A Boosting-based Algorithm for Classification of Semi-Structured Text
using Frequency of Substructures
Tomoya Iwakura Fujitsu Laboratories Ltd
Abstract
Research in text classification currently fo-cuses on challenging tasks such as sen-timent classification, modality identifica-tion, and so on. In these tasks, approaches that use a structural representation, like a tree, have shown better performance rather than a bag-of-words representation. In this paper, we propose a boosting algorithm for classifying a text that is a set of sentences represented by tree. The algorithm learns rules represented by subtrees with their frequency information. Existing boosting-based algorithms use subtrees as features without considering their frequency be-cause the existing algorithms targeted a sentence rather than a text. In contrast, our algorithm learns how the occurrence frequency of each subtree is important for classification. Experiments on topic iden-tification of Japanese news articles and En-glish sentiment classification shows the ef-fectiveness of subtree features with their frequency.
1 Introduction
Text classification is used to classify texts such as news articles, E-mails, social media posts, and so on. A number of machine learning algorithms have been applied to text classification success-fully. Text classification handles not only tasks to identify topics, such as politics, finance, sports or entertainment, but also challenging tasks such as categorization of customer E-mails and reviews by types of claims, subjectivity or sentiment (Wiebe, 2000; Banea et al., 2010; Bandyopadhyay and Okumura, 2011). To identify difficult categories on challenging tasks, a traditional bag-of-words representation may not be sufficient. Therefore, a richer, structural representation is used rather
than the traditional bag-of-words. A straightfor-ward way to extend the traditional bag-of-words representation is to heuristically add new types of features such as fixed-length n-grams such as word bi-gram or tri-gram, or fixed-length syntac-tic relations. Instead of such approaches, learn-ing algorithms that handle semi-structured data have become increasingly popular (Kudo and Mat-sumoto, 2004; Kudo et al., 2005; Ifrim et al., 2008; Okanohara and Tsujii, 2009). This is due to the fact that these algorithms can learn better substructures for each task from semi-structured texts annotated with parts-of-speech, base-phrase information or syntactic relations.
Among such learning algorithms, boosting-based algorithms have the following advantages: Boosting-based learning algorithms have been ap-plied to Natural Language Processing problems successfully, including text classification (Kudo and Matsumoto, 2004), English syntactic chunk-ing (Kudo et al., 2005), zero-anaphora resolution (Iida et al., 2006), and so on. Furthermore, clas-sifiers trained with boosting-based learners have shown faster classification speed (Kudo and Mat-sumoto, 2004) than Support Vector Machines with a tree kernel (Collins and Duffy, 2002).
However, existing boosting-based algorithms for semi-structured data, boosting algorithms for classification (Kudo and Matsumoto, 2004) and for ranking (Kudo et al., 2005), have the follow-ing point that can be improved. The weak learn-ers used in these algorithms learn classifilearn-ers which do not consider frequency of substructures. This is because these algorithms targeted a sentence as their input rather than a document or text consist-ing of two or more sentences. Therefore, even if crucial substructures appear several times in their target texts, these algorithms cannot reflect such frequency. For example, on sentiment classifica-tion, different types of negative expressions may be preferred to a positive expression which
pears several times. As a result, it may happen that a positive text using the same positive expres-sion several times with some types of negative ex-pressions is classified as a negative text because consideration of frequency is lacking.
This paper proposes a boosting-based algorithm for semi-structured data that considers the occur-rence frequency of substructures. To simplify the problem, we first assume that a text to be classified is represented as a set of sentences represented by labeled ordered trees (Abe et al., 2002). Word se-quence, base-phrase annotation, dependency tree and an XML document can be modeled as a la-beled ordered tree. Experiments on topic identifi-cation of news articles and sentiment classifiidentifi-cation confirm the effectiveness of subtree features with their frequency.
2 Related Works
Prior boosting-based algorithms for semi-structured data, such as boosting algorithms for classification (Kudo and Matsumoto, 2004) and for ranking (Kudo et al., 2005), learns classifiers which do not consider frequency of substructures. Ifrim et. al (Ifrim et al., 2008) proposed a logistic regression model with variable-length N-gram features. The logistic regression learns the weights of N-gram features. Compared with these two algorithms, our algorithm learns frequency thresholds to consider occurrence frequency of each subtree.
Okanohara and Tsujii (Okanohara and Tsujii, 2009) proposed a document classification method using all substrings as features. The method uses Suffix arraies (Manber and Myers, 1990) for effi-ciently using all substrings. Therefore, the trees used in our method are not handled. Their method uses feature types of N-grams features, such as term frequency, inverted document frequency, and so on, in a logistic regression. In contrast, our al-gorithm differs in the learning of a threshold for feature values. Tree kernel (Collins and Duffy, 2002; Kashima and Koyanagi, 2002) implicitly maps the example represented in a labeled or-dered tree into all subtree spaces, and Tree kernel can consider the frequency of subtrees. However, as discussed in the paper (Kudo and Matsumoto, 2004), when Tree kernel is applied to sparse data, kernel dot products between similar instances be-come much larger than those between different in-stances. As a result, this sometimes leads to over-fitting in training. In contrast, our boosting
algo-rithm considers the frequency of subtrees by learn-ing the frequency thresholds of subtrees. There-fore, we think the problems caused by Tree ker-nel do not tend to take place because of the dif-ference presented in the boosting algorithm (Kudo and Matsumoto, 2004).
3 A Boosting-based Learning Algorithm for Classifying Trees
3.1 Preliminaries
We describe the problem treated by our boosting-based learner as follows. LetX be all labeled or-dered trees, or simply trees, andY be a set of la-bels {−1,+1}. A labeled ordered tree is a tree where each node is associated with a label. Each node is also ordered among its siblings. Therefore, there are a first child, second child, third child, and so on (Abe et al., 2002).
Let S be a set of training samples {(x1, y1), ...,(xm, ym)}, where each
exam-plexi ∈ X is a set of labeled ordered trees, and
yi ∈ Yis a class label.
The goal is to induce a mapping
F :X → Y fromS.
Then, we define subtrees (Abe et al., 2002).
Definition 1 Subtree
Letuandtbe labeled ordered trees. We callta subtree ofu, if there exists a one-to-one mapping
φbetween nodes in t tou, satisfying the condi-tions: (1) φ preserves the parent relation, (2) φ
preserves the sibling relation, and (3)φpreserves the labels. We denotetas a subtree ofuas
t⊆u.
If a treetis not a sbutree ofu, we denote it as
t⊈u.
We define the frequency of the subtreetinuas the number of timestoccurs inuand denoted as
|t⊆u|.
The number of nodes in a tree t is referred as the size of the treetand denote it as
|t|.
Figure 1: A labeled ordered tree and its subtrees.
the tree in the left side. For example, the size of the subtree⃝-a ⃝b (i.e. |⃝-a ⃝|) is 2 and the frequencyb |⃝-a ⃝ ∈b u|is also 2. For the subtree⃝-a ⃝, thec size|⃝a-⃝|c is also 2, however, the frequency|⃝a
-c
⃝ ∈u|is 1.
3.2 A Classifier for Trees with the Occurrence Frequency of a Subtree
We define a classifier for trees - that is used as weak hypothesis in this paper. A boosting algo-rithm for classifying trees uses subtree-based de-cision stumps, and each dede-cision stump learned by the boosting algorithm classifies trees whether a tree is a subtree of trees to be classified or not (Kudo and Matsumoto, 2004). To consider the fre-quency of a subtree, we define the following deci-sion stump.
Definition 2 Classifier for trees
Let t and u be trees, z be a positive integer, called frequency threshold, andaandbbe a real number, called a confidence value, then a classi-fier for trees is defined as
h⟨t,z,a,b⟩(u) =
a t⊆u∧z≤ |t⊆u| −a t⊆u∧ |t⊆u|< z b otherwise
.
Each decision stump has a subtree t and its fre-quency thresholdzas a condition of classification, and two scores,aandb. Iftis a subtree ofu(i.e. t ⊆ u), and the frequency of the subtree|t ⊆u| is greater than or equal to the frequency threshold z, the scoreais assigned to the tree. Ifusatisfies t ⊆ uand|t ⊆ u|is less than z, the score -ais assigned to the tree. Iftis not a subtree ofu(i.e. t⊈u), the scorebis assigned to the tree.
This classifier is an extension of decision trees learned by learning algorithms like C4.5 (Quin-lan, 1993) for classifying trees. For example, C4.5 learns the thresholds for features that have contin-uous values, and C4.5 uses the thresholds for clas-sifying samples including continuous values. In a similar way, each decision stump for trees uses a frequency threshold for classifying samples with a frequency of a subtree.
3.3 A Boosting-based Rule Learning for Classifying Trees
To induce accurate classifiers, a boosting algo-rithm is applied. Boosting is a method to create a final hypothesis by repeatedly generating a weak hypothesis in each training iteration with a given weak learner. These weak hypotheses are com-bined as the final hypothesis. We use real Ad-aBoost used in BoosTexter (Schapire and Singer, 2000) since real AdaBoost-based text classifiers show better performance than other algorithms, such as discrete AdaBoost (Freund and Schapire, 1997).
Our boosting-based learner selects R types of rules for creating a final hypothesisF on several training iterations. TheFis defined as
F(u) =sign(∑Rr=1h⟨tr,zrar,br⟩(u)). We use a learning algorithm that learns a subtree and its frequency threshold as a rule from given training samplesS = {(xi, yi)}mi=1 and weights
over samples {wr,1, ..., wr,m} as a weak learner.
By training the learning algorithm R times with different weights of samples, we obtainRtypes of rules.
wr,i is the weight of sample numberiafter
se-lectingr −1 types of rules, where 0<wr,i, 1 ≤
i≤mand1≤r≤R. We setw1,ito1/m.
Let Wr⟨y,≤,z⟩(t) be the sum of the weights of samples that satisfy t ⊆ xi (1 ≤ i ≤ m), z ≤
|t⊆xi|andyi =y(y∈ {±1}),
Wr⟨y,≤,z⟩(t) =
∑
i∈{i′|t⊆xi′}
wr,i[[C≤(xi,t, y, z)]],
where[[C≤(x,t, y, z)]]is
[[yi=y∧z≤ |t⊆x|]]
and[[π]] is 1 if a proposition π holds and 0 oth-erwise. Similarly, let Wr⟨y,<,z⟩(t) be the sum
of the weights of samples that satisfy t ⊆ xi,
|t⊆xi|< zandyi =y,
Wr⟨y,<,z⟩(t) = ∑
i∈{i′|t⊆xi′}
[[C≤(xi,t, y, z)]],
where[[C<(x,t, y, z)]]is
[[yi=y∧ |t⊆x|< z]].
Wr⟨y,z⟩(t) is the sum of Wr⟨y,≤,z⟩(t) and
Wr⟨−y,<,z⟩(t),
Wr⟨y,z⟩(t) =Wr⟨y,≤,z⟩(t) +Wr⟨−y,<,z⟩(t).
rightmost-Table 1: Statistics of Mainichi Shimbun data set. #P, #N and #W relate to the number of positive samples, the number of negative samples, and the number of distinct words, respectively.
Mainichi Shimbun
Category Training Development Test
#P #N #W #P #N #W #P #N #W
business 4,782 18,790 67,452 597 2,348 29,023 597 2,348 29,372 entertainment 938 22,632 67,682 117 2,829 29,330 117 2,829 28,939 international 4,693 18,879 67,705 586 2,359 28,534 586 2,359 29,315 sports 12,687 10,884 67,592 1,586 1,360 28,658 1,585 1,360 29,024 technology 473 23,097 67,516 59 2,887 29,337 59 2,887 28,571
Table 2: Statistics of Amazon data set. #N, #P and #W relate to the number of negative reviews, the number of positive reviews, and the number of distinct words, respectively.
Amazon review data
Category Training Development Test
#N #P #W #N #P #W #N #P #W
books 357,319 2,324,575 1,327,312 44,664 290,571 496,453 44,664 290,571 496,412 dvd 52,674 352,213 446,628 6,584 44,026 157,495 6,584 44,026 155,468 electronics 12,047 40,584 85,543 1,506 5,073 26,945 1,505 5,073 26,914 music 35,050 423,654 571,399 4,381 52,956 180,213 4,381 52,956 179,787 video 13,479 88,189 161,920 1,685 11,023 61,379 1,684 11,023 61,958
would not finish. Table 2 shows the statistics of the Amazon data set. Each training data is 80% of samples in all.review of each cate-gory, and test and development data are 10%. Parameters are decided in terms of F-measure on negative reviews of the development data, and we evaluate F-measure obtained with the decided parameters. The number of positive reviews in the data set is much larger than negative reviews. Therefore, we evaluated the F-measure of the negative reviews.
To represent a set of sentences represented by labeled ordered trees, we use a single tree created by connecting the sentences with the root node of the single tree.
5 Experiments
5.1 Experimental Results
To evaluate our classifier, we compare our learn-ing algorithm with an algorithm that does not learn frequency thresholds. For experiments on Mainichi Shimbun, the following two data repre-sentations are used: Bag Of Words (BOW) (i.e. ζ = 1), and trees (Tree). For the representations of texts of Amazon data set, BOW and N-gram are used. The parameters,R andζ, areR = 10,000 andζ ={2,3,4,5}.
Table 3 and Table 4 show the experimental re-sults on the Mainichi Shimbun and on the Ama-zon data set. +FQ suggests the algorithms learn
frequency thresholds, and -FQ suggests the algo-rithms do not. A McNemars paired test is em-ployed on the labeling disagreements. If there is a statistical difference (p < 0.01) between a boost-ing (+FQ) and a boostboost-ing (-FQ) with the same feature representation, better results are asterisked (∗).
The experimental results showed that classifiers that consider frequency of subtrees attained bet-ter performance. For example, Tree(+FQ) showed better accuracy than Tree(-FQ) on three categories on the Mainichi Shimbun data set. Compared with BOW(+FQ), Tree(+FQ) also showed better perfor-mance on four categories.
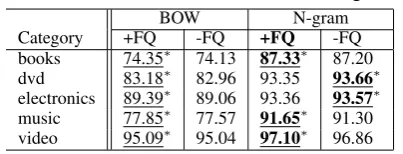
On the Amazon data set, N-gram(+FQ) also had better performance than BOW and N-gram(-FQ). N-gram(+FQ) performed better performances than BOW on all five categories, while performing bet-ter than N-gram(-FQ) on four categories. These results show that our proposed methods con-tributed to improved accuracy.
5.2 Examples of Learned Rules
Table 3: Experimental Results of the training on the Mainichi Shinbun. Results in bold show the best accuracy, and while an underline means the accuracy of a boosting is better than the booting al-gorithm with the same feature representation (e.g. Tree(-FQ) for Tree(+FQ)) on each category.
BOW Tree
Category +FQ -FQ +FQ -FQ
business 88.79 88.87∗ 91.45∗ 90.89 entertaiment 95.07∗ 94.27 95.11∗ 94.64 international 85.25 85.99∗ 87.91 88.28∗ sports 98.17 98.52∗ 98.70∗ 98.64 technology 83.02∗ 78.50 79.21 80.77∗ Table 4: Experimental Results of the training on the Amazon data set. The meaning of results in bold and each underline are the same as Figure 3.
BOW N-gram
Category +FQ -FQ +FQ -FQ
books 74.35∗ 74.13 87.33∗ 87.20 dvd 83.18∗ 82.96 93.35 93.66∗ electronics 89.39∗ 89.06 93.36 93.57∗ music 77.85∗ 77.57 91.65∗ 91.30 video 95.09∗ 95.04 97.10∗ 96.86
more than once, was learned. Generally, “I won’t read” seems to be used in negative reviews. How-ever, reviews in training data include “I wont’ read” more than once is positive reviews. In a similar way, “some useful” and “some good” with <2, which means less than 2 times, were learned for classifying as negative. These two expression can be used in both meanings like “some good ideas in the book.” or “... some good ideas, but for ... ”. The learner seems to judge only one time occurrences as a clue for classifying texts as nega-tive.
6 Conclusion
We have proposed a boosting algorithm that learns rules represented by subtrees with their frequency information. Our algorithm learns how the occur-rence frequency of each subtree in texts is impor-tant for classification. Experiments with the tasks of sentiment classification and topic identification of new articles showed the effectiveness of subtree features with their frequency.
References
Kenji Abe, Shinji Kawasoe, Tatsuya Asai, Hiroki Arimura, and Setsuo Arikawa. 2002. Optimized substructure discovery for semi-structured data. In
PKDD’02, pages 1–14.
Sivaji Bandyopadhyay and Manabu Okumura, editors. 2011. Sentiment Analysis where AI meets
Psychol-ogy. Asian Federation of Natural Language Process-ing, Chiang Mai, Thailand, November.
Carmen Banea, Rada Mihalcea, and Janyce Wiebe. 2010. Multilingual subjectivity: are more languages better? InProc. of COLING ’10, pages 28–36.
John Blitzer, Mark Dredze, and Fernando Pereira. 2007. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classi-fication. InProc. of ACL’07, pages 440–447.
Michael Collins and Nigel Duffy. 2002. New rank-ing algorithms for parsrank-ing and taggrank-ing: Kernels over discrete structures, and the voted perceptron. In
Proc. of ACL’02, pages 263–270.
Michael Collins and Terry Koo. 2005. Discriminative reranking for natural language parsing. Computa-tional Linguistics, 31(1):25–70.
Yoav Freund and Robert E. Schapire. 1997. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of computer and system sciences 55(1).
Georgiana Ifrim, G¨okhan Bakir, and Gerhard Weikum. 2008. Fast logistic regression for text categorization with variable-length n-grams. InProc. of KDD’08, pages 354–362.
Ryu Iida, Kentaro Inui, and Yuji Matsumoto. 2006. Exploiting syntactic patterns as clues in zero-anaphora resolution. InProc. of Meeting of Asso-ciation for Computational Linguistics.
Hisashi Kashima and Teruo Koyanagi. 2002. Kernels for semi-structured data. In ICML’02, pages 291– 298.
Taku Kudo and Yuji Matsumoto. 2002. Japanese dependency analysis using cascaded chunking. In
Proc. of CoNLL’02, pages 1–7.
Taku Kudo and Yuji Matsumoto. 2004. A boosting algorithm for classification of semi-structured text. InProc. of EMNLP’04, pages 301–308, July.
Taku Kudo, Jun Suzuki, and Hideki Isozaki. 2005. Boosting-based parse reranking with subtree fea-tures. InProc. of ACL’05, pages 189–196.
Udi Manber and Gene Myers. 1990. Suffix arrays: a new method for on-line string searches. In Proceed-ings of the first annual ACM-SIAM symposium on Discrete algorithms, SODA ’90, pages 319–327.
Daisuke Okanohara and Jun’ichi Tsujii. 2009. Text categorization with all substring features. InSDM, pages 838–846.
J. R. Quinlan. 1993. C4.5: Programs for Machine Learning. Morgan Kaufmann.
Robert E. Schapire and Yoram Singer. 2000. Boostex-ter: A boosting-based system for text categorization.
Janyce Wiebe. 2000. Learning subjective adjectives from corpora. In Proceedings of the Seventeenth National Conference on Artificial Intelligence and Twelfth Conference on Innovative Applications of Artificial Intelligence, pages 735–740. AAAI Press.