Web-based Video Database Management: Issues, Mechanisms, and Experimental
Development
£ Z(invited paper)
Qing Li Shermann S.M. Chan
Department of Computer Science
City University of Hong Kong, China
Yi Wu Yueting Zhuang
Department of Computer Science
Zhejiang University, Hangzhou, China
£ Z
This research has been supported, in part, by a Strategic Research Grant from CityU (Project no. 7001073).
Abstract
A comprehensive video retrieval system over the web should be able to accommodate and utilize various (complementary) description data in facilitating effective retrieval. In this paper, we advocate a hybrid retrieval approach by integrating a query-based (database) mechanism with content-based retrieval (CBR) functions. We describe the VideoMAP*
architecture, discuss issues related to developing such a web-based video database management system, and its specific language mechanism (CAROL/ST with CBR) which provides an improved expressive power than what pure query-based or CBR methods currently offer. An experimental prototype is being developed using a commercial object-oriented toolkit based on VC++ and Java.
1.Introduction
A current important trend in multimedia information management is towards web-based/enabled multimedia search and management systems. Video is a rich and colorful media widely used in many our daily life applications like education, entertainment, news spreading, etc. Digital videos have diverse sources of origin such as cassette recorder, tape recorder, home video camera, VCD and Internet. Expressiveness of video documents decides their dominative position in the next-generation multimedia information systems. Unlike traditional / static types of data, digital video can provide more effective dissemination of information for its rich content. Collectively, a (digital) video can have several information descriptors: (1) meta data - the actual video frame stream, including its encoding scheme and frame rate; (2) media data - the information about the characteristic of video content, such as visual feature, scene structure and spatio-temporal feature; (3) semantic data - the text annotation relevant to the content of video, obtained by manual or automatic understanding.
Video meta data is created independently from how its contents are described and how its database structure is organized later. It is thus natural to define “video” and other meaningful constructs such as “scene”, “frame” as objects corresponding to their respective inherent semantic and visual contents. Meaningful video scenes are identified and associated with their description data incrementally. But the gap between the user realization and video content remains a big problem. Depending on the user’s viewpoint, the same video/scene may be given different descriptions. It is extremely difficult (if not impossible) to describe the whole contents of a video, especially due to the visual content.
In order to develop an effective (web-based) video retrieval system, one should go beyond the traditional query-based or purely content-based retrieval (CBR) paradigm. Our standpoint is that videos are multi-faceted data objects, and an effective retrieval system should be able to accommodate all of the above complementary information descriptions for retrieving video. As such, in this paper we advocate a web-based hybrid approach to video retrieval by integrating the query-based (database) approach with the CBR paradigm.
1.1 Related Work
Text-based information retrieval and content-based image retrieval have been two separate topics historically. The former one uses annotation/specification of high-level semantics of images manually. The latter one needs accurate recognition of low-level image features. Seldom research focuses on these two information integration,
however actual application demonstrates its importance. At the moment, this aspect of work still remains an unexplored but challenging problem. Recently, Simone and Ramesh [SJ00] have attempted to integrate both for image retrieval. They used labels attached in the HTML files as the textual information, and developed several search engines which analyze low-level image features individually. As the labels extracted from the HTML files may not be relevant to the images, the two kinds of information used in their system may not actually represent each other.
In the context of videos, the original research work was on video structuring, such as shot detection and key frame extraction based on visual features in the video. Its application areas have been extended from commercial video databases to home videos (e.g., [MZ00]). But most of the practical systems annotate videos by textual information manually. For example, in OVID[OT93], each video object has a set of manually annotated attributes and attribute values describing its content. In [CJ91], both the video objects and their spatial relationships are manually annotated in order to support complex spatial queries. In order to index video automatically, not only the visual contents but also the audio content should be used (see [NK98, NC97,WZ01]). Recent work also proposed the use of closed caption. An obvious trend in video indexing and retrieval is to use all the different features like audio, closed captions and so on instead of simply visual features. Another trend is towards web-enabled/based video management system.
Over the last couple of years we have been working on developing a generic video management and application processing (VideoMAP) framework [CL99a,CL99b,LLS00]. A central component of VideoMAP is a query-based video retrieval mechanism called CAROL/ST which supports spatio-temporal queries [CL99a,CL99b]. While the original CAROL/ST has contributed on working with video semantic data based on an extended object oriented approach, little support has been provided to support video retrieval using visual features. To support a more effective video retrieval system through a hybrid approach, we have been making extensions to the VideoMAP framework, and particularly the CAROL/ST mechanism [CWLZ01a]. In this paper, we further put forward our web-based version of VideoMAP (termed as VideoMAP*), and discuss the main issues involved in developing such a web-based video database management system supporting hybrid retrieval.
1.2 Paper Organization
The rest of our paper is organized as follows. In next section we review the main extensions we have made to VideoMAP, the result of which is a comprehensive video database management system (called VideoMAP+ ) which supports CBR and query-based retrieval methods. In section 3 we detail the VideoMAP* framework and its web-based hybrid approach to video retrieval. The specific user interface facilities are described in section 4; example queries are also given to illustrate the expressive power of this mechanism. Finally, we conclude the paper and offer further research directions in section 5.
2. Research Background
As mentioned earlier, we have been developing an extended version of VideoMAP, which we termed it VideoMAP+ [CWLZ01a], for
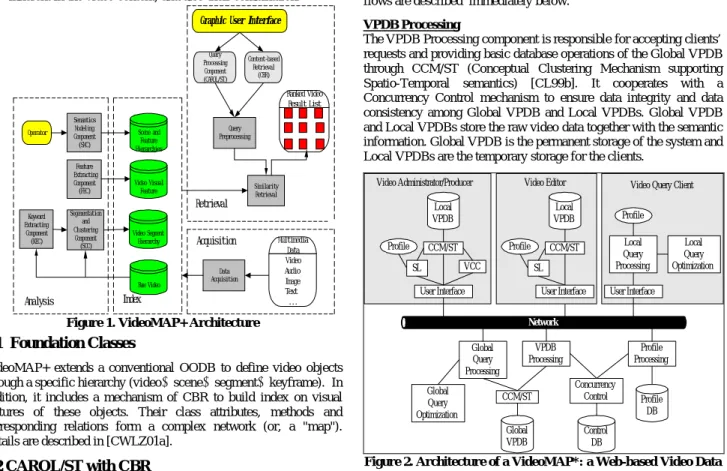
supporting hybrid retrieval of videos through query-based and content-based accesses. The architecture of VideoMAP+ is depicted in Fig.1. It is divided into several components: Video acquisition, video analysis, video index and video retrieval. The main processing flows are embodied by the following:
(1) Video acquisition: Multimedia data has extensive distribution in the world. And video, as an important member of multimedia, also possesses of plenty sources to obtain.
(2) Video analysis: The obtained video meta data is only a sequence of frames, without structure and annotation initially, so the in-depth work of video indexing and retrieval must be formed based on analysis. There are three modules:
§ Segmentation and Clustering Component(SCC): Detect the camera movements in video, and cluster the semantically relevant segments into scene, which module is necessary for structuring video objects.
§ Feature Extracting Component(FEC): Extract the visual feature vector from the video and other object defined in, such as the color, texture ,shape and so on.
§ Semantic Modeling Component(SMC): Organize video segments into semantically meaningful hierarchies with annotated feature indices.
(3) Video index: After the processing of video analysis, video has a hierarchical structure. We make index on scene and feature hierarchy, video visual feature and video segment hierarchy. These indexes are not absolutely self-existent. For example, in the “Segment” and “Keyframe” level of video hierarchy, there all exist the index of visual and semantic feature.
(4) Video retrieval: Video retrieval contains three kinds of retrieval format: CAROL/ST Retrieval - the original retrieval format which mainly uses the semantic annotation and spatio-temporal relationships of video; Content-based Retrieval - the new added retrieval format which mainly uses the visual information inherent in the video content; and also their combination.
Semantics Modeling Component (SMC) Operator Feature Extracting Component (FEC) Segementation and Clustering Component (SCC) Keyword Extracting Component (KEC) Scene and Feature Hierarchies Video Visual Feature Video Segment Hierarchy Raw Video Data Acquisition Video Audio Image Text ... Multimedia Data Analysis Index Content-based Retrieval (CBR) Query Processing Component (CAROL/ST)
Graphic User Interface
Similarity Retrieval Query Preprocessing Ranked Video Result List Retrieval Acquisition
Figure 1. VideoMAP+ Architecture
2.1 Foundation Classes
VideoMAP+ extends a conventional OODB to define video objects through a specific hierarchy (videoàsceneàsegmentàkeyframe). In addition, it includes a mechanism of CBR to build index on visual features of these objects. Their class attributes, methods and corresponding relations form a complex network (or, a "map"). Details are described in [CWLZ01a].
2.2 CAROL/ST with CBR
In the hybrid approach, there are three kinds of queries possible for the query-processing component: Text-based Search, Content-based Search, and the Hybrid Search. Search paths of the three kinds of queries are described in [CWLZ01a]. According to the class diagram
[CWLZ01a], objects, attributes, and methods are stored in separated classes. Therefore, the query processor can search the object database with different entry points. The Content-based Search is based on the low-level image features such as color, shape, and texture. After integrating it with CBR, the search paths applicable to our hybrid approach. Here, we show some query examples (cf. fig. 5 and fig. 6). Detailed query syntax and additional features for query processing are described in [CWLZ01b].
3. VideoMAP*: Towards a Web-based VDBMS
As mentioned earlier, we are building a web-based version of VideoMAP+, which we term as VideoMAP*. The architecture of VideoMAP* is shown in Figure 2. It is being built on top of a network and the components can be classified into two parts: server-components, and client-components. For the client-server-components, they are grouped inside the gray boxes; for the server-components, they are shown below the network backbone. The main server-components providing services to the clients include Video Production Database (VPDB) Processing, Profile Processing, and Global Query Processing. Theoretically, there is no limit on the number of users working at the same time. There are four kinds of users who can utilize and work with the system: Video Administrator, Video Producer, Video Editor, and Video Query Client. Each type of users is assigned with a priority level for the VPDB Processing component to handle the processing requests from the queue. A request from a user who has the highest priority level is processed first, with the requests from the users of the same priority level being processed in FIFO. The user priority levels of our system, in descending order, are from Video Administrator, Video Producer, Video Editor, and to Video Query Client.
3.1 Main Process Flows
For the four main components of VideoMAP*, their main process flows are described immediately below.
VPDB Processing
The VPDB Processing component is responsible for accepting clients’ requests and providing basic database operations of the Global VPDB through CCM/ST (Conceptual Clustering Mechanism supporting Spatio-Temporal semantics) [CL99b]. It cooperates with a Concurrency Control mechanism to ensure data integrity and data consistency among Global VPDB and Local VPDBs. Global VPDB and Local VPDBs store the raw video data together with the semantic information. Global VPDB is the permanent storage of the system and Local VPDBs are the temporary storage for the clients.
Concurrency Control Profile DB Global Query Processing Global Query Optimization Profile Processing Profile Local Query Optimization Local Query Processing Global VPDB CCM/ST Local VPDB Profile SL CCM/ST Video Administrator/Producer Network User Interface VCC Local VPDB Profile SL CCM/ST
Video Editor Video Query Client
User Interface User Interface
VPDB Processing
Control DB
Figure 2. Architecture of a VideoMAP*: a Web-based Video Data Management System
Concurrency Control
The Concurrency Control mechanism is used to handle multiple-user processing of the system. As a small change to the ToC (Table of Content) of the video program may affect the final display order of
the video program [CL99a], data locks cannot be used in the virtual editing of video program; otherwise, the whole sequence of the video program should be locked entirely. In order to ensure data integrity and data consistency, a complemented mechanism is introduced here. When a user wants to do virtual editing of a video program, he retrieves the video data from the Global VPDB to his Local VPDB. Then the modified video data is saved as a new view of the video program. A collection of views is stored with the original video program. Therefore, Video Query Clients can choose to display the video program from different perspectives. In order to reduce the size of the database, it is necessary to limit the number of versions of views of each user stored in the database. The Video Administrator can also remove some obsolete videos.
Profile Processing
Profile Processing is used to provide basic database operations of the ProfileDB. It ensures that all the clients can retrieve and update their corresponding user profiles (which are stored in the ProfileDB). There are three types of profiles: common profile, personal profile, and the specific video profile. Each profile stores the common knowledge and the Activity Model [CL99b] of which the semantic meanings can be different to different users. Common profile is the standard profile provided to every user, thereby supporting the desired “subjectivity” for virtual editing and access activities. Personal profile is the customized common profile according to the need of the individual user. The Video Producers create the specific video profiles based on the video programs. The personal profile can only be modified by its owner; and the specific video profile can only be modified by the Video Administrator. The profiles are represented in the form of rules for effective reasoning and can be converted into a universal format (e.g. XML) before transmitting to the clients. Therefore, the information can be easily interpreted by the web browsers.
Semantic Query Processing (CAROL/ST) with CBR
The query processing mechanism of VideoMAP* is inherited from, and thus exactly the same as that of VideoMAP+ [CWLZ01a]. We therefore omit its descriptions here for the sake of conciseness.
3.2 Distribution Design
In a web-based environment, the cost of data transfer and communication is an important issue worth great attention. In order to reduce this overhead, databases can be fragmented and distributed into different sites. There are many research efforts on data fragmentation of relational databases. On the contrary, there is only limited recent work on data (object) fragmentation in object databases [ODV94,OV99,KL00]. As it is time-consuming (and quite often unnecessary) to transmit an entire object database to the client side, especially for a large video object database, it is advantageous to fragment and cluster objects in order to minimizing the overhead of locking and transferring objects. After objects are fragmented, the next step is to allocate the fragments to various sites, which is another open research issue for object databases, hence is beyond the scope of this paper (see, e.g., [SAK99]).
3.2.1 Global VPDB
In VideoMAP*, different types of users such as Video Producers (VPs), Video Editors (VEs), and the Video Administration (VA) can retrieve the Global VPDB into their Local VPDBs for processing, and their work may affect and be propagated to the Global VPDB. In particular, each type of users may work on a set of video segments and create dynamic objects out of the video segments. It therefore makes sense to cluster the video objects in the same manner as shown in Figure 3(a). Specifically, each raw video is assumed to have a specific domain and relevant domains are grouped together first. Since multiple video segments (may belong to different domains) may be included by one application, raw videos linked by the same application are therefore grouped together. The other objects which have links with these video segments are then grouped into clusters. Further fragmentation based on by user views [CL00] can be processed if necessary. The clusters can be stored in more than one database, therefore the size of object locking can be minimized.
In order to maintain the fragmentation transparency, a processing component is needed to locate objects. A Global Schema is also needed to contain the meta-data of objects in several levels (by domain, application, link, etc). VP, VE, and VA users can easily retrieve the objects, and also easily insert/update the databases through the global schema. Consequently, the global schema also needs to be carefully shared and maintained.
3.2.2 Global Video Query DataBase (Global VQDB)
In VideoMPA*, the Global VPDB is replicated into a mirror database (i.e. Global VQDB) for Video Query Client processing. As the Global VQDB is a read-only database and is independent of other processes, it can be fragmented according to the interests of the query clients thoroughly. Since an Activity Model is composed of user-interested activities, and a User Profile is constructed by the user’s activity model and query histories, the Global VQDB can be fragmented based on the semantics in multiple levels.
a b c d a b c d a b c d f g h i f g v1.avi, (comic) v2.avi, (comic) v3.avi, (action) domain1: {v1, v2} domain2: {v3} domain3: {v4} Raw video files and segments
By Domain a b c d v4.avi, (horrible) freq1: {v1, v2} freq2: {v3, v4} By Frequency Applications
app1: {v1.a, v1.b, v1.c, v2.a} app2: {v1.d, v2.d, v2.e} app3: {v3.a, v3.b, v3.c, v4.c} By Link frag1: {freq1, s1, s3, s5, f1, f2,...} frag2: {freq2, s2, s6, f3,...} Other objects scene: {s1, s2, s3,...} sfeature: {f1, f2, f3,...} : : N.B. sfeature is the semantic feature
Figure 3(a). Data Distribution of Global VPDB
obj-level1(football): {sf1,...} obj-level2(leg): {...} motion-level1(kicking): {obj-level1, obj-level2,...}
event-level1(football): {motion-level1,...} activity-level1(sports): {event-level1,...}
: :
Objects with Semantics
By Activity Model
By Link
frag1: {activity-level1, s1, f2, f3, seg2,...} frag2: {activity-level2, s2, f2, f3,...}
:
Other objects scene: {s1, s2, s3,...} vfeature: {f1, f2, f3,...} segment: {seg1, seg2,...}
: sfeature: {sf1(football), sf2(basketball), sf3(volleyball), sf4(peter), sf5(mary), sf6(clock), sf7(watch),...} vobject: {vo1(hand), vo2(face) , vo3(human), vo4(ball),...} sem1(hand): {vo1,...} sem2(face): {vo2,...} sem3(human): {vo3, sf4, sf5,...} sem4(ball): {vo4, sf1, sf2, sf3,...} sem5(timer): {sf6, sf7,...} : By Semantics (Thesaurus) Activity Model
sports (Activity) --> football, basketball, volleyball (Event) football (Event) --> kicking (Motion) kicking (Motion) --> leg, football (Object) basketball (Event) --> slam-dunk (Motion) slam-dunk (Motion) --> hand, basket,
basketball (Object) :
N.B. sfeature - semantic feature vobject - visual object vfeature - visual feature
Figure 3(b). Data Distribution of Global VQDB
As shown in Figure 3(b), semantic objects (i.e. SemanticFeature, and VisualObject) can be grouped by two ways: by Semantics, and by Activity Model. In the former case, the objects are grouped together by a thesaurus and then they are linked with other associated objects (such as scene, visual feature, etc). In the latter case, semantic objects are first clustered from the object level to the activity level, and then linked with other associated objects (e.g. scene, visual feature, etc).
In order to maintain the fragmentation transparency, a processing component is needed to serve as a directory for locating the objects. As in the case of the Global VPDB, it works with the Global Schema in which multiple levels of meta data information are stored.
3.3 Distributed Query Processing and Optimization
When the query client submits a query, the Local Query Processing component may rewrite and transform it into a number of logical query plans. Since the Global VQDB is fragmented according to the semantics and the Activity Model, the logical query plans can be generated based on User Profiles which contain relevant semantic information. For example, if a user requests for a “ball”, the query plans can include “ball”, “football” etc. based on his/her profile. Each query plan is then decomposed into sub-queries. After the decomposition of all plans, the sub-queries are sent to the Local Query Optimization component to determine the order of importance. Next, the query plans are sent to the Global Query Processing component and the Global Query Optimization component to search the results by using the information from the Global Schema. As the original query is rewritten into a number of similar queries with different priority levels, the probability of obtaining the right results can be greatly increased.4. Experimental Prototyping Work
As part of our research, we have been building an experimental prototype system on the PC platform. In this section, we briefly describe our prototype work in terms of the implementation environment, the actual user interface and language facilities, and sample results.
4.1 Prototype Implementation Environment
Starting from the first prototype of VideoMAP, our experimental prototyping has been conducted based on Microsoft Visual C++ (as the host programming language), and NeoAccess OODB toolkit (as the underlying database engine). Here we illustrate the main user facilities supported by VideoMAP+ which is also the kernel for our web-based prototype, i.e., VideoMAP* (the latter is being developed with necessary extensions based on CORBA standard and COM technology as the middleware). VideoMAP+ currently runs on Windows and it offers a user-friendly graphical user interface supporting two main kinds of activities: Video editing, and Video retrieval.
4.1.1 Video editing
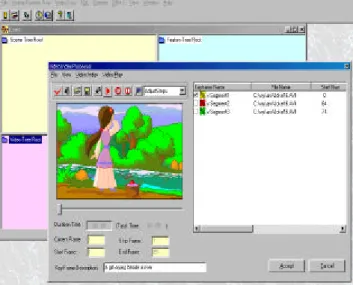
Figure 4. Annotating the segments after video segmentation When a user invokes the function of video editing, a screen comes up for uploading a new video into the system and annotating its semantics (cf. Figure 4). For example, s/he can name the video object and assign some basic descriptions to get started.
A sub-module of Video segmentation is devised to help decompose the whole video stream into segments and to identify the keyframes. Further, the Feature Extraction module is to calculate the visual features of the media object. By reviewing the video abstraction structure composed by the segments and keyframes, the user can annotate the semantics according to his/her understanding and preference (cf. Figure 4).
4.1.2 Video retrieval
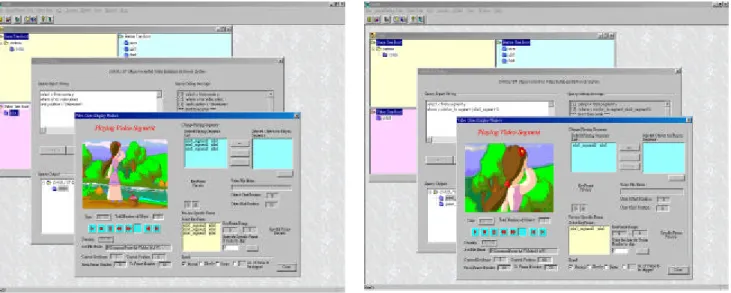
Our prototype also provides an interface for the user to issue queries using its query language (i.e. CAROL/ST with CBR). All kinds of video objects such as “Scene”, “Segment”, “Keyframe”, can be retrieved by specifying their semantics or visual information. Figure 5 shows a sample query issued by the user, which is validated by a compiler sub-module before execution. The retrieved video objects are then returned to the user in the form of a tree (cf. figure 5), whose node not only can be played out, but also can be used subsequently for formulating new queries in an iterative manner.
Figure 5. Query facilities
4.2 Sample Results
As described earlier, our system supports three primary types of queries, namely: (1) query by semantic information, (2) query by visual information, and (3) query by both semantic and visual information (the "hybrid" type). For type (1), VideoMAP+ supports retrieving all kinds of video objects (Video, Scene, Segment, Keyframe, Feature) based on the semantic annotations input by the editor/operator earlier (cf. section 4.1.1). Figure 6(a) shows the interface for users to specify semantic query, and for displaying the query result video.
For type (2), users can specify queries which involve visual features and their similarity measurement. Visual similarity considers the feature of color, texture and so on. Users can specify the query by using either individual feature or its combination [CWLZ01a]. Figure 6(b) illustrates the interaction sessions for the user to specify a visual feature based query (using "similar-to" operator), and the resulting video being displayed to the user. Finally, for type (3), users can issue queries which involve both semantic and visual features of the targeted video objects. These "heterogeneous" features call for different similarity measurement functions, and their integration is currently being devised in the context of VideoMAP* prototype system.
5. Conclusion
We have been developing a comprehensive web-based video data management system, viz., VideoMAP*, and presented in this paper its central mechanisms which offer a number of unique features. In particular, VideoMAP* provides a hybrid approach to video retrieval over the web, by combining query-based method with content-based retrieval (CBR) functions. In addition, it supports concurrency control
for the virtual editing of video data among different users who are assigned with priority levels, and also accommodates various kinds of profiles containing knowledge information and activity models. These profiles are useful for annotating abstracted information into the video data and for processing queries of the video data. We have also described the user interface facilities of our system from the perspective of sample user interactions.
There are a number of issues for us to further work on. Among others, we are extending our prototype system to make it as MPEG standard compatible, by allowing input videos to be in either AVI or MPEG format. We also start to examine the possible performance issues, such as replication technique for the Global VPDB to be distributed into mirror databases, so as to accommodate larger number of Video Query Clients. Finally, the issues of optimizing CAROL/ST with CBR queries, and the possibility of combining local query processing with global query processing in light of overall query optimization are interesting for investigation in the context of VideoMAP*.
References
[CJ91] S. Chang and E. Jungert, “Pictorial data management based upon the theory of symbolic projections”, Journal of Visual Languages and Computations, no.2, pp.195-215, 1991.
[CL99a] S.S.M. Chan and Q. Li. Facilitating Spatio-Temporal Operations in a Versatile Video Database System, Proc. of 5th Int’l Workshop on
Multimedia Information Systems (MIS’99), pp. 56-63, 1999.
[CL99b] S.S.M. Chan and Q. Li. Developing an Object-Oriented Video Database System with Spatio-Temporal Reasoning Capabilities, Proc. of
18th Int’l Conf. on Conceptual Modeling (ER’99), pp. 47-61, 1999.
[CL00] S.S.M. Chan and Q. Li, "Architecture and Mechanisms of a Web-based Video Data Management System", Proc. 1st IEEE International
Conference on Multimedia and Expo (ICME'00), New York City, NY,
USA, Jul 30-Aug 2 (CD-ROM), 2000.
[CWLZ01a] S.S.M. Chan, Y. Wu, Q. Li, Y. Zhuang, "A Hybrid Approach to Video Retrieval in a Generic Video Management and Application Processing Framework", IEEE Int’l Conf. on Multimedia and Expo
(ICME'01), Tokyo, Japan, August 22-25, 2001.
[CWLZ01b] S.S.M. Chan, Y. Wu, Q. Li, Y. Zhuang, "Development of a Web-based Video Management and Application Processing System“, SPIE Int’l Symposium on Convergence of IT and Communications (ITCom2001), Denver, CO USA, August 20-24, 2001.
[KL00]K. Karlapalem and Q. Li. A Framework for Class Partitioning in Object Oriented Databases, Distributed and Parallel Databases,8(3):317-350, Kluwer Academic Pub., 2000.
[LLS00] R.W.H. Lau, Q. Li, and A. Si. VideoMAP: a Generic Framework for Video Management and Application Processing, Proc. 33rd Int'l Conf. on System Sciences (HICSS-33): Minitrack on New Trends in Multimedia Systems, IEEE Computer Society Press (CD-ROM), 10 pages, 2000.
[MZ00] Wei-Ying Ma and HongJiang Zhang, “AN INDEXING AND BROWSING SYSTEM FOR HOME VIDEO”, Invited paper, EUSIPCO'2000, 10th European Signal Processing Conference, 5-8 [NC97] J. Nam, A.E. Cetin, A.H. Tewfik, “Speaker Identification and
Video Analysis for Hierarchical Video Shot Classification” ICIP97, vol.2, pp.550-555.
[NK98] M.R. Naphade, T. Kristjansson, B.J. Frey, and T.S. Huang, “Probabilistic Multimedia Objects Multijects: A novel Approach to Indexing and Retrieval in Multimedia Systems”, Proc. IEEE Int’l Conference on Image Processing, Vol.3, pages 536-540, Oct 1998, Chicago, IL.
[ODV94] M. Tamer Ozsu, Umeshwar Dayal, Patrick Valduriez, “Distributed Object Management”, Morgan Kaufmann Publishers, San Mateo, California, 1994.
[OT93] E. Oomoto and K. Tanaka. OVID: Design and Implementation of a Video-Object Database System, IEEE Trans. Knowledge and Data
Engineering, 5(4):629-634, 1993.
[OV99] M. Tamer Ozsu, Patrick Valduriez, “Principles of Distributed Database System”, Prentice Hall, Upper Saddle River, New Jersey, 1999. [SJ00] S. Santini and R. Jain. “Integrated Browsing and Querying for
Image Databases”, IEEE Multimedia, Vol.7, No.3, pp.26-39, 2000. [SAK99] S-K So, I. Ahamad and K. Karlapalem. “Response Time Driven
Multimedia Data Objects Allocation for Browsing Documents in Distributed Environments”, IEEE TKDE, Vol.11, No.3, pp.386-405, 1999. [WZ01] Fei Wu, Yueting Zhuang,Yin Zhang, Yunhe Pan, “Hidden Markovia-based Audio Semantic Retrieval” , Pattern Recognition and Artificial Intelligence [in Chinese], vol.14, no.1, 2001.
(a) (b)