International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
363
Speech Feature Extraction and Recognition Using Genetic
Algorithm
Hitesh Gupta
1, Deepinder Singh Wadhwa
2BGIET, Sangrur, Punjab, India.
Abstract People are so comfortable with speech that they would also like to interact with computers via speech, rather than having to resort to primitive interfaces such as keyboards and pointing devices. However, undesired noises in environment like sound from heavy machines, vehicles are also present that causes undesired effects in speech transmission and acquiring systems reducing the performance of the machine receiving the speech signal. Advanced speech enhancement algorithms can be classified in main three categories, namely; filtering/estimation based noise reduction, beam forming and active noise cancellation (ANC) techniques. Recent work shows improved performance results when GA is applied on speech signals recorded under noisy conditions. The work here applies evolutionary computation in form of genetic algorithm to select the features that are responsible for discriminating the different words. In doing so, the amount of feature elements to be used also gets reduced and hence system can be made to recognize the word-speech with real-time performance.
Keywords: speech recognition, genetic algorithms, MFCC, FBCC
I. INTRODUCTION
1.1 Speech Recognition
1.1.1 Introduction to Speech Recognition
Speech is a natural mode of communication for people. We learn all the relevant skills during early childhood, without instruction, and we continue to rely on speech communication throughout our lives. Vocalizations can vary widely in terms of their accent, pronunciation, articulation, roughness, nasality, pitch, volume, and speed; moreover, during transmission, our irregular speech patterns can be further distorted by background noise and echoes, as well as electrical characteristics (if telephones or other electronic equipment are used). All these sources of variability make speech recognition, even more than speech generation, a very complex problem.
Yet people are so comfortable with speech that we would also like to interact with our computers via speech, rather than having to resort to primitive interfaces such as keyboards and pointing devices.
A speech interface would support many valuable applications — for example, telephone directory assistance, spoken database querying for novice users, “hands busy” applications in medicine or fieldwork, office dictation devices, or even automatic voice translation into foreign languages.
1.1.2 Paradigm for Speech Recognition
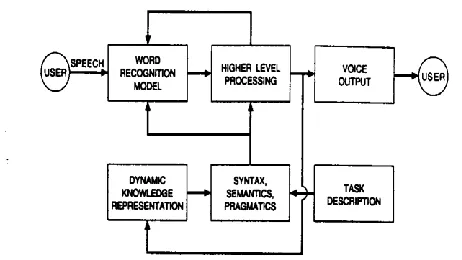
[image:1.612.324.555.337.467.2]A general model for speech recognition, as shown in Fig.1.1 is used here.
Figure 1.1. General block diagram of a task oriented speech recognition system.
The conditions of evaluation — and hence the accuracy of any system — can vary along the following dimensions:
Vocabulary size and confusability
It is easy to discriminate among a small set of words, but error rates naturally increase as the vocabulary size grows.
Speaker dependence vs. Independence
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
364
Isolated, discontinuous, or continuous speechIsolated speech means single words; discontinuous speech means full sentences in which words are artificially separated by silence; and continuous speech means naturally spoken sentences. Isolated and discontinuous speech recognition is relatively easy because word boundaries are detectable and the words tend to be cleanly pronounced.
Task and language constraints
Even with a fixed vocabulary, performance will vary with the nature of constraints on the word sequences that are allowed during recognition. The difficulty of a task is more reliably measured by its perplexity than by its vocabulary size.
Read vs. spontaneous speech
Systems can be evaluated on speech that is either read from prepared scripts, or speech that is uttered spontaneously. Spontaneous speech is vastly more difficult
Adverse conditions
A system’s performance can also be degraded by a range of adverse conditions like environmental noise ,acoustical distortions, different microphones ,limited frequency bandwidth and altered speaking manner.
The central issue in speech recognition is dealing with variability. Currently, speech recognition systems distinguish between two kinds of variability: acoustic and temporal. Acoustic variability covers different accents, pronunciations, pitches, volumes, and so on, while temporal variability covers different speaking rates. These two dimensions are not completely independent — when a person speaks quickly, his acoustical patterns become distorted as well — but it’s a useful simplification to treat them independently.
1.1.3 Research in the field of speech recognition
Various approaches for noise reduction and speech enhancements have been investigated and developed. Wiener filter can be adaptively estimated used in an environment where the surrounding noise has time-varying characteristics. Adaptive algorithms such as Least Mean Square (LMS) and Recursive Least Squares (RLS) are well known examples and also widely used.
The speech enhancement is not only useful for storage and transmission of speech data but it can play vital role in improving much need system based speech recognition where accurate identification of words and sentences can provide automation in most of the human-machine based interface and also be useful in machine-machine interaction based automation. It is obvious that speech enhancement can boost up the performance of speech recognition systems by keeping low word error rate (WER).
There are various types of advanced speech enhancement algorithms in literature and they can be classified in main three categories, namely; filtering/estimation based noise reduction, beam forming and active noise cancellation (ANC) techniques.
The development for speech recognition system has been for a while. The recognition platform can be divided into three types. Dynamic Time Warping (DTW)[1], the earliest platform, uses the variation in frame's time for adjustment and further recognition. Later, Artificial Neural Network (ANN) replaced DTW. Finally, Hidden Markov Model was developed to adopt statistics for improved recognition performance.
Besides the recognition platform, the process of speech recognition also includes: recording of voice signal, point detect, pre-emphasis, speech feature capture, etc. The final step is to transfer the input sampling feature to recognition platform for matching.
In recent years, study on Genetic Algorithm can be found in many research papers [2], [3], [4]. They demonstrated different characteristics in Genetic Algorithm than others. For example, parallel search based on random multi-points, instead of a single point, was adopted to avoid being limited to local optimum. In the operation of Genetic Algorithm, it only needs to establish the objective function without auxiliary operations, such as differential operation. Therefore, it can be used for the objective functions for all types of problems.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
365
1.2 Genetic Algorithms 1.2.1 Introduction
Darwin’s principle “Survival of the fittest” captured can be used as a starting point in introducing evolutionary computation. Biological species have solved the problems of chaos, chance, nonlinear interactivities and temporality. These problems proved to be in equivalence with the classic methods of optimization. The evolutionary concept can be applied to problems where heuristic solutions are not present or which leads to unsatisfactory results. As a result, evolutionary algorithms are of recent interest, particularly for practical problems solving.
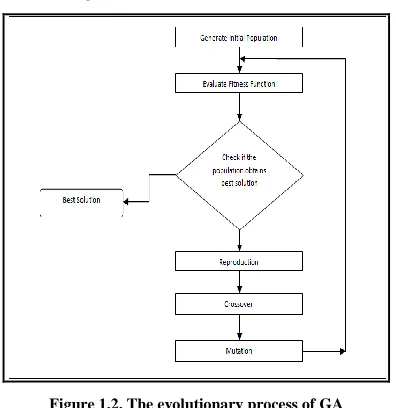
In an evolutionary algorithm, a representation scheme is chosen by the researcher to define the set of solutions that form the search space for the algorithm. A number of individual solutions are created to form an initial population. The following steps are then repeated iteratively until a solution has been found which satisfies a pre-defined termination criterion. Each individual is evaluated using a fitness function that is specific to the problem being solved. Based upon their fitness values, a number of individuals are chosen to be parents. New individuals, or offspring, are produced from those parents using reproduction operators. The fitness values of those offspring are determined. Finally, survivors are selected from the old population and the offspring to form the new population of the next generation. The mechanisms determining which and how many parents to select, how many offspring to create, and which individuals will survive into the next generation together represent a
selection method. Many different selection methods have been proposed in the literature, and they vary in complexity. Typically, though, most selection methods ensure that the population of each generation is the same size.
From the optimization point of view, the main advantage of evolutionary computation techniques is that they do not have much mathematical requirements about the optimization problems. All they need is an evaluation of the objective function. As a result, they are applied to non-linear problems, defined on discrete, continuous or mixed search spaces, constrained or unconstrained.
Evolutionary algorithms are thus made efficient because they are flexible, and relatively easy to hybridize with domain-dependent heuristics.
1.3 Speech Recognition using Genetic Algorithms
An important pre-processing step in Automatic Speech Recognition systems is to detect the presence of noise. It has been shown that accurate speech endpoint detection improves the isolated word recognition accuracy. Also, proper location of regions of speech reduces the amount of processing.
This aspect is also important for mobile telephony. Thus, for developing speech recognition device capable of working in car an appropriate endpoint detection algorithm is needed.
The endpoint detection problem is nontrivial for non stationary backgrounds where artifacts (i.e., non speech events) may be introduced by the speaker, the recording environment, and the transmission system. Ordinarily, the rate of zero crossing and short time energy is used for endpoint detection. However, this is not a trivial process and many different algorithms have been developed.
1.3.1. Speech pre-processing
The speech signal needs be pre-processed prior to entering the recognition platform. The speech pre-processing includes point detection, hamming windows, speech feature, etc.
1. Fixed-size frame and Dynamic-size frame 2. Point Detection
3. Hamming Window 4. Feature capture
1.3.2 Speech recognition platform
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
366
[image:4.612.70.268.146.350.2]1.3.3 Genetic algorithm Process
Figure 1.2. The evolutionary process of GA
II. METHODOLOGY
The process of speech recognition in noisy condition is accomplished in two phases:
1. Feature extraction
[image:4.612.333.555.279.415.2]2. Speech recognition using features extracted Figure 2.1 depicts the methodology of the proposed work. In the first phase, the features from the underlying speakers’ database are extracted and stored in a feature database. The database for features is now accessed by the speech recognition block to recognize the user for a new speech input, using Genetic Algorithm as an evolutionary computation tool for optimizing the search in the database. The result in the form of matched user ID is shown as an output of the work from the database.
Fig. 2.1 Proposed methodology
2.1 Feature Extraction
The features extracted out of the users’ speech must be robust to noise and insensitive to the changes in the characteristics of the microphone and environment. Feature vector based on Fourier-Bessel coefficients will characterizes both speech and speaker [6]. However the perceptual and cepstral characteristics of Bessel coefficients have not been explored yet.
FBCC based feature extraction indicates an improved accuracy and efficiency in comparison to MFCC features extracted [7]. The block diagram of estimating or extracting the MFCC and FBCC features is shown in Fig. 2.2.
Figure 2.2 Block diagram of extraction of speech features.
The FBCC feature extraction technique is applied in the proposed work to extract the features of users’ speech. The zerothorder Fourier-Bessel series expansion of a signal considered over some arbitrary interval is expressed as:
(2.1)
Where , and is the time frame of
the analysis. The coefficients in (2.1) can be calculated as:
(2.2)
[image:4.612.68.270.541.671.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
367
2.2 Speech recognition using Genetic Algorithm
As genetic algorithm is well known for handling noisy functions well hence, the methodology adopted here uses genetic algorithm for recognizing the speech features and matching the same from the available database generated from the FBCC feature extraction technique.
The speech features are recognized using genetic algorithm following a systematic technique which includes iterations consisting of a process looping around below mentioned steps:
1. Selection 2. Reproduction 3. Evaluation 4. Replacement
2.3 The basic genetic algorithm is as follows:
• [start] Genetic random population of n chromosomes (suitable solutions for the problem)
• [Fitness] Evaluate the fitness f(x) of each chromosome x in the population
• [New population] Create a new population by repeating following steps until the New population is complete
o[Selection] select two parent chromosomes from a population according to their fitness ( the better fitness, the bigger chance to get selected). o[crossover] With a crossover probability, cross over the parents to form new offspring (children). If no crossover was performed, offspring is the exact copy of parents.
o[Mutation] With a mutation probability, mutate new offspring at each locus (position in chromosome)
o[Accepting] Place new offspring in the new population.
• [Replace] Use new generated population for a further sum of the algorithm.
• [Test] If the end condition is satisfied, stop, and return the best solution in current population.
• [Loop] Go to step2 for fitness evaluation.
III. SIMULATION AND RESULTS
Simulation was taken out in Matlab and in order to simulate the analytics discussed previously, the database of 40 speakers is taken. This database contains different utterances of 40 different speakers, both male and female speakers, and each speaker has uttered 8 different sentences.
The speech signals are pre-processed before working on them. The signals are down converted to a sampling frequency of 16 kHz, and the length of the signals is constrained to at the most 4 seconds. For making a robust speech recognizer for different users, and for efficient working of the genetic algorithm, a database is required which should contain the extracted features of the user pertaining to different utterances. The extracted feature database of the utterances is made using FBCC, as discussed in the previous chapter. The features extracted are accessed by the genetic algorithm to search out the best match. The utterance is added with different types of noise, the features of the signal with added noise are extracted and the genetic algorithm finds optimally the best match for the features extracted with respect to the feature database, and displays the result for best match
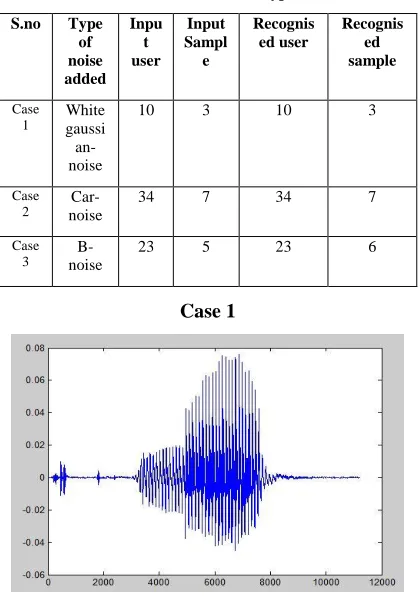
The simulations results for different types of noises are as below in table 3.1
Table 3.1.
simulation results for different types of noises S.no Type of noise added Inpu t user Input Sampl e Recognis ed user Recognis ed sample Case 1 White gaussi an-noise
10 3 10 3
Case 2
Car-noise
34 7 34 7
Case
3 noise B- 23 5 23 6
Case 1
[image:5.612.340.550.366.666.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
368
Figure 3.1.2. White noise added to the signal.
Case 2
[image:6.612.74.265.120.598.2]Figure 3.2.1. Speech Signal
Figure 3.2.2 Car noise signal added.
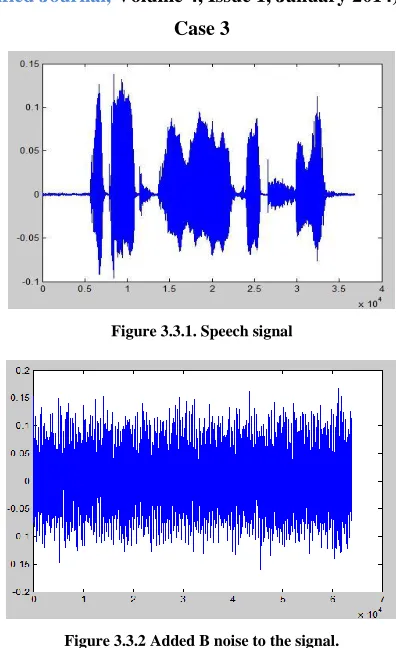
[image:6.612.343.541.127.451.2]Case 3
Figure 3.3.1. Speech signal
Figure 3.3.2 Added B noise to the signal.
The simulation shown accurate results for low intensity noise like white Gaussian noise and car noise, whereas for high intensity noise like B-noise and impulse noise simulation results were quite comparable.
IV. CONCLUSION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 1, January 2014)
369
It is found that recognition accuracy for feature extraction with FBCC features in comparison with MFCC is better. In this thesis work combination of FBCC and Genetic algorithm has been implemented and better results are achieved. This algorithm has been tested on samples of various users with and without adding noise and a high degree of accuracy is achieved during recognition
V. FUTURE SCOPE
In fact the proposed method gives better results than the algorithms proposed earlier but there is always a window of improvement. Better results may be achieved by putting genetic algorithm with a combination of neural or fuzzy logics. Better feature extraction techniques can be implemented to achieve higher degree of accuracy in less computational time.
REFERENCES
[1 ] Sakoe, H. and Chiba, S., " Dynamic Programming Optimization for Spoken Word Recognition", IEEE Transactions on Signal Processing, Vol. 26, pp 43- 49. (1978).
[2 ] Chu, S. H. , "Combination of GA and SDM to Improve ANN Training Efficiency", Shu-Te University, MS Thesis, Taiwan. (2003).
[3 ] Chen, S. C., "Use of GA in CSD Coded Finite Impulse Digital Filter (FIR)", Shu-Te University, MS Thesis, Taiwan, (2003)
[4 ] Chu, W. C. ,"Speech Coding Algorithms'', John Wiley & Sons, 978-0- 471-37312-4, USA. (2003).
[5 ] Yeh, Y. C. , "Implementation and Application of Artificial Neural Network", Ru Lin Publication, 957499628X, Taiwan ,(1993) [6 ] K. Gopalan, T. R. Anderson and E. J. Cupples, "A comparison of
speaker identification result using features based on cepstrum and Fourier-Bessel expansion," IEEE Trans. Acoust. Speech Signal Processing, vol.7, no. 3, pp. 289-294, May., 1999