International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
661
An Efficient Ensemble Based Hierarchical Clustering
Algorithm
Shyamlal Bobdiya
1, Kamlesh Patidar
21 Master of Engineering (SE) IV Sem, JIT Borawan RGPV Bhopal 2
Assistant Professor, JIT Borawan RGPV Bhopal
Abstract: - Clustering is an important data mining technique which play and very important role in many application. In this paper we enhanced hierarchical clustering algorithms like single, complete and average linkage methods by using the concept of cluster ensemble techniques. Single linkage method is based on similarity of two clusters that are most similar (closest) points in the different clusters. Complete linkage method based on similarity of two clusters that are least similar (most distant) points in the different clusters. The complete-linkage clustering methods usually produce more compact clusters and more useful hierarchies than the single-linkage clustering methods, yet the single-link methods are more versatile.
Keywords - clustering, single linkage, complete linkage, hierarchical, ensemble, enhance.
I. INTRODUCTION
Clustering is defined as”A Cluster is a set of entities which are alike, and entities from different clusters are not alike.” Clustering is unsupervised learning because it doesn’t use predefined category labels associated with data items[1]. Clustering algorithms are engineered to find structure in the current data, not to categories future data. A
clustering algorithm attempts to find natural groups of
components (or data) based on some similarity. The cluster should be a tight and compact high-density region of data points when compared to the other areas of space[2,3,15].
From compactness and tightness, it follows that the degree
of dispersion (variance) of the cluster is small. The shape of the cluster is not known a priori. It is determined by the used algorithm and clustering criteria. Separation defines the degree of possible cluster overlap and the distance to each other.
II. ELEMENTS OF CLUSTER ANALYSIS
Cluster analysis is a convenient method for identifying homogenous groups of objects called clusters; objects in a Specific cluster share many characteristics, but are very dissimilar to objects not belonging to that cluster. After having decided on the clustering variables we need to decide on the clustering procedure to form our groups of objects[4,6,18].
This step is crucial for the analysis, as different procedures require different decisions prior to analysis. These approaches are: hierarchical methods, partitioning methods and two-step clustering. Each of these procedures follows a different approach to grouping the most similar objects into a cluster and to determining each object’s cluster membership [9,14,19]. In other words, whereas an object in a certain cluster should be as similar as possible to all the other objects in the same cluster, it should likewise be as distinct as possible from objects in different clusters [5,7,8,17].
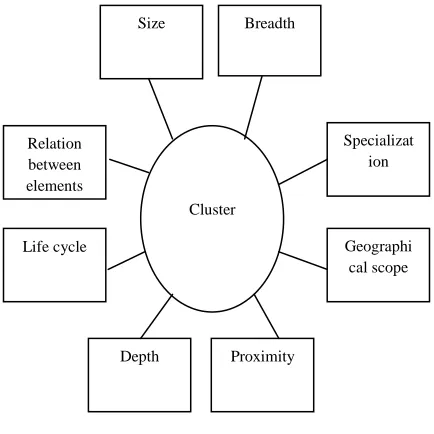
[image:1.612.331.548.371.588.2]Figure 1.1 elements of cluster analysis
Boundaries of a cluster are not exact. Clusters vary in size, depth and breadth. Some clusters consist of small and some of medium and some of large in size. The depth refers to the range related by vertically relationships. Furthermore, a cluster is characterized by its breadth as well. The breath is defined by the range related by horizontally relationships [9,11,20].
Life cycle
Specializat ion Breadth
Relation between elements
Depth
Geographi cal scope
Proximity Size
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
662
III. PROBLEM STATEMENT
The important problems with ensemble based cluster analysis that this work have identified are as follows:
A. The identification of distance measure: Identification measure numerical attributes, as well as for categorical attributes is difficult.
B. The number of clusters: Identifying the number of clusters & its proximity value is a difficult task
C. Types of attributes in a database: The databases may not necessarily contain distinctively numerical or categorical attributes. They may also contain other types like nominal, ordinal, binary etc.
D. Classification of Ensemble Clustering Algorithm: Clustering algorithms can be classified according to the method adopted to define the individual clusters. So which algorithm is used for what specific purpose is not properly mentioned?
E. Merging decision in not given: Hierarchical clustering tends to make good local decisions about combining two clusters since it has the entire proximity matrix available. However, once a decision is made to merge two clusters, the hierarchical scheme does not allow for that decision to be changed.
Each of these linkage algorithms can yield totally different results when used on the same dataset, as each has its specific properties. So it is very difficult to decide which method is to best for select data set. The complete-link clustering methods usually produce more compact clusters and more useful hierarchies than the single-link clustering
methods, yet the single-link methods are more
versatile[10,12,14,13].
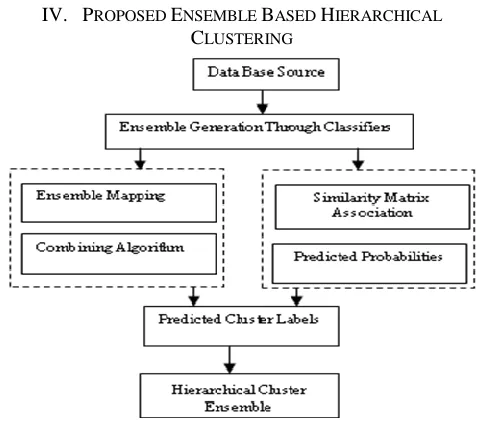
IV. PROPOSED ENSEMBLE BASED HIERARCHICAL
[image:2.612.323.562.134.346.2]CLUSTERING
Figure 1.2 working method of proposed algorithm
The proposed approach is used on generation of ensembles based cluster on the basis of few perations like mapping & combination. These operations can be performed with the help of two operators’ similarity association & probability for correct classification or classifier analysis of cluster. In this proposed approach our main aim is to identify the cluster partitional data for hierarchical clustering. It may be represented via
parametric representation of nested clustering &
Dendograms.
Consider a simple data set with six object and coordinate value. Each object is represented in two dimensional plan
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
663
TABLE1.1SIMPLE DATA SET WITH SIX OBJECTS
X Y Object
4 4 A
8 4 B
15 8 C
24 4 D
24 12 E
Now calculate distance matrix for these object by using any distance calculation formula between two point given in a two dimensional plan. We have used Euclidean distance .suppose two given point’s p(x1, y1) and q(x2, y2) Euclidean distance between p and q are denoted as
TABLE1.2
DISTANCE MATRIX OF GIVEN SIX OBJECTS
A B C D E
A 0 4 11.7 20 21.4
B 4 0 8.1 16 17.8
C 11.7 8.1 0 9.8 9.8
D 20 16 9.8 0 8
E 21.4 17.8 9.8 8 0
[image:3.612.342.544.129.298.2]A The iterations for generating cluster using single linkage (MIN):- Using single linkage methods we merge the objects one by one according to minimum distance. First we merge the object A and B, than we merge the object D and E. object C is merge with the object AB and at last we merge all object. Finally we create a dendogram according to merging of the objects. Dendogram in figure 1.3 show the merging process.
Figure 1.3 merging processes using single linkage
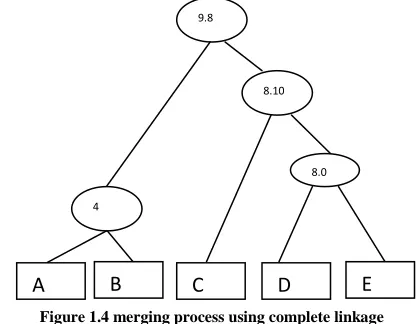
B. The iterations for generating cluster using complete linkage (MAX) :- Using complete linkage methods we merge the objects one by one according to minimum distance. First we merge the object A and B, than we merge the object D and E. object C is merge with the object DE and at last we merge all object. Finally we create a dendogram according to merging of the objects. Dendogram in figure 1.4 show the merging process
Figure 1.4 merging process using complete linkage
Now we calculate the dendogram distance matrix of
single linkage and complete linkage
.
9.8
4
8.10
A
B
C
D
E
8.0
9.8
4
8.10
A
B
C
D
E
[image:3.612.338.547.402.564.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
[image:4.612.53.554.100.484.2]664
TABLE 1.3DENDOGRAM DISTANCE MATRIX FOR SINGLE LINKAGE METHOD
A B C D E
A 0 4 8.1 9.8 9.8
B 4 0 8.1 9.8 9.8
C 8.1 8.1 0 9.8 9.8
D 9.8 9.8 9.8 0 8.0
[image:4.612.54.283.123.472.2]E 9.8 9.8 9.8 8.0 0
TABLE 1.4
DENDOGRAM DISTANCE MATRIX FOR COMPLETE LINKAGE METHOD
A B C D E
A 0 4 21.4 21.4 21.4
B 4 0 21.4 21.4 21.4
C 21.4 21.4 0 8.10 8.10
D 21.4 21.4 8.10 0 8.0
E 21.4 21.4 8.10 8.0 0
Now ensemble original distance matrix with dendogram distance matrix to find which method generates more accurate clustering.
We use Association Relation Coefficient (ARC) to find out ensemble hierarchical based clustering. This coefficient calculates the Association between these two distance matrices. One of the common uses of this measure is to evaluate which type of hierarchical clustering is best. It
shows the goodness/fit of the clustering. The ARC between
two distance matrices X and Y are represented as r(X, Y) which is defined in below formula.
The arc (X,Y) yields a value between 0 and 1. The higher the correlation grows, the larger arc(X, Y) gets. In particular, when X is identical to Y, arc(X,Y) = 1. Finding correlation between single linkage and complete linkage distance matrix
TABLE 1.6
COMPARISON TABLE USING ENSEMBLE
Techniques Relational value
Single Linkage (MIN) 0.6159
Complete Linkage (MAX) 0.7196
V. ANALYSIS AND RESULT
We evaluate the performance of proposed algorithm and compare it with single linkage, complete linkage and average linkage methods. The experiments were performed on Intel Core i5-4200U processor 2GB main memory and RAM: 4GB Inbuilt HDD: 500GB OS: Windows 8. The algorithms are implemented in using C# Dot Framework Net language version 4.0.1. Synthetic datasets are used to evaluate the performance of the algorithms.
We have taken 50 objects in two dimensional plan. Maximum value for X coordinated, 100 and Maximum value for Y coordinated is also 100. User can give the coordinated value for any object between 0 to 100 for pair of X and Y. SQL Server R2 (2008) to store our database. Database contain three attribute first is name or number of the object, second X coordinated value and third is Y coordinated value.
A Execution Time with Number of objects
For comparing the performance of the proposed algorithms we implement the single linkage and complete linkage method. Our first comparison is based on execution time and number of objects
TABLE 1.7
NUMBER OF OBJECTS AND EXECUTION TIME
Number of Object
Single Linkage
Execution time Complete Linkage Execution time
50 2119 2011
100 7512 8034
[image:4.612.322.567.517.624.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
[image:5.612.53.286.123.278.2]665
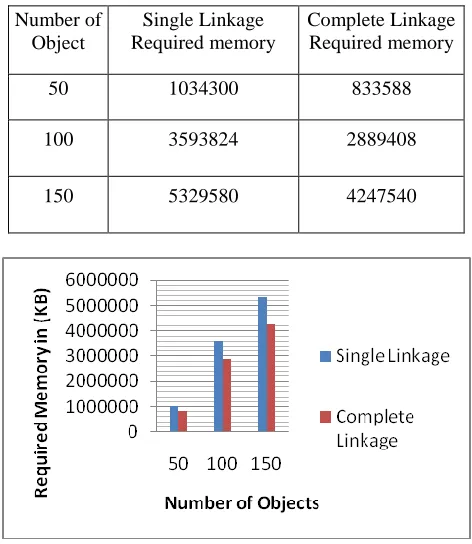
Figure 1.5 Comparisons with Execution time and number of objectsB Memory Used for Execution and Number of Objects
Table 1.8 show memory used for execution for Single
[image:5.612.316.566.141.715.2]linkage and complete linkage method
TABLE 1.8
NUMBER OF OBJECTS AND MEMORY REQUIRED EXECUTION
Number of Object
Single Linkage Required memory
Complete Linkage Required memory
50 1034300 833588
100 3593824 2889408
150 5329580 4247540
Figure 1.6 Comparison with Number of Objects and memory required for execution
REFERENCES
[1] J. Han, M. Kamber, Data mining, Concepts and techniques, Academic Press, 2003.
[2] Arun K. Pujari, Data mining Techniques, University Press (India) Private Limited, 2006.
[3] D. Hand, H. Mannila, P. Smyth, Principles of Data Mining, Prentice Hall of India, 2004
[4] Nachiketa Sahoo Incremental Hierarchical Clustering of Text Documents May 5, 2006
[5] Sanjoy Dasgupta Philip M. Long Performance guarantees for hierarchical Clustering Preprint submitted to Elsevier Science 24 July 2010
[6] Tapas Kanungo, Nathan S. Netanyahu “An Efficient k-Means Clustering Algorithm: Analysis and Implementation” IEEE Transactions On Pattern Analysis And Machine Intelligence, Vol. 24, No. 7, July 2002.
[7] R. M. Castro, M. J. Coates, R. D. Nowak, Member, IEEE Department of Electrical and Computer Engineering, Rice University, MS366, Houston, TX 77251-1892 USA
[8] Matej Franceti, Mateja Nagode, and Bojan Nastav Hierarchical Clustering with Concave Data Sets Metodoloski zvezki, Vol. 2, No. 2, 2005, 173-193
[9] Ming-Chuan Hung, Jungpin Wu, Jin-Hua Chang and Don-Lin Yang “An Efficient k-Means Clustering Algorithm Using Simple Partitioning “Journal of Information Science And Engineering 21, 1157-1177 (2005).
[10] Yi Lu Lily R. Liang Hierarchical Clustering of Features on Categorical Data of Biomedical Applications Computer Science Department Prairie View A&M University Prairie View, Texas, 77446, USA.
[11] Dar-Jen Chang, Mehmed Kantardzic, Ming Ouyang Hierarchical clustering with CUDA/GPU Computer Engineering & Computer Science Department University of Louisville Louisville, Kentucky 40292
[12] Mahmood Hossain, Susan M. Bridges, Yong Wang, and Julia E. Hodges “An Effective Ensemble Method for Hierarchical Clustering “ June 27-29, Montreal, QC, CANADA Editors: B. C. Desai, S. Mudur, E. Vassev Copyright c_2012 ACM 978-1-4503-1084-0/12/06 .
[13] Xiaoke Su, Yang Lan, Renxia Wan, and Yuming Qin “ A Fast Incremental Clustering Algorithm” ISBN 978-952-5726-02-2 (Print), 978-952-5726-03-9 (CD-ROM) Proceedings of the 2009 International Symposium on Information Processing (ISIP’09) [14] Revati Raman Dewangan , Lokesh Kumar Sharma, Ajaya Kumar
Akasapu Fuzzy Clustering Technique for Numerical and Categorical dataset Revati Raman Dewangan et al. / International Journal on Computer Science and Engineering (IJCSE) NCICT 2010 Special Issue.
[15] Parul Agarwal, M. Afshar Alam, Ranjit BiswasAnalysing the agglomerative hierarchical Clustering Algorithm for Categorical Attributes International Journal of Innovation, Management and Technology, Vol. 1, No. 2, June 2010 ISSN: 2010-0248
[image:5.612.50.286.372.644.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 7, July 2014)
666
[17] Dan Wei, Qingshan Jiang, Yanjie Wei and Shengrui Wang A novel hierarchical clustering algorithm for gene Sequences 2012 Wei et al.; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License.
[18] Elio Masciari1, Giuseppe Massimiliano Mazzeo, and Carlo Zaniolo A New, Fast and Accurate Algorithm for Hierarchical Clustering on Euclidean Distances J. Pei et al. (Eds.): PAKDD 2013, Part II, LNAI 7819, pp. 111–122, 2013. Springer-Verlag Berlin Heidelberg 2013.
[19] Yuri Malitsky, Ashish Sabharwal, Horst Samulowitz, Meinolf Sellmann Algorithm Portfolios Based on Cost-Sensitive Hierarchical Clustering IBM Watson Research Center Yorktown Heights, NY 10598, USA.