Submittedin:March2013 Acceptedin: April2013 Publishedin:January2014
Recommended citation
Ril, Y., Toll, Y.C. & Fonseca, E. (2014). Determinationofwritingstylestodetectsimilaritiesindigitaldocu
Abstract
Anythinginvolvinghumanintellectisatriskofbeingplagiarised. Thisincludesscientificandliterary workssuchasarticles, theses, audiovisualworks, plans, projectsandcomputerprograms. However,
thisarticlepaysspecialattentiontotheexistenceofthisphenomenoninwrittenworksingeneral,
andindigitaldocumentsinnaturalorprogramminglanguagesinparticular. Theobjectiveofthe
researchistodevelopandapplyamathematicalmodelthatallows thewritingstyleusedinthe
draftingoftextstobedetermined. Theresultsobtainedfromtheapplicationoftheprocedureare
intendedtoserveasthebasisforreducingthenumberofdocumentsthatneedtobecomparedin
ordertoanalyseanddetectsimilaritiesinthem. Theprocedurewasexperimentallyappliedtoasetof articlesclassifiedbytopicandauthor, wherethewritingstylesusedtodraftthemdiffered.
Keywords
writingstyle, digitaldocuments, plagiarism, procedure
Determinación de estilos de escritura para la detección de similitudes
entre documentos digitales
Resumen
Todo lo inherente al intelecto humano es susceptible de actos de plagio: obras científicas y literarias tales como artículos, tesis, obras audiovisuales, planos y proyectos, códigos fuentes de programas, entre otros. Sin embargo, el presente trabajo dedica especial atención a la existencia de este fenómeno en obras escri-tas, en concreto documentos digitales provenientes de lenguajes naturales o de programación, y centra su objetivo en el desarrollo y aplicación de un modelo matemático que permite determinar el estilo de escri-tura empleado en la redacción de los textos. Los resultados que se esperan obtener a partir de la aplicación del procedimiento servirán de base para la reducción en el número de documentos que se deben comparar en el análisis y detección de similitudes entre estos documentos. De forma experimental se aplica el proce-dimiento a un grupo de artículos clasificados por temáticas y autores y que difieren entre ellos en el estilo de escritura utilizado para su redacción.
Palabras clave
estilo de escritura, documentos digitales, plagio, procedimiento
1. Introduction
The advantages offered by information and communication technologies (ICTs) are irrefutable andborneoutbynumerousexamples. However, alongwiththepositivescomethenegativeslike plagiarism, whichisundoubtedlyoneofthemostillustrativeexamples. TheReal Academia Española,
theinstitutionresponsibleforregulatingtheSpanishlanguage, definestheSpanishterm ‘plagiar’ (Real AcademiaEspañola, 2001)– ‘toplagiarise’inEnglish–inasimple, categoricalmanner: “Copiar en
lo sustancial obras ajenas, dándolas como propias”. A definitioninEnglishofthetermis “toappropriate
Anythinginvolvinghumanintellectisatriskofbeingplagiarised. Thisincludesscientificandliterary
workssuchasarticles, theses, films, sheetmusic, audiovisualworks, plans, projects, computerprograms
andwebsites. However, thisarticlepaysspecialattentiontotheexistenceofthisphenomenonin
writtenworksingeneral, andindigitaldocumentsinnaturalorprogramminglanguagesinparticular.
Using elements from other works isacommon practice. The way itisdone determinesthe
intentionality of respecting– or otherwise– the authorship ofthe sources. Among thevarious
methodsusedarethefollowing:
R Correct: the provenance of the referenced textual material is accurately shown, adding
informationabouttheauthoroftheworkcited.
R Paraphrasing:basedonaninterpretation, certainideasfromotherdocumentsareexpressed
inanauthor’sownwords.
R Multiple sources:anewdocumentiscreatedbythetextualormodifieduseoffragmentsof
textfromotherdocuments.
R Mosaic:segmentsofanoriginaldocumentaredisarrangedsoastobetextuallyusedinanew
document.
R Odd modifications:segmentsofanoriginaldocumentareusedwhilewordsorphrasesare
insertedtomodifythem.
R Copying and pasting:thedocumentiscopiedinpartorinfullwithoutanymodifications. This
isrelativelyeasytodetectbydoingacomparisontodeterminewhetherornotthereareany
differencesbetweenthedocuments.
Technologicaladvancesmeanthatsystemsarenowavailabletodetectplagiarismindocuments;
however, humansupervisionoftheprocessisstillessential. Anaccusationofplagiarismisserious
andshouldnotbemadelightly. The useofautomated toolsreducesthenumber ofdocuments
thatrequirehumaninterventionbydifferentiatingbetweenthem, sometimesusingheuristics, as
isthecasefordeterminingthattheoriginalofseveralsimilarwebsitesistheonewiththehighest
ranking. Forcomparisonsbetweenworksdonebystudents, theonebythestudentwiththehighest
performancecouldbeconsideredtheoriginal. Unfortunately, theseheuristicsarenotalwaysvalid,
anditisnotevenpossibletobesurethattheyaresointhemajorityofinstances. Asisoftenthecase,
theproposedanalysisdependsonasubjectiveassessment. Thus, fromthispointforward, theterm
‘determinationofsimilarities’willbeusedinsteadof ‘plagiarism’.
Manyarticleshavediscussedtopicsrelatingtothedeterminationofsimilarityindocuments. Of
particularnoteamongtheseare:
“Detecting similar documents using salient terms” (Cooper et al., 2002)
Thecomparisonbetweentwodocumentsisdonebypre-processingbothandsearchingfortokens1
definedinadvance, suchaspropernouns, acronyms, locations, abbreviations, etc. AnInformation
1. A token, alsocalleda ‘lexicalcomponent’, isastringofcharactersthathasacoherentmeaninginaparticularnaturalor
Quotient(IQ)(Cooperetal., 2002)isassignedtoeachterm, whichisequivalenttotheamountof
informationthatitsappearanceinthetextprovides. Thescoreforthesimilarityintwotextsreflects
proportionalitywiththenumberoftermsappearinginonedocumentbutnotintheother.
“Tool support for plagiarism detection in text documents” (Gruner & Naven, 2005)
A methodisshownfortheanalysisofwritingstylesonthebasisofstatisticalbehaviour. Itseeksto
determinehowlanguageisusedbytheauthorandtocompareitwithotherdocuments. Thesearch
forstylescanbeperformedonparagraphsoronfragmentsoftext.
“Check: a document plagiarism detection system” (Si et al., 1997)
Itdeterminessimilarityonthebasisofhowoftenthetermsappear. A weightingsvectorforeach
compareddocumentsisgenerated, andthecosinebetweenthesevectorsisusedasaparameter
inafunctionthatreturnsanestimateofsimilarity. Theprocedureisrepeatedforeachsectionofthe
documentsuntiltheexistenceorotherwiseofcopyingbetweenthemisdetermined.
“Sim: a utility for detecting similarity in computer programs” (Gitchell & Tran, 1999)
Thearticleisaboutdetectingsimilarityinprograms. Theprogramsareseparatedintotokensinorder
tothencalculatethealignment scorebetweentwotokenstreams. Eachgapormismatchinthe
alignmentisassignedaweighting. Thesimilarityiscomputedusingtheexpression:
Where score (p1, p2)isthealignmentscorebetweenprogram1andprogram2.
“Plagiarism in natural and programming languages: an overview of current tools and
technologies” (Clough, 2000)
Itsummarisesasetoftoolsavailablefordetectingsimilaritiesintextsinnaturalorprogramming
languages. Itconciselydescribesthedistinctiveelementsofsomealgorithmsusedbythosetoolsto
performcomparisons, asisthecasefordeterminingtheLongestCommonSubsequence.
The objectiveofthe researchistodevelopandapplyamathematicalmodelthat allowsthe
writingstyleusedinthedraftingoftextstobedetermined.
Research method and theory used
In ordertoconducttheresearch, variousscientificmethodswereused. Forexample, aliterature
reviewwasconductedtolookforsourcesofinformationtotheoreticallyunderpinthestudy. Analysis
andsynthesismethodsweregenerallyusedthroughouttheresearchprocess, andparticularlyfor
specifyingthetheoreticalfundamentalsrelatingtothedetectionofsimilaritiesindigitaldocuments,
andtotheanalysisandinterpretationoftheresultsobtained fromtheapplicationofthetoolto
detectplagiarismindigitaldocuments. Inaddition, descriptivestatisticswereusedtoprocessthe
[I]
s 2 = score (p1,p2)
data obtained from the applicationof the tools todetect similarities in digital documents, and
inferentialstatisticswereusedtomakedecisionsaboutwhetherornottorejectthedataobtained
fromtheprocessfordetectingsimilaritiesindigitaldocuments.
2. Development
Inthecaseofsystemsfordetectingsimilaritiesindocuments, thebiggestchallengeistheenormous
volumeofdatathathastobeprocessed;thatiswhyapre-classificationofthewholesampleorthe
originaldocumentsavailableforthecomparisonisrequired.
The criteriataken intoaccountfor the classification ofteninclude documenttype, language,
category, subcategory, keywords, authorsanddates. Ourproposalistoincorporatewritingstyleas
acomparativecriterionwhenitcomestodeterminingwhetherornotadocumentisoriginal. Thus,
thenumberofdocumentstobecomparedinthesearchforsimilaritieswouldbereducedtothose
thathaveadirectrelationship–intermsofclassification–withthecompareddocument, whichin
turnhaveasimilarwritingstyle.
2.1. Procedure for writing style extraction
Anytextcanberepresentedbyastatisticalmodelthatidentifiesitsintrinsiccharacteristics, which
relatetotheauthor’swritingstyle. Amongthesewewouldmention:
Stop words: thisreferstotheuseofarticles, adverbs, prepositionsandconjunctions. Thefrequency
withwhichthesewordsareuseddenotestheauthor’swritingstyle. Consequently, stopwordmean
isdefinedas:
WherePpisstopwordmean, CppisthenumberofstopwordsusedandTpisthetotalnumberof
wordsinthetext.
Level of difficulty: determines thelevel ofeducation thatsomeone needs tohavein order to
understandthetext. Thereareseveralindicesavailabletocalculatethislevel. Gunning(Wikipedia,
2011), DaleandChall(1948)andFlesch-Kincaid(DuBay, 2004)aresomeofthem, althoughthelatter
isthemostcommonlydocumentedandcited.
TheexpressiontodeterminetheFlesch-Kincaidindexisasfollows:
[II]
Pp CppTp * 100 %
[III]
Where λ is the mean ofone-syllable wordsper 100words, and βis themean sentence length
measuredbythenumberofwords.
Richness of vocabulary:proposedby Honoré (1979), thistriestodeterminetherichnessofthe
author’s vocabularyon the basis of the totalunrepeated words usedin the text. The following
expressionisusedforthatpurpose:
WhereMisthenumberofdifferentwordsinthetext.
Dependingonthetypeofdocumentbeinganalysed, thecalculationofRhasmoreorlessvalidity.
Certainspecialistarticlesandcomputerprogramsaregoodexamplesofthis, as theirverynature
requirestheconstantrepetitionofwords.
Asaconsequenceoftheabove, anapproachproposedby Yule(1944)isintroducedasacalculation
alternative, defining:
WhereViisthenumberofwordsthatappearitimesinthetext. Mhasthesamemeaningasinthe
previouscalculation.
Mean sentence length:isareliablemeasureofgrammaticalknowledgethattheauthorusesinthe
compositionofsentences.
Whereloiisthelengthinwordsofthesentenceoccuringinpositioni, Noisthetotalnumberof
sentencesandTpisthetotalnumberofwordsinthetext.
Mean word length:thistermisdirectlyconnnectedwiththerichnessoftheauthor’svocabularyand
measureshisorherabilitytousecomplexwords2.
2. Complexwordsareconsideredtobethoseformedbythreeormoresyllablesthatdonotrepresentpropernouns, prefixes,
suffixesorcompoundwords.
[IV]
R 100 log (M)M2
[V]
K 10
4 (
-i' 1 i2Vi<M)
M2
[VI]
Lp0 -i
No
1 loi
No
Tp No
[II]
WhereLppismeanwordlength, Tcisthetotalcharactersused(excludingspaces), andTpisthetotal
numberofwordsused.
The finaldefinitionisthatofthe writing stylevector (E), whosecomponents aredescribed
above:
Whileitistruetosaythedeterminationofanauthor’swritingstyleimpliessomedegreeofuncertainty,
knowingwhatthatdegreeisenablesasuitablemarginofdeviationtobeestablishedwhenitcomes
todeterminingwhothecreatorofadocumentis. Amongthemainparametersthathaveaninfluence
onuncertaintyarethetopiccovered, thedocumentlength(intermsofthenumberofparagraphs,
sentencesorwordsused), theauthor’sexperienceandthedocumentenduser.
Havingastatisticalestimateofthewritingstyleisimportanttoensurethatthereisacomparative
criterionforselectingandclassifyingdocuments, andfordeterminingtheirauthorship. Oneofthe
applicationsisthedeterminationofsimilaritiesindocuments, whereprocessingtimeneedstobe
optimised. The materialstobecomparedarestoredonvastdatabases, soprocessingeverything
isnotanoption, norisprocessingonlythosedocumentsbelongingtooneclassificationcategory.
Otherarguments are required todifferentiate betweenand considerably reducethe numberof
documentstobeprocessed, likeawritingstyleidentifier, forexample.
3. Research analysis and results
Inordertoapplytheproposalfordeterminingwritingstyles, 37documentsby5authorsin4thematic
areaswereselected:education, history, medicineandchildren’sstories. Twooftheauthorsbelongto
thethematicareaofmedicine. Chart1showsthedocumentdistributionbythematicarea.
EDUCATION HISTORY MEDICINE STORIES
14%
27%
32%
27%
Chart 1.Document distribution by thematic area
[VIII]
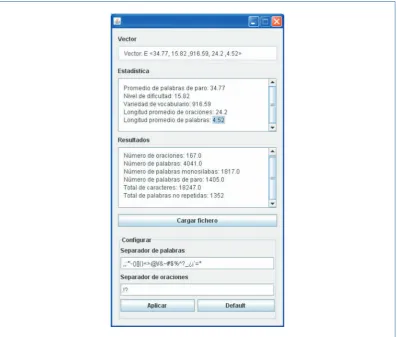
Inordertoautomaticallydeterminethewritingstylevector, atoolwasdeveloped(Figure1)toenable
theextractionofasetofstatisticsfromthetextsanalysedasthesteppriortocalculatingthevector.
Figure 2.Tool for calculating the style vector
The characteristicsextractedfrom the documentsare listedbelow (to aid understanding ofthe
contentofFigure1fornon-Spanishspeakers, theEnglishtranslationofeachcharacteristicisgiven
inbrackets):
R Promedio de palabras de paro (Stopwordmean)
R Nivel de dificultad (Levelofdifficulty)
R Variedad de vocabulario (Richnessofvocabulary)
R Longitud promedio de oraciones (Meansentencelength, measuredinwords)
R Longitud promedio de palabras (Meanwordlength, measuredincharacters)
R Número de oraciones (Numberofsentences)
R Número de palabras (Numberofwords)
R Número de palabras monosílabas (Numberofone-syllablewords)
R Número de palabras de paro (Numberofstopwords)
R Total de caracteres (Totalcharacters)
Inordertodeterminetrendsandothersstatistics, aMicrosoftOffice2007 spreadsheetwasused.
Table1showsthemeanvaluesobtainedforthestylevectorcomponentsforeachauthor. Aswecan
see, theparameterthatmakesthebiggestdifferenceisrichnessofvocabulary. Authors1and2stand
outinthiscase, whocoverededucationandhistorytopics, respectively. Inparticular, author2hasthe
lowestlevelofdifficultyowingtotheuseofeasilyunderstandablenarrativedocuments.
Foreachauthor, itisessentialtodeterminehowthewritingstyleparametersvary, thatistosay,
whethernotaparticularauthorisabletomaintainhisorherwritingstyleacrossasetofdocuments
on thesame topic. Ananalysis was performed on eachvector parameter tocalculate its mean
deviation, asshownin Table2. Ascanbeanticipatedfromtheinformationshownintheprevious
table, itispreciselytherichnessofvocabularyparameterthatvariesthemost, andthemeanword
lengthparameterthatvariestheleast–solittlesothatitwasnecessarytoincreasethenumberof
decimalplacestothree.
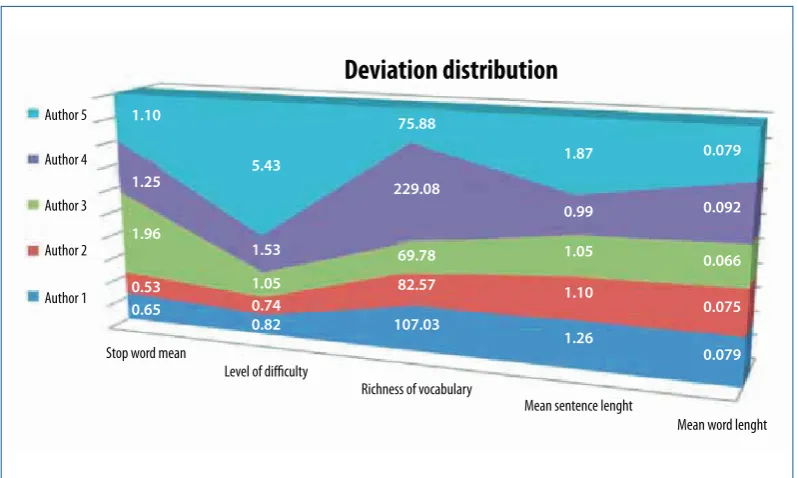
Chart2showsthedistributionofdeviationsthroughagraphicrepresentation ofareas. Aswe
cansee, author2hasthemostconsistentwritingstylebecausethearearepresentingit(red)ismore
uniform. Theoppositeisthecaseforauthors4and5, whohaveseveralpeaksandtroughsintheir
respectivedeviationdistributionareas.
Despitethefactthatauthors3and4bothbelongtothethematicareaofmedicine, thereisa
considerabledifferenceintheirwritingstyles.
Table 1.Style vector means by author
Stop word mean Level of difficulty Richness of vocabulary Mean sentence lenght Mean word length
Author 1 37.49 21.89 2482.43 20.46 5.314
Author 2 35.88 11.40 2357.63 30.39 4.742
Author 3 30.52 26.88 1011.01 12.41 5.162
Author 4 24.21 28.96 1121.34 10.57 5.356
Author 5 33.34 26.70 665.76 12.54 4.399
Table 2.Mean deviations by vector parameter
Stop word mean Level of difficulty Richness of vocabulary Mean sentence lenght Mean word length
Author 1 0.65 0.82 107.03 1.26 0.079
Author 2 0.53 0.74 82.57 1.10 0.075
Author 3 1.96 1.05 69.78 1.05 0.066
Author 4 1.25 1.53 229.08 0.99 0.092
Theproposedmethodfordeterminingwritingstylescanbeusedinascenariowhereitisnecessary
todescribedocumentswhoseauthorshiphasbeenvalidated. Somedescriptorsarecommonlyused,
suchasauthor, title, keywords, category, subcategoryanddocumenttype, yethavingadescriptor
likewritingstylewillenableareductioninthenumberofdocumentsthatneedtobecompared
inthesearchfor possibleplagiarism. Inthis respect, whentheaimistoanalysethepresenceof
plagiarisminanewdocument, itwillonlyneedtobecomparedwithasub-setmadeupofthose
withasimilarwritingstylevector.
Althoughitispossibletostartwiththeideathateveryauthorhasauniquewritingstyle, itis
neverthelessimportanttoconsiderthat themainthreatstothevalidityofthis methodresidein
the selection of documentsto determinean author’s writing style. They should be documents
whoseauthorshiphasbeenauthenticated, whilebearinginmindthatmorethanoneauthormay
have participatedin the drafting of adocument. Whenthe document is notaboutone ofthe
topicscustomarilycoveredbytheauthor, itisacceptableforthedeviationindicestovarywithin
areasonablerange. Thus, itisadvisabletousedocumentsontopicsthattheauthorusuallycovers.
Finally, thereareotherelementsthatareequallyasimportant, suchasthelearningprocessandthe
changingrealitysurroundingtheindividual, whichgraduallygiverisetovariationsineveryauthor’s
writingstyle. Inthisrespect, thedeterminationofwritingstyleswillbemorereliablewhen, fromthe
viewpointofwritingstyle, theindividualismorematureandexperienced.
Figure 3. Deviation distribution areas
Stop word mean
Level of difficulty
Richness of vocabulary
Mean sentence lenght
4. Discussion and conclusions
Theproposedprocedurefocusesonthedeterminationofwritingstylesandenablestheacademic
community to observe similarities in documents. However, it does not constitute a definitive
solutiontotheseriousproblemofacademicplagiarism. Mindful, systematictraininginvaluessuch
asresponsibilityandhonestyisrequired.
Whyinsist onacademichonesty? If academichonesty isnon-existent, thenan impressionof
knowledgewillbegiventhatdoesnotmatchtherealityofwhatisgenuinelyinthecognitivestructure.
Dishonestbehaviourintheacademicsphereisameansofdeceitand, aboveall, ofself-deceit. It
erodesthecoreoftheeducationalaimofourteachingactivity. Owingtoitsethicalnature, wemight
assumethattheconceptofhonestyisimplicit, butthisassumptionisnotabsolutelycertain. Actsof
plagiarismmaybecommitteddeliberately, accidentallyorunknowingly.
Whatcanbedonetostrengthenthesevaluesamongourstudents? Whenweshowprofessional
coherenceand commitment, creatinga high-levelpedagogicalandintellectual atmosphere, we
managetoeliminateorreduceacademicdishonestyanditsnegativeeffects. Inhighereducation, there
areclearlymajoropportunitiestolearnand, atthesametime, majoropportunitiestodefraud. Insome
ways, wetrustthatmostofthestudentsareawareoftheirobligationstolearn, influencedbytheneed
togetadegree. Oureducationfunctioncannotbelimitedtotheuseoftoolstooverseeplagiarism;this
doesnotguaranteethatthestudentswillnotactfraudulently. Wemustinsistonthefactthatethical
behaviourisbasedonfreeacceptanceoftherulesofconductthatcannotbeimposedbyforceofauthority.
Fromaveryyoungage, humanbeingsgraduallyenrichtheirvocabulary, gainmoreexperienceand
training, anddeveloptheirwritingstylesastheylearn. Thatiswhythecreationofauniquewritingstyle
isperceivedasaslowprocess. Infuturestudies, theintentionistoexplore(a)theproceduresinorder
toobtainthedevelopmentcurvesforwritingstyles, and(b)thecharacterisationofthesestylesonthe
basisoftheparametersdescribingthem, allofwhichhaveformedafundamentalpartofthisstudy.
Theappropriationofthird-partyworksasone’sownwillcontinueandevolveatthesamepace
astechnology, sobeingreadytocounteractthisphenomenonisofvitalimportance. Mostofthe
studiesreviewedforthisresearchwillformthebasisforthedevelopmentoffutureworksonthe
detectionofsimilarities indocuments, andtheproposalpresentedherewillserveas thestarting
pointfordeterminingwhichdocumentstocompare. Theextractionofthestylevectormarksthe
differencebetweenauthors, whetherornottheycoverthesametopic. Byapplyingtheproposed
mathematicalmodeltoaconsiderablesetofdocuments, itwasfoundthattrendsreallydoexist
whenitcomestodrafting, andthatsuchtrendsputastampofauthenticityontoadocument.
References
Clough, P. (2000). Plagiarisminnaturalandprogramminglanguages:anoverviewofcurrenttools
andtechnologies. Research Memoranda: CS-00-05, Department of Computer Science, University of
Cooper, J. W., Coden, A. R., & Brown, E. W. (2002). Detectingsimilardocumentsusingsalientterms. In
Proceedings of the 11th international conference on Information and Knowledge Management. New
York, NY: ACM. Retrievedfromhttp://www.labsoftware.com/flahdo/Papers/CIKMDuplicates.pdf
Dale, E., & Chall, J. S. (1948). A formulaforpredictingreadability. Educational Research Bulletin, 27(1),
11-20. Retrievedfromhttp://www.ecy.wa.gov/quality/plaintalk/resources/classics.pdf
Dubay, W. H. (2004). The principles of readability. CostaMesa, CA:ImpactInformation. Retrievedfrom
http://files.eric.ed.gov/fulltext/ED490073.pdf
Gitchell, D., & Tran, N. (1999). Sim: autility for detectingsimilarity in computer programs. In The
proceedings of the 30th SIGCSE technical symposium on Computer Science Education. New York, NY:
ACM. Retrievedfromhttp://www.eng.uwi.tt/depts/elec/staff/feisal/ee302/sim-gitchell.pdf
Gruner, S. & Naven, S. (2005). Toolsupportforplagiarismdetectionintextdocuments. InProceedings
of the 2005 ACM symposium on Applied Computing. New York, NY: ACM.Retrievedfrom http://
dl.acm.org/citation.cfm?id=1066677.1066854. doihttp://dx.doi.org/10.1145/1066677.1066854
Honoré, A. (1979). Somesimple measures of richness of vocabulary. Association for Literary and
Linguistic Computing Bulletin, 7(2).
Plagiarise(n.d.). In The Collins English Dictionary. Retrievedfromhttp://www.collinsdictionary.com/
dictionary/english/plagiarise
Real AcademiaEspañola(Ed.)(2001). Diccionario de la Real Academia Española. Madrid, Spain:Real
AcademiaEspañola.
Si, A., Leong, H. V., & Lau, R. W. H. (1997). Check:adocumentplagiarismdetectionsystem. InProceedings
of the 1997 ACM symposium on Applied Computing. New York, NY: ACM. Retrievedfrom http://
www.cs.cityu.edu.hk/~rynson/papers/sac97.pdf. doihttp://dx.doi.org/10.1145/331697.335176
Wikipedia (2011). Gunning fog index. Wikipedia. Online: Wikipedia.org. Retrieved from http://
en.wikipedia.org/wiki/Gunning_fog_index
Yule, G. U. (1944).The statisticalstudy ofliteraryvocabulary. Journal of the Royal Statistical Society,
107(2), 129-131. Retrievedfrom http://www.jstor.org/discover/10.2307/2981280?uid=3737824&