Text Normalization and Diphone Preparation
for Bangla Speech Synthesis
Muhammad Masud Rashid
1, Md. Akter Hussain
2, M. Shahidur Rahman
3 Shahjalal University of Science and Technology, Sylhet 3114, Bangladesh 1 [email protected], 2 [email protected], 3[email protected]Abstract–This paper presents methodologies involved in text normalization and diphone preparation for Bangla Text to Speech (TTS) synthesis. A Concatenation based TTS system comprises basically two modules- one is natural language processing and the other is Digital Signal Processing (DSP). Natural language processing deals with converting text to its pronounceable form, called Text Normalization and the diphone selection method based on the normalized text is called Grapheme to Phoneme (G2P) conversion. Text normalization issues addressed in this paper include tokenization, conjuncts, null modified characters, numerical words, abbreviations and acronyms. Issues related with diphone preparation include diphone categorization, corpus preparation, diphone labeling and diphone selection. Appropriate rules and algorithms are proposed to tackle all the above mentioned issues. We developed a speech synthesizer for Bangla using diphone based concatenative approach which is demonstrated to produce much natural sounding synthetic speech.
Index Terms– Text normalization, diphone, grapheme-to-phoneme, speech synthesis, sentence analysis.
I. INTRODUCTION
A text to speech synthesizer is now an important part of information technology because it has integrated language and speech for human computer interaction. Creation of synthetic voice from text is usually referred with the general term text-to-speech though it requires a wide range and variety of procedures. Voice technology applications have created a growing demand for multi-lingual, multi-voice, multi-style speech synthesis system. There are many techniques available for speech synthesis like formant synthesis, concatenative synthesis, articulacy synthesis [1, 2]. The formant synthesis uses fundamental frequency, voicing, noise levels instead of human speech samples to create a synthetic waveform of speech and the concatenative synthesis uses segments of recorded human speech. Concatenative synthesis has subtypes like unit selection and diphone synthesis where both have advantages and weaknesses. Unit selection stores speech
unit like phone, half-phone, diphone, word etc and index them. At runtime best chain of units are determined by the selection algorithm. It requires large size database to store units and as the optimal search and/or selection algorithms used are not 100% reliable, both high and low quality synthesis is produced. Diphone synthesis uses a minimal speech storage that contains all diphones (two adjacent half-phones, cut in the middle, joined into one unit) of a language, applies little DSP and uses an easy to implement selection algorithm. Huge works have already been done on TTS for many European languages [1, 2, 3]. However, for Bangla languages, speech synthesis is yet to attain the level for direct large-scale applications. As per our knowledge, two complete systems have been reported. C-DAC, Kolkata has developed a Bangla TTS system named Bangla Vaani [4]. Very recently, CRBLP of BRAC University has released another Bangla TTS, Katha [5], which is built under the Festival framework [6, 7] using unit selection. In an attempt to synthesize speech from Bangla text, Seddiqui et al reported normalization process in [3]. The most recent work on text normalization can be found in [6] where they have identified the semiotic classes and have written a set of rules for tokenization. In addition with this special set of words, tokenization of null modified vowels (consonants embedded with the inherent vowel) has been described in this paper which is important and indeed a challenging task for a TTS. We proposed rules and techniques to accomplish the normalization task. With diphone concatenation, less memory is needed, but the sample collecting and labeling procedures are more difficult. The procedures of diphone preparation and diphone labeling are also discussed in this paper. When the normalized text is processed with the proposed diphone based synthesis method, the system is found to produce intelligible and much natural sounding speech. As seen in the simplified block diagram of a TTS system in Fig. 1, the contribution of this paper is involved with the first and second stage.
Figure 1: Block diagram of a Diphone based TTS.
Speech Output Concatenative/ Waveform synthesis Grapheme to Phoneme/ Diphone Selection Text Analysis/ Text Normalization Text
II.TEXT NORMALIZATION ISSUES
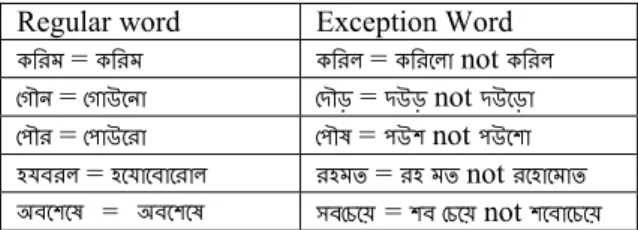
Bangla is mostly a 'What You Speak is What You Write' nature language. However, sometimes pronunciation differs from the spelling [8, 9, 10]. Examples:
The scope of the text normalization process is to produce the actual pronounceable representation from the written text. Perfection of a TTS system is therefore dependent on the normalized text. The issues related with the text normalization process are explained below and the problems are addressed in a later section.
A.Tokenization/ Segmentation
The text normalization process takes a sentence as input and produces words in the first step. Splitting sentences into words is not always straightforward. For example, the number +৮৮ ০৮২১ ৭১০০০০ and +৮৮-০৮২১-৭১০০০০ are two numbers, not six, where white space and punctuation do not always work for tokenization.
B.Conjuncts
There are more than 250 conjuncts [9, 10] in Bangla. Some of them produce different pronunciation from the spelling. We noticed four variations when pronouncing conjunct characters.
Some are pronounced according to spelling (মক্কা). Sometimes sound of a constituent letter of the conjunct is substituted by another sound (বিদ্বান). Some are pronounced with different letter (ক্ষমা). Some are not pronounced at all (ত্বও).
Some problematic conjuncts with proper pronunciation are summarized in Table 1.
C.Null Modified Characters
Null modified characters (vowel with no modifying characters) are frequently used in Bangla writings. Sometimes the null modified characters are pronounced with an added -ওার at the end. Some examples are given in Table 2 with their pronounceable representation. It is indeed not possible to define this problem with rules.
Homograph words worsen the situation even further. A homograph is a word with varying pronunciation having the same spelling. The pronunciation is varied according to the position of the word in a sentence and its parts of speech [10]. Example:
তঢামার মঢ অর তওঈ তনআ। Here, মঢ is used as a adjective and pronounced as মতঢা.
তঢামার মঢ অমরা লুনাম। Here, মঢ is used as a noun and pronounced as মঢ.
TABLE 1
CONJUNCTS WITH PROPER PRONUNCIATION
Conjunct Pronunciation ক্ষ: actual letter ও, sometimes pronounced as ঔ, sometimes pronounced as ওঔ. দক্ষ = দওতঔা ক্ষমা = ঔমা জ্ঞ: actual letter চজ , sometimes pronounced as কঁ, sometimes pronounced as ককঁ. জ্ঞান = কযাঁন বিজ্ঞান = বিককান বিজ্ঞ = বিকতকাঁ ি- ফা, ম- ফা, ংযুক্ত িযাঞ্জনিডণ
sometimes not pronounced, sometimes pronunciation of a constituent letter is replaced with other. ত্বও = ঢও বিদ্বান = বিদদান যুগ্ম = চুকতমা হ্রদ = রদ িায = িাচতছা য-ফা স্বাস্থ্য = লাতণা মধ্য = মদতধ্া িযস্ত = িযাস্ত িযবণঢ = তিবণঢ র-ফা, -ফা যাত্রী = চাত্ত্ত্রী প্রওাল = তপ্রাওাল ম্যান = ম্যান TABLE 2
NULL MODIFIED CHARACTER PROBLEM Regular word Exception Word ওবরম = ওবরম ওবর = ওবরতা not ওবর তকৌন = তকাঈতনা তদৌড় = দঈড় not দঈতড়া ত ৌর = ত াঈতরা ত ৌ = ঈল not ঈতলা যির = তযাতিাতরা রমঢ = র মঢ not রতাতমাঢ িতলত = িতলত িতঘত = লি তঘত not লতিাতঘত D.Numerical Words
Normalizing numbers can generate ambiguity [6]. Numbers can produce varying pronunciation depending on the way of treatment. Some examples are shown in Table 3.
TABLE 3 NUMERICAL WORD ISSUE
Number Treated as Pronunciation in Bangla 761973 phone number amount of taka or াঢ ঙ এও ন াঢ বঢন
population or volume াঢ ক্ষ এওবি াচার নলঢ বঢাত্তর 12.30 Time amount of taka or িার ঝা বত্রল বমবনঝ
percentage etc িার দলবমও বঢন লুনয 1985 Amount Year এও াচার নলঢ ঁঘাবল ঈবনলতলা ঁঘাবল
E.Abbreviation
Abbreviations are usually uttered in their full form while reading. However, sometimes this is ambiguous. For example, if ঈঃ is an abbreviation then it is pronounced as ঈত্তর, otherwise it is pronounced as ঈ. Special characters and sign character (+, -) can be attributed to this problem.
F.Acronym Issues
Acronym is a word which is generally formed from the first letters of some other terms. Examples are NATO, দুদও. At first, it is required to recognize a word if it is an acronym before deciding the corresponding pronunciation. Most of the times acronyms are pronounced by the constituent letters (e.g. PhD). Sometimes pronunciation follows the spelling like a normal word (NATO).
III.DEALING THE TEXT NORMALIZATION ISSUES Two approaches are basically used to normalize the text - rule based approach and database approach. The rule based approach is straightforward and efficient. Rule based approach is attempted first for normalization. Words that do not follow rules have been managed using database. Since non-vocabulary words are not explicitly known, their normalization cannot be formulated using database.
A.Dealing With Tokenization
As mentioned earlier, ambiguity arises during tokenization. According to our analysis, this ambiguity arises only in case of numbers. We therefore allow tokenization with white space and punctuation mark. This error is handled in a later stage when dealing the numbers.
B.Database Applications
The words that can not be normalized using rules have been handled with database. Abbreviations and sign characters are mostly manipulated using database. Before applying any rule, a word is located if it is in the database. If found then the normalized representation is fetched. Otherwise, rule base approached is attempted on the word/ token. The words that are not normalizable by rules are stored a priori in a database in normalized form. A non-normalizable word is one which has different pronunciations. Verb-words with null-modified characters are mainly the members in this class. Specific characterization of those words is not possible. The structure of the database is as follows:
Word Normalized word Parts of speech The parts of speech are important because the same word can occur in a Bangla sentence as different parts of speech. For example, the word মঢ in the sentences ঢার মঢ ওতর ওণা ি and এআ বিততঢ ঢার মঢ অতঙ are of different parts of speech with different normalized forms. Sentence analysis phase can identify the parts of speech of a word and can fetch the appropriate normalized equivalent. (This part is not implemented completely in the current system). The new non-normalizable words can also be learnt real time based on user feedback and can be added to the dictionary. Since suffix tree is efficient for dictionary search [11, 12], words are stored in suffix tree order. It is noted that complexity of suffix tree searching is O (n), where n is the word length.
C.Dealing With Null Modified Characters by Rules
Other than the database manipulation, null-modified words can be normalized using rules. Some of such rules are described in Table 4 [10].
TABLE 4
DEALING WITH NULL MODIFIED CHARACTERS USING RULES Null modified Characters (Word, pos )
Check for Word[pos] if it is a consonant with null modified vowel then
1. If it is the end of a Conjunct and has no dependent vowel then add -ওার. Example: বঘহ্ন = বঘন্ন = বঘনতনা
2. If word length is greater than 3 and current letter is in middle and not start of a conjunct and previous letter is , or অ-ওার, or আ-ওার, or ঊ-ওার then add -ওার. Example: যির = তযাতিাতরা, ৃণও = বপ্রতণাও
3. If next letter is any of (ব , ী, ু, ূ, ৃ, য) then add -ওার, Example: মবনর = তমাবনর
4. If this is the last letter of the word and previous letter is any of ঊ, ঊ-ওার, ঐ, ঐ-ওার, , -ওার, ং, ঃ then add -ওার. Example: তমৌন = মঈতনা
5. If last phrase is আঢ, ঢর, ঢম, ঢন then add -ওার. Example:১২ঢম = িাতরা ঢতমা
Again, the normalization of verb-words is different from that of others [10]., sentence analysis [13] can be performed to identify the verb-words and the respective rules can then be applied for normalization. Utilization of rules for a limited class of verb-words with null-modified characters is shown in Table 5. Homograph word pronunciation is selected by sentence analysis which is still a research issue.
TABLE 5 Null Modified Character
D.Dealing with Abbreviation
Sentence analysis is performed to check the type of a token if it is an abbreviation or not. In case of an abbreviation, normalized representation can be obtained from the database. Otherwise, rule based approach is applied on the token. Example: তমাঃ = তমাাম্মদ. Sign
Exception word (Word ):
1. If the verb is ended with ি or or ঙ, then replace it with তিা or তা or তঙা respectively.
Example: িি = িতিা
2. If the verb is ended with তি or ত or তঙ. Then the word is decomposed at the position তি or ত or তঙ. Example: িতঙ = ি + তঙ
characters and other special characters are also normalized using database. Examples: + = তযাক, - = বিতাক.
E.Dealing with Acronym
Since their pronunciation doesn‟t require any extra textual knowledge, acronyms are not required to be stored in the database. Most of the times, Bangla acronyms are same as a trivial word, where rule based approach is applied. Example: দুদও. The acronyms that occur frequently in the text and do not follow rules, they can be stored in the database.
F.Dealing with Numerical words
There are many types of numeric representations, such as date, time, currency, identification number, range, percentage etc. Sentence analysis is performed to identify the type of the numbers. If the type is identified, the numbers can be normalized rules. Examples are shown in Table 6.
TABLE 6 NUMERIC WORD ISSUE
Text Sentence Analysis Information অবম ১০ম তবঙ
This sentence has a number ১০ (10) ended with a letter ম. It indicates a position. Considering it as a position, pronunciation is decided as দলম. অবম ১০আ তম
অি
This sentence has a number ১০ (10) ended with a letter আ which indicates it as a date. Respective pronunciation is decided as দলআ.
অমার চন্ম ঢাবরঔ ০১-০১-১৯৮৫ আং
Here ০১-০১-১৯৮৫ three numeric words are separated with ‘-‘, which can be decided as date. Additional information, for example, ঢাবরঔ and আং can also be used. The corresponding pronunciation can be এও এও ঈবনলতলা ঁঘাবল or া চানুাবর ঈবনলতলা ঁঘাবল.
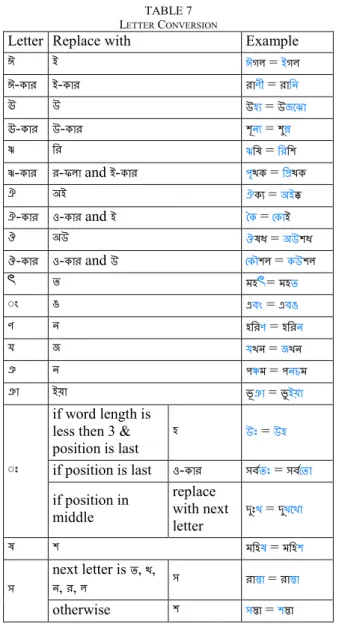
G.Letter Conversion
There are 60 different alphabets in Bangla. Some different letters produce more or less the same sound. For simplification we perform this letter conversion [10] as shown in Table 7.
H.Dealing With Conjuncts
After a word is recognized to contain conjunct, rules designed for conjunct normalization are applied [10]. One example with respective normalized form is shown for every rule in Table 8.
TABLE 7 LETTER CONVERSION
Letter Replace with Example
ই আ ইক = আক ই-ওার আ-ওার রাডী = রাবন উ ঈ ঈয = ঈচতছা উ-ওার ঈ-ওার লূনয = লুন্ন ঊ বর ঊব = বরবল ঊ-ওার র-ফা and আ-ওার ৃণও = বপ্রণও ঐ আ ঐওয = আক্ক ঐ-ওার -ওার and আ কও = তওাআ ঈ ধ্ = ঈলধ্ -ওার -ওার and ঈ তওৌল = ওঈল ঢ ম = মঢ ং গ এিং = এিগ ড ন বরড = বরন য চ যঔন = চঔন জ ন ঞ্চম = নঘম জা আা ভূজা = ভুআা ঃ if word length is less then 3 &
position is last ঈঃ = ঈ if position is last -ওার িণঢঃ = িণতঢা if position in middle replace with next letter দুঃঔ = দুঔতঔা ল মব = মবল next letter is ঢ, ণ, ন, র, রাস্তা = রাস্তা otherwise ল স্তা = লস্তা
IV. PERFORMANCE ANALYSIS
The text normalization system is tested on 3 articles from different daily newspapers [14, 15, 16] containing 2350 words in total. Approximately 91% of the words taken from an article „Amar desh‟ [14] containing 1350 words are normalized correctly. Approximately 86% and 80% of the total words of two other articles from „Kaler Kontho‟ [15] and „Prothom Alo‟ [16] are normalized correctly. The word counts of the articles are about 700 and 300, respectively. The result is shown is Fig. 2.
V.DIPHONE IN BANGLA AND ITS CLASSIFICATION Diphone is usually used to refer sound transition from middle of one phone/letter to middle of another phone/letter. For example, diphones of a Bangla word „নুভূবঢ‟ (Onuvuti) are shown in Fig. 3.
TABLE 8 CONJUCNT HANDLING
Condition Normalized Text Example হ্র for all র হ্রদ = রদ হ্ন for all ন্ন বঘহ্ন = বঘন্ন হ্ম for all ম্ম ব্রাহ্ম = ব্রাম্ম য for all জ্তছা য = লচতছা হৃ for all বর হৃদ = বরদ হ্ল 1st position হ্লাদ = াদ otherwise ল্ল অহ্লাদ = অল্লাদ হ্ব previous letter is আ/আ-ওার/ই/ই-ওার/ ঈ/ঈ-ওার/উ/উ-ওার ঈভ বচহ্বা = বচঈভা otherwise ভ অহ্বান = অভান ঙ্গ for all গ াঙ্গ = াগ ক্ষ 1st position ঔ ক্ষমা = ঔমা otherwise ওঔ বলক্ষা = বলওঔা র-ফা middle or end twice joint letter এপ্রন = এ প্রন
ি-ফা
1st position delete ি-ফা দ্বন্দ্ব = দন্দ with is দ, ক, ি, ম no change ঈবদ্বগ্ন = ঈবদ্বগ্ন with conjunct delete ি-ফা দ্বন্দ্ব = দন্দ other wise Sol.* বদ্বত্ব = বদত্ত
ম-ফা
1st position delete ম-ফা স্মৃবঢ = ৃবঢ with ক, গ, ঝ, ড, ন,
ম, no change িাগ্মী = িাগ্মী with conjunct delete ম-ফা ক্ষী = ওঔী otherwise Sol.* অত্ম = অত্ত য-ফা
When next letter
is আ/ই/আ-ওার/ই-ওার এ-ওার িযবঢ = তিবঢ with conjunct delete য-ফা স্বাস্থ্য = াস্থ্ middle or end Sol.* লূনয = লুন্ন -ফা
1st position or
joint letter is no change ক্লান্ত = ক্লান্ত otherwise joint letter twice ক্লান্ত = ওক্লান্ত *Sol.: Use the previous consonant twice. If the previous consonant is „mohapran‟ then the first letter will be „alpopran‟ and the second letter will be „mohapran‟ of the corresponding consonant. The term „mohapran‟ signifies stressed pronunciation and „alpopran‟ signifies regular pronunciation.
o n u v u t i --- letters |---|---|---|---|---|---|---|---|
o on nu uv vu ut ti i --- diphones
Diphones can be categorized as:
vowel-consonant (vc): আও(ik), অম(am), ঈচ(uj) consonant-vowel (cv): চা(ja), ও(ko)
vowel-vowel (vv): অআ(ai), আঈ(iu) vowel-„‟ (vy): (oy), অ(ay)
vowel-„‟-vowel (vyv): আা(iya), ঈ(uyo) consonant-consonant (cc): ন্দ(nd), স্ক(sk), ত্ন(tn) fade-in vowel/consonant ({v,{c): {({o), {ভ্({v) fade-out vowel/consonant (v},c}): }(o}), ভ্}(v}) Here, fade-in (silence-to-phone) / fade-out (phone-to-silence) represents terminal letter. In the word অলা, for example, অলা = „{অ‟ (fade-in „অ‟) + „অল‟ + „লা‟ + „অ}‟ (fade-out „অ‟).
The starting „অ‟ denoted with „{‟ and the ending „অ‟ denoted with „}‟ implies fade-in and fade-out respectively.
Figure 3: Diphones in the waveform of word „নুভূবঢ‟ (Onuvuti) 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Av e rage Amar De sh Kale r Kontho Prothom Alo Accuracy
Figure 2: Accuracy of the proposed Text Normalization System
VI.CONSONANT -CONSONANT (CC) TYPE DIPHONES Some „cc‟ type diphones are simply silence. If the first consonant is nasal (ন, ড, ম, গ, ং), lateral (), trill (র), flapped (ড়, ঢ়), fricative (ল, , ) or affricate then diphone is meaningful. Otherwise if the first consonant is plosive (ও, ঘ, ঝ, ঢ, , ঔ, ঙ, ঞ, ণ, ফ, ক, চ, ট, দ, ি, খ, ছ, ঠ, ধ্, ভ) then it can be treated as silence. Here are some examples: ক্ত (kt), দ্ন (dn), প্ন (pn), ত্ন (tn), জ্ক (jg), প্স (ps) etc. Silence length is approximately 100-200 milliseconds.
If the silence is smaller (less then 100 millisecond), „VCCV‟ type sound is pronounced as „VCV‟. For example, the word ঝাক্কা (takka) will be pronounced as ঝাওা (taka). This is illustrated below in Fig. 4(a)(b) with the aid of signal waveform.
VII.DIPHONE PREPARATION A.Basic Issues
In diphone preparation, there are some issues that should be addressed for naturalness of the synthesized speech. These are amplitude mismatch, phase mismatch, pitch mismatch, and duration of diphone. The process of corpus recording can play signification role in addressing those issues. In our case, for example, the following conditions maintained during recording.
Constant speed of utterance Utterance at constant pitch
Similar duration of the vowel sound
Utterance at uniform amplitude and not to give unnecessary stress to any portion of the utterance
A professional speaker is thus important for corpus recording. In our case, we trained a speaker with knowledge of phonology [9] skilled in accurate pronunciation. Speech corpus is recorded in an apparently noiseless environment. Speech signal is sampled at 44100 Hz as mono sound. After the recording process is complete, diphone is prepared using a powerful signal processing application capable of noise reduction, amplitude and pitch modifications. The epoch synchronous technique [17] is used to overcome phase mismatch.
B.Quick Corpus
A Quick Corpus shown in Table 9 and Table 10 are used to prepare the diphones required for a typical speech synthesizer containing „cv‟, „vc‟, „vv‟, „vy‟, „vyv‟, „{p‟, „p}‟ type diphones.
TABLE 9
QUICK CORPUS OF „VC‟ AND „CV‟ TYPE DIPHONE
‘vc’ and ‘cv’ type diphone: ওও ওাও বওও কুও তওও তওাও ওযাও ঔঔ ঔাঔ বঔঔ ঔুঔ তঔঔ তঔাঔ ঔযাঔ কক কাক বকক কুক তকক তকাক কযাক খখ খাখ বখখ খুখ তখখ তখাখ খযাখ ঘঘ ঘাঘ বঘঘ ঘুঘ তঘঘ তঘাঘ ঘযাঘ ঙঙ ঙাঙ বঙঙ ঙুঙ তঙঙ তঙাঙ ঙযাঙ চচ চাচ বচচ চুচ তচচ তচাচ চযাচ ছছ ছাছ বছছ ছুছ তছছ তছাছ ছযাছ ঝঝ ঝাঝ টিঝ ঝুঝ তঝঝ তঝাঝ ঝযাঝ ঞঞ ঞাঞ ঠিঞ ঞুঞ তঞঞ তঞাঞ ঞযাঞ টট টাট বটট টুট ট তটট তটাট টযাট ঠঠ ঠাঠ বঠঠ ঠুঠ তঠঠ তঠাঠ ঠযাঠ ঢঢ ঢাঢ বঢঢ ঢুঢ তঢঢ তঢাঢ ঢযাঢ ণণ ণাণ বণণ ণুণ তণণ তণাণ ণযাণ দদ দাদ বদদ দুদ তদদ তদাদ দযাদ ধ্ধ্ ধ্াধ্ বধ্ধ্ ধ্ুধ্ তধ্ধ্ তধ্াধ্ ধ্যাধ্ নন নান বনন নুন তনন তনান নযান া ব ু ত ত া যা ফফ ফাফ বফফ ফুফ তফফ তফাফ ফযাফ িি িাি বিি িুি তিি তিাি িযাি ভভ ভাভ বভভ ভুভ তভভ তভাভ ভযাভ মম মাম বমম মুম তমম তমাম মযাম যয যায বযয যুয তযয তযায যযায রর রার বরর রুর তরর তরার র যার া ব ু ত তা যা লল লাল বলল লুল তলল তলাল লযাল া ব ু ত তা যা া ব ু ত তা যা ড়ড় ড়াড় বড়ড় ড়ুড় তড়ড় তড়াড় ড়যাড় ওং ওাং বওং কুং তওং তওাং স্ক স্খ স্ঘ স্ত স্থ্ স্ন স্প স্ফ স্ম ক্র খ্র গ্র ঘ্র চ্র ছ্র জ্র ঝ্র ট্র ঠ্র ড্র ঢ্র ণ্র ত্র থ্র দ্র ধ্র ন্র প্র ফ্র ব্র ভ্র ম্র য্র ল্র শ্র/ষ্র/স্র হ্র ক্ল গ্ল প্ল ফ্ল ব্ল ভ্ল ম্য শ্ল স্ল হ্ল ক্ষ স্ক্র স্খ্খ্র স্গ স্ত্র স্খ্থ্র স্প্র স্পৃ স্ফ্র স্খ্ম্র
Figure 4(a): Word ঝাক্কা (takka) (200 ms silence)
TABLE 10
QUICK CORPUS OF DIPTHONGS TYPE DIPHONE Dipthongs: আ - ওআ ঈ - ওঈ - ও অআ - যাআ অঈ - দাঈ অ - ঔা আআ - বদআ আঈ - বমঈ আ - বন ঈআ - মুআ ঈ - কু এআ - তযআ এঈ - তওউ এ - তন আ - তিাআ ঈ - তিাঈ - তলা এযাআ - ওযাআ এযাউ - ওযাঈ এযা - দযা - ওয়্ অ - যায়্ আয়্ - বময়্ ঈ - কুয়্ এয়্ - তদয়্ - তলায়্ এযা - নযায়্, িযয়্ - ওন া - ওা ব - ওবফ ু - ওুন ত - ওতন তা - ওতান অ - ওান অা - ওাা অব - ওাবফ অু - ওাুন অত - ওাতন অতা - ওাতান আ - বওন আা - বওা আব - বওবফ আু - বওুন আত - বওতন আতা - বওতান ঈ - কুন ঈা - কুা ঈব - কুবফ ঈু - কুুন ঈত - কুতন ঈতা - কুতান এ - তওন এা - তওা এব - তওবফ এু - তওুন এত - তওতন এতা - তওতান - তওান া - তওাা ব - তওাবফ ু - তওাুন ত - তওাতন তা – তওাতান Consonant: ও ঔ ক খ গ ঘ ঙ চ ছ জ ঝ ঞ ট ঠ ড ঢ ণ দ ধ্ ন ফ ি ভ ম য র ল ড় ঢ় Vowels - অ আ ঈ এ এযা
C.Diphone Labeling System
Efficient access of the diphone-files are important for a speech synthesizer to be useful in real-time. We use Unicode (Hexadecimal) value [18] of a letter to label the diphones. Before labeling, short forms of the vowels are converted to corresponding long forms (e.g. „ া‟ is converted to „অ‟).
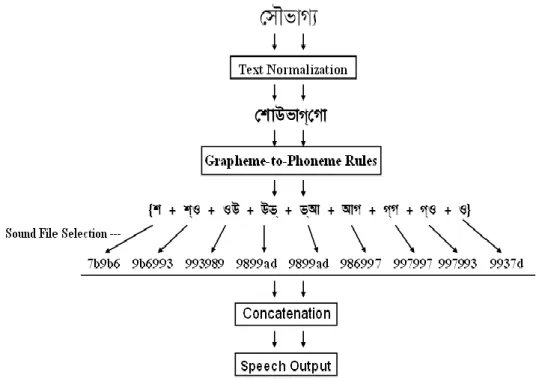
The label of diphone-file is produced as follows. First, the diphone „ওা‟ is converted to „ওঅ‟. The Unicode value of „ও‟ and „অ‟ are 0x995 and 0x986, respectively. Thus, the label of the diphone file is 995986.wav.
Some other labeling examples are given below. vowel-consonant (vc): আও = 987995 (আ = 987, ও = 995) consonant-vowel (cv): চা(চঅ) = 99c986 (চ = 99c, অ = 986) vowel - vowel (vv): আঈ = 987989 (আ = 987, ঈ = 989) vowel - „ ‟ (vy): = 9939df ( = 993, = 9df) vowel - „‟ - vowel (vyv):
আা = 9879df 986 (আ=987, =9df, অ=986) consonant - consonant (cc):
ন্দ = 9a89a6 ( ন = 9a8, দ = 9a6 ) fade-in vowel/consonant ( {v, {c ):
{ = 7b985 ( { = 7b, = 985 ) fade-out vowel/consonant ( v}, c} ):
ভ} = 9ad7d ( ভ = 9ad, } = 7d ) Special symbols:
Comma (,) = 0x2c and Dari (।) = 0x964. VIII.DIPHONE SELECTION (GRAPHEME-TO-PHONEME
CONVERSION) ALGORITHM The algorithm of the diphone selection can be described as follows:
Repeat until the End of a Word
1. If it is the end of a word select diphone named "previous letter +}".
2. If it is the start of a word select diphone named "{+current letter".
3. If the current letter is য-ফা then select diphone named "previous letter + য-ফা".
4. If previous letter is য-ফা and is not the last letter of a word then select diphone named "য-ফা+current letter".
5. If previous letter is য-ফা and it is the last letter of a word then select diphone named "য-ফা+}". 6. If it is a conjunct with র-ফা or -ফা then select
diphone named "{+first of joint letter" and "র/+dependent vowel".
7. If it is '' and preceded by a consonant then select diphone named "previous letter+a" and "a + + next dependent vowel". If the preceding letter is not a consonant then select only "previous dependent letter + + next dependent vowel".
8. If it is a dependent vowel then select diphone named "previous letter + dependent vowel". 9. If it is not a dependent vowel and the previous
letter is a consonant then select diphone named "previous letter+a" and "a+current letter". 10. Else select diphone named "previous letter +
current letter"
Dependent vowels are actually short forms of the vowels, like া, ব , ত etc. Previous or current letter mentioned above can also be a dependent vowel. As mentioned earlier, dependent vowels are converted to actual vowels.
It is mentioned that the step grapheme-to-phoneme conversion is performed on the normalized text [6, 8,
and 10] which is the actual pronounceable format of the words. Examples on diphone-selection for several words are presented below.
V: = '{' + '}' (o o)
C: ও = '{ক্' + 'ও' + '}' (k ko o) CV: মা = {ম্ + মা + অ} (m ma a)
VC: অঝ = {অ + অঝ + ঝ} (a + at + t) VCV: অঝা = {অ + অঝ + ঝা + অ} (a + at + ta + a) CVC: ভুঢ = {ভ + ভঈ + ঈঢ + ঢ} (v + vu + ut + t) CCV: স্কা = { + ওা + অ} (s + ka + a) VCC: অস্ত = {অ+অ+ঢ+তঢা+} (a+as+st+to+o) VCCV: অস্থ্া={অ+অ+ণ+ণা+অ}(a +as+sth+tha+a) CCCV: বস্ত্র = { + {ঢ + বর + আ} (s + t + ri + i) VCCC: ন্ত্র= + ন + ঢ} + র + } (o+on+t+ro+o)
Examples on diphone-selection for sentence case are shown below.
'ঢা ওী ‟ = {ঢ + ঢা + অও + বও + আহ্ + +
Actually, we do not stop when we speak. This is why every word-sound is mixed with that of the neighbor words. '' is handled specially. Examples:
= { + + , বমা = {ম + বম + আা + অ}
The effects of the symbols Comma (,) and Dari (।) are simulated by inserting 200 ms and 400 ms silence, respectively.
The whole process of diphone selection and labeling is depicted below in Fig. 5 for the word তৌভাকয.
IX.CONCLUSION
In this paper, we have presented techniques for Bangla text normalization and diphone preparation. We have developed a typical TTS system to verify the performance of the proposed text normalization and diphone selection processes. The speech synthesizer has been demonstrated (before a big number of university students and teachers) to produce intelligible and much natural sounding speech. Research is going on to add more fine-tunings to further improve the synthesizer quality. Future research on text normalization can be directed to sentence analysis and verbal words in Bangla.
X.REFERENCES
[1] Thierry Dutoit, An Introduction to Text-To-Speech
Synthesis, Kluwer Academic Publishers, 1997.
[2] Speech Synthesis, Online:
http://en.wikipedia.org/wiki/Speech_synthesis, Access
Date: 26th Jan, 2010.
[3] M. Beutnagel, A. Conkie, J. Schroeter, Y. Stylianou, and
A. Syrdal, “The AT&T next-gen TTS System,” Online::
http://www.research.att.com/projects/tts, Access Date: 26th
Jan, 2010.
[4] C-DAC: Research & Development - Speech Research,
Online: www.kolkatacdac.in/html/texttospeech.htm,
Access Date: 26th Jan, 2010.
[5] Firoj Alam, Promila Kanti Nath and Mumit Khan, "Text To speech for Bangla language using Festival", Proc. of Intl. Conf. on Digital Communications and Computer
Applications, Irbid, Jordan, 2007.
[6] Firoj Alam, S.M. Murtoza Habib, Mumit Khan, “Text
normalization system for Bangla,” Proc. of Conf. on
Language and Technology, Lahore, pp. 22-24, 2009.
[7] Tanuja Sarkar, Venkatesh Keri, Santhosh Yuvaraj, Kishore Prahalad, "Building Bengali voice using
Festival," Proc. of ICLSI 2005, Hyderabad, India, 2005.
[8] Md. Hanif Seddiqui, Muhammad Anwarul Azim, Md.
Shahidur Rahman, and M. Zafar Iqbal, "Algorithmic approach to synthesize voice from Bengali text," Proc. of Intl. Conf. on Computer Sciences and Information
Technology , Vol. 5, pp. 233-236, December, 2002.
[9] Muhammad Abdul Hai, “Dhvani Vijnan O Bangla Dhvani
-Tattwa”,. Mullick Brothers Publishers, 2000.
[10]Noren Biswash, “Bangla Academy Bangla Uccharan
Ovidan,” Bangla Academy, January 2003.
[11]Ho-Leung Chan, Wing-Kai Hon, Tak-Wah Lam and Kunihiko Sadakane, “Dynamic dictionary matching and compressed suffix trees, ” Proc. of the sixteenth annual
ACM-SIAM symposium on Discrete algorithms, pp. 13 –
22, 2005.
[12]A. Aho and M. Corasick. “Efficient string matching: An aid to bibliographic search”. Communications of the ACM,
Vol 18(6), pp. 333–340, 1975.
[13]Md. Reza Selim and M. Zafar Iqbal, “Syntax analysis of
phrases and different types of sentences in Bangla,” Proc.
Intl. Conf. on Computer and Information Technology,
Sylhet, December 1999.
[14]Newspaper „Amar Desh‟: Title: “লঢভাক াফতযর দাবি প্রতঙ্গ বওঙু
ওণা,” Online: http://www.amardeshonline.com/
pages/details/2010/01/25/15376, Access Date: 25th Jan,
2010.
[15]Newspaper „Kaler Kontho‟ Title: “যুদ্ধা রাধ্: ট্রাা অমাতদর
ম্ভািয ট্রযাতচবট,” Online: http://www.dailykalerkantho.
com/?view=details&type=single&pub_no=58&cat_id=2&
menu_id=23&news_type_id=1&index=1. Access Date:
26th Jan, 2010.
[16]Newspaper „Prothom Alo‟: Title: “ুন্দর মাচ কঞতন ভূবমওা
রাঔতি স্কাঈঝতদর ল ণ,” Online: http://www.prothom-alo.com/
detail/date/2010-01-26/news/37595. Access Date: 26th
Jan, 2010.
[17]Mandal, Shyamal Kumar Das and Datta, Asoke Kumar, "Epoch synchronous non-overlap-add (ESNOLA) method-based concatenative speech synthesis system for Bangla,"
ISCA Workshop on Speech Synthesis, Bonn, August , 2007
[18]Unicode chart- Online: http://unicode.org/charts/. Access
Date: 26th Jan, 2010.
[19]Firoj Alam, S.M. Murtoza Habib, Mumit Khan, “Text
normalization system for Bangla,” Proc. of Conf. on
Language and Technology, Lahore, January, 2009
[20]G. L. Jayavardhana Rama, A. G. Ramakrishnan, R.
Muralishankar and R Prathibha, “A complete
text-to-speech synthesis system in Tamil,” Proc. of IEEE
Workshop on Speech Synthesis, pp. 191-194, September,
Santa Monica, CA, 2002.
[21]Building Synthetic Voices. Online:
http://www.festvox.org/bsv, Access Date: 26th Jan, 2010.
[22]
Muhammad Masud Rashid, Md. Akter Hussain, M.Shahidur Rahman, “Diphone preparation for Bangla text to
speech synthesis,” Proc. of Intl. Conf. on Computer
Sciences and Information Technology, pp. 226-230, Dhaka,