A Technique for Incomplete Pattern
Classification by Using EM Clustering
Ashwini. S. Bhosale, Dr.A.B.Pawar
PG Student, Department of Computer Engineering, SRES’ College of Engineering, Kopargaon, Savitribai Phule Pune
University, India
Associate Professor, Department of Computer Engineering, SRES’ College of Engineering, Kopargaon, Savitribai
Phule Pune University, India
ABSTRACT: Depending on the values that are not present in dataset a system is designed known as incomplete pattern system. Classifying the incomplete pattern is very critical task. The prototype base creedal classification (PCC) is a novel method proposed to solve above problem. To guess the absent values training samples are utilize via class prototypes. To address the classification issue a novel credel combination technique is proposed. In this proposed system k-means clustering is performed for classification of the incomplete pattern in particular class. The information fusion is performed in the system with the selected meta-class.
KEYWORDS: Prototype Based classification, clustering, k-means clustering.
I.INTRODUCTION
Missing pattern imputation is an important topic in information preprocessing that's an imperative step in information mining, as well as it usually gives increase to typical dispute challenges by domain specialists. Because the information quality of the outcome in the preprocessing step could be a noteworthy worry in information preparing, analysts have associated sizable consideration on missing value imputation throughout all through the previous decade. Much work has been done to create techniques as well as tool to handle missing qualities. All through late years, in whichever field of study, kNNI imputation system has been broadly contemplated as well as wide connected as a consequence of its high strength, straightforward agent and sizable precision. Information attribution is created as a tangle of estimation of missing qualities by numerous operations supported cluster. Besides, the prime commitment of this paper may be delineated as follows. (a) Separating non missing things into a limited range of well-partitioned clusters contributes to make the fulfillment inside the optimum tailored space. (b) The grey relative examination, that signifies the situational variety of the curve, may describe the relative disparity extra precisely. (c) CBGMI is adjusted to the sensible area with proper performance. In any case, in line with the examination of the unfinished learning, it furthermore altogether influenced by thickness of focuses in each quadrant furthermore the distance between the unfinished information and complete information. That's why, supported QENNI, it means to take under attention the density as well as distance by consideration them and therefore propose an a great deal of enhanced imputation algorithmic program, Density- and Distance-weighted and Quadrant-based imputation algorithmic program (DDWQ), that beats the limitations specified above and demonstrates a more functional execution than QENNI.
classification strategy, as an outcome of the meta-classes square measure really helpful and important to show to the estimation of the characterization.
II.RELATED WORK
In paper [2], authors has given a novel credal combination technique for addressing the classification issue that is adequate to characterize the inherent uncertainty because of the likely confusing outcomes given by the different estimations of absent information attributes. The incomplete patterns which are not easy to classify in a particular class will be reasonably as well as automatically committed to some proper meta-classes by this novel PCC technique for minimizing the misclassification rate. The effectiveness of this novel PCC technique is analysed by three experiments with artificial and real sets of data.
In paper [3], the mass appearing on the empty set while the conjunctive combination rule is commonly treated as confusions, but that is not actually a conflict. Some cases of conflict have been given, this recalls few from them also this demonstrates some counter-intuitive examples with these measures. Hence it characterizes a conflict measure depending on expected properties. This conflict measure is implemented from the distance-based conflict measure weighted by a degree of inclusion given in this paper.
In paper [4], a regression method depending on the statistical learning theory of Vapnik. The membership as well as belief processes have common attributes; which it takes as constraints in the resolution of our convex issue in the support vector regression. The given method is used in a pattern recognition context to calculate its efficiency. Therefore, the regression of the membership functions as well as the regression of the belief functions provided two types of classifiers: a fuzzy SVM as well as a belief SVM. From the studding information, the membership also belief functions are created from two classical methods given accordingly by fuzzy as well as belief k-nearest neighbors. Hence, it compares the proposed method, in terms of classification outcome, with these two k-nearest neighbors as well as with support vector machines classifier.
In paper [5], authors have investigates methods for studying efficiently from uncertain information utilizing belief functions. For extracting more knowledge from improper as well as insufficient data also for improving classification prison, it provides a supervised learning technique derived from a feature selection process as well as a two-step classification method. By making use of training data, the given feature selection process automatically determines the higher informative feature subset by suppressing an objective function. Given two-step classification method increases the decision-making accuracy by using complementary information obtained during the classification process. The performance of the implemented system was calculated on different synthetic as well as real datasets.
III.PROPOSED SYSTEM
A System Architecture
Fig.1. System Architecture
We created a new system for classification of incomplete information based on the estimation of missing values in proposed system. Most popular mean imputation (MI) technique is used, for the missing values are importantly changed through all common values of that attribute. The missing values are calculated by implementing the K nearest neighbors of the object (incomplete pattern) in the K-nearest neighbor imputation (KNNI) technique. Further, KNNI needs most calculation overhead. The missing values are filled on the basis of the clustering centers generated through FCM and the distance between the object and the centers in fuzzy c-means imputation (FCMI) method. Number of various techniques is also available for imputation, such as the SOM imputation, the regression imputation, the multiple imputation methodology etc. All of the systems (except multiple imputations) generate one and only accurate estimation for the missing value and they are not prepared for good reflection the ambiguity related the prediction of the missing values. Missing values are imputed M times to generate M whole data sets depending on an suitable structure with random variety, but the structure is complex to obtain in few scenarios in multiple imputation system. The multiple imputation methodology essentially focuses over the imputation of the missing values.
B. Algorithms
Algorithm 1: K means Algorithm
Input K: the number of clusters D: a data set containing n objects Output: A set of k clusters
2. Repeat
3. Find similarity distance from centroids to documents.
4. Reassign each object to the most similar cluster based on the mean value of the object in the cluster
5. Update the cluster means
6. Do 3, 4, and 5 until no change
Algorithm 2: EM Clustering Algorithm
1. Check for base cases [Initial Device List form Current Active Directory List]
2. . For each attribute a{ from the captured packets- Device address MAC} Find the normalized information gain from splitting on a{ select the 16 Bit device from the Least Most Significant Bit}
3. Let a best be the attribute with the highest normalized information gain {Allowed to communicate on Network}
4. Create a decision node that splits on a best {Select the Least Significant Bits or the Significant bit for Cross Over}
Recourse on the sub lists obtained by splitting on a best, and add those nodes as children of node.
C. Mathematical Model
Determine the weighting factors by
i
W
W
igg
i
max
2. Discount the c classification results using
)
(
)
(
1
)
(
{
m
A
P
A
P
m
g i s i g i g i g i s i g i
3. Sub combination of consistent classification results bymws
A
m
m
A
m
k i j i w is
(
)
[
,....,
]
4. Select meta-classes according to
}
)
(
)
(
|
{
maxmax
s ws i w i si
w
Bel
w
Bel
w
a
PROBLEM MODELLING AND DESIGN USING SET THEORY
1. Input Incomplete Pattern I= {i1, i2, i3,..., in} Where, I is the set of Incomplete Pattern and i1, i2, i3,....,in are the number of documents.
2. EM Clustering C = {c1, c2,....,cn} Where C is the set of clusters and c1,c2,...,cn represent as a number of clusters.
3. Object with missing values = X
4. Classification XL = {xl1,xl2,...,xln}
5. Discounting the classification P= {p1,p2,ˆapn}
5. Global Fusion F= {f1, f2, f3 ,...,fn}Where, F is the set of global fusion and f1, f2, f3,..., fn are the number of Fusion.
6. Credal Classification of x = R
D. Experimental Setup
For building the system we used Java framework (version jdk 8) on windows system. As a development tool we are using Net beans (version 8.1). The system will be work on any standard machine. In case of experiments we are writing code for missing data from dataset.
IV. RESULTS AND DISCUSSION
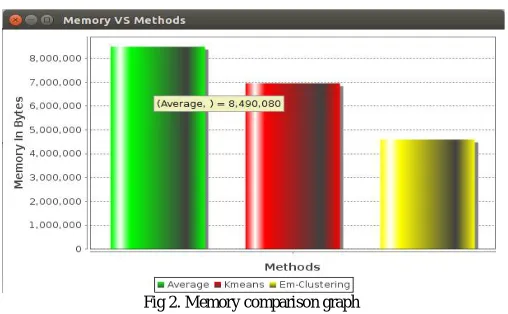
Fig 2. Memory comparison graph
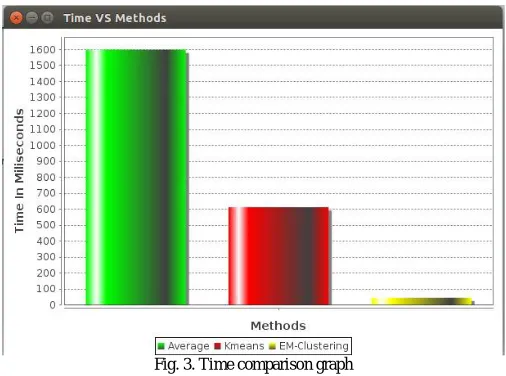
Fig. 3. Time comparison graph
Figure 3 shows the time comparison graph between three different techniques. In which we can clearly see that the EM clustering takes less time to process compared with others.
V.CONCLUSION AND FUTURE SCOPE
This given a missing pattern classification for inadequate information operation which ends the values as well as pattern by math operation. In the proposed system evidential thinking considers imperative part to missing pattern in the dataset. The worldwide combinations of those marked down outcomes are adopted for philosophical framework order of the article. If the c result comes to about square measure consistent on the classifications, the article will be centered on a selected classification which is strongly maintained by the c results. Nevertheless, the high conflict among these c results recommends that the classification of the article is somewhat unverifiable and evaluated only maintained the far-really well known qualities information. In such case, the article ends up being frightfully hard to categoryify really in an exceedingly specific class and it's truly dispensed to the benefit meta-class portrayed by the union of the definite arrangements that the article is in all likelihood going to fit in with. By then the conflicting mass of conviction is traded not thoroughly to the picked meta-class. At the point when Associate in nursing article is centered around a meta-class, it proposes that the accurate classification encased within the meta-class appear to be indistinct for this thing supported the far-truly well-known qualities.
REFERENCES
[1] Zhun-ga Liu , Quan Pan, A new incomplete pattern classification method based on evidential reasoning, School of Automation, Northwestern Polytechnical University, Xi’an, China, 2013.
[2] Arnaud Martin, About conflict in the theory of belief functions, University of Rennes 1, IRISA, rue E. Branly, 22300 Lannion, 2007.
[3] HichamLaanya, Arnaud Martin, Support vector regression of membership functions and belief functions - Application for pattern recognition, Faculty of Sciences of Rabat, Morocco and ENSITA-E312-EA3876, 2, rue Francois Verny 29806 Brest Cedex 9, France, 2014.
[4] ChunfengLian, Su Ruan, An evidential classifier based on feature selection and two-step classification strategy University de Rouen, QuantF-EA 4108 LITIS, France, 2015.
[5] Zhun-gaLiu , Jean Dezert , Grégoire Mercier, Belief C-Means: An extension of Fuzzy C-Means algorithm in belief functions framework, School of Automation, Northwestern Polytechnical University, Xi’an, China, 2012.
[6] Thierry Denoeux, Maximum Likelihood Estimation from Uncertain Data in the Belief Function Framework University de Technologie de Compiegne, CNRS, Compieque, 2013