A Survey Based on Secure and Efficient Task
Scheduling Technique For Cloud Computing
Bharath B S, Manjesh B N
Abstract—over the past few years the concepts of Task Scheduling Scheme for cloud have been considered as a very much promising fields. Cloud environment be the pattern of computing in which on demand extensible and frequently imaginary resources are provided as service through online network. It consist of huge amount of resources, the cloud consumer can use those resources based on SLA (Service Level Agreement) between consumer and cloud vendor. Resource scheduling in cloud environment is NP-hard problem. Since many years many researchers have been proposed various techniques for task scheduling in the field of cloud computing. This study focuses on efficient scheduling algorithms and resource scheduling based on SLA and demerits related in cloud computing. In this project work, it introduces an algorithm which considered Preempt able task execution and multiple SLA parameters such as memory, network bandwidth, and required CPU time. An obtained experimental results show that in a situation where resource contention is fierce our algorithm provides better utilization of resources. Here in this paper we have presented various task scheduling techniques and their efficiency.
Keywords: Cloud Computing, Task Scheduling Scheme,, Virtual Machine , Software as a Service(SaaS).
I. INTRODUCTION
Cloud computing is a new paradigm for distributed computing that delivers infrastructure, platform, and software (application) as services. These services are made available as subscription-based services in a pay-as-you-go model to consumers. Cloud computing helps user applications dynamically provision as many compute resources at specified locations (currently US east1a-d for Amazon1) as and when required. Also, applications can choose the storage locations to host their data (Amazon S32) at global locations. In order to efficiently and cost effectively schedule the tasks and data of
Manuscript received May, 2015,.
Bharath B S, Department of computer science and Engg. Akshya Institute of Technology Tumkur, India E-Mail: [email protected]
Manjesh B N, Department of computer science and Engg. Akshya Institute of Technology Tumkur, India
an entity (an autonomic system or component) into a real scalar value. Utility functions have very attractive theoretical properties, but their use in practical autonomic computing systems is just beginning to be explored. The major contribution of this paper is to show how utility functions expressed in high-level business terms, or service-level attributes, can be used to dynamically allocate resources in a realistic autonomic computing system. Typically, the state can be described as a vector of attributes, each of which is either measured directly by or synthesized from sensor measurements. The value may be expressed in any suitable unit, with monetary units being the most typical. The utility function might be specified by a human administrator, derived from a contract, or derived from another utility function [4]. In this paper we see that in the area of advance efficient scheduling data scheme in the field of cloud computing.
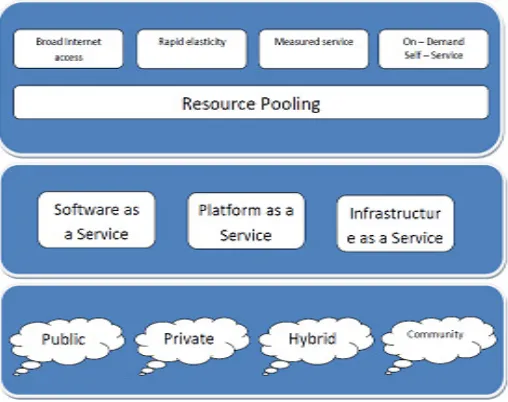
II ANALYSIS OF TASK SCHEDULING TECHNIQUES Job-scheduling algorithms are developed to accomplish several goals like expected outcome, efficient use of resources, low make span, high throughput, better quality of service, maintaining efficiency. In job scheduling algorithms, priority of jobs is a challenging issue because some jobs need to be serviced first than those other jobs which can stay for a long time. Suitable job scheduling algorithm must consider the priority of a job [1]. In Fig 1, Cloud computing architecture is presented. Cloud services are divided into three types namely, Infrastructure as a Service (IaaS), Platform as a Service (PaaS) and Software as a Service (SaaS) respectively. Fig 1 shows the essential characteristics of cloud computing such as resource pooling, broad network access, elasticity, on-demand services, physical cloud resources (System Level) and middleware capabilities form the basis provider of delivering IaaS and PaaS in the form of a collection of transparently data centres and runtime environment and composition tools which ease the creation, deployment and execution process of application in the cloud. Finally, to provide the above mentioned services, deployment models such as Public Cloud, Private Cloud, Hybrid Cloud and Community Cloud are used by the cloud providers. The infrastructure of the cloud is provided publicly to all the general public by the organization in public cloud. Anyone can access services from anywhere publicly. Where, private cloud is used for a single organization only. Community Cloud is formed by several organizations and supports a specific community that has shared concerns for their future use. It might be managed by the any one of the shared organization or a third party organization. Last type is Hybrid Cloud, is a cloud formed by the composition of two or more clouds that is private, community, or public. Hybrid computing is bound together by standardized technology which enables data and application portability.
Fig. 1. Cloud Architecture
Job Scheduling is used to allocate certain jobs to particular resources in particular time. In cloud computing, job- scheduling problem is a biggest and challenging issue. Hence the job scheduler should be dynamic. Job scheduling in cloud computing is mainly focuses to improve the efficient utilization of resource that is bandwidth, memory and reduction in completion time. An efficient job scheduling strategy must aim to yield less response time so that the execution of submitted jobs takes place within a possible minimum time and there will be an occurrence of in-time where resources are reallocated. Because of this, less rejection of jobs takes place and more number of jobs can be submitted to the cloud by the clients which ultimately show increasing results in accelerating the business performance of the cloud. There are different types of scheduling based on different criteria, such as static vs. Dynamic, centralized vs. Distributed, offline vs. Online etc are defined below
o Static Scheduling: Pre-Schedule jobs, all information are
known about available resources and tasks and a task is assigned once to a resource, so it’s easier to adapt based on scheduler’s perspective
o Dynamic Scheduling: Jobs are dynamically available for
scheduling over time by the scheduler. It is more flexible than static scheduling, to be able of determining run time in advance. It is more critical to include load balance as a main factor to obtain stable, accurate and efficient scheduler algorithm
o Centralized Scheduling: As mentioned in dynamic
scheduling, it’s a responsibility of centralized / distributed scheduler to make global decision. The main benefits of centralized scheduling are ease of implementation; efficiency and more control and monitoring on resources. On the other hand; such scheduler lacks scalability, fault tolerance and efficient performance. Because of this disadvantage it’s not recommended for large-scale grids
o Distributed / Decentralized Scheduling: This type of
There is no central control entity, so local schedulers’ requests to manage and maintain state of jobs’ queue.
o Pre-Emptive Scheduling: This type of scheduling allows
each job to be interrupted during execution and a job can be migrated to another resource leaving its originally allocated resource, available for other jobs. If constraints such as priority are considered, this type of scheduling is more helpful.
o Non Pre-Emptive Scheduling: It is a scheduling process,
in which resources are not being allowed to be re-allocated until the running and scheduled job finished its execution.
o Co-operative scheduling: In this type of scheduling,
system have already many schedulers, each one is responsible for performing certain activity in scheduling process towards common system wide range based on the cooperation of procedures, given rules and current system users.
o Immediate / Online Mode: In this type of scheduling,
scheduler schedules any recently arriving job as soon as it arrives with no waiting for next time interval on available resources at that moment.
o Batch / Offline Mode: The scheduler stores arriving jobs
as group of problems to be solved over successive time intervals, so that it is better to map a job for suitable resources depending on its characteristics.
III VARIOUS JOB SCHEDULING TECHNIQUES IN CLOUD
• Dynamic task scheduling in grid computing using prioritized round robin algorithm:-a novel grid scheduling heuristic that adaptively and dynamically schedules task without requiring any prior information on the workload of incoming tasks. This models the grid system in the form of a state – transition diagram with job replication to optimally schedule jobs. This algorithm uses prediction information on processor utilization. In this algorithm they uses concept of job replication that is, a job can be replicated to other resource if that resource completes execution of current job than the resource it is currently allocated. This algorithm uses two types of queue namely, Waiting Queue and Execution Queue. This approach is based on exploiting information on processing capability of individual grid resources and applying replication on tasks assigned to the slowest processors. The approach facilitates replication of tasks, and also assigned to execute on slower machines, on machines with higher processing capacity. In this approach the communication cost are ignored. Experimental results show the better performance of this approach compared to traditional round robin algorithm.
• Priority based Job Scheduling Algorithm in Cloud Computing:-This algorithm considers the priority of jobs for scheduling and named as priority based job scheduling algorithm. It is based on multiple criteria decision making model. A pairwise comparison based
on multiple criteria and multiple attributes method was first developed by Thomas Saaty in 1980 and named as Analytical Hierarchy Process (AHP). Consistent Comparison Matrix is the foundation of AHP, so to use the concept of AHP comparison matrices are computed according to the attributes and criteria’s accessibilities. In this algorithm, each job requests a resource with determined priority. So comparison matrices of each jobs according to resources accessibilities is computed and also comparison matrix of resources is computed. For each of the comparison matrices priority vectors (vector of weights) are computed and finally a normal matrix of all jobs is computed named as ∆. Likewise, normal matrix of all resources is also computed and name of that matrix is γ. The next step of the algorithm is to compute Priority Vector of S (PVS), where S is set of jobs. PVS is calculated by multiplying matrix ∆ with matrix γ. The final step of the algorithm is to choose the job with maximum calculated priority, so a suitable resource is allocated to that job. The list of jobs is updated and the scheduling process continues till all the jobs are scheduled to suitable resource. Experimental results indicate that the algorithm has reasonable complexity. Also there are several issues related to this algorithm such as complexity, consistency and finish time.
• A new Class of Priority-based Weighted Fair Scheduling Algorithm:- It is based on strict rob priority class which adds an absolute priority queue based on the foundation of based class weighted fair scheduling algorithm (CBWFQ). This algorithm covers the disadvantage of traditional weighted fair scheduling algorithm. Weighted Fair Scheduling algorithm differentiates the services of all active queues on the basis of weight of each business flow. When a new job arrives the classifier classifies the jobs into categories. Then buffer is checked for each category and if buffer is not overloaded then job is stored in the buffer otherwise job is dropped. Each job enters a different virtual queue. Weight, Dispatch, Discard and Rob are four main rules of this algorithm. The main advantage of this algorithm is that it has introduced the rob rule together with dropping rule. Experiments are done on NS-2 software to simulate SRPQ-CBWFQ algorithm. This new algorithm combined buffer management and queue scheduling and only guarantees low delay of real time applications. It also gave consideration to fairness and better utilization of buffers
IV. PRIOR STUDY
for a substantial amount of time until the connection would be eventually established. Roy and Chuah introduced storage nodes in DTNs where data is stored or replicated such that only authorized mobile nodes can access the necessary information quickly and efficiently. Many military applications require increased protection of confidential data including access control methods that are cryptographically enforced. In many cases, it is desirable to provide differentiated access services such that data access policies are defined over user attributes or roles, which are managed by the key authorities. For example, in a disruption-tolerant military network, a commander may store a confidential information at a storage node, which should be accessed by members of “Battalion 1” who are participating in “Region 2.” In this case, it is a reasonable assumption that multiple key authorities are likely to manage their own dynamic attributes for soldiers in their deployed regions or echelons, which could be frequently changed (e.g., the attribute representing current location of moving soldiers). We refer to this DTN architecture where multiple authorities issue and manage their own attribute keys independently as a decentralized DTN.
[
1] S. Pandey, L. Wu, S. M. Guru, and R. Buyya, “A particle swarm optimization-based heuristic for scheduling workflow applications in cloud computing environments,” in AINA ’10: Proceedings of the 2010, 24th IEEE International Conference on Advanced Information Networking and Applications, pages 400– 407, Washington, DC, USA, 2010, IEEE Computer Society. [2] M. Salehi and R. Buyya, “Adapting market-oriented scheduling policies for cloud computing,” In Algorithms and Architectures for Parallel Processing, volume 6081 of Lecture Notes in Computer Science, pages 351–362. Springer Berlin / Heidelberg, 2010[3] M. Qiu and E. Sha, “Cost minimization while satisfying hard/soft timing constraints for heterogeneous embedded systems,” ACM Transactions on Design Automation of Electronic Systems (TODAES), vol. 14, no. 2, pp. 1–30, 2009.
[4] W. E. Walsh, G. Tesauro, J. O. Kephart, and R. Das, “Utility Functions in Autonomic Systems,” in ICAC ’04: Proceedings of the First International Conference on Autonomic Computing. IEEE Computer Society, pp. 70–77, 2004.
[5] Yazir Y.O., Matthews C., Farahbod R., Neville S., Guitouni A., Ganti S., Coady Y., “Dynamic resource allocation based on distributed multiple criteria decisions in computing cloud,” in 3rd International Conference on Cloud Computing, Aug. 2010, pp. 91-98.[6] V. Cardellini, M. Colajanni, P. S. Yu,“Dynamic Load Balancing on Web-Server Systems”, IEEE Internet Computing, Vol. 33, May-June 1999, pp. 28 -39.
[7] V. C. Emeakaroha, I. Brandic, M. Maurer, and S. Dustdar, “Low leve l metrics to high level SLAs - LoM2HiS framework: Bridging the gap between monitored metrics and SLA parameters in cloud environments,” In High Performance Computing and Simulation Conference, pages 48 – 55, Caen, France, 2010 [8] Vincent C. Emeakarohaa, Marco A.S. Netto b, Rodrigo N. Calheiros c, Ivona Brandic a, Rajkumar Buyyac, César A.F. De Rose , “Towards autonomic detection of SLA violations in Cloud
infrastructures”, V.C. Emeakaroha et al. / Future Generation Computer Systems, 2010
[9] V. C. Emeakaroha, I. Brandic, M. Maurer, and S. Dustdar, “Low leve l metrics to high level SLAs - LoM2HiS framework: Bridging the gap between monitored metrics and SLA parameters in cloud environments,” In High Performance Computing and Simulation Conference, pages 48 – 55, Caen, France, 2010. [10] T. Hagras and J. Janecek, “A high performance, low complexity algorithm for compile-time task scheduling in heterogeneous systems,” Parallel Computing, vol. 31, no. 7, pp. 653–670, 2005.
[11] Chandrashekhar S. Pawar, Rajnikant B. Wagh, “Priority Based Dynamic Resource Allocation in Cloud Computing with Modified Waiting Queue”, International Conference on Intelligent Systems and Signal Processing (ISSP), 2013
V RESEARCH ISSUES
In the literature, many researches tried to solve the problem of job scheduling in cloud computing using artificial intelligence techniques such as genetic algorithm and ant colony. Unfortunately, the proposed techniques have some problems. Neural Networks designed to mimic the way that the human brain executes a specific task or function. Its most important feature is the adaptive nature, where “learning by example” is used to solve complex or ambiguous systems problems, pattern classification and recognition. ANNs are trained using different learning rates, parameters and propagation methods. It learn by changing the connections between the input and output layers. Networks performance is affected by number of layers, number of nodes and training algorithms. ANNs are trained by iterating the recombination, mutation and fitness selection until developing chromosomes with accurate ANN. After neural network has been trained in certain information collection, it can be used to predict new situation. The suitable output is generated at the output layer at the end of the learning or training process. Better results can be achieved by using neural network architecture with proper selection of input variable and training set. Neural networks are widely used for identifications, classification, and prediction when a vast amount of information is available. By examining hundreds, neural network detects important relationships and patterns in information. The advantages of using neural networks are: learn and adjust to new cases on their own, lend them to massive parallel processing, function without complete or well-structured information and cope with huge volume of information with many dependant variables. Finally, neural network can learn to classify new input instantly that has not been seen before while the genetic algorithm finds acceptable solution within the solution space. Thus, the job scheduling result would be optimized using neural network by finding new set of classifications based on the provided tasks. Therefore, solving and optimizing the scheduling problems in cloud computing environment can be achieved using artificial neural networks.
In this survey paper we have described, some new Scheme based on secure and efficient task scheduling techniques for cloud computing which are proposed and demonstrated. As compared to the conventional scheme the proposed scheme handles how monitoring of data is carried out by preserving privacy of data. The objective of the scheduling methods in scattered computing is to distribute the workload on to the processors and increasing their consumption while decreasing the overall job execution time Job scheduling. The scheduling algorithms can be classified into two categories: 1) Stable scheduling technique and 2) Unstable scheduling technique. The pair of these techniques having their own merits and limitations. Compare with the stable scheduling technique, unstable scheduling achieves efficient performance. Dynamic scheduling handles unidentified dependencies at compile time. This work much suits for describing various techniques and various algorithms which have been proposed by many researchers since many years
VII. REFERENCES
[1] S. Pandey, L. Wu, S. M. Guru, and R. Buyya, “A particle swarm optimization-based heuristic for scheduling workflow applications in cloud computing environments,” in AINA ’10: Proceedings of the 2010, 24th IEEE International Conference on Advanced Information Networking and Applications, pages 400– 407, Washington, DC, USA, 2010, IEEE Computer Society. [2] M. Salehi and R. Buyya, “Adapting market-oriented scheduling policies for cloud computing,” In Algorithms and Architectures for Parallel Processing, volume 6081 of Lecture Notes in Computer Science, pages 351–362. Springer Berlin / Heidelberg, 2010
[3] M. Qiu and E. Sha, “Cost minimization while satisfying hard/soft timing constraints for heterogeneous embedded systems,” ACM Transactions on Design Automation of Electronic Systems (TODAES), vol. 14, no. 2, pp. 1–30, 2009.
[4] W. E. Walsh, G. Tesauro, J. O. Kephart, and R. Das, “Utility Functions in Autonomic Systems,” in ICAC ’04: Proceedings of the First International Conference on Autonomic Computing. IEEE Computer Society, pp. 70–77, 2004.
[5] Yazir Y.O., Matthews C., Farahbod R., Neville S., Guitouni A., Ganti S., Coady Y., “Dynamic resource allocation based on distributed multiple criteria decisions in computing cloud,” in 3rd International Conference on Cloud Computing, Aug. 2010, pp. 91-98.
[6] V. Cardellini, M. Colajanni, P. S. Yu,“Dynamic Load Balancing on Web-Server Systems”, IEEE Internet Computing, Vol. 33, May-June 1999, pp. 28 -39.
[7] V. C. Emeakaroha, I. Brandic, M. Maurer, and S. Dustdar, “Low leve l metrics to high level SLAs - LoM2HiS framework: Bridging the gap between monitored metrics and SLA parameters in cloud environments,” In High Performance Computing and Simulation Conference, pages 48 – 55, Caen, France, 2010
[8] Vincent C. Emeakarohaa, Marco A.S. Netto b, Rodrigo N. Calheiros c, Ivona Brandic a, Rajkumar Buyyac, César A.F. De Rose , “Towards autonomic detection of SLA violations in Cloud infrastructures”, V.C. Emeakaroha et al. / Future Generation Computer Systems, 2010
[9] V. C. Emeakaroha, I. Brandic, M. Maurer, and S. Dustdar, “Low leve l metrics to high level SLAs - LoM2HiS framework: Bridging the gap between monitored metrics and SLA parameters in cloud environments,” In High Performance Computing and Simulation Conference, pages 48 – 55, Caen, France, 2010. [10] T. Hagras and J. Janecek, “A high performance, low complexity algorithm for compile-time task scheduling in heterogeneous systems,” Parallel Computing, vol. 31, no. 7, pp. 653–670, 2005.