Evaluation of text document clustering approach based on
Bees Algorithm
M. Sonia
1Assistant Professor, Department of CSE, Mahaveer Institute of Science and Technology, Dist Ranga Reddy, Telangana, India.
ABSTRACT─ Content text Clustering is one of the
quickest developing examination regions in view of convenience of huge measure of data in an electronic profile. There are a few number of systems propelled for grouping records such that archives inside a group have high intra-similitude and low between likeness to different groups. Many record grouping calculations give controlled follow in viably exploring, reducing, and sorting out data. A worldwide ideal arrangement can be acquired by applying fast and excellent streamlining calculations. The improvement procedure plays out a globalized look in the whole arrangement space. In this paper, a short study on improvement ways to deal with
content record grouping is turned out. This paper
presents the utilization of the Bees Algorithm in improving the record grouping issue. The Bees Algorithm impersonates the searching conduct of bumble bees groups in gathering nectar from bloom fixes by performing worldwide and nearby investigation all the while; this enhances evasion of nearby minima merging. Traditional Algorithm and the K-implies calculation are utilized for examinations as they are among the most generally utilized procedures to take care of the issue.
1. INTRODUCTION
Grouping is an information mining approach that looks for to find the structure of the gathered information. Since numerous Applications, for example, web crawlers, investigation of archives, monetary investigation and human face location are done based on grouping, this
A grouping calculation endeavors to discover regular gathering of a given information focuses in light of the similitude between these focuses. In addition, the grouping calculation finds the centroid of a gathering of informational indexes. To decide group participation, most calculations assess the separation between a point and the group centroids. The yield from a grouping calculation is fundamentally a measurable depiction of the group centroids with the quantity of parts in each group. Group investigation or grouping assumes a critical part in sorting out such huge measure of archives returned via seek motors into significant groups. A group is an accumulation of information protests that are like one another inside a similar group and are unlike questions in different groups. Archive grouping is firmly identified with information grouping. Information grouping is under overwhelming advancement. Group examination has its underlying foundations in numerous information mining research zones, including information mining, data recovery, design acknowledgment, web look, insights, science and machine learning.
The quantity of pertinent terms in an archive set is commonly in the request of thousands, if not many thousands. Each of these terms constitutes a measurement in an archive vector. Regular groups as a rule don't exist in the full dimensional space, however in the subspace shaped by an arrangement of corresponded measurements. Finding groups in subspaces can challenge. Certifiable informational collections may contain countless reports. Many grouping calculations work fine on little informational collections; however neglect to deal with huge informational collections effectively. A decent grouping arrangement ought to have high intra-group comparability and low Inter-cluster similarity, (i.e., reports inside a similar group ought to be
comparative yet are not at all like archives in different groups).
2. RELATED WORK
Progressive grouping the calculation makes a settled arrangement of groups that are composed as a tree. Such progressive calculations can be agglomerative or disruptive. Agglomerative calculations, likewise rang the base calculations, at first regard each protest as a different group and progressively blend the couple of groups that are near each other to make new groups until the greater part of the groups are converged into one. Troublesome calculations, additionally called the best down calculations, continue with the greater part of the articles in a similar group and in each progressive cycle a group is split up utilizing a level grouping calculation recursively until the point that each protest is in its own particular singleton group.
calculations since it is easy to execute and has an extremely helpful computational productivity – as it straightly develops with the quantity of information focuses this direct development makes K-implies extremely helpful to extensive informational indexes. The fundamental disadvantage of K-implies is that it can without much of a stretch unite to problematic nearby minima. Breadth based grouping techniques assembling the information objects with discretionary shapes. Grouping is finished as indicated by a thickness (number of items), (i.e.) thickness based availability. Network based grouping strategies utilize multiresolution framework structure to group the information objects. The advantage of this technique is its speed in handling time. A few cases incorporate WaveCluster. Display based techniques utilize a model for each group and decide the attack of the information to the given show. It is likewise used to consequently decide the quantity of groups. Expectation Maximization, Visit design based grouping utilizes designs which are extricated from subsets of measurements, to aggregate the information objects. A case of this strategy is Cluster. Limitation based grouping techniques perform grouping in view of the client indicated or application-particular limitations. It forces client's limitations on grouping, for example, client's necessity or clarifies properties of the required grouping comes about.K-implies calculation, a group is spoken to by the mean estimation of information focuses inside a group (i.e. Centroid) furthermore, the grouping is finished by limiting the whole of Euclidean separations between information focuses and the comparing group centroid.
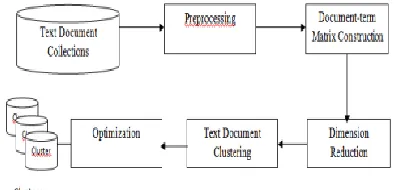
3. FRAME WORK
Another population based track computation is the bees calculation the bees calculation is a streamlining calculation initially created and it depends on the characteristic sustenance rummaging exercises of bumble bees. As an initial step, an underlying populace of arrangements are made and after that assessed in view of a wellness work. At that point in view of this assessment, the most elevated finesses esteems are chosen for neighborhoods seek, doling out more bees to look hold up under to the best arrangements of the most elevated fitness's. At that point for each fix select the fittest answer for construct the following new populace. The rest of the honey bees in the populace are designated haphazardly around the inquiry space exploring for new conceivable arrangements. These means are rehashed until the point that a halting paradigm is met.The bumble bees mean to discover the blooms in a fix with more amounts of nectar keeping in mind the end goal to deliver more nectar with less exertion of hunt. Along these lines the blooms with more nectar should be gone by more honey bees. The honey bees begin hunting by sending scout honey bees down irregular pursuit in the fix; when these honey bees are back to the hive they assess the went by blooms in light of a particular foundation. To speak with each other and trade data.
The content archive preprocessing essentially comprises of a procedure to strip all designing from the article, including capitalization, accentuation, and superfluous markup (like the dateline, tags). At that point the stop words are evacuated. Stop words term (i.e., pronouns, relational words, conjunctions and so on) are the words that don't convey semantic importance. Stop words can be killed utilizing a rundown of stop words. Stop words end utilizing a rundown of stop word rundown will significantly lessen the measure of clamor in content gathering, and additionally make the calculation less demanding. The advantage of expelling stop words abandons us with consolidated form of the records containing content words as it were. Measurement decrease can be partitioned into include determination and highlight extraction. Highlight choice is the way toward choosing littler subsets (highlights) from bigger arrangement of data sources and Highlight extraction changes the high dimensional information space to a space of low measurement. The objectives of measurement decrease techniques are to permit less measurement for more extensive correlations of the ideas contained in a content gathering.
The Genetic Algorithm (GA) is an extremely well known developmental calculation. The essential thought of GAs is intended to make manufactured frameworks programming that holds the heartiness of regular natural advancement framework. Hereditary calculations have a place with seek procedures that copy the guideline of characteristic choice. The choice administrator depends on a wellness work; guardians are chosen for mating (i.e. recombination or hybrid) as per their wellness. In view of the determination administrator, the better the chromosomes would be incorporated into the following populaces and the others would be dispensed with. The
prominently utilized techniques that can be utilized to choose the best chromosomes are roulette wheel determination, competition choice, Boltzmann choice, Steady state choice and rank choice. The hybrid is connected and it chooses qualities from parent chromosomes with a specific end goal to make the new populace. The hybrid point is chosen with likelihood Pc. After a hybrid is performed, transformation happens. A change can be connected by arbitrarily altering bits.
4. EXPERIMENTAL RESULTS
The proposed Bees calculation utilizing the records accumulations and the underlying estimations of parameters of the three calculations.
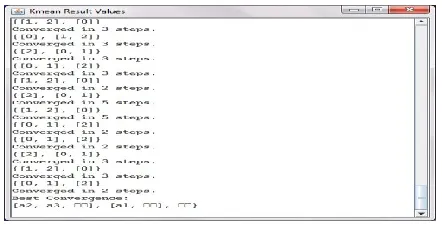
Fig 2: Output of the k-means algorithm
Fig 3: Bees Result Values
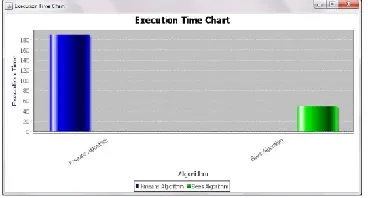
The trial was connected on the m parameter where a few esteems were tried while keeping the qualities of whatever is left of the parameters the same. The created comes about demonstrates that the subsequent wellness has expanded while expanding the estimation of the m until soaked when m is equivalent to 8 and no adjustment in the arrangement wellness was come to. Final execution time taken by the k-means algorithm and bees algorithm
Fig 4: Final execution time taken by the k-means
algorithm and bees algorithm
5. CONCLUSION
This paper has displayed a review on the examination work done on content report grouping based on streamlining strategies. This study begins with a concise presentation about grouping in information mining, delicate registering and investigated different research papers identified with content record grouping. More
research works must be completed in view of semantic to make the nature of content record grouping. The Bees calculation Cosine separate was utilized as a wellness work; The calculation has demonstrated its vigor through trials on an informational index of 818 records against the Genetic Algorithm and K-implies calculation and demonstrated its capacity of getting arrangements that best fulfill the wellness metric with a satisfactory increment in the calculation time over Genetic Algorithm what's more, the K-implies calculation times. As a result of the calculation capacity to perform worldwide and neighborhood look all the while, the calculation abstains from getting caught into a nearby minimum.
6. REFERENCES
[1] Pham, D.T. and Afify, A.A.: Clustering techniques and their applications in engineering. The Institution of Mechanical Engineers, Part C: Journal of Mechanical Engineering Science (2006)
[2] Nihal M. AbdelHamid, M.B. AbdelHalim, M.W. Fakhr: Document clustering using Bees Algorithm. International Conference of Information Technology, IEEE, Indonesia (March 2013)
[3] Goldberg D.E.: Genetic Algorithms-in Search, Optimization and Machine Learning. Addison- Wesley Publishing Company Inc., London (1989)
[4] K. Premalatha, A.M. Natarajan: Hybrid PSO and GA Models for Document Clustering. Int. J. Advance. Soft Comput. Appl. 2, 2074-8523 (2010)
[6] Kennedy, J.; Eberhart, R.C. Swarm Intelligence. Morgan Kaufmann 1-55860-595-9 (2001)
[7] Mathur M, Karale SB, Priye S, Jayaraman VK and Kulkarni BD.: Ant Colony Approach to Continuous Function Optimization. Ind. Eng. Chem. Res. 3814-3822 (2000)
[8] Pham D.T., Ghanbarzadeh A, Koc E, Otri S, Rahim S and Zaidi M.: The Bees Algorithm. Technical Note, Manufacturing Engineering Centre, Cardiff University, UK (2005)
[9] Lukasz Machnik: Documents clustering method based on Ants Algorithms. 123 – 130 (2006)
[10] Bilchev G and Parmee IC. The Ant Colony Metaphor for Searching Continuous Design Spaces, Selected Papers from AISB Workshop on Evolutionary Computing. 25-39 (1995)
[11] Priya Vaijayanthi, Natarajan A M and Raja Murugados: Ants for Document Clustering, 1694-0814 (March 2012)
[12] Salton G.: Automatic Text Processing. Addison-Wesley (1989)
[13] Salton G., Wong A. and Yang C.,A.: Vector Space Model for Automatic Indexing. J. of Communications of the ACM, 18, 613–620 (1975)
[14] D.T. Pham, S. Otri, A. Afify, M. Mahmuddin and H. Al-Jabbouli:Data Clustering Using the Bees Algorithm, CIRP International Manufacturing Systems Seminar (2007).