Available online:
https://edupediapublications.org/journals/index.php/IJR/
P a g e | 258A Statistical Clustering Data Streams Based On Shared Density among Micro
Clusters
Mrs.A.Geetha, Mr.N.Rajkumar
Assistant Professor, DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING , visvesvaraya college
of engineering and technology
[email protected]
[email protected]
ABSTRACT
As of currently the applications offer streaming information, an agglomeration information stream has introduced a very important formulation for information and information engineering. A tough understanding is to instantiate the information stream in period with an internet method to create an enormous variety of functions known as micro-clusters. Micro-clusters formulates shared density enhance by providing the information the knowledge the information of huge data points during an outlined place. On the prevailing demand, a (enhanced) supposed to convey agglomeration algorithmic rule that is employed during a specific offline step to create the micro-clusters into immense final micro-clusters. to create agglomeration, the information of the small clusters are used as pseudo points with clusters isn't keep within the on-line method and re agglomeration is predicated on specific engorged assumptions concerning the promotion of information among and between small clusters that incontestable captures the density between small clusters via information streams supported shared density graph. Data stream information during this graph is then used for re agglomeration supported shared density between adjacent small clusters. We have a tendency to conclude the realm and time complexness of handling the shared density graph. Tests supported big selection of incontestable and original information sets highlight that victimization shared density improves agglomeration quality over different exhausted
information stream agglomeration strategies that need the creation of an enormous variety of less small clusters to extract comparable results.
Index Terms
—Data mining, data stream clustering, density-based clusteringINTRODUCTION
The data stream is an existing and capable limit sequence of information points. Those streams area unit unceasingly existing knowledge area unit created for a lot of forms of applications and
embody GPS knowledge from sensible mobiles internet click-stream knowledge, electronic network observant knowledge, broadcast association knowledge, extracting from detector networks,
Available online:
https://edupediapublications.org/journals/index.php/IJR/
P a g e | 259clusters (cells) and therefore its be part of micro-clusters (grid cells)
that area unit combined along however by identical time divided by a tiny low place of low data stream density. To switch this drawback, He introduced AN extension to the shared density-based dB Stream algorithmic program supported the thought of extraction between connected grids cells and showed its efficiency
In this paper, we have a tendency to enhance and judge a replacement module to access this drawback for small cluster stream based mostly algorithms. We have a tendency to provide the trail thought of a shared density graph that clearly holds the density of the important knowledge between small clusters throughout bunch and so show however the graph may be used for the small clusters. this is often a unique commitment since various on trust and on assumptions concerning the distribution of information points appointed to a small cluster (MC) it enhance the density within the shared region between small clusters directly from the info. To the simplest of our data, this paper is that the 1st to implement and investigate employing a shared density based mostly re bunch approach for knowledge stream bunch. A pc cluster consists of a group of loosely or tightly connected pc that job along in order that, in several respects, they will be viewed as one system.
In contrast to grid pcs computer clusters have every node set to perform identical task, controlled and regular by software package. Grid computing is that the assortment of pc resources from multiple locations to achieve a standard goal. The grid may be thought of as a distributed system with non-interactive workloads that involve an outsized variety of files. Grid computing is distinguished from standard high performance computing. Systems like cluster computing therein grid pc have every node set to perform a special task/application. Planned work utilizes the situation and interest feature of cluster to boost the potency of file question. Density clusters area unit supported the situation and sub clustered on the interest and file replication in streams in order that content delivery may be done quick overloading on one peer may be avoided.
Summarize the information employing a set of k0 small clusters organized during a space-efficient organization that conjointly allows quick search. Small clusters square measure representatives for sets of comparable knowledge points and square measure created employing a single leave out the information (typically in real time once the information stream arrives). Micro-clusters square measure generally
diagrammatic by cluster centers and extra statistics as weight (density) and dispersion (variance). Every new datum is assigned to its highest (in terms of a similarity function) micro-cluster. Some algorithms use a grid instead and non-empty grid cells represent small clusters. If a replacement datum can't be assigned to associate existing micro-cluster, a replacement small cluster is formed. The
algorithmic rule may additionally perform some work (merging or deleting small clusters) to stay the amount of micro-clusters at a manageable size or to get rid of noise or data noncurrent because of conception drift. When the user or the applying need as agglomeration, the k0 micro-clusters square measure re clustered into k (k eight k0) final clusters typically cited as macro-
clusters. Since the offline half is typically not regarded time essential, most researchers solely state that they use a traditional agglomeration algorithmic rule (typically k-means or a variation of DBSCAN [10]) by concerning the micro-cluster center positions as pseudo-points.
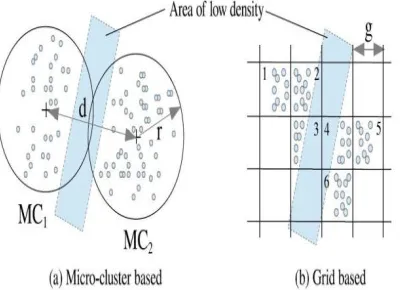
The algorithms square measure typically changed to require conjointly the burden of small clusters under consideration. Re agglomeration ways primarily based only on micro-clusters solely take closeness of the micro-clusters under consideration. This makes it doubtless those 2 micro-clusters that square measures on the brink of one another, however separated by a neighborhood of denseness still are going to be unified into a cluster. Data concerning the density between small clusters isn't out there since {the information |the knowledge |the knowledge} doesn't get recorded within the on-line step and therefore the original data points are not any longer out there. Illustrates the matter wherever the micro-clusters MC1 and MC2 are going to be unified as long as their distance d is low. This can be even true once density-based agglomeration ways (e.g., DBSCAN) square measure utilized in the offline re agglomeration step, since the re agglomeration remains solely supported the micro-cluster centers and weights. Many density-based approaches are planned for data-stream agglomeration. Density-based knowledge stream agglomeration algorithms like D-Stream [7] and MR-Stream [8] use the thought
of density estimation in grid cells within the on-line step. Within the re agglomeration step these algorithms cluster adjacent dense grid cells into clusters. However, Tu and bird genus [9] show that this results in a haul once the information points at intervals every cell don't seem to be uniformly distributed and 2 dense cells square measure separated by a tiny low space of denseness. Illustrates this downside wherever the grid cells one through half dozen square measure unified as a result of three and four square measure adjacent ignoring the realm of denseness separating them. This downside may
Available online:
https://edupediapublications.org/journals/index.php/IJR/
P a g e | 260nodes with fast connections and regular nodes with slower
connections.
Disadvantages of Existing System:
Hence numerous stream-based and interest-based super-cluster topologies have been proposed with different features, few methods are able to cluster data according to both cluster and interest.
In addition, most of these methods are on unstructured clustered systems that have no strict policy for topology construction.They cannot be directly applied to general DHTs in spite of their higher file search efficiency
PROPOSED SYSTEM
Data Stream Based On Shared Density
Re-cluster represents the algorithm’s offline part that uses the information captured by the web part. For simplicity we tend to discuss two-dimensional knowledge 1st and later discuss implications for higher-dimensional knowledge. For re cluster, we wish to hitch MCs that area unit connected by areas of high density. this can permit United States to make macro-clusters of discretional form, the same as hierarchic cluster with single-linkage or DBSCAN’s reachability, whereas avoiding change of integrity MCs that area unit near to one another however area unit separated by a locality of rarity.
Fig. 1. Problem with clustering when dense areas are separated by small areas of low density with (a) micro clusters and (b) grid cells.
EXIXTING SYSTEM
In Existing system, this allows more Clustered data to be routed than a slower backbone and, therefore, allows greater scalability. Super-node networks occupy the middle-ground between centralized and entirely symmetric stream based on shared entity, and have the potential to combine the benefits of both centralized and distributed searches.
Another class of methods to improve file location efficiency is through a clustering structure.
The third class of methods to improve file location efficiency is to cluster nodes with similar interests which reduce the file location latency. A file criterion to judge a cluster file sharing system is its file location efficiency. To improve this efficiency, numerous
methods have been proposed. One method uses a computing topology which consists of super
Cluster Based Higher-Dimensional Data
In dimensions more than 2 the intersection space becomes associate intersection volume. to get the higher limit for the intersection issue a we tend to use a simulation to estimate the supreme fraction of the shared volume of MCs(hyper spheres) that encounter in d ¼ 1; 2; ; 10; twenty and 50-dimensional house. The results area unit shown in Table one. With increasing spatial property the amount of every hyper sphere will increase rather more than the amount of the intersection. This leads at higher dimensions to a state of affairs wherever it becomes impossible that we tend to observe several knowledge points within the intersection. This is often in keeping with the matter referred to as the curse of spatial property that effects distance-based agglomeration moreover as Euclidian density estimation. This conjointly affects different density primarily based algorithms (e.g., D-Stream’s attraction in [9]) within the same approach. For high-dimensional knowledge we tend to arrange to extend a topological space agglomeration approach
like horsepower Stream [15] to take care of a shared density graph in lower dimensional subspaces.
Implementation of Data Stream Clustering
To perform our experiments and create them reproducible, we've implemented/interfaced all algorithms in an exceedingly in public offered R-extension referred to as stream [30]. Stream provides associate intuitive interface for experimenting with knowledge streams and knowledge stream algorithms. It includes generators for all the artificial knowledge utilized in this paper yet as a growing range of knowledge stream mining formulas together with agglomeration algorithms offered within the ratite bird (Massive on-line Analysis) framework [31] and therefore the algorithm mentioned during this paper. During this paper we have a tendency to use four
Available online:
https://edupediapublications.org/journals/index.php/IJR/
P a g e | 261oversized set of analysis measures (purity, precision, recall, F-measure,
total of square distances, silhouette constant, mutual info, adjusted Rand index). During this study we tend to in the main report the adjusted Rand index to judge the common agreement of the familiar cluster structure (ground truth) of the info stream with the found structure. The adjusted Rand index (adjusted for expected random agreements) is wide accepted because the acceptable live to check the standard of various partitions given the bottom truth [33]. Zero indicates that the found agreements are often entirely explained accidentally and therefore the nearer the index is to 1, the higher the agreement. For bunch with idea drift, we have a tendency to additionally report average purity and average at intervals cluster total of squares (WSS). However, like most different measures, these create comparison tough. As an instance, average purity (equivalent to exactness and a part of the Measure) depends on range | the amount |the quantity} of clusters and therefore makes comparison of clustering’s with a unique number of clusters invalid. That intervals cluster total of squares favors algorithms that turn out spherical clusters (e.g., k-means-type algorithms). A smaller WSS represent tighter clusters and therefore a
higher bunch. However, WSS forever can get smaller with Associate in nursing increasing range of clusters. We have a tendency to report these measures here for comparison since they're utilized in several information stream bunch papers.
Statistical Properties of Data-Stream Clustering Next, we tend to investigate clump performance over many information streams. For analysis, we tend to use the horizon-based prudent approach introduced within the literature [6] for clump evolving information streams. Here the present clump model is evaluated with succeeding one, 000 points within the horizon so these points area unit won’t to update the model. Recent elaborated analysis of prudent error estimation for classification is found in [34], [35]. We tend to compare DBSTREAM once more to D-Stream, Den Stream and Cluster Stream. Note that the quantity of clusters varies over time for a few of the datasets. This has to be thought-about once
comparison to Cluster-Stream that uses a set range of clusters and so
is at an obstacle during this state of affairs. Fig. a pair of shows the results over the primary ten, 000 points from a stream from the Cassini information set. DBSTREAM’s shared density approach learns the structure quickly whereas Cluster-Stream’s k-means re clump cannot cluster the indented structure of the information properly. Density Stream typically tends to position single or few MCs in its own cluster, leading to spikes of terribly quality.
D-Stream is slower in adapting to the structure and produces results inferior to DBSTREAM. Show the results on a stream created with MOA’s Random Radial Base perform (RBF) Generator with Events. The events square measure cluster splitting/merging and deletion/creation. We tend to use the default settings with ten pic noise, begin with 5 clusters and permit one event each ten, 000 information points. We tend to use for Density Stream the two parameters as recommended within the original paper. Since the amount of clusters changes over time, and Cluster Stream desires a set range, we tend to set k to five, the initial range of clusters, accepted the fact that generally this can be incorrect. Cluster Stream doesn't perform well thanks to this mounted range of macro-clusters and also the noise within the information whereas Density Stream, D-Stream and DBSTREAM perform higher. Next, we tend to use a knowledge stream consisting of two million readings from the fifty four sensors deployed within the Intel Berkeley workplace measurement humidness, temperature, lightweight and voltage over an amount of over one month. The ends up in show that everyone clumps algorithms observe daily
ISSN 2347-3983
fluctuations, and DBSTREAM produces the simplest results. Finally, we tend to use the Forest cowl sort information, which contains 581,012 instances of fashioning variables (we use the ten numeric variables). The bottom truth teams the instances into seven totally different forest cowl varieties. Though this information isn't an information stream, we tend to use it here during a streaming fashion. Fig. a pair of shows the results. The info set is difficult to cluster with several clusters within the ground truth heavily overlapping with one another. For a few a part of the info the adjusted Rand index for all algorithms even becomes negative, indication that structure found within the fashioning variables doesn't correspond with the bottom truth. DBSTREAM is once more the highest entertainer with on the average a better average adjusted Rand index than Density Stream and Cluster Stream.
The file structure of cluster is enhanced by two novel strategies, online and offline development, in the wake of directing an exhaustive examination the various leveled file procedures. To the best of our insight, this is the first work to give an exhaustive expense examination on the progressive file systems and apply stochastic procedure to streamline the record various leveled structure.
Cluster specifically gets information in remote show situations, which essentially decrease the tune-in expense.
Cluster data proficiently keeps up the record for live activity circumstances by fusing Dynamic Stream cluster [22] into various leveled list systems. What's more, a limited adaptation Micro cluster is proposed to further lessen the show overhead.
By joining the above components, Cluster diminishes the tune-in expense up to a request of size when contrasted with the cutting edge contenders; while despite everything it gives focused question reaction time, telecast size, and upkeep time. To the best of our insight, we are the first work that endeavors to minimize these entire execution elements.
CONCLUSION:
Available online:
https://edupediapublications.org/journals/index.php/IJR/
P a g e | 262rules required to take care of the graph within the on-line element of
an information stream mining algorithm. Although, we have a tendency to showed that the worst-case memory necessities of the shared density graph grow very quick with knowledge spatial property, quality analysis and experiments reveal that the procedure are often effectively applied
to knowledge sets of moderate spatial property. Experiments additionally show that shared-density re-clustering already performs very well once the web knowledge stream agglomeration element is ready to supply a tiny low range of huge MCs. Different standard re-clustering ways will solely slightly improve over the results of shared density re-clustering and wish considerably additional MCs to realize comparable results. This is often a crucial advantage since it implies that we are able to tune the web element to supply less micro-cluster for shared-density re-clustering. This improves performance and, in several cases, the saved memory quite offset the memory demand for the shared density graph.
Future Enhancement
As a future work, we can put into effect most of these algorithms and examine them primarily based on the cluster excellent on single dataset we discover 4 density-based totally clustering algorithms the usage of micro-clusters. These algorithms utilize the density-primarily based clustering due to their potential to find any form clusters and micro-clusters as a fashionable summarization of incoming data streams for solving information mining issues on streams.
REFERENCES
[1]S. Guha, N. Mishra, R. Motwani, and L. O’Callaghan, “Clustering data streams,” in Proc. ACM Symp. Found. Computer. Sci., 12–14Nov. 2000, pp. 359–366.
[2]C. Aggarwal, Data Streams: Models and Algorithms, (series Advances in Database Systems). New York, NY, USA: Springer-Verlag, 2007. [3]J. Gama, Knowledge Discovery from Data Streams, 1st ed. London, U.K.: Chapman & Hall, 2010.
[4]J. A.Silva, E.R. Faria, R.C. Barros, E.R. Hruschka, A. C. P. L. F. d.Carvalho, and J. A. Gama, “Data stream clustering: A survey,”ACM Computer. Surveys, vol. 46, no. 1, pp. 13:1–13:31, Jul. 2013.
[5]C. C. Aggarwal, J. Han, J. Wang, and P. S. Yu, “A framework for clustering evolving data streams,” in Proc. Int. Conf. Very Large Data Bases, 2003, pp. 81–92.
[6]F. Cao, M. Ester, W. Qian, and A. Zhou, “Density-based clustering over an evolving data stream with noise,” in Proc. SIAM Int. Conf. Data Mining, 2006, pp. 328–339.
[7]Y. Chen and L. Tu, “Density-based clustering for real-time stream data,” in Proc. 13th ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2007, pp. 133–142.
[8]L. Wan, W. K. Ng, X. H. Dang, P. S. Yu, and K. Zhang, “Density-based clustering of data streams at multiple resolutions,” ACM Trans. Knowl. Discovery from Data, vol. 3, no. 3, pp. 1–28, 2009.
[9]L. Tu and Y. Chen, “Stream data clustering based on grid density and attraction,” ACM Trans. Knowl. Discovery from Data, vol. 3, no. 3, pp. 1– 27, 2009.
Available online:
https://edupediapublications.org/journals/index.php/IJR/
P a g e | 263spatial databases with noise,” in Proc. ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 1996, pp. 226–231.
[11] A. Hinneburg, E. Hinneburg, and D. A. Keim, “An
efficient approach to clustering in large multimedia databases with noise,” in Proc. 4th Int. Conf. Knowl. Discovery Data Mining, 1998, pp. 58–65.
[12] L. Ertoz, M. Steinbach, and V. Kumar, “A new shared
nearest neighbor clustering algorithm and its applications,” in Proc. Workshop Clustering High Dimensional Data Appl. 2nd SIAM Int. Conf. Data Mining, 2002, pp. 105– 115.
[13] G. Karypis, E.-H. S. Han, and V. Kumar, “Chameleon:
Hierarchica clustering using dynamic modeling,” Computer, vol. 32, no. 8, pp. 68–75, Aug. 1999.
[14] S. Guha, A. Meyerson, N. Mishra, R. Motwani, and L.
O’Callaghan, “Clustering data streams: Theory and practice,”