International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 11, November 2013)
142
Effective Implementations of
GF (p)
Elliptic Curve
Cryptography Computations Using Parallelism
N. Sivasankari
1, M. Kannan
21Assistant Professor, Kalasalingam University 2Special Officer, Annamalai University
Abstract
--
This paper aims at analyzing the impact of parallelism available in two common Elliptic Curve Cryptography (ECC) projective forms on speed and cost factors.The time consuming multiplication is implemented with m-ary algorithm. Using scalable multipliers. for various key sizes. To implement large bit-length multiplications we used a novel partitioning and pipeline foldingscheme to fit at least 256-bit modular multiplications on a single Xilinx FPGA. Comparisons to several other schemes are presented.Keywords-- ECC, projective forms, modulo multipliers.
I. INTRODUCTION
ECC was first proposed in 1985 by N. Koblitz and V. Miller . Since then, a considerable amount of research has been performed on secure and efficient ECC implementations. One of the most important advantages of ECC over conventional public-key schemes is that much smaller key sizes are required to achieve the same security level . As an example 160 bits ECC is equivalent to 1024 bits RSA . Smaller key sizes make ECC suitable for embedded systems and wireless applications, which require combining performance with low-power hardware and smaller security certificates. Several ECC implementations have been reported in the literature at the software level and hardware level as well []. The performance of an ECC cryptosystem is mostly determined by an efficient implementation of its arithmetic over a Galois Field GF( p ) or GF( 2m) . ECC arithmetic is applied on points located on selected elliptic curves and includes point-addition, point-doubling and point-multiplication. When elliptic curve (EC) points are expressed in affine coordinates, ECC arithmetic includes multiplications and divisions (inversions), which are highly time-consuming.
In order to eliminate these divisions (inversions), EC points are expressed in projective coordinates, where scalar multiplication becomes the operation to optimize in order to reach the targeted cost/performance constraints. The scalable multipliers are used to replicate the design for varying-size security keys. The remainder of this paper is organized as follows: Section 2 presents a basic background about ECC. Section 3 presents ECC point-multiplication algorithms and related sequential and parallel implementation of projective forms.\ Section 4 presents simulation results and section 5 concludes the paper.
II. ELLIPTIC CURVES OVER GF (P)
2.1 General Background on ECC Arithmetic
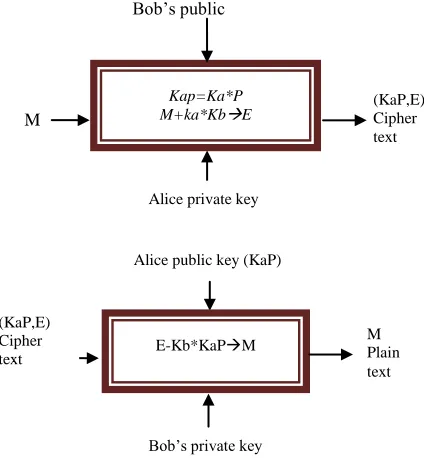
The encryption and decryption setup process in elliptic curve cryptosystems is shown in Figure 2. We will assume Alice is going to send Bob an encrypted plain-text message, M, using an agreed upon elliptic curve E
defined over a finite field GF(q) and a point Q ∈ E(GF(q)).Alice initially generates a random scalar number ka and computes a public key KaP = kaP using the point scalar multiplication.She keeps her private key
ka secret and shares KaP with Bob as a public key. Meanwhile, Bob generates a random scalar number kb
and computes Kb = kbP. He keeps his private key kb
secret and shares KbP with Alice as a public. A relatively
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 11, November 2013)
[image:2.612.93.233.140.365.2]143
Fig 1:Elliptic curve scalar multiplication hierarchyFig 2: Encryption and Decryption in ECC
2.2 ECC Arithmetic Using Projective Coordinates
Group operations in affine coordinates involve finite field inversion, which is a very costly operation, particularly over prime fields.
Table 1.
Cost of ECC operations in affine coordinates
Operations Point addition Point doubling Additions (A) 6 4 Multiplications (M) 3 4 Inversions (I) 1 1 Total 6A + 3M+1I 4A + 4M+1I
These inversions can be avoided by using projective coordinate systems. The cost of converting from affine to projective coordinates is trivial. We will assume that the cost of a squaring operation is equivalent to a multiplication.
Table 2.
Point-addition Using Projective coordinates
Input : P0(x0,y0,Z0) ,P1 (x1,y1,Z1) Output: P2 :P0+P1
Operations Cost
U0x0z12, S0y0z13 5 Multiplications
U1x0z12 2 Multiplications
S1y1z03 3 Multiplications
W U0- U1 1 Addition
R S0- S1 1 Addition
T U0+ U1 1 Addition
M S0-+S1 1 Addition
Z2Z1Z0W 2 Multiplications
X2R-TW2 1 Multiplication+1 Addition
V TW2 -2X
2 2 Multiplication+1 Addition
2Y2 VR-YW3 2 Multiplication+1 Addition
Total 16 Multiplication + 7 Addition Point Scalar Multiplication
Qk*P
ECC Point operations ECC Point addition QP+Q ECC Point doublingQ P+P
ECC architecture Data path scheduling
Modular multiplier FPGA partitioning & folding
Projective coordinates
M
Alice private key Bob’s public key(KbP)
(KaP,E) Cipher text
Alice public key (KaP) Kap=Ka*P
M+ka*KbE (KaP,E) Cipher
text
E-Kb*KaPM
Bob’s private key
[image:2.612.320.552.403.572.2] [image:2.612.52.264.406.635.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 11, November 2013)
[image:3.612.93.228.156.316.2]144
Fig: 3 Scheduled dataflow graph of point adding operation usingmultipliers and four add/sub units.
[image:3.612.343.531.190.311.2]Fig: 4 Scheduled dataflow graph of point doubling operation using multipliers and two add/sub units.
Table 3
Point-doubling Using Projective coordinates:
Input : P1 (x1,y1,Z1),a
Output: P2 :P1+P1
Operations Cost M3x12+az14 5M + 1A
Z22y1z1 2M
S4x1Y12 3M
X2M2-2S 1M + 1A
T8Y14 3M
YM(S- X2)-T 1M + 2A
Total 15 M + 4A
III. IMPLEMENTATIONS
Implementing the computations involved in projective forms using the m-ary multiplication algorithm requires the following basic units:
- A register file to store results and needed parameters.
- A set of multipliers (between 1 and 4) to implement multiplication operations.
- Adder/subs tractor. Controller
[image:3.612.97.241.376.581.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 11, November 2013)
145
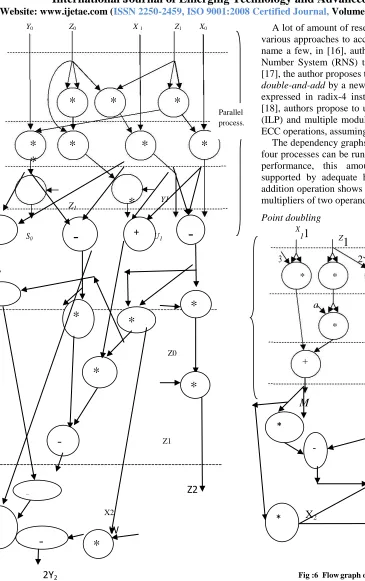
Y0
Z0 X 1 Z1 X0
*
*
*
*
*
*
*
*
Z1
*
Y1
S0
S1 U1 U0
---
Z0
Z1
---
Z2
X2
W
[image:4.612.61.426.119.700.2]
2Y
2Fig 5: Flow graph of point addition operation
A lot of amount of research is being conducted to find various approaches to accelerate ECC operations. Just to name a few, in [16], authors explore the use of Residue Number System (RNS) to speed- up multiplications. In [17], the author proposes to replace the intrinsic operation
double-and-add by a new operation called quad-and-add
expressed in radix-4 instead of the popular radix-2. In [18], authors propose to use Instruction-level parallelism (ILP) and multiple modular arithmetic logic to speed-up ECC operations, assuming the popular binary algorithm.
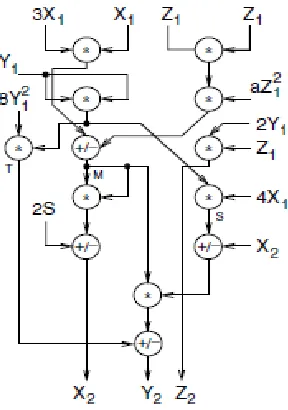
The dependency graphs presented here show that up to four processes can be run in parallel. To achieve the best performance, this amount of parallelism must be supported by adequate hardware resources. The point addition operation shows that in one level it requires four multipliers of two operands.
Point doubling X
1
1
Z1
Y1
3 2
* * * *
a
8
* * * 4 X1
+
M Z
2T S
2
T
X
2Y2
Fig :6 Flowgraph of point doubling operation
*
-
Parallel process.
*
*
*
*
-
*
*
-
-
-
+
+
*
-
*
*
-
-
*
[image:4.612.285.571.326.684.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 11, November 2013)
146
IV. SIMULATION RESULTS
In our research work, we want to exploit the parallelism available in projective forms at the operation level (fine grain parallelism) to accelerate ECC point multiplication, assuming the m-ary algorithm instead of the binary algorithm. Therefore, two levels of optimization are achieved: at the algorithmic level by using the m-ary algorithm and at the operation level by exploiting fine-grain parallelism. Fine-grain parallelism can be identified by exploring the dependency graph of the targeted operations. All proposed algorithms of the multipliers are simulated by using VHDL language and Xilinx tools V 6.1, implemented and synthesized on the Spartan 3s2000fg900-5 FPGA. Depending on the constraints imposed by the design specifications, the performance of the proposed architectures are measured by means of propagation Delay (ns), Area occupation (Slices) and Power consumption (mW). To measure the quality of a design, several metrics can be used. In our work, we use an AT metric where (A) is the area and (T) the time ( N represents no of multipliers)
AT 2( NMult ) = A( NMult ) ×T 2( NMult )
[image:5.612.375.503.158.296.2]=( NMult× AMult ) ×T 2( NMult )
Table 4
Area and Delay performance of affine and projective coordinate multipliers
Bit length
Affine coordinates Projective coordinates
Area(no of slices)
Delay(ns) Area(no of slices)
Delay(ns)
32 182 278 289 521
64 303 600 453 856
128 544 1323 854 1625
256 1045 2855 1229 2945
When the no of bits increased projective coordinates occupies comparably less area and less delay.
Area (A): it will be defined as the total area occupied by the number of multipliers allocated to compute ECC operations. The minimum number of multiplier is 1 and the maximum number of multipliers is 4 . The cost of an adder will be neglected compared to the cost of one multiplier.
- Time (T): it will be defined as the number of multiplication cycles needed to compute ECC operations. Addition cycles will be neglected since addition requires less time compared to multiplication.
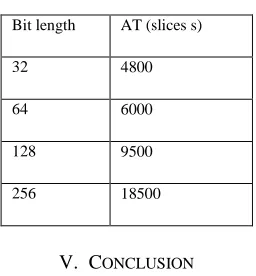
Table 5
Performance with AT metric
Bit length AT (slices s)
32 4800
64 6000
128 9500
256 18500
V. CONCLUSION
In this paper, we analyzed the impact of using the m -ary algorithm as an alternative to the bin-ary algorithm to implement ECC multiplication operations in projective form. This analysis took into account several aspects: time, AT 2 score, and efficiency. It clearly showed the superiority of the m-ary algorithm over the binary algorithm and speed-up factors can be doubled . This performance can be enhanced by using the parallelism available in the computations related to projective form. Experiments showed that in some cases increasing the number of multipliers did not result in a substantial performance gain, as a direct consequence of the data dependencies available in various computations. This result is very important for low-power applications, where design constraints are usually severe. Results also showed that depending on the design parameter being analyzed one projective form may have the advantage over the other one. This suggests a careful choice of the projective form depending on design constraints.
REFERENCES
[1] Dr. Hakim khali, Prof. Ahcene Farah”Cost effective implementations of GF(P) Elliptic curve cryptography computations” IJCSNS International Journal of Computer Science and Network Security, VOL.7 No.8, August 2007
[2] I. Blake, G. Seroussi, and N. Smart, Elliptic Curves in Cryptography, Cambridge University Press: New York, 1999. [3] R. L. Rivest, A. Shamir, and L. Adleman, "A Method for
Obtaining Digital Signatures and Public-Key Cryptosystems", Communications of the ACM, 21(2), 1978, pp. 129-126. [4] S. Okada, N. Torii, K. Itoh, and M. Takenaka, "Implementation of
Elliptic Curve Cryptographic Coprocessor over GF(2m) on an
FPGA", Workshop on Cryptographic Hardware and Embedded Systems, CHES 2000, pp. 25-40.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 11, November 2013)
147
[6] G. A. Orton, M. P. Roy, P. A. Scott, L. E. Peppard, S. E. Tavares,"VLSI implementation of public-key encryption Algorithms", Advances in Cryptology -- CRYPTO '86, Vol. 263 of Lecture Notes in Computer Science, Springer-Verlag, pp. 277-301, [7] A. F. Tenca, and C. K. Koc, "A Scalable Architecture for Modular
Multiplication Based on Montgomery's Algorithm", IEEE Transactions on Computers, 52(9), 2003, pp. 1215-1221. [8] A. Gutub, A. F. Tenca, and C. K. Koc, "Scalable VLSI
architecture for GF(p) Montgomery Modular Inverse Computation", IEEE Computer Society Annual Symposium On VLSI, 2002, pp. 53-58.
[9] Gutub, A. F. Tenca, and C. K. Koc, "Scalable and Unified Hardware to Compute Montgomery Inverse in GF(p) and GF(2n)",
Cryptographic Hardware and Embedded Systems - CHES 2002, 2002, pp. 485-500.
[10] Royo, Moran, Lopez, "Design and implementation of a Coprocessor for cryptography applications", European Design and Test Conference Proceedings, 1997, pp. 213–217.
[11] S. B. Ors, L. Batina, B. Preneel, and J. Vandewalle, "Hardware Implementation of an Elliptic Curve Processor over GF(p)", Proceedings of the IEEE International Conference on Application-Specific Systems, Architectures, and Processors (ASAP), 2003, pp. 433-443.
[12] D. Hankerson, J. L. Hernandez, and A. Menezes, "Software Implementation of Elliptic Curve Cryptography over Binary Fields", Workshop on Cryptographic Hardware and Embedded Systems, CHES 2000, LCS, Springer-Verlag, W. Stallings, Cryptography and Network Security: Principles and Practice, 3rd
Ed., Prentice Hall, NJ, 2003.
[13] P. K. Mishra, “Pipelined Computations of Scalar Multiplication in Elliptic Curve Cryptosystems”, IEEE Trans. Comp. September 2006, pp. 1000-1010.
[14] A. A. Gutub, “Fast 160-Bits GF(P) Elliptic Curve Crypto Hardware of High-Radix Scalable Multipliers”, International Arab Journal, Vol. 3, No. 4, 2006, pp. 342-249.
[15] D. M. Schinianakis, A.P. Kakarountas, and T. Stouraitis, "A New Approach to Elliptic Curve Cryptography: an RNS Architecture", Proceedings of IEEE MELECON, 2006, pp. 1241-1245. [16] S. Moon, " Elliptic Curve Scalar Point Multiplication Algorithm
Using Radix-4 Booth's Algorithm", ECTI Transactions on Computers and Information Theory, 1(1), 2005, pp. 3-8. [17] K. Sakiyama, E. De Mulder, B. Preneel, and I. Verbauwhede, "A
Parallel Processing Hardware Architecture For Elliptic Curve Cryptosystems", Proceedings of ICASSP, Vol. 3, 2006, pp. 904-907.
[18] A. F. Tenca, G. Todorov, and C. K. Koc, "High-Radix Design of a Scalable Modular Multiplier", Proceedings of Workshop on Cryptographic Hardware and Embedded Systems, 2001, pp. 185-201.