CREDIBILITY ASSESSMENT OF HEALTH INFORMATION ON SOCIAL MEDIA: DISCOVERING CREDIBILITY FACTORS, OPERATIONALIZATION, AND PREDICTION
Heejun Kim
A dissertation submitted to the faculty at the University of North Carolina at Chapel Hill in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the School of
Information and Library Science.
Chapel Hill 2019
Approved by: Jaime Arguello Javed Mostafa Guilherme Del Fiol Sam Oh
© 2019 Heejun Kim
ABSTRACT
Heejun Kim: Credibility Assessment of Health Information on Social Media: Discovering Credibility Factors, Operationalization, and Prediction
(Under the direction of Jaime Arguello and Javed Mostafa)
The amount of information is rapidly increasing in the information age. Paradoxically, it is becoming difficult to find credible information. This phenomenon can have various negative effects. The associated social costs are increasing, and the digital divide can become worse. Vulnerable users with low levels of domain expertise might not be able to select credible
information on their own. Thus, one of the primary goals of this dissertation research is to create a more reliable information retrieval environment for general users by developing an intelligent system that can automatically predict the credibility of information.
This study combined both social science and technical approaches to an interdisciplinary problem. From the human side, this study examined the criteria people use to judge the
credibility of health information on social media by conducting a content analysis of randomly selected health information. From the system side, the study operationalized these criteria as features for machine-learned models. Finally, the dissertation study evaluated the credibility models based on the ground-truth data that was annotated by experts and crowd workers.
factors (topic, prior knowledge, and type of social media) in which people judge the credibility of information. This study also empirically examined the application of the Elaboration
Likelihood Model to the context of credibility assessment.
ACKNOWLEDGMENTS
My doctoral study was not an expected journey considering my previous stable career path, and I am very thankful to everyone who supported it. I would like to begin by thanking all members of my doctoral committee. I am deeply thankful to Dr. Jaime Arguello for providing invaluable help in defining the nebulous concept of credibility, measuring it, and designing my dissertation study. My deepest appreciation is extended to Dr. Javed Mostafa for ALWAYS providing incredible insight and sponsoring most of the years of my doctoral study. I was extremely lucky to work with Dr. Guilherme Del Fiol, who provided the most effective and efficient feedback at all times. I would especially like to thank Dr. Stephanie W. Haas for challenging me with very difficult, but constructive questions and Dr. Sam Oh for encouraging me in numerous ways since we met in 2016. My dissertation defense was intellectually the most challenging moment since I started the program, but it was the happiest moment, too. All of you have played an immeasurable role in building my academic credibility.
I would like to express my gratitude for the SILS community including faculty, staff, and colleagues. To my mentor, Dr. Barbara M. Wildemuth, for showing an example of true scholar and being my academic mother. To Anita Crescenzi, for her invaluable help in my early settlement and the remarkable notes that she made during my presentations. To Bogeum Choi, for her incredible work on the content analysis in my dissertation study and constructive
editing my dissertation and other publications and making them very readable. I cannot list all the names due to space constraints, but I am really grateful to everyone at SILS, which has been the most collegial and intellectually strong community of all the academic communities I have experienced. I like to present my work in any environment, but I feel happiest as well as challenged when I presented my work at SILS.
I would like to extend my sincere gratitude and love to my family. To my parents, Keeyoung Kim and Kyunglee Kim, for their endless love and belief, which has helped me to overcome a difficult period in my life. To my parents-in-law, Jungsik Ahn and Youngsun Yang, who allowed and supported my decision for the doctoral study while knowing it would be a hard time for their daughter. It is still vivid in my memory that they immediately consented and encouraged me to pursue my doctoral study when I presented them with my UNC admission. To my beloved sister, Youngshin Kim, for her endless love and an incredible belief in me, which helped me relax when I really needed to. To my sister-in-law, Jihyun Ahn, who once shared the common dream with me and emotionally supported her sister, which is the most important to me. Last, but most importantly, I would like to express my sincerest appreciation to my wife, Ilhyun Ahn, who bravely accepted life as a wife of a doctoral student and provided countless help during my study. Any existing words are not appropriate to express how much you mean to me and how much I love you. This work would have never been possible without you.
Finally, I deeply thank God for sending people who changed my life, leading my way, and loving me.
TABLE OF CONTENTS
LIST OF TABLES ... xi
LIST OF FIGURES ... xiv
LIST OF ABBREVIATIONS ... xv
CHAPTER 1: INTRODUCTION ... 1
CHAPTER 2: LITERATURE REVIEW ... 5
2.1 Introduction ... 5
2.2 Credibility and Its Related Concepts ... 5
2.2.1 Quality ... 6
2.2.2 Trustworthiness ... 9
2.2.3 Credibility ... 11
2.2.4 Summary ... 14
2.3 Theories and Models Related to Credibility ... 15
2.3.1 Wilson’s Model of Information Behavior ... 15
2.3.2 Prominence-Interpretation Theory ... 16
2.3.3 Elaboration Likelihood Model ... 19
2.3.4 Rieh’s Theoretical Framework for Credibility ... 21
2.3.5 Summary ... 22
2.4 Concepts Related to Credibility, Their Criteria, and Operationalization ... 23
2.4.1 Criteria Related to Credibility Assessment ... 24
2.4.3 Summary ... 40
2.5 Contextual Factors Affecting Credibility Judgments ... 42
2.5.1 Topic ... 43
2.5.2 Prior Knowledge ... 45
2.5.3 Type of Social Media ... 47
2.5.3 Summary ... 50
2.6 Credibility Instrument ... 50
2.6.1 Existing Credibility Instruments ... 51
2.6.2 Instrument Verification Method ... 56
2.6.3 Summary ... 59
CHAPTER 3: METHODS ... 60
3.1 Introduction ... 60
3.2 Data ... 62
3.3 Content Analysis ... 73
3.4 Creation of Credibility Labels ... 76
3.5 Feature Ablation Study ... 84
CHAPTER 4: CONTENT ANALYSIS RESULTS ... 95
4.1 Credibility Factors Identified ... 95
4.2 Credibility Labels Created by Experts ... 99
4.3 Assessor Agreement ... 100
4.4 Statistical Analysis of the Relationship between Credibility and Credibility Factors .. 103
4.4.1 Correlation Analysis ... 103
4.4.2 Regression Analysis ... 109
4.4.3 F-Test ... 117
CHAPTER 5: PREDICTIVE ANALYSIS RESULTS ... 125
5.1 Credibility Labels Created by Crowd Workers ... 125
5.1.1 Data Collection ... 125
5.1.2 Discussion ... 129
5.2 Operationalization of Credibility Factors ... 130
5.2.1 Content Informativeness ... 131
5.2.2 Sentiment ... 138
5.2.3 Presentation ... 140
5.2.4 Source ... 142
5.2.5 Discussion ... 145
5.3 Feature Ablation Study ... 146
5.3.1 Yahoo! Answers ... 147
5.3.2 Yelp ... 151
5.3.3 Discussion ... 154
5.4 Varying Effects of Features by Topic ... 155
5.4.1 Yahoo! Answers ... 155
5.4.2 Yelp ... 158
5.4.3 Discussion ... 160
5.5 Varying Effects of Features by Prior Knowledge ... 162
5.5.1 Yahoo! Answers ... 163
5.5.2 Yelp ... 164
5.5.3 Discussion ... 166
CHAPTER 6: CONCLUSION ... 168
6.1 Contributions ... 169
6.3 Limitations ... 175
6.4 Future Research ... 177
APPENDIX 1: RECRUITMENT POSTING ... 182
APPENDIX 2: CONSENT FORM ... 183
APPENDIX 3: ENTRY QUESTIONNAIRE ... 185
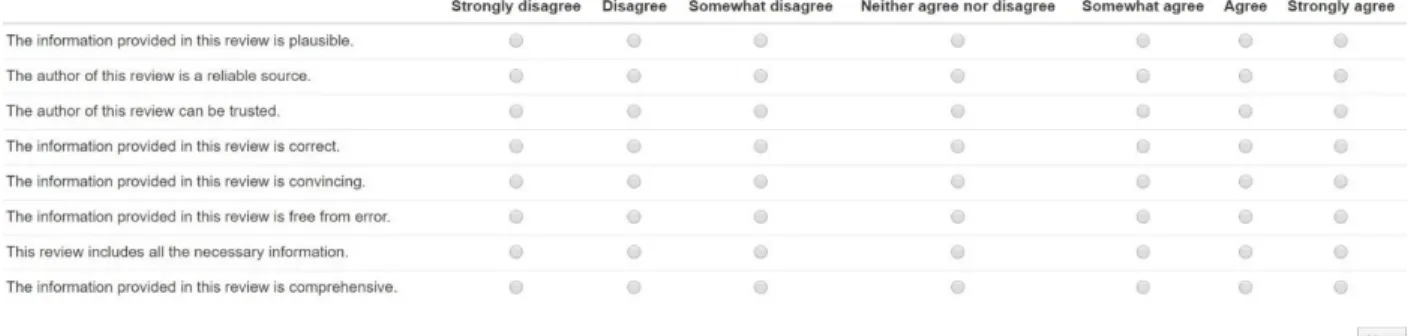
APPENDIX 4: ORIGINAL CREDIBILITY QUESTIONNAIRE ... 188
APPENDIX 5: ALTERNATIVE CREDIBILITY QUESTIONNAIRE ... 190
APPENDIX 6: PRIOR KNOWLEDGE QUESTIONNAIRE ... 192
APPENDIX 7: ANSWER JUSTIFICATION QUESTIONNAIRE ... 193
APPENDIX 8: CODING BOOK ... 194
LIST OF TABLES
Table 1. Concepts Related to Credibility and Their Criteria ... 28
Table 2. Promising Features in Predicting Credibility of Information and Source ... 38
Table 3. Existing Credibility Instruments ... 52
Table 4. Exclusion Criteria ... 66
Table 5. A List of Spam Words ... 68
Table 6. Credibility Instrument ... 77
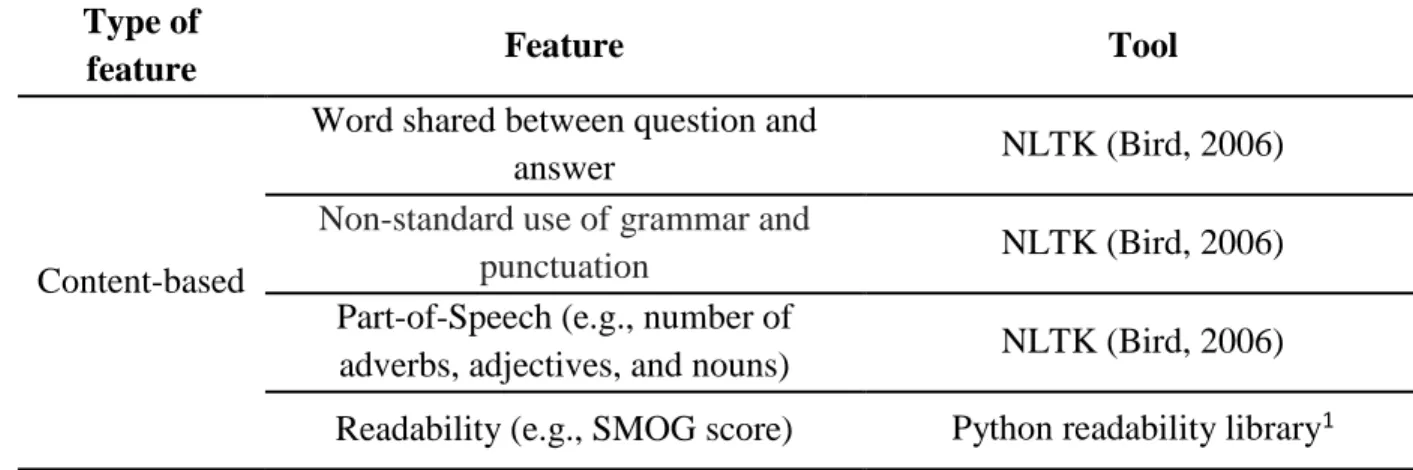
Table 7. Promising Features in Predicting Credibility of Information and Tools to Extract the Corresponding Feature ... 84
Table 8. Authoritative Online Resources for Content Validation ... 87
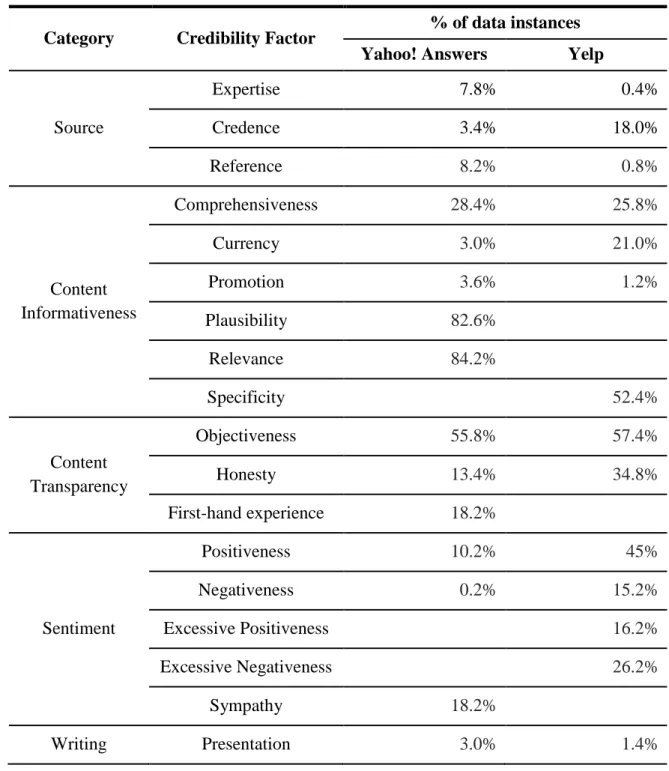
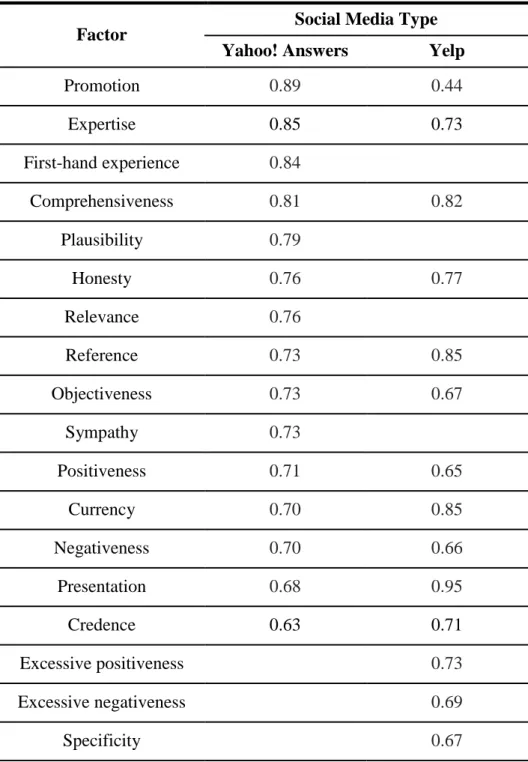
Table 9. Factors of Credibility ... 96
Table 10. Frequencies of Credibility Factor per Social Media Type ... 98
Table 11. The frequency of Credibility Labels by Experts ... 100
Table 12. Cohen’s Kappa Coefficient for Credibility and Factors ... 101
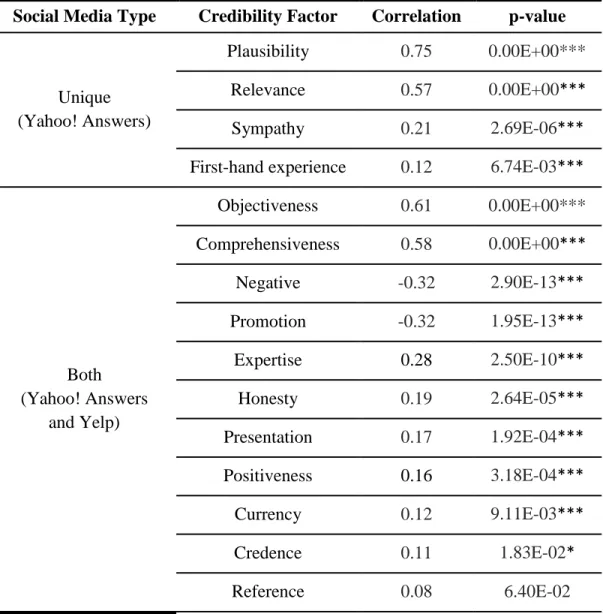
Table 13. Correlation between Credibility and Underlying Factors (Yahoo! Answers) ... 104
Table 14. Correlations between Credibility Factors (Top 10 Pairs, Yahoo! Answers) ... 105
Table 15. Correlation between Credibility and Underlying Factors (Yelp) ... 107
Table 16. Correlations between Credibility Factors (Top 10 Pairs, Yelp) ... 108
Table 17. Linear Regression with the Full Model (Yahoo! Answers) ... 110
Table 18. Variance Inflation Factors (Yahoo! Answers) ... 112
Table 19. Bootstrapped Linear Regression with the Full Model (Yahoo! Answers) ... 113
Table 20. Linear Regression with the Full Model (Yelp) ... 114
Table 21. Variance Inflation Factors (Yelp) ... 116
Table 22. Bootstrapped Linear Regression with the Full Model (Yelp) ... 117
Table 24. Results of F-tests (Yahoo! Answers) ... 120
Table 25. Parsimonious Linear Regression Model (Yelp) ... 121
Table 26. Results of F-tests (Yelp) ... 122
Table 27. MTurk Workers’ Demographics ... 126
Table 28. The frequency of Credibility Labels by MTurk workers ... 128
Table 29. Websites Used to Operationalized Plausibility ... 132
Table 30. Features that Represent “Plausibility” ... 133
Table 31. Features that Represent “Relevance” ... 135
Table 32. Features that Represent “Comprehensiveness” ... 136
Table 33. Features that Represent “Specificity” ... 137
Table 34. Features that Represent “Sentiment” ... 140
Table 35. Features that Represent “Presentation” ... 142
Table 36. Performance of Credibility Classifiers (Yahoo! Answers) ... 148
Table 37. Final Features Selected for Feature Ablation Study (Yahoo! Answers) ... 149
Table 38. Friedman Test Result (Yahoo! Answers) ... 149
Table 39. Feature Ablation Study Results (Yahoo! Answers) ... 150
Table 40. Performance of Credibility Classifiers (Yelp) ... 151
Table 41. Final Features Selected for Feature Ablation Study (Yelp) ... 152
Table 42. Friedman Test Result (Yelp)... 153
Table 43. Feature Ablation Study Results (Yelp) ... 153
Table 44. Performance of Credibility Classifiers over Topic (Yahoo! Answers) ... 156
Table 45. Results of Friedman Test over Topic (Yahoo! Answers) ... 156
Table 46. Bootstrapped Feature Ablation Study Results over Topic (Yahoo! Answers) ... 157
Table 47. Performance of Credibility Classifiers over Topic (Yelp)... 158
Table 49. Bootstrapped Feature Ablation Study Results over Topic (Yelp) ... 159 Table 50. Performance Measures of Credibility Classifiers over Different
Prior Knowledge (Yahoo! Answers) ... 163 Table 51. Bootstrapped Feature Ablation Study Results by Prior Knowledge
LIST OF FIGURES
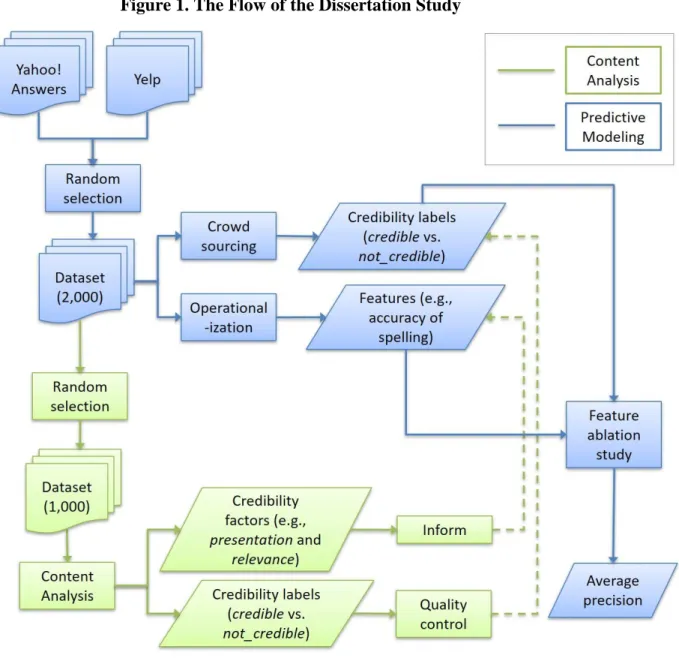
Figure 1. The Flow of the Dissertation Study ... 62
Figure 2. Overall Characteristics of Datasets ... 72
Figure 3. Labeling Task Interface with Yahoo! Answers Data and the Original Instrument ... 80
Figure 4. Labeling Task Interface with Yelp Data and the Alternative Instrument ... 80
Figure 5. A Questionnaire for Asking MTurk Workers’ Prior Knowledge on the Task ... 94
LIST OF ABBREVIATIONS
AIC Akaike information criterion AIDT Automatic indicator detection tool AMT Amazon Mechanical Turk
ANOVA Analysis of variance
AQA Automated quality assessment
AP Average precision
CDF Cumulative distribution function CFI Comparative fit index
CFS Correlation-based feature selection CI Confidence intervals
ELM Elaboration likelihood model HIT Human intelligence task
HoNcode Health On the Net Foundation’s Code of Conduct
KG Knowledge graph
LSA Latent semantic analysis MAP Mean average precision
MCPs Multiple comparisons procedures MIS Management information system MTurk Mechanical Turk
NLP Natural language processing
PEW Pew Internet & American Life Project RL Reinforcement learning
ROC Receiver operating characteristic RMSE Root mean square error
RMSEA Root mean square error of approximation RTL Recursive trust labeling
SemRep Semantic Knowledge Representation SILS School of information and library science STD Sexually transmitted diseases
SVD Singular value decomposition
TF-IDF Term frequency-inverse document frequency IR Information retrieval
ISO International organization for standardization IT Information technology
UMLS Unified medical language system VIF Variance inflation factor
WKG Wikipedia knowledge graph
CHAPTER 1: INTRODUCTION
Advances in technology such as the Internet, Web 2.0, and mobile devices have increased our exposure to information from a variety of sources. Online information is promising in that it can be fast, can reach farther, and can be cost-effective. These developments have often been considered an “information revolution of unprecedented magnitude” (Jadad & Gagliardi, 1998, p. 611) or the “exponential growth of information” (Francalanci & Galal, 1998, p. 229). In this new paradigm, the general public can produce and share a large amount of information on the Web and social media.
This shift also has an enormous effect on healthcare and health information behavior. According to the Pew Internet & American Life Project (Pew) report, 72% of Americans who have Internet access used the Web to search health information within the past year (Fox & Duggan, 2013). The Internet has promoted interactive health communication and allowed consumers to engage in seeking health information (Cline & Haynes, 2001). We witness an era in which the general public is equipped with an extraordinary ability to access and process information and is actively involved in evidence-based healthcare (Eysenbach & Jadad, 2001).
can post questions and comments and interact with others. Social media may be better suited to meet those personalized information demands than traditional media.
However, the increased availability of information has also raised concerns about the quality of health information and its negative impact on users’ lives (Wang & Liu, 2007). For instance, in May 2016, a huge scandal resulted from incorrect health information recommended by Baidu, the market-leading search engine in China. A 21-year-old college student died after receiving an experimental cancer treatment known as immunotherapy, which had not been extensively tested and ineffective but was in the top search results. Baidu has been criticized for its improper sponsored rank manipulation.
Information on social media has also further amplified these concerns as we could observe from the spread of fake news related to the 2016 presidential election on Facebook. Not only credible news but also fake news can easily be propagated through a network of friendships on social media. The impact caused by unreliable information in the context of health problems is more severe than the impact in the context of a general information search because it can be detrimental to users’ health and threaten their lives. Given the increasing importance of online health information in general as well as health information on social media, our efforts to understand the credibility of health information on social media are imperative.
discussion on how to define credibility and how it differs from other similar concepts (e.g., quality and trustworthiness) will be introduced in more detail in the literature review.
To facilitate the communication of credible online information, previous studies have examined factors that influence the credibility of information (e.g., Freeman & Spyridakis, 2004; Hong, 2006; Kim, Oh, & Oh, 2008; Rieh, 2002), developed theoretical models (e.g., Petty & Cacioppo, 1986; Sundar, 2008; Tseng & Fogg, 1999), and applied automatic methods for
assessing the credibility of information (e.g., Castillo, Mendoza, & Poblete, 2011; Ciampaglia et al., 2015; Sondhi, Vydiswaran, & Zhai, 2012). However, these studies have not integrated the human side and computational side of the credibility assessments. None of these studies
simultaneously addressed what the significant factors of credibility judgments are and how those factors can be operationalized and applied to predictive modeling based on machine learning.
This dissertation study aims to automatically predict the credibility of information based on computational credibility models. From the human side, this research examines the criteria people use to judge the credibility of information. These credibility criteria are investigated through a content analysis of randomly selected health information. From the system side, the study operationalizes these criteria as features for machine-learned models. The key contribution of this dissertation study is finding comprehensive criteria for people's credibility judgments based on the content and source and operationalizing these criteria for machine-learned models. Finally, the dissertation study evaluates the credibility models based on ground-truth data that is annotated by trained experts and crowd workers.
RQ2: How can these factors be operationalized as input features for predictive models developed using machine learning? In this dissertation, I develop and evaluate different types of features, and I discuss their effectiveness in modeling their intended underlying factors.
CHAPTER 2: LITERATURE REVIEW 2.1 Introduction
This chapter presents a review of extant literature that is relevant to this study. It is comprised of five sections. The first section covers the definition of credibility and its related concepts. The second section describes models and theories that explain the perceptions and formulations of credibility that are potentially relevant to credibility judgments. The discussion of these models and theories will form the theoretical framework for this study. The third section looks at the factors that make up credibility and the criteria that consist of those factors.
Promising features in predicting credibility of information and source and previous studies that applied those features are also summarized. The fourth section reviews the contextual factors affecting credibility judgments. The final section summarizes the previous credibility
instruments that can be used to create ground-truth labels for credibility and verification methods for a new instrument.
2.2 Credibility and Its Related Concepts
The primary goal of this study is to automatically predict the credibility of health information on social media. It is, however, imperative to understand the process of people’s credibility judgments, as well as the difference between credibility and other related concepts such as quality and trust. Thus, this section will review previous studies that can help us
2.2.1 Quality
Many research studies have used the term “data quality” in different research contexts. In general, quality is “a measure of the difference between the data and the reality they represent, and becomes poorer as the data and the corresponding reality diverge” (Devillers & Jeansoulin, 2006, p. 12). To measure the difference, the ISO 19113 standard (International Organization for Standardization, 2002) recommends the following criteria: completeness, consistency, accuracy, definition, coverage, lineage, precision, legitimacy, and accessibility. In his value-added model, Taylor (1986) defined quality as “a user criterion which has to do with excellence or in some cases truthfulness in labeling” (p.62). In this model, Taylor introduced five criteria of
information quality: accuracy, comprehensiveness, currency, reliability, and validity. These five criteria are relatively identical to what has been studied for user relevance criteria regarding the quality of information (Park, 1993; Rieh & Belkin, 1998; White & Wang, 1997). Wand and Wang (1996) claimed that the core dimensions of data quality are accuracy, completeness, consistency, and timeliness. Experts may assess these values with their previous experiences and training; however, it may be challenging for novice users to make an appropriate evaluation of these dimensions of data quality. As the main actors of information use have shifted from experts to the general public, appropriate adjustments on these criteria are necessary if they are to be used by the general public in new environments.
closely related to the characteristics of the information object (e.g., accuracy, completeness, comprehensiveness, and coverage). If a source of information repeatedly tells the truth, we will expect more truth from the source, and transfer our cognitive authority to others by word-of-mouth (WOM). Wilson (1983) also argued that the plausibility of textual content influences the cognitive authority. The intrinsic plausibility of content has critical value in the era of Web and social media, although textual content was only considered to be the fourth dimension of cognitive authority in addition to the three core factors (author, publisher, and document type). Finding balance among the attributes of information object and information source will be critical in building predictive models for credibility.
Rieh (2002) conducted a content analysis using participants’ think-aloud comments and responses to a post-search interview to examine criteria of information quality. One of the interesting findings of the studies conducted by Rieh et al. (Rieh, 2002; Rieh & Belkin, 2000) is that there are two kinds of judgments when people search the Web for information: predictive judgment (expecting what will happen before people actually look at the search results) and evaluative judgment (expressing preference after people inspect the search results). For
predictive judgments, people mainly analyze system structure and system functionalities. On the other hand, people analyze characteristics of information objects for evaluative judgments.
of the ability of the information sources to provide accurate and valid information (Hilligoss & Rieh, 2008). Evaluating the content of information is essential in verifying information quality. Interaction with content is arguably the most cognitively burdensome of the three interactions: interaction with content cues, interaction with source peripheral cues, and interaction with information object peripheral cues (Hilligoss & Rieh, 2008; Petty & Cacioppo, 1986).
As we reviewed in the above, prior research supports the idea that the perception of information quality can be formulated after inspection. Thus, quality is more related to the content of the information and subject than to more evaluative and posterior judgments. As we have seen in the research discussed above, the criteria for quality are mainly for measurement, so it is more objective rather than subjective, and close to expertise in credibility. Moreover, it is important to note that one of the definitions of credibility is a perceived quality (Tseng & Fogg, 1999). However, evaluating all of the criteria related to the quality of information in a flood of information is hardly feasible. Thus, in credibility, information is verified by using expertise, which is closely related to accuracy and one of the core elements of quality along with subjective trustworthiness. We can imagine that a person with expertise can manage and evaluate these quality-related criteria thoroughly.
In this dissertation study, the focus will be on the results of the expertise, which is how the content itself (object-level) is accurate due to the expertise in relation to the information source. Wilson asserted that “a person is competent in some area of observation or investigation if he is able to observe accurately or investigate successfully” (Wilson, 1983, p. 15). In
2.2.2 Trustworthiness
Instead of assessing the quality of individual information, the assessment can be more flexible and feasible by leveraging the trustworthiness of the information source. In an interview study by Rieh and Belkin (Rieh & Belkin, 1998), participants assessed information quality based on source authority and credibility rather than information content and other criteria due to the self-publishing characteristics of the Web and the lack of quality control mechanisms. Trust can be defined as a user’s willingness to accept a piece of information as being truthful (Tseng & Fogg, 1999). Trustworthiness can capture “perceived goodness and morality of the source” (Tseng & Fogg, 1999, p. 123). In a similar sense, Hertzum et al. (2002) defined credibility as the perceived quality of a source or piece of information and asserted that establishing the credibility of information is closely related to the extent to which one is willing to place trust in the
information.
Trust can be formulated based on the intention of the information source, which may be provided by reputation or certification (Barber, 1983). Trust is “an expectancy held by an
individual or a group that the word, promise, verbal, or written statement of another individual or group can be relied on” (Rotter, 1967, p. 444). Trust can emerge and be derived from their repeated interaction over time (Rousseau, Sitkin, Burt, & Camerer, 1998). Long-term interaction can lead to the formation of trust based on reciprocated interpersonal care and concern
(McAllister, 1995). Trust is considered something that can be changed, developed, increased and decreased by interactions or relationships (Rousseau et al., 1998).
trustees) (Doney & Cannon, 1997), bonding (development of a trustor-trustee relationship) (Kelton, Fleischmann, & Wallace, 2008), reputation (awarding of trust on the recommendation of others and in this stage), and identification (sharing a common identity, goals, and values) (Kelton et al., 2008). Reputation can be spread through reviews, information from other users, or online ratings (Chopra & Wallace, 2003). “The main reason that we are interested in finding information sources that are authoritative, objective, and current is because we think that they are more likely to be accurate” (Fallis, 2004, p. 2). Finding information by using trustworthiness of users is based on the assumption that certain users will provide better information than others (Bouguessa, Dumoulin, & Wang, 2008), although users with good reputations do not always provide high-quality information (Fichman, 2011).
The perception of credibility is a personal judgment of the user, and it is hard to be objective about the information object or its provider (Fogg et al., 2001). Credibility judgment is a substantially subjective process that reflects an individual's knowledge, experience, and
expertise (Rieh, 2010). When people evaluate the credibility of online reviewers or the
usefulness of online reviews, they are influenced by information that represents the reviewers' identity or expertise based on their profile or review (Forman, Ghose, & Wiesenfeld, 2008; Jeon & Rieh, 2014; Willemsen, Neijens, & Bronner, 2012). One approach is to rank authority of information providers based on link analysis (Jurczyk & Agichtein, 2007a, 2007b).
However, Tseng and Fogg (1999) differentiated credibility from trust in that credibility is close to believability and trust is close to dependability. In other words, credibility is the
Credibility may or may not cause trust in the source of information (Rieh & Danielson, 2007). The difference between trust and credibility in the context of this dissertation research is that trust is a particular dependency (or reliance) on the source of information and credibility is the degree of overall believability, which can work both on the information object and the
information source.
It is typically acknowledged that credible sources and credible messages are
fundamentally interlinked (Slater & Rouner, 1996). Information seekers tend to believe that their friends, family members, and colleagues are generally trustworthy and more competent than others. They consider them to be credible sources of information (Rieh & Danielson, 2007; Wilson, 1983). This phenomenon has also been called “word-of-mouth effects” in the field of communication. Source credibility is a critical factor when assessing the credibility of
information, and the characteristics of sources (e.g., source reputation, type of sources, and author credentials) should be examined in order to understand the process of credibility assessment (Rieh & Danielson, 2007). We need to know how people formulate credibility depending on developmental experiences, personality types, contexts (including cultural backgrounds), the objects of credibility, the stages of developing credibility, and social
relationships with the information source. Moreover, we need to examine the link between the credibility of information (expertise in this study) and the credibility of the information source (trustworthiness in this study) and the interactions between these two aspects of information. 2.2.3 Credibility
Rieh, 2008). In the field of communication, researchers and practitioners have conducted credibility studies regarding people’s choice of media such as TV, radio, and newspaper (Metzger, Flanagin, Eyal, Lemus, & Mccann, 2003). The assumption associated with these studies is that people consume information from media outlets that produce accurate, fair,
objective, and informative content (Johnson & Kaye, 2000). Credibility assessments of media are fundamentally interlinked with sources and messages, and they influence each other (Slater & Rouner, 1996). At the same time, credibility is frequently attached to objects – source, message, and media – and credibility of these objects is often different (Kiousis, 2001).
MIS researchers have focused on the credibility of advice provided by expert systems and decision support systems and the impact of the advice on decision-making (Hilligoss & Rieh, 2008). Researchers in the field of information science have an interest in the role of credibility in information seeking and retrieval. In information science, credibility has often been considered as an important criterion for judging relevance of retrieved information. (Rieh & Danielson, 2007).
Despite these diverse perspectives, the overarching view across various definitions of credibility is believability. Credible people are considered to be believable, and credible information is also considered to be believable (Hilligoss & Rieh, 2008; Tseng & Fogg, 1999). Notwithstanding the absence of a clear definition, many scholars (Flanagin & Metzger, 2008; Flanagin & Metzger, 2008; Hovland, Janis, & Kelley, 1953; Rieh, 2010; Tseng & Fogg, 1999; Wilson, 1983) consider credibility to be the believability of a source, message, or media that consists of two main dimensions of trustworthiness and expertise. Believability refers to “people’s confidence in the truth of information without having some form of absolute proof” (Rieh, Jeon, Yang, & Lampe, 2014, p. 438). Trustworthiness refers to people’s belief in the information source (information provider). Expertise refers to an ability with which an agent or group of agents can provide accurate information (information content).
According to Fallis (1999), the way to make health information more easily verifiable is to increase access to two types of evidence. The first type of evidence is direct evidence of the accuracy of information such as empirical studies of the effectiveness of a particular medical treatment. Another type of evidence is indirect evidence of the accuracy of information such as the medical certificate of an individual who supports the medical treatment (Fallis, 2004). Researchers in library and information science have emphasized that people should consider the source of information when attempting to verify it. On the other hand, philosophers have
emphasized that people need to look at information itself closely. Philosophers, especially, pay particular attention to the reasons for backing up the claim and the plausibility of the claim (Fallis, 2004).
factors influencing the judgment of information quality and cognitive authority. According to Rieh and Danielson (Rieh & Danielson, 2007), credibility has been operationalized by reliability and accuracy in many studies. In other words, they equated the reliability and accuracy with trustworthiness and expertise respectively. The commonality of these studies is that the
characteristics of information objects and information sources are essential factors in verifying information. “While trust and expertise have meaning separate from credibility and from each other, credibility is usually conceived as possessing at least some degree of both trust and expertise in combination” (Flanagin & Metzger, 2008, p. 141). In this dissertation study, trustworthiness is considered to be a peripheral cue that utilizes source-based heuristics, and expertise is considered to be a central cue that scrutinizes messages contained in health
information. The term of credibility refers to the perceived credibility of information rather than the objective measurement of the quality of information.
2.2.4 Summary
With the emergence of Web 2.0 and social media, an expanded set of criteria needs to be considered for distinguishing between relevant and non-relevant information (Rieh & Belkin, 1998). The concept of “information quality” has been widely used to distinguish between correct (high-quality) and incorrect (low-quality) information. Quality has more focus on verifying information content, although this approach is not feasible in the current information
environment. Insufficient sources of comparable information are available when considering the vast quantity of information that needs to be verified.
characteristics are peripheral cues in judging the quality of information and focus more on judging the information source. Thus, we need a balance between quality and trust, and a new notion of quality—credibility—needs to be applied in the context of social media in predicting the quality of information. Credibility can be applied both to the information object and the information source and accommodate both objective and subjective aspects of information evaluation. Perceived credibility that is measured using a credibility instrument is the target of prediction in this dissertation study. More details on the credibility instrument will be introduced in a later section.
2.3 Theories and Models Related to Credibility
In the previous section, the definitions of credibility and related concepts and the factors that influence them have been reviewed. In this dissertation research, understanding how people seek credible information and judge the credibility of that information is critical. Thus, this section will review literature on credibility and information seeking. There are several theories and models of credibility and information seeking that can be particularly useful for
understanding the credibility judgments of health information users. These include: Wilson’s Model of Information Behavior (1997), Prominence and Interpretation Theory (Tseng & Fogg, 1999), Elaboration Likelihood Model (Richard E. Petty & Cacioppo, 1986), and Hilligoss and Rieh’s theoretical framework for credibility (2008). These previous studies provide a valuable theoretical framework that serves as a conceptual basis for this study.
2.3.1 Wilson’s Model of Information Behavior
environmental factors. In his second model (1999), he incorporated the context of information seeking in which the environmental context, social role, and personal role can work as supports or barriers. Wilson (1981) also asserted that information needs are secondary and are driven by three other basic needs: cognitive, affective, and physical. For instance, an affective need for information can be filled by communicating with a person or a support group, whereas a cognitive need can be met by reading a written source of information.
Many researchers have adopted Wilson’s models of information behavior and have applied them to information behavior research. It is commonly acknowledged that information is actively constructed, dependent on the context, and highly individualized (Williamson &
Manaszewicz, 2002). As Williamson and Manaszewicz (2002) asserted, ‘One size does not fit all.’ From a credibility standpoint, it is important to consider the cognitive, affective, and
environmental factors affecting credibility judgments. Therefore, one of the main goals of this dissertation study is to investigate the variations of credibility factors influenced by the type of social media, prior knowledge, and topic.
2.3.2 Prominence-Interpretation Theory
instance, a good visual design can increase the surface credibility of a website. Experienced credibility refers to believability based on first-hand experience.
Tseng and Fogg (1999) also proposed three types of credibility evaluation: binary, threshold, and spectral evaluation. A binary evaluation is the simplest evaluation strategy
because information is classified as credible or not credible. This evaluation happens when a user has low interest and ability to process information or little prior knowledge with the subject matter. The threshold evaluation incorporates upper and lower thresholds. If the perceived credibility is over the upper threshold, the information is considered “credible.” If the perceived credibility is under the lower threshold, the information is considered “not credible.” If the perceived credibility is between the upper and lower thresholds, the information is considered “somewhat credible” or “fairly credible.” This evaluation happens when a user has moderate
interest, cognitive ability, or prior knowledge. The spectral evaluation is the most complex evaluation strategy. In this evaluation, the credibility of information increases gradually according to the level of credibility. This evaluation happens when a user has high interest, cognitive ability, or prior knowledge.
influence on credibility, so people with a title such as Dr. and professor are also considered more credible (Cialdini, 1993).
Based on the previous studies, Fogg (2003) developed the Prominence-Interpretation theory that explains how people judge the credibility of websites. The theory argued that the impact made by Web page elements has a close relationship to both its prominence (the
likelihood of being noticed) and interpretation (the meaning assigned to it) (Fogg, 2003). In other words, users notice something important (prominence) and make a judgment about it
(interpretation). Fogg (2003) argued that there are five factors in prominence: involvement of the user, topic, search task, experience, and individual differences. Among these, the user’s
involvement (such as motivation) was the most crucial factor in noticing the most useful prominent element. The three main factors for the interpretation process are assumptions, skill/knowledge, and context.
does not explain how factors of credibility will vary according to the prior knowledge of assessors. Therefore, the experiments examine how factors of credibility can vary according to an assessor’s prior knowledge.
2.3.3 Elaboration Likelihood Model
Elaboration Likelihood Model (ELM) (Petty & Cacioppo, 1986) is a theory of persuasion and was first developed in the field of psychology. This theory assumes that readers tend to judge the credibility of text either based on arguments of the text or through external cues such as the type of publication (Freeman & Spyridakis, 2004). Elaboration is the extent to which a person critically examines the arguments contained in a message (Petty & Cacioppo, 1986). In other words, it is the probability of doing a critical assessment of the arguments. The
"elaboration likelihood" increases when an individual has the motivation and ability to think
critically about the information being examined.
In persuasion, there are two routes: a central route and a peripheral route (Petty & Cacioppo, 1986). The central route is used to assess information logically by evaluating the claims of the content in the communication to determine the credibility of the information. It is the result of the careful consideration of the substance of the information provided to support the claim. Readers should make a substantial cognitive effort to evaluate arguments in the
information. With regard to the peripheral route, people rely on cognitive clues to determine the credibility of the information source. Peripheral routes are the result of relying on simple cues or heuristics (e.g., the attractiveness of a source) rather than by thoroughly reviewing the substance of the information provided.
weaken the likelihood of elaboration, the second kind of persuasion, the peripheral route, occurs (Petty & Cacioppo, 1986). Critical thinking largely depends on two primary factors: motivation and ability. If we have high motivation or ability, we will use a central route. If we have low motivation or ability, we will use a peripheral route. Only those with very high motivation or those with high ability will verify the content, as it will require a lot of effort. While evaluating online information, the peripheral route becomes the default route to assess credibility (Ohshima et al., 2011; Thomson et al., 2012). Ohshima et al. (2011) elaborated on Hovland (1953) by suggesting that peripheral clues consist of “the degree to which a communicator is perceived to have adequate expert knowledge and trustworthiness (p. 3).” The persuasion created by the two different routes has different effects on our life. In several cumulative works of literature, the first kind of persuasion (central route) appears to last longer and probably has more effects on how we behave than the second kind of persuasion (peripheral route) (Cook & Flay, 1978; Petty & Cacioppo, 1986; Petty, 1977).
2.3.4 Rieh’s Theoretical Framework for Credibility
Rieh (Rieh, 2002; Rieh & Belkin, 2000) introduced two types of credibility judgments when people search the Web for information: predictive judgment (expecting what will happen before people look at the search results) and evaluative judgment (expressing preference after people inspect the search results). For predictive judgment, people mainly analyze system structure and system functionalities. Predictive judgment is important in modern information environments in which a massive amount of information is handled. On the other hand, people analyze characteristics of information objects for evaluative judgment. These two types of judgments are interlinked and iterative processes. People make predictive judgments first and make evaluative judgments later. If the information quality matches their expectations, they continue to use the same information source.
These two types of judgments support the results of Nelson’s studies (1970, 1974) about consumer behaviors in quality inspections, in which he found the fundamental differences between the search quality of a product that can be determined prior to purchase (such as the design of a dress) and the experience quality that cannot be determined until after purchase (such as the taste of canned food). According to the elaboration likelihood model, by depending on the credibility of the source, the peripheral route is used rather than the central route, causing a change of attitude such as making the behavior more predictive (Petty & Cacioppo, 1986).
information quality (good, accurate, current, useful, and important) is closely connected to the expertise of the source, and cognitive authority (credible, reliable, scholarly, official, and authoritative) is closely connected to trustworthiness.
In a similar vein, the characteristics of information are divided into two types:
characteristics related to information objects and characteristics related to information sources. The examples for characteristics of information objects are information type, title, and content. The examples for characteristics of information sources are URL domain, reputation, and author credentials. Hilligoss and Rieh (2008) have developed a theoretical framework that includes three levels of credibility judgments related to credibility assessment: construct, heuristics, and interaction. The construct level is the step for users to conceptualize and construct credibility. The heuristic level is to evaluate credibility by developing and applying general rules of thumb based on the concept. Interaction level requires extraordinary efforts to evaluate particular content, peripheral source cues, and peripheral information object cues (Hilligoss & Rieh, 2008; Jeon & Rieh, 2014). The proposed framework of credibility assessment supports ELM in that credibility is sometimes assessed using cues for the source and other times assessed evaluating the content.
2.3.5 Summary
These different types and assessment processes of credibility sometimes need simple cues (e.g., peripheral route and predictive judgments) and on other occasions require a critical assessment (e.g., central route and evaluative judgments). Second, credibility is made up of a number of different factors (e.g., goodness, accuracy, and currency) that are affected by various contexts (e.g., topic, experience, and individual difference).
These previous studies provide a theoretical framework that serves as a conceptual basis for this study. The content analysis that aims to investigate factors of credibility judgments is conducted based on these theories and models of credibility. Especially, ELM will be the main basis of the theoretical framework. The research questions to investigate variations of credibility factors influenced by the type of social media, prior knowledge, and topic were also developed based on these theories and models.
2.4 Concepts Related to Credibility, Their Criteria, and Operationalization
three types (content, source, and others) and how they have been operationalized in prior work for descriptive and predictive modeling.
2.4.1 Criteria Related to Credibility Assessment Criteria related to information content
Accuracy is considered to be most indicative of the quality of information. It is the “sine qua non” of the quality of the information source (Fallis, 2004, p. 2). According to Fallis (2004), four important indicators of accuracy are an authority, independent corroboration, plausibility and support, and presentation. Taylor (1986) introduced four more criteria of information quality: comprehensiveness, currency, reliability, and validity. Wand and Wang (1996) claimed that completeness, consistency, and timeliness are core dimensions of data quality. Wilson (1983) also found that the plausibility of information content is closely related to increasing or decreasing cognitive authority. The plausibility of content has critical value in the era of the Web and social media.
Criteria related to information source
The reputation and credential of the information source are also critical factors for information quality and cognitive authority (Rieh & Belkin, 2000). Credential denotes a qualification, personal quality, or aspect of a person’s affiliation and background. Source characteristics such as reputation were important criteria for both predictive and evaluative judgment (Rieh, 2002). Rieh (2002) found five judgment criteria regarding characteristics of source: URL domain type, type of source, source reputation, one source - collective sources, and author/creator credentials. Among these characteristics, the type of source and the source
reputation were primarily mentioned as judgment criteria for information quality and cognitive authority by participants for all types of information search.
How can we make decisions if a number of different people are claiming to be
reputation among others as an indicator of outstanding competence (Wilson, 1983). While reputation is not direct proof of the wisdom of an information source, it can be a reasonable basis when selecting an information source (Wilson, 1983).
Kleinberg (1999) has suggested a way to pick out the few most authoritative web pages out of many relevant web pages. The hyperlink structure between Web pages can encode latent human judgments that are quite precise in formulating the credibility of web pages. The
PageRank algorithm (Brin & Page, 1998) has been used by Google to identify high-quality websites utilizing the link structure of the web. As we know, this has been the most successful method to provide users with high-quality and relevant search results. Social network metrics such as eigenvector, which take into account the importance of friends similar to the PageRank, have been used in the computational trust models. Reputation rule works well in many cases, but it can also lead to different outcomes depending on how an appropriate reference group whose collective opinion is considered as an index of competence is chosen.
However, there is a problem with this reputation-based system. There is no guarantee that the witness will not either deceive or be deceived (Hume, 1977). At Amazon, some fraudulent sellers sell large quantities of low-priced products early in the sale to raise their star rating. However, these fraud sellers often sell expensive products later and do not deliver them, thereby disabling the reputation system. This example is one of the reasons why finding a right balance between the attributes of the information object and the information source is critical in judging the credibility of information.
Criteria related to other aspects of information
Hume (1977) asserts that people should particularly pay attention to the manner in which testimony is delivered. For example, the attitude and manner of a witness often can be indicative of the reliability of the witness. The organization/structure of the presentation of information such as the writing style and grammar is one facet of criteria in judging the quality of
information (Rieh, 2002; Rieh & Belkin, 2000). If a website contains any spelling or
grammatical errors, these mistakes show the authors' lack of interest in quality and accuracy (Cooke, 1999; Wilkinson, 1997). If a person is careful to use correct spelling and grammar, he/she is more likely to pay attention to conveying the right facts (Fallis, 2004). Tombros et al. (2005) also find that errors in a web page are an important indicator of the quality of information.
Fogg et al. (2001) conducted an online survey of more than 1,400 participants to examine elements of the Web affecting people’s perception of credibility “Real-world feel” and “ease of use,” increased the perception of credibility, and “commercial implications” and “amateurism”
decreased the perception of credibility.
Criteria affecting the credibility judgments that belong to one of three groups of
the characteristics of an information source affect the perceived credibility of information under the assumption that a credible source produces credible information. Conversely, the attributes of information are used to build source credibility when there is little to no information about the source (Kim, 2010; Rosenthal, 1971; Slater & Rouner, 1996). In other words, the groups of credibility concepts to which these criteria belong are not necessarily mutually exclusive. Credibility assessment is an iterative and interactive process among information object and its sources. The concepts and their corresponding criteria reviewed are summarized in Table 1.
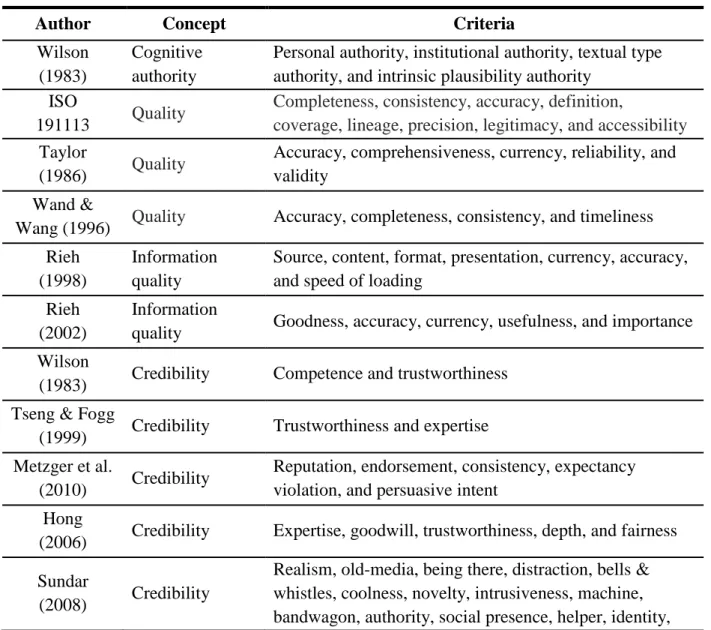
Table 1. Concepts Related to Credibility and Their Criteria
Author Concept Criteria
Wilson (1983)
Cognitive authority
Personal authority, institutional authority, textual type authority, and intrinsic plausibility authority
ISO
191113 Quality
Completeness, consistency, accuracy, definition,
coverage, lineage, precision, legitimacy, and accessibility
Taylor
(1986) Quality
Accuracy, comprehensiveness, currency, reliability, and validity
Wand &
Wang (1996) Quality Accuracy, completeness, consistency, and timeliness Rieh
(1998)
Information quality
Source, content, format, presentation, currency, accuracy, and speed of loading
Rieh (2002)
Information
quality Goodness, accuracy, currency, usefulness, and importance Wilson
(1983) Credibility Competence and trustworthiness Tseng & Fogg
(1999) Credibility Trustworthiness and expertise Metzger et al.
(2010) Credibility
Reputation, endorsement, consistency, expectancy violation, and persuasive intent
Hong
(2006) Credibility Expertise, goodwill, trustworthiness, depth, and fairness Sundar
(2008) Credibility
interaction, activity, responsiveness, choice, control, telepresence, flow, contingency, similarity, browsing, elaboration, scaffolding, play, prominence, and similarity
2.4.2 Operationalization of Credibility Criteria
To facilitate the communication of credible online information, previous studies have applied automatic methods for assessing the credibility of information (e.g., Castillo et al., 2011; Ciampaglia et al., 2015; Sondhi et al., 2012). These studies operationalized credibility factors as features for machine-learned models. The final goal of the dissertation study is to build and evaluate computational credibility models. In this section, I review credibility models for health information and social media. Some models are descriptive, and others are predictive.
Furthermore, I consider studies that focused on textual and non-textual sources of evidence. I describe how prior work operationalized credibility factors as features for machine learning according to three types (content, source, and others).
Operationalization related to information content
Benevuto et al. (2010) developed models to detect spammers on Twitter. Results found several trends. First, spammers were found to publish tweets with more URLs, spam words, and hashtags. Second, spammers were found to reference multiple trending topics in the same tweet. O’Donovan et al. (2012) found that credible tweets are more likely to contain language
phenomena (e.g., question, exclamation, smile, and sentiment) that is rare. In particular, credible tweets had more “news” feature that computes similarity between tweets and data archived at Twibe (a service archiving credible tweets and users).
Yamamoto and Tanaka (2011) selected five factors to judge the credibility of Web search results: accuracy, objectivity, authority, currency, and coverage. They operationalized those five factors by making several assumptions. First, they assumed that accurate Web pages are
mean number of credible Web pages found by their system + Google was significantly larger than when only using Google (p <0.01).
Ciampaglia et al. (2015) utilized the shortest path between concept nodes in the semantic proximity metrics on the knowledge graph to evaluate the veracity of information. They
constructed the semantic proximity metrics by using a public knowledge graph extracted from Wikipedia. They extracted the factual statements of Wikipedia’s “infoboxes” from the DBpedia database (Auer et al., 2007). For example, the statement “Socrates is a person” can be
represented by a subject-predicate-object triple as “Socrates,” “is a,” “person.” These triples constitute a knowledge graph (KG) in which nodes denote entities (e.g., subject or object of the statement) and edges denote predicates. Given a statement, if a short path linking its subject to an object exists within the KG, the statement can be considered true. For instance, their best
algorithm (which used k-NN), achieved 96 in Area under Receiver Operating Characteristic (ROC). They exploited the implicit information from the topology of the Wikipedia Knowledge Graph (WKG) and operationalized it with the semantic proximity metrics. In the domain of health informatics, the Semantic Knowledge Representation based on the UMLS has been produced and maintained by the national library of medicine (NLM) (Aronson & Rindflesch, 1998). The NLM also developed the Semantic Knowledge Representation (SemRep) program that extracts semantic predications from text. These resources from the authoritative organization have potential usefulness for enriching knowledge graphs in improving decision making for credibility judgments.
appear in high-quality websites but rarely appear in low-quality ones. Those quality queries could be expanded and filtered by applying the relevance feedback algorithm. They produced a golden dataset by using statements in the Oxford University Centre for Evidence-Based Mental Health’s guidelines for treating depression. The performance of AQA outperformed the Google PageRank algorithm regarding correlation with a golden dataset. It should be noted that authors applied this automated filtering approach only to depression websites.
Saglam and Temizel (2015) proposed a framework that automatically identifies and classifies diabetes websites according to relevance and information quality. This was one of a few studies that handled both relevance and information quality (Sağlam & Temizel, 2015; Seidman, Steinwachs, & Rubin, 2003). They adopted the relevance feedback approach introduced by Griffiths et al. (2005) and added sentiment analysis. The authors first filtered biased and untrusted websites out by using the subjectivity detection approach that was proposed by Denecke (2009) and based on SentiWordNet (http://sentiwordnet.isti.cnr.it/). They assumed that a sensational writing style (e.g., excessive exclamation marks) and the frequency of positive and negative words could reveal whether a site was biased or not. Then, the quality queries were expanded by using the relevance feedback algorithm. Several studies have demonstrated the effectiveness of simple word frequency, and these quality queries, which frequently appear in high-quality information, could be extended through relevance feedback algorithm.
Aphinyanaphongs and Aliferis (2007) applied text categorization models to another topic. This study aimed to identify the quality of health information about unproven cancer treatments. Their approach was unique in that they did not identify high-quality pages, but low-quality pages. Thus, they adopted the approach of information avoidance (Sweeny, Melnyk, Miller, & Shepperd, 2010) as email service providers apply spam filter for their users. They used gold standard on unproven cancer treatments identified by experts at the Quackwatch. Their model outperformed the result (AUC=0.63) by Quacko meter (http://quackometer.net) that applied alternative medication terms for their modeling and also outperformed another baseline approach based on the PageRank algorithm (Brin & Page, 1998). This dissertation study also applies the information avoidance approach by focusing on classifying not_credible information, because it is a minority class and filtering spam information makes more sense in real life.
Operationalization related to information source
With the assumption that a user with more authority would register more tweets, Mendoza et al. (2010) investigated the number of followers and followees on Twitter. For top users, the number of followers is two times larger than the number of followees. The number of followers decreases when the number of tweets that a user created decreases. They also found that top users tended to be connected to one another by friendships. This implies that we can give more credentials to users who are socially connected to other users. Network analysis was
originated from sociology to find meaningful patterns in people's social networks and can produce discriminative features for the credibility models.
while the context of the study by Benevenuto et al. is related to a trending hot topic such as Michael Jackson’s death. Therefore, we need to more carefully examine the relationship between the number of followers and the number of followees for credibility judgment. The explanation by Mendoza et al. (2010) about spammers’ dual behavior, usually sharing non-spam tweets to pretend to be a non-spammer, but spreading spam tweets occasionally, partly explains the high ratio of followers per followees.
Gupta et al. (2013) collected user profiles that are suspended by Twitter during the event of the Boston Marathon Blasts and analyzed their characteristics. There were several interesting findings. First, many malicious accounts were made just after the bomb blast, and it took about 8 hours for fake tweets written by them to become viral. The source accounts of fake content had a low social status (e.g., a small number of followers) and unconfirmed identity. However, once other users with high social status (e.g., celebrities and politicians) retweeted those fake contents, the spread of the fake contents showed steep growth. The effect of the identity fraud might be related to previous studies in which the social status did not contribute to predicting credibility. Second, they found each group who tweeted true or fake tweets were unique to each other. In other words, fake users cooperated and formed a closed-community by retweeting each other’s tweets. Their analysis indicated that tracing back to the original source of information and observing their mutual interactions will be critical in identifying fake content.
(spam user: 8.66 tweets per day, legitimate user: 6.7 tweets per day). The total number of followers and friends for spammers was three times larger than that of legitimate users. These results did not support the finding by Gupta et al. (2013). The generalizability of their findings to other contexts should be carefully examined.
Operationalization related to information content, source, and other features
Price and Hersh (1999) were the first pioneers who applied an empirical approach to find high-quality consumer health information on the Web. They developed a program to identify some quality criteria such as authorship information and Health On the Net Foundation’s Code of Conduct (HONcode) (Boyer, Selby, Scherrer, & Appel, 1998) acceptance, amount of content, currency, and average link score and return quality scores. They did not make clear the accuracy and precision of the study in the report on their experiment, and their results were too
preliminary to be considered conclusive, it is meaningful in that they opened the door of automatic assessment of quality in the domain of online health information.
Abbasi et al. (2012) utilized an adaptive learning algorithm called recursive trust labeling (RTL) that consists of content and graph-based classifiers. Content-based features comprising of fraud cues were extracted from the Web pages’ body text, source code, anchor text, and URLs, and word n-grams were used to represent body text features. To reduce redundancy in fraud cues, the authors utilized the Unified Medical Language System (UMLS) MetaThesaurus (https://www.nlm.nih.gov/research/umls/) to aggregate synonymous concept words. For graph-based classifier, they adopted dual class (legitimate and fake sites) with two ways (in-link and out-link), as the assumption of the PageRank principles that fake websites can point to legitimate websites, but cannot force legitimate websites to point to them (Page, Brin, Motwani, &
Winograd, 1999) may not be valid for fake medical websites. By comparing the result by RTL classifier with 19 other classifiers, they demonstrated that the recursive labeling mechanism enhanced detection of fake medical websites by effectively leveraging the information provided by these two classifiers.
Castillo et al. (2011) investigated how people judge the credibility of tweets concerned with trending events (e.g., earthquakes). Results found that both content- and source- related features were closely related to assessors’ credibility judgments. Content-related features were whether the user cited a source, if the user questioned the information, and if the user used a lot of opinionated statements in the tweet. Source-related features were account activity (e.g., frequency of posting), age of account, and number of followers. Also, tweets that have been re-tweeted many times tended to be more credible.
Another study by Castillo et al. (2013) used the crowdsourcing tool Mechanical Turk to generate ground truth data. To increase the quality of labeling from crowdsourcing, the
was given to seven assessors. If more than five assessors agreed then the label was utilized, otherwise ignored. They posited that there are several factors which are useful to predict
credibility of information: the reactions like positive and negative sentiment which are generated by certain topic, the level of certainty expressed by users who propagate the information,
external sources cited (e.g., top 100 popular domain), and characteristics of users (e.g., the number of followers). According to the feature selection study based on the correlation-based feature selection (CFS) subset evaluation, there were 16 most useful features such as the average number of tweets posted by the author in the topic in the past, the average number of followees, and the maximum depth of the propagation trees.
Xia et al. (2012) conducted an experiment with supervised learning to predict credibility of tweets. They collected 350 tweets and asked five experts to label them as credible or non-credible. Four categories of features were utilized: source-related feature (e.g., time interval of last 2 tweets and total number of tweets per day), content-related feature (length of the tweet and number of the reply comments), topic-related feature (e.g., the URL fraction of the tweet and the hashtags fraction of the tweet), and diffusion-related feature (e.g., time of the tweet cited and time of the original tweet was cited in case of retweet). Their approach achieved equivalent performance (precision: 0.61 and recall: 0.64) to the state-of-the-art SVM algorithm.
made a comprehensive set of credibility factors. Based on the final code book, they ran the second round of crowdsourcing to collect credibility factors of previous workers’ justifications. They also created a predictive model of Web content credibility using these crowd workers’ credibility evaluations and credibility factors. In the linear regression model, the root mean square error (RMSE) reached 0.709 which was better than the random and constant value model. However, the features in their study were not automatically generated, but annotated by AMT workers. Thus, this approach has a limitation in terms of automation.
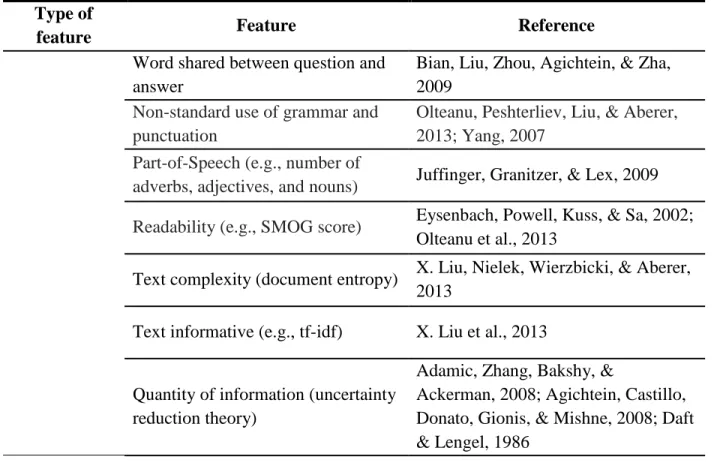
Most of the features described in the studies above focus on attributes of the content, author, format, etc. All details of the features for machine learning cannot be fully described here but features that are most likely to be discriminative in predicting the credibility of online social question & answer (Q & A) and reviews are summarized in Table 2.
Table 2. Promising Features in Predicting Credibility of Information and Source Type of
feature Feature Reference
Word shared between question and answer
Bian, Liu, Zhou, Agichtein, & Zha, 2009
Non-standard use of grammar and punctuation
Olteanu, Peshterliev, Liu, & Aberer, 2013; Yang, 2007
Part-of-Speech (e.g., number of
adverbs, adjectives, and nouns) Juffinger, Granitzer, & Lex, 2009 Readability (e.g., SMOG score) Eysenbach, Powell, Kuss, & Sa, 2002;
Olteanu et al., 2013
Text complexity (document entropy) X. Liu, Nielek, Wierzbicki, & Aberer, 2013
Text informative (e.g., tf-idf) X. Liu et al., 2013
Quantity of information (uncertainty reduction theory)
Adamic, Zhang, Bakshy, &
Content-based
Vividness, descriptiveness, and strength of message (e.g., inclusion of personal experience, number of suggestions)
Adamic et al., 2008; Agichtein et al., 2008; Daft & Lengel, 1986
Perceived expertise (ratio of jargon) Jeon & Rieh, 2014 Frequency of modal and inferential
conjunction
Mukherjee, Weikum, & Danescu-Niculescu-Mizil, 2014
Sentiment (e.g., frequency of
affective words, attitude, tone) Kim, 2010; Mukherjee et al., 2014 Content similarity with validated
source Juffinger et al., 2009
Redundancy of the content Drost & Scheffer, 2005
Frequency of emoticons Weerkamp & Rijke, 2008 Fraction of content containing spam
words
Benevenuto, Magno, Rodrigues, & Almeida, 2010
Authorship (authors and their affiliation) and attribution
(references and sources of content)
Lederman, Fan, Smith, & Chang, 2014; Silberg, Lundberg, & Musacchio, 1997
Number of witnesses (e.g., number
of positive replies) Don Fallis, 2004; Hume, 1977
Link-based
PageRank Brin & Page, 1998
HITS Kleinberg, 1999
Network metrics (e.g., degree, eigenvector, betweenness)
Mui, Mohtashemi, & Halberstadt, 2002
Ratio of external/internal inbound
links to outbound links Liu, Wei, Zhang, & Zhou, 2013 Number of internal/external inbound
links Liu et al., 2013
Ratio of number of replies to
number of questions Liu et al., 2013 Maximum depth of the propagation