International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)83
Identification of Cross Cutting Concerns and Refactoring of
Object Oriented System Based on Aspect Mining
Dinesh V. Attarde
1, Ratnesh R. Gaikwad
2, Pankaj C. Jadhav
3, Vijayendra Bari
4Information Technology Department, University of Pune.
1
[email protected] 2[email protected] 3[email protected] 4[email protected]
Abstract—The process of Aspect Mining and Refactoring tries to indentify the cross-cutting concerns in the existing software system and refactoring if for a good AOP.
The aim of the paper is to analyze the techniques use for the evaluation of the cross-linking and making the system easier to maintain and evolve based on the clustering algorithms. Clustering is a technique of grouping the data based on similar objects.
We provide an initial assessment of how aspect oriented techniques and tool are used to identify the cross-cutting and refactoring the system on the basis of cross-linking, and also differ the aspect oriented system from the object oriented system by means of graphical techniques.
Keywords—[Aspect Oriented Programming, Aspect Mining, Refactoring, Clustering, kAM Algorithm]
I. INTRODUCTION
Aspect Oriented Programming (AOP) is a new programming paradigm that offers a novel modularization unit for the crosscutting concerns. Functionalities originally spread across several modules and tangled with each other can be factored out into a single, separate unit, called an aspect. Although AOP was originally proposed for the development of new software, systems written using traditional modularization techniques may also benefit from the adoption of the more versatile decomposition offered by AOP, in terms of code understandability and evolvability.
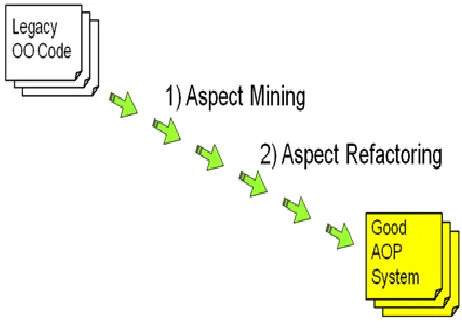
The goal of this paper is to investigate automated techniques that can be used to support the migration of existing Object Oriented Programming (OOP) code to AOP. To migrate an application to the new paradigm, a preliminary identification of the crosscutting concerns is required (aspect mining). Then refactoring is applied to transform the scattered concerns into aspects. The proposed methods have been assessed on case studies for a total of more than half a million lines of code.
[image:1.612.327.558.349.517.2]One of the proposed aspect mining method has also been compared with other state of the art methods.They all have been applied to a common case study and the results have been used to propose a brand new aspect mining technique, based on their combination.
Figure 1. Migration OOP code to AOP.
A. Clustering
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)84
In our approach, we have used the Euclidian distance:
(
)
(
) √∑
The similarity between two objects Oi and Oj is defined as
We have chosen Euclidian distance in our approach, because we have obtained better results, from the aspect mining point of view, than using other metrics.
B. Aspect Mining
Firstly, some definitions on aspect mining are provided.
Definition 1: Crosscutting concerns: the requirements that fail to be modularized in OO system; correspondingly, those are well encapsulated are regarded as the base concerns.
Definition 2: Crosscutting concern codes: the codes that implement the crosscutting concern; correspondingly, the codes that implement the base concern are base concern codes. In programs with good programming style, base concerns codes are well modularized. Crosscutting concerns codes are scattered across the modules of base concerns. But they are well modularized in each local module, too.
Definition 3: Aspect Mining: a reverse engineering process that aim to find out the potential crosscutting concerns from the existing OO program.
II. CLUSTERING ALGORITHM
A. K-means algorithm
One of the simplest exclusive clustering method is the kmeans clustering . The k-means algorithm partitions a collection of n objects into k distinct and non-empty clusters , data being grouped in an exclusive way (each object will belong to a single cluster).
The procedure follows a simple and easy way to classify a given data through a certain number of clusters (k), fixed a-priori.
The algorithm starts with k initial centroids, then iteratively recalculates the clusters (each object is assigned to the closest cluster - centroid), and their centroids until convergence is achieved.
The main disadvantages of k-means are:
• The performance of the algorithm depends on the initial centroids. So the algorithm gives no guarantee for an optimal solution.
• The user needs to specify the number of clusters in advance.
B. kAM algorithm
In order to avoid the two main disadvantages of the traditional k-means approach, we propose a new k-means based clustering algorithm, kAM (k-means in Aspect Mining), that uses an heuristic for choosing the number of clusters and the initial centroids. This heuristic is particular to aspect mining and it will provide a good enough choice of the initial centroids.
After selecting the initial centroids, kAM behaves like the classical k-means algorithm.
The main idea of kAM’s heuristic for choosing the initial centroids and the number k of clusters is the following: (i) The initial number k of clusters is n (the number of
methods from the system).
(ii) The method chosen as the first centroid is the most ―distant‖ method from the set of all methods (the method that maximizes the sum of distances from all other methods).
(iii) For each remaining methods (that were not chosen as centroids), we compute the minimum distance (dmin) from the method and the already chosen centroids. The next centroid is chosen as the method m that maximizes dmin and this distance is greater than a positive given threshold (distMin). If such a method does not exist it means that m is very close to its nearest centroid nc and should not be chosen as a new centroid (from the aspect mining point of view m and nc should belong to the same (crosscutting) concern). In this case, the number k of clusters will be decreased.
(iv) The step (iii) will be repeatedly performed, until k centroids will be reached.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)85
We mention that the algorithm stops when the clusters from two consecutive iterations remain unchanged, or the number of steps performed exceeds the maximum number of iterations allowed.
Remark
If the cluster is a set of methods
{
}
, we denote by the centroid (mean) of , defined as:(
∑
∑
)
III. IDENTIFICATION OF CROSSCUTTING CONCERNS
In order to identify crosscutting concerns we propose the following steps:
Step 1. Computation
Computation of the set of methods in the selected source code, and computation of the attribute set values, for each method in the set.
Step 2. Filtering
Methods belonging to some data structures classes like ArrayList, Vector are eliminated. We also eliminate the methods belonging to some built-in classes like String, StringBuffer, StringBuilder, etc.
Step 3. Grouping
The remaining set of methods is grouped into clusters using a clustering algorithm. The clusters are sorted by the average distance from the point 0l in descending order, where 0l is the l dimensional vector with each component 0.
Step 4. Analysis
The obtained clusters are analyzed to discover which clusters contain methods belonging to crosscutting concerns. We analyze the clusters whose distance from 0l point is greater than a given threshold (eg. two).
Algorithm: kAM Algorithm
Input:
The set M = { ,…, } of methods to be clustered
The metrix between methods in a multidimensional space
distMin > 0 the threshold for merging the clusters
noMaxIter the maximum number of iterations allowed
Output:
K = { ,…, } the partion of methods in M
Algorithm kAM is:
.k n // the initial numbers of cluster
{ ∑ ( )
}
// the index of the first centroid is chosen
.nr 1 // the number of centroid already chosen
Whilenr < k do
{ | { } { ( )} }
IfD= then
.k k-1 //the number f cluster is decreased
Else
. nr nr+1 // another centroid is chosen
{ { ( )}}
Endif
For j 1,k do
. // the centroids are initialized
Endfor
While ( K changes between two consecutive steps )and (there were not performed noMaxIter iteration)
Do
For j 1,k do
{ | ( ) ( )}
. the mean of objects in
// the j-th centroid is recalculated
Endfor Endwhile
IV. REFACTORING
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)86
A. Aspectizable interfaces
1) Refactoring process description :
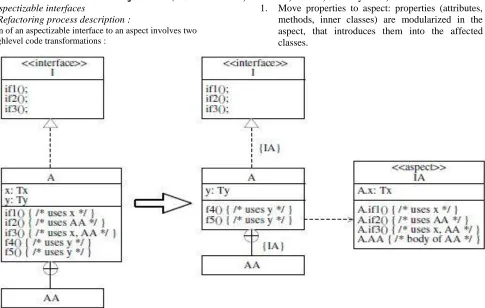
Migration of an aspectizable interface to an aspect involves two main, highlevelcode transformations :
[image:4.612.81.566.128.436.2]1. Move properties to aspect: properties (attributes, methods, inner classes) are modularized in the aspect, that introduces them into the affected classes.
Figure 2: Refactoring: Move interface implementation to aspect.
2. Remove references to properties: execution points referencing aspectized properties are moved into the aspect code (called advice code) triggered by the pointcuts.
In the case of the aspectizable interfaces, the first transformation is the most important one, since the methods in the interface implementations are seldom referenced by methods in the principal decomposition. Figure 2 shows the mechanics of the first refactoring. The overall transformation can be described in terms of three simpler refactoring steps, applied repeatedly:
Move method to aspect.
Move field to aspect.
Move inner class to aspect.
These three (atomic) refactorings consist of removing a method (resp. field or inner class) from a given class and adding it to an aspect, where it becomes an introduction.
In Figure 2, class A implements the interface I by defining the body of methods if1, if2, if3, the class field x is used only inside if1, if3,and the inner class AA is used only inside if2, if3. Moving the interface implementation to a new aspect IA consists of applying the three steps above respectively to if1, if2, if3, to x, and to AA.
The result (see Figure 2, right) is a thinner class A, with only 1 field (y) and two methods (f4, f5), which depends (dashed edge) on the aspect IA for the implementation of the interface I (see tag over the realization relationship). Inclusion of the inner class AA is also dependent on the new aspect IA (tag over nesting relationship).
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)87
When an interface migrated to an aspect is implemented by several classes in the system under analysis, additional advantages can be potentially obtained from the separation of the crosscutting concern represented by the interface. In fact, if the different implementations of the interface share some computations, it becomes possible to factor them out into a common super-aspect.
B. Code Smell
In computer programming, code smell is any symptom in the source code of a program that possibly indicates a deeper problem.
Often the deeper problem hinted by a code smell can be uncovered when the code is subjected to a short feedback cycle where it is refactored in small, controlled steps, and the resulting design is examined to see if there are any further code smells that indicate the need of more refactoring. From the point of view of a programmer charged with performing refactoring, code smells are heuristics to indicate when to refactor, and what specific refactoring techniques to use. Thus, a code smell is a driver for refactoring.
V. CONCLUSION
In this paper we have analyzed and evaluated the results obtained by kAM clustering algorithm for crosscutting concerns identification. If a clustering based algorithm succeeds in obtaining an optimal partition of a software system, then the results can be integrated with tools that (automatically) perform aspect oriented based refactorings, as a first step to refactoring.
References
[1]. Grigoreta Sofia Cojocar, Gabriela (Serban) Czibula. On Clustering based Aspect Mining. IEEE 2008
[2]. G. Serban and G. S. Moldovan. A New k-means Based Clustering Algorithm in Aspect Mining. In Proceedings of 8th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC’06), pages 69–74, Timisoara, Romania, September, 26-29 2006. IEEE Computer Society.
[3]. http://en.wikipedia.org/wiki/Code_smell.html
[4]. G. Serban and G. S. Moldovan. Aspect Mining using an Evolutionary Approach. WSEAS Transactions on Computers, 6(2):298–305, 2007.
[5]. J. Han and M. Kamber. Data Mining: Concepts and techniques. Morgan Kaufmann Publishers, 2001.
[6]. S. Breu and J. Krinke. Aspect Mining Using Event Traces. In Proc. International Conference on Automated Software Engineering (ASE), pages 310–315, 2004.