Virtual Human: Storytelling & Computer Graphics
for a Virtual Human Platform
Stefan Göbel1, Oliver Schneider1
, Ido Iurgel1,Axel Feix1, Christian Knöpfle2, Alexander Rettig2
1 ZGDV Darmstadt e.V., Digital Storytelling Department, 64283 Darmstadt, Germany
{Stefan.Goebel, Oliver.Schneider, Axel.Feix, Ido.Iurgel}@zgdv.de
http://www.zgdv.de/distel/
2 Fraunhofer IGD, Department Virtual & Augmented Reality, 64283 Darmstadt, Germany
{Christian.Knoepfle, Alexander.Rettig}@igd.fraunhofer.de http://www.igd.fhg.de/igd-a4
Abstract. This paper describes the usage of Computer Graphics and Interactive, Digital Storytelling Concepts within the Virtual Human project and its technical platform. Based on a brief overview of the Virtual Human approach, global aims and first R&D results, the Virtual Human platform is introduced. Hereby, methods and concepts for the authoring environment, the narration engine and the avalon player as rendering platform are provided as well as an overview of the Direction and Player Markup Language used for interfaces purposes between these components. Finally, our current Virtual Human demonstrator recently presented at CeBIT 2004 in Hannover using these methods and concepts is described and further R&D activities are pointed out within a brief summary and outlook.
1 Motivation
Virtual Human [11] has been initiated as research project funded by the Federal Ministry of Education and Research. The global aim of Virtual Human is to combine Computer Graphics technology provided by the INI-GraphicsNet (Fraunhofer IGD, ZGDV Darmstadt and TU Darmstadt) with speech and dialogue processing technology provided by the German Research Center for Artificial Intelligence (DFKI) in order to develop methods and concepts for “realistic” anthropomorphic interaction agents. In addition, the third major project partner Fraunhofer IMK is responsible for the domain model of the Virtual Human application scenario.
Whereas interactive storytelling techniques are primarily used for the dialogue and narration engine as control unit of the Virtual Human run-time environment, computer graphics technology is used for photo-realistic rendering and appearance of Virtual Human characters within the Virtual Human rendering platform.
Since the Virtual Human project start in late 2002, an early demonstrator has been set up for summer 2003 indicating the basic principles of Virtual Human components. Another major step represented the first integrated Virtual Human demonstrator presented at the CeBIT 2004 exhibition fair in Hannover providing an eLearning scenario.
Fig. 1. Virtual Human presented to the german chancellor Gerhard Schröder and Edelgard Bulmahn, minister of the Federal Ministry of Education and Research at CeBIT 2004
2 Virtual Human Platform
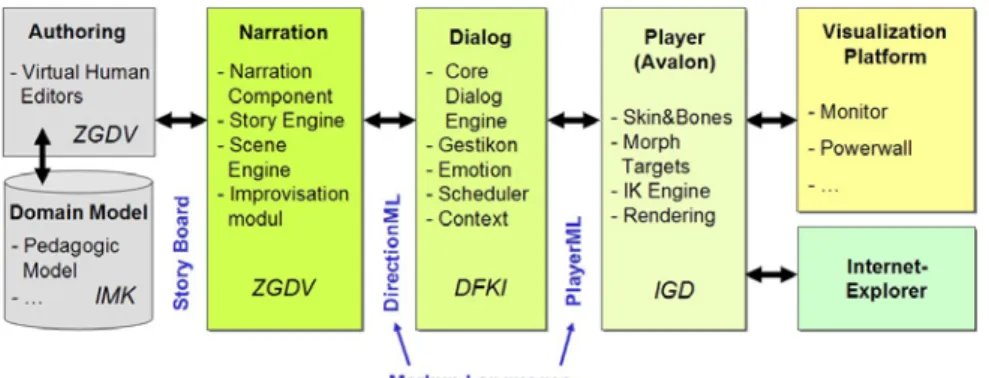
From the technical point of view, figure 2 provides an overview of the major components of the Virtual Human platform and indicates partner responsibilities:
• The content layer consists of a domain model providing geometry, story models and character models, pedagogic models, media, etc.. Furthermore, Virtual Human editors are used to create application scenarios and stories. The output of the content layer is a story board.
• The narration engine consists of a story engine [3] controlling a scene engine [8] and an improvisation module [5]. The output of the story engine are directions coded in Direction ML for ...
• ... the dialog engine. Here, dialogues among virtual characters are generated during run-time and sent to the player component in form of Player ML scripts.
• Finally, the player component based on Avalon [1] creates/renders the 3D environment and sends corresponding data to the visualization platform. • Possible peculiarities of visualization platforms range from simple monitors
or web-based application scenarios up to high-level rendering applications to be shown on a Powerwall.
Fig. 2. Virtual Human Platform – Component based Architecture
The following sections describe these major components of the Virtual Human platform in detail.
2.1 Authoring
Apart from basic Virtual Human editors to control virtual characters, ZGDV in collaboration with Fraunhofer IGD Rostock establish a comprehensive authoring environment enabling authors to configure application scenarios, create stories and characters (inclusive behavior and characteristics of virtual humans) or define interaction metaphors among virtual humans and between users and the VH system.
Fig. 3. Virtual Human Editors – First version providing form based editors (left) and second version using graph based hierarchic visualization techniques (right)
In addition to methods and concepts developed for the Virtual Human editors within the VH project, ZGDV Darmstadt and Fraunhofer IGD Rostock bring in results of their own strategic research in the field of graph based visualization techniques for the creation of storytelling based edutainment applications respectively methods and concepts for game based interfaces for authoring environments [7].
2.2 DML – Direction Markup Language
DirectionML represents a XML-based script-language to initialize a scene. It describes all static scene items such as background, position and orientation of the virtual characters and the virtual camera. The DirectionML is created by the Narration Engine and sent to the Dialog Engine to set up the scene.
Example for using the Direction ML: Scene Initialization <directionML>
<object id="Background"> ....</object> <user id="User"> ... </user>
<character id="Tina">
<position type="absolute"> <point x="-1" y="1"/> <direction> <user id="user"/> </direction> </position>
</character>
<character id="Ritchie"> ...</character> <light> ... </light> < camera > ... </camera> <scene name="greet_user">... </scene>
</directionML>
2.3 Narration Engine
The Narration Engine controls both the narrative and the didactic progress of a session. For this, the Narration Engine executes concurrently declarative story and learning models, which are represented as XML documents. Those models guide the choice of "scenes", which are elementary portions of the variable story line, usually taking place at a single place and time.
Thus, during run-time story creation, scenes are subsequentially chosen out of a pool of scenes, according to their appropriateness with respect to the learning and the dramatic situation.
From a technical point of view, a single scene consists of XML-directions, formulated either in DirectionML or directly in PlayerML (see next paragraph). In the first case, the engine issues abstract commands to the CDE (Conversational Dialogue Engine), which then leads the conversation accordingly, assembling sentences out of data base information. E.g., a direction to the CDE could have the meaning of "discuss the composition of the sun in an Q/A-manner in 2 minutes." In the second case, the directions are concrete dialogue acts, together with corresponding animations, which are displayed without further refinement. This is especially important for sections where the author wants to define every detail of the gestures and words of the virtual humans, or for dialogues and events which cannot be appropriately generated by the CDE.
2.4 PML – Player Markup Language
The Player Markup Language (PML) is a XML based Markup Language which takes up concepts from the RRL (rich representation language) [10]. PML defines a format for sending instructions (commands) from the dialog-manager to a 3D virtual reality system (VR player Avalon [1]). It. Additionally it defines a message format which can be sent to a player or received from it.
PML scripts are strictly scene-based. A scene describes the 3 dimensional space containing objects and virtual characters as well as all possible actions for objects or characters (e.g. movement, animation, interaction).
At the beginning of a new scene all static objects and characters are defined by sceneDefinition scripts. During the scene actions scripts describe all run-time dependent actions depending on their temporal appearance. PML distinguishes between SceneActions, CharacterActions and WorldQueries. Hereby, SceneActions represent actions depending on the virtual environment (e.g. fade-in or fade-out of Objects). CharacterAnimations are actions which a virtual character can achieve (e.g. talking, smiling, walking).
Altogether, PML is an abstract specification language. It is independent of the implementation of the VR player and the virtual environment. But any players used have to convert the abstract definitions of PML to their own set of commands.
PML is used as descriptive interface markup language between a dialog creating environment (dialog engine) and the VR player and synchronizes all steps of dialog-generation. In the first step a very common representation of the dialog is generated. In the next step additional information (e.g. emotion, timing for lip-synchronization) augments the dialog-skeleton. In the third step the dialog is enhanced by using fitting animations like mimic and other animations. The result is a script with abstract commands to the player which is sent by the scheduler to the player.
The following example shows a slightly simplified PML actions script. The animation tags refer to preloaded animations, which are referenced by their name. In complete PML the tag sentence would contain a list of phonemes including their duration, which are mapped by the system to facial animations, as well as a source URL of an audio file, which contains generated speech.
<playerML id="s1"> <actions>
<characterAct id="ca2">
<character refName="Sven"/>
<animation id="a3" refName="pride"/> <sentence id="s4">
<text>This sentence shall be spoken proudly. </text>
</sentence>
<animation id="a5" refName="progress"/> <temporalOrder>
<seq> <par>
<act refId="s4" begin="300" dur="3700"/> </par>
<act refId="a5" begin="0" dur="2000"/> </seq> </temporalOrder> </characterAct> <temporalOrder> <seq> <act refId="ca2"/> </seq> </temporalOrder> </actions> </playerML> 2.5 Avalon Player
Avalon is a component based Virtual and Augmented Reality system developed and maintained at ZGDV Darmstadt and Fraunhofer IGD. Within Avalon the behavior of the virtual world is defined by a scene graph following and extending the concepts of VRML/X3D [2]: The scenegraph describes the geometric and graphical properties of the scene as well as it's behavior. Each component in the system is instantiated as a node, which has specific input and output slots. Via connections between the slots of the nodes (called routes), events are propagated, which lead to state changes both in the behavior graph and usually in the visible representation from render frame to render frame. Events are generated by different sensor nodes exclusively, which may receive data from input devices controlled by the user and from internal sensors like CollisionSensors, which can detect collisions of objects or - most important for animations - the TimeSensor, which can generate timer events every frame. The rendering backend of Avalon is OpenSG [6], an open source high performance and high quality scenegraph renderer, which has been developed in majority by members of the INI-Graphics Net since 2001.
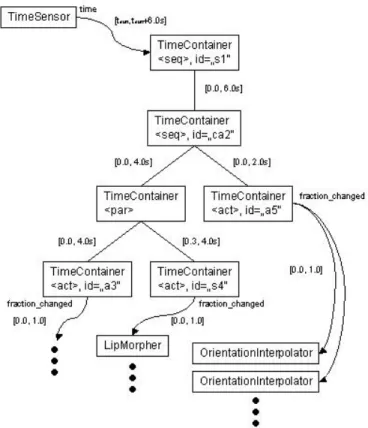
One major advantage of the architecture of Avalon is that new functionality can be integrated quite easily by adding respective nodes. For the Virtual Human prototype a few nodes needed to be written. Almost all the animation and sound replay stuff could be done with the already existing nodes. One new node, the PmlInterface node, performs the parsing of PML and constructing the appropriate behavior sub-graphs accordingly (mainly a time graph). For the time graph we implemented a node type TimeContainer (the naming follows the SMIL 2.0 standard [9]). This node performs the conversion between the respective local times up to the mapping of the final animation duration time to the fraction of the key frame interval, which is used to play the VRML animations.
The following figure shows the time graph corresponding to the PML example above to illustrate the mapping to VRML-like data structures.
Fig. 4. Example of a time graph. Squarebrackets contain the relative time as mapped by the respective TimeContainers (note that PML describes time in milliseconds, whereas Avalon uses the VRML compliant unit second). Arrows resemble routes, which connect the time graph with other nodes in the behavior graph as e.g. Interpolators, which hold animation data
3 Virtual Human Demonstrator
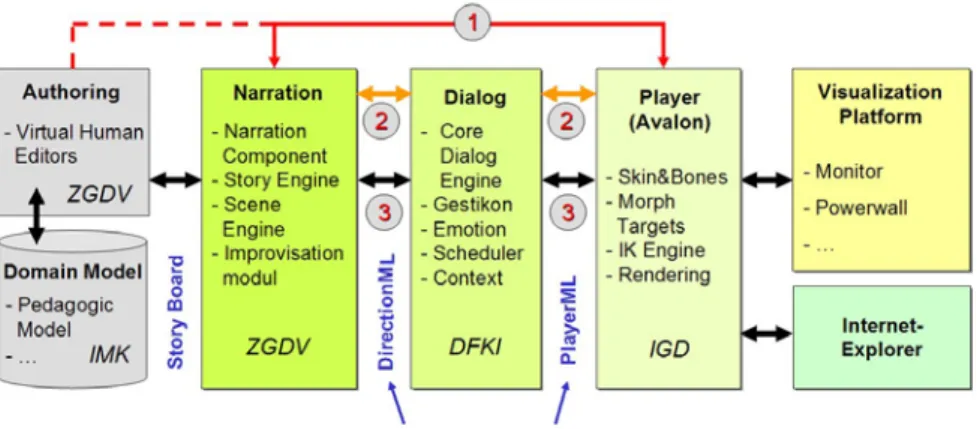
The Virtual Human platform in some way is very generic allowing to replace/exchange components by other components providing the same functionality and following the well-defined interfaces. Further on, it is scalable referring to the intelligence of the system. Subsequently, their different “levels of intelligence” for Virtual Human demonstrators and prototypes, see figure 5:
1. The most simple level consists of predefined scenes and dialogues created within in the authoring environment and directly sent to the player. In a
second step predefined scripts are smoothly modified (assembled) and processed by the Narration Engine as control unit of the VH platform. No interaction is possible in this level.
2. Using the Dialog Engine to create dialogues during run-time, intelligence is brought into the system. Thus it is possible to generate very free commands by the Narration Engine such as “Tina is talking to a user” or “Ritchie is greeting the user”. Hereby, commands are coded in Direction ML and sent to the Dialog Engine. The Dialog Engine generates commands such as speech acts (Tina says “My friend Ritchie and me welcome you!..”) and send these commands to the Player using Player ML.
Within this second level, predefined interactions are possible.
3. In a third intelligence level, bidirectional communication between the VH components is enabled taking into account events caused by user interactions. Hence, the story becomes very variable and users are totally involved in the application and become “authors of their own story”. In this sense Virtual Human represents a platform for Interactive Storytelling applications.
Fig. 5. Virtual Human Platform – Interaction level concept
Since project start in 2002, various VH demonstrators have been established, for example for the CeBIT 2004 a Virtual Human system consististing of a Dialog Engine from the DFKI and Avalon as player component was presented. Hereby, the virtual characters are realistic models designed by Charamel in 3ds max / character studio, which have been exported with a VRML exporter provided by INI-Graphics Net resulting in H|Anim 2001 [4] humanoids to be used within the Avalon VR player. In this scenario, user interaction is limited to multiple choice selections.
Fig. 6. The Virtual Human Demonstrator at CeBIT 2004. (Background model courtesy of rmh new media GmbH, Character models courtesy of Charamel Software GmbH)
4 Summary and Outlook
By the cooperation of leading research groups in Germany in the research fields of computer graphics and multi-modal user interfaces, a world-wide leading position in the development of virtual characters as personal dialogue partners is aspired.
Since project start in November 2002, a global architecture of a Virtual Human platform consisting of different components and interfaces have been established. First demonstrators indicate the enormous potential of Virtual Human concepts and usage in a wide-spread range of application scenarios. For example, the project team has successfully presented a Virtual Human learning scenario at CeBIT 2004, which was presented both on a traditional and simple physical setup with a PC and usual monitor but also on a high-end Powerwall providing appropriate visualizations for high-resolution images and photo-realistic Virtual Humans.
Within Virtual Human, at ZGDV and Fraunhofer IGD current research effort is spent on the definition of Direction and Player ML, the development of the Narration Engine and its integration with the Dialog Engine, the integration of dynamic hair simulation, realistic real time skin and hair rendering, inverse kinematics for
humanoids or seamless motion blending with multiple animation channels. Further aspects, methods and concepts are brought in by the Virtual Human project partners resulting in a very interesting and promising project with fruitful collaboration among all partners and enormous results.
Whereas the project team has been concentrated on the establishment of early demonstrators and a stable application scenario for eLearning during the first project phase, now the focus is settled on integration issues and the adaptation of the Virtual Human platform for additional application scenarios such as interactive game/quiz shows, personal service or management training.
References
1. Avalon Virtual Reality System, http://www.ini-graphics.net/~avalon
2. Behr, J., Dähne, P., Roth, M.:Utilizing X3D for Immersive Environments. Web3D 2004 Symposium, Monterey
3. Braun, N.: Automated Narration – the Path to Interactive Storytelling. Proceedings NILE, Edinburgh, Scotland (2002) 38-46
4. H|Anim Humanoid Animation Working Group, http://www.h-anim.org
5. Iurgel, I.: Emotional interaction in a hybrid conversational group. In: Prendiger, H. (ed.): International Workshop on Lifelike Animated Agents. Working Notes in Proceedings PRICAI-02, Tokyo, Japan (2002) 52-57
6. OpenSG, an open source scenegraph renderer, http://www.opensg.org
7. Schneider, O.: Storyworld creation: Authoring for Interactive Storytelling. Journal of the WSCG, Plzen, Czech (2003) 405-412
8. Schneider, O., Braun, N.: Content Presentation in Augmented Spaces by the Narration of Interactive Scenes. Proceedings AVIR, Geneva, Swiss (2003) 43-44
9. Synchronized Multimedia Integration Language (SMIL 2.0), http://www.w3.org/TR/smil20 10. The NECA RRL, Information on Neca’s Rich Representation Language,
http://www.ai.univie.ac.at/NECA/RRL