Capturing the Stars: Predicting Ratings for Service and Product Reviews
Full text
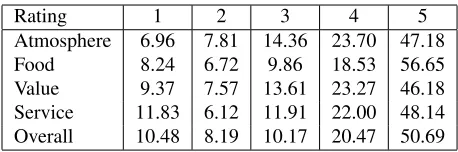
Figure


Related documents
This suggests that although police forces in many European countries see their role in enforcing compliance with seat belt laws as minimal at best, due to the belief that
Atlikto tyrimo duomenimis, pacientų, gydytų trombocitų praturtintos plazmos geliu, grupėje žaizdų sekrecijų dažnis tyrimo pabaigoje buvo statistiškai reikšmingai mažesnis
When transfecting HEK 293T cells with either “mIFP-P2A-mNG2(full)” or “mIFP- P2A-mNG211SpyCatcher and mNGX1-10 (X represent 2, 3A or 3K)”, we observed both mNG31-10
In Example 3, a production line which has a 20% defec- tive rate, what is the minimum number of inspections, that would be necessary so that the probability of ob- serving a
We find that the demanded upfront payment is higher in the case of printed pens than plain pens, which suggests that indeed wholesalers fear the possibility of being held up ex
Then, comparing the effect of CEEMDAN and EEMD on bearing fault feature frequency extraction, the experiment proves that CEEMDAN has a better ability to preserve original signal
Topic Number of reactions per topic Water quality 50 Focus farms 74 Nitrate residue 51 Nitrogen fertilisation standards 84 Phosphorus fertilisation standards 217
