−tn+1)
i
=E
h
Vt(z)n (YT−tn) +f YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
(tn+1−tn)
+b YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
ztn+1(YT−tn)−ztn(YT−tn) S(YT−tn+1)
i
.
(34)
In addition, observe that the fact that for every n ∈ {0,1, . . . , N −1} it holds that the function Ω∋ω 7→YT−tn+1(ω)∈R
disS(Y
T−tn+1)/B(R
d)-measurable assures that for every
sufficiently regular function z: [0, T]×Rd → R and every n ∈ {0,1, . . . , N −1} it holds
P-a.s. that
Vt(z)n+1(YT−tn+1) =E
h
Vt(z)n+1(YT−tn+1)|S(YT−tn+1)
i
. (35)
This and (34) imply that for every sufficiently regular function z: [0, T]×Rd → R and every n ∈ {0,1, . . . , N −1} it holdsP-a.s. that
Vt(z)n+1(YT−tn+1)
=E
h
Vt(z)n (YT−tn) +f YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
(tn+1−tn)
+b YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
ztn+1(YT−tn)−ztn(YT−tn) S(YT−tn+1)
i
.
(36)
Equation (36) constitutes the Feynman-Kac type representation we were aiming at. In the following subsection we employ the factorization lemma (cf., for example, Becker et al. [6, Lemma 2.1] or Klenke [66, Corollary 1.97]) and the L2-minimality property of conditional
expectations (cf., for example, Klenke [66, Corollary 8.17]) to reformulate (36) as recursive minimization problems.
2.3
Formulation as iterative recursive minimization problems
In this subsection we reformulate (36) as recursive minimization problems. For this observe that (31) shows that for every sufficiently regular function z: [0, T]×Rd → R and every
n ∈ {0,1, . . . , N −1} it holds that E h V (z)
tn (YT−tn) +f YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
(tn+1−tn)
+b YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
ztn+1(YT−tn)−ztn(YT−tn)
2i
<∞. (37) The factorization lemma, e.g., in [6, Lemma 2.1] (applied with (S,S) x (Rd,B(Rd)), ΩxΩ, X xYT−t
n+1 for n ∈ {0,1, . . . , N −1} in the notation of [6, Lemma 2.1]), theL
2
-minimality property for conditional expectations, e.g., in Klenke [66, Corollary 8.17] (ap-plied withX xΩ∋ω7→ V(z)(YT−t
n(ω)) +f(YT−tn(ω),V
(z)
tn (YT−tn(ω)),(∇V
(z)
tn )(YT−tn(ω)))
(tn+1 − tn) +b(YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn))(ztn+1(YT−tn)−ztn(YT−tn)) ∈ R, F x
S(YT−t
n+1), A x F in the notation of [66, Corollary 8.17]), the fact that for every
suffi-ciently regular function z: [0, T]×Rd →R and every n ∈ {0,1, . . . , N −1} it holds that Rd ∋x7→ V(z)
tn+1(x)∈R is a continuous function, the fact that for every Borel measurable
set A ∈ B(Rd) with positive Lebesgue measure it holds that minn∈{0,1,...,N−1}P(YT−t
n+1 ∈
A)>0, and (36) hence imply that for every sufficiently regular functionz: [0, T]×Rd→R and every n∈ {0,1, . . . , N −1} it holds that
(Vt(z)n+1(x))x∈Rd = argmin
u∈C(Rd,R)
E
h
u(YT−tn+1)−
Vt(z)n (YT−tn)
+f YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
(tn+1−tn)
+b YT−tn,V
(z)
tn (YT−tn),(∇V
(z)
tn )(YT−tn)
ztn+1(YT−tn)−ztn(YT−tn)
2i
.
(38)
Therefore, we obtain that for every sufficiently regular function z: [0, T]×Rd → R and
every n ∈ {1,2, . . . , N} it holds that (Vt(z)n (x))x∈Rd = argmin
u∈C(Rd,R)
E
h
u(YT−tn)−
Vt(z)n−1(YT−tn−1)
+f YT−tn−1,V
(z)
tn−1(YT−tn−1),(∇V
(z)
tn−1)(YT−tn−1)
(tn−tn−1)
+b YT−tn−1,V
(z)
tn−1(YT−tn−1),(∇V
(z)
tn−1)(YT−tn−1)
ztn(YT−tn−1)−ztn−1(YT−tn−1)
2i
.
(39)
In the following subsection we approximate for every sufficiently regular functionz: [0, T]× Rd →R and every n ∈ {1,2, . . . , N} the function Rd∋ x7→ V(z)
tn (x)∈R by suitable deep
neural networks.
2.4
Deep neural network approximations
In this subsection we employ for every sufficiently regular function z: [0, T]×Rd→R and every n ∈ {1,2, . . . , N} suitable approximations for the function
Rd∋x7→ V(z)
More specifically, let ν ∈ N and for every sufficiently regular function z: [0, T]×Rd → R let V(z)n = (V(z)n (θ, x))(θ,x)∈Rν×Rd: Rν × Rd → R, n ∈ {0,1, . . . , N}, be continuously
differentiable functions which satisfy for every sufficiently regular functionz: [0, T]×Rd→ R and every θ∈Rν, x∈Rd that V(z)
0 (θ, x) =ϕ(x). For every sufficiently regular function
z: [0, T]×Rd→R, every n∈ {1,2, . . . , N},x∈Rd, and every suitable θ∈Rν we think of V(z)n (θ, x)∈R as an appropriate approximation
V(z)
n (θ, x)≈ V (z)
tn (x) (41)
ofVt(z)n (x). Combining this and (13) indicates for every sufficiently regular functionz: [0, T]×
Rd→R, every n ∈ {1,2, . . . , N}, x∈Rd, and every suitable θ ∈Rν that
V(z)
n (θ, x)≈E
Xtn(x)|Z =z
. (42)
For every sufficiently regular functionz: [0, T]×Rd→Rwe propose to choose the functions V(z)n : Rν ×Rd →R, n ∈ {1,2, . . . , N}, as deep neural networks (cf., for instance, [7, 77]). For example, for every k ∈ N let Tk: Rk → Rk satisfy for every x= (x1, x2, . . . , xk)∈ Rk that
Tk(x) = tanh(x1),tanh(x2), . . . ,tanh(xk)
(43) (multidimensional version of the tangens hyperbolicus), for every θ= (θ1, θ2, . . . , θν)∈Rν,
v ∈ N0 = {0} ∪ N, k, l ∈ N with v +lk +l ≤ ν let Aθ,v
k,l: Rk → Rl satisfy for every
x= (x1, x2, . . . , xk)∈Rk that
Aθ,vk,l(x) =
θv+1 θv+2 . . . θv+k
θv+k+1 θv+k+2 . . . θv+2k
θv+2k+1 θv+2k+2 . . . θv+3k
..
. ... ... ...
θv+(l−1)k+1 θv+(l−1)k+2 . . . θv+lk
x1 x2 x3 .. . xk + θv+lk+1 θv+lk+2 θv+lk+3 .. . θv+lk+l (44)
(affine function), let s ∈ {3,4,5,6, . . .}, assume that s(N + 1)d(d+ 1) ≤ν, and for every sufficiently regular function z: [0, T]×Rd →R let V(z)n : Rν×Rd →R, n ∈ {0,1, . . . , N}, satisfy for every n ∈ {1,2, . . . , N}, θ∈Rν, x∈Rd that V(z)
0 (θ, x) =ϕ(x) and
V(z)
n (θ, x) = (45)
Aθ,(sn+sd,1 −1)d(d+1)◦ Td◦Aθ,(sn+sd,d −2)d(d+1)◦. . .◦ Td◦Aθ,(sn+1)d(d+1)d,d ◦ Td◦Aθ,snd(d+1)d,d
(x).
For every sufficiently regular function z: [0, T]×Rd →R and every n ∈ {1,2, . . . , N}the function V(z)n : Rν ×Rd → R in (45) describes a fully-connected feedforward deep neural network with s+ 1 layers (1 input layer withdneurons, s−1 hidden layers withdneurons each, and 1 output layer with 1 neuron) and multidimensional versions of the tangens hyperbolicus as activation functions (see (43)).
2.5
Stochastic gradient descent based minimization
We intend to find for every sufficiently regular function z: [0, T] × Rd → R suitable
θz,1, θz,2, . . . , θz,N ∈ Rν in (41) by recursive minimization. More precisely, for every
suf-ficiently regular function z: [0, T] × Rd → R we intend to find for n ∈ {1,2, . . . , N},
θz,0, θz,1, . . . , θz,n−1 ∈Rν a suitable θz,n ∈Rν as an approximate minimizer of the function
Rν ∋θ 7→E
h
V(z)n (θ, YT−tn)−
V(z)
n−1(θz,n−1, YT−tn−1)
+f YT−tn−1,V
(z)
n−1(θz,n−1, YT−tn−1),(∇xV
(z)
n−1)(θz,n−1, YT−tn−1)
(tn−tn−1)
+b YT−tn−1,V
(z)
n−1(θz,n−1, YT−tn−1),(∇xV
(z)
n−1)(θz,n−1, YT−tn−1)
· ztn(YT−tn−1)−ztn−1(YT−tn−1)
2i
∈R
(46)
(cf. (39) and (41) above). To this end for every sufficiently regular functionz: [0, T]×Rd→ R let Bz,m: [0, T]×Ω → Rd, m ∈ N0, be i.i.d. standard (Ft)t∈[0,T]-Brownian motions, let
ξz,m: Ω → Rd, m ∈ N
0, be i.i.d. F0/B(Rd)-measurable functions, for every sufficiently
regular function z: [0, T]×Rd → R and every m ∈ N0 let Yz,m: [0, T]×Ω → Rd be an (Ft)t∈[0,T]-adapted stochastic process with continuous sample paths which satisfies that for
every t ∈[0, T] it holds P-a.s. that Ytz,m =ξz,m+
Z t
0
µ(Ysz,m)ds+
Z t
0
σ(Ysz,m)dBsz,m, (47)
let γ ∈ (0,∞), M ∈ N, and for every sufficiently regular function z: [0, T]×Rd → R let
ϑz,n = (ϑz,n
m )m∈N0: N0×Ω→ Rν, n ∈ {0,1, . . . , N}, be stochastic processes which satisfy
for every n ∈ {1,2, . . . , N}, m∈N0 that
ϑz,nm+1 =ϑz,nm −2γ·(∇θV(z)n )(ϑz,nm , Y z,m T−tn)·
h
V(z)
n (ϑz,nm , Y z,m T−tn)−V
(z) n−1(ϑ
z,n−1 M , Y
z,m T−tn−1)
−f YTz,m−tn−1,V
(z) n−1(ϑ
z,n−1 M , Y
z,m
T−tn−1),(∇xV
(z) n−1)(ϑ
z,n−1 M , Y
z,m T−tn−1)
(tn−tn−1)
−b YTz,m−tn−1,V
(z)
n−1(ϑz,nM −1, Y z,m
T−tn−1),(∇xV
(z)
n−1)(ϑz,nM −1, Y z,m T−tn−1)
· ztn(Y
z,m
T−tn−1)−ztn−1(Y
z,m T−tn−1)
i
(48)
(cf. (66)–(68) below).
2.6
Temporal discretization of the auxiliary stochastic process
Equation (48) provides us an implementable numerical algorithm in the special case where for every sufficiently regular function z: [0, T]×Rd → R one can simulate exactly from the solution processes Yz,m: [0, T] × Ω → Rd, m ∈ N
(15) above). In the case where it is not possible to simulate for every sufficiently regular function z: [0, T]×Rd → R exactly from the solution processes Yz,m: [0, T]×Ω → Rd,
m∈N0, of the SDEs in (47), one can employ a numerical approximation method for SDEs, say, the Euler-Maruyama scheme, to approximatively simulate for every sufficiently regular function z: [0, T]×Rd →R from the solution processes Yz,m: [0, T]×Ω → Rd, m ∈ N0, of the SDEs in (47). This is subject of this subsection. More formally, note that (47) implies that for every sufficiently regular function z: [0, T]×Rd → R and every m ∈ N0,
r, t∈[0, T] with r≤t it holds P-a.s. that Ytz,m =Yrz,m+
Z t
r
µ(Ysz,m)ds+
Z t
r
σ(Ysz,m)dBsz,m. (49) Hence, we obtain that for every sufficiently regular function z: [0, T]×Rd →R and every
m∈N0, n ∈ {0,1, . . . , N −1} it holdsP-a.s. that YTz,m−tn =YTz,m−tn+1 +
Z T−tn
T−tn+1
µ(Ysz,m)ds+
Z T−tn
T−tn+1
σ(Ysz,m)dBsz,m. (50) This shows that for every sufficiently regular functionz: [0, T]×Rd→Rand everym∈N0,
n ∈ {0,1, . . . , N −1} it holdsP-a.s. that YTz,m−tN
−(n+1) =Y
z,m T−tN−n+
Z T−tN−(n+1)
T−tN−n
µ(Ysz,m)ds+
Z T−tN−(n+1)
T−tN−n
σ(Ysz,m)dBsz,m. (51) Next we introduce suitable real numbers which allow us to reformulate (51) in a more compact way. More formally, let τn ∈ [0, T], n ∈ {0,1, . . . , N}, satisfy for every n ∈
{0,1, . . . , N}that
τn =T −tN−n. (52)
Observe that (2) and (52) ensure that
0 =τ0 < τ1 <· · ·< τN =T. (53)
Moreover, note that (51) and (52) demonstrate that for every sufficiently regular function
z: [0, T]×Rd→R and every m ∈N0,n ∈ {0,1, . . . , N −1} it holdsP-a.s. that Yτz,mn+1 =Yτz,mn +
Z τn+1
τn
µ(Ysz,m)ds+
Z τn+1
τn
σ(Ysz,m)dBsz,m. (54) This suggests for every sufficiently regular function z: [0, T]×Rd→Rand every m∈N
0,
n ∈ {0,1, . . . , N −1} that
Yτz,mn+1 ≈Yτz,mn +µ(Yτz,mn ) (τn+1−τn) +σ(Yτz,mn ) (B
z,m τn+1−B
z,m
Based on (55) we now introduce for every sufficiently regular function z: [0, T]×Rd →R suitable Euler-Maruyama approximations for the solution processes Yz,m: [0, T]×Ω →
Rd, m ∈ N0, of the SDEs in (47). More formally, for every sufficiently regular function
z: [0, T]×Rd→Rand every m∈N0 let Yz,m = (Yz,m
n )n∈{0,1,...,N}: {0,1, . . . , N} ×Ω→Rd
be the stochastic process which satisfies for every n ∈ {0,1, . . . , N −1} that Y0z,m =ξz,m
and
Yn+1z,m =Ynz,m+µ(Ynz,m) (τn+1−τn) +σ(Ynz,m) (Bτz,mn+1 −B
z,m
τn ). (56)
Observe that (52), (55), and (56) suggest for every sufficiently regular function z: [0, T]× Rd→R and every m ∈N0, n∈ {0,1, . . . , N}that
Ynz,m ≈Yτz,mn =Y
z,m
T−tN−n. (57)
This, in turn, suggests for every sufficiently regular function z: [0, T]×Rd→Rand every
m∈N0, n ∈ {0,1, . . . , N} that
YTz,m−tn ≈ YNz,m−n. (58) In the next step we employ (58) to derive for every sufficiently regular function z: [0, T]× Rd→R approximations of the stochastic processes ϑz,n: N
0×Ω→Rν, n ∈ {0,1, . . . , N},
in (48) which are also implementable in the case where one cannot simulate exactly from the solution processes of the SDEs in (47). More precisely, for every sufficiently regular function z: [0, T]×Rd → R let Θz,n = (Θz,n
m )m∈N0: N0 ×Ω → R, n ∈ {0,1, . . . , N}, be
stochastic processes which satisfy for every sufficiently regular function z: [0, T]×Rd→R and every n∈ {1,2, . . . , N},m ∈N0 that
Θz,nm+1 = Θz,nm −2γ·(∇θV(z)n )(Θz,nm ,Y z,m N−n)·
h
V(z)
n (Θz,nm ,Y z,m N−n)−V
(z) n−1(Θ
z,n−1 M ,Y
z,m N−n+1)
−f YNz,m−n+1,V(z)
n−1(Θ z,n−1 M ,Y
z,m
N−n+1),(∇xV (z) n−1)(Θ
z,n−1 M ,Y
z,m N−n+1)
(tn−tn−1)
−b YNz,m−n+1,V(z)
n−1(Θ z,n−1 M ,Y
z,m
N−n+1),(∇xV(z)n−1)(Θ z,n−1 M ,Y
z,m N−n+1)
(59)
· ztn(Y
z,m
N−n+1)−ztn−1(Y
z,m N−n+1)
i
(cf. (66)–(68) below). Note that (48) , (58), and (59) indicate for every sufficiently regular function z: [0, T]×Rd →R, every n ∈ {1,2, . . . , N}, and every sufficiently large m ∈ N0 that
Θz,nm ≈ϑz,nm . (60)
In the following two subsections (Subsection 2.7 and Subsection 2.8) we merge the above derivations to precisely formulate the proposed approximation algorithm, first, in a special case (Subsection 2.7) and, thereafter, in the general case (Subsection 2.8).
2.7
Description of the proposed approximation algorithm in a
special case
In this subsection we describe the proposed approximation algorithm in the special case where the standard Euler-Maruyama scheme (cf., e.g., Kloeden & Platen [67] and Maruyama [82]) is the employed approximation scheme for discretizing (47) (cf. (56)) and where the plain vanilla stochastic gradient descent method with constant learning rate γ ∈ (0,∞) and batch size 1 is the employed minimization algorithm. A more general description of the proposed approximation algorithm, which allows to incorporate more sophisticated machine learning approximation techniques such as batch normalization (cf., for instance, Ioffe & Szegedy [56]) and the Adam optimizer (cf., for example, Kingma & Ba [65]), can be found in Subsection 2.8 below.
Framework 2.1 (Special case). Let T, γ ∈ (0,∞), d, N, M ∈ N, ϕ ∈ C2(Rd,R), s ∈
{3,4,5, . . .}, ν =s(N + 1)d(d+ 1), t0, t1, . . . , tN ∈[0, T] satisfy
0 =t0 < t1 < . . . < tN =T, (61)
let τ0, τ1, . . . , τn ∈ [0, T] satisfy for every n ∈ {0,1, . . . , N} that τn = T − tN−n, let
f: Rd×R×Rd → R, b: Rd ×R×Rd → R, µ: Rd → Rd, and σ: Rd → Rd×d be
con-tinuous functions, let (Ω,F,P,(Ft)t∈[0,T]) be a filtered probability space, for every function z: [0, T]×Rd→R let ξz,m: Ω→Rd, m∈N0, be i.i.d. F0/B(Rd)-measurable random
vari-ables, let Bz,m: [0, T]×Ω →Rd, m ∈ N
0, be i.i.d. standard (Ft)t∈[0,T]-Brownian motions,
let Yz,m: {0,1, . . . , N} ×Ω→Rd, m∈N
0, satisfy for everym∈N0, n∈ {0,1, . . . , N−1}
that Y0z,m =ξz,m and
Yn+1z,m =Ynz,m+µ(Ynz,m) (τn+1−τn) +σ(Ynz,m) (Bτz,mn+1 −B
z,m
τn ), (62)
let Td: Rd→Rd satisfy for every x= (x1, x2, . . . , xd)∈Rd that
Td(x) = tanh(x1),tanh(x2), . . . ,tanh(xd)
, (63)
for every θ = (θ1, θ2, . . . , θν) ∈ Rν, k, l ∈ N, v ∈ N0 = {0} ∪N with v +lk+l ≤ ν let
Aθ,vk,l: Rk →Rl satisfy for every x= (x1, x2, . . . , xk)∈Rk that
Aθ,vk,l(x) =
θv+kl+1+
k P
i=1
xiθv+i
, . . . , θv+kl+l+
k P
i=1
xiθv+(l−1)k+i , (64)
for every function z: [0, T]×Rd→R let V(z)n : Rν×Rd→R, n∈ {0,1, . . . , N}, satisfy for
every n∈ {1,2, . . . , N}, θ ∈Rν, x∈Rd thatV(z)
0 (θ, x) =ϕ(x) and
V(z)
n (θ, x) = (65)
Aθ,(sn+sd,1 −1)d(d+1)◦ Td◦Aθ,(sn+sd,d −2)d(d+1)◦. . .◦ Td◦Aθ,(sn+1)d(d+1)d,d ◦ Td◦Aθ,snd(d+1)d,d
for every function z: [0, T]× Rd → R let Θz,n: N0 × Ω → Rν, n ∈ {0,1, . . . , N}, be
stochastic processes, for every function z: [0, T]×Rd → R and every n ∈ {1,2, . . . , N},
m∈N0 let φz,n,m: Rν×Ω→R satisfy for every θ ∈Rν, ω ∈Ω that
φz,n,m(θ, ω) =hV(z)
n θ,Y z,m N−n(ω)
−V(z)
n−1(Θ z,n−1 M (ω),Y
z,m
N−n+1(ω)) −(tn−tn−1)
·f YNz,m−n+1(ω),V(z)
n−1(Θ z,n−1 M (ω),Y
z,m
N−n+1(ω)),(∇xV(z)n−1)(Θ z,n−1 M (ω),Y
z,m
N−n+1(ω))
−b YNz,m−n+1(ω),V(z)
n−1(Θ z,n−1 M (ω),Y
z,m
N−n+1(ω)),(∇xV (z) n−1)(Θ
z,n−1 M (ω),Y
z,m
N−n+1(ω))
· ztn(Y
z,m
N−n+1(ω))−ztn−1(Y
z,m
N−n+1(ω))
i2
,
(66)
for every functionz: [0, T]×Rd→Rand every n∈ {1,2, . . . , N}, m∈N0 let Φz,n,m: Rν× Ω→ Rν satisfy for every θ ∈Rν, ω ∈ Ω that Φz,n,m(θ, ω) = (∇θφz,n,m)(θ, ω), and assume
for every function z: [0, T]×Rd →R and every m ∈N0, n ∈ {1,2, . . . , N} that
Θz,nm+1 = Θz,nm −γ·Φz,n,m(Θz,nm ). (67) In the setting of Framework 2.1 we note that for every function z: [0, T]×Rd→R and every n ∈ {1,2, . . . , N}, m ∈N0 it holds that
Θz,nm+1 = Θz,nm −2γ·(∇θV(z)n )(Θz,nm ,YNz,m−n)·
h
V(z)n (Θz,nm ,Yz,m
N−n)−V (z)
n−1(Θz,nM −1,Y z,m N−n+1)
−f YNz,m−n+1,V(z)
n−1(Θ z,n−1 M ,Y
z,m
N−n+1),(∇xV(z)n−1)(Θ z,n−1 M ,Y
z,m N−n+1)
(tn−tn−1)
−b YNz,m−n+1,V(z)
n−1(Θ z,n−1 M ,Y
z,m
N−n+1),(∇xV(z)n−1)(Θ z,n−1 M ,Y
z,m N−n+1)
(68)
· ztn(Y
z,m
N−n+1)−ztn−1(Y
z,m N−n+1)
i
(cf. (48), (59), (66), and (67) above). Moreover, in the setting of Framework 2.1 we think under suitable hypothesis for sufficiently largeN, M ∈N, for sufficiently smallγ ∈(0,∞), for every sufficiently regular function z: [0, T]×Rd→R, and for every n∈ {0,1, . . . , N},
x∈Rd of V(z)n (Θz,n
M , x) : Ω→R as a suitable approximation
V(z)
n (Θ z,n
M , x)≈E
Xtn(x)|Z =z
(69) of E[Xt
n(x)|Z = z] where X: [0, T]×R
d ×Ω → R is a random field which satisfies for
every t ∈ [0, T], x ∈ Rd that Xt(x) : Ω → R is Ft/B(R)-measurable, which satisfies for every ω ∈ Ω that (Xt(x, ω))(t,x)∈[0,T]×Rd ∈ C0,2([0, T]×Rd,R) has at most polynomially
growing partial derivatives, and which satisfies that for every t ∈ [0, T], x ∈ Rd it holds
P-a.s. that
Xt(x) =ϕ(x) +
Z t
0
f x, Xs(x),(∇Xs)(x)
ds+
Z t
0
b x, Xs(x),(∇Xs)(x)
dZs(x)
+
Z t
0
h
1
2Trace σ(x)[σ(x)]
∗
(HessXs)(x)
+µ(x),(∇Xs)(x)
Rd
i
ds
(70)
whereZ: [0, T]×Rd×Ω→Ris a sufficiently regular random field (cf. (1), (13), (14), (41), and (42)).
2.8
Description of the proposed approximation algorithm in the
general case
In this subsection we present in Framework 2.2 a general approximation algorithm which includes the proposed approximation algorithm derived in Subsections 2.1–2.7 above as a special case. Compared to Framework 2.1, Framework 2.2 allows to incorporate other minimization algorithms than just the plain vanilla stochastic gradient descent method (see, e.g., (67) in Framework 2.1 in Subsection 2.7 above) such as, for example, the Adam optimizer (cf. Kingma & Ba [65]). Furthermore, Framework 2.2 also allows to incorporate more advanced machine learning techniques like batch normalization (cf. Ioffe & Szegedy [56] and (74) below).
Framework 2.2 (General case). Let T ∈ (0,∞), M, N, d, δ, ̺, ν, ς ∈ N, (Jm)m∈N0 ⊆ N,
t0, t1, . . . , tN ∈[0, T]satisfy 0 = t0 < t1 < . . . < tN =T, letτ0, τ1, . . . , τn∈[0, T]satisfy for
every n∈ {0,1, . . . , N}thatτn=T−tN−n, letf: Rd×R×Rd→R, b: Rd×R×Rd→Rδ,
H: [0, T]2×Rd×Rd →Rd, andH
n: Rd×R×Rd×Rδ →R,n ∈ {1,2, . . . , N}, be functions,
let (Ω,F,P) be a probability space with a normal filtration (Ft)t∈[0,T], for every function z: [0, T]×Rd → Rδ and every n ∈ {1,2, . . . , N} let Bz,n,m,j: [0, T]×Ω → Rd, m ∈ N0,
j ∈N, be i.i.d. standard (Ft)t∈[0,T]-Brownian motions, for every function z: [0, T]×Rd→ Rδ and every n ∈ {1,2, . . . , N} let ξz,n,m,j: Ω→ Rd, m ∈ N0, j ∈ N, be i.i.d. F0/B(Rd)
-measurable random variables, for every functionz: [0, T]×Rd→RδletVz,j,s
n : Rν×Rd →R,
j ∈N, s∈Rς, n∈ {0,1, . . . , N}, be functions, for every function z: [0, T]×Rd→Rδ and
every n∈ {1,2, . . . , N}, m∈N0, j ∈Nlet Yz,n,m,j: {0,1, . . . , N} ×Ω→Rdbe a stochastic
process which satisfies for every k ∈ {0,1, . . . , N −1} that Y0z,n,m,j =ξz,n,m,j and
Yk+1z,n,m,j =H(τk+1, τk,Y z,n,m,j k , B
z,n,m,j τk+1 −B
z,n,m,j
τk ), (71)
for every functionz: [0, T]×Rd→RδletΘz,n: N0×Ω→Rν,n∈ {0,1, . . . N}, be stochastic
processes, for every function z: [0, T]×Rd → Rδ and every n ∈ {1,2, . . . , N}, m ∈ N0,
s∈Rς let φz,n,m,s
: Rν ×Ω→R satisfy for every θ ∈Rν, ω ∈Ω that
φz,n,m,s
(θ, ω) = 1
Jm Jm
X
j=1
Vz,j,s
n θ,Y z,n,m,j N−n (ω)
− Hn
YNz,n,m,j−n+1(ω),V z,j,s
n−1 Θz,nM −1(ω),Y z,n,m,j N−n+1(ω)
, (72)
(∇xVz,j,
s
n−1) Θ z,n−1 M (ω),Y
z,n,m,j N−n+1(ω)
, ztn Y
z,n,m,j N−n+1(ω)
−ztn−1 Y
z,n,m,j N−n+1(ω)
2
, for every function z: [0, T]× Rd → Rδ and every n ∈ {1,2, . . . , N}, m ∈ N
0, s ∈ Rς
let Φz,n,m,s
: Rν × Ω → Rν satisfy for every ω ∈ Ω, θ ∈ {η ∈ Rν: φz,n,m,s
(·, ω) : Rν → R is differentiable at η} that
Φz,n,m,s
(θ, ω) = (∇θφz,n,m,
s