Procedia Computer Science 79 ( 2016 ) 100 – 111
1877-0509 © 2016 Published by Elsevier B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/).
Peer-review under responsibility of the Organizing Committee of ICCCV 2016 doi: 10.1016/j.procs.2016.03.014
ScienceDirect
7th International Conference on Communication, Computing and Virtualization 2016
Performance Analysis of Various Fuzzy Clustering Algorithms: A
Review
Anjana Gosain
a, Sonika Dahiya
ba
Professor, USICT, GGS Indraprastha University, Sector 16C, Dwarka, Delhi-110075, India bAssistant Professor, USICT, GGS Indraprastha University, Sector 16C, Dwarka, Delhi-110075, India
Abstract
Fuzzy clustering is useful clustering technique which partitions the data set in fuzzy partitions and this technique is applicable in many technical applications like crime hot spot detection, tissue differentiation in medical images, software quality prediction etc. In this review paper, we have done a comprehensive study and experimental analysis of the performance of all major fuzzy clustering algorithms named: FCM, PCM, PFCM, FCM-σ, T2FCM, KT2FCM, IFCM, KIFCM, IFCM-σ, KIFCM-σ, NC, CFCM, DOFCM. To better analysis their performance we experimented with standard data points in the presents of noise and outlier. This paper will act as a catalyst in the initial study for all those researchers who directly or indirectly deal with fuzzy clustering in their research work and ease them to pick a specific method as per the suitability to their working environment.
© 2016 The Authors. Published by Elsevier B.V.
Peer-review under responsibility of the Organizing Committee of ICCCV 2016.
Keywords: Fuzzy Clustering; FCM; PCM; FCM-σ; IFCM-σ; KFCM-σ; Type 2; Intuitionisitic; IFCM; DOFCM; CFCM; NC;
1.Introduction
Clustering is an important unsupervised form of classification technique of data mining [1,3]. It divides the data elements in a number of groups such that elements within a group possess high similarity while they differ from the elements of other groups. Clustering can of two types: Hard Clustering and Fuzzy Clustering[1,3]. When each element is solely dedicated to one group, that type of clustering is called Hard clustering. In hard clustering, clusters have crisp sets for representing element's membership, i.e. the membership of elements in a cluster is assessed in binary terms according to a bivalent condition that an element either belongs or does not belong to the set. In contrast, when the elements are not solely belonging to any one group, instead they share some fraction of
* Corresponding author. Tel.: +0-000-000-0000 ; fax: +0-000-000-0000 .
E-mail address: [email protected].
© 2016 Published by Elsevier B.V. This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/).
membership in a number of groups, that type of clustering is called Fuzzy clustering. So, fuzzy clustering permits the gradual assessment of the membership of elements in a set which is described by a membership function valued in the real unit interval [0, 1]. Thus membership functions are represented as a fuzzy set which can be either Type-I, Type-II or Intuitionistic. Algorithms proposed in the literature are based one of the three fuzzy set theory as shown in figure 1.
Fig. 1. Classification of Fuzzy algorithms discussed.
Bezdek's famous fuzzy clustering algorithm named as Fuzzy C-Means Algorithm and other algorithms such as PCM, PFCM, FCM-σ which are derived from FCM algorithm have been useful in many technical areas like image analysis, pattern recognition [3, 4, 5, 6,7]. FCM performs well with noise free data but are highly sensitized to noise and outliers. As they fail to distinguish between data points and noise or outliers, so centroid is attracted towards outliers instead of the center of the cluster. Though PCM and PFCM perform better in presence of noise in comparison to FCM, but PCM fails to find optimal clusters in presence of noise[4]. PFCM fails to give appreciable results when data set consists of two clusters which are highly unalike in size and outliers are present[5].
T2FCM and KT2FCM algorithms are based on Type-2 fuzzy sets, so some data elements contribute more in computing appropriate cluster centroids [8,9]. Though they outperform earlier proposed algorithms but T2FCM fails when the data structure of input patterns is non-spherical and complex[8]. KT2FCM overcome the problem of T2FCM by introducing kernel, tangent function and lagrangian methods, with basic objective function of the T2FCM algorithm and gives better segmentation over noisy data [9].
To further improve the effectiveness of clustering algorithms new concept of hesitation degree was merged with membership degree, based on which IFCM, IFCM-σ, KIFCM, KIFCM-σ were proposed. IFCM extends conventional FCM by adding intuitionistic feature to membership and objective functions. IFCM improved cluster computation over existing algorithms but failed to efficiently cluster non-spherically separable data. Then next Robust Intuitionistic Fuzzy C-means (IFCM-σ) was proposed that takes into account new distance metric to work well with non-spherically separable data. KIFCM was proposed next by introducing Radial Basis kernel function to improve the accuracy of the intuitionistic fuzzy c-means. KIFCM-σ is a hybridization of IFCM, kernel function, and new distance metric in the feature space and in the data space and thus overcomes various problems of IFCM and FCM-σ.
The main focus of all these algorithms is on improving the clustering or centroid computation without considering the noise and outliers. NC and CFCM are proposed specifically to work efficiently with noisy data. They emphasise on reducing the effect of outliers on resulting clusters rather than exactly identifying them. CFCM does this by introducing a new variable named credibility. As these algorithms emphasis on reducing the effect of outliers on resulting clusters. Therefore, the problem with these algorithms is that they fail to find accurate clusters. To overcome this problem, DOFCM works on identifying outliers based on density of data set and then performs clustering considering actual data points. Thus, it improved the accuracy of clusters.
In this paper we discussed all these algorithms in detail and experimentally showed a performance comparison of all these algorithms.
Paper Organisation is like this: In 2nd section, a brief discussion of the fuzzy clustering algorithms. In 3rd section, short description of datasets, used in this paper for experimental analysis. In section 4, experimental results in the form of figure for comparison of algorithms are represented.
2.Literature Review
In this paper, the data-set is denoted by X, where X={x1, x2, x3, …… xn}, specify n points in 2-dimensional space. Centroids of clusters are denoted by ݒ, and c is the total number of clusters present in the data-set, k is used
to denote cluster. Therefore, value of k is in the range [1,c].
2.1.The Fuzzy C-Means (FCM)[10]
FCM is one of the most renowned fuzzy clustering algorithm. It works on the assumption that number of clusters 'c' are known for the given dataset and minimizes the objective function (ܬிெ), given as:
2 1 1 c n m FCM ik ik k i
J
¦¦
u d
[1]Where 'ݑ'is the membership of datapoint ‘xi’ in cluster ‘k’ and
d
ikx
iv
k is the Euclidean distancebetween ‘xi’ and cluster center ݒ and membership 'ݑ' satisfies the following relationship:
1 1 1, 2,3.. c ik k u i n
¦
[2]and ‘m’ is a constant value known as the fuzzifier (or fuzziness index) as it controls the fuzziness of the resulting clusters. In our implementation m is taken to be 2. Minimization of ܬிெ is performed by the alternating
optimization technique [6]. Membership of every point is updated using following equation:
2 1 1 1 , ik m c j k i dki dji
u
§
·
¦¨
©
¸
¹
[3]where k is an integer in range [1,c] and i is an integer in range [1,n] and
1 1 n m ik i i n k m ik iu x
v
u
¦
¦
[4]But FCM failed to detect noise and outliers, so it treats the noisy points and outliers same as the actual data points. Thus, it's centroid is attracted towards outliers instead of the center of the cluster.
2.2.Fuzzy C-Means with new distance metric (FCM-σ)[18]
D. M. Tsai and C. C. Lin [9] proposed FCM-σ by changing the distance metric used in conventional FCM with a new distance metric, '݀ԢଶԢ, defined as:
2
'
i k ki kx v
d
V
[5]Where ߪ is the weighted mean distance of cluster center 'ݒԢ and is defined as:
2 1 1 .
||
||
n m ik i n m k ik i i ku
x
v
u
V
¦
¦
[6]2 1 1
||
||
c n m FCM ik k i i i kx
v
J
Vu
V
¦¦
[7]Membership function equation is -
[8]
where k is an integer in range [1,c] and i is an integer in range [1,n] Cluster center equation is:
1 1 n m ik k i n k m ik i iu x
v
u
¦
¦
[9]2.3.Possibilistic C-Means Algorithm (PCM) [12]
Krishnapuram and Keller proposed a new PCM algorithm, by relaxing the following constraint:
1 1 c ik k i
u
¦
[10] 2 . 1 ( , ) 1 1 1 1 c n c n m m JPCM U V ukidki k uki k i k i K ¦ ¦ ¦ ¦ [11]where ߟ are suitable positive numbers. The first term of this objective function tries to minimise the distance of the data points to the centroids and the second term works on ݑ to be as large as possible, thus it avoids the trivial solution [6, 12]. The updating of centroids are same as that in FCM (eq no. [4]) and membership of data points is updated as:
[12]
PCM, sometimes helps with noisy data. But the problem is it suffers from the inconsistencies like instead of global minimum of the underlying objective function, a suitable non-optimal local minimum provides the desired clustering results.
2.4.Possibilistic Fuzzy C-Means (PFCM) [13]
N.R. Pal integrated the fuzzy approach from FCM and possibilistic approach of PCM. Hence PFCM has a possibilistic membership (ݐሻ and a fuzzy membership (ݑሻ associated with data point. It works on minimising the following objective function:
2 ( , , ) 1 1 1 11
c n c n m k PCM U V T ki ki ki k i k i kiJ
au
bt d
t
K K¦¦
¦ ¦
b
[13]subject to constraint that
1 1 c ik k i
u
¦
where 0 ≤uik ˂ 1 and 0 ≤t
ki ˂ 1 and m > 1, ߟ > 1,a
> 0 andb
> 0.'a' and 'b' are constants define the relative importance of fuzzy membership and typicality values in the objective
2 1 1 1 ,
'
'
ik m c j k i ki jiu
d
d
§
·
¦¨
¸
©
¹
1 1 1 2 1||
||
ki m i k ku
x
v
K
§
¨
·
¸
©
¹
function. 2 1 1
1
,
m ki ji ik c d d ju
k i
¦
[14]where k is an integer in the range [1,c] and i is an integer in the range [1,n].
and possibilistic membership 'ݐ' is defined as:
[15]
where 1≤k≤c and cluster center 'ݒ' is defined as:
1 1 n m ki ki i i n k m ki ki iau
bt
x
v
au
bt
K K¦
¦
[16]This algorithm outperforms PCM and FCM but fails to give desired results when clusters are highly unequal sized and when outliers are present.
2.5.Type-2 Fuzzy C-Means (T2FCM) [14]
Rhee and Hwang proposed this new algorithm by introducing the concept of type-2 fuzzy sets. The idea behind the design of this algorithm is that all data points should not have same contribution in computing the cluster centers, instead the data points with higher memership value should dominate the cluster center computation. Type-2 membership is computed via following equation:
1 2 ik ik ik
u
a
u
[17] where ݑ and ܽ are the Type-1 and Type-2 fuzzy membership respectively. ܽ is used for cluster centers computation in T2FCM other computations are same as conventional FCM. Following equation is used for updating cluster centers 'ݒ': 1 1 n m ik i i n k m ik ia x
v
a
¦
¦
[18]Cluster centers computed using ܽ are more appropriate than the one computed using ݑ. T2FCM has been proven to be effective for spherical stuctured datasets, but it fails when the input dataset is of non-spherical and complex structures.
2.6.Kernelized Type-2 Fuzzy C-Means (KT2FCM) [15]
Prabhjot Kaur, I.M.S Lambh and Anjana Gosain proposed KT2FCM by exploiting Hyper Tangent kernel function in reckoning the distance among data points and cluster centers. Hyper Tangent Kernel function is:
2 2 2 , 1 tanh K x y
x
y
V
§ · ¨ ¸ ¨ ¸ ¨ ¸ © ¹ [19]Objective function is:
1 1 1 2 1 ki ki
t
b
d
K§
¨
·
¸
b
©
¹
2 2 1 1 2 c n m KT FCM ik i k k i
J
¦¦
a
I
x
I
v
[20]where ܽ is Type-2 membership.
and ԡ˗ሺݔሻ െ ˗ሺݒሻԡ is the distance between ˗ሺ୧ሻ and ˗ሺݔሻ.
2
. k i k i k i
x
v
Ix
Iv
Ix
Iv
I
I
x
k .x
k 2x
kv
iv
i .v
i I I I I I I ൌKx x
k, k2Kx v
k, i Kv v
i, i ሾʹͳሿIn KT2FCM, ܭሺݔǡ ݒሻ is calculated using Hyper Tangent Kernel function from eq no. 21 and σ is defined as kernel
width and it is a positive number, then ܭሺݔǡ ݔሻ ൌ ͳ. Thus, eq no. 20 can be written as:
2 1 1 2 1 , c n m KT FCM ik k i i k KJ
¦¦
a
x v
[22]minimizing under the condition:
1 1 c ik k i
u
¦
thus, 1 1 1 2 tanh 2 1 1 1 2 1 tanh 2 m x y m c x y i ika
V V § · ¨ ¸ ¨ ¸ ¨ ¸ © ¹ § · ¨ ¸ ¨ ¸ ¨ ¸ © ¹ § · ¨ ¸ ¨ ¸ ¨ ¸ ¨ ¸ ¨ ¸ © ¹ § · ¨ ¸ ¨ ¸ ¨ ¸ ¨ ¸ ¨ ¸ © ¹¦
[23] 2 2 1 2 2 1 , 1 tanh , 1 tanh n m ik k i k k i n m ik k i k K Kx y
a
x v
x
v
x y
a
x v
V
V
§ § ·· ¨ ¨ ¸¸ ¨ ¨ ¸¸ ¨ ¸ ¨ © ¹¸ © ¹ § § ·· ¨ ¨ ¸¸ ¨ ¨ ¸¸ ¨ ¸ ¨ © ¹¸ © ¹¦
¦
[24]2.7.Intuitionistic Fuzzy C-Means (IFCM) [19]
Intuitionistic fuzzy c-means [10] function contains two terms: (i) modified objective function of conventional FCM using Intuitionistic fuzzy set and (ii) intuitionistic fuzzy entropy (IFE). IFCM minimizes the objective function as: IFCM minimizes the objective function as:
* * * 2 1 1 1 1 i c n c m IFCM ik ik i i k i
J
¦¦
u d
¦
K
e
K
[25]with m=2, ݑכ= uik + ηik , where uik* (uik) denotes the intuitionistic fuzzy membership of the kth data in ith class. ηik is hesitation degree, which is defined as:
1/
1
(1
)
,
0
ik ik ikn
u
u
D DD
!
and * 1 1,
n i N ik kK
¦
K
k belongs to [1,N]At each iteration, the cluster center and membership matrix are updated and the algorithm stops when the updated membership and the previous membership.
2.8.Kernel Fuzzy C-Means with new distance metric (KFCM-σ)
Conventional IFCM and FCM-σ can only deal with linearly separable data points in observation space. The observed data-set can be transformed to higher dimensional feature space by applying a non-linear mapping function to achieve nonlinear separation. KFCM-σ incorporates a new distance measure into the mapped feature space. New distance metric is defined as:
2 2 2 kc kc i i k i d d x v V V
I
I
I
I
I
I
c [26]where ʣఙ is the weighted mean distance of cluster 'i' in the mapped featue space and is given by:
2 1/ 2 1 1
.
kc i n m ki d k n m ki ku
u
VI
I
½
°
°
°
°
®
¾
°
°
°
°
¯
¿
¦
¦
[27]and objective function is:
2 1 1 c n m KFCM ik k i i k J V
¦¦
uI
xI
v [28]2.9.Robust Intuitionistic Fuzzy C-Means (IFCM-σ) [17]
Prabhjot Kaur, A. K. Soni, and A. Gosain proposed this algorithm by incorporating a different distance metric from IFCM to regularize the distance variation in each cluster. Hence, improved clustering performance for non-spherically separable data where IFCM failed. Objective function is:
1 2 1 1 1
.
i c n c m KFCM ik ki i i k iJ
V¦¦
u
d
c
¦
S
e
S [29] where 2 2 k i ki i x v dV
c and ߪ is the weighted mean distance of cluster i.
2.10.Kernel version of Intuitionistic Fuzzy C-Means (KIFCM) [9]
This algorithm works by exploiting Radial Basis kernel function for calculating the distance between the cluster centroid and data points. Hence improved the accuracy of IFCM. Objective function is:
2 1 1 1 1 i c n c m KFCM ik k i i i k i J
¦¦
uI
xI
v¦
S
eS [30] 2.11.Noise Clustering [20, 21]Dave proposed a robust clustering algorithm named Noise clustering. It took into the consideration the major problem of FCM by minimising the following objective function:
1 2 1 1
,
c N m ki ki k iJ U V
u
d
¦¦
[31]where out of 'c+1' clusters one is noise cluster and 'c' are good clusters and ሺ݀ሻଶ = 2 for k = n= c+1. NC
outperforms PCM, FCM and PFCM. But it emphasises on reducing the influence of outliers on the cluster computation rather than nullifying the outliers.
2.12.Credibilistic Fuzzy C-Means (CFCM)
Krishna K. Chintalapudi proposed CFCM algorithm by introducing a new variable, named credibility, which is defined as: 1.. (1 ) max ( )
1
k, 0
1
j n j k T D D\
d d
T
[31] where 1..min(
)
k i cd
ikD
, this is distance of point ݔ from it's closest centroid 'j'.Noisiest point 'ݔ' gets its credibility value equal to Ф. and Ф is a parameter that controls the minimum value of
ߖ. CFCM performs clustering by minimizing the following objective function:
2 ( , ) 1 1 c n m CFCM U V ki ki k i
J
¦¦
u d
[32]Subject to the constraint:
1
,
1...
c ik k iu
\
k
n
¦
CFCM lessen the effect of outliers on cluster computation. Thus, it is observed that it improves centroid computation but still doesn't provide the accurate centroids and assigns some outlier points to more than one cluster[5].
2.13.Density Oriented Fuzzy C-Means (DOFCM) [24, 25]
Prabhjot Kaur and Anjana Gosain proposed DOFCM by defining a density factor, neighborhood membership, which measures the density of an object in a given dataset considering its neighborhood. For an object 'i' in dataset 'X', neighborhood membership is defined as:
max i neighborhood i neighborhood
M
X
K
K
[33]where,
K
neighborhoodi = count of points in the neighborhood of point i andK
max imax1...nK
neighborhoodi , i is any point in dataset X.Any point 'p' is said to be in neighborhood of point 'i' if it satifies following condition:
,
|
( , )
neighborhoodp
X i
X dist p i
d
r
where dist(p, i) is Euclidean distance between points 'p' and 'i'; and ݎௗ is the radius of neighborhood.
Outliers are identified by setting a threshold value 'α' for the neighborhood membership. If
M
neighborhoodj( )
X
valueof a point 'j' is less than α than 'j' is an outlier, otherwise not.
This way DOFCM identifies outliers and by assigning zero fuzzy membership to those points performs clustering using FCM algorithm.
3.Dataset Used
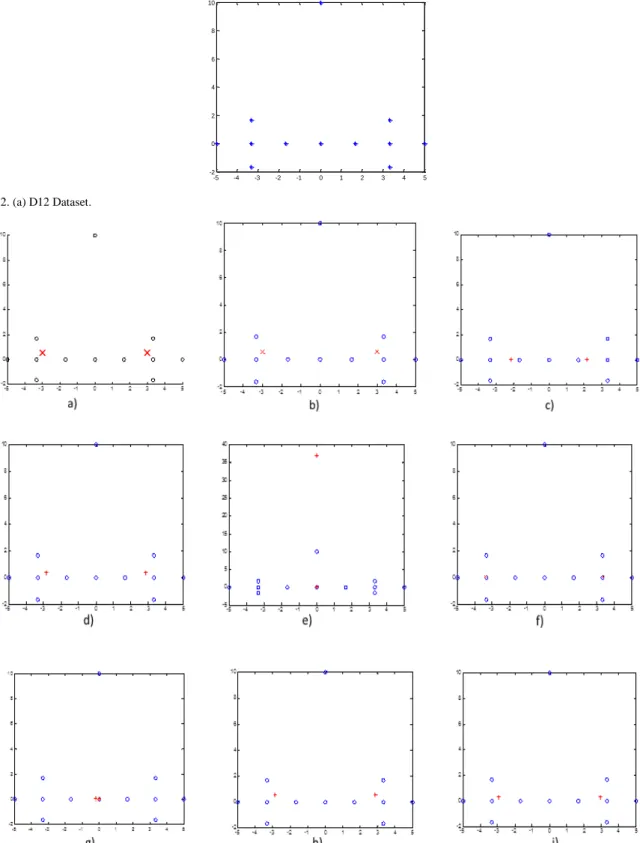
In this section we are discussing about a standard data set that is used in our experimental analysis. That is shown in Fig. 2(a) , it consists of 10 data points, one noise point and one outlier [39].
Fig. 2. (a) D12 Dataset. -5 -4 -3 -2 -1 0 1 2 3 4 5 -2 0 2 4 6 8 10
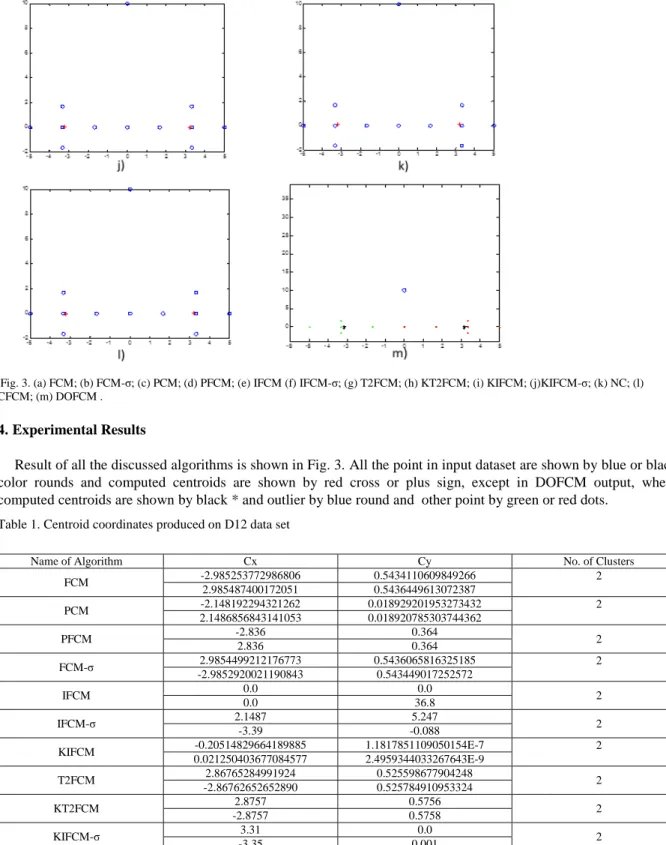
Fig. 3. (a) FCM; (b) FCM-σ; (c) PCM; (d) PFCM; (e) IFCM (f) IFCM-σ; (g) T2FCM; (h) KT2FCM; (i) KIFCM; (j)KIFCM-σ; (k) NC; (l) CFCM; (m) DOFCM .
4.Experimental Results
Result of all the discussed algorithms is shown in Fig. 3. All the point in input dataset are shown by blue or black color rounds and computed centroids are shown by red cross or plus sign, except in DOFCM output, where computed centroids are shown by black * and outlier by blue round and other point by green or red dots.
Table 1. Centroid coordinates produced on D12 data set
Name of Algorithm Cx Cy No. of Clusters
FCM -2.985253772986806 0.5434110609849266 2 2.985487400172051 0.5436449613072387 PCM -2.148192294321262 0.018929201953273432 2 2.1486856843141053 0.018920785303744362 PFCM -2.836 0.364 2 2.836 0.364 FCM-σ 2.9854499212176773 0.5436065816325185 2 -2.9852920021190843 0.543449017252572 IFCM 0.0 0.0 2 0.0 36.8 IFCM-σ 2.1487 5.247 2 -3.39 -0.088 KIFCM -0.20514829664189885 1.1817851109050154E-7 2 0.021250403677084577 2.4959344033267643E-9 T2FCM 2.86765284991924 0.525598677904248 2 -2.86762652652890 0.525784910953324 KT2FCM 2.8757 0.5756 2 -2.8757 0.5758 KIFCM-σ 3.31 0.0 2 -3.35 0.001 CFCM -3.219676117514328 2.733094769802608E-9 2 3.2196794691751194 -2.0703916044325292E-10
NC -3.194 0.099 2
3.193 0.099
DOFCM -3.1674776298251195 -1.7719838377515058E-8 2 3.167200252455762 1.638450898897021E-8
5.Conclusion
In this review paper, as we experimentally analysed all major fuzzy clustering algorithms on a standard data sets (D12) in presence of noise and outliers. It has been observed that PCM and PFCM improves performance of FCM in presence of noise but not significantly; T2FCM and KT2FCM significantly improves clustering results over FCM, PCM, PFCM and KT2FCM is even more robust than T2FCM in presence of noise; IFCM-σ significantly improve centroid position over FCM and IFCM; NC and CFCM turned out to be most robust algorithms in presence of noise and outliers as suppressed the effect of outliers. DOFCM worked best with to exactly identify outliers first and then give best centroids compared to all other algorithms. As a future work, we will try to come up with a better proposal to overcome the existing problems.
References
1.Han, Jiawei, Micheline Kamber, and Jian Pei. Data mining, southeast asia edition: Concepts and techniques. Morgan kaufmann, 2006. 2.Wu, Xindong, Vipin Kumar, J. Ross Quinlan, Joydeep Ghosh, Qiang Yang, Hiroshi Motoda, Geoffrey J. McLachlan et al. "Top 10 algorithms
in data mining." Knowledge and Information Systems 14, no. 1 (2008).
3.Kesavaraj, G., and S. Sukumaran. "A study on classification techniques in data mining." In 2013 Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), pp. 1-7. IEEE, 2013.
4.Jain, Anil K., M. Narasimha Murty, and Patrick J. Flynn. "Data clustering: a review." ACM computing surveys (CSUR) 31, no. 3 (1999): 264-323.
5.Kaur, Prabhjot, A. K. Soni, and Anjana Gosain. "Robust kernelized approach to clustering by incorporating new distance measure."
Engineering Applications of Artificial Intelligence 26, no. 2 (2013): 833-847.
6.J.C. Bezdek (1981), “Pattern Recognition with Fuzzy Objective Function Algorithm”, Plenum, NY.
7.Law, Martin HC, Mario AT Figueiredo, and Anil K. Jain. "Simultaneous feature selection and clustering using mixture models." Pattern Analysis and Machine Intelligence, IEEE Transactions on 26, no. 9 (2004): 1154-1166.
8.Patel, Bhaskar N., Satish G. Prajapati, and Kamaljit I. Lakhtaria. "Efficient Classification of Data Using Decision Tree." Bonfring International Journal of Data Mining 2, no. 1 (2012): 06-12.
9.Kaur, Prabhjot, A. K. Soni, and Anjana Gosain. "Robust Intuitionistic Fuzzy C-means clustering for linearly and nonlinearly separable data." In Image Information Processing (ICIIP), 2011 International Conference on, pp. 1-6. IEEE, 2011.
10. J.C. Bezdek (1981), “Pattern Recognition with Fuzzy Objective Function Algorithm”, Plenum, NY.
11. Zhang, Dao-Qiang, and Song-Can Chen. "Clustering incomplete data using kernel-based fuzzy c-means algorithm." Neural Processing Letters 18, no. 3 (2003): 155-162.
12. R. Krishnapuram and J. Keller (1993), "A Possibilistic Approach to Clustering", IEEE Trans. on Fuzzy Systems, vol .1. No. 2, pp.98-1 10. 13. Pal N.R., K. Pal, J. Keller and J. C. Bezdek ," A Possibilistic Fuzzy c- Means Clustering Algorithm", IEEE Trans. on Fuzzy Systems, vol 13 (4),pp 517-530,2005.
14. Rhee, Frank Chung Hoon, and Cheul Hwang. "A type-2 fuzzy C-means clustering algorithm." In IFSA World Congress and 20th NAFIPS International Conference, 2001. Joint 9th, vol. 4, pp. 1926-1929. IEEE, 2001.
15. Kaur, Prabhjot, I. M. S. Lamba, and A. Gosain. "Kernelized type-2 fuzzy c-means clustering algorithm in segmentation of noisy medical images." In Recent Advances in Intelligent Computational Systems (RAICS), 2011 IEEE, pp. 493-498. IEEE, 2011.
16.Tsai, Du-Ming, and Chung-Chan Lin. "Fuzzy C-means based clustering for linearly and nonlinearly separable data." Pattern recognition 44, no. 8 (2011): 1750-1760.
17. Kaur, P. R. A. B. H. J. O. T., A. K. Soni, and A. Gosain. "Novel intutionistic fuzzy c means clustering for linearly and non linearly separable data." WSEAS Trans Comput 11 (2012): 65-76.
18. Chaira, Tamalika. "A novel intuitionistic fuzzy C means clustering algorithm and its application to medical images." Applied Soft Computing 11, no. 2 (2011): 1711-1717.
19. Dave, Rajesh N. "Robust fuzzy clustering algorithms." In Fuzzy Systems, 1993., Second IEEE International Conference on, pp. 1281-1286. IEEE, 1993.
20. Dave, Rajesh N. "Characterization and detection of noise in clustering." Pattern Recognition Letters 12, no. 11 (1991): 657-664.
21. Chatzis, Sotirios P. "A fuzzy c-means-type algorithm for clustering of data with mixed numeric and categorical attributes employing a probabilistic dissimilarity functional." Expert Systems with Applications 38, no. 7 (2011): 8684-8689.
22. Li, Dan, Hong Gu, and Liyong Zhang. "A fuzzy c-means clustering algorithm based on nearest-neighbor intervals for incomplete data." Expert Systems with Applications 37, no. 10 (2010): 6942-6947.
23. Kaur, Prabhjot. "DFCM: Density based approach to identify Outliers and to get efficient clusters in Fuzzy Clustering." In Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology-Volume 01, pp. 906-909. IEEE Computer Society, 2008.
24.Kaur, Prabhjot, and Anjana Gosain. "Density-oriented approach to identify outliers and get noiseless clusters in Fuzzy C-Means." In FUZZ-IEEE, pp. 1-8. 2010.
25.Tasdemir, Kadim, and Erzsébet Merényi. "A validity index for prototype-based clustering of data sets with complex cluster structures." Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on 41, no. 4 (2011): 1039-1053.
26. Kaur, Prabhjot, and Anjana Gosain. "Improving the performance of fuzzy clustering algorithms through outlier identification." In Fuzzy Systems, 2009. FUZZ-IEEE 2009. IEEE International Conference on, pp. 373-378. IEEE, 2009.
27. Kaur, Prabhjot, A. K. Soni, and Anjana Gosain. "Robust kernelized approach to clustering by incorporating new distance measure." Engineering Applications of Artificial Intelligence 26, no. 2 (2013): 833-847.
28. Zhang, Hong-mei, Ze-shui Xu, and Qi Chen. "On clustering approach to intuitionistic fuzzy sets." Control and Decision 22, no. 8 (2007): 882.
29. T. Chaira, “A novel intuitionistic fuzzy c means clustering algorithm and its application to medical images”, Applied Soft computing 11(2011) 1711-1717.
30. D. Q. Zhang and S. C. Chen, “Clustering incomplete data using kernel based fuzzy c means algorithm”, Neural Processing Letters 18(2003) 155-162.
31. Hawkins, Douglas M. Identification of outliers. Vol. 11. London: Chapman and Hall, 1980.
32. Fawcett, Tom, and Foster Provost. "Adaptive fraud detection." Data mining and knowledge discovery 1, no. 3 (1997): 291-316.
33. Tushir, Meena, and Smriti Srivastava. "A new kernel based hybrid c-means clustering model." In Fuzzy Systems Conference, 2007. FUZZ-IEEE 2007. FUZZ-IEEE International, pp. 1-5. IEEE, 2007.
34. Ester, Martin, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. "A density-based algorithm for discovering clusters in large spatial databases with noise." In Kdd, vol. 96, no. 34, pp. 226-231. 1996.
35. R.N. Dave (1991), “Characterization and Noise in Clustering”, Pattern Rec. Letters, vol. 12(11), pp 657-664.
36. F.C.H. Rhee, C. Hwang, A Type-2 fuzzy c means clustering algorithm, in: Proc. in Joint 9th IFSA World Congress and 20th NAFIPS International Conference 4, 2001, pp. 1926–1929.
37. M. N. Ahmed, S. M. Yamany, N. Mohamed, A. A. Farag, and T. Moriarty(2002), ‘‘A modified fuzzy c-means algorithm for bias field estimation and segmentation of MRI data,’’ IEEE Trans. Med. Imag., vol. 21, no. 3, pp. 193--199, Mar. 2002.
38. D. Q. Zhang and S. C. Chen, “Clustering incomplete data using kernel based fuzzy c-means algorithm”, Neural Processing Letters 18(2003) 155-162.