Master of Science in Information Security and Cryptography
Federated Machine Learning Nancy Adobea Addo
[email protected] Supervisor: Prof Ion Petre
Abstract
In recent times , machine gaining knowledge has transformed areas such as processer
visualisation, morphological and speech identification and processing. The implementation of machine learning is frim built on data and gathering the data in confidentiality disturbing circumstances. The studing of amalgamated systems and methods is a innovative area of modern technolgical field that facilitate the training within models without gathering the information. As an alternative of transferring the information, clients co-operate together to train a model be only delivering weights updates to the server. While this concerning privacy is better and more adaptable in some circumstances very expensive.
This thesis generally introduces some of the fundamental theories, structural design and procedures of federated machine learning and its prospective in numerous applications. Some optimisation methods and some privacy ensuring systems like differential privacy also
Table of Contents
Introduction: Federated Machine learning ... 1
Motivation ... 1
Background ... 1
The composition of the Dissertation ... 2
Chapter 1: Federated Systems ... 3
1.1 Federated Learning System ... 3
1.2 Traditional federated system ... 3
1.3 Dimension of Federation ... 5
1.4 Rationale of a federation ... 5
1.5 Correlation within federated Systems ... 6
1.6 Characteristics of a federated system ... 6
1.6.1 Heterogeneity ... 6 1.6.2 Privacy Prerequisites ... 6 1.6.3 Data Differences ... 7 1.6.4 Assignments Differences ... 7 1.6.5 Independence ... 8 1.6.6 Association Independence ... 8 1.6.7 Communication Independence ... 8
Chapter 2. Classification of federated Systems ... 9
2.1 Machine Learning Models ... 10
2.2Confidentiality ’s of Federated learning... 11
Background ... 11
2.2.1 Model aggregation ... 11
2.2.2 Cryptographic Procedure ... 12
2.2.3Differential Privacy ... 13
2.2.5 Homomorphic Encryption ... 18
2.2.6 Gaussian mechanism ... 18
2.2.7 Laplacian mechanism ... 18
2.3. Data distribution in Federated learning ... 19
2.3.1 Horizontal federated learning ... 20
2.3.2 Vertical Federated Learning ... 20
2.3.3 Federated Transfer Learning (FTL) ... 22
2.4: Exchange Architecture of a federated system ... 22
2.4.1 Operation of the federated learning system ... 23
Chapter 3 Established studies ... 27
3.1 Approach ... 27
3.2 Discrete Studies ... 27
3.3 Researches on Algorithm Design ... 28
3.4 Researches on Benchmarking ... 29
3.5 Researches on Application ... 29
3.6 Efficiency Enhancement ... 30
Chapter4: Applicability of Federated Learning ... 31
4.1 Industry Data Association and Federated learning ... 31
4.2 Quick Medical Diagnosis ... 31
4.3 Target Marketing and Advisement ... 32
Chapter 5: On-Device Federated Machine Learning. ... 33
Conclusions ... 34
1
Introduction: Federated Machine learning
MotivationData privacy in recent years is a significant issue in this era of machine learning and artificial intelligence (AI). In finding ways of handling data without compromising it is of enormous importance, that the motivation of this thesis on federated learning.
Federated learning is a framework in artificial intelligence and machine learning where a model is developed and distributed over mobile devices. The framework is thereby providing highly personalised models with the privacy of the end-user a priority. Federated learning enables the end device to collaboratively learn a shared model using data on the end device and maintain the data on the device.
However, federated learning approach does not only handle privacy concerns. Nevertheless, it also improves functionality and provides with efficient computational models to mine this large set of data.
Background
In a machine learning model, the traditional machine learning model is based on the approach of centralised data training on a single machine. The significant issues with the centralised data training approach are its privacy-intrusive for the end device users. However, the federated learning approach is using the distributed data training approach. Thereby making end devices located at serval and different physical locations to learn a machine learning model together.
In-addition federated learning enables edge devices to implement high-level aspects of machine learning without centralising information and with confidentiality by default. Federated learning comes to existence at the coming together of on-device AI, blockchain, and edge computing and internet of things. Furthermore, the process of federation aids in the transportation of the simulations to where the information is needed or the customer's
machine for the facilitation of federation and interpretation. The Network invisibilities and costs of the original component of the dummy on the device is exclude and earned because there is a continuous interaction within the server and data. The training has been local; model response is very personalised for the end-user. For the process of federated learning to be achieved the end-user device’s storage and computing power is tapped into to help in minimaxing the storage capacity the process of federation would have normally needed.
2
Today's AI still faces two significant throws down the gauntlet. Firstly, is that generally within businesses, information occurs in the form of segregated isles. The additional is the fortification of information privacy and protection. A review of proposing a possible solution to these questions: firstly, look at protected federated learning. Outside the associated
learning, the structure initially recommended by Google in 2016, which was the introduction of a large, protected federated learning structure. The proposed protected federated learning also further comprises horizontal associated learning, vertical associated learning and federated transfer learning. Review of available classifications, structural design and presentations for the federated learning structure, and an across-the-board assessment of current effects on this field of study are still being carried out by researchers. Besides, some researchers have proposed the building of information networks within organisations founded on federated mechanisms as a successful clarification to consent information shared without compromising user confidentiality.
The composition of the Dissertation
The primary purpose of the dissertation is to review already existing literature and a general overview of federated learning and applicability in daily lives.
The thesis outlook is as follows: federated learning is explained and the fundamental features and reviewed in chapter 1. In chapter 2, the characteristics of federated systems and their properties are reviewed, and then chapter 3 covers some established studies in the field. The applicability of federated learning in our day-to-day lives and its applicability in on-device mobile learning is reviewed in chapter 4 and five, respectively.
3
Chapter 1: Federated Systems
In this chapter, I am evaluating the background of federated systems, general traditional federated systems how to represent the combined learning systems and some general features of the federated learning system
1.1 Federated Learning System
Machine learning, particularly deep learning, has drawn many considerations in recent years. The combination of machine learning and federation is surfacing like new and exciting research focus.
In terms of federated learning, the fundamental purpose is to carry out a give-and-take machine learning procedure among diverse parties under the restriction of privacy. A recognised narrative of federated learning system stated as: Give that there is M number of different organisations, and each organisation represented by Xi, such that i is associated with
[1, N]. Let Di represent the data of Xi. However, for a non-federated setting, each organisation
Xi uses its own locally generated data Di to facilitate the progression of the statistical model
Ni. The implementation within model Ni represented as Pi.
Furthermore, in all the federated setting, the organisation together trains a model Nf which
each of the organisation Xi secures its data accordance with specific privacy restrictions [1].
The performance of Nf represented as Pf. then to establish a sound come together learning
system, there should exist i belongs to [1, N]. Such that the performance achieved from systems which collaborate is higher than the non-collaborating system.
Although, from the definition of federated learning system (FLS) requires that there exists an organisation that can benefit from the learning system. Even though there may be some organisation which might not benefit directly, however, their benefits may be in the form of rewards per agreement with the other organisation or participate in the federated system in a way which is beneficial to them.
1.2 Traditional federated system
The concept of federation is part of our everyday life. As an example, my home country Nigeria is a federation of thirty-six (36) self-governing states. The main attribute of the alliance is collaboration. Federation does not only exist in our society but correspondingly in the area of computing, which is recent years have been an eye-catching sphere of study [1].
4
There have been numerous studies in the 1990s about federated database structures [2]. Federated database structures are assemblies of self-governing databases collaborating for reciprocated benefits. According to previous research [2], a federated database made up of three main features, namely diversity, autonomy and distribution.
A database system (DBS) that contributes to a federated database system is autonomous, meaning it is self- directed and has independent control. Ensuring that parties involve can manage their data without a collaborating database system. Furthermore, the database system working together allows the application and use of different devices, operating system and different information exchange systems among parties involved. The management of private party’s data is possible because the federated database system (FDBS) can operate within various hardware or software backgrounds.
Finally, the presence of multiple database systems before the federated database system can be established; the data sharing may differ in the different database systems. Federated database system established and beneficial from data sharing when there is the system well and appropriately designed.
In contemporary times, with the progression and improvement of cloud computing, many types of research have been carried out into the aspect of federated cloud computing [3]. Meanwhile, the amalgamated cloud is the enhancement with the administration of various peripheral and intramural available data centres facilities. The idea of on-demand
amalgamation ensure that costs is low because part of the project is subcontracting to
facilitate charge conservative constituencies. Availability of more source of having materials needed and the transportation of the resource fundamental descriptions of federated cloud [3] — the resource assigned from one contributor to another. The migration facilitates the transfer of resources.
Secondly, termination permits synchronised handling of comparable service features in different domains. For illustration, the information knows how to disintegrate and
administered at the different contributors succeeding the unchanged computation rationality. Overall, the planning of diverse sources is a critical aspect in the layout of a collaborating cloud system.
5 1.3 Dimension of Federation
Federation comes in two dimensions commonly refers to as the private and the public federated learning systems. Their classification mainly based on the numbers of organisations and the amount of information stored with each organisation.
In the federated public learning, the system consists of many organisations, and each
organisation has small computation power of their small information. Google keyboard [4] is an excellent example of the implementation of public federated learning system because Google tries enhancing the query suggestion of the google keyboard based on federated learning Also, with the increasing rate of mobile phones and other IoT devices containing the information of its user, Ensuring public federation is required daily, but there is a significant constraint of energy consumption. Hence the phones and other devices cannot carry out complex assignments of the information training. Furthermore, under public learning, the co-ordination should be formidable enough to manage an enormous number of organisations and handle the likelihood of an unstable connection between the .1devices and the server.
Contrary, federated private learning involves a small group of organisations, and each of the organisation has a comparatively an extensive dataset with the computational power to support. A practical case is a shopping website like Amazon, eBay, Alibaba suggesting items to its shoppers. This suggestion is possible due to the training of data gathered from millions of data centre globally.
The data centres globally have vast volumes of data as well as the computational capacity; however, the issues of distribution is a significant concern with the restriction of privacy models.
1.4 Rationale of a federation
Practically, the implementation of associated learning, individual organisations require rationale and identify the benefits of implementing a federated system. Federated learning within an organisation is usually pursued by lay down regulations.
However, due to the memorandum of understanding among organisation in the learning, pressure cannot be on any organisation to share their information or data due to regulations. The Google companies introduction of G keyboard [4] for instance is a clear indication that an institution implementing federated learning cannot prevent users who refuse to share data from their apps or service. However, the is an advantage of a significant word prediction accuracy for users who willing agrees to data sharing. For such benefits can serve as a
6
rationale for users to share their information for improving the performance of the general model.
1.5 Correlation within federated Systems
There is some noticed difference among merged learning system and the traditional federated systems. Although the idea of federation applies in both instances. The standard and
fundamental concept is the collaboration of various individual organisations. The viewpoint of considering diversity and autonomy among organisations still holds in federated learning systems. Additionally, some influences in the propose of the distributed system are
nonetheless critical for federated learning systems. For instance, the method of information sharing among organisations can impact the competence of the system [1] from other viewpoints; these federated systems have a difference. Merged databases emphasis on the administration of the distributed information and federated cloud focus on the scheduling of resources. Federated learning system induces new encounters such as the design of the algorithms of the shared learned model and the information security as per the confidentiality standards. Also, federated learning is more concerned with security computation among the individual organisation.
1.6 Characteristics of a federated system
Under this section, I am going to take a looking at the two main characteristics of previous merged systems since current existing federated learning systems focus is on the user’s privacy and machine learning models. Hence, heterogeneity and Independence rarely discussed.
1.6.1 Heterogeneity
Heterogeneity exists base on technological difference like the difference in hardware, operating systems and communication system [2]. Consideration of heterogeneities among organisations is going to be in three aspects: privacy prerequisites, data (information) and assignment [1]. In-addition will consider heterogeneity among database management system which can further be divided into two areas thus difference in the database management system and the semantics of the data
1.6.2 Privacy Prerequisites
Organisations usually have different guidelines and directive of data and information sharing. For instance, organisations in the European Union have to act per the General Data Protection Regulation (GDPR) [5]. Meanwhile, countries like China have their own set of guidelines under their newly introduce directive, namely the Personal Information Security Specification
7
(PISS). The privacy prerequisites are an essential aspect in federated learning systems and their design. However, an organisation in the same geographical location can still have a difference in the privacy guidelines. Generally, organisations can achieve more from
federated learning if the privacy guidelines are flexible. However, various research suggests that the organisation in federated learning have the same level of privacy [6], [7]. It is very thought-provoking to plan a federated learning system which can maximise the utilisation of data of each organisation while not violating their confidentiality prerequisites. In the case where organisations have different privacy prerequisites are more complicated and
meaningful, for instance, considering organisations from Europe, China and the Americans. 1.6.3 Data Differences
Organisations usually have different data and information distributions policies. The modification in information distributions may be an essential dynamic in the design of federated learning systems. The organisation can theoretically advance a lot from federated learning if they have abundant and partly demonstrative allocations towards an exclusive assignment. Furthermore, if an organisation has fully demonstrative data for assignments D and another organisation has fully demonstrative information for assignments E. Both organisations can agree to conduct joined learning for both assignments D and E to improve the performance for assignment E and assignments D, Correspondingly.
Additionally, to the information distribution and sharing, the data dimensions may also vary in different organisation. Federated learning facilitates cooperation between organisation operating, functioning in different sectors and structural scale. Additionally, with the
independence, the organisation which invest and provides next level information profit extra from federated learning.
1.6.4 Assignments Differences
The responsibilities of different organisation may also vary. For instance, a financial institution may want to know a client’s loan repayment capability. Nevertheless, and
insurance institution would like to find out whether a person will be interested and purchase their products. The financial and insurance institution can implement federated learning, even though the organisation might want to execute different jobs. Several automaton studying models may learn within the federated learning progression. Procedures such as multi-task learning can be embraced in federated learning [8]
8 1.6.5 Independence
The organisations are usually independent and under sovereignty control. These organisations are enthusiastic about sharing data among the other merely if they maintain command.
Hence, it is very critical to concentrate on independence possessions when designing a federated learning system.
1.6.6 Association Independence
An organisation can decide whether to affiliate or disengage itself from combined learning and can contribute to one or more learning systems. Preferably, a federated learning system should be robust enough to endure the admission and withdrawal of any organisation. Thus the federated learning system should not be exclusively reliant on any single organisation [1]. However, this fundamental objective is challenging to accomplish; in practice, the
organisation can agree to permit the admission and withdrawal to ensure that the merged learning system functions appropriately.
1.6.7 Communication Independence
An organisation should have the capability to determine how many information and data to share and reveal with the other organisation. The organisation can select the size of the data and information to participate in federated learning. However, the organisation turns to gain more from federated learning by sharing more information, although there is a high chance of compromising the client ’s privacy.
9
Chapter 2. Classification of federated Systems
Although analysis of many application situations in the assembling merged, learning systems can categorise federated learning schemes into six viewpoints. Information distribution, exchange architecture, privacy procedure, machine learning model, the balance of federation and enthusiasm of federation. However, these viewpoints used to point in the right direction the outline of federated learning systems. Figure 1 demonstrations the outline of the
classification of federated learning systems.
Furthermore, in the description of these viewpoints, let us see a natural example. Schools in distinct constituencies want to supervise federated learning to increase the operation of forecast assignment on high school students. Then, the six viewpoints focus on in the building such a collaboration learning system. Firstly, look at how the student's data are allocated between the schools. While the school has distinctive students, they may also have distinctive knowledge for a collective student. Thus, they must exploit both the
non-overlapping occurrences and characteristics in federated learning.
Figure 1: Classification of federated learning systems (Personal drawing)
Secondly, it should fathom which machine learning model implemented for such an assignment. For instance, the implementation of a boosting decision tree which shows excellent performance on many classification problems. Besides, the decision on what technique to implement for privacy security chosen. Subsequently, the student’s records cannot reveal publicly; the method of differential privacy is an option to accomplish the privacy agreement. The method used in communication exchange is also critical. The essential for a centralised machine to take over the management and the apprises of the models. However, the schools and the power needed in calculating the outcome in each
Federated learning Systems Data partition Horizontal Vertical Federated transfer Machine learning model Statistical method Decision trees Neutral network Privacy mechanism Diffeerential Privacy Crytographic methods Communicati on architecture Centralized Decentralized Motivation Federation Incentive Regulation
10
school deliberate. Contrasting learning on smart gadgets, have a comparatively miniature scale and satisfactory constancy of alliance in this situation. Finally, deliberation of the reason of each organisation is focal point. A bright and uncomplicated incentive for the schools is to upsurge the precision of high school performance forecast. Nonetheless, it is essential to accomplish an exact machine learning model by federated learning.
2.1 Machine Learning Models
Machine learning models are various but in terms of federated learning, let us consider three main models frequently used and supported in combined learning. They are the decision trees model, linear model and the neural networks.
In the decision tree model, the federated learning system implemented for either a single or multiple tree. However, in terms of popularity, the gradient boosting decision trees is
favourably implemented due to the fact it accounts for excellent performance in classification and regression assignments. According to [9] and [7] suggested that gradient boosting
decision trees should be on horizontally and vertically data, respectively in federated learning systems.
Furthermore, in the linear model, there include some mathematical methods such as regression; thus, both linear and logistics [6]. These commonly used because of it easy to learn and understand compared to some methods like the neural networks, also there already existing sophisticated systems for linear and logistics regression [10], [11].
Nevertheless, in the neural network system, the primary focus is to implement a neural network, and neural networks are hot topics in machine learning. According to [12], [13], most of the current researches are on simple deep neural networks. They are hence leaving a considerable room for studies on the specialised optimisation on complex architectures like the recurrent and complex neural networks in federated learning.
By and large, machine learning models are different in the designing of the federated learning system. With one major issue in machine learning is suggesting a practical tree or neural network base for the federated learning system. Besides, due to the rate of development in the discipline of machine learning, there is an interruption between the support of the
11 2.2Confidentiality ’s of Federated learning Background
Confidentiality is several of the vital mechanisms of federated learning. The motivation to make known federated learning was mainly privacy problem in terms of how fast rate of growth in the areas of machine learning and according to book nature. Federated learning seems like a considerable upgrading in the area of privacy since the data does not leave the users devices.
For instance, neural networks are global function approximators; neural networks can become imprecise a function that acts as a look-up table to all the data [14]. Neural networks with several neurons characteristically memorise parts of the training data instead of learning several general patterns [15]. In the provision of privacy, it must consider the probability of an accusatorial player analysing the weights to figure out data about individuals. Although weights of neural networks have the standards of being incredibly hard to analyse, yet a great deal of research has gone on in this area.
A recent case related to the issues of privacy was the Netflix Prize [16], was when Netflix circulated a database that included data about users and their preferred movie choices. The database was meant to use in a competition to help improve the recommendation system of the site, although personal identification such as names, and users’ identification is removed from the database, but based on the fact that most users post movie reviews on other sites, researchers were able to deanonymise the Netflix database by using the information from the other site and Netflix [17].
There are several privacy procedures currently which deliver different confidentiality securities. The features of existing privacy procedures are synopsised in the report [18].In this unit, a brief definition of differential privacy, model aggregation, cryptographic methods and introduce the Laplacian mechanism, Gaussian mechanism, composition theorems and identify methodologies and challenges for preventing indirect leakage that is adopted in current federated learning systems.
2.2.1 Model aggregation
Model aggregation is an extensively used structure to prevent the transmission of raw information in joined learning. Notably, universal simulation trained with averaging the dummy restrictions as per the resident organisations. A standard procedure is the federated averaging [19] founded on the principal of optimising the function with the suitable smoothness features, averaging the resident-calculated models and nonetheless modernises
12
the universal model in each sequence. The combination of numerous black-box resident models to understand a universal model was shared in [20], which forecast an outcome chosen by noisy electing within all the resident models. Furthermore, an anticipation federated learning framework established by Yurochkin et al. [21] with the application of Bayesian nonparametric mechanism. In their research, they implemented the Beta-Bernoulli method, which informed the pairing procedure to the general universal model by paring the neurons in the resident model. Federated learning with multi-task learning combined by Smith et al. [8] to permit multiple organisations to learn models versus different assignment. A problem with model averaging approaches is been able to guarantee the improved
usefulness of the universal representation than the resident models. 2.2.2 Cryptographic Procedure
Under the cryptographic procedure, the fundamental knowledge is to protect the data or parameters before sharing. A procedure such as secret sharing [22] and homomorphic encryption [10] widely implemented. Insecure serval-party computation [23] warranties that all organisations cannot know anything aside the results. However, such systems are usually not cost-effective and have extensive calculation and exchange operating cost.
For this reason, many systems implement differential privacy [9] for data and information privacy fortification, where organisations have no idea of an individual participates data used in the learning or not. The addition of clatter to the information or the boundaries of the models, difference privacy, imparts statistical discretion for individual data, fortification versus the calculation incident on the models. However, all the mention approaches are sovereign of the each other, and a federated learning co-ordination can implement manifold processes to ensure the confidentiality certifications.
Nevertheless, the majority of the prevailing federated learning system implements cryptographic methods or differential concealment to complete thriving confidentiality certification. Restrictions of the methods look like a problematical. Whereas trying to
minimise the effect generated by the approaches, it can be an exceptional selection to look for different methodologies to safeguard the data privacy and accommodating confidentiality obligations.
13 2.2.3Differential Privacy
Differential privacy is a mathematical hypothesis which deals with privacy validation using stochastic framework [24] by allowing the analysis of how many specific algorithms hold in the highest regard privacy.
Differential privacy allows companies to collect information about their users without compromising the of an individual. This process brings about a concept knows as data unnamed, this anonymisation process usually happens on the servers of the companies that collect the data, and questions of trust can be an issue. Also, the question of how anonymous data is really. Companies trying to anonymise client’s data by removing some part of their data can bring about attacks known as linkage attack, and it happens when pieces of seemingly anonymous data can be combined to reveal real identities. Differential privacy, however, neutralises these types of strikes.
The same explanation of differential in randomised mechanism as [25]: Randomised mechanism M: D → R with area D and range R satisfies (ε, δ)-differential privacy if for any two adjoining inputs d, d’ ∈ D and any subset of product S ⊆ R it maintains that
Pr[𝑀(𝑑) ∈ 𝑆] ≤ 𝑒𝜀Pr[𝑀(𝑑′)𝜖 𝑆] + 𝛿
In this clarity, δ represents the probability that understandable ǫ-differential privacy
smashed. To express the above equation formally, two datasets D and𝐷′ Are considered. The datasets in question are contiguous to each other. The explanation of the contiguous to each other can differ from application to application. However, it mostly explains the fact that the two datasets are indistinguishable except for one data point, which is missing in one of the two data. A statistical interrogation M then implemented on both datasets. The interrogation, for instance, is used in the calculating of mean or the goodness of fit for a statistical model which generally has some randomness.
The figure or number calculated for the ε referred to as the standard of Differential Privacy. From the definition above, it should be challenging to understand whether an individual participated in the sharing of information, and much so, the features of their information shared.
Differential privacy algorithm fits into the context of differential privacy implementation of strategies such as randomisation [24], [26]. However, according to research, the users do not report they are accurate information. They contribute just a part of their information where random noise added on the information. However, in the instance of discrete information or
14
data where the addition of noise is demanding, users could fall within a given likelihood [26]. By this act, the person gathering the information cannot make any assertive conclusion about individuals anymore. The only likelihood is through the review of enough users to help establish the overall random noise.
Looking at some variation in the explanation of differential privacy;
A query is denoted as a differential private query if for all its likely subsets of the outcomes and all adjacent datasets the following rule stands.
𝑃[ 𝑄(𝐷1) ∈ 𝑅] ≤ 𝑒𝜀∗ 𝑃 [𝑄(𝐷2) ∈ 𝑅] + 𝛿
In comparing to the early definition, a new element 𝛿 added. The addition gives a chance for the probability of 𝛿 of openly breaking the differential privacy. However, for ensuring good privacy of the system, both the 𝛿 𝑎𝑛𝑑 𝜀 are kept.
The sensitivity of the query illustrates how much the outcome can vary if the query implemented on two adjacent datasets.
𝑆(𝑄) = 𝑚𝑎𝑥𝐷1,𝐷2∥ 𝑄(𝐷1) − 𝑄 (𝐷2) ∥2
Where ∥. ∥2 represents the 𝑙2 𝑛𝑜𝑟𝑚. Furthermore, the sensitivity should be as low or preferable a constant.
Besides, in one duplication of federated learning, information is of a user is either used fully or not at all. For the clarification for this, a different explanation of adjacent dataset needed. Considering two datasets 𝐷1 𝑎𝑛𝑑 𝐷2 To be adjacent if they vary in the information of an individual user. The datasets are similar except that one of the datasets comprises data from a user that is not present in the other dataset.
The motivating force behind this is that it should be challenging to distinguish between a user-contributed in training the model. However, the model should not diverge much by adding a new user.
To construct a federated learning algorithm which can be recognised to be (𝜀, 𝛿)-
differentially -private, is established on the ideas from Abadi et al. [27]. They introduced a different type of SGD and present came up with the theorem:
A learning algorithm based on SGD calculates the gradient estimate in each of the T
iterations. The data used to calculate the estimate is a sampled probability q. The sensitivity of the approximation bounded by a constant d and noise sampled from N(0,δ2d2) added to
15
the approximation in each iteration. However, estimating the weights of the next iteration, the approximation subtracted from the current weights.
Moreover, the constants c1,𝑐2 exist, such as the procedure is (𝜀, 𝛿)- differentially-private for any ε< c1q2T and δ>0 if the noise added using:
σ≤c2 √T log (1/δ)
q
ϵ
The adaption of federated learning to enable it to fit into the sated framework above suggested by McMahan et al. [28]. In the framework implementation, as suggested by McMahan et al. [28], firstly all users are sampled with a probability q. The probability q shows that the number of experimented users can differ across iterations. The fundamental proof of the theorem requires that the data were sampled individualistically from each other, so we have a sample with a probability q instead of always sampling K users.
The proofing of the theorem shows that stratagems like stratified or cluster sampling cannot implement as the introduction of bias into the data. However, the sampling of a user with the highest probability is more likely hence making it challenging to ensure the person’s privacy. Bounding of the sensitivity of the gradient approximation, the size of the individual update Hi 𝐶an have by s through bounding. The implementation carried out by checking the L2- norm of Hi 𝑀𝑜𝑟𝑒𝑜𝑣𝑒𝑟, scaling it down when the need arises:
𝐻̅ = {𝐻 𝐻𝑖 𝐼 ∗ 𝑠 ‖𝐻𝑖‖2 , ⅈ𝑓‖𝐻𝑖‖2 ≤ 𝑆
However, another form of expressing how to reduce the L2- The norm for an unbiased network is applying the different limits in the various stages. For instance, let 𝑠𝑖 be the limit of the L2- the norm in the i-th stages and there are l stages; then the overall limit is shown as
𝑠 = √∑ 𝑠𝑖2 𝑙
𝑖=1
The summation in the square root expanded to the sum of squares of the individual aspects on the process of updating the vector. Also, the bounds of the single stage can be tuned to
advance the learning process.
16 ∥ 𝐻𝑖 ∥2= √𝑚
Where m represents the number of weights. However, if a C represents a set of sample users, then the more natural way for the estimation of the gradient as follows
𝑔(𝐶) = ∑𝑖𝜖𝐶𝑛𝑖 𝐻𝑖 ∑𝑖𝜖𝐶𝑛𝑖
Where 𝑛𝑖 Is the data points checks the significance of the user's update? Furthermore, in the checking for the level of sensitivity, firstly the estimation of the gradient g (C) done upwards. Let represent 𝑁 = ∑𝑖𝜖𝐶𝑛𝑖 show the number of data points implemented in an up-to-date iteration: ∥ 𝑔(𝐶) ∥2=∥∑𝑖𝜖𝐶𝑛𝑖 𝐻𝑖 ∑𝑖𝜖𝐶𝑛𝑖 ∥2 = ∥ ∑𝑛𝑖 𝑁 𝑖∈𝐶 𝐻𝑖 ∥2 ≤ ∑ ∥ 𝑖∈𝐶 𝑛𝑖 𝑁𝐻𝑖 ∥2 = ∑ |𝑛𝑖 𝑁| 𝑖∈𝐶 ∥ 𝐻𝑖 ∥2≤ ∑ |𝑛𝑖 𝑁| 𝑆 𝑖∈𝐶 = 𝑆
In the implementation of the triangle, the inequality equation permits us to be bound to the sensitivity of the gradient estimate.
𝑆(𝑔) = max 𝐶,𝑘 ∥ 𝑔(𝐶) − 𝑔(𝐶 ⋃𝑘 ∥2 ≤ max𝐶,𝑘 ∥ 𝑔(𝐶) ∥2+∥ −𝑔( 𝐶 ∪ 𝑘) ∥2 = max 𝐶,𝑘 ∥ 𝑔(𝐶) ∥2+∥ 𝑔( 𝐶 ∪ 𝑘) ∥2 = max 𝐶,𝑘 2𝑠 = 2𝑠
The theorem stated above holds because the sensitivity of the gradient estimate is bounded. Furthermore, a significant amount of noise added to each iteration.
Gradient snipping often implemented to deal with exploding gradients, an example found in the optimisation of every steep area [29]. Furthermore, the final gradient is clipped, before the clipping of the individual elements before the calculation of their average.
17
The addition of noise is a prevalent regularisation plan [30]. Adding noise randomly, the model will have a harder time memorising data, which helps in handling overfitting. Also, it has stated that this common regularisation can be comparable to other forms of regularisation, like the penalising the size of the weights [31].
Besides, one major problem in differential confidentiality is the selection of the appropriate standard of differential privacy. There is not a standard as to which level is considered a good and acceptable choice in each case. The choosing of the differential level is a fundamental problem in general [32], [33], independent of the implementation of collaborating learning. In ensuring the right level of differential Privacy in the collaborating learning system, both methods of regularisation implemented considerably. Ensuring the regularisation effect become strong hence making learning more problematic. Empirically, McMahan et al. [28] suggested that they can accomplish the same level of precision with this algorithm. But the training time takes about 60times longer since the trimmed gradients and the additional noise decelerates the convergence procedure down
Nevertheless, from the standpoint of economics differential, privacy guarantees the protection of individuals from any new sources of harm. That may arise due to their information used in private data systems that generally would not have encountered if the data was not part of d. However, individuals may still encounter some harm as soon as the result M (d) from the differential private mechanism M is published. Differential privacy guarantees that individuals’ agreement of participation will not meaningfully increase their harm.
Furthermore, one thing that differential privacy cannot guarantee is unconditional freedom from harm. Nor does differential privacy guarantee that a secret is going to remain a secret. 2.2.4 Secure Multi-party Computation (SMC)
Secure multi-party computation built on an idea from cryptography. In SMC organisations input data like a pick-up location which is then split into different pieces and masked with different randomly selected numbers. The information are hence sent to different server which operation are mutually exclusive from each other, carrying out the process the servers never exchange the original information from the organisation, but only the encoded,
aggregate amount then compared. SMC guarantees data privacy and trust, unlike traditional cloud computing. In-addition, Secure multi-party computation allows organisations to work together without ever knowing one another’s confidential information.
18
The principle of zilch-knowledge is very appropriate, but these characteristics typically need complex computation protocols and hence, might not be easy to achieve or effective [12]. In some instances, partial knowledge disclosure is satisfactory when security agreements are assured. However, it is very available to develop a security prototype with the secure multi-party computation with low security environment in substitute for productivity.
2.2.5 Homomorphic Encryption
Data security is an excellent barrier to the version of no-demand computing. Conventional standard encoding approaches provide confidence to the information on the end-user’s devices form and when they are in the process of transportation or exchange state. However, in managing stage, carrying out operations on data require decryption of data. At this stage, information is obtainable to the on-demand computing provider. Hence traditional corded approaches are not sufficient to protect the information available completely. In this thesis, I review the homomorphic encryption methods and their implementation methods in on-demand computing to secure data in the managing stage. Homomorphic cording permits the user to activate encrypted information directly without decryption.
2.2.6 Gaussian mechanism
The Gaussian mechanism (GM) approximates a real-valued function f: D → R with a differentially private mechanism. Specifically, a GM adds Gaussian babble measure to the functions data set sensitivity Sf. This sensitivity established as the maximum of the absolute distance 𝑘(𝑑) − 𝑓(𝑑′)𝐾
2, where d′ and d are two adjacent inputs. A GM then explained as 𝑀(𝑑) = 𝑓(𝑑) + 𝑁 (0, 𝛿2𝑆𝑓2)
In the following, we consider σ and ǫ are stable and assess a question to the GM conceding a single approximation of f(d). We can then bound the probability that ǫ-differential privacy removed according to 𝛿 ≤ 45 exp(−(𝜎ǫ) 2 2⁄ ) [25]. However, δ is accumulative and grows if the consecutive inquiries to the GM. Therefore, to protect privacy, the δ should always be monitored, thus ensuring that when a threshold for δ achieved, the GM shall not answer any new inquires.
2.2.7 Laplacian mechanism
Laplacian mechanism apprehends all that is learnable in the arithmetical queries learning model, as well as many standard data mining assignments and necessary information.
However, the attention of a counting query is 1. The adding or deletion of a single individual can change a count by at most 1. It is an instantaneous corollary of the formula that(𝜀, 0) - differential confidentiality accomplished with the calculating queries by the addition of noise
19
scaled to 1⁄𝜀, that is, with the addition of noise drawn from Lap(1 𝜀⁄ ).The predictable bias, or miscalculation, is 1/ε, free of the size of the datasets. A constant but arbitrary list of m
counting queries can be observed as a vector-valued query. Missing any further statistics about the set of probes a worst-case bound on the thoughtfulness of this vector-valued probe is m, as a single entity might change every count.
Given any function𝑓: 𝑁|𝑋| → 𝑅𝑘, the Laplace mechanism is defined as 𝑀𝐿(𝑥, 𝑓(. ), 𝜀) = 𝑓(𝑥) + (𝑌1, … … . , 𝑌𝑘)
where 𝑌ⅈ are independent identically distributed random variables drawn from Lap (∆f /ε). The Laplace mechanism preserves (ε, 0)-differential privacy. Proof. Let 𝑥 ∈ 𝑁 |𝑋| and 𝑦 ∈ 𝑁 |𝑋| be such that ∥ 𝑥 − 𝑦 ∥ 1 ≤ 1, and let 𝑓 (·) be some function 𝑓: 𝑁 |𝑋| → 𝑅 𝑘. Let 𝑝𝑥 represent the probability density function of 𝑀𝐿 (𝑥, 𝑓, 𝜀), and let py denote the probability density function of 𝑀𝐿 (𝑦, 𝑓, 𝜀). We associate the two at some subjective point where the first inequity follows from the triangle inequality, and the last follows from the description of sensitivity and the fact that ∥ 𝑥 − 𝑦 ∥ 1 ≤ 1. That 𝑝𝑥(𝑧) 𝑝𝑦(𝑧) ≥ 𝑒𝑥𝑝(−𝜀) follows by symmetry.
2.3. Data distribution in Federated learning
In this subdivision, the focus is on by what means to categorise federated learning founded on the allocation attributes of the information. In the permitting of a matrix, 𝐷ⅈindicates the information assumed by respectively information proprietor i. Each vertical section of the matrix corresponds to a section, and each horizontal section symbolises characteristics. Within identical period, information arrangements may also comprise tag information. We symbolise the descriptions item as Q, the tag item as R, and we use X to represent the sample ID object. In the economic world, markers may be users’ money; in the advertising discipline labels may be the customer’s acquisitions yearning; in the schooling discipline, X may be the grade of the school children. The feature Q tagged R and experiment Ids X constitute the comprehensive training data (Q, R, X). The attribute and experiment space of the information participants not indistinguishable.
Federated learning is group into three main groupings; thus, the horizontal federated
learning, vertical federated learning, hybrid [12] with federated transfer learning founded on ways information are handed out between countless participants in the feature and experiment ID space.
20 2.3.1 Horizontal federated learning
Horizontal federated learning is mainly in place when two data do not have overlapping information. However, the data will have similar feature spaces because the data might be from the same field. In-addition, in horizontal federated learning organisations usually process and send home-grown gradients to train a universal model. Hence, making the two data used in collaborating deep learning where there is independent training of the data and only the subset of the updated parameters. According, to the 2017 google proposed solutions for horizontal learning in Android devices model upgrade [34]. Also, researches from [35] suggested ways to decrease the bandwidth needed in during in large-scale distributed training for communication. Similarly, in [5], the writers suggested approaches to improve the
expenditure incurred for transmission during the facilitation of the training of the centralised models based on data distributed over mobile customers.
Furthermore, in terms of security, horizontal federated learning schemes often adopt
authentic participants and security against an authentic but snooping servers. That is, only the server can achieve a concession in the privacy of the data participants. Besides, techniques such as homomorphic encryption [36] and secret sharing [22] used to administer the gradients to safeguard user privacy. Google, however, propositioned a horizontal federated learning system which can efficaciously work on billions of phones [13] Hence, the system operates a server for the accumulation of information or data from the gadgets which implements differential privacy [34] and secure accumulation to improve privacy certification. Word identification [37] as implemented by Apple Inc. and Google in ’hey Siri’ and ‘Ok Google’ respectively, very mainstream implementation of horizontal separation due to the fact that individuals can expresses the similar words with a diverse expression.
Further research also focused on building security models that consider the malicious user due to the increasing privacy challenges they pose [38]. Let consider two banks from the same country. Although they have non-overlapping clientele, their information will have similar feature spaces since they have very similar business models. They might come together to work in partnership in an example of horizontal federated learning.
2.3.2 Vertical Federated Learning
In recent research’s algorithms for confidentiality - maintaining technological learning top the suggested for vertically segregated information sets, and one of the suggested methods was the Cooperative Statistical Analysis, association rule mining, secure linear regression among others. Similarly, [10] suggested a vertical federated learning system train privacy-
21
preservative logistic regression model. Studies are on-going looking at the effects of entity determination on the learning functioning and methods by which homomorphic encryption for privacy-preserving calculation could be incorporated.
Vertical federated learning is an applicable instance where the data distribute the same experiment ID space but have a difference in their feature space. Also, vertical federated learning is the method in combining unique components and calculating the implementation cost with gradients in confidentiality-preserving routine, establish with a model with the data from each of the organisations collaboratively.
Furthermore, in terms of security, vertical federated learning scheme assumes authentic but spooning members. Also, an advantage in the vertical federated learning is when there is an adversary in one part of the data sets, let say data set A, it does not affect the other data set B. Because of their non-colluding and the security in vertical federated learning is that an
adversary is only to learn for the data set of the customer which has been compromised but not the other customer's data sets beyond what is exposed by the contribution and production. Additionally, a Semi-honest Third Party (STP) introduced to help in the enablement of secure estimation between the two data sets if the STP does not collide with either of the data sets. In vertical federated learning at the end of learning each data set has access to the model parameters linked to its components, hence at inference time, the two data sets also need to co-operate to cause a production.
In vertical federated learning, two corporations providing different services (e.g. banking and e-commerce) but having a significant intersection of clientele might find room to collaborate on the different feature spaces they own, leading to better outcomes for both. Furthermore, in vertical federated learning systems frequently embraces unit alignment systems to collect the overlapping samples of the organisations. The overlapping information collected is then used in the instruction of the model implementing an encryption process. From [7] suggested a lossless vertical federated learning system facilitate organisations collaboratively train gradient advancing decision trees.
Furthermore, vertical federated learning implements privacy-preserving entity alignments to discover a standard user among the two organisations, whose gradients used to instruct the decision tree cooperatively — an organisation such as the governmental agencies preserved as a condition of vertical partition. For instance, the unit of healthcare requests the tax
22
statistics of inhabitants, kept by the taxation unit, to implement their health policies whiles the department of taxations requests the health information of inhabitants, which is stored by the health section. These two units have a common sample space which is the inhabitants, but each of the organisation only has a part of the features.
In several other functions, while existing federated learning systems mostly emphasis on one type of division, the breaking up of data and information within the involving organisation maybe hybrid of horizontal and vertical partition.
2.3.3 Federated Transfer Learning (FTL)
Federated Transfer learning implemented in cases where the two data sets are different not only in their components space but also sample. Geographical constraints are one of the major limiting factors.
The users of the two sets of data have a very limited intersection, and, it can be that the two sets of data are from diverse businesses, making an insignificant part of the component space from other data to overlap.
In such instances, transfer learning is more applicable compared to horizontal and vertical learning. Notably, a communal instance between the two dataset’s components space learned using the spare standard sample set. Moreover, well ahead, a prediction analysis can be carried out on the data sets to obtain a sample with only one-side components. FTL deals with question and issues beyond the capacity of current federated learning algorithms, hence making it an essential extension to the current federated learning system.
In recent years, research on adopting federated transfer learning in various areas such as image classification projects and sentiments analysis. Intuitively parties in the same data federation are usually organisations from the related industry, therefore are more inclined to information propagation.
2.4: Exchange Architecture of a federated system
In the implementation of the exchange process between the federated learning systems, there are two main fundamental designs involved, namely: centralised and the distributed design. In the distributed design, an excellent example of a system that supports this distribution found in the blockchain [41] platform, thus because in the distributed design the exchange are within the organisations [9] with each organisation able to update the universal parameters without delay. Furthermore, the distributed disease diagnosis systems among healthcare
23
centres is an illustration of distributed architecture. Hence, each healthcare centre in the system share the model train with information from their patients and receives a universal model diagnosis. A principal problem in the distributed design is developing a fair in the protocol to suit each organisation involved.
In centralised design, they are mainly used in current existing federated learning systems due to the high risk of unfairness in the distributed design implementation. Also, this is due to the facts that in the centralised design the exchange of information within an organisation is often asymmetric meaning one server or a particular organisation from the group is responsible for the combination of the information from the other organisations and forwarding back the trained results [13]. Furthermore, the update of the initial parameters also carried out in the same server. A popular used for the centralised design is implemented by Google in their keyboard [4]. Information collected from clients through their phones where a collaborative training of the model is implemented using the collected information and forward back to the clients, however, one major problem in this design is the reduction of exchange cost in the architecture.
2.4.1 Operation of the federated learning system
In this unit, the general building for a horizontal and vertical federated learning scheme considered, it noted that the two types of architecture are dissimilar in design; therefore, examined separately.
24 Horizontal Federated learning Architecture:
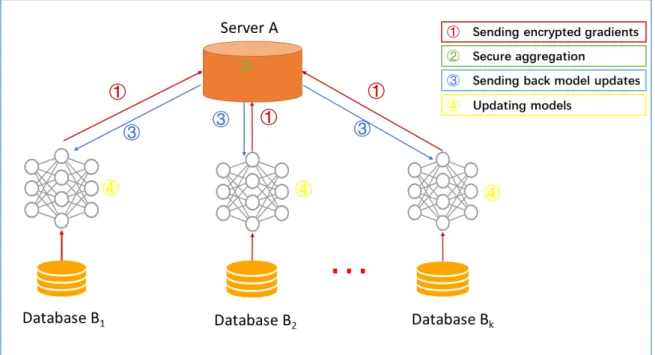
Figure 2: Horizontal federated learning architecture: Source,https://www.groundai.com
In a horizontal joined learning scheme, the participants can only collaborate when they have the same data structure, the learning of the machine learning dummy carried out with
assistance of a boundary.
According to [10], there is no leakage of data from any of the parties to the server based on the assumption that the parties involved are trustworthy and honest. In contrast, the server is considered trustworthy, honest, but curious. Furthermore, the are four main processes involved in the training process in these architectures.
In the first stage of the training process, all parties calculate training gradients, disguise assortment with encryption, differential privacy or confidential allocation systems on their local servers and machine before sending a disguised result to the server. Secondly, a secure aggregation is executed by the server without learning data about any parties. Thirdly, after the secure aggregation execution, the result is forward back to parties involved by the server. In the concluding stage, parties upgrade their corresponding dummy with the decrypted gradients.
The style of horizontal federated learning confirms the [22] statement of information seepage in opposition to a partially-honest server protected if the gradients combination is carried out with homomorphic cording.
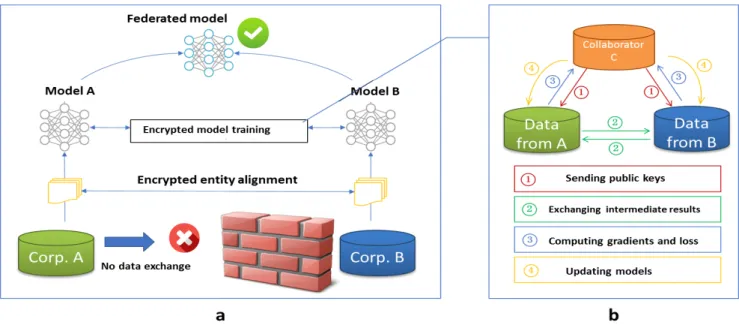
25 Vertical federated learning Architecture:
Figure 3: Vertical Federated Learning architecture; Source,https://www.groundai.com
Conceding two companies would be keen on to train a machine learning prototype jointly, and their business classifications apiece have their information. Besides, one of the
companies also has tag information that the model essentials to forecast. For information confidentiality and confidence purposes, the two companies cannot straightforwardly trade information. In ensuring the discretion of the information during the training stage, a third-party associate introduced. Here we assume the associate is honourable and does not conspire with either company, but both companies are truthful-but inquisitive to the other. The
confidential third party a sensible supposition since the third party played by establishments such as a legal authority.
Moreover, in the vertical federated learning architecture, since the user group of the two companies are dissimilar, the whole alignment must be encrypted. To enable the system to implement the encryption-based user identification alignment methods as proposed in [42] as a confirmation of the familiar users of both organisations without either revealing their data. In the process of the whole alignment, the scheme does not reveal users that do not involve intersection with each other.
Furthermore, after the common element from both parties has been established, by the encrypted training model, we can implement these interactive elements information to train
26
the machine learning model. There are four primary processes involved in the training of the model; firstly, a third party known as the associate, develops an encryption pair and send the public key to the two companies involved. Secondly, the two companies also encode and share the transitional consequences for gradient and damage estimations; additionally, the two companies calculate corded gradients and add additionally disguised respectively, the encrypted values forwarded to the collaborator. Finally, the collaborator decodes and
forwards the encoded gradients and loss back to the two companies, then the two companies remove the disguise and update their model parameters.
The training process illustrated mathematically using linear regression and homomorphic encryption.
Incentives Machinery: In order to ultimately commercialise federated learning within several businesses, an open policy and inducement procedures industrialised. The presentation of the model will be demonstrated in the real applications and this implementation after it
established and documented in a perpetual information logging device. A business which provides extra information turns to benefit more hence essential, and the prototype’s achievement greatly relays on the information provider’s influence on the scheme. The efficiency of the models is circulated to participants depending on federated scheme and continue to encourage businesses to connect their data to the information federation. The application of the earlier mention style not only take into account the confidentiality
fortification and efficiency of collaboratively-modelling among multiple businesses, but also considers how to recompense businesses that provide more information, and by what method to apply inducements with a compromised system. Consequently, making federated machine studying an "enclosed- ring " system.
27
Chapter 3 Established studies
Under this section, will build on the first sections be focusing more on already prevailing researches on federated learning systems.
3.1 Approach
The approach used in determining already prevailing research was using search engines like Google through the search of keyword “federated learning”. The focus of the search was on publication in general areas of the topic without any restrictions to a specific field like computer science or mathematics.
3.2 Discrete Studies
From individual studies already in existence, an exciting trend identified, indicating that most of the existing research focused on horizontal data segregating. This trend is likely due to benchmarking in horizontal data segregation is easily accessible compared to the other forms of data segregations available.
For instance, in vertical data segregation, alignment of a dataset with different characteristics is an issue dependent and thus can be challenging. Hence, further needed studies on vertical segregation implementation.
Furthermore, generally, methodologies of the prevailing researches can be functional in one form of machine learning dummy, with a mainly premeditated procedure. A model may accomplish advanced model usefulness, and a broad-spectrum joined learning agenda may be more chaotic or easier-to-implement.
Finally, the feature of stochastic gradient descent, the dummy combination process can efficiently utilise the stochastic gradient descent and is presently the most widely held methodologies to implement federated learning without the risk of unswervingly revealing the client’s information. The centralised design is conventional of current implementations. A dependable server is needed their hypotheses.
Algorithm design, benchmark, application and efficiency enhancement are the focus of most recent researches; hence, the review of those areas.
28 3.3 Researches on Algorithm Design
Implementation of federated averaging on TensorFlow, focusing on enhancing interaction competence, according to McMahan et al. [19]
Horizontal tree-bases federated learning system suggested by Zhao et al. [9], where each of the decision trees is trained locally without exchange between the organisations. The tree trained in an organisation is forwarded to the next organisation to continuous train several trees. Protection in a decision tree ensured by the implementation of differential privacy. A technique for privacy-preserving the ridge regression as propositioned by Nikolaenko et al. [43] suggested method brings together homomorphic encryption and Yao’s garbled circuit to accomplish the confidentiality prerequisites. However, an additional assessor required in the implementation of the algorithm.
Furthermore, Chen et al. [7] proposed the implementation of a vertical tree-based federated learning system known as the Secure Boost. In the implementation, it assumed that only one organisation has the labelled dataset, using the alignment method to get shared information and then build the decision trees. The gradients by the implementation of the homomorphic encryption are safeguarded.
Federated learning framework, together with transfer learning for neural networks as familiarised by Liu et al. [40] suggests a scenario of two organisation, has a part of shared samples. Moreover, all the label data in one organisation tackled — furthermore, additional one key coded to protect the model parameters to ensure information privacy.
Smith et al. [8] merged confederated learning with multi-tasking learning [44]. Their
processes focus on the problems of extreme transmission cost, laggards, and fault acceptance for multi-tasking learning in the federated situation.
Blanchard et al. [45] focused research on the instance where the organisations may be Secretive and try to find the midmost ground in the federated learning system. Hence the proposal for the use of Krum, which helps in the selection the gradient vector closest to the barycentre within the suggested parameters vectors.
Yurochkin et al. [21] built a probabilistic dual structure by implementing a Bayesian
nonparametric mechanism. Beta-Bernoulli procedure cognisant the pairing process to join the local prototypes into a federated universal prototype.
29
Truex et al. [46] join secure cooperative calculation and differential privacy- protective federated learning. The differential privacy implemented to push noised to the local updates. However, the protection of the raucous update was carried out with Paillier cryptosystem [47] before forwarded to the local server.
3.4 Researches on Benchmarking
Studies on the performance comparison among different federated learning algorithms by Nilsson et al. [48], also incorporated combined averaging [19], federated stochastic variance reduced gradient [49] and Cooperative machine learning [50], all through-out experiments both independently and identically distributed random variable. Furthermore, Non- self-governing and identically dispersed partitions executed dataset, which performs better on MNIST than any other algorithm stated.
LAEF benchmarking framework for federated learning as suggested by Caldas et al. [51], LEAF consist of freely available combined datasets, system metric and an array of statistical. 3.5 Researches on Application
Studies carried out by Wang et al. [52] proposed federated averaging to apply allocated hidden strengthening learning in a mobile edge computing system. The implementation of deep reinforcement learning and federated learning can successfully advance the mobile edge computing, interaction.
Ulm et al. [53] employed federated learning in Erlang, which is a well-designed indoctrination language—founded on federated averaging, the creation of an efficient accomplishment of an simulated neural network in Erlang.
Hard et al. [54] implemented combined learning in phone keyboard prediction — Federated averaging technique to learn an alternative of LSTM used in the research.
Nishio et al. [55] used federated averaging in stable smart phone edge processing structures. Through-out the studies, the implementation of mobile edge computing framework applied in the management of resource of diverse clients.
Samarakoon et al. [56] initial implementation of federated learning were in the studies of privacy certifications, however during further research, the team assumes SPDZ [57] and moment accountant [27] approaches similarly for discrepancy privacy and multi-party computation in associated learning perspective.
30
Nevertheless, some well know examples are the implementation of Photo Labeller by Corbacho, which is a practical, functional case of a federated learning system. The mobile device was used in the training of models locally. Furthermore, used federated averaging on the servers to link the model, and then the trained model is distributed across every client for the process of photo labelling.
The combined learning platform is known as the federated Al Technology Enable, which supports multiple data partitioning algorithms types implemented by the WeBankFinTech company. The platforms security computation procedures based on homomorphic encryption and multi-party calculation.
3.6 Efficiency Enhancement
Sattler et al. [58] suggested a compression structure known as the sparse ternary compression. The primary function of the sparse ternary is the compression of the interaction within the system using error gathering, optimal Golomb encoding, among other methods. In the studies, it established at the method applied is robust to non- independent and identically distributed data and a considerable number of organisations.
Zhu and Jin [59] developed a multi-objective evolutionary algorithm to decrease the message sharing cost with the universal prototypical test faults concurrently. Contemplating on the decreasing of the message price and the strengthening of the universal learning model correctness as the two objectives, lead to the formulation the federated learning as a bi- impartial optimisation question and answered by the multi-objective evolutionary algorithm. Jeong et al. [60] suggested a federated learning structure corresponding gadgets with non- independent and fairly distributed( IID) local dataset. Through the research the developed a federated distillation, whose interaction depth relied on the output measurement but not the scope of the model. Furthermore, it suggested the data reinforcement process using an oppositional generating network to transform the training dataset into an independent and same distributed form.
Konevcny et al. [49] brought to light two methods, the structured and sketched updates, to minimise the message sharing the cost in federated averaging. The process can minimise the message sharing the cost by order of two in magnitude, causing a small deprivation in the merging speed.