2017 2nd International Conference on Wireless Communication and Network Engineering (WCNE 2017) ISBN: 978-1-60595-531-5
A Point-of-Interest Recommender System
Based on Factorization Machines
Long-fei TU and Dong WANG
*Shanghai Jiao Tong University, Shanghai, China *Corresponding author
Keywords: Point-of-Interest, Factorization Machines, Recommender Systems
Abstract. With the rapid development of location-based social networks (LBSNs), Point-of-Interest (POI) recommendation which can benefit both users and service providers has attracted much academic and industrial interest. Although various aspects of users' behavior data have been utilized in POI recommendation, challenges such as data sparsity and how to accurately model users' preferences exist. In this paper, we propose a model named as Geo-STFM which exploits social, temporal and geographical information for POI recommendation based on factorization machines. Specifically, we first give a precise analysis of the self-similar and other-similar characteristics in users' behaviors, and accordingly propose an improved factorization machines (FM) model with social and temporal regularization terms. Then, geographical information is fused into the model to build a POI recommender system. The experimental results on two real-world data sets show that our proposed method achieves remarkable improvements compared to the state-of-the-art POI recommendation techniques.
Introduction
The mobile internet has developed rapidly in recent years, which results in the prosperity of location-based social network (LBSN) services such as Facebook Places, Foursquare and Gowalla. Users behaviors in these LBSNs include checking-in a Point-of-Interest (POI, e.g., cinemas, restaurants and stores), interacting with friends and sharing experiences associated with the checked-in POIs, etc. Correspondingly, these behavior data can be utilized to make POI recommendations that not only help users discover more POIs but also benefit for businesses to find more potential customers. Actually, building an accurate personalized POI recommender system is a crucial demand in LBSN services.
Although varieties of users' behavior data can be collected, challenges still exist. Firstly, the preference of a user is hard to capture since a user's decision process of checking-in a POI can be influenced by many factors which are difficult to be modeled. Social influence, temporal influence and geographical influence are generally the most important factors in a user's decision process. For example, a user may be used to go to a cinema on weekend, but he may also go on a weekday if he is invited by a friend, while he is not likely to go if the distance is extremely far. Secondly, the check-in data is usually very sparse since a user usually checks-in a limited area in his daily life. Sparse data usually means lacking training samples, which will in further influence the accuracy of the model.
one target feature variable of a user can be regarded as the latent factor of the user's preference) at the same time, thus it is difficult to learn different variables, let alone the interactions between these variables. While the decision process of a user is complicatedly influenced by many influences factors, the absence of learning interactions between these factors could lead to serious model deviations or errors.
Based on factorization machines (FM) [6], we propose a method named as Geo-STFM which can better exploit social, temporal and geographical correlations for POI recommendations. Factorization machines (FM) is a generic approach which models interactions between features (explanatory variables) using factorized parameters. Therefore, FM can estimate all interactions between features even with extreme sparsity of data. Based on factorization machines (FM), we put forward a two-step framework to make POI recommendations. In the first step, we give a precise analysis of the self-similar and other-similar characteristic in users' behaviors, and accordingly propose an improved factorization machines model with social and temporal regularization terms (notated as STFM). In the second step, we fuse the power law modeling method of geographical influence with the STFM model, and rank the fused rate to make top-N POI recommendations.
To summarize, the major contributions of this paper are as follows:
(1) Give a precise analysis of the self-similar and other-similar characteristics in users' behaviors; To the best of our knowledge, this is the first time that the concept of self-similarity characteristic of users' behaviors is proposed, whereas previous works only mentioned the similarity in social ties (namely other-similarity).
(2) Propose an improved factorization machines with social and temporal regularization terms, which better learns the interactions of latent preference factors even with a sparse data; To the best of our knowledge, this is the first paper that utilizes factorization machines in POI recommendation.
(3) Fuse the geographical influence with the improved factorization machines model to better make POI recommendations.
Preliminaries
According to the users’ behaviors in LBSN, structured data can be extracted for POI recommendation. Several notations in this paper are as follows:
Notation 1 (Check-in): Given the user set{ ,u u1 2,...,uid,...,un} and the POI set { , ,...,l l1 2 lid,..., }lm .
The check-in record of a user uid is represented by 〈uid,lid,timestamp〉 which describes uid has
checked-in at location lid in a specific time. For convenience, U denotes for the user set, L denotes
for the POI set, Luirepresents for the set of POIs that ui have checked-in, and ri m, represents the
overall check-in frequency of ui on lm.
Notation 2 (Check-in Context): The social friends of a specific user uid can be represent by tuples
of 〈uid,uid_of_his_friend〉 , further, related users who have visited to the same POIs checked-in by the user
can be notated as his POI friends. For convenience, Fs
i denotes for the user’s social friends, F p i
represent for his POI friends, and Fi ( F =F
s p
i i ∪Fi ) stand for ui’ s friends. The check-in time stamp
can be extracted to specific temporal information, namely the day of a week and the time slot of 24 hours (namely 24 hours are divided into 24 time slots). Geographical information of a POI is denoted by the tuple of its longitude and latitude as 〈lid,longitude latitude, 〉.
Geo-STFM: A POI Recommender System Based on FM
User Behavior Analysis and Feature Engineering
Empirically, users' check-in behaviors show the characteristics of other-similarity and self-similarity. Other-similarity is the characteristic that the user tends to share common interests with their friends [1,4], and it is obvious that the user is likely to have similar favor with those users (notated as POI friends) who have checked-in the same POIs. Further, the user may have a potential interest for exploring the POIs that nearby his visited POIs since businesses (e.g., clothing stores) often cluster in a specific area. On the other hand, self-similarity is reflected in a way that the user's favors are regular and the user tends to have habit patterns in time. For instance, a user may check-in the same restaurant for dinner every night, this behavior is a periodic self-similar characteristic. Besides, the user is consecutive self-similar in a successive time [7] since user' activities are often continuous in time without any tremendous leaps, and this characteristic is especially obvious in a case that the user is engaged in something consecutively for hours such as shopping.
For instance, in time slot ts1 (extracted from a time stamp, and ts1 is the time slot that denotes for 00 : 00 01: 00− on Monday), the target user ui has checked-in at locations { }l1 and his social friends are { }u1 , the users that have checked-in the same POIs are
2
{ }u . Additionally,
2
u has also checked-in
3
{ }l . Moreover,
2
l is close to
1
l . While in time slot ts2 (ts2 is the time slot that denotes for
01: 00 02 : 00− after ts1), ui has also checked-in at locations { }l1 . It is worth noting that these simple data cases are just for demo, and actually u1 is just one of ui's social friends, so as to other
[image:3.612.83.531.360.499.2]data cases.
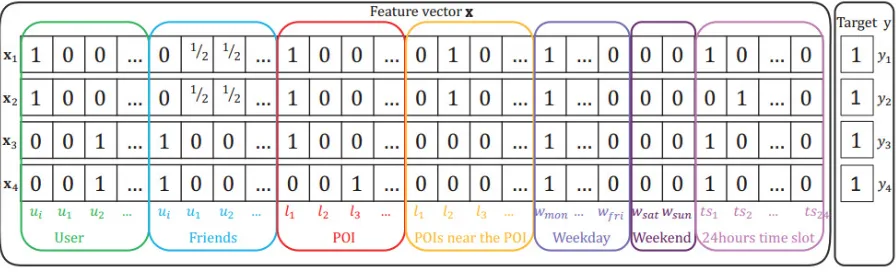
Figure 1. Example of the feature vector x constructed for our proposed model STFM.
According the example data, the feature vectors x can be generated. Figure 1 shows the demo of
feature engineering of our following proposed model (STFM). More concretely, xi represents for the
one check-in record of a user with contextual information. For example, xi denotes that ui
checked-in at l1 ints1. Seven different fields of context information are all engaged in after encoding
by one-hot encoding, they are user field, user’s friends field (including social friends and POI friends), POI field (the specific POI that the user checked-in), POIs near the checked-in POI (POIs that are close to the specific checked-in POI), weekday field (the day in a week extracted from the check-in time stamp, for example, Monday, etc.), weekend field (namely Saturday or Sunday) and time slot field (the time slot in a day divided by hours, for example, 00 : 00 01: 00− is the time slot
1
ts while 23 : 00 24 : 00− is the time slot ts24, etc.). In addition, the target yi denotes for the user’s
preference of the POI, where yi = 1 if the user has checked-in.
STFM: An Improved Factorization Machines with Social and Temporal Regularization Terms
(
)
(
)
(
)
2 ( , ) 2 j 2i , Fieldweekday
2
i , Fieldweekend
2
i Field , =ts 1 ˆ
OPT( )=argmin( | ,
sim ,
)
F x y S
i j F i U Fi
p q F U p q
p q F U p q
p q F
U p q p
S l y x y
i j v v
v v v v v v θ θ λ θ α β γ δ
Θ ∈ ∈Θ
∈ ∈ ∈ ∈ ∈ ∈ ∈ ∈ + Θ + + − + − + − + −
∑
∑
∑∑
∑
∑
∑
∑
∑
∑
.. (1)
And the loss function:
(
)
(
ˆ | ,)
=(
ˆ(
|)
)
2l y x Θ y y x Θ −y (2)
And, we have:
k
2 2
j j F= j f, j,f F f
v v v v
′ ′
−
∑
− (3)Where ( , )x y (an example is showed in Figure 1) is a training sample from S, Θ represents for the
parameters of FM (including p 0
w R w, R ,V Rp k×
∈ ∈ ∈ ), λθ is the L2 regularization parameter(λθ is
correspondingly notated as λ0 for w , 0 λw for wj, λv for vj f, ). Further, Uis the set of users, n is the number of users, p is the feature numbers of xi , k is the dimension of the factorized
parameters(also can be notated as the number of factors of a feature variable), ⋅2F is the Frobenius
norm, { ,p q∈Fieldweekday} means p and q belong to the field of weekday(which were introduced in
Section3.1), and Fieldweekend means the field of weekend and Fieldts stands for the field of time slot,
while
α
, β, γ, andδ
are the weight of the corresponding regularization terms.Regularization Terms. As show in Eq.(1), four regularization terms which aim at capture the characteristics of other-similarity and self-similarity were added to the FM model. In Eq.(1), the different latent feature vectors’ similarity were measured in a Frobenius norm. Actually, the better way to compute the similarity between vectors is to use cosine similarity. However, the calculation is complex, thus we exploit the Frobenius norm to approximately measure the similarity.
Reg1: Modeling the other-similarity. The first regularization term can capture the characteristic of other-similarity. As show in Eq.(4), the other-similarity regularization term consists of the similarity function for quantifying the preference similarity of the user with his friend and the Frobenius norm that measures the actual similarity of corresponding latent favor(which also can be notated as the factorized user’s preference).
(
)
2j
sim , i j F i U F
i
i j v v
α
∈ ∈
−
∑∑
(4)Where Fi is the friends set ofui , and sim ,
(
i j)
is measured by cosine similarity, given by:, ,
2 2 , ,
*
sim( , ) =
i m j m m L L
i j
i m j m m L m L
i j r r i j r r ∈ ∩ ∈ ∈
∑
Where ri m, is the overall check-in frequency of ui on lm.
This social regularization term can constrain the model so that the learned favor of users will close to their friends since it is proposed based on the assumption that the user tends to share more common interests with his friends. However, if a user is not similar in favor with some friends, the similarity is small thus the regularization term will throw little effect on the model.
The other regularization terms are to model the self-similarity in weekdays, the self-similarity in weekends and the self-similarity in successive time.
Geo-STFM: Fused Geographical Influence with STFM
The geographical distance of a POI can significantly affects users’ check-in behavior. Almost all existing works have taken the geographical influence into consideration, and several modeling methods have been proposed. In recent works, it is common to model geographical information alone and then integrate it into a synthetic recommendation model. In this paper, we mainly focus on the improved FM model which has not been used for POI recommendation, thus we simply utilize the most widely used power law model to integrate the geographical influence. The power law model which means a user’s check-in probability and his distance away from home (or it can be denoted by the most frequent check-in POI) follow a power law distribution, which is defined as follows:
( )
g = b
d a d⋅ (6)
Where a and b are the parameters which can be easily learned by a likelihood estimation. Therefore,
the overall preference that a user ui to a POI lj after incorporating with the normalized ge
ographical influence can be denoted as :
(
)
(
,i,home)
,
min
g( )
ˆ
p = ( , ) |
g
l l j
i j i j
d y u l
d
Θ ⋅ (7)
Where dmin denotes for the minimum pairwise distance, li home, denotes the home location of ui, and
,i,home
ljl
d denotes for distance between lj and li home, .
Finally, the overall pi j, will be ranked to get the top-N recommendation list for the users.
Experiments
Datasets, Metrics and Set up
We used the Foursquare dataset and the Gowalla dataset [7]. And we use the commonly used two metrics: precision (precision@topN) and recall (recall@topN) to evaluate the item recommendation performance of our model [10].
We implement and evaluate our method based on the CARSKit Lib [10] and compare our method with the following stat-of-the-art POI techniques(the parameters are from our experiments or suggested by previous or related works): PMF[12] which out performs traditional collaborative filtering methods in the situation of big data sets or data sparsity.WRMF[13] which is a matrix factorization method widely used for modeling implicit feedback, many works have used this method for user preference modeling. USG[8], which integrates user preferences,social and geographical information for location recommendation. LRT[4], which investigates the temporal properties of user check-in behaviors and proposes a location recommendation framework with temporal effects. IRenMF[14], which incorporates two levels of geographical neighborhood into the learning process of latent features of users and locations.
Performance Comparision
0 = 0.001, w= 0.0015, v = 0.001, = 0.1, = = 0.05, = 0.02
λ λ λ α β γ δ on Foursquare and and
0= 0.001, w= 0.0015, v = 0.001, = 0.15, = = 0.05, = 0.01
λ λ λ α β γ δ on Gowalla, we get the
relatively best performance. Furthermore, the parameters of IRenMF, LRT and USG are set according to the suggested value in related works as mentioned above.
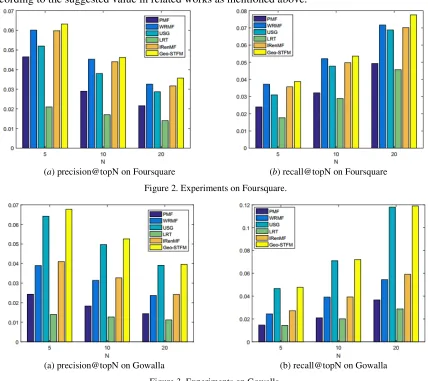
(a) precision@topN on Foursquare (b) recall@topN on Foursquare Figure 2. Experiments on Foursquare.
[image:6.612.90.518.123.504.2](a) precision@topN on Gowalla (b) recall@topN on Gowalla Figure 3. Experiments on Gowalla.
Figure 2 and Figure 3 show the results of our experiments. The results show that our proposed method achieve remarkable the improvements both in precision and recall metrics. Based on the results, we can observe that LRT performs the worst among all methods on two data sets. This result may due to the fact that LRT only takes the temporal influence into consideration, however, other influences such as geographical influence are also indispensable. Besides, PMF performs a little better than LRT since the deviation has been considered. What’s more, both WRMF and IRenMF perform well on foursquare but just so so on Gowalla, this phenomenon may be explained by the fact that Gowalla covers a much larger area than Foursquare, thus the implicit feedback or geographical cluster on Foursquare seem to be more centralized and valuable. On the contrary, USG performs both well on Foursquare and Gowalla. It is understandable since USG takes more context information into consideration. However, compared to Geo-STFM, USG still performs a little bit worse since Geo-STFM has modeled the additional temporal patterns of users’ behaviors.
Conclusion
factorization machines model with social and temporal regularization terms (STFM). Further, we fuse the geographical influence which modeled by power law with STFM. The experimental results on two real-world data sets show that our proposed method achieves remarkable improvements compared to the state-of-the-art POI recommendation methods.
References
[1] Ramesh Baral, Dingding Wang, Tao Li, and Shu-Ching Chen. 2016. Geotecs: exploiting geographical, temporal, categorical and social aspects for personalized poi recommendation. In Information Reuse and Integration (IRI), 2016 IEEE 17th In-ternational Conference on. IEEE, 94– 101.Reference to a book:
[2] Chen Cheng, Haiqin Yang, Irwin King, and Michael R Lyu. 2012. Fused Matrix Factorization with Geographical and Social Influence in Location-Based Social Networks.. In Aaai, Vol. 12.
17–23.
[3] Eunjoon Cho, Seth A Myers, and Jure Leskovec. 2011. Friendship and mobility: user movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 1082–1090.
[4] Huiji Gao, Jiliang Tang, Xia Hu, and Huan Liu. 2013. Exploring temporal effects for location recommendation on location-based social networks. In Proceedings of the 7th ACM conference on Recommender systems. ACM, 93–100.
[5] Huiji Gao, Jiliang Tang, Xia Hu, and Huan Liu. 2015. Content-Aware Point of Interest Recommendation on Location-Based Social Networks. In AAAI. 1721–1727.
[6] S. Rendle, “Factorization machines with libfm,” ACM Transactions on Intelligent Systems and Technology (TIST), vol. 3, no. 3, p. 57, 2012.
[7] Huayu Li, Yong Ge, Richang Hong, and Hengshu Zhu. 2016. Point-of-Interest Recommendations: Learning Potential Check-ins from Friends. In KDD. 975–984.
[8] Moshe Lichman and Padhraic Smyth. 2014. Modeling human location data with mixtures of kernel densities. In Proceedings of the 20th ACM SIGKDD international conference on
Knowledge discovery and data mining. ACM, 35–44.
[9] Bin Liu, Yanjie Fu, Zijun Yao, and Hui Xiong. 2013. Learning geographical preferences for point-of-interest recommendation. In Proceedings of the 19th ACM SIGKDD international
conference on Knowledge discovery and data mining. ACM, 1043–1051.
[10] Zheng Y, Mobasher B, Burke R. Carskit: A java-based context-aware recommendation engine[C]//Data Mining Workshop (ICDMW), 2015 IEEE International Conference on. IEEE, 2015: 1668-1671.
[11] Hao Ma, Dengyong Zhou, Chao Liu, Michael R Lyu, and Irwin King. 2011. Recommender systems with social regularization. In Proceedings of the fourth ACM international conference on Web search and data mining. ACM, 287–296.
[12] Mnih A, Salakhutdinov R R. Probabilistic matrix factorization[C]//Advances in neural information processing systems. 2008: 1257-1264.
[13] Hu Y, Koren Y, Volinsky C. Collaborative filtering for implicit feedback datasets[C]//Data Mining, 2008. ICDM'08. Eighth IEEE International Conference on. IEEE, 2008: 263-272.