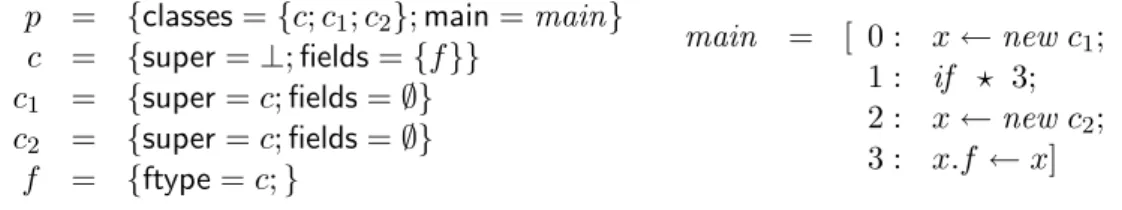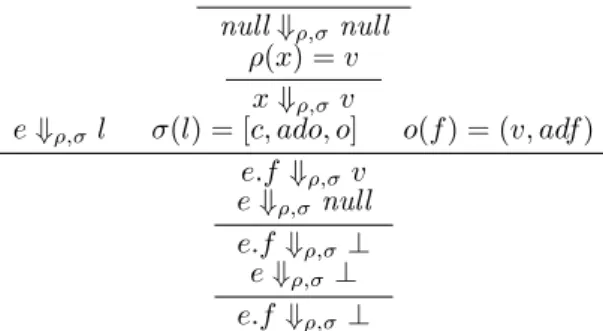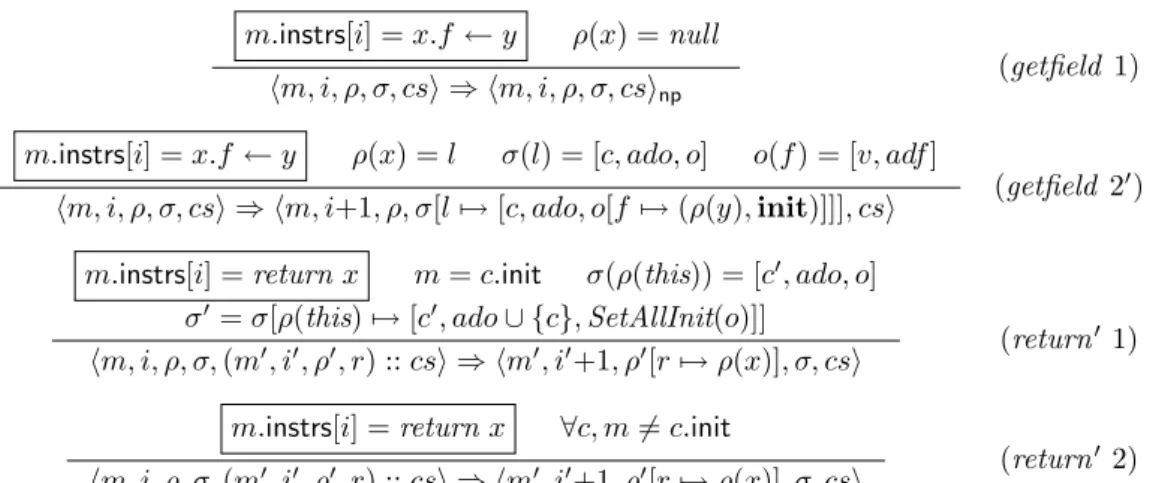No d’ordre : 4243 ANN´EE 2010
TH`
ESE / UNIVERSIT´
E DE RENNES 1
sous le sceau de l’Universit´
e Europ´
eenne de Bretagne
pour le grade de
DOCTEUR DE L’UNIVERSIT´
E DE RENNES 1
Mention : Informatique
´
Ecole doctorale Matisse
pr´
esent´
ee par
Laurent Hubert
pr´
epar´
ee au sein de l’´
equipe Celtique `
a l’IRISA (UMR 6074)
Institut de Recherche en Informatique et Syst`
emes Al´
eatoires
UFR Informatique et Electronique (ISTIC)
Foundations and
Implementation of a
Tool Bench for
Static Analysis of
Java Bytecode
Programs
Th`ese soutenue `a Rennes
le 17 d´ecembre 2010
devant le jury compos´e de :
Jean-Marc JEZEQUEL
Professeur `a l’Universit´e de Rennes 1 / pr´esident
Erik POLL
Associate Professor `a Radboud University Nijmegen / rapporteur
Anindya BANERJEE
Research Professor `a IMDEA Software / examinateur
Mario S ¨
UDHOLT
Professeur `a l’ ´Ecole des Mines de Nantes / examina-teur
Thomas JENSEN
Directeur de recherche `a l’INRIA / directeur de th`ese
David PICHARDIE
Remerciements
Je souhaite tout d’abord remercier chaleureusement le jury, pour l’int´erˆet qu’il a port´e `a mon travail et `a ma pr´esentation, et pour le rapport qu’il a r´edig´e. Je souhaite particuli`erement remercier Pierre- ´Etienne Moreau et Erik Poll d’avoir accept´e d’´evaluer mon rapport de th`ese et d’avoir pr´esent´e autant d’int´erˆet pour ce document, avec une mention sp´eciale pour Erik qui a en plus dˆu venir des Pays-Bas pour ´evaluer la soutenance. Merci aussi `a Anindya Banerjee, qui a accept´e d’ˆetre examinateur `a ma soutenance et donc de venir de Madrid pour l’occasion. Merci ensuite `a Mario S¨udholt d’avoir lui aussi accept´e d’ˆetre examinateur `a ma soutenance. Enfin, merci `a Jean-Marc J´ezequel qui a accept´e de pr´esider ce jury.
Je n’aurai probablement pas fait un doctorat si un certain nombre de personnes ne m’avait pas incit´e `a faire ce choix, et je tiens `a les en remercier car cela a ´et´e une exp´erience tr`es riche. J’aurai ainsi pu ne pas faire de Master de recherche pour pouvoir faire un stage en Espagne. Je tiens donc `a remercier Mireille Ducass´e qui, en me proposant un stage de recherche `a l’UPM, m’a permis de faire un Master de Recherche avec un stage `a Madrid. Je tiens aussi `a remercier le groupe de recherche CLIP, qui m’a accueilli `a l’UPM et qui a largement contribuer `a mon orientation vers le doctorat, et en particulier Manuel Hermenegildo, Germ´an Puebla, Elivra Albert, Astrid Beascoa et Samir Genaim. Enfin, David et Thomas ont aussi pris de leur temps pour me convaincre, et je les en remercie.
Ces trois ann´ees de doctorat ont ´et´e intenses mais plaisantes. Le travail a ´et´e int´eressant, et je tiens `a remercier mes deux directeurs de th`ese pour les directions qu’ils m’ont indiqu´ees. J’ai aussi appr´eci´e travailler en ´equipe et je les remercie me l’avoir permis, que ce soit directement avec David, ou en encadrant des stagiaires et ing´enieurs. Merci d’ailleurs `a ces deux ing´enieurs, Nicolas et Vincent, avec qui il a ´et´e agr´eable de travailler. Ces trois ann´ees n’auraient pas non plus ´et´e les mˆemes sans leurs voyages. Merci `a David et Thomas de m’avoir permis de partir, mais aussi `a Lydie et Christiane pour le support. Ensuite, il n’y a pas que le travail qui a ´et´e int´eressant, la bonne ambiance dans l’´equipe Lande/Celtique a aussi largement contribu´e `
a rendre ces ann´ees plaisantes. Merci `a tous, avec une mention particuli`ere `a Florence et Pierre-Emmanuel, deux “co-bureau” bien sympathiques, et `a Benoˆıt, qui, en soutenant sa th`ese en mˆeme temps que moi, m’a permis de me sentir moins seul face `a la r´edaction et `a l’administration.
Je souhaite ´egalement remercier ceux qui ´etaient pr´esent lors de ma soutenance. Je ne me risquerai pas `a une liste se voulant exhaustive de peur d’oublier quelqu’un, mais je tiens tout particuli`erement `a remercier mes parents, mon oncle et ma tante d’ˆetre venu de Nantes pour me soutenir.
Enfin, merci `a Charlotte pour sa pr´esence et son soutient durant ces ann´ees et tout par-ticuli`erement `a l’approche de la soutenance.
Abstract
In this thesis we study the static analysis of Java bytecode and its semantics foundations. The initialization of an information system is a delicate operation where security properties are enforced and invariants installed. Initialization of fields, objects and classes in Java are difficult operations. These difficulties may lead to security breaches and to bugs, and make the static verification of software more difficult. This thesis proposes static analyses to better master initialization in Java. Hence, we propose a null pointer analysis that finely tracks initialization of fields. It allows proving the absence of dereferencing of null pointers (NullPointerException) and refining the intra-procedural control flow graph. We present another analysis to refine the inter-procedural control flow due to class initialization. This analysis directly allows inferring more precise information about static fields. Finally, we propose a type system that allows enforcer secure object initialization, hence offering a sound and automatic solution to a known security issue. We formalize these analyses, their semantic foundations, and prove their soundness. Furthermore, we also provide implementations. We developed several tools from our analyses, with a strong focus at having sound but also efficient tools. To ease the adaptation of such analyses, which have been formalized on idealized languages, to the full-featured Java bytecode, we have developed a library that has been made available to the community and is now used in other research labs across Europe.
R´
esum´
e
Dans cette th`ese, nous nous int´eressons `a l’analyse statique du bytecode Java. L’initiali-sation d’un syst`eme d’information est une phase d´elicate o`u des propri´et´es de s´ecurit´e sont v´erifi´ees et des invariants install´es. L’initialisation en Java pose des difficult´es, que ce soit pour les champs, les objets ou les classes. De ces difficult´es peuvent r´esulter des failles de s´ecurit´e, des erreurs d’ex´ecution (bugs), ou une plus grande difficult´e `a valider statiquement ces logi-ciels. Cette th`ese propose des analyses statiques r´epondant aux probl`emes d’initialisation de champs, d’objets et de classes. Ainsi, nous d´ecrivons une analyse de pointeurs nuls qui suit finement l’initialisation des champs et permet de prouver l’absence d’exception de pointeurs nuls (NullPointerException) et de raffiner le graphe de flot de contrˆole intra-proc´edural. Nous proposons aussi une analyse pour raffiner le graphe de flot de contrˆole inter-proc´edural li´ee `a l’initialisation de classe et permettant de mod´eliser plus finement le contenu des champs statiques. Enfin, nous proposons un syst`eme de type permettant de garantir que les objets manipul´es sont compl`etement initialis´es, et offrant ainsi une solution formelle et automatique `
a un probl`eme de s´ecurit´e connu. Les fondations s´emantiques de ces analyses sont donn´ees. Les analyses sont d´ecrites formellement et prouv´ees correctes. Pour pouvoir adapter ces analyses, formalis´ees sur de petits langages, au bytecode, nous avons d´evelopp´e une biblioth`eque logi-cielle. Elle nous a permis de produire des prototypes efficaces g´erant l’int´egralit´e du bytecode Java.
R´
esum´
e ´
etendu
Introduction
Les fautes, ou bugs, sont fr´equentes dans le logiciel, si fr´equentes que les d´eveloppeurs et ´editeurs de logiciel ne souhaitent pas ˆetre tenus pour responsables. Ainsi, les licences de logiciels comportent g´en´eralement des clauses visant `a limiter les garanties fournies et leurs responsabilit´es. L’extrait suivant provient de la licence CeCILL.
La responsabilit´e du Conc´edant [...] ne saurait ˆetre engag´ee en raison notam-ment : (i) [...], (ii) des dommages directs ou indirects d´ecoulant de l’utilisation ou des performances du Logiciel subis par le Licenci´e et (iii) plus g´en´eralement d’un quelconque dommage indirect. En particulier, les Parties conviennent ex-press´ement que tout pr´ejudice financier ou commercial (par exemple perte de donn´ees, perte de b´en´efices, perte d’exploitation, perte de client`ele ou de com-mandes, manque `a gagner, trouble commercial quelconque) ou toute action dirig´ee contre le Licenci´e par un tiers, constitue un dommage indirect et n’ouvre pas droit `
a r´eparation par le Conc´edant.
Le logiciel peut donc causer des pertes financi`eres ou commerciales pour l’utilisateur sans que le distributeur du logiciel ne soit inqui´et´e.
En d´epit de ces clauses, les fautes logicielles coˆutent g´en´eralement quand mˆeme aux d´eveloppeurs et distributeurs de logiciels. En effet, la faible qualit´e d’un logiciel peut coˆuter en r´eputation au distributeur. Certains logiciels sont distribu´es avec des licences qui offrent plus de garanties `a l’utilisateur et l’autorisent, par exemple, `a demander le remboursement du logiciel. Le coˆut peut aussi ˆetre en termes de ressources quand le d´eveloppeur doit corriger l’erreur et distribuer un correctif. Dans le cas de logiciel o`u le correctif doit ˆetre install´e sur du mat´eriel tr`es d´eploy´e et non connect´e (des voitures ou des chaˆınes hi-fi par exemple), ce coˆut peut ˆetre tr`es ´elev´e. Enfin, le d´eveloppeur peut ˆetre aussi l’utilisateur, auquel cas toutes les cons´equences du mauvais fonctionnement du logiciel sont support´ees directement par lui. Dans ce dernier cas, la fameuse phrase “ce n’est pas moi, c’est l’informatique” permet quand mˆeme de se d´edouaner quelque peu. Pour toutes ces raisons, et malgr´e les clauses limitant les risques encourus par les distributeurs, la plupart des entreprises d´eveloppant du logiciel investissent temps et argent dans la qualit´e logicielle.
Am´eliorer la qualit´e logicielle
Il existe plusieurs outils pour am´eliorer la qualit´e des logiciels. Celui dans lequel les en-treprises investissent le plus est tr`es certainement le test. Tester un programme consiste `a l’ex´ecuter sur un jeu de test, c’est-`a-dire un ensemble d’entr´ees, et contrˆoler la sortie du pro-gramme avec un oracle (qui peut ˆetre un humain, une version pr´ec´edente du programme, un
x R ´ESUM ´E ´ETENDU
mod`ele du programme, etc.). Le test n’est pas exhaustif : il n’est pas possible de prouver l’absence d’erreur par le test car il n’est pas possible de tester un programme sur toutes ses entr´ees. Par cons´equent, tester un programme permet de gagner en confiance dans la correc-tion du programme, mais desbugs peuvent toujours ˆetre pr´esents. Une autre approche est de prouver enti`erement la correction fonctionnelle de la sp´ecification formelle d’un logiciel, et de g´en´erer le code `a partir de la sp´ecification.1 Elle a ´et´e utilis´ee dans l’industrie avec l’Atelier B et la M´ethode B [Abr96], et dans des recherches plus acad´emiques avec des assistants `a la preuve tels que Coq [Coq] ou Isabelle/HOL [NPW02]. Cette technique requiert un haut niveau d’expertise et est habituellement tr`es coˆuteuse en temps. Dans l’industrie, elle est seulement utilis´ee dans les cas o`u le coˆut d’une erreur peut ˆetre prohibitif, tels que dans les transports o`u unbug peut causer la perte de centaines de personnes. Enfin, la technique qui est sans doute la plus utilis´ee, bien que cela soit relativement discret, est l’analyse statique (AS). En effet, la majorit´e des d´eveloppements sont faits dans des langages int´egrant des syst`emes de types tels C, C]ou Java, et les syst`emes de types sont des AS.2 Une analyse d’un logiciel est statique si elle se fait sans ex´ecuter le logiciel. C’est une technique puissante qui permet de v´erifier automatiquement que des programmes respectent des propri´et´es vari´ees pouvant porter aussi bien sur des consommations de ressources, des types de donn´ees ou la confidentialit´e de donn´ees.
Contrairement au test, l’AS peut ˆetre exhaustive : elle peut donner des informations sur le logiciel valides pour toutes les ex´ecutions du programme, quelles que soient les entr´ees. Un avantage de l’AS sur la preuve de correction manuelle est que les AS sont g´en´eralement enti`erement automatiques. N´eanmoins, cet automatisme vient au prix de l’ind´ecidabilit´e dans le cas g´en´eral : un analyseur statique ne pourra prouver correct certains programmes pourtant corrects (dans le sens o`u ceux-ci respectent la propri´et´e attendue).
Un analyseur statique v´erifie qu’un code (source ou machine, une m´ethode ou un pro-gramme complet, etc.) respecte une propri´et´e. Si l’analyseur trouve un point du code qui viole cette propri´et´e, alors il l`eve une alarme appel´ee positif. Un analyseur peut lever de nombreux positifs pour un morceau de code analys´e, par exemple, toutes les lignes du code source qui appellent une certaine m´ethode. A cause de l’ind´ecidabilit´e de la plupart des pro-pri´et´es, les analyseurs ne peuvent trouver l’ensemble exact des points du code violant la propri´et´e. Il l`eve donc des faux positifs ou des faux n´egatifs. Un faux positif est une alarme qui est lev´ee alors que le code respecte la propri´et´e mais que l’analyseur n’a pas r´eussi `a le prouver. Un faux n´egatif est une alarme qui n’a pas ´et´e lev´ee alors que le code ne respecte pas la propri´et´e. Une analyse correcte n’a aucun faux n´egatif. Une analyse compl`ete n’a aucun faux positif.
Plusieurs m´ethodes sont utilis´ees pour faire face au probl`eme de l’ind´ecidabilit´e.
– Une premi`ere approche pragmatique est diff´erencier les alarmes qui sontprobablement correctes de celles qui sont probablement incorrectes. Cela peut se faire en utilisant des heuristiques ou des annotations de l’utilisateur auxquelles l’analyse fait confiance. Seules les alarmes probablement correctes sont ensuite lev´ees. Bien que cette approche soit incorrecte (puisque cela introduit des faux n´egatifs), cela permet aux d´eveloppeurs de se concentrer sur les alarmes qui correspondent plus probablement `a desbugs r´eels. Ces outils sont connus sous le nom de trouveur d’erreurs ou bug finders. Un exemple
1Une approche similaire est de prouver directement la correction fonctionnelle du code, par exemple dans
le cadre de JML, mais cela peut ˆetre vu comme un cas particulier o`u la sp´ecification est le code.
2L’analyse statique est aussi tr`es utilis´ee dans les compilateurs pour un autre objectif que l’absence
xi
notable est FindBugs [HSP06].
– Une autre approche consiste `a utiliser des annotations sans leur faire confiance. V´erifier une preuve est plus facile que de la faire, et les annotations peuvent ˆetre vues comme des preuves partielles que l’analyse peut v´erifier au lieu de les prouver. Ces annotations peuvent aussi ˆetre vues comme des indices r´eduisant l’espace de recherche de l’analyse et permettant ainsi des analyses plus pr´ecises. Par exemple, le compilateur Java n´ecessite que l’utilisateur annote chaque variable avec son type. Cette approche permet de r´eduire le nombre de faux positifs.
– Les AS peuvent aussi s’appliquer sur des langages sur lesquels il est plus facile de rai-sonner. Par exemple, les donn´ees sont sans doute plus simples `a suivre dans un langage fonctionnel o`u, par d´efaut, il n’y a pas de r´ef´erences et les d´efinitions associent directe-ment une valeur `a un nom. En d´epit d’un syst`eme de types riche (qui rend l’espace de recherche plus important), il est possible d’inf´erer les types pour les programmes ´ecrits en ML. Inversement, en Java, toutes les variables sont mutables (mˆeme les champsfinal
au niveau du bytecode), leur d´eclaration est s´epar´ee de leur initialisation, et l’initiali-sation des champs, objets et classes en Java est particuli`erement difficile comme nous le montrons dans cette th`ese.
– Enfin, l’AS permet d’inf´erer des invariants qui peuvent ˆetre utilis´es pour aider le d´eveloppement (refactoring,reverse engineering), une preuve de correction assist´ee ou une autre AS.
Comme cette th`ese le montre, Java (ou le bytecode Java) n’est pas un langage sur lequel il est facile de raisonner. C’est un langage incluant de nombreuses fonctionnalit´es, indus-triellement utilis´e, et utilisant des sch´emas d’initialisation complexes. Concevoir des analyses `
a la fois correctes et pr´ecises pour Java n’est donc pas une chose facile. Cette th`ese pro-pose des analyses dont la correction est formellement prouv´ee et des outils pour aider au d´eveloppement d’analyses correctes pour le bytecode Java. Ces contributions peuvent ˆetre utilis´ees directement pour assurer des propri´et´es de s´ecurit´e (telle que pr´esent´e Chapitre 7), ou comme fondation pour rendre les analyses plus pr´ecises et plus simples `a d´evelopper.
Java et bytecode Java
Java [GJSB05] est un langage source. Il est g´en´eralement compil´e vers du code objet, ou
bytecode, qui est le langage de bas niveau interpr´et´e par la machine virtuel Java (JVM) [MD97]. Java poss`ede de nombreuses constructions aux effets similaires mais qui peuvent ˆetre plus o`u moins faciles `a lire selon les situations. Java est aussi un langage qui ´evolue et de nouvelles fonctionnalit´es sont r´eguli`erement ajout´ees au langage. `A l’inverse, le bytecode Java propose beaucoup moins de constructions syntaxiques et ´evolue beaucoup moins, les nouvelles fonc-tionnalit´es de Java ´etant compil´ees en utilisant des fonctionnalit´es pr´eexistantes du bytecode. De plus, on peut souhaiter analyser un programme sans en avoir le code source ; c’est par exemple le cas du v´erificateur de bytecode (BCV) qui v´erifie au chargement des classes par la JVM que celles-ci respectent le syst`eme de types de la JVM. C’est pour ces raisons que nous nous int´eressons dans cette th`ese au bytecode et non au code source.
Analyse de pointeurs nuls et initialisation des champs
Les d´er´ef´erencements de pointeurs nuls en Java sont une source d’erreurs importante. Prouver leur absence apparaˆıt donc int´eressant. De plus, la pr´ecision des analyses statiques
xii R ´ESUM ´E ´ETENDU
d´epend de la pr´ecision du graphe de flot de contrˆole (CFG). Or, en Java, les d´er´ef´erencements de pointeurs nuls g´en`erent des exceptions qui sont la cause de branchements suppl´ementaires, soit des arc suppl´ementaires dans le CFG intra-proc´edural. Ces arcs sont pr´esents entre chaque instruction pouvant lever une exception et le gestionnaire d’exceptions correspondant ( hand-ler), ou la fin de la m´ethode ou du programme s’il n’y a pas de gestionnaire d’exceptions. Bien que la plupart des instructions puissent lever des exceptions, la plupart sont g´en´eralement sˆures. Par exemple, en Java, chaque instruction du typeo.fpeut lever une exception sioest nul. Si une analyse peut prouver que o est toujours diff´erent de nul, il est alors possible de retirer un arc du CFG et ainsi d’am´eliorer la pr´ecision des analyses reposant sur la pr´ecision du CFG intra-proc´edural.
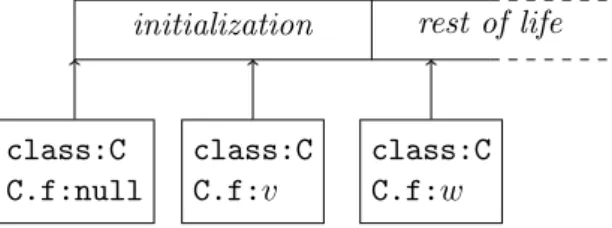
L’une des difficult´es dans la conception d’une analyse de pointeurs nuls pour le bytecode Java est l’initialisation des champs. Ainsi, n’´ecrire que des valeurs non nulles dans un champ ne permet pas d’assurer que seulement des valeurs non nulles ne puissent ˆetre lues de ce champ. En effet, les champs sont tous nuls par d´efaut ; une analyse un peu simple inf´ererait donc que tous les champs peuvent ˆetre nuls sans plus de pr´ecision.
L’une des id´ees cl´e `a la base de cette analyse d’inf´erence est de suivre finement l’initia-lisation des champs dans les constructeurs et m´ethodes appel´ees `a partir des constructeurs.
`
A la fin d’un constructeur, tous les champs d´efinis dans la classe courante qui n’ont peut ˆetre pas ´et´e explicitement initialis´es sont annot´es@Nullable, les autres champs ´etant annot´es conform´ement `a la valeur avec laquelle ils ont ´et´e initialis´es (par exemple,@NonNulls’ils ont ´et´e initialis´es avec la r´ef´erence d’un objet).
Pour la conception de notre analyse, nous avons d´efini undomaine abstrait State] et une
sp´ecification `a base de contraintes qui contraint S] ∈State] en fonction d’un programme P
(´ecrit S] |= P). Une valeur du domaine abstrait S] ∈ State] abstrait l’ensemble des ´etats atteignables deP. Un composant essentiel de State] est le domaine des valeurs Val].
Val]={MayBeNull,NotNull,Raw} ∪ {Raw(C)|C∈Classes} ∀C1, C2, C1 C2 =⇒ NotNull vRaw(C1)vRaw(C2)vRaw vMayBeNull
Le relation est la relation de sous-typage sur les classes :C1 C2 siC2 est un parent (une
super classe) de C1. Raw abstrait les r´ef´erences non nulles vers des objets possiblement en
cours d’initialisation.NotNull abstrait les r´ef´erences non nulles vers des objets ayant termin´e leurs constructeurs. MayBeNull d´esigne une r´ef´erence quelconque ou la constante null, c’est le maximum (>) de notre treillis. Raw(C) abstrait les r´ef´erences non nulles vers les objets ayant termin´e un constructeur de la classeC (et donc aussi un constructeur de chaque parent de C). Lors de la lecture d’un champ par une instruction o.f, si la variable o est de type
Raw(C) (ou d’un sous-type) et que le champfest d´eclar´e dans la classeC, alors l’abstraction du champ f est utilis´ee car l’objet est suffisamment initialis´e. Sinon, l’objet n’est peut-ˆetre pas suffisamment initialis´e et le champfest consid´er´e comme pouvant ˆetre nul, donc abstrait par MayBeNull.
Pour prouver la correction de notre analyse, nous avons proc´ed´e comme suit.
– Nous avons d´efini un langage, proche du bytecode Java mais sans pile, avec une
s´emantique exprim´ee sur undomaine concret State.
– Nous avons donn´e l’interpr´etation du domaine abstraitState] dans le domaine concret avec une relation ∼∈State]×State.
– Nous avons d´efini la propri´et´esafe(JPK) qui est v´erifi´ee lorsque tous les ´etats accessibles du programme P sont sˆurs (c’est-`a-dire qu’il ne peut y avoir d’exception de pointeur nul). Bien sˆur, JPKn’est pas calculable en g´en´eral.
xiii
– Nous avons d´efini la propri´et´esafe](S]) qui est v´erifi´ee siS] permet d’assurersafe(JPK)
´
etant donn´e que S] est une sur-approximation des ´etats de JPK, c’est-`a-dire que pour tout S∈JPK,S]∼S est v´erifi´e.
– Nous avons prouv´e la correction de l’analyse, c’est-`a-dire que si S] est une solution du syst`eme de contraintes pour le programme P (S]|=P) et sisafe](S]) est v´erifi´e, alors
safe(JPK) est v´erifi´e (safe](S])∧S]|=P =⇒ safe(JPK)).
Notre analyse ne n´ecessite aucune annotation de la part de l’utilisateur, on peut cependant la comparer au syst`eme de types propos´e par F¨ahndrich et Leino[FL03]. Nous avons montr´e que pour tout programme correct vis-`a-vis de leur syst`eme de types, notre analyse peut inf´erer des annotations S] |= P telles que safe](S]) et donc montrer que le programme est sˆursafe(JPK). Comme de plus notre analyse est prouv´ee correcte, cela prouve indirectement la correction de leur syst`eme de types (ou plutˆot de la formalisation que nous proposons de leur syst`eme de types).
Ces travaux ont principalement ´et´e r´ealis´es avec David Pichardie et publi´es dans la conf´erence internationale Formal Methods for Open Object-based Distributed Systems (FMOODS) [HJP08a].
Nit : un outil d’inf´
erence d’annotations de nullit´
e pour le
byte-code Java
Nous pr´esentons maintenant Nit (Nullability Inference Tool), une impl´ementation de notre analyse de pointeurs nuls pr´esent´ee pr´ec´edemment. Cette analyse a ´et´e formellement d´efinie sur un petit langage id´ealis´e, relativement haut niveau et abstrayant de nombreux d´etails du bytecode Java. Pr´esenter l’analyse `a ce niveau est important pour avoir une pr´esentation concise, centr´ee sur l’essentiel, et facilitant la preuve de correction. N´eanmoins, l’implantation ne peut se faire `a ce niveau et, comme expliqu´e dans pr´ec´edemment, l’outil analysera du bytecode Java.
Analyse d’alias
L’une des particularit´es du langage haut niveau utilis´e pour la sp´ecification de l’analyse ´etait l’absence de pile. Le bytecode est quant `a lui un langage `a pile. Il inclut aussi des instructions qui permettent d’obtenir des informations sur la nullit´e de r´ef´erence. Par exemple, l’instructionifnull jmpd´epile un ´el´ement de la pile et sautenoctet d’instruction si l’´el´ement d´epil´e est nul. Pour tester la nullit´e d’une variable localex, on empile le contenu dex(load x), puis l’instruction ifnull n permet de tester le contenu du sommet de pile. L’analyse peut donc inf´erer que si le test ´echoue, alors l’´el´ement d´epil´e est non nul. En revanche, sans information suppl´ementaire, elle n’a aucune information sur x. Nous proposons donc une analyse qui inf`ere des ´egalit´es entre variables locales et ´el´ements de pile.
Une nouvelle valeur abstraite
Nous supposons avoir deux fonctions, une fonction d’abstraction α∈2Val → Val] et une fonction de concr´etisation γ ∈ Val] → 2Val o`u Val est le domaine concret des r´ef´erences (incluant la constante null) et o`u Val] est le domaine abstrait. Si une variable peut soit contenir une r´ef´erence de type NotNull soit la constante null, elle est alors abstraite par
xiv R ´ESUM ´E ´ETENDU
l’information maisMayBeNull abstrait aussi les objets en cours d’initialisation, la meilleure abstraction que l’on puisse retrouver est donc α(γ(MayBeNull) \ {null}) = Raw. Cette configuration se produit fr´equemment dans les programmes et nous avons donc introduit une nouvelle valeur abstraite,MayBeNullInit qui permet de manipuler des valeurs pouvant ˆetre nulles sans introduire de valeurRaw.
Analyse des instructions instanceof
Le bytecode Java poss`ede l’instructioninstanceof qui met 1 sur la pile si le sommet de pile est une instance de C (et n’est donc pas nul), ou 0 sinon. Bien que cette instruction semble donner une information sur la nullit´e d’une variable, cette information n’est pas directe : on ne peut rien d´eduire tant qu’un test n’est pas effectu´e sur le sommet de pile. Or, l’analyse ne mod´elise pas les entiers (ni les bool´eens). Nous avons donc ajout´e une analyse suppl´ementaire qui calcule une abstraction de la pile telle que, pour chaque variable de pile, l’abstraction contient une sous-approximation de l’ensemble des variables locales qui doivent ˆetre non nulles si la variable de pile correspondante est ´egale `a 1.
Conclusion
L’analyse globale est une analyse en trois ´etapes (analyse intra-proc´edurale d’alias, analyse intra-proc´edurale des instanceof, et analyse inter-proc´edurale de pointeurs nuls) ex´ecut´ee sur un programme complet. Pour passer `a l’´echelle, de nombreuses optimisations ont ´et´e faites. Il est maintenant possible d’analyser des programmes cons´equents (3.400 classes ou 26.000 m´ethodes) en 2 minutes. L’analyse permet d’inf´erer que pr`es de 53% des champs sont non nuls. L’objectif n’´etant pas 100% (car des champs sont effectivement nuls), il n’est pas simple d’´evaluer la pr´ecision de ces 53%. En revanche, avec les annotations inf´er´ees, il est possible de prouver que 80% des d´er´ef´erencements sont sˆurs. En comparaison, sans les adaptations pr´esent´ees dans cette section, l’analyse permet de prouver 69% des d´er´ef´erencement sˆurs. Bien que ces r´esultats soit insuffisants pour trouver des erreurs (bugs), ils permettent d’am´eliorer la pr´ecision du CFG et sont utiles pour de la documentation ou dureverse engineering. Nous avons d´evelopp´e pour cet outil un greffon (plug-in) pour pouvoir l’utiliser `a partir d’Eclipse. Ce greffon propose des options pour r´eduire le nombre de positifs et faciliter son utilisation pour trouver des bugs. Nit et le greffon ont ´et´e pr´esent´es `a la conf´erence JavaOne et sont disponibles sous licence GPL `ahttp://nit.gforge.inria.fr.
Ce travail `a ´et´e publi´e `a l’atelier ACMProgram Analyis for Software Tools and Engineering (PASTE) [Hub08].
Sawja : atelier d’analyse statique pour Java
Lors du d´eveloppement de Nit, une grande partie du code ´ecrit n’´etait pas propre `a l’analyse d´evelopp´ee mais bien plus g´en´erale. Ce code permettait de fournir une repr´esentation OCaml des fichiers binaires.classcontenant le bytecode Java, de naviguer facilement dans la hi´erarchie de classe et dans le graphe de flot de contrˆole, etc. Une partie importante de l’effort de d´eveloppement de Nit a ´et´e sur l’efficacit´e du code produit, et donc aussi sur ces couches les plus basses. Pour faciliter le d´eveloppement d’analyseurs statiques correctes et efficaces, nous avons donc d´ecid´e de d´evelopper Sawja. Sawja est une biblioth`eque logicielle d´evelopp´ee en OCaml `a partir du code de Nit et de l’exp´erience acquise lors de ce d´eveloppement.
xv
Repr´esentation des classes de haut niveau
L’utilisation du langage OCaml permet l’utilisation du typage pour exprimer des contraintes structurelles. Par exemple, classe et interface, bien que simplement diff´erenci´ees par un drapeau au niveau binaire, utilisent deux structures diff´erentes au niveau OCaml. Quand on veut les manipuler indiff´eremment, cela reste possible car des fonctions sont four-nies qui permettent d’acc´eder `a leurs champs communs. Exprimer les contraintes structurelles facilite l’´ecriture de code car il n’est plus n´ecessaire de se prot´eger de nombreux cas impos-sibles. Par exemple, il n’est plus utile de g´erer le cas d’une interface non abstraite.
Afin d’´eviter une trop forte duplication du code, nous avons utilis´e les variants disponibles en OCaml. Les variants sont un type d’´enum´eration permettant le partage des constructeurs. Par exemple, lorsqu’une valeur de typejvm typeoujava basic typeest attendue, un mˆeme constructeur peut ˆetre utilis´e pour le type entier 64 bits (‘Long) dans les deux cas.
Afin d’´eviter l’analyse syntaxique des m´ethodes non accessibles, leparsing est paresseux. Le partage des constantes au sein d’une classe est assur´e au niveau bytecode grˆace `a une table (constant pool). Les instructions contiennent alors des indices de cette table au lieu des donn´ees. Sawja garde ce partage en m´emoire mais cache l’indirection en maintenant un nouvel indi¸cage. De plus, le partage est ´etendu `a toutes les classes charg´ees : cela permet ainsi d’utiliser des tests d’´egalit´e physique l`a o`u des ´egalit´es structurelles auraient ´et´e n´ecessaires et l’indi¸cage permet d’utiliser des structures de donn´ees efficaces sur les entiers comme les arbres de Patricia [Mor68] ou les BDDs [Bry92].
Repr´esentation interm´ediaire
Le bytecode Java est un langage `a pile et l’utilisation intensive de la pile d’op´erandes rend difficile l’adaptation des analyses statiques classiques qui ont ´et´e d´efinies sur un lan-gage `a variables et expressions. Ainsi, plusieurs outils d’analyse et d’optimisation de by-tecode Java travaillent en fait sur une repr´esentation interm´ediaire, rendant l’analyse plus simple [BCF+99, VRCG+99]. ´Etonnamment, la correction des transformations du bytecode Java vers ces repr´esentations interm´ediaires ne semble pas avoir ´et´e ´etudi´ee formellement. Demange et Pichardie ont ´etudi´e les fondations s´emantiques de ces transformations et ont propos´e un langage interm´ediaire avec une transformation pour laquelle ils ont prouv´e un th´eor`eme de pr´eservation s´emantique. Le langage propos´e est sans pile, avec des expressions sans effets de bords (des variables suppl´ementaires peuvent donc ˆetre n´ecessaires). La cr´eation d’objets, qui est souvent une op´eration d´elicate pour les analyses statiques, se fait en deux ´etapes au niveau du bytecode Java. Elle est ramen´ee `a une unique op´eration au niveau de la repr´esentation interm´ediaire, comme au niveau Java, ce qui facilite, l`a aussi, l’implantation des analyses. Une validation exp´erimentale de la transformation a aussi ´et´e r´ealis´ee et montre qu’elle est 10 fois plus rapide que Soot, le principal concurrent, et comparable en nombre de variables introduites.
Programmes complets
Un programme complet d´esigne l’ensemble du code accessible `a partir des points d’entr´ees du programme. Quand on analyse une m´ethode, par exemple, il est souvent n´ecessaire d’avoir une abstraction des entr´ees. Certaines analyses utilisent pour cela des annotations de l’utili-sateur (types, invariants, pr´e- ou post-conditions), mais il est aussi possible de calculer cette
xvi R ´ESUM ´E ´ETENDU
information `a partir des diff´erents contextes d’appel possibles, r´ecursivement. Avoir un pro-gramme complet permet de fournir une sur-approximation de l’ensemble des contextes d’ap-pel. Sawja propose une repr´esentation des programmes complets avec une API permettant de naviguer dans le CFG du programme. Sawja propose aussi plusieurs analyses permettant de construire des programmes complets, entre autre, CRA, RTA et XTA.
Nous avons con¸cu CRA (Class Reachability Analysis) pour charger tr`es rapidement des programmes pouvant ˆetre cons´equents en tirant partie du caract`ere paresseux du chargement des m´ethodes. CRA utilise en effet les informations contenues dans les tables des constantes des classes pour calculer une sur-approximation du code accessible.
RTA [BS96] est une analyse connue et efficace qui nous permet de comparer la performance de Sawja `a celle de Wala : Wala prend trois fois plus de temps et consomme 75% de m´emoire en plus.
Conclusion
Sawja est la premi`ere biblioth`eque proposant des outils pour le d´eveloppement d’analyseur statique pour le Java bytecode. Elle repr´esente un effort de codage de 1,5 homme-an et environ 22.000 lignes de code OCaml (commentaires inclus), dont 4.500 pour les interfaces. Forts de notre exp´erience sur Nit, nous avons con¸cu Sawja comme une biblioth`eque g´en´erique permettant `a tout nouvel analyseur statique de b´en´eficier des mˆemes composants efficaces. Sawja a d´ej`a ´et´e utilis´ee dans deux prototypes pour l’ANSSI (Agence nationale de la s´ecurit´e des syst`emes d’information) dont l’un est l’implantation du syst`eme de types garantissant l’initialisation des objets pr´esent´ee ci-apr`es. Nit a aussi ´et´e port´e sur la version actuelle de Sawja, ce qui, d’apr`es nos premiers essais, a permis d’am´eliorer ses performances de 30%. Sawja est disponible sous licence GPL `a http://sawja.inria.fr/.
Ces travaux ont ´et´e publi´es dans les actes de la conf´erence internationale Formal Verifi-cation of Object-Oriented Software (FoVeOOS) [HBB+10]. La couche la plus basse de Sawja (analyse syntaxique) a ´et´e initialement d´evelopp´ee par Nicolas Cannasse, la repr´esentation interm´ediaire est une contribution de Delphine Demange et David Pichardie, l’implantation de RTA est une contribution de Nicolas Barr´e, l’utilisation de variant OCaml pour la facto-risation des types est une contribution de Tiphaine Turpin, et enfin d’autres personnes ont contribu´e avec de plus petits d´eveloppements, des correctifs et des discussions sur la concep-tion de la biblioth`eque : ´Etienne Andr´e, Fr´ed´eric Besson, Florent Kirchner et Vincent Monfort. En d´epit de ces nombreuses contributions, je suis le d´eveloppeur principal de la biblioth`eque et ma contribution repr´esente environ 40% du code de la biblioth`eque.
Initialisation de classes
En Java, l’initialisation des classes, et donc des champs statiques, est implicite et pares-seuse. G´en´eralement, pour un programme, un grand nombre d’instructions est susceptible de d´eclencher l’initialisation d’une classe. Cela rend le flot de contrˆole tr`es peu intuitif pour un d´eveloppeur et tr`es impr´ecis et tr`es dense (car c’est une sur-approximation qui est consid´er´ee) pour une analyse statique. Nous proposons ici une solution pour am´eliorer la pr´ecision du graphe de flot de contrˆole tenant compte de l’initialisation des classes. Elle permet aussi une analyse plus fine des champs statiques et en particulier de d´etecter des utilisations de champs statiques avant leur initialisation.
xvii
Les contributions de ces travaux sont les suivantes. (i) Nous rappelons que l’initialisation implicite et paresseuse rend le CFG difficile `a calculer. (ii) Nous identifions des exemples de code que l’on souhaite pouvoir rejeter et d’autre que l’on souhaite pouvoir accepter. (iii) Nous proposons un langage pour l’´etude de l’initialisation des classes et des champs statiques. Ce langage abstrait de nombreux d´etails du bytecode Java et rend explicite l’initialisation de classes en introduisant une instruction initialize(C) qui a pour effet de d´eclencher l’initialisation de la classe C si celle-ci n’a pas d´ej`a ´et´e commenc´ee. (iv) Nous proposons une analyse prouv´ee correcte pour am´eliorer la pr´ecision du CFG et calculer l’ensemble des champs statiques initialis´es `a chaque point de programme. (v) Cette analyse n’´etant pas suffisamment pr´ecise, nous proposons une autre analyse plus pr´ecise, sensible au contexte. (vi) Nous d´etaillons quelques pistes pour une implantation efficace de cette seconde analyse.
Graphe de flot de contrˆole peu intuitif
L’initialisation des classes est faite par des m´ethodes sp´ecifiques qui ne peuvent ˆetre appel´ees que par la JVM. Ces m´ethodes contiennent du code arbitraire et peuvent donc d´eclencher l’initialisation d’autres classes. Les seules instructions pouvant d´eclencher l’initia-lisation d’une classe sont la lecture et l’´ecriture d’un champ statique, l’appel d’une m´ethode statique et la cr´eation d’une instance d’une classe. L’initialisation d’une classe est d´eclench´ee lorsqu’une telle instruction est rencontr´ee et si la classe n’a pas d´ej`a ´et´e initialis´ee. Le flot de contrˆole li´e `a l’initialisation de classes, ne d´epend donc pas de la syntaxe (comme les appels de m´ethodes statiques) ni des donn´ees (comme les appels de m´ethodes virtuelles), mais de l’historique des classes initialis´ees.
Analyse de l’´etat d’initialisation des classes
La seconde analyse est fond´ee sur une abstraction de l’´etat d’initialisation de chaque classe. Chaque classe peut ˆetre dans l’un des trois ´etats suivants. Une classe peut ne pas avoir d´ebuter son initialisation (´etat α). C’est l’´etat de toutes les classes au d´ebut du programme. Une classe peut ˆetre en cours d’initialisation (´etatβ). Une classe est vue dans cet ´etat par tout le code accessible depuis l’initialiseur de la classe. Enfin, une classe peut ˆetre compl`etement initialis´ee (´etat γ). `A l’ex´ecution, une classe ne peut ˆetre que dans un seul ´etat `a un instant donn´e. L’analyse abstrait cette information en calculant des ´etats d’initialisation abstraits du programme (IS]).
IS] =P(Classes× {α, β, γ})
Un ´etat d’initialisation associe `a chaque classe les ´etats d’initialisation dans lesquelles la classe peut se trouver. L’analyse propos´ee est une analyse de flot de donn´ees, sensible au contexte, utilisant cette abstraction. La fonction de transfert essentielle est celle de l’instruction d’ini-tialisation initialize(C). Le flot de donn´ees peut ˆetre propag´e `a l’initialiseur si la classe peut ˆetre dans l’´etat α d’apr`es l’abstraction de l’´etat d’initialisation courantIS ∈IS]. Dans ce cas,γ est ajout´e `a l’´etat d’initialisation au point de programme suivant et la post-condition calcul´ee pour l’initialiseur de classe peut ˆetre utilis´ee (assum´ee).
Conclusion
L’initialisation de classes, et donc aussi des champs statiques, est donc plus complexe qu’il peut y paraˆıtre `a un premier abord. Ainsi, bien que dans la plupart des cas le comportement
xviii R ´ESUM ´E ´ETENDU
r´eel correspond au comportement attendu, ce n’est pas toujours le cas, et une analyse statique correcte ne peut se contenter de supposer que l’initialisation d’une classe a toujours lieu avant son utilisation. Nous avons donc propos´e un langage pour l’´etude de ce probl`eme qui permet de s’abstraire du bytecode Java en conservant le m´ecanisme d’initialisation de classes ainsi qu’une analyse qui permet d’inf´erer, pour chaque point de programme, l’ensemble des ´etats d’initialisation des classes et l’ensemble des champs statiques qui ont d´ej`a ´et´e initialis´es. Une telle analyse peut ˆetre utilis´ee directement pour v´erifier que les champs statiques sont initialis´es avant leur premi`ere lecture. Elle peut aussi ˆetre utilis´ee pour am´eliorer l’analyse de pointeurs nuls pr´esent´ee pr´ec´edemment sachant que si un champ est initialis´e avant une lecture, alors l’abstraction du champ peut ˆetre l’union de l’ensemble des valeurs ´ecrites dans le champ.
Une partie de ces travaux a ´et´e r´ealis´ee avec David Pichardie et publi´ee `a Bytecode Se-mantics, Verification, Analysis and Transformation (ByteCode) [HP09].
Garantir l’initialisation des objets
L’initialisation d’un syst`eme d’information est une phase d´elicate o`u des propri´et´es de s´ecurit´e sont v´erifi´ees et des invariants install´es. Il est donc important de garantir que seule-ment des objets enti`erement initialis´es puissent ˆetre librement manipuler par le programme et que les objets partiellement initialis´es sont pr´ecis´ement suivis. Plusieurs failles de s´ecurit´e im-portantes du JRE (Java Runtime Environment) avaient pour cause des objets partiellement initialis´es. Nous proposons ici un syst`eme de types fond´e sur l’id´ee propos´ee par F¨ahndrich et Leino pour leur syst`eme de types de pointeurs nuls que nous avons d´ej`a aussi utilis´e pour notre analyse de pointeurs nuls : le suivi des objets en cours d’initialisation avec le type
Raw(C). Ce syst`eme de types permet `a un d´eveloppeur d’exprimer unepolitique d’initialisa-tion : quelles variables peuvent r´ef´erencer des objets en cours d’initialisation. Exprimer cette politique sous forme d’un syst`eme de types offre l’avantage qu’il devient possible de v´erifier automatiquement la politique.
L’exemple suivant montre une classe qui durant l’ex´ecution de son constructeur s’as-sure que (i) l’utilisateur `a la permission d’´ecrire dans le dossier /tmp (sinon la m´ethode
checkPermission l`eve une exception) et (ii) initialise un champ non null field par l’in-term´ediaire de la m´ethodeinits.
class S e n s i t i v e C l a s s { private O b j e c t n o n _ n u l l _ f i e l d ; S e n s i t i v e C l a s s (){ i n i t s (); S e c u r i t y M a n a g e r sm = S y s t e m . g e t S e c u r i t y M a n a g e r (); if( sm !=null){ sm . c h e c k P e r m i s s i o n (new j a v a . io . F i l e P e r m i s s i o n ( " / tmp / - " , " w r i t e " )); } }
protected void i n i t s (){this. n o n _ n u l l _ f i e l d = new O b j e c t ( ) ; } public void s e n s i t i v e M e t h o d ( ) { . . . }
}
Cette classe poss`ede plusieurs d´efauts de conception qui peuvent ne pas ˆetre ´evidents `a voir au premier abord : elle poss`ede au moins deux failles permettant d’appeler la m´ethode
xix
classeAttacker exploitant ces deux vuln´erabilit´es. La premi`ere vuln´erabilit´e est li´ee `a l’uti-lisation d’une m´ethode virtuelle pour initialiser le champnon null field : il est possible de surcharger cette m´ethode et donc d’appeler la m´ethode sensible avant que les permissions soient v´erifi´ees. La seconde vuln´erabilit´e est li´ee `a la m´ethode finalizequi est appel´ee par le ramasse-miette (garbage collector) avant la lib´eration m´emoire d’un objet. En effet, lorsque l’utilisateur n’a pas la permission d’´ecrire dans /tmp, la m´ethode checkPermission´echoue, interrompant la construction de l’objet et le rendant normalement inaccessible, pouvant donc ˆetre collect´e par le ramasse miette. Lorsque la m´ethodefinalizeest appel´ee sur l’objet, elle peut appeler la m´ethodesensitiveMethod.
class A t t a c k e r extends S e n s i t i v e C l a s s { protected void i n i t s (){
this. s e n s i t i v e M e t h o d (); }
void f i n a l i z e (){this. s e n s i t i v e M e t h o d ( ) ; } public static void m a i n ( S t r i n g a r g s [ ] ) {
try{ A t t a c k e r o = new A t t a c k e r ( ) ; } catch( T h r o w a b l e e ) { . . . }
} }
Le probl`eme est connu et a ´et´e `a l’origine de plusieurs failles de s´ecurit´e, mais aucune solution statique n’a ´et´e propos´ee pour r´esoudre ce probl`eme. Nous proposons un jeu d’an-notations Java 5 pour que le d´eveloppeur puisse annoter son code pour sp´ecifier la politique qu’il souhaite voir assur´ee.
V ANNOT ::= @Init | @Raw | @Raw(CLASS) R ANNOT ::= @Pre(V ANNOT) | @Post(V ANNOT)
Une annotation produite par la r`egleV ANNOTpeut ˆetre utilis´ee pour les champs, les valeurs de retour et les param`etres des m´ethodes. Les receveurs des m´ethodes virtuelles peuvent avoir une annotation diff´erente au d´ebut et `a la fin de la m´ethode, d’o`u la r`egle de production
R ANNOT. Dans l’exemple pr´ec´edent, il suffirait d’annoter la m´ethode sensitiveMethod avec
@Pre(@Init).
Nous avons formalis´e la v´erification statique de la coh´erence des annotations sous forme d’un syst`eme de types. Cela permet de rejeter les classes qui, comme la classe Attacker
dans l’exemple pr´ec´edent, pourraient essayer d’acc´eder `a une m´ethode n´ecessitant un objet initialis´e alors que l’objet poss´ed´e est partiellement initialis´e.
Un tel syst`eme est modulaire : les classes peuvent ˆetre v´erifi´ees une `a une et, quand une classe ne respecte pas la politique, le programme peut ˆetre arrˆet´e sans que la vuln´erabilit´e d´etect´ee n’ait pu ˆetre utilis´ee. Cependant, pour ˆetre correcte, l’analyse doit ˆetre ex´ecut´ee sur le programme complet, par exemple au fur et `a mesure du chargement par la JVM. Nous avons ´evalu´e exp´erimentalement le nombre d’annotations n´ecessaires pour v´erifier des classes existantes de la biblioth`eque Java. D’apr`es nos exp´eriences, pour v´erifier 380 classes des 381 classes des paquetsjava.lang,java.securityetjavax.security, seulement 43 annotations ont ´et´e ajout´ees sur les 131.486 lignes de code source Java. Une classe n’a pas pu ˆetre v´erifi´ee `
a cause d’une limitation de notre syst`eme de types sur les tableaux : il est en effet impossible actuellement de stocker un objet partiellement initialis´e dans un tableau.
Ces travaux ont ´et´e r´ealis´es avec Thomas Jensen, Vincent Monfort et David Pichardie, et publi´es dans les actes de la conf´erence internationaleEuropean Symposium on Research in
xx R ´ESUM ´E ´ETENDU Computer Security (ESORICS) [HJMP10]
Conclusion
Cette th`ese pr´esente des travaux allant de la formalisation de nouvelles analyses ou d’ana-lyse d’inf´erence pour des syst`emes de types pr´eexistant, `a l’implantation de ces analyses pour l’ensemble du bytecode Java et `a leurs ´evaluations exp´erimentales.
F¨ahndrich et Leino proposent une analyse de pointeurs nuls qui mod´elise finement l’ini-tialisation d’objets en ´etiquetant les objets en cours d’initialisation commebrut (Raw). Une contribution de cette th`ese est de donner une fondation s´emantique `a cette id´ee en donnant une s´emantique au langage et `a ces annotations. Cela nous permet de prouver que notre analyse d’inf´erence et leur syst`eme de types sont corrects. Une autre contribution de cette th`ese est d’avoir identifi´e cette propri´et´e comme solution pour rendre plus sˆure l’initialisation d’objets. Cette analyse peut ˆetre utilis´ee pour am´eliorer les garanties de s´ecurit´e que four-nit le v´erificateur de bytecode (BCV). Avoir des fondations s´emantiques et formelles est une motivation importante de nos travaux, mais nous ne fournissons pas seulement des analyses correctes, nous fournissons aussi des implantations.
`
A partir de nos sp´ecifications formelles, qui abstraient de nombreux d´etails du bytecode Java, nous avons produit plusieurs logiciels avec succ`es.
– Nit est l’implantation de notre analyse de pointeurs nuls. Elle est disponible en licence GPL et a ´et´e t´el´echarg´ee plus de 930 fois. Rendre cette implantation efficace a ´et´e une partie importante du travail. En tant qu’analyseur de programme complet, elle a besoin d’une abstraction du flot de contrˆole, mais mˆeme une simple analyse de hi´erarchie de classes (CHA) [DGC95] n’est pas si facile `a implanter sur le bytecode car il y a 5 types d’appels de m´ethode diff´erents. Nit a ´et´e une importante source d’am´elioration pour Sawja.
– Nit/Eclipse, le greffon (ou plug-in) pour utiliser Nit `a partir d’Eclipse, a ´et´e pr´esent´e `
a JavaOne, qui est une conf´erence organis´ee par Sun/Oracle pour les utilisateurs de la technologie Java. Nit a re¸cu des retours positifs de la part des utilisateurs et s’est r´ev´el´e bien pratique pour faire la d´emonstration d’un analyseur statique. Vincent Monfort, ing´enieur dans l’´equipe Celtique, travaille `a rendre le greffon ind´ependant de Nit pour qu’il puisse ˆetre utilis´e par d’autre analyseur statique. Il pourrait ainsi ˆetre int´egr´e `a Sawja.
– Sawja est notre biblioth`eque de d´eveloppement d’analyseur statique pour le bytecode Java. Avec Javalib, son pr´ed´ecesseur et maintenant composant, ils sont disponibles en licence LGPL et ont ´et´e t´el´echarg´es plus d’un millier de fois. Pour une biblioth`eque g´erant du bytecode Java `a partir d’OCaml, ce r´esultat nous semble plutˆot encourageant. Sawja est maintenant utilis´ee pour d´evelopper d’autre analyseur statique dans notre laboratoire, mais aussi par Julien Signoles et Philippe Hermann au CEA (Commissariat `
a l’ ´Energie Atomique) et par Afshin Amighi et Dilian Gurov `a l’Institut Royal de Technologie (KTH) `a Stockholm.
– Notre analyse de sˆuret´e d’initialisation d’objets a donn´e lieu `a un prototype pour l’ANSSI (Agence Nationale de la S´ecurit´e des Syst`emes d’Information) qui est aussi dis-ponible sous forme d’un d´emonstrateur Web (http://www.irisa.fr/celtique/ext/ rawtypes/). Il a ´et´e int´egr´e `a une version de la machine virtuelle JamVM [Lou]. En ciblant nos analyses vers le bytecode Java, nous avons d´ecouvert `a quel point le langage
xxi
est compliqu´e. Par exemple, nous avons r´ealis´e la complexit´e de l’initialisation de classes durant le d´eveloppement de Nit. Au d´epart, nous pensions qu’un initialiseur ´etait similaire `a un constructeur et que l’analyse de pointeurs nuls pourrait ˆetre ais´ement ´etendue aux champs statiques. Ce n’´etait d´efinitivement pas le cas.
Une autre surprise a ´et´e la taille des programmes. Nos analyses de pointeurs nuls et d’initialisation de classes travaillent sur des programmes complets. Une telle analyse sur des programmes Java r´ev`ele des d´efis insoup¸conn´es. Par exemple, un simple programme hello worlden Java utilise en fait des milliers de m´ethodes dans la biblioth`eque (runtime). Analyser mˆeme un petit programme requiert donc des outils performants. Nous avons apport´e des solutions `a ce probl`eme en d´eveloppant Nit puis Sawja.
L’objectif principal de l’analyse statique est d’am´eliorer la qualit´e du logiciel. Cet objectif est vain tant que l’analyse statique n’est pas plus largement adopt´ee que pour des syst`emes de types `a minima.
Une piste int´eressante pour d´evelopper l’adoption des analyses statiques est probablement (et paradoxalement) les analyses incorrectes. Grˆace `a leur faible taux de faux positifs, le coˆut n´ecessaire pour corriger l’ensemble des probl`emes relev´es par l’outil est relativement bas. Cela peut rendre ces outils relativement efficaces et devrait aider `a convaincre les d´ecideurs que les analyseurs statiques peuvent avoir un ROI (Return On Investment) suffisant pour ˆetre plus largement utilis´e.
Une autre difficult´e pour l’adoption des analyseurs statiques est qu’ils semblent g´en´eralement ˆetre ´evalu´es relativement tard dans le processus de d´eveloppement. Les ana-lyses statiques ont des difficult´es `a g´erer pr´ecis´ement certains motifs de code (patterns), qui peuvent d´ependre de l’analyse. Par exemple, Nit fonctionne mieux si un champ est initia-lis´e dans son constructeur, mais certains d´eveloppeurs ont tendance `a initialiser les champs d’un objet juste apr`es leur cr´eation. Un autre exemple est la manipulation des champs. Si une m´ethode teste qu’un champ est diff´erent de nul avant de l’utiliser, il vaut mieux copier d’abord le champ dans une variable locale : cela ´evite `a l’analyse de devoir prouver qu’un autre processus (ou thread) ne peut modifier le champ entre son test et son utilisation. Si l’analyseur statique est utilis´e d`es le d´ebut du d´eveloppement, ces patterns difficiles seront plus naturellement ´evit´es par les d´eveloppeurs.
Une fois que les erreurs simples seront corrig´ees, une fois que les d´eveloppeurs auront pris l’habitude d’utiliser les analyseurs statiques et connaˆıtront les patterns `a ´eviter pour faciliter le travail de ces outils, alors des analyses plus correctes (trouvant plus d’erreurs) seront n´ecessaires. Une autre approche est donc probablement de d´evelopper d`es maintenant des analyses correctes, mais o`u des options permettent d’activer des suppositions incorrectes et o`u des priorit´es sont associ´ees aux alarmes. Par exemple, nous avons introduit dans Nit des options permettant de supposer que les tableaux ne contiennent que des valeurs non nulles. Une autre solution pourrait ˆetre de diff´erencier les valeurs nulles provenant des tableaux de celles provenant des champs. Ensuite, d´er´ef´erencer une valeur nulle de tableau d´eclencherait une alarme de priorit´e plus faible qu’un d´er´ef´erencement d’une valeur nulle de champ.
Un autre axe qui peut ˆetre ´etudi´e est l’information donn´ee sur la cause d’une alarme. En effet, lorsqu’une alarme est lev´ee, le d´eveloppeur a besoin d’informations pour trouver l’origine de l’alarme (et ´eventuellement l’erreur). Par exemple, en montrant les annotations que Nit a trouv´ees, il est plus simple de comprendre pourquoi il peut reporter `a un certain point de programme une erreur. Cependant, comprendre pourquoi Nit a inf´er´e une annotation peut ˆetre fastidieux.
Contents
Remerciements iii Abstract v R´esum´e vii R´esum´e ´etendu ix 1 Introduction 11.1 Improving Software Quality . . . 1 1.2 Java versus Java bytecode . . . 3 1.3 Background on Static Analysis Through a Tutorial . . . 4 1.4 Contents and Contributions . . . 8
2 BIR Language 11
2.1 Syntax . . . 11 2.2 Semantic Domains . . . 13 2.3 Operational Semantics . . . 13 2.4 Conclusion . . . 14
3 Non-Null References and Field Initialization 17
3.1 Introduction . . . 17 3.2 Related Work . . . 19 3.2.1 Type Systems . . . 19 3.2.2 Type Inference . . . 19 3.3 Non-Null Annotations . . . 20 3.4 Syntax and Semantics . . . 21 3.5 Null-Pointer Analysis . . . 22 3.5.1 Modular Type Checking . . . 22 3.5.2 Abstract Domains . . . 23 3.5.3 Inference Rules . . . 24 3.5.4 Example . . . 27 3.6 Correctness . . . 29 3.7 F¨ahndrich and Leino’s Type System . . . 31 3.8 Conclusions . . . 35
xxiv CONTENTS
4 A Non-Null Annotation Inferencer for Java Bytecode 37
4.1 Towards a Bytecode Analysis . . . 37 4.1.1 Alias Analysis . . . 37 4.1.2 A New Abstract Value . . . 38 4.1.3 Analysis of instanceofInstructions . . . 39 4.2 Implementation . . . 40 4.3 The Nit/Eclipse Plug-in . . . 41 4.4 Empirical Results . . . 42 4.5 Related Work . . . 45 4.6 Conclusion . . . 45
5 Sawja: Static Analysis Workshop for Java 47
5.1 Introduction . . . 47 5.2 Existing Libraries for ManipulatingJava Bytecode . . . 48
5.3 High-level Representation of Classes . . . 50 5.4 Intermediate Representation . . . 52 5.5 Complete Programs . . . 53 5.5.1 API of Complete Programs . . . 53 5.5.2 Construction of Complete Programs . . . 54 5.6 Conclusion . . . 57
6 Static Initialization 59
6.1 Introduction . . . 59 6.2 Why Static Analysis of Static Fields is Difficult? . . . 60 6.3 The Language . . . 62 6.3.1 Syntax . . . 62 6.3.2 Semantics . . . 63 6.4 A Must-Have-Been-Initialized Dataflow Analysis . . . 65 6.4.1 Informal Presentation . . . 66 6.4.2 Formal Specification . . . 67 6.4.3 Implementation . . . 71 6.5 A Three-Valued Initialization State Analysis . . . 71 6.5.1 MHBI Analysis is Too Dependent on the Control Flow Analysis . . . 71 6.5.2 Specification of the Analysis . . . 73 6.6 Towards an Implementation . . . 76 6.6.1 Handling the Full Bytecode . . . 76 6.6.2 Scaling the Analysis . . . 77 6.7 Related Work . . . 78 6.8 Conclusion and Future Work . . . 79
7 Secure Object Initialization 81
7.1 Introduction . . . 81 7.2 Related Work . . . 82 7.3 Context Overview . . . 82 7.3.1 Standard Java Object Construction . . . 83 7.3.2 Attack on the Class Loader and the Patch From Oracle . . . 83 7.4 The Right Way: A Type System . . . 85
CONTENTS xxv 7.5 Formal Study of the Type System . . . 89 7.5.1 The language . . . 89 7.5.2 Initialization Types . . . 90 7.5.3 Typing Judgment . . . 91 7.6 Extensions . . . 92 7.6.1 Introducing Dynamic Features . . . 92 7.6.2 Handling Arrays . . . 93 7.7 Experimental Results . . . 93 7.7.1 Implementation . . . 93 7.7.2 A Case Study: Oracle’s JRE . . . 94 7.8 Conclusion and Future Work . . . 96
8 Conclusion 97
Chapter 1
Introduction
Software bugs are common, so common that developers and editors do not want to be re-sponsible. Thus, software licenses usually include a disclaimer of warranty and liability such as the following one (extracted from the GNU General Public License).
“In no event [...] will any copyright holder [...] be liable to you for damages, including any general, special, incidental or consequential damages arising out of the use or inability to use the program [...], even if such holder or other party has been advised of the possibility of such damages.”
Software may not perform as promised, and may result in data or financial loss for the user. Even if the developer was informed of the defect, he often takes no responsibility for it.
Despite these disclaimers and limitations, software bugs usually still cost to the developer. Bugs may cost its popularity to the developer. Bugs may also carry a cost because of a less-limited warranty. E.g., some licenses offer to reimburse the loss directly caused by the software within the limit of the price of the software. Bugs also cost resources when the developer needs to fix the bug and distribute a patch. For largely-deployed unconnected devices, it may be very expensive. The developer may also be the user, in which case the developer directly suffers from the consequences of bugs in his software. For those reasons, despite warranty and liability disclaimers, most companies developing software do invest in software quality.
1.1
Improving Software Quality
Several tools exist to improve software quality. The one in which companies invest the most is certainly tests. During testing, the code is run on several test sets and the output of the program for those sets is checked by an oracle (which can be a human, a previous version of the program, a model of the program, etc.). Testing is not exhaustive: it is impossible to prove the absence of a class of bugs using testing because it is impossible to test programs on all their possible entries. Therefore, although testing allows gaining some confidence in the quality of the software, bugs may still happen on the software. Another kind of approach is to completely prove correct a formal specification of a program, and then extract the code from the specification.1 It has been industrially used with the Atelier B and the B Method [Abr96] and in more academic research with proof assistants such as Coq [Coq] or Isabelle/HOL [NPW02]. This approach requires a highly technical expertise and is usually
1There is another approach where the proof is done directly on the code, for example within the JML
framework, but we can see this approach as a special case where the code is the specification.
2 CHAPTER 1. INTRODUCTION
time consuming. In industry, it is only used where the cost of a bug may be huge, like in the transport industry where a bug may cost the lives of hundreds of people. It is also preventively introduce in domains where it may be required by law or standards in the future, such as in the aircraft or smart-card industry. Finally, the one that is arguably the most used, although people usually do not think about it, is probably static analysis (SA). Indeed, almost all developments are done in languages that integrate type systems, like C, C# or Java, which are a kind of SA. An analysis of software is static if it is performed without actually running the studied software. It is a powerful technique that enables automatic verification of programs with respect to various properties such as type safety or resource consumption.
As opposed to test, SAs may be exhaustive: they can give information on the software that is valid for all executions of the program and in particular that does not depend on the inputs. An advantage over manual proofs of correctness is that SAs are usually fully automatic. However, this comes at the price of undecidability in the general case: a SA will inevitably fail to prove that some correct programs are indeed correct (in the sense that they respect the property of interest).
A static analyzer checks that some code (source or machine code, a small piece of code or a complete program) respects some property. If the analyzer finds that the program violates the property at some point, it issues an alarm, called apositive. An analyzer may report many positives for one analyzed code. E.g., all the lines of the source code that call a particular method. As a result of undecidability, most analyzers cannot report the exact set of points that do not respect the property. Hence, they issue false positives or false negatives. A false positive is an alarm that is issued when, in fact, the code respects the property but the analyzer was unable to prove it. A false negative is an alarm that is not issued despite the code violates the property because the analyzer did not notice it. A sound analysis reports no false negatives. A complete analysis reports no false positives.
To face incompleteness, different approaches may be used by SAs.
• SAs may use a more pragmatic approach and try to differentiate programs that may be correct from programs that may be incorrect, using heuristics or user-trusted annota-tions, and only reporting the latter ones. Although this is unsound (it introduces false negatives), it also allows reducing the number of false positives. Developers then only concentrate on alarms that are very likely to be real issues. Those tools are known as bug finders. This is notably the case of FindBugs [HSP06].
• Some SAs rely on user-untrusted annotations. Checking a proof is often easier than proving, and user annotations may be seen as partial proof that an analysis checks instead of proving them. Untrusted annotations may also be seen as “tips” reducing the search space of the analysis and allowing for more precise analyses. E.g., the Java compiler requires the user to put type annotations on each variable. This reduces the number of false positives.
• SAs may also focus on languages that are easier to reason about. For example, data are arguably easier to track in functional languages where, by default, there are no references, and definitions associate directly a value to a name. Despite a rich type system (which makes the search space extremely large), core ML is provided with type inference. Conversely, in Java, all variables are mutable (even final fields when look-ing at the Java bytecode), their declaration is separated from their initialization, and
1.2. JAVA VERSUS JAVA BYTECODE 3 initialization of fields, objects and classes in Java is particularly difficult, as this thesis will illustrate.
• Finally, SA may be used to infer invariants, either helping the development (refactoring, reverse engineering), an assisted proof of correctness, or another SA.
As this thesis will try to demonstrate, Java (or Java bytecode) is not a language easy to reason with. It is a full-featured language, used in the industry, and using complex initializa-tion schemes. Building sound and precise analyses for Java is therefore a difficult task. This thesis proposes sound analyses and tools for the actual Java bytecode. They may be used directly to ensure security properties (as proposed in Chapter 7), or as a basis to make the development of other analyses easier and the analyses more precise.
1.2
Java versus Java bytecode
Java [GJSB05] is a source language. It is usually compiled to Java bytecode, the low-level programming language interpreted by the Java Virtual Machine (JVM) [LY99].
As a source language, Java has many constructs which have similar effects, but which may be easier to use or to read by developers. E.g., a for loop can be encoded into a
while loop, and a switch instruction can be encoded intoif/then/else conditionals. All loops in Java are compiled into conditional and unconditional jumps at the bytecode level. The same occurs with other language constructs and the Java bytecode contains therefore a lot less constructs.2 Another issue with Java is that it evolves more quickly. E.g., generics, annotations, asserts, autoboxing and unboxing, enum types, foreach loops, variable arity methods and static imports have been added to the Java language without changing the Java bytecode language. Finally, when one wants to analyze a program, the source may not be available. This may be the case if an external library is used, if the compiler is not trusted, or if a user wants to check code he has downloaded. E.g., the Java ByteCode Verifier (BCV), a checker integrated in the JVM, analyzes the bytecode before executing it, when the source code is no more available. For those reasons, the work presented in this thesis targets the Java bytecode, although part of it also applies to Java.
Although Java bytecode is not a source language, it is not as low level as the assembly language of standard microprocessors: it is a typed and based language. The stack-based architecture helps to ensure the independence from the hardware. E.g., the number of registers available in the microprocessor is not needed. Being typed means that all data are labeled with a type, e.g., ensuring that when a field is read from an object, as in o.f, the objectois an instance of a class that declares a fieldf. The Java bytecode, like Java, is a full-featured language: it supports objects, classes, interfaces, arrays, basic types such as 8, 16, 32 and 64-bit integers, 32 and 64-bit floating-point numbers, Booleans, characters, strings, multi-threading, 5 different types of method calls, exceptions, subroutines, unstructured control-flow, etc. To compact the code and for efficiency reasons, an operation can be encoded in several ways. E.g., to push an integer onto the stack, one may use the instruction bipush,
sipush,ldcorldc w. Most of the time, those details do not affect the analyses we may build. Thus, although the analyses we present in this thesis are targeted to the Java bytecode, we do
2Although there are more than 200 Java bytecode instructions, there is no expression in bytecode and many
4 CHAPTER 1. INTRODUCTION
x, y∈Var jmp∈ L=N
p ∈ Prog ::= { classes∈ P(Class), main∈Meth,} c ∈ Class ::= { super∈Class⊥, fields∈ P(Field)}
f ∈ Field ::= { ftype∈Type } m ∈ Meth ::= { instrs∈Instr array}
e ∈ Expr ::= null|x|e.f
ins ∈ Instr ::= x←e|x.f ←y |x←newc|if (?) jmp|return
Figure 1.1: Language Syntax
not formalize the analyses directly on the bytecode but on another language, BIR (Bytecode Intermediate Representation), that will be presented in Chapter 2.
1.3
Background on Static Analysis Through a Tutorial
This thesis formalizes analyses using constraint systems, dataflows equations or type (and) effect systems. Each analysis is presented in the formalism we think is the most appropriate. Of course, theses analysis could all have been presented in the standard framework of abstract interpretation [CC77]. It could have been of interest to prove the optimality of our analyses or to introduce widening operators. However, having a proof of optimality was not one of our main objectives and we did not use any widening operator.
In this section, we propose a tutorial to introduce SA. We present a language with an abstract syntax and show how a program in this language may look like with an example. We also introduce type systems with an example, and show that it is equivalent to a constraint system. Finally, we explain how such a constraint system can be solved.
Figure 1.1 presents the (abstract) syntax of a very small language based on the one that is presented in Chapter 2. We use this language as a base to demonstrate the basics of SA. A program in this language is a record composed of a fieldclasses, which contains the classes of the program, and a field main, which is the only method of the program. Having only one method avoids introducing method calls. A class c is composed of two fields: super, which contains the superclass if the class has one or ⊥otherwise, andfields, which contains the set of fields defined in class c. A field only contains a type annotation. This type annotation is not yet specified and it can be changed depending on the type system we want to specify. A method contains an array of instructions. An expression is the null constant, a local variable, or a field read. An instruction may be an assignment of an expression to a local variable, an assignment of a local variable to a field, an assignment of a newly allocated object to a local variable, or a conditional. All instructions are standard but the object allocation, which runs no constructor, and the conditional, which is a non-deterministic jump: it abstracts standard conditionals and avoids introducing Booleans in our language.
A program in this language may not be valid for several reasons. The instructionif(?) jmp
may jump outside the instruction array if jmp is greater than the instruction array of the method, thesuper field may not describe a class hierarchy, the last instruction of the array may not be a return instruction, one may try to dereference the null constant, or one may try to access a field which is not defined.
1.3. BACKGROUND ON STATIC ANALYSIS THROUGH A TUTORIAL 5 these flaws, with the exception of the dereferencing. Before executing the code, at load time, the Java Virtual Machine (JVM) executes the BCV on each class to check some properties on the code. Among these properties, the BCV ensures that there may be no jump outside the code array, the number of local variables used by each method is below the number of local variables it declares to use, that methods are given the right number of arguments when they are called, etc. The absence of null-pointer dereferencing is not checked at load time by the BCV, it is checked at run time and leads toNullPointerExceptionwhen it occurs.3 To demonstrate static analysis, we assume that the code has already been partially checked and that there is no jump outside the instruction array, that the last instruction is a return and that the relation described by superis indeed a hierarchy. This allows us to define a simple analysis to check the latter property: when a field of an object is accessed, the field is indeed defined in the class of the object or in one of its superclasses.
If the program contains a field access x.f, we need to check that each instance that x
may point to is of a class that defines f. Like for the Java language, we consider an instance has a field if it is defined in its class or in one of its parents. To check this property, we could try to compute all the objects that may be referenced by x, and check that their class defines f; but this is not computable in general, i.e. for some program, such an analysis would not terminate. The main issue is that the number of objects allocated by a program is unbounded (or only by an unknown and huge value, e.g., the number of objects that may fit in the memory of a computer). For the problem to be computable, we need to simplify it, and this can be achieved by abstracting some information. Many abstractions may be defined, we will use here a standard approach for object-oriented languages: we will abstract all objects that may be referenced by a variable by a single class.
Letsuperclasss∈Class×Classbe the relation such thatc1 superclass c2 iffc2.super=c1.
We call c1 the (direct) superclass of c2. Let parent be the transitive closure ofsuperclass. If
c parent c0, we say thatcis a parent of c0, or thatc0 is a subclass ofc, wri