Distributed Java Virtual Machine
Ken H. Lee
Mathias Payer
Responsible assistant
Prof. Thomas R. Gross Laboratory for Software Technology
ETH Zurich
Because Java has a built-in support for multi-threading and thread-synchronisation, parallel Java applications that are traditionally executed on a single Java Virtual Machine (JVM) can be con-structed easily. Because of the emergence of cluster computing that are a cost-effective substitute for multi-core computers, there have been different approaches for developing a distributed runtime environment to run Java application in parallel.
In this thesis we added a distributed runtime system to an open-source JVM called Jikes Re-search Virtual Machine to provide a true parallel execution environment for multi-threaded Java applications within a cluster of workstations. To achieve transparency, we implemented a virtual global object space to hide the underlying distribution from the programmer and the application. Supplementarily, we added mechanisms for accessing objects in this global memory space, thread synchronization, distributed classloading, distributed scheduling and finally for I/O redirection and evaluated the overhead of these mechanisms with several microbenchmarks.
The result is a prototype of a distributed Java Virtual Machine running as part of the JikesRVM which offers a wide scope for extensions. By embedding the virtual object heap into the JVM and making the JVM aware of the cluster, the distributed runtime system benefits from the abundant runtime information of the JVM which gives the opportunity for further optimizations.
Dank der eingebauten Unterst¨utzung f¨ur Multithreading und Thread-Synchronisation k¨onnen Java Applikationen ohne grossen Aufwand parallelisiert werden, welche jedoch gew¨ohnlicherweise nur auf einer Java Virtual Machine (JVM) laufen. Mit dem Aufkommen des Cluster Computings, welches eine kosteng¨unstige Alternative zu Multiprozessor-Rechnern darstellt, gab es verschiedene Ans¨atze, eine verteilte Laufzeitumgebung zu entwickeln, um Java Applikationen echt parallel laufen zu lassen.
In dieser Arbeit haben wir die open-source JVM namens Jikes Research Virtual Machine um ein verteiltes Laufzeitsystem erweitert, welches parallele Java Applikationen erm¨oglicht, in einem Cluster echt parallel laufen zu lassen. Wir haben einen virtuellen globalen Speicher implementiert, um die darunterliegende Verteilung vor dem Programmierer und der Applikation zu verbergen. Zus¨atzlich haben wir Mechanismen f¨ur den Zugriff auf Objekten in diesem globalen Adressraum, f¨ur die Synchronisation von Threads, f¨ur das verteilte Klassenladen und verteilte Scheduling und f¨ur die I/O Weiterleitung implementiert und haben fr diese Mechanismen die Zusatzkosten evaluiert. Mit unserer Implementation haben wir einen Prototypen einer verteilten JVM geschaffen, welcher innerhalb einer stabilen JVM l¨auft und viel Spielraum f¨ur Erweiterungen zul¨asst. Dadurch, dass der virtuelle globale Speicher in die JVM eingebettet wurde und die JVM sich der Existenz des Clusters bewusst ist, profitiert das verteilte Laufzeitsystem von den vielen Laufzeitinformationen der JVM. Dies erm¨oglicht zus¨atzliche Optimierungen, um die Leistung zu steigern.
I would like to take this opportunity to express my gratitude towards the following people: First of all, I want to thank Professor Thomas Gross for being my mentor and giving me the chance to explore an interesting research topic. I would also like to thank my supervisor Mathias Payer for his guidelines and advices during our weekly meetings. He has provided me with many inspiring ideas for this work. My vote of thanks also goes to the Jikes Research Virtual Machine community, especially Ian Rogers, for their prompt help and support. Last but not least, I would like to thank my friends Michael Gubser and Yves Alter for revising the linguistic aspects of this documentation.
List of Tables xii
List of Figures xiii
1 Introduction 1
2 Background and Preliminary Work 3
2.1 Jikes Research Virtual Machine . . . 3
2.1.1 Baseline and Optimizing Compilers . . . 3
2.1.2 Threading Model . . . 4
2.1.3 Object Model . . . 5
2.2 Distributed Shared Memory . . . 6
2.2.1 Page-Based Distributed Shared Memory . . . 7
2.2.2 Object-Based Distributed Shared Memory . . . 7
2.3 Memory Consistency Model . . . 7
2.3.1 Lazy Release Consistency Model . . . 8
2.3.2 Java Memory Model . . . 9
3 Related Work 11 3.1 Compiler-Based Distributed Runtime Systems . . . 12
3.1.1 Hyperion . . . 12
3.2 Systems Using Standard JVMs . . . 12
3.2.1 JavaSplit . . . 13
3.3 Cluster-Aware JVMs . . . 13
3.3.1 Java/DSM . . . 14 ix
x Table of Contents 3.3.2 cJVM . . . 14 3.3.3 JESSICA2 . . . 14 3.3.4 dJVM . . . 14 3.4 Conclusion . . . 15 4 Design 17 4.1 Overview . . . 17
4.2 Home-Based Lazy Release Consistency Model . . . 18
4.2.1 Adaption to Our DSM . . . 18 4.3 Communication . . . 19 4.3.1 Protocol . . . 19 4.4 Shared Objects . . . 20 4.4.1 Definition . . . 20 4.4.2 Globally Unique ID . . . 21 4.4.3 Detection . . . 21 4.4.4 States . . . 22 4.4.5 Conclusion . . . 24 4.5 Distributed Classloading . . . 24 4.6 Scheduling . . . 26 4.6.1 Synchronization . . . 26 4.7 I/O Redirection . . . 27 4.8 Garbage Collection . . . 27 5 Implementation 29 5.1 Messaging Model . . . 29 5.2 Boot Process . . . 30
5.3 Shared Object Space . . . 32
5.3.1 Shared Objects . . . 32
5.3.2 GUID Table . . . 33
5.3.4 Cache Coherence Protocol . . . 36
5.3.5 Statics . . . 37
5.4 Distributed Classloader . . . 40
5.4.1 Class Replication Stages . . . 41
5.5 Distributed Scheduling . . . 42
5.5.1 Thread Distribution . . . 42
5.5.2 Thread and VM Termination . . . 43
5.6 Thread Synchronization . . . 44
5.7 I/O Redirection . . . 45
6 Benchmarks 47 6.1 Test Environment . . . 47
6.2 Test Application Suite . . . 47
6.3 Performance Evaluation . . . 49
7 Conclusions and Future Work 53 7.1 Problems . . . 53
7.2 Future Work . . . 55
7.2.1 Object Home Migration . . . 55
7.2.2 Object Prefetching . . . 56
7.2.3 Thread Migration . . . 57
7.2.4 Fast Object Transfer Mechanism . . . 57
7.2.5 VM and Application Object Separation . . . 58
7.2.6 Garbage Collector Component . . . 58
7.2.7 I/O Redirection for Sockets . . . 58
7.2.8 Volatile Field Checks . . . 58
7.2.9 Trap Handler Detection of Faulting Accesses . . . 58
7.2.10 Software Checks in the Optimizing Compiler . . . 59
xii Table of Contents A Appendix 61 A.1 DJVM Usage . . . 61 A.2 DJVM Classes . . . 62 A.2.1 CommManager . . . 62 A.2.2 Message . . . 62 A.2.3 SharedObjectManager . . . 62 A.2.4 GUIDMapper . . . 63 A.2.5 LockManager . . . 63 A.2.6 DistributedClassLoader . . . 63 A.2.7 DistributedScheduler . . . 63 A.2.8 IORedirector . . . 63
A.3 Original Task Assignment . . . 64
3.1 Distributed runtime systems overview . . . 11
4.1 Protocol header . . . 20
6.1 Access on node-local and shared objects . . . 50
6.2 Overhead thread allocation, classloading and I/O redirection . . . 50
2.1 LRC protocol . . . 8
4.1 DJVM overview . . . 17
4.2 Lazy detection of shared objects example . . . 23
4.3 Shared object states . . . 24
4.4 Classloading states . . . 25
5.1 Cluster boot process . . . 31
5.2 GUID table example . . . 34
5.3 Cache coherence protocol . . . 38
5.4 Thread distribution . . . 43
5.5 Acquire lock on a shared object . . . 45
6.1 Thread synchronization time . . . 51
7.1 Thread representation . . . 53
A.1 Message class hierarchy . . . 62
A.2 Original task assignment page 1 . . . 64
A.3 Original task assignment page 2 . . . 65
Since its introduction in 1995, Java has become one of the most popular programming languages. Considered as a productive language, the performance of Java applications has been insufficient for a long time because of the poor performance of the Java Virtual Machine (JVM) that runs the application. Due to recent progress in compilation, garbage collection, distributed computing, etc. Java has even become attractive for high performance applications such as multi-threaded server applications that require computational power. One way is to run computation-intensive applications on multi-core computers that are expensive. Motivated by the emergence of cluster computing that is a cost-effective substitute for such dedicated parallel computers, the idea of running multi-threaded applications truly in parallel and transparently within a cluster has become a discussed research topic.
Although current JVMs are limited to a single machine, they could be extended to multiple ma-chines due to their virtual design and the fact that they do not have any special hardware bounds. The general idea of a distributed JVM, a JVM running on a cluster, is to distribute Java threads among the cluster nodes to gain a higher degree of execution parallelism. In order to provide transparency for a shared memory abstraction for Java threads, we added a global object space. We move objects into this space if they can be accessed by multiple threads on different machines allowing threads to be scheduled on any node based on load and locality information.
In our thesis, we extended the Jikes Research Virtual Machine to run within a cluster. In contrast to other approaches such as JESSICA and Java/DSM [24,30] that use a paged-based distributed shared memory, we embedded our Shared Object Space, a virtual global object heap, directly into the JVM to make it cluster-aware which gives us more ways for further optimizations. We defined a cache coherence protocol to deal with objects in the Shared Object Space and in the node’s local object heap and added support for distributed object synchronization. Additionally, we developed mechanisms for classloading to achieve a consistent view on all nodes and scheduling for distributing threads among the cluster. Finally, we redirected all I/O operations to a single node in the cluster handling all I/O for transparency issues for the programmer and the Java application itself1.
Chapter 2 introduces the background information that is needed to understand the design decisions we made for our system presented in Chapter 4 where we talk about the concept of shared objects
1
Imagine that several threads are distributed among several cluster nodes and each thread calls
System.out.println(). Transparency is achieved if all console outputs are printed on a single screen of a certain node.
2 1. Introduction
and the cache coherence protocol. In Chapter 3 we will show related work in the area of distributed JVMs. We discuss different approaches and techniques to build a distributed runtime environment to run multi-threaded Java applications and compare them with our work. In Chapter 5 we give some implementation details of our distributed JVM and we measured the performance and show benchmark results in Chapter 6. Finally in Chapter 7, we conclude, discuss about problems we encountered during the work and present several further work to our distributed JVM such as different optimization techniques.
To understand the design decisions we made for our virtual global object heap embedded in our chosen JVM more clearly, we will give a short overview about the used JVM and an introduction about distributed shared memory systems in software on which our global object heap is based on. Finally, we talk about the Java Memory Model that is needed to clarify the cache coherence protocol used in our implementation.
2.1
Jikes Research Virtual Machine
The Jikes Research Virtual Machine (JikesRVM) [3] is an open-source project of a Java Virtual Machine. The JikesRVM has evolved from the Jalape˜no Virtual Machine [7, 8] developed at IBM Watson Laboratories. A special characteristic about the JikesRVM is that it has been written nearly entirely1 in Java itself. The JikesRVM code base provides a stable and well-maintained
framework for researchers and gives them the opportunity to experiment with a variety of design and implementation alternatives. Due to many publications2 released over the last ten years and
due to a broad and active community enhancing the code base, the JikesRVM has become a state-of-the-art Java Virtual Machine.
2.1.1 Baseline and Optimizing Compilers
Within the JikesRVM the Java bytecode is not interpreted, instead each method is compiled from bytecode into native machine code by using either the Baseline or the Optimizing compiler. The Baseline compiler can be considered as a fast pattern-matching compiler, i.e. the bytecode instruc-tions are matched against several patterns and then the compiler emits the corresponding machine code. Since the Baseline compiler translates the bytecode in a stack machine manner of the JVM specification [21], the resulting native code runs slower because its quality is similar to an inter-preter. If a simple assignment such as x = y + z is considered, it gets translated into the native code as shown in Listing 2.1 as pseudocode.
1
Some part of the code has been written in C such as the bootloader for launching the JVM or some relay code for performing system calls.
2
http://jikesrvm.org/Publications
4 2. Background and Preliminary Work
Listing 2.1: Pseudocode produced by the Baseline compiler for a simple assignment
1 load (y, r1) // l o a d y i n t o r e g i s t e r r1 2 push (r1) // p u s h r1 o n t o s t a c k 3 load (z, r2) 4 push (r2) 5 pop (r1) // pop v a l u e f r o m s t a c k i n t o r1 6 pop (r2) 7 add (r1 , r2 , r3) // r1 + r2 = r3 8 push (r3) 9 pop (r3) 10 store (r3 , x) // s t o r e v a l u e in r3 to v a r i a b l e x
In order to improve the performance, the Optimizing compiler utilizes the registers more effec-tively and uses some advanced optimizations techniques such as dead code removal to produce competitive performance [7]. The Optimizing compiler implementation exceeds the Baseline com-piler in size and complexity. The JikesRVM allows an adaptive configuration where methods are initially compiled by the Baseline compiler since the translation occurs more quickly. Frequently used or computationally intensive methods are identified by the adaptive optimization system of the JikesRVM and are recompiled with the Optimizing compiler for performance improvements (cf. [3] for more details).
2.1.2 Threading Model
In the JVM specification [21] the behaviour of Java threads is defined, but there are no constraints about the underlying threading model, i.e. how the threads’ behaviour must be implemented on a specific operating system and architecture. Basically, there are two known threading models used in several JVM implementations: Green threads model and native threads model.
Green threads are scheduled by the VM and are managed in user space. Since Green threads emulate a multi-threaded environment without using any native operating system capabilities, they are lightweight but also inefficient. From the underlying operating system’s point of view only one thread exists, i.e. the VM itself. As a consequence, Green threads cannot be assigned to multiple processors since they are not running at OS level, therefore they are bound to be executed within a single JVM running on a single processor. On the other hand, native threads are created in kernel space which allows them to benefit from a multi-core system. This can result in performance improvements since the execution to blocking I/O system calls will not cause the JVM to be stalled because only the native thread waiting for the I/O result is blocked. The Green threads model was the only model used in Java 1.1 for the HotSpot JVM. Due to the limitations described above, subsequent Java versions dropped Green threads in favor of native threads3.
The threading model used in the JikesRVM is an M:N threading model that implements both 3
threading models in particular. Java threads, i.e. threads from the Java applications4 and VM
daemon threads such as mutator and garbage collector threads, are multiplexed onto one or more virtual processors, each of them bound to a POSIX thread. The number of virtual processors can be defined on the command line. Per default only one virtual processor is created. The JikesRVM runtime system schedules an arbitrarily large number M of Java threads over a finite number N virtual processors. As a result, at most N Java threads can be executed concurrently. The M:N threading model benefits from the fact that the runtime system can only use N POSIX threads from
the underlying operating system. As a consequence, the OS cannot be swamped by Java threads, crowding out system and other application threads as it would happen in the native threads model that corresponds to a 1:1 thread model. However, the main reason for using Green threads is that the JikesRVM utilizes them for garbage collection. After some bytecode instructions each Green thread checks its yieldpoint condition that is inserted during method compilation. Only if the condition evaluates to true, the Green thread is allowed to switch to another thread which is a pro-active thread switching process. This approach makes garbage collection easier because the collector thread knows the state and stackframe of each mutator which are stored in a GC map, therefore the computation of the root set is easier. With the M:N threading model the JikesRVM
does also benefit from the system-wide thread management since it requires synchronizing on at most N active threads instead of an unbounded number of M threads. E.g. a stop-the-world garbage collector merely needs to flag the N currently running threads that they should switch into a collector thread rather than having to stop every mutator thread in the system. A drawback of the M:N threading model however is that many native I/O operations are blocking so that the
calling native thread is blocked until the operation is completed. As a result, the virtual processor is blocked and not able to schedule further threads. To avoid this problem, blocking I/O operations are intercepted by the JikesRVM runtime system and replaced by non-blocking operations. The calling thread is suspended and placed into an I/O queue. The scheduler periodically polls for pending I/O operations and after they complete, the calling thread is removed from the I/O queue and queued for execution [3].
2.1.3 Object Model
An object model defines how an object5 is represented in memory. The introduced object model in
the JikesRVM fulfills some requirements such as fast instance field and array accesses, fast method dispatching, small object header size, etc.
The object header in the default object model consists of two words for objects and three words for arrays which store the following components:
• TIB Pointer: The Type Information Block (TIB) pointer is stored in the first word and contains information about all objects of a certain type. A TIB consists of the virtual method
4
In the thesis, the termuser threadis sometimes used to refer to Java threads created by the application.
6 2. Background and Preliminary Work
table, a pointer to an object representing the type and pointers to a few data structures for efficient interface invocation and dynamic type checking.
• Hash Code: Every Java object has an identity hash code. By default the hash code is the object’s memory address. Due to the fact that some garbage collectors copy objects during garbage collection, the memory address of the object changes. Since the hash code must remain the same, space in the object header (part of the second word) may be used to store the original hash code value.
• Lock: Each Java object has an associated lock state that could either be a pointer to a lock object or a direct representation of a lock.
• Garbage Collection Information: Garbage collectors may store some information in an object such as mark bits, etc. The allocated space for this type of information is located in the second word of the header.
• Array Length(for array objects): The number of elements of an array is stored in the third word.
• Miscellaneous Fields: For additional information, the object header can be expanded by several words in which for example profiling information can be stored. Note that Miscella-neous Fields are not available in the default object model.
Object fields are laid out in the order they are declared in the Java source file with some exceptions to improve alignment. doubleand long fields (and object references in a 64bit architecture) are 8-byte aligned and are laid out first so that holes in the field layout alignment are avoided for these fields. For other fields whose sizes are four bytes or smaller, holes might be created to improve the alignment. E.g. for an int field followed by a byte, a three byte hole following the byte field is created to keep the int field 4-byte aligned.
2.2
Distributed Shared Memory
Software distributed shared memory systems (DSM6) virtualize a global shared memory abstraction
across physically connected machines. DSM systems can be classified into two categories that are based on their granularity of the shared memory region. In page-based DSM systems shared memory is organized as virtual memory pages of a fixed size. The object-based approach uses shared memory region as an abstract space for storing shareable objects of variable size. Additionally, a coherence protocol combined with a memory consistency model maintains the memory coherence.
2.2.1 Page-Based Distributed Shared Memory
Page-based DSM systems utilize a Memory Management Unit (MMU) that detects faulting access to an invalid or not available shared page. The MMU handles the faulting access by getting a valid copy from the machine where the shared page is located. The benefit of the MMU is that it only intercepts faulting accesses whereas normal accesses do not have to be handled. A drawback of page-based DSM systems however is the false sharing problem that arises when two processes
access mutually exclusive parts of a shared page. In this case two virtual memory pages, that usually have fixed size of 4KB per default, are mapped against the same shared page, resulting in two different views of the same page.
2.2.2 Object-Based Distributed Shared Memory
The object-based DSM approach reduces thefalse sharing problemof the page-based DSM approach
since the granularity is an object of an arbitrary size. Contention happens only if two processors access the same object. False contention is not possible however. Since the MMU cannot trap accesses to objects of variable size, software checks must be inserted upon every access to an object.
2.3
Memory Consistency Model
A memory consistency model contains a set of rules that specify a contract between the programmer and the memory system. As long as these specifications are followed, the memory system will be consistent and the result of the memory operations are predictable. In particular, the model defines which value might be read from the shared memory, to which other threads could have written before. Sequential Consistency is one of the most intuitive consistency models for the programmer. The model defines that every processor in the system sees the write operations on the same memory part, meaning that the processor follows the program order execution and that all write operations are visible to the other processors. Due to this fact, the Sequential Consistency has a poor performance since compiler optimizations such as reordering of memory accesses to different addresses cannot be performed. In a DSM system, this results in excessive communication traffic. Therefore, several models have been introduced to relax the memory order constraints of Sequential Consistency. The idea of relaxed memory consistency models such as the Release Consistency7is to reduce the impact of remote memory access latency in a DSM system. In
the following subsection the Lazy Release Consistency model (LRC) is introduced which is the base model for our implementation of the DSM. We also give a description of the memory consistency model used in the Java programming language to clarify the understanding when we compare our implemented model with the Java Memory Model later.
7
Release Consistency is a form of relaxed memory consistency that allows the effects of shared memory accesses to be delayed until certain specially labeled accesses occur [20].
8 2. Background and Preliminary Work
2.3.1 Lazy Release Consistency Model
Lazy Release Consistency is an algorithm that implements Release Consistency in such a way that propagations of modifications to the DSM is postponed until the time the modifications becomes necessary, i.e. the propagations are sent lazily. The goal is to reduce the number of exchanged messages.
In LRC, accesses to memory are distinguished between sync and nsync, where sync accesses are
further divided into acquires and releases. An acquire operation is used to enter a critical section
and a release operation is used when a critical section is about to be exited. The time when a
modification to the DSM becomes necessary is when anacquireoperation is executed by a processor P1 as shown in Figure 2.1. P1 P2 acquire(x) release(x) write(x) acquire(x) release(x) read(x) send diffs(x) Figure 2.1: LRC protocol.
Before entering the critical section, the last processorP2 that released the lock must send a notice
of all writes, that were cached inP2 before exiting the critical section, to P1 such that the cached
values inP1 become up-to-date. Another optimization to limit the amount of data exchanged is to
send adiff of the modification to the DSM. A diff describes the modifications made to a memory
2.3.2 Java Memory Model
The Java language was designed with multi-threading support which requires an underlying shared memory (the object heap) on which Java threads can interact. The memory consistency model for Java is calledJava Memory Model (JMM)and defines the Java Virtual Machine’s thread interaction
with a shared main memory (cf. [21] for a full specification). In JMM, all threads share a main memory, which contains the master copy of every variable. In Java this can either be an object
field, an array element or a static field. Every thread has its own working memory that represents
a private cache in which aworking copy of all variables that the thread uses are kept, i.e. when a
variable in the main memory is accessed, it will be cached in the working memory of the thread. A lock that is kept in the main memory is associated with each object. Java provides the
synchronized keyword for synchronization among multiple threads. When a thread enters a synchronized block, it tries to acquire the lock of the object. When a thread exits a synchronized block, it releases the lock, respectively. A synchronized block does not only guarantee exclusive access for the thread entering the block, but it does also maintain memory consistency of objects among threads that have performed synchronizations on the same lock. In particular, the JMM defines that a thread must flush its cache before releasing the lock, i.e. all working copies are transferred back to main memory. Before a thread acquires a lock, it must invalidate all variables in its working memory. This guarantees that the latest values are read from main memory.
In this chapter we give an overview of different approaches to build a distributed runtime envi-ronment to run multi-threaded Java applications in parallel within a cluster. We discuss the used techniques shortly and highlight the advantages and disadvantages of each system. Finally, we compare the existing approaches with our work and point out our motivation to implement such a runtime system.
As done in the paper about JavaSplit [16], existing distributed runtime systems for Java can be classified into three different categories:
Distributed Runtime Systems Advantages Disadvantages Cluster-aware VMs • Java/DSM • cJVM • JESSICA • JESSICA2 • dJVM • Efficiency
• Direct memory access
• Direct network access
• Portability
Compiler-based
• Hyperion
• Jackal
• Compiler optimizations
• Local execution of ma-chine code
• Portability
Using standard JVMs
• JavaParty
• JavaSplit
• Portability • Reduced Single System Image
Table 3.1: Distributed runtime systems overview.
Each category has its benefits and drawbacks when it comes to portability and performance. While systems based on a standard JVM usually preserve portability, they might not provide a complete Single System Image (SSI), i.e. they deviate from the standard Java programming paradigm by introducing new keywords for example. The systems in the other two categories usually have a
12 3. Related Work
complete SSI, but they have portability issues. In the following, we explain the concepts for these different distributed runtime environments and describe some existing implementations.
3.1
Compiler-Based Distributed Runtime Systems
In compiler-based distributed runtime systems, the source or the bytecode of a Java application is compiled into native machine code. During translation, calls to DSM handlers are added and several optimizations are done to improve the performance. Since the Java application is compiled completely to machine code before its execution, the speed is increased because a Just-In-Time (JIT) compiler is not required anymore. Compiler-based systems do also preserve the standard Java programming paradigm. However, updates to such compilers need to be done if there are changes to the Java programming language. Jackal [28], for example, compiles Java source files directly into machine code. With the addition of generics in Java 5, adjustments to the compiler must be done. Besides, the source code of the Java application might not be available due to confidentiality reasons. As a consequence, such systems do not scale very well regarding portability because they do not have the opportunity of using reflection and therefore they have a limited language support.
3.1.1 Hyperion
Hyperion [23] is a compiler-based DSM system that translates Java application’s bytecode into C source code that is finally compiled into native machine code by a C compiler. While translating the bytecode, code for DSM support is added and several optimizations are done to enhance performance. Since Hyperion allocates all objects in a global object heap, the local garbage collector needs to be extended. However, this has not been done in the paper [23]. A benefit of Hyperion compared to Jackal is that new additional Java constructs will not necessarily result in changes to the bytecode. Therefore, Hyperion is less sensitive to evolution of the Java language but portability is still an issue.
3.2
Systems Using Standard JVMs
Since distributed runtime systems utilize a standard JVM, they usually benefit from the portability. These systems can use a set of heterogeneous cluster nodes. As a result, each node is able to do local optimizations, e.g. using JIT compiler, and the local garbage collector of the standard JVM can still be used. Such systems however have two main drawbacks. The access to a node’s resource is relatively slow since the access must usually go through the underlying JVM. Additionally, most of these systems deviate from the standard multi-threaded Java programming paradigm. Systems like JavaParty [31] try to be close enough to pure Java by only introducing a small set of new language constructs such as the remote keyword to indicate which objects should be distributed among
the cluster nodes. The source code is transformed and extended with RMI code. Therefore, the SSI is further reduced since the programmer must differentiate between local and remote method invocations due to the different parameter passing convention. JavaSplit [15,16] is also a distributed runtime system that uses only a standard JVM. The authors claim that JavaSplit has all the benefits of systems using unmodified JVMs. In addition, JavaSplit preserves SSI.
3.2.1 JavaSplit
The techniques used in JavaSplit are based on bytecode instrumentation, performed by the Byte-code Engineering Library (BCEL)1. JavaSplit takes the Java application as input, rewrites the
bytecode and combines the instrumented code with an own runtime logic that is also implemented in Java. The result is a distributed application that is ready to be executed on multiple standard JVMs. During bytecode rewriting, events in the context of a distributed runtime are intercepted such as the start of new threads. Such calls are replaced with calls to a DSM handler (similar to Hyperion described above) that ship the thread to a node chosen by a load balancing function for example. JavaSplit does not require any special language construct, thus preserving a complete SSI. To make use of the standard JVM’s garbage collector, they classify objects into shared and local objects. The former are handled by their object-based DSM garbage collector while the latter are reclaimed by the local garbage collector [15]. In addition, JavaSplit should be able to be executed on any standard JVM. However, in [16] the authors mention that “the bytecode rewriter does not intercept I/O operations of the user application. Instead, the Java bootstrap classes that perform low-level I/O are modified to achieve the desired functionality.” In other words, the standard JVM needs to be modified and therefore portability issues arise again.
3.3
Cluster-Aware JVMs
Cluster-aware JVMs are usually a result of modifying an existing standard JVM by adding distri-bution. These systems consist of a set of nodes that have the same homogeneous JVM installed and that execute their part of the distributed execution. In comparison to systems using standard JVMs, cluster-aware JVM benefit from efficiency since direct access to resources such as memory and network are possible rather than going through the JVM. Furthermore, cluster-aware JVM usually preserve an SSI. On the other hand, due to the homogeneity, cluster-aware JVM systems lack true crossplatform portability. In the following we introduce several known cluster-aware JVM systems.
1
14 3. Related Work
3.3.1 Java/DSM
Java/DSM [30] was one of the first JVM containing a DSM. A standard JVM is implemented on top of a software DSM system called TreadMarks2. The DSM handling code is done by TreadMarks
since all Java objects are allocated over this DSM system. However, since the thread’s location is not transparent to the programmer, the SSI provided by Java/DSM is incomplete.
3.3.2 cJVM
Instead of using an underlying software DSM, the Cluster VM for Java called cJVM [9,10] makes use of a proxy design pattern, i.e. rather than requesting a valid copy of an object as in DSM systems, the access is executed as a remote request and the actual execution is done on the node where the object is actually located. No consistency issue is involved in this approach. cJVM runs within an interpretation mode. To improve performance, several optimizations such as caching and object migration techniques have been implemented.
3.3.3 JESSICA2
JESSICA2 [35] is based on the Kaffe VM3 and embeds an object-based DSM called Global Object
Space (GOS). JESSICA2 implements many features such as thread migration, an adaptive home migration protocol for its GOS and a dedicated JIT compiler, since the standard JIT compiler cannot be used (in contrast to systems using standard JVMs). Their dedicated compiler improves the performance significantly compared to an interpreter. Objects are separated into shared and local objects. While shared objects are put into GOS and are handled by a distributed garbage collector, local objects are reclaimed by the VM’s local garbage collector. Like cJVM, JESSICA2 provides a true SSI.
3.3.4 dJVM
The Jikes distributed Java Virtual Machine [36] called dJVM was developed at the Australian National University in Canberra and is the first known distributed JVM based on the JikesRVM. dJVM follows a similar approach as cJVM by generating proxy stubs for remote access on objects rather than implementing a GOS like in JESSICA2. The distribution code was added to the JikesRVM version 2.2, which is out-of-date. In a later version of the dJVM4, the developers switched
to a bytecode rewriting approach by using the BCEL as done in JavaSplit
2 http://www.cs.rice.edu/~willy/TreadMarks/overview.html 3 http://www.kaffe.org/ 4 http://cs.anu.edu.au/djvm/
3.4
Conclusion
In this chapter, we have given an overview of existing distributed Java runtime systems and high-lighted their benefits and drawbacks. As discussed, systems using standard JVMs usually have the advantage of portability but they have usually worse performance or introduce unconventional language constructs. For performance reason, we pursue a cluster-aware JVM approach at the cost of portability. We decided to embed our work into the JikesRVM for several reasons:
• The JikesRVM is open-source and provides a stable infrastructure that allows experimenting with different implementation alternatives.
• The VM is consistently maintained and the documentation is mostly up-to-date.
• Its code base is relatively small compared to other open-source JVMs such as the OpenJDK. Additionally, the code is well-structured so that it is possible to understand the internal workings in an appropriate time.
• Unlike other open-source JVMs that only provide an interpreter, the JikesRVM contains an optimizing JIT compiler that produces high quality code that can be used in a productive environment.
Since the JikesRVM5 only runs on Linux-based operating systems, portability is not a big issue for
our work.
Motivated by the concept of object-based DSMs in JavaSplit and JESSICA2 and by the fact that no known work has been done for the JikesRVM, we have embedded a virtual global object heap called the Shared Object Space into the JikesRVM and added mechanisms to achieve a complete
SSI. Although running a VM on top of a page-based DSM such as Java/DSM would reduce the complexity of constructing a global object heap since the cache coherence issues are managed by the DSM system, there are some drawbacks to be mentioned:
• Since the sharing granularity of Java and the page-based DSM are not compatible (objects of variable size vs. virtual memory pages of a fixed size, cf. Section 2.2), the false sharing problem arises. Additionally, if a Java object resides across virtual memory pages, a fault-in results in requesting two pages which is quite heavyweight.
• Because the page-based DSM resides in a layer below the VM, it is not able to use the runtime information of the VM. In addition, the detection of access patterns of an application becomes difficult since several Java objects could reside in a single memory page. In contrary, our Shared Object Space can fully utilize the abundant runtime information of the VM that allows further optimizations.
5
For our work, we used the JikesRVM version 2.9.2 that was the latest stable build at the time writing the thesis. Recently, version 2.9.3 and the latest 3.0 have been released.
16 3. Related Work
• In paged-based DSM systems, each node manages a portion of the shared memory where the objects are allocated. As a consequence, each object is considered as shared requiring special treatment when it comes to garbage collection. In our Shared Object Space we distinguish objects shared among different nodes from local objects since local objects require no special treatment.
In this chapter we will discuss the design decisions we made when adding a distributed runtime system to the JikesRVM. We show how we extended the JVM to be cluster-aware with a master-slave architecture. We implemented a global object heap by introducing the Shared Object Space by defining shared objects and how we solved memory consistency issues across node boundaries. Mechanisms of a distributed classloading, thread synchronization and garbage collection and for distributing the workload across multiple machines are also presented. To achieve transparency for Java applications, we also show how I/O is redirected in our distributed JVM.
4.1
Overview
The design we chose for our distributed JVM (DJVM) is based on a single system image (SSI), i.e.
the underlying distribution should be transparent to the Java application running in the DJVM.
Rather than using a page-based DSM software as done in Java/DSM [30] and JESSICA [24], we decided to implement an own object-based DSM into the JikesRVM to make the VM aware of the shared memory which allows us to do further optimizations as described in Section 7.2.
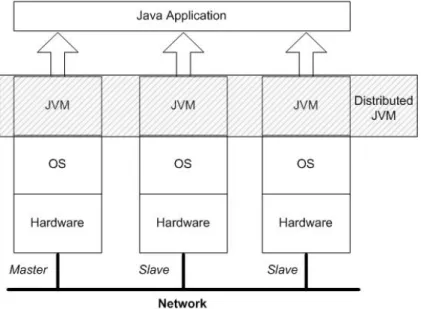
Figure 4.1: DJVM overview.
For our cluster we use a master-slave architecture where one node in the cluster embodies the master 17
18 4. Design
node and the other nodes become so-called slave or worker nodes1. The master node is assigned
some special functions such as setting up the cluster and controlling all global data (cf. Section 5.3.5) and classes loaded by the Java application. Furthermore, threads of the Java application are scheduled and distributed via the master node which is therefore responsible for shutting down the cluster when all threads of the application have terminated. Since threads can be distributed among different nodes in the cluster, they must still be able to synchronize on objects located on another node. We therefore developed a Shared Object Space that combines the object heap of every cluster node that represent a virtual global object heap.
4.2
Home-Based Lazy Release Consistency Model
In Section 2.3.1 we have given a description of the LRC model. In [32] it has been shown that LRC does not scale very well because of the large amount of memory consumption for the protocol overhead so that garbage collectors have difficulties in collecting that data. To achieve a better performance, LRC has been extended toHome-based Lazy Release Consistency (HLRC) [32]. Each
shared memory page is assigned a home-base to which all propagations are sent to and from which all copies are fetched. The main idea of HLRC is to detect possible updates to a shared memory page, compute the diffs and send them back to their home bases where those diffs are applied. The diffs are computed only on non-home bases by comparing the cached shared memory page with a so-called twin page, that contains the original data upon the initial page request. The advantages
of HLRC compared to LRC are that accesses to pages on their home-base will not cause any page faults. Additionally, non-home bases can update their copies of shared pages in a single roundtrip message. Thus, the protocol data and messages are smaller because the detection of the processor that has most recently released a lock is omitted in HLRC. This makes the timestamp technique used in LRC unnecessary.
4.2.1 Adaption to Our DSM
Our DSM is based on HLRC. Since our DSM is object-based rather than page-based, every object is assigned to ahome node which is the node from where the object’s reference is initially exposed
across node boundaries. When an object2 is requested from an other node, a copy of the requested
object is created on the non-home node. Instead of creating the twin as a separate object as
proposed in [32] and [20], we place the twin’s data at the end of the requested copy which saves us two words per shared object since we can omit the header for the twin.
We adapted our cache coherence protocol to become similar to the JMM (see Section 2.3.2). Upon a release of a lock, diffs are computed for all written non-home nodes objects by comparing each field of the copy with their respective twins. The updates are then sent in a message to the according home node that finally applies the updates to the home node object. This procedure corresponds
1
In the following, these terms can be substituted with each other.
exactly to the cache flush in the JMM. When a lock is acquired, the JMM states that all copies in the working memory of a thread must be invalidated [21]. In our DSM, this means that every non-home node object must be invalidated such that further reads or writes to an invalid object will cause the runtime system to fetch the object’s latest value from its home node.
4.3
Communication
Since our Shared Object Space is embedded into a cluster-based JVM, we have to make JikesRVM cluster-aware by implementing a communication subsystem that is responsible for sending and receiving messages between nodes in the cluster. Our CommManager is an interface to hide the
actual underlying hardware involved during communication. Currently, we provide two different communication channels.
• Raw sockets: Provide fast communication by encapsulating messages directly in Ethernet frames.
• TCP/IP sockets: Provide reliable communication between the cluster nodes.
Under the assumption that all our cluster nodes are located within the same subnet in a local area network, we provide a communication substrate based on raw sockets. Because messages sent over these sockets are encoded directly in Ethernet frames, we avoid the overhead of the messages going through the TCP/IP stack of the operating system. As shown in a comparison in [6], raw sockets can even outperform UDP sockets that do not provide reliability compared to TCP. Broadcasting messages over raw sockets is also a benefit since only one message3 must be sent to address all
nodes in the cluster. However, due to the lack of reliability by using raw sockets, we also provide a communication based on TCP/IP4
Our cluster supports a static set of nodes. At startup, after booting the CommManager, the
master node applies for the role of a coordinator that waits until all worker nodes have established a connection to the master node5. When all worker nodes have setup a connection, the master
node sends unique node IDs, that are assigned to each node, and the nodes’ MAC or IP address. When using TCP/IP sockets, the worker nodes further establish a communication channel between each other so that nodes can send messages to and receive messages from each other.
4.3.1 Protocol
For the serialization process of our messages, we avoided the standard object serialization provided by the Java API because the object serialization provides meta information encapsulated in the serialized object bytestream to reconstruct the object on the receiver side which leads to unnecessary
3
By using the MAC addressFF:FF:FF:FF:FF:FF.
4
TCP is reliable because lost messages are retransmitted accordingly and messages are received in-order.
20 4. Design
overhead of the communication traffic. Instead, we designed an own protocol consisting of a 15 byte header that is sufficient to reconstruct the message on the receiving node.
Message Type Message Subtype Node-ID Packet Number Total Packets Message-ID Message Length
1 byte 1 byte 1 byte 2 bytes 2 bytes 4 bytes 4 bytes Table 4.1: Protocol header.
The Message Type field defines the type of the message such as classloading, I/O, object
syn-chronization, etc. The Message Subtype field specializes the exact type of the message, e.g. the ObjectLockAcquire subtype that is sent when a remote lock for an object should be acquired. The Node-ID contains the unique ID of the sending cluster node.
Since a message cannot exceed the length of 1500 bytes when using raw sockets, every message larger than this limit is splitted into several packets. ThePacket Number defines the actual packet
of the possibly splitted message whereas theTotal Packets field states the total amount of packets
the splitted message consists of. Finally we have two 4-byte fields for the Message-ID that is used
for messages requiring an acknowledgment and for the Message-Length defining the length of the
message excluding the 15-byte header per packet.
When sending a message, it is encoded into a buffer that is obtained from a buffer pool, set up by the CommManager to avoid allocation upon each use. If the buffer pool becomes empty, new
buffer objects will be allocated to expand the pool. A filled buffer contains all necessary data to reconstruct the message object on the receiving node. By serializing the messages ourselves, we reduce communication traffic for each transmitted message compared to the standard object serialization API in Java. For every socket, a MessageDispatcher thread waits in a loop to receive
messages. This thread dispatches all incoming packets by reading the 15 bytes of the protocol header first and assembling them together to construct a new message object which can then be processed by calling theprocess() method (more details are given in Section 5.1).
4.4
Shared Objects
In our DJVM, the object heaps of every node contribute for a global object heap that we call the Shared Object Space. Before we start to explain the design of our Shared Object Space, we discuss
some memory related issues by definingShared Objects, what their benefits are and how they are
detected to become part of theShared Object Space.
4.4.1 Definition
An object is said to be reachable if there is a reference in a Java thread’s stack or if there exists a path in a connectivity graph6. When an object is reached by only one thread, that object is considered
6
Two objects are considered as connected when one object contains a reference to the other object. A connectivity graph is formed by the transitive relationships of connected objects.
as a thread-local object and since only one thread operates on that object, synchronization is not an issue whereas objects reached by several threads need to be synchronized (cf. Section 2.3.2). In a distributed JVM an object can also be reached from Java threads that reside on a different node in the cluster and therefore we distinguish between (based on [16,17])
• node-local objects that are only reached by one or multiple threads within a single node and • shared objects that are reached by at least two threads located on different nodes.
This means when an object is exposed to a thread residing on a different node than the object itself, the object becomes a shared object.
4.4.2 Globally Unique ID
In a JVM running on a single node, every object in the heap can be reached by loading its memory address. In a distributed JVM though, locating an object by a memory address is not sufficient enough since an object o1 at a specific address on nodeN1 is not necessarily located at the same
address on another node N2. Shared objects are required to be reachable from any node per
definition. For that purpose, every shared object is assigned a Globally Unique Identifier (GUID).
Every node keeps track of a GUID table that maps the object’s local address against its GUID which allows to do pointer translation across node boundaries.
A GUID consists of 64 bits, containing an Object-ID (OID) and a Node-ID part: 0 |{z} 1 Bit, unused 11 |{z} 2 Bits, Node-ID 1...1 |{z} 61 Bits, Object-ID
We left the most significant bit unused that can be used freely for example for garbage collection. Since ourDJVM is a prototype of a distributed runtime system that is designed for small clusters,
we only use 2 bits for addressing at most 4 different nodes, leaving 61 bits for the OID. However, our design is flexible so that this can be changed by modifying a constant. As discussed in Section 4.2.1, every shared object is assigned to a home node. Therefore, the information encapsulated in a GUID suffices to relocate an object on a particular node.
4.4.3 Detection
By using the definition in Section 4.4.1 an object becomes a shared object if two threads located at different nodes reach the object. Because of Java’s strong type system every object on the heap or thread-local objects on the thread’s stack is associated with a particular type that is either a reference type or a primitive type. Since the JikesRVM runtime systems keeps track of all types, it is easy to identify which variables are reference types. By creating an object connectivity graph we can detect at runtime if a particular object will be reached from a thread’s stack. When a thread is
22 4. Design
scheduled on a different node in the cluster (cf. Section 4.6) all reachable objects from the thread’s stack become shared objects since they are reachable from a different node, too.
The idea of marking all reachable objects as shared whenever an object becomes shared leads to several performance issues since objects with a large connectivity graph have to be traversed. We encountered problems when objects that reference VM-internal objects had been marked as shared. For the reason that we cannot distinguish VM objects from application objects in the JikesRVM (see Section 7.1 for more details), we use a lazy detection scheme for shared objects similar to the one described in the paper [18] along with explicit exception cases that some objects never become shared objects to avoid this problem. It makes more sense to share objects lazily since the maintenance cost of a node-local object is lower and because it is undecidable if an object will be accessed by its reaching thread.
When a thread is distributed from a sender node to a receiver node, we only mark all directly reachable objects from the thread’s stack as shared objects and a GUID will be assigned to them. By sending the thread to the receiver node, the GUIDs belonging to the references of the thread object will also be transmitted along. On the receiving side we reconstruct the thread object and the received GUIDs are looked up in the GUID table which maps a GUID against a local memory address. If the GUID is found, the local memory address of the object belonging to the GUID will be written into the corresponding object reference field. On the other hand if the GUID is not found, that means that the object has never been seen before and the object reference field is replaced by an invalid reference. Our software DSM detects accesses to such dangling pointers which leads to a request of the corresponding object on its home node, i.e. the copy of the object is faulted-in from the home node.
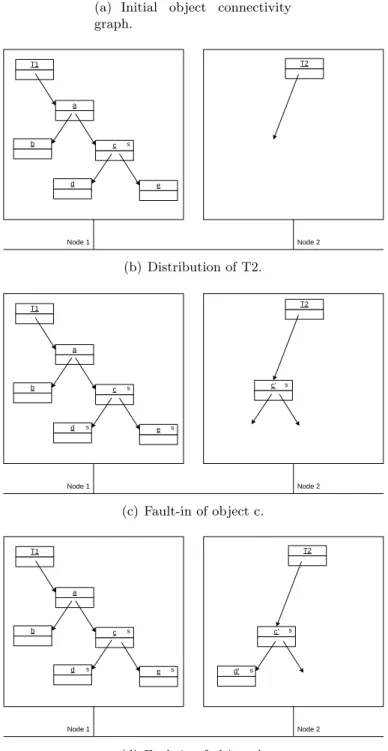
Consider an example as shown in Figure 4.2. Thread T1 has a reference to the root object a.
Thread T2 is created and a reference to object c is passed (Figure 4.2(a)). Since object c is
reachable by thread T2,c will be detected as a shared object when T2 is distributed and started
on node 2 (Figure 4.2(b)). Note that objecta andbremain local objects since they are only reached
by the local thread T1. Upon the first access to c by T2, object c will be requested from node
1. Because objectc has references tod and e, they become shared objects as well (Figure 4.2(c)).
Node 2 receives the GUIDs of d and e and a copy of c for which dangling pointers are installed
representing remote references to d and e. When T2 accesses object d in a later step, d will be
faulted-in from node 1 (Figure 4.2(d)). 4.4.4 States
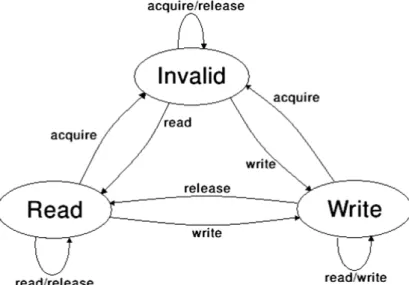
As seen in Section 4.2.1 shared objects can have some different states as shown in Figure 4.3. Non-home shared objects can become invalid after an acquire operation requiring the object the be faulted-in on further reads or writes. Since only modified non-home objects must be written back to their corresponding home node upon releasing a lock, we set a bit in the shared object’s header upon a write operation, which enables that only diffs from non-home shared object are computed
6E.g. A
T1 T2
a
b c
d e
(a) Initial object connectivity graph. T1 a b c d e s Node 1 Node 2 T2 (b) Distribution of T2. T1 a b Node 1 Node 2 c s e s d s T2 c' s (c) Fault-in of object c. T1 a b T2 Node 1 Node 2 c s e s d s c’ s d’ s (d) Fault-in of object d.
24 4. Design
that were actually changed. After the diffs have been propagated to the home nodes, the write bit is cleared.
Figure 4.3: Shared object states.
4.4.5 Conclusion
By combining the object heap of several JVMs, we form a single virtual heap that consists of our so-called Shared Object Space and a local heap. Shared objects are moved into the Shared Object Space when they are reachable from at least two threads on two different nodes. Node-local objects remain in the local heap. This separation of the heap is different from other approaches described in Chapter 3 where usually all objects are allocated in one global object heap only. The lazy detection scheme helps us to gain performance when dealing with memory consistency issues. As specified in the JMM, a Java thread’s working memory is invalidated upon a lock and the cached copies must be written back to main memory upon an unlock. In our context this means that these operations are triggered when a node-local object is acquired or released. Further, in our DJVM
we have to consider distributed memory consistency issues since changes to cached copies must be written back to their home nodes: When a shared object is locked or unlocked, these operations are much more expensive compared to their local counterparts. By sharing only objects that are currently accessed by a remote thread, we reduce the communication traffic of the distributed cache coherence protocol (see Section 5.3.4).
4.5
Distributed Classloading
The JikesRVM runtime system keeps track of all loaded types. If a type is loaded by the classloader, so-called meta-objects such asVM_Class,VM_Array,VM_Field,VM_Method, etc., describing classes, interfaces, fields and methods respectively, are created. Therefore, if classes are loaded into the JVM, the type information maintained by each cluster node is altered. For our DJVM we make
use of a centralized classloader (similar to [36]) that helps to achieve a consistent view of all loaded types on all nodes in the cluster by replicating these meta-objects to the worker nodes. Loading all classes on a centralized node simplifies the coordination but it also has the disadvantage of creating a bottleneck. But since classloading becomes less common during the runtime of a long running application, we believe that this should not effect the performance. If classes have been loaded once, they can be compiled and instantiated locally.
Since the JikesRVM is written in Java, a set of classes is needed for bootstrapping. These classes are written into the JikesRVM bootimage and are considered initialized and do not need to be loaded anymore. When the JikesRVM is booted, some additional types are loaded by a special bootstrap classloader to set up the JikesRVM runtime system. After booting, the VM types of the Java application will be loaded by the application classloader. In our DJVM, the cluster is set up
during boot time of the VM. Therefore, to achieve a consistent view on all cluster nodes, we must further divide the boot process into two different phases:
1. Before the cluster is set up, all types that must be loaded prior to a node can join the cluster. 2. After the cluster is set up, some additional types needed for the VM runtime system are
loaded.
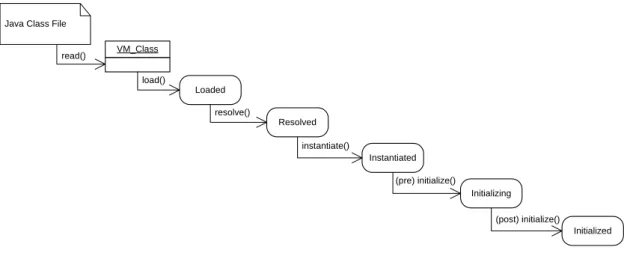
To achieve a consistent view of the type information on all cluster nodes before the cluster is set up, we add all classes into the bootimage prior to the cluster booting. Since only one thread is running during the boot process, we can guarantee consistent class definitions on all nodes at this point. After the cluster is setup, consistency is maintained by the centralized classloading mechanism described above. Loaded Resolved Instantiated Initializing VM_Class read() Initialized resolve() instantiate() (pre) initialize() (post) initialize() Java Class File
load()
Figure 4.4: Classloading states.
When a class, that is not located in the bootimage, is loaded, a Java .class file is read from the filesystem and a corresponding VM_Classobject in the VM is created and put into theloaded state
as shown in Figure 4.4. Resolution is the process where all (static) fields and methods of the class are resolved and linked against theVM_Classobject (stateresolved). After compiling all static and
26 4. Design
virtual methods, the object is considered to be instantiated. Initialization finally invokes the static
class initializer which is only done once per class. During initialization theVM_Classobject is put into theinitializing state, after the process has completed the state changes to initialized.
Because the JikesRVM stores all static variables in a special table, all classloading phases except instantiation must be done by the master node. The master node executes the classloading phase and replicates the resulting type information to the cluster nodes. The instantiation process can be done locally on any node since no entries are inserted into the static table. An exception exists for the initialization phase for classes that are considered as local per node only, such as runtime supporting classes (see Section 5.3.5). If such a class is initialized, the initialization is also done locally per node since the class is intended for internal management purposes and therefore not considered as global7
4.6
Scheduling
To gain performance in a cluster-aware JVM, threads from the Java application are distributed automatically to the nodes in the cluster. In ourDJVM we use a load balancing mechanism based
on theLinux Load Average[5] that is a time-dependent average of the CPU utilization. Particularly,
the averages of the last minute, 5 minutes and 10 minutes are shown by calling this command. Every worker node reports the Load Average of the last minute periodically to the master node, i.e. after a certain time period, a message containing the Load Average is sent to keep the CPU utilization up-to-date. Load balancing is achieved by distributing Java application threads to the node in the cluster with the lowest load. Upon the start of an application thread, the master node is contacted to get the ID of the cluster node with the lowest Load Average. The thread is then copied to the cluster node where the thread is finally started. The node, to which the thread is distributed, should become the new home node for that thread object due to access locality, i.e. if the node where the thread is distributed to is a non-home node of the thread object, upon every lock operation the thread object would become invalid due to memory consistency. As a consequence the thread object must be faulted-in from the home node of the thread object which is quite inefficient. Since our DJVM does currently not support object home migration (see Section
7.2.1), we introduced a mechanism to simulate object home migration for threads to avoid these access locality problems (described in Section 5.5.1). We follow an initial placement approach because it is lightweight and easier to implement compared with thread migration (see Section 7.2.3).
4.6.1 Synchronization
Even after Java threads have been distributed among nodes in the cluster in the DJVM (cf.
Section 4.6), they should still be able to communicate with each other through the synchronization
operations lock,unlock,wait andnotify across node boundaries. In our design that is based on the
HLRC protocol described in [32], each shared object is assigned a respective home node on which the synchronization operations are executed, i.e. if synchronization happens on a non-home shared object, a synchronization request is sent to the corresponding home node where the synchronization is finally processed. If the shared object is already located on its home node, the lock can be acquired locally without sending a request.
Due to our classloading concept where loaded classes are always replicated from the master node to its worker nodes, all objects of type Classare automatically considered shared, with the master node as their home node. Whenever a synchronization is executed on a Class object, the request is redirected to the master node because there is only one instance of aClass object.
4.7
I/O Redirection
As mentioned earlier, our DJVM is based on an SSI design even for I/O. To achieve this, all I/O
operations are redirected to the master node. As a consequence whenever the Java application opens a a file for example on a worker node, the file name will be forwarded to the master node where the file is actually opened. The file descriptor is returned to the worker node. If any read or write operations happen in a later stage, the worker node sends this file descriptor to the master node where the I/O operation is executed and the result is sent back to the requesting worker node. The redirections do also apply for the standard file descriptor meaning that the output of a System.out.println()in the Java application will always be displayed on the master node. With our approach, we avoid a global view of the filesystem such as NFS used in [17] so that each JVM instance on each cluster node sees the same file system hierarchy of the master node.
4.8
Garbage Collection
In this section, we give an algorithm for a garbage collector in our Shared Object Space. We describe a distributed Mark and Sweep garbage collector. Since Mark and Sweep does not involve copying objects in the heap, updates of object addresses in the distributed GUID table (cf. Section 5.3.2) are not needed. To add distribution to Mark and Sweep, we need to introduce three synchronization points.
1. If a node in the cluster runs out of memory, garbage collection is executed and a message should be sent to all nodes to force their garbage collectors to run (first synchronization point).
2. The mark phase starts on every node locally.
3. If there are any marked objects that are also marked as shared, a message must be sent back to the shared objects’ home nodes where the objects will also be marked (if not
al-28 4. Design
ready happened) because the shared objects are still reachable from a remote thread (second synchronization point)
4. After detecting every reachable object, the sweep phase can run locally on each cluster node. Garbage collected shared objects that have been inserted into the GUID table earlier should be removed from the table.
5. Since the sweep phase stops every thread in the system, the worker nodes report to the master node when they have finished the sweep phase. If all cluster nodes are done with sweeping, the master node sends a broadcast message to all worker nodes to inform them to continue execution (third synchronization point).
Steps 2 and 4 are from the usual Mark and Sweep garbage collector whereas steps 1, 3 and 5 are needed because of the distributed nature of the JVM. It should be mentioned that the second and the third synchronization points add an overhead since all threads must be kept suspended until the corresponding messages arrive. Note that a local garbage collector will not suffice since shared objects on the home node cannot be reclaimed if there are remote references to it on another cluster node.
Turning back a shared object on its home node to a node-local object should be done in step 4 when all non-home nodes have reported their remote references. If a shared object is marked as reachable during the mark phase but has no remote references pointing to it, the shared object can be removed safely from the Shared Object Space since the object is only reached by local threads (cf. definition in Section 4.4.1 and future work in Section 7.2.6).
This section gives some implementation details for the design decisions made for the DJVM as
described in Chapter 4.
5.1
Messaging Model
As explained in Section 4.3 the communication within the cluster is based on a message model. We have developed a set of messages that inherit from a common abstract superclass Message.
By introducing a class tree of different message types, the messaging model becomes flexible and extendible at the cost of some overhead because of additional method calls and conversions. The Message class provides some concrete implementation such as for getting the message’s type,
subtype or ID as described in Section 4.3.1. Furthermore, each message contains code for sending, processing and converting a message into bytes and vice versa:
• send: This concrete implementation gets a message buffer from the buffer pool and converts the message into a bytestream by calling the methodtoBytes. The message buffer containing the message’s data is then sent over the socket to the receiving node.
• toBytes: This method is abstract and a concrete class extending fromMessage must
imple-ment it. In this method the message’s data should be serialized into a bytestream that can finally be sent over the communication socket.
• dispatch: This static method is intended for message deserialization. TheMessage object is
constructed on the receiving side by decoding the bytestream from the sender. The resulting data are passed to a private constructor such that the message object can be created.
• process: After constructing the Message object on the receiver node, the message is finally
processed by the MessageDispatcher thread. This method is abstract and each subclass
defines the actual work that must be done upon receiving this message.
When a message is received, theMessageDispatcher thread calls the staticdispatchmethod of the
class Message where the header of the packet (cf. Table 4.1) is inspected to get the message type
and its subtype. E.g. the type could be MessageIO, also an abstract class from which all concrete
30 5. Implementation
messages extend that are related to I/O such asMessageIOChannelReadReq that contains code for
an I/O read operation request and therefore is declared as its subtype. The received bytestream is finally passed to the dispatch method of the concrete implementation so that theMessage object
is created and can be processed.
Some messages like I/O messages require the sending thread to block until the reply arrives. If a message needs an acknowledgement, the message ID combined with the destination’s node ID and the Message object is inserted into a message registry. The sending thread is forced to wait1 on
the Message object until the response is received. By processing the acknowledged message the MessageDispatcher thread removes the corresponding entry in the message registry and wakes up
the waiting thread such that it can resume its execution.
5.2
Boot Process
In this section, we briefly describe the modifications of the boot process of the JikesRVM, especially we explain how the cluster is set up.
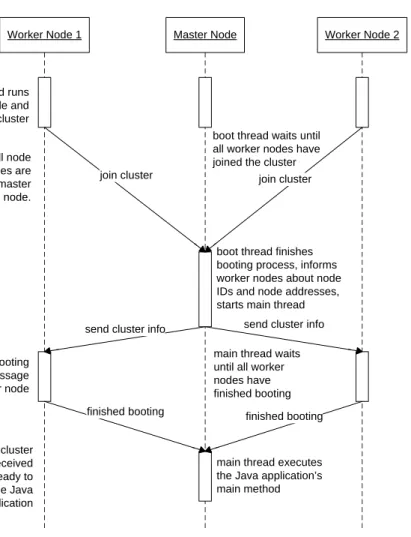
When the JikesRVM is launched, a single thread is started which is responsible for the bootstrap-ping. Since our cluster needs to be set up during boot time so that the centralized classloading is activated (cf. Section 4.5), the boot thread sets up the communication by instantiating the corresponding raw or TCP sockets and starting a MessageDispatcher thread (and a MessageCon-nectionListener thread if TCP is used). At this point the boot process of the master node and the
worker nodes become a bit different as Figure 5.1 shows. For the master node the following steps are executed:
1. Since the number of cluster nodes is static and given as a parameter at the start of the VM, the boot thread will wait until all worker nodes have established a connection to the master node and have reported their node ID and MAC / IP address.
2. The boot thread wakes up when all worker nodes made a successful connection to the mas-ter node and finishes booting the VM. This involves setting up all runtime support data structures.
3. When the VM is booted, the master node sends a message to the worker nodes telling them to finish their booting process. The message sent to the worker nodes contains all node IDs and their corresponding MAC / IP addresses.
4. Before the boot thread terminates, a VM_MainThreadis started to execute the main method of the Java application. For the DJVM, this main thread is blocked until the worker nodes
have done their bootstrapping.
boot thread waits until all node IDs