Analysis Of Different Utility Mining Methodologies
In Transactional Databases
Divvela.Srinivasa Rao
Sr.Asst.Professor, Lakireddy BaliReddy College of Engineering,
Abstract: Utility Mining may be delineated as an motion that analyze the data and draws out a few new nontrivial information from the big amount of databases. traditional data mining methods have focused on finding the statistical correlations between the items which are often acting within the database. high software itemset mining is a place of studies where application primarily based mining is a descriptive type of information mining, geared toward locating itemsets that dedicate maximum to the entire software. Mining high software itemsets from a database refers to the discovery of itemsets with excessive utility in phrases like weight, unit earnings or price, additionally entitled as common itemset mining with high earnings. In high utility Itemset Mining the aim is to understand itemsets which have utility values above a given application threshold. in this paper, we present a literature survey of the prevailing state of studies and the numerous algorithms and its obstacles for high application itemset mining.
Keywords: Transactional Databases, Utility Mining, Item set Mining, UP-Growth, UP Growth+
I. INTRODUCTION
The objective of frequent itemset mining [1] is to find items that frequently appear in a transaction database [2] and higher than the frequency threshold given by the consumer, without considering profit of the item. However, quantity, weight and value are significant for addressing real world decision problems that require maximizing the utility in an organization.
The restraint of frequent itemset mining [3] is it assumes (1) an item can only appear once in a transaction (2) all items have the same importance/weight (e.g. Profit). So it may ignore rare itemset having higher profit (e.g. Caviar, wine). To overcome this issue, the problem of FIM [1] has been resolved as High-Utility Itemset Mining (HUIM). The high utility itemset mining problem is to find all itemsets that have utility larger than a user specified value of minimum utility. The value or profit Associated with every item in a database is called the utility of that itemset. Utility of items in transaction database involves following two aspects:
The importance of distinct items, called external utility(e), and The importance of items in transactions, called internal utility(i).
Utility of Itemset (U) = external utility (e) * internal utility (i).
In many areas of business like retail, inventory, etc. decision making is very important. In a transaction database each item is represented by a binary value, without considering its profit.In many applications like cross-marketing in retail stores, online e-commerce management, website click- stream analysis and finding the important pattern in bio- medical
applications High utility mining are widely used.The older strategies of ARM keep in mind the application of the objects by
the concept of excessive application itemset mining the use of the principles of records mining. In section II we’re imparting the example of mining frequent itemset from transaction dataset. In segment III we’re imparting the different methods presented for high application mining. Application- based totally facts mining is a vast subject matter that covers all elements of economic utility in records mining. It encompasses predictive and descriptive strategies for facts mining, a number of the later especially detection of uncommon occasions of high utility (e.g. high application patterns). This paper describes techniques for itemset mining or more particularly, mining software-common itemsets that is a special form of high utility itemset mining. Utility of an itemset is defined because the fabricated from its external application and its inner utility. An itemset is known as a excessive utility itemset. If its application isn’t any much less than a person-detailed minimal utility threshold; in any other case, it’s miles called a low-application itemset.
II. LITERATURE SURVEY
On this section we present a brief assessment of the one of a kind algorithms, strategies, ideas and processes that have been described in diverse research journals and guides. Agrawal, R., Imielinski, T., Swami, A. [1] proposed frequent itemset mining set of rules that uses the Apriori precept. General technique is primarily based on SupportConfidence model. Support degree is used. An anti-monotone property is used to reduce the quest space. It generates common itemsets and finds association rules between objects inside the database. It does not become aware of the utility of an itemset [1]. Yao, H., Hamilton, H.J., Buzz, C.J. [2] proposed a framework for high application itemset mining. They generalize preceding work on itemset proportion degree [2]. This identifies kinds of utilities for objects, transaction software and external utility. They recognized and analyzed the hassle of software mining. In conjunction with the software sure property and the aid bound assets. They defined the mathematical version of application mining primarily based on those residences. The utility sure property of any itemset offers an top sure at the application fee of any itemset. This software sure belongings can be used as a heuristic degree for pruning itemsets as early ranges that are not predicted to qualify as excessive software itemsets [2]. Yao, H., Hamilton, H.J., Buzz, C.J. [3] proposed an set of rules named Umining and any other heuristic primarily based algorithm UminingH to find high utility itemsets. They apply pruning strategies primarily based on the mathematical houses of application constraints. Algorithms are greater green than any previous software based mining set of rules. Liu, Y., Liao, W.okay., Choudhary A. [4] proposed a two phase set of rules to mine high software itemsets. They used a transaction weighted software (TWU) degree to prune the hunt area.
dense datasets at most aid degrees for lengthy and quick styles.
III. FP-GROWTH PROCEDURE FOR PATTERN MINING
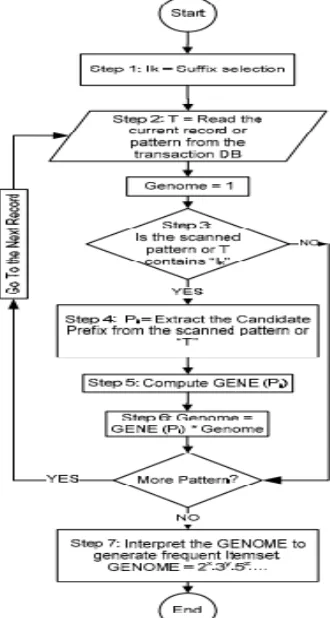
The essential theorem of mathematics says that every positive integer has a completely unique high factorization. What the FP-growth does is getting a not unusual suffix after which extracts all viable prefixes and after joining them to the suffix a common pattern is created. In the FP-growth set of rules it isn’t always crucial that we are searching out all common patterns cease to a selected suffix like “I5” or we want to extract all the frequent patterns. In contrast with FP-increase the FPPF for mining of all frequent styles cease to a specific suffix like “I5”, does no longer create complete of the tree and just makes a speciality of prefixes related to that specific suffix. Without producing a tree, our set of rules referred to as common sample-high aspect (FPPF) extracts the common prefixes and generates the common itemset which ends up with that suffix. In table three all of the used symbols and acronyms which might be used in this section are supplied. The following affords a few primitive definitions which can be important to clarify the frequent sample mining hassle.
Definition 2.1: “L” is defined as a fixed of all frequent itemsets with duration 1 and is denoted as follows:
[image:4.612.201.366.328.637.2]L = I1: SUP(I1), I2: SUP(I2), …, In: SUP(In) wherein: ƒ “Ii” is a frequent itemset with period 1. “SUP (Ii)” is a support count of itemset “Ii” that’s extra than minimal support be counted.ƒ “L” is looked after descending primarily based on aid depend, because of this SUP (Ii) > SUP (Ii+1). As an example regarding table 1 the L set is I2:7, I1:6, I3:6, I4:2, I5:2.
Figure 1: Framework with procedure of utility mining operations.
Definition 2.2: A sample or itemset “T” with period m is represented as T = I1, I2, …, Im such that “Ij” represents the object in “jth” function of “T”. for example if T = a, b, c then “I1” is the item “a”. all the patterns “Ti” is taken care of in “L” order which means SUP(Ii) > SUP(I(i+1)).
represented as M = T1,T2,…,Tn in which “T” is a sample or itemset (Definition 2.2).
Definition 2.4: A common sample “FP” is a sample like T = I1, I2, …, Ik such that the “SUP(T)” is more than minimal assist count.
Definition 2.5: The set “Fj” is described as a set of all frequent patterns in which their ultimate object is “Ij” that “Ij L”. It way “Ij” is a suffix for all of the styles in “Fj” set. For example if “I3” is “h” then “F3” is about of all frequent styles like “abh” or “asdfh”
wherein the ultimate item is “h”. observe that after “I ≠ j” then “Fj ∩ Fi = ” this means that there is no frequent pattern like “T” that
at the identical time ends with two distinctive gadgets “Ii” and “Ij”.
The problem of mining the frequent patterns of set “M” is reduced to the problem of mining “Fj” sets. Frequent pattern mining for “Fj” is achieved by extracting all prefixes (subpattern) such that if joining the prefixes to the related suffix “Ij” the result pattern is a frequent pattern.
IV. COMPARISON BTW PROCEDURE OF UTILITY MINING
Table 1: Comparison of different methods for extracting high utility itemsets from transactional data bases
No Title Of Paper Year Author(s) Datasets Name of
Algorithm
Overview of
work/Idea Limitation
`Idea Of Improvem
1
A Two-Phase Algorithm for Fast Discovery of High
Utility Item sets[4] 2005
Ying Liu, Wei-keng Liao, and Alok Choudhary Transaction dataset Two- Phase
Phase 1: Discover
Multiple scans of database and generates many candidate Itemsets This approach is suitable for sparse database with short Patterns. candidate
itemsets, that is
having a TWU ≥
minutil,
Phase 2: For each candidate, calculate its exact utility by database 2 CTU-Mine: 2007 Alva Erwin, Raj P. Gopalan, N.R. Achuthan, Transaction
dataset CTU-Mine
Use pattern growth algorithm and also
eliminates the expensive second phase of scanning the database
Complex for evaluation due to the tree structure
This approach is suitable for dense dataset with long pattern An Efficient High
Utility Itemset Mining Algorithm Using the Pattern Growth
Approach [5]
3
UP-Growth: An Efficient Algorithm for High Utility Itemset
Mining[6] 2010
Vincent S. Tseng, Bai-En Shie, Transaction dataset UP- Growth (1) construction Complex for evaluation due to the tree structure
synthetic and real datasets are used to evaluate the high performanc ofUP-Tree, (2) generation of potential high utility itemsets from the UP-Tree by UP-Growth, and (3)
itemsets e of the algorithm
4
Mining High Utility Itemsets without Candidate Generation[7] 2012 Mengchi Liu, Junfeng Qu Transaction dataset Hui-Miner Single Phase Algorithm. No need to multiple times database scan
Calculating
We should try to avoid performing joins if possible for low-utility the utility of an itemset joining utility list is very costly. 5 FHM: Faster 2014 Philippe Fournier- Viger, Cheng- Wei wu Transaction
dataset FHM
Estimated-Utility Co-occurrence pruning Static Database We should try it using a dynamic database. High-Utility
Itemset Mining using Estimated Utility Co- occurrence
Pruning[8]
V. METHODS
There are four predominant methods used for mining high software itemsets from transactional databases which can be given as follows:
A. Data Structure
A compact tree structure, UP-Tree, is used for facilitate the mining performance and keep away from scanning authentic database repeatedly. it will additionally hold the transactions information’s and high application itemsets.
B. UP-Boom Mining Technique
After creation of worldwide UP tree, mining UP-Tree through FP- increase for producing PHUIs will generate so many candidates with a view to avoid that UP-increase technique is used with two strategies: One is discarding unpromising objects in the course of building a neighborhood UP-Tree. another is discarding local node utilities. preceding studies, problems in this section arise: 1) number of HTWUIs is too big; and (2) scanning original database could be very time eating. In our framework, overrated utilities of PHUIs are smaller than or same to TWUs of HTWUIs for the reason that they're decreased via the proposed strategies. as a result, the quantity of PHUIs is a good deal smaller than that of HTWUIs. therefore, in segment II, our technique is tons green than the preceding techniques. moreover, although our methods generate fewer candidates.
C. An Advanced Mining Method: UP-Growth+
Increase achie es higher perfo mance than FP-increase by way of the usage of DLU and DLN to decrease overvalued utilities of itemsets. however the overestim ted utilities can be in the direction of their real u ties with the aid of eliminating the predicted utilities that are loser t actual utilities of unp mising gadgets and descendant nodes in this phase, we advocate an progressed approach, named UP-growth+, for reducing overvalued utilities more successfully. In UP-increase, minimal object application desk is used to lessen the overvalued utilities. In UP-increase+, minimum node utilities in each course are used to make the estimated pruning values toward actual application values of the pruned gadgets in database.
D. Correctly Discover High Application Itemsets
Moreover, although our methods generate fewer candidates.
VI. CONCLUSION
Most of research on high utility itemset focuses on static databases (eg. Transaction database). With the emergence of the new application, the data processed may be in the continuous dynamic data streams. Because the data in streams come with high speed and are continuous and unbounded, mining result should be generated as fast as possible and make only
one pass over a data. In this paper, we have proposed two algorithms named UP- Growth and UP-Growth+ for mining high
utility itemsets from transaction databases. A data structure named UP-Tree was proposed for maintaining the information of high utility itemsets. PHUIs can be efficiently generated from UP-Tree with only two database scans. Moreover, we developed several strategies to decrease overestimated utility and enhance the performance of utility mining. Comparison results show that the strategies considerably improved performance by reducing both the search space and the number of
candidates. Proposed algorithms, especially UP- Growth+, outperform the state of-the-art algorithms substantially especially
when databases contain lots of long transactions or a low minimum utility threshold is used. Proposed system having applications in Website click stream analysis, Business promotion in chain hypermarkets, Cross marketing in retail stores, online e-commerce management, Mobile commerce environment planning and even finding important patterns in biomedical applications. In this Paper we have presented a review on various algorithms, work, idea and limitations of different methods for high utility Itemset mining using a transaction dataset, In the next paper we will present One pass algorithm for High utility Itemset Mining using stream data.
REFERENCES
[1] Agrawal, R., Imielinski, T., Swami, A.: Mining Association Rules between Sets of Items in Large Database. In: ACM SIGMOD International Conference on Management of Data (1993) .
[2] A. Erwin, R.P. Gopalan, and N.R. Achuthan,“Efficient Mining of High Utility Itemsets from Large Datasets”, T. Washio et al. (Eds.):PAKDD2008, LNAI 5012, pp. 554–561, 2008. © Springer-Verlag Berlin Heidelberg 2008.
[3] Yao, H., Hamilton, H.J., Buzz, C. J., “A Foundational Approach to Mining Itemset Utilities from Databases”, In: 4th SIAM International Conference on Data Mining, Florida USA (2004).
[4] “A Two-Phase Algorithm for Fast Discovery of High Utility Itemsets”, Ying Liu, Wei-Keng Liao, and Alok Choudhary, Northwestern University, Evans.
[5] “CTU-Mine: An Efficient High Utility Itemset Mining Algorithm Using the Pattern Growth Approach” In: Seventh International Conference on Computer and Information Technology (2007).
[6] “UP-Growth: An Efficient Algorithm or High Utility Itemset Mining ”, Vincent S. Tseng, Cheng-Wei Wu, Bai-En Shie, and Philip S. Yu. University of Illinois at Chicago, Chicago, Illinois, USA, 2010.
[7] Mengchi Liu Junfeng Qu, “Mining High Utility Itemsets without Candidate Generation”, 2012.
[8] “FHM: Faster High-Utility Itemset Mining using Estimated Utility Co-occurrence Pruning”, Philippe Fournier-Viger1, Cheng-Wei Wu 2014.
[9] Smita R. Londhe,, Rupali A. Mahajan,, Bhagyashree J. Bhoyar,”Overview on Methods for Mining High Utility Itemset from Transactional Database”, International Journal of Scientific Engineering and Research (IJSER), Volume 1 Issue 4,December2013
[10] Y. Liu, W. Liao and A. Choudhary, “A fast high utility itemsets mining algorithm,” in Proc. of the Utility-Based Data Mining Workshop, 2005.
[11] S.Shankar, T.P.Purusothoman, S. Jayanthi,N.Babu, “A fast agorithm for mining high utility itemsets” ,in :Proceedings of IEEE International Advance Computing Conference (IACC 2009), Patiala, India, pp.1459-1464.
[12] Sucahyo, Y.G., Gopalan, R.P., CT-PRO: “A BottomUp Non Recursive Frequent Itemset Mining Algorithm Using Compressed FP-Tree Data Structure”, In: IEEE ICDM Workshop on Frequent Itemset Mining Implementation (FIMI), Brighton UK (2004).
[13] G. Salton, Automatic Text Processing, AddisonWesley Publishing, 1989.
[14] J. Pei, J. Han, L.V.S. Lakshmanan, “Pushing convertible constraints in frequent itemset mining”, Data Mining and Knowledge Discovery 8 (3) (2004) 227–252.
[15] A. Erwin, R.P. Gopalan, and N.R. Achuthan, “Efficient Mining of High Utility Itemsets from Large Datasets”, T. Washio et al. (Eds.): PAKDD 2008, LNAI 5012, pp. 554–561, 2008. © SpringerVerlag Berlin Heidelberg 2008.
[16] Bin Chen, Peter Hass, Peter Scheuermann, “A New Two-Phase Sampling Based Algorithm for Discovering Association Rules”, SIGKDD '02 Edmonton, Albetra, Canada © 2002 ACM 1 58113 567 X/02/2007.
[17] Ming-Yen lin, Tzer-Fu Tu, Sue-Chen Hsueh, “High utility pattern mining using the maximal itemset property and, lexicographic tree structures”, Information Science 215(2012) 1-14.