A Text Classification Algorithm Based on PCA
Jian-lin LI
1,2,a*1Nanjing College of Information Technology Nanjing, Jiangsu, 210023, China
2 University of Regina, Regina S4S0A2, Canada
*Corresponding author
Keywords: PCA-MCFEA, Feature extraction, Text classification.
Abstract. Study the related WEB text feature extraction algorithm, through the mutual information (MI), document frequency (DF), information gain (IG) andχ2 statistics (CHI) algorithm research, using of their respective advantage complementary, proposed a multiple combination feature extraction algorithm based on principal component analysis (PCA-MCFEA). First, by the orthogonal transformation of the PCA algorithm to faster dimensionality reduction of the text feature space; Then through the multiple combination feature extraction algorithm in the lower dimension of feature space fast extract more representative of the feature, filter out some representative weak feature items; Finally, using the SVM classifier to classify the text. The experimental results show that PCA-MCFEA algorithm can effectively improve text classification accuracy and running efficiency.
Introduction
At present, the text feature extraction is mainly on the basis of the characteristics of the document matrix using some feature evaluation to assess the function of each feature words, by setting the threshold to retain a certain number of characteristics, existing feature selection function was document frequency (DF), mutual information (MI), information gain (IG) and χ2 statistics (CHI) etc. But these feature extraction algorithms are on the assumption that feature items independent premise, and each algorithm, the focus is different, the document frequency(DF) emphasized the impact of high-frequency words for text classification, although the literature[1]ontology associated with the degree of improvement feature words extracted TF-IDF method, but the quality of the experimental results and the choice of domain ontology is
concerned, such as ontology concept subdivision level, covering degree, ontology
construction mature degree, the formula for calculating the correlation parameter selection and threshold Settings will be set for the construction of ontology correlative impact, then affects the text classification accuracy; Mutual information(MI) feature selection tend to rare words to text classification effect, literature[1] through introducing disturbance factor, improved the MI method, so at the dimension reduction and classification performance all obtained a good effect, but to a low dimensional data processing are not satisfactory; χ2statistics(CHI) is assumed between categories and entry satisfiesχ2 distribution, χ2 statistic of the higher the value, between the entry and text category of the relationship the more strong, the text categories classification of the contribution the more bigger[2], the application premise hypothesis will naturally cause part of the loss of the information classification, influence text classification results. According to the limitation of the above methods, this paper puts forward a multiple combination feature extraction algorithm based on principal component analysis(PCA-MCFEA),using PCA method
2017 2nd International Conference on Computer Science and Technology (CST 2017)
to take into consideration the characteristics of the relationship between the item, change the characteristics of the original document matrix to low dimensional orthogonal feature matrix, the matrix compose of the original document matrix principal component, it retained the original feature matrix of the most feature information, and to ensure the new features are not related to each other, and not loss of useful information by reasons of delete a feature, so can get best describes characteristics of the text. Use the improved respectively to document frequency (DF), the mutual information (MI), information gain(IG) and χ2statistics(CHI) method combined feature extraction based on the PCA dimensionality reduction, overcome the use of single feature extraction of defect to achieve better classification characteristics, the experimental results show that by use of the PCA-MCEFA extraction method to improve the feature word text classification accuracy and efficiency are effective.
Key Technology of Text Classification Principal Component Analysis (PCA)
PCA is a very classical multivariate data analysis tool, it can make the multiple variable into a few comprehensive items, it is a kind of very good data dimension reduction processing technology. Suppose there are N data samples, each sample is expressed with n observed variables x1,x2,…,xn, we can get a sample of the data matrix:
1 1 1
1
... ... ... ...
n
N N n
x x
x x
(1)
A comprehensive item fory1,y2,…,ym, they are a linear combination of the observation variablesx1,x2,…,xn, namely:
1 1 1 1 2 1 2 n 1 n
m 1 m 1 2 m 2 n m n
y a x a x a x
...
y a x a x a x
= + + … + …
= + + … +
m≤n (2)
Among them, aij coefficient by the following principles decision: (1) any two of the comprehensive item not related;
(2) y1is with the biggest variance of the Linear combination ofx1,x2,…,xn,
y2,y3,…,ymin turn reduce;
y1,y2,…,ym respectively called the first, second,…,m principal component of
thex1,x2,…,xn. They can be regarded as a set of new features, they retained the
original feature set as many characteristic information; According to the mathematical theory, the coefficient a is m characteristic value of the corresponding feature vector of covariance matrix of x1,x2,…xn.
Multiple Combination Feature Extraction Algorithm based on Principal Component Analysis (PCA-MCFEA)
According to literature [1-6], that the mutual information (MI), document frequency
(TF-IDF), χ2statistics (CHI) and information gain(IG) and other single feature
through the appropriate combination application to have complementary advantages, improve the text classification accuracy.
The PCA method dimensionality reduction to retain as many of the characteristics of the amount of information in the original features set, and comprehensive vector are linearly independent; At the same time, the development of computer algorithms for PCA method has been very prefect, can greatly improve the speed and accuracy of the calculation, it has inherent advantages on the characteristics of the amount of data reduced for support vector machine classification.
Therefore, the comprehensive utilization of mutual information (MI), document frequency (TF-IDF), χ2statistical (CHI) and Information Gain(IG) feature extraction advantages, proposed a multiple combination feature extraction algorithm based on principal component analysis (PCA-MCFEA) to accelerate the computational speed of the training text, improve the accuracy and efficiency of the implementation of the text classification.
PCA-MCFEA Algorithm Description
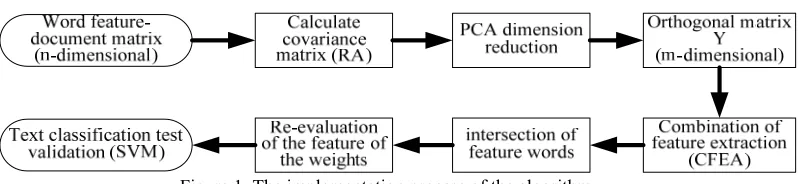
[image:3.612.112.511.304.396.2]The implementation process of the algorithm shown in figure 1,
Figure 1. The implementation process of the algorithm.
The implementation process of the algorithm steps is described as follows:
(1) Prepare the data; The corpus is divided into training set and test set. Assume
that the training set of document number for N, set to x1,x2,…xN,. We select n
keywords a1,a2,…an as document feature, can build a word feature-document
matrix A:
1 1 1
1 2
1 ... [ , , ..., ] ... ... ...
... n N T
N N n
a a
A x x x
a a
= =
Among them, a row of the matrix represents a document feature vector, a list of matrices represents the frequency of the appeal of a feature word in the document.
(2) Calculate the feature values of the covariance matrix RA=ATA:
1 2 ... n 0
λ ≥ λ ≥ ≥λ ≥ , and the corresponding feature vector: e1,e2,…,en.
(3) Choose PCA transform orthogonal space dimension m, m≤n,generally speaking:
/ 1 1
m n
T
i j
i= λ j= λ ≥ , T is a threshold value that represents the amount of information
reserved, in information theory it general equal to 0.85, because people think the loss 15% of the information is acceptable (by strengthening the threshold T can keep more of the original information, can obtain higher text classification accuracy, but need more time to calculate).
(4) Select the orthogonal eigenvectors that corresponding to the m maximum eigenvalue in RA, e1,e2,…,em, formed the best transformation matrix WKL=
(5) Use transfer matrix WKL can turn n-dimensional original words-document space
into m-dimensional orthogonal feature space, Y=(WAT)T=AWT, Y is an n ×
m-dimensional matrix, the lower dimension of the matrix Y (m ≦ n), due to the sparse matrix A ,under normal circumstances m << n, and Y is an orthogonal matrix, it can retain more characteristic information.
(6) Feature words Extraction: using the mutual information(MI), document frequency(TF-IDF), χ2 statistics (CHI), information gain (IG) calculated the weight of each word in the orthogonal matrix Y after dimensionality reduction; Each method calculated weights of the every words and sorted by weight, obtain four array;
①taken T+t(assumed to take T feature words)feature words from front of the weight
array, and calculate the intersection of four arrays, the number of intersection is K.
②if K=T, turn ③;if K<T,t=t+1 turn ①;if K>T,t=t-1 turn ①.
③finish.
(7) Use of the improved TF-IDF re-evaluated the weight on the rest of the T feature words, this weight values as the final weight of the feature words that composition of this word characteristics-document matrix (N×T matrix) of the training sample.
(8) By the above combination of feature extraction algorithm, feature items and corresponding data take into the SVM classifier for classification training and testing.
Experimental Results and Analysis
Using the Chinese academy of sciences institute of Chinese natural language processing and open platform to provide the corpus to experiment, the choice of politics, economy, and military, cultural, industrial, computer and so on six kinds of text, a total of 2000 articles. We were used to the mutual information (MI), document frequency (TF-IDF), χ2 statistics (CHI), information gain (IG) and the proposed PCA-MCFEA feature extraction methods to select the 1500 article as a training text, the rest of the 500 articles as test text carries on the experiment, the support vector machine (SVM) classifier for the experimental validation.
The experimental procedure is as follows:
1) Extracted the feature word from 1500 training text ,total of 12013, so the establishment of the word feature - document matrix of M1500 x 12013. Using PCA transform to training set words feature-document matrix dimension reduction, transformation of the m=350, the threshold value T=0.9502, m=250, the threshold value T=0.8613, we let m=350, after the PCA transform we can get a 1500×350 orthogonal matrix Y, it is able to retain more than 95% of the original information.
2) Respectively, using the mutual information (MI), document frequency (TF-IDF), χ2 statistics (CHI), information gain (IG) method calculated the weight of the each word of the dimensionality reduction of the orthogonal matrix Y; Each method calculated weights of the every words and sorted by weight, obtain four array;
3) Take 50 feature words (can choose more to retain more feature information), and calculate the intersection of the four array.
4) Use of the improved TF-IDF re-evaluated the weight on the rest of the 50 feature words, this weight values as the final weight of the feature words that composition of this word characteristics-document matrix(1500×50 matrix) of the training sample.
5) By the above combination of feature extraction algorithm feature items and corresponding data take into the SVM classifier for classification training and testing.
paper discussed using the single feature extraction with SVM classifier and using the proposed PCA-MCFEA feature extraction with SVM classifier, comparing the calculation time and the final classification results,the experimental results are given in Table 1, table 2 shows:
Table 1. Popular feature extraction method+SVM classification results.
Feature extraction method
Feature extraction method +SVM
Classification accuracy (%) Train time(S) Test time(S) total time(S)
MI 149 31 180 63.5
DF 1048 92 1140 87.3
CHI 405 48 453 85.2
IG 1392 159 1551 86.1
First, use of the popular text classification feature extraction, then using SVM classifier training and classification, because the original word feature-document matrix dimension higher, classification of the training and testing time minimum MI also takes 180 seconds, CHI requires 453 seconds, DF requires 1140 seconds; the best classification accuracy rate is 87.3%, due to the number of test samples is not too much, basically be acceptable, but with the increase of sample data, the feature extraction using SVM classifier training and testing time will suddenly increase.
Table 2. PCA-MCFEA + SVM classification results.
PCA dimensionality reduction time
Combination of feature extraction time-consuming(S)
SVM
Total
time(S) Classification accuracy (%) Train
time(S) time(S) Test
53 42 43 27 166 93.6
Using of PCA-MCFEA+SVM classifier for training and classification, although the original word feature-document matrix A has higher dimension, However, due to the sparsity of the matrix A, after PCA in keep more than 95% under the premise of information for dimension reduction after transformation to get a lower dimension of orthogonal matrix Y, then the efficiency of extraction of various features on a lower-dimensional orthogonal matrix improved a lot, even with all four feature extraction and seeking the feature words intersection of the sum of the time is only 166 seconds, much lower than the single feature extraction using SVM classifier training and classification time, at the same time, the Classification accuracy is 93.6%, has also been greatly improved.
Conclusions
At present, although there have been many compared to the classical algorithm of text classification, some scholars also to these classic algorithm to improve the appropriate and optimal[3-6].However, most of the classification system are limited to the application of a particular classification algorithm or its improved algorithm, which makes the classification performance of the system by the deficiencies of algorithm constraints.
[image:5.612.139.473.345.396.2]improve the speed of the system operator to obtain a higher classification accuracy.
Acknowledgement
In this paper, the research was sponsored by the year 2016 "Blue Project" of Jiangsu Province young academic leaders (ProjectNo.Jiangsu Education 2016-15).
Reference
[1] Jianmin Xu, Jinhua Wang, Weiyu Ma. Ontology associated with the degree of improvement and TF-IDF feature words extraction method[J], Information Science, 2011 (2) :279-283.
[2] Jian Li, Weiming Zhang. Mutual information-based text feature selection methods for improvement[J], Computer Engineering and Applications,2008,44 (10) :135-137.
[3] MUtiyama and H Isahara. Large-scale text categorization(in Japanese) [C]. 9th Annual Meeting of the Association (Japan)for Natural Language Processing, 2003, 385-388.
[4] Hong Shen, BaoliangLu.Text classification feature extraction method comparison and improvement [J], Computer Simulation, 2006 (3) :222-224
[5] Tao Kang, a PCA and RS-based text feature extraction method[J], Computer Applications, 2007 (10) :88-90