Available at http://www.JofCI.org
1553-9105/ Copyright © 2010 Binary Information Press January, 2010
Automatic Classification of Deep Web Databases
Based on Centroid and WordNet
Wanli ZUO1,2,†, Ying WANG1,2, Xin WANG3, Dandan ZHANG1,2, Tao PENG1,2 1College of Computer Science and Technology, Jilin University, Changchun 130012, China
2Key Laboratory of Computation and Knowledge Engineering, Ministry of Education 3College of Software, Changchun institute of technology, Changchun 130012, China
Abstract
Deep Web contains a significant amount of visited information, in order to be able to make full use of the information, we need to organize it according to different domain. Therefore, it is imperative that Deep Web databases should be classified by domain automatically. In this paper, a new Deep Web database classification framework is proposed, which adds semantic information to feature vectors and centroid vector by extracting the synsets of terms which can be obtained from WordNet, and replace the terms by corresponding synsets in the feature vectors and centroid vector to achieve dimensionality reduction of vectors. Lastly, highlight the semantic feature vectors by semantic centroid vector, and classify the highlighted semantic feature vectors by classification algorithm. Experiments show that experiment 3 which combines experiment 1 and experiment 2 can effectively improve the classification accuracy of Deep Web databases.
Keywords: Deep Web; SVM; WordNet; Centroid
1. Introduction
With the rapid development of the web, more and more information has been transferred from static web pages (that is Surface Web) into web databases (that is Deep Web) managed by web servers. Public information on the Deep Web is currently 400-500 times than that of Surface Web [1]. Compared with Surface Web, Deep Web databases generally belongs to specific domains, which the subjects are simplex, therefore, the idea that organizing and integrating Deep Web information according to specific domains has been recognized by the most of researchers. In order to achieve the integration of Deep Web databases, an important step is to automatic classification to web databases. Artificial classification is a time-consuming work, so it is imperative to accelerate research on automatic classification of Deep Web databases.
Related work. There are two methods for automatic classification of Deep Web databases. One is pre-query, which classifies web databases according to the features of query forms. The other is post-query, which identifies the search interfaces by submitting probing queries to the HTML forms and analyzing the result pages. Literature[2] introduces QProber, a modular system that automates this classification process by using a small number of query probes, generated by document classifiers. To classify a database,
† Corresponding author.
QProber does not retrieve or inspect any documents or pages from the database, but rather just exploits the number of matches that each query probe generates at the database in question. Literature[3] presents an approach to the automatic induction of wrappers for sources of the hidden web that does not need any human supervision. The approach only needs domain knowledge expressed as a set of concept names and concept instances. However, when the database records have more attributes, it is difficult for this method of post-query to obtain a better classification. What is more, it is some of wasting network and server resources by submitting a large number of queries only for the purpose of classification. Therefore, the method of pre-query which depends on visual features of query interfaces, namely, attribute labels and other available resources, are usually used to determine the domain. Literature[4] hypothesizes that “homogeneous sources” are characterized by the same hidden generative models for their schemas. To find clusters governed by such statistical distributions, it proposes a new objective function, model-differentiation, which employs principled hypothesis testing to maximize statistical heterogeneity among clusters. However, effectiveness of the method will be highly dependent on the extraction of form labels. Literature[5] proposes a new strategy that automatically and accurately classifies online databases based on features that can be easily extracted from web forms. By judiciously partitioning the space of form features, this strategy allows the use of simpler classifiers that can be constructed using learning techniques that are better suited for the features of each partition.
2. The Framework of Automatic Classification in Deep Web
The existed centroid-based text classification research[6][7][8] is usually used to compute similarity by the comparability between test samples and different domain-specific centroid, and then classify test samples to the highest similarity centriod domain. However, the method in this paper makes full use of domain-specific centriod and WordNet[9] to highlight these features of test samples, and then sends these highlighted feature vectors to text classifier(such as SVM, Decision tree, etc.). The classification framework presented in this paper is shown in Fig.1, in which part of the color deepening means the main ideas presented in this paper. The purpose of highlighting training samples is to improve the feature weights of positive samples.
The classification process is as follows:
Step1. Collect training forms and construct the root centroid set.
Step2. Extract the form features and preprocess the features, such as case conversion, stopwords removal, stemming, ect, and then finish the term frequency statistics and compute feature weights by TF-IDF to construct feature vector of each form.
Step3. Construct domain-specific centroid vector: Firstly, according to the last step to process the root set for obtaining the feature vectors, and compute the centroid weights by average method to construct centroid vector.
Step4. Highlight the vectors by centroid to get the final feature vectors.
Step5. Send the highlighted feature vectors to classification algorithms for training and learning to generate form classifier model.
Step6. Given query forms and preprocess the forms to construct feature vectors, and then highlight the feature vectors by centroid, finally, send these highlighted feature vectors to form classifier model to output the form category.
3. Automatic Classification of Deep Web Databases
3.1. Construct Semantic Feature Vectors of Forms
In this paper, we adopt pre-query method to classify Deep Web databases, the features of Deep Web query forms are the only clue of pre-query. Constructing feature vectors of forms by adding semantic information to feature vectors is as follows[10]:
The process of constructing semantic feature vectors:
Step1. Each form is denoted into a feature vector
t
d=
(
tf
(
d
,
t
1),
tf
(
d
,
t
2),
"
,
tf
(
d
,
t
m))
.Step2. If
t
ican be searched in WordNet, thentf d t
( , )
i is replaced bycf d c
( ,
j)
, wherec
jis the synset oft
iin WordNet.tf d t
( , )
i means the frequency of thei
th term in document d,cf
(
d
,
c
j)
means the concept frequency of the
j
th term in document d,i
∈
(
1
,
"
,
m
)
,j
∈
(
1
,
"
,
l
)
,l
=
C
,C
is the sum of synset.Step3. If
t
ican not be searched in WordNet, thent
iis the non-entry word, which will store in featurevector.
Step4. The feature vector of form adding semantic features is:
))
,
(
,
),
,
(
,
),
,
(
,
),
,
(
(
1 l n q dcf
d
c
cf
d
c
df
d
t
df
d
t
ct
=
"
"
"
(1)3.2. The Generation of Centroid Vector
A centriod of positive samples can be well reflected the features of positive samples, each feature of centroid vector is mostly the specific term of domain, the weight of each feature reflects the importance of
positive samples, at the same time, it also can reflect the importance of this feature in domain-specific. Firstly, deal with each form of root set and extract features of forms, then construct the feature vectors and compute the centroid weights by heuristic rules. In this paper, we adopt the average method to compute the centroid weights, which can better reflect the importance of centroid feature in all positive samples. If there are
n
+
1
forms andm
+
1
features,x
ijis thej
th feature weight in thei
th form vector. Ifthe feature
j
in thei
th form vector is non-zero, then label form vector is 1, namely,φ
(
x
ij)
=1,else
φ
(
x
ij)
=0. For each featurej
,g j
( )
denotes the average of weights in all the forms. Make eachaverage weight as the feature weight of centroid vector. The formula is as follows, which cave is the centroid vector.
1
0
( )
0
0
ij ij ijif x
x
if x
φ
= ⎨
⎧
>
=
⎩
(2) 0 0( )
(
)
n ij i n ij ix
g j
x
φ
= ==
∑
∑
(3)( (0),
, ( ))
Cave
=
g
"
g m
(4)3.3. Highlight Feature Vectors by Centroid
The process of highlighting feature vectors by centroid:
Step1. Preprocess each feature of Deep Web query form and convert into feature vector d.
Step2. For each feature
i
of the vector, if featurei
is contained into centroid vector, then highlight its weight of this feature by the following formula:( )
( )
( ,
)
weight i
=
weight i
+
Sim d centroid
(5)Where
weight
(
i
)
is the weight of featurei
,Sim
(
d
,
centroid
)
is the similarity between centroid and feature vectors, the larger the value, the more similar the vectors, namely, it is more possible for the feature vectors to belong to the domain which the centroid represented.Sim
(
d
,
centroid
)
can be obtained by the cosine function[11], its formula is as follows:( ,
)
cos( ,
)
*
d centroid
Sim d centroid
d centroid
d
centroid
⋅
=
=
(6)Where “
⋅
”denotes the dot-product of the two vectors.there is no need to highlight the feature vectors.
Step3. Normalize the highlighted feature vector by the following formula, then send this highlighted feature vector to form classifier.
2 0
( )
( )
[
( )]
m jweight
i
weight
i
weight
i
==
∑
(7)According to above steps, we can easily obtain the highlighted feature vectors.
4. Experiments
4.1. Training Samples Collection
Before classification, we need to collect the training samples. In this paper, the training samples consist of some query forms from UIUC data set[12], which is initially established by the MetaQuerier[13] project of UIUC University and is constantly increasing.
The data set is shown in Table 1. There are six domain-specific, for each domain-specific, the data set contains positive samples and negative samples..
Table 1 Data Set
Domain-specific Positive number Negative number
Airfare 43 264 AutoMobiles 50 257 Books 51 256 Job 39 268 Movie 37 270 MusicRecords 44 263 4.2. Experiment Schema
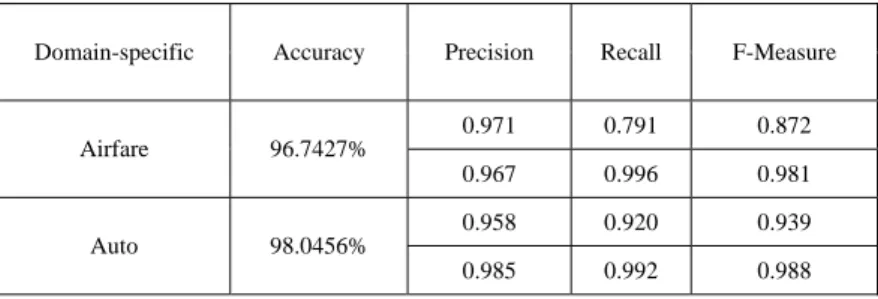
Experiment 1. Classify forms based on centroid. Experiment 1 is to highlight the feature vectors of training samples based on centroid, and then classify the highlighted feature vectors of training samples by classification algorithms, the classification algorithms in experiment 1 adopts SVM. The results for six domains are shown in Table 2.
Table 2 The Classification Results for Six Domain-specific based on Centroid
Domain-specific Accuracy Precision Recall F-Measure
0.971 0.791 0.872 Airfare 96.7427% 0.967 0.996 0.981 0.958 0.920 0.939 Auto 98.0456% 0.985 0.992 0.988
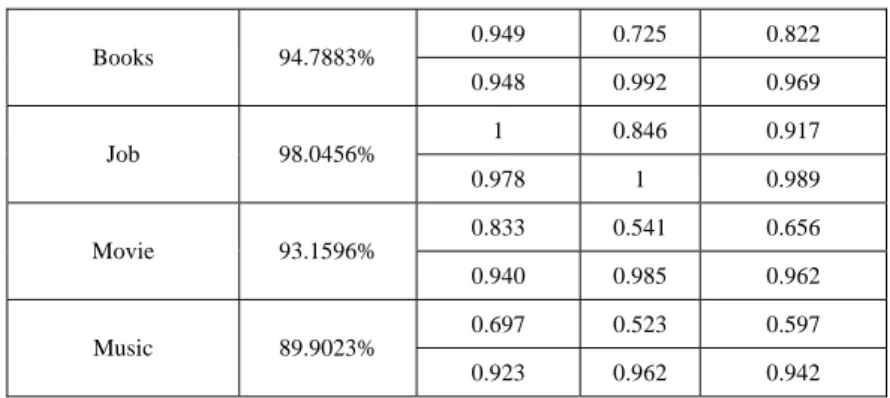
0.949 0.725 0.822 Books 94.7883% 0.948 0.992 0.969 1 0.846 0.917 Job 98.0456% 0.978 1 0.989 0.833 0.541 0.656 Movie 93.1596% 0.940 0.985 0.962 0.697 0.523 0.597 Music 89.9023% 0.923 0.962 0.942
Experiment 2. Classify forms by semantic feature vectors. The feature vector of experiment 1 is constructed without semantics, the feature vector of experiment 2 is constructed with semantics by WordNet. JWNL is the API to call WordNet, after setting JWNL, then constructing the semantic feature vectors, the results of experiment 2 are shown in Table3:
Table 3 The Classification Results for Six Domain-specific based on WordNet
Domain-specific Accuracy Precision Recall F-Measure
0.971 0.767 0.857 Airfare 96.4169% 0.963 0.996 0.980 0.978 0.900 0.938 Auto 98.0456% 0.981 0.996 0.988 0.974 0.745 0.844 Books 95.4397% 0.951 0.996 0.973 0.941 0.821 0.877 Job 97.0684% 0.974 0.993 0.983 0.870 0.541 0.667 Movie 93.4853% 0.940 0.989 0.964 0.706 0.545 0.615 Music 90.228% 0.927 0.962 0.944
Experiment 3. Classify forms based on centroid and WordNet. The process is as follows:
Step1. Replace the terms of feature vectors in experiment 1 by corresponding synsets of WordNet to generate the semantic centroid vector.
Step2. Highlight the semantic feature vectors by semantic centroid vector.
Step3. Classify the highlighted semantic feature vectors by SVM classification algorithm. The results for experiment 3 are shown in Table 4.
Table 4 The Classification Results for Six Domain-specific based on Centroid and WordNet
Domain-specific Accuracy Precision Recall F-Measure
0.972 0.814 0.886 Airfare 97.0684%
0.979 0.920 0.948 Auto 98.3713% 0.985 0.996 0.990 0.976 0.784 0.870 Books 96.0912% 0.959 0.996 0.977 0.971 0.846 0.904 Job 97.7199% 0.978 0.996 0.987 0.846 0.595 0.698 Movie 93.8111% 0.947 0.985 0.966 0.735 0.568 0.641 Music 90.8795% 0.930 0.966 0.948
4.3. The Comparability for Experiments
In this paper, we carry out three experiments. Experiment 1 is the first idea which highlights the feature vectors by centroid. Experiment 2 is the second idea which adds semantics to feature vectors by WordNet. Experiment 3 is to combine the two ideas, which add semantics to centroid vector, training vectors and test vectors by WordNet, then highlight the training vectors and test vectors by centroid vector. The comparability for three experiments is shown in Fig.2
84 86 88 90 92 94 96 98 100
Air Auto Book Job Movie Music
Experiment1 Experiment2 Experiment3
Fig.2 The Comparability for Three Experiments
From Fig.2, we find that experiment 3 which combines experiment 1 and experiment 2 can effectively improve the classification accuracy of Deep Web databases, so it is feasible for experiment 3 to classify Deep Web databases.
5. Conclusions and Future Work
This paper studies the automatic classification of Deep Web databases, a new Deep Web database classification framework is proposed, which adds semantic information to feature vectors of forms and centroid vector by extracting the synsets of terms which can be searched from WordNet. Lastly, highlight the semantic feature vectors by semantic centroid vector, and classify the highlighted semantic feature vectors by classification algorithm. Experiments show that the method can effectively improve the
classification accuracy of Deep Web databases.
In the future work, we will study the more effective method to improve the classification results, which guarantee that it not only should be more versatile, but also importing domain ontology. In addition, during automatic classification of Deep Web databases, we do not combine focusing crawling and classifier to crawl on the Internet, which will be researched in the future.
Acknowledgement
This work is supported by the National Natural Science Foundation of China under Grant No.60973040; the National Natural Science Foundation of China under Grant No.60903098; the Science and Technology Development Program of Jilin Province of China under Grant No. 20070533; the Specialized Research Foundation for the Doctoral Program of Higher Education of China under Grant No.200801830021;the basic scientific research foundation for the interdisciplinary research and innovation project of Jilin University under Grant No.200810025.
References
[1] Bergman M k. The Deep Web: Surfacing Hidden Value[J]. The Journal of Electronic Publishing.
2001,7(1):8912-8914
[2] Luis Gravan, Giotis G.ipeirotis. QProber: A System for Automatic Classification of Hidden-Web Databases[J]. ACM Transactions on Information Systems, 2003, 21(1): 1-41
[3] Pierre Senellart, Avin Mittal, Daniel Muschick, Remi Gilleron, Marc Tommasi. Automatic wrapper induction from hidden-web sources with domain knowledge. ACM, 2008, pp:9-16
[4] B. He, T. Tao, K. C.-C. Chang. Organizing Structured Web Sources by Query Schemas: A Clustering Approach [C]. Proceedings of the thirteenth ACM international conference on Information and knowledge management, 2004, pp:22-31
[5] L. Barbosa and J. Freire. Combining Classifiers to Identify Online Databases [C]. In Proceedings of WWW, 2007, pp:431-440
[6] Tan S, Cheng X, Wang B, Xu H, Ghanem MM, Guo Y, Using dragpushing to refine centroid text classifiers[C], ACM SIGIR, 2005, pp:653-654
[7] Lertnattee V, Theeramunkong T, Effect of term distributions on centroid-based text categorization[J].
Information Sciences, 2004, 158(1): 89-115
[8] E. Hanand, G. Karypis, Centroid-Based Document Classification: Analysis & Experimental Results[C], In European Conference on Principles of Data Mining and Knowledge Discovery,2000, pp:424-431
[9] G. Miller. WordNet: A lexical database for English. CACM, 1995, 38(11):39-41
[10] Andreas Hotho, Steffen Staab, Gerd Stumme, Ontology Improves Text Documents Clustering[C], Proc.of ICDM, 2003, pp541-544
[11] G.Stalton. Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer. Addison-Wesley, 1989
[12] The UIUC Web integration repository. Computer Science Department, University of Illinois at
Urbana-Champaign. http://metaquerier.cs.uiuc.edu/repository/
[13] sChang K C, He B, Zhang Z. Toward Large Scale Integration: Building a MetaQuerier over Databases on the Web [C]. In Proceedings of the CIDR C