International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)322
Multi - Agent Collaborative Service Request Scheduling
Model Based on Reinforcement Learning
Qianpeng Li
1, Chao Ma
2, Yaming Chen
3, Xinlou Wang
4, Qingtao Wu
51-5
Information Engineering College,Henan University Science and Technology,Luoyang471023,China
Abstract—Increasing of Internet information, the existing
TCP / IP architecture faces many challenges and cannot cope with the transmission of large amounts of data or the access of heterogeneous terminals. Therefore, the future Internet represented by Information-Centric Networking (ICN) has become a hot research topic. Resource scheduling as one of the important research points of ICN, has its scheduling mechanism and algorithm directly impacting its performance and cost. In order to improve the performance of scheduling mechanism in ICN, this paper proposes a multi-agent cooperative service request scheduling model based on reinforcement learning. The model mainly achieves service request scheduling by constructing two layers of intensive learning units. The first layer of intensive learning unit is responsible for learning agents' joint task collaboration strategy. The second layer of intensive learning unit is responsible for learning. This agent seems to be the most effective action strategy. Through the simulation analysis, this model improves the service request response speed and throughput under the premise of guaranteeing the service quality, thus shortens the response delay.
Keywords—ICN, Intensive learning, Multi-agent collaboration, Service request scheduling.
I. INTRODUCTION
In the past ten years, computer networks have shown a surprising expansion in scale, and a series of meaningful innovations and reforms have emerged in terms of network access and network roles [1], [2]. However, in the entire process of computer network development, the core status of the TCP/IP architecture remains unchanged. The advantage of the TCP/IP architecture is that it can carry the development of diverse physical link layers and application service layers [3]. Although the advantages of the TCP/IP architecture accelerate the development of computer networks, it also brings new problems to the network architecture [4].
The original design of the Internet was designed to solve the problem of resource sharing. With the rapid increase in the amount of information on the Internet, people's sharing of resources gradually becomes the acquisition and distribution of content [5], [6]. Users are more concerned with how to get the content itself, not the location of the content. Therefore, the "assumption" of traditional Internet design can no longer meet the needs of new applications. The information center network shifts the user's focus from the host to the content, that is, the user only needs to be concerned about the content they need, without going into the location of the location and decoupling the content and location to solve many problems that the traditional Internet face. As can be seen, ICN network as a new architecture, which brought a revolutionary change in the network has aroused widespread academic attention, the future development of network technology has important theoretical and practical significance [7], [8].
In the ICN network, each intermediate node is intelligent. How to combine the caching strategy and routing algorithm with the response of routing nodes to service requests, make full use of network built-in cache information, and inform other routing nodes reasonably , Which is a problem that needs to be studied deeply in the scheduling of service requests of routing nodes in ICN network.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)323
On the one hand, agents choose the optimal response action based on opponent strategy under the rational constraint through mutual interaction (countermeasure); on the other hand, The choice of body actions should be based on an understanding of the actions of the environment and other agents, which requires that agents use reinforcement learning to establish and continually correct their beliefs about other agents [10]-[12].
Based on multi-agent collaborative Q-learning for reinforcement learning, this paper uses two layers of reinforcement learning method to achieve multi-agent collaborative scheduling. While all the agents are running around their own local targets, they are finally processed by the global Q-learning unit to learn collaborative knowledge of joint tasks and achieve efficient collaborative scheduling. Simulation results show that the proposed method is efficient.
The rest of this article is organized as follows. Section 2 is the related work of this article. Section 3 introduces the reinforcement learning model and algorithm proposed in this paper. Section 4 describes the evaluation results based on Linux. Finally, Section 5 summarizes this paper.
II. REALTED WORK
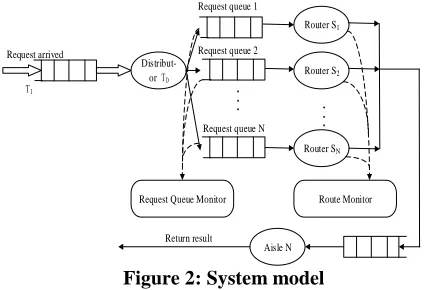
Figure 1 for the ICN network service business processing system structure. The process is as follows: 1.The user logs in to the home page of the business system through various computers of the distributed network terminal, and submits the business request; 2.The web server transmits the information to the middleware, and the middleware judges the different types of the business request. The request sent to the corresponding different service queue, waiting in line to enter the service area; 3, all kinds of servers and intelligent router processing through intelligent router middleware, the network server will process the results back to the user [13], [14].
It can be seen from the above process that the quality of network service is affected by two factors. One is the performance of various servers, router nodes and database servers on the back end, and the other is the scheduling strategy used by the system.
Desktop
Tablet
Laptop
Database Web server
Other servers
Middleware
Figure 1: Network service request processing system structure
Traditional Web Services is a new Internet application model and a brand new distributed computing model. More and more enterprises have set up their own websites to publish product and business information and provide users with various convenient Internet service businesses [15]. However, the current internet servers have such problems as reliability, testability, security and performance conflicts that it is difficult to meet the needs of the core business transactions. Internet terminals are used as a distributed Web services business platform, these Web services need to feed back information from the server. Most of the Internet servers use the "best effort" service principle, namely, the first-come-first-serve (FCFS) queuing rules. This queuing rule in the case of a sharp increase in user requests, the request is coming much faster than the server can handle the request rate, resulting in the queue waiting for the increasing number of requests, the performance of the entire Web service system deteriorate dramatically, causing unpredictable The request response delay[16]. This delay cannot be tolerated for time-critical business-critical requests. Addressing unpredictable response times is paramount to such services [17].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)324
This paper studies a new scheduling strategy of ICN network service request, which analyzes the key factors that affect the quality of service, analyzes the quality of service as the goal, real-time feedbacks the corresponding time according to the operation information, and real-time dispatches the request to meet the requirements of users.
III. MULTI-AGENT COLLABORATION MODEL
CONSTRUCTION
A. Quality of Service Factors - Response Time
The whole model has four logical parts, namely user request sender
T
i, user request distributorT
D, request server and request processing result return channelN
. Specifically, as shown in Figure 2, user requests arrive and are queued into the request distributor. The distributor distributes the request to the corresponding server queue according to the request type and priority, and the server returns the result through the channelN
after processing. The author focuses on the problem of router scheduling to ensure that processing results to meet the needs of users.As can be seen from the above process, Web service quality is affected by two factors, one is the performance of various servers and routers on the back end, and the other is the scheduling policy used by the system.
T1
Request arrived
Distribut-or TD
Router S1
Router S2
Router SN
Aisle N
Route Monitor Request Queue Monitor
Request queue 1
Request queue 2
Request queue N
.
.
.
.
.
.
[image:3.612.57.270.470.615.2]Return result
Figure 2: System model
Quality of service has two important factors, namely, the quality of service parameters on the system performance and the quality of service parameters on the system stability
Q
, including the quality of service parameters on the system performance, including the request response timeTr
and server throughputV
. Recorded as:
, ,...
i
Q
F Tr V
(1)Throughput is the focus of the service side, the request response time reflects the true feelings of the user is an important parameter reflecting the user satisfaction, and easier to monitor than other parameters, so I choose the appropriate time information feedback to schedule the user's business request. According to the queuing theory, suppose the request queue arrival rate
i1of the request queuei
, the server processing speed is
i2 , and the length of the task queue at the initial time of the monitoring sampling isL
i. Then, the expected response timet
0,
T
, requestq
i arriving at timet
, for any request arriving at any timeT
e is calculated by the formula (1).
1 2
/
2e i i i i pi
T
L
t
T
(2)In the formula, the parameter
L
i can be directly obtained by monitoring the system state;
i1 andT
piusing the average sampling rate
i1 and the average processing timeT
pi calculated in the previous sampling interval;
i2 is the service rate of the i-type requesting server.B. Two-tier reinforcement learning method
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)325
Agent Enhanced information R Environment
Action A
[image:4.612.49.294.151.232.2]Status S
Figure 3: Strengthen the basic principles of learning map
Q-learning is one of the main algorithms for intensive learning. It is a model-free learning method that learns the optimal action strategy by sampling the objective world rather than trying to learn the model of the objective world. In the Q-learning method, the optimal strategy of the agent is to choose the behavior with the largest Q in each state. The single-step Q-learning method's value update formula is:
1
1 max 1 1
( , )
( , )
(
, ')
( , )
t t t t
t t t t
Q
s a
Q s a
r
Q s
a
Q s a
(3)
Where:
is the learning rate;
is the discount rate;s
t is the environmental status at timet
;Q s a
t( , )
trepresents the value of
Q S
(
t,
a
)
at timet
1
;r
t1 is the return given by environment at time1
t
;
maxQ s
t(
t1, ')
a
is the state value of the environmental stateS
t1 at timet
1
(that is, the maximum valueQ
in theS
t1 state);a
'
is any agent can take any action. Research shows that whena
satisfies certain conditions, the Q-learning learning algorithm must converge on the optimal solution.In the multi-agent theory, according to the relationship between agents and the degree of cooperation, there is a kind of collaboration called collaborative collaboration. That is, the agents in the system have a common global goal, and at the same time, they are consistent with the global goal Local goals. The goal of this paper is to obtain the relatively deterministic global target knowledge through the learning of local objects with state transition uncertainty.
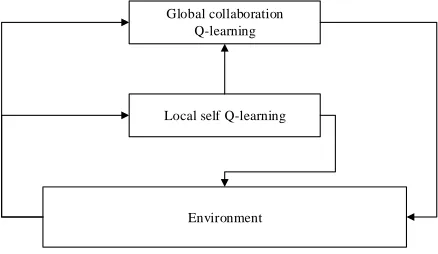
In this method, we consider each agent as an individual with intensive learning, which contains two layers of intensive learning units. The first layer of intensive learning units is responsible for learning the joint task cooperation strategy of an agent, which is called Global Cooperation Q-learning unit, the second layer of intensive learning unit is responsible for learning This agent seems to be the most effective action strategy, called the local own Q-learning unit. The structure is shown in Figure 4.
Global collaboration Q-learning
Local self Q-learning
[image:4.612.321.540.266.393.2]Environment
Figure 4:Collaboration Agent Internal Structure
In order to realize the scheduling of massive interest packages, this paper introduces the reinforcement learning algorithm into multi-agent routing scheduling, and proposes a multi-agent collaborative service request scheduling method based on reinforcement learning. The basic idea of this method is to learn the processing strategy according to the global cooperative Q-learning unit, and then feedback the information to other local cooperative Q-learning units, and eventually learn an efficient collaborative action strategy.
The multi-agent collaborative service request scheduling model based on reinforcement learning is mainly applied to intelligent routing and scheduling to achieve mass interest packet service request scheduling. The specific steps are as follows:
Step 1: Initialization: Set the Q-value table of the two-layer Q-learning unit, that is, the initial value of the global cooperative Q-value table and the local self-Q-value table is 0, and t=0;
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)326
Step 4: Simultaneously perform the respective selected actions a, get a new state
S
t1, and a strengthening signal1
t
r
;Step 5: Update the local Q-value table update formula according to the action and
r
t1 that you have taken:
1
1 max 1 1
( , )
( , )
(
, ')
( , )
t t t t
t t t t
Q
s a
Q s a
r
Q s
a
Q s a
(4)Step 6: Through the local self-Q unit feedback each other just performed actions, to obtain a combination of actions to obtain a combined action vector
A
;Step 7: Update the global cooperative Q-value table according to the combined action vector and
r
t1. The update formula is:
1
1 max 1 1
( , )
( , )
(
, ')
( , )
t t t t
t t t t
Q
s A
Q s A
r
Q s
A
Q s A
(5)'
A
represents one of all possible combined action vectors of the agent;Step 8: If the number of learning and learning effects meet the requirements, then the learning is over. Afterwards, the agent selects the actions according to the global Q-value table and analyzes the actions to be executed respectively. Otherwise, it turns to step 2;
C. Monitor the sampling period
The scheduling strategy is to periodically monitor all kinds of request queues, calculate the expected time of all kinds of requests in real time after the arrival of the sampling moment, and then adopt the scheduling strategy. Monitoring the sampling period
T
has a non-negligible effect on the scheduling result. A periodT
that is too short may be very sensitive to impulsive overload and cause unnecessary blind scheduling; if the period is too long, quality of service cannot be ensured. Select the monitoring sampling periodT
should meet the following two conditions:(1) In order to prevent the monitoring sampling period from being too short, we should use the minimum scheduling period
T
min to constrain it, that is,T
min
T
, so that we can not only guarantee the correctness of the scheduling judgment, but also avoid wasting too much of the system resources because of too short scheduling period.(2) The maximum scheduling period of
T
maxis fixed to meetT
max
T
, so as to ensure that the scheduling process can respond to complex changes in time.(3) At the end of each scheduling period, the size of the monitoring and sampling period
T
should be adjusted in a small range according to the actual situation of the scheduling, and the adjustment step isV
T
.Assumption 3-1: If for the different request queues
i
at the sampling time, the expected time
T
e obtained from the formula (2) for the new arrival requestq
i does not meet the quality of service agreement, an alarm is said to be generated; if no service quality problem is found within the scheduling period, it is said to produce a null operation. The rules for getting the periodT
for this are as follows:1) If two empty operations are generated in a continuous scheduling period, the scheduling period
T
is increased.
2) If a warning is generated in a certain scheduling period
T
, the scheduling periodT
is reduced.D. Scheduling Algorithm
Each kind of request
q
i has two response time parameters, one is the normal response timeT
si, and the other is the longest response timeT
ti that the user can tolerate. The expected response timeT
e of the newly arrivedq
i is requested every sampling moment. The scheduling algorithm for various types of queue requests is as follows:1)
T
e
T
si, Satisfy the quality of service agreement without any scheduling;2)
T
e
T
ti , May cause severe timeouts, drop requestsq
i, and refuse to processi
requests;3)
T
si
T
eT
ti , Discard the request with the probabilityP
i drop requestq
i and accept the typei
request with probability
P
i.International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)327
The relationship between the probability
P
and the two response timesT
si andT
ti can be represented by Figures 5.Pimax 1.0
Tti
Tsi Te
Figure 5: Probability relationship
The back-end server uses a “priority queueing” (PQ) scheduling policy to schedule user requests. In the PQ policy,
n
queues are defined. The priorities of these queues are1, 2,...,
n
(where the priority is the highest, and so on). The servers handle queues strictly according to their priority. If there is a request in the higher priority queue, the queue will be processed until it is empty. When the higher priority queue is empty, the server goes to the lower priority queue to process a request, and then the processor checks the higher Priority queue to determine if it is empty. If it is, it will continue to handle lower priority queues, and so on. Before a request in a low-priority queue is serviced, all queues with higher priority must be completely empty. In this way, for a waiting request, if there are still unexecuted processes in the request cache queue with a higher priority, the priority request can only wait.IV. SIMULATION AND ANALYSIS
In order to evaluate the performance of the multi-agent collaborative service request scheduling model based on reinforcement learning, the model is programmed in Linux using C language, and the scheduling algorithm proposed by the author and the simple first-come-first-serve (FCFS) algorithm are improved firstly. The first service algorithm was compared. The following assumptions are made: 1.The length of each request queue is long enough; 2.The delay caused by the network is not considered.
Based on the above assumptions, the three curves in Figure 6 represent the response time curves for FCFS, improved FCFS, and the proposed algorithm.
10 20 30 40 50 60 70 80 90 100
0 100 200 300 400 500 600 700 800
response time(s)
n
u
m
b
e
r
o
f
a
rr
iv
a
l
[image:6.612.331.525.179.332.2]FCFS Improved FCFS Algorithm in this paper
Figure 6: Response time curve
As can be seen from Figure 6, when the number of request arrivals is normal, all routing nodes can complete all requests normally, and the response time does not exceed their normal response time. With the increase in the number of requests, the service request response time of the scheduling model algorithm proposed by the author grows slower than the FCFS “best-effort” response time. This shows that under the same service quality, the proposed scheduling model can more user requests are processed.
0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0
20 40 60 80 100 120
throughput Mib/S
de
te
ct
ion
ti
m
e(
s)
[image:6.612.332.517.478.643.2]Algorithm in this paper Improved FCFS FCFS
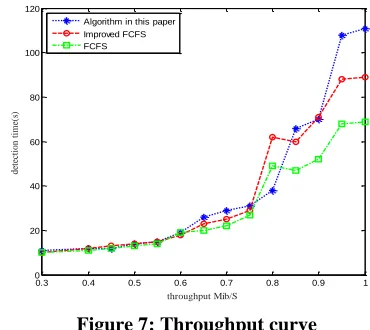
Figure 7:Throughput curve
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, UGC Approved List of Recommended Journal, Volume 8, Issue 3, March 2018)328
It can be seen from the throughput curve that the multi-agent has higher throughput than the other two algorithms, and finally tends to be stable, that is, the result is convergent. The main reason why the proposed method is effective is that adding a layer of global cooperative Q-learning unit greatly enhances the cooperation information processing between agents. Although the environmental change is still random for a single agent, the environmental change is determined for the entire group of multi-agents. Simulation results show that the proposed two-layer reinforcement learning method can effectively achieve multi-agent cooperation.
V. CONCLUSION
The traditional "best effort" service the first come first service (FCFS) rules, the lack of quality of service in perception, user service request a sharp increase in cases, resulting in the number of requests waiting to be processed in the queue increases, a sharp deterioration in the performance of the router. Request scheduling strategy based on service quality, according to the feedback information in time aware routers overload and request response time and request timeout, using probabilistic methods to reject some random business, serious request response delay control due to overloading of the router business, which can effectively guarantee the user's quality of service. Moreover, it is a learning process to send a packet of interest each time. With the increase of the number of attempts, the collaboration efficiency between multi agents is getting higher and higher.
REFERENCES
[1] Nelson T H. Literary Machines. The Report on, and of, Project Xanadu Concerning Word Processing, Electronic Publishing, Hypertext, Thinkertoys, Tomorrow's Intellectual Revolution, and Certain Other Topics Including Knowledge, Education and Freedom[J]. 1981.
[2] Sutton R S,Barto A G.Reinforcement learning[M].MIT
Press,1997.
[3] Model selection in reinforcement learning[J]. Amir-massoud Farahmand,Csaba Szepesvári. Machine Learning. 2011 (3)
[4] An iterative adaptive dynamic programming algorithm for
optimal control of unknown discrete-time nonlinear systems with
constrained inputs[J] . Derong Liu,Ding Wang,Xiong
Yang. Information Sciences . 2013
[5] Optimal control of unknown nonaffine nonlinear discrete-time systems based on adaptive dynamic programming[J]. Ding
Wang,Derong Liu,Qinglai Wei,Dongbin Zhao,Ning
Jin. Automatica . 2012 (8)
[6] Learning near-optimal policies with Bellman-residual
minimization based fitted policy iteration and a single sample path[J] . András Antos,Csaba Szepesvári,Rémi Munos. Machine Learning . 2008 (1)
[7] Santana Sosa Graciela, Kaltofen Thomas. Collision and
containment detection between biomechanically based eye muscle volume[J]. Studies in health technology and informatics, 2011, 163.
[8] Thomas Sanjeev V. Antimicrobial resistance: Neurologists role in containment and prevention[J]. Annals of Indian Academy of Neurology, 2011, 14(2).
[9] Van Damme H, Michel L. Health care cost
containment[J]. ACTA CHIRURGICA BELGICA, 2008, 108(1).
[10]CHEN X B,MOHAPATRA P.Performance evaluation of service
differentiating internet servers[J].IEEETrans . on
Compmers,2002,5l(11):368—375.
[11]RAN S P.A model for web services discovery with QoS[J].ACM
SIGecom Exchanges,2003,4(1):1—10.
[12]Thungjaroenkul Petsunee, Kunaviktikul Wipada. Possibilities for cost containment in intensive care[J]. Nursing and Health Sciences, 2006, 8(4).
[13]W. Fisher, M Suchara, J. Rexford, “Greening backbone networks: reducing energy consumption by shutting off cables in bundled links”[R],Proc. of the ACM SIGCOMM Workshop on Green Networking, New Delhi, India, August 2010: 29-34.
[14]E. Goma, M. Canini, A. Lopez, et al, “Insomnia in the access” [R], Proc. of the ACM SIGCOMM, Toronto, Canada, August 2011:338-349.
[15]Esteve C,Verdi F L,Magalhaes M F Towards a new generation of
information-oriented internetworking architectures,2008:7-9.
[16]Pan J,Paul S,Jain R. A survey of the research on future Internet architectures.IEEE Communications Magazine,2011,49(7):26— 36.
[17]Fayazbakhsh s K,et aI.Less pain,most of the gain:Incre—
mentally deployable ICN. ACM SIGCOMM Compute
Communication Review.2013,.43(4):147—158.
[18]Nelson T H. Literary Machines. The Report on, and of, Project Xanadu Concerning Word Processing, Electronic Publishing, Hypertext, Thinkertoys, Tomorrow's Intellectual Revolution, and Certain Other Topics Including Knowledge, Education and Freedom[J]. 1981.
[19]Koponen T, Chawla M, Chun B G, et al. A data-oriented (and beyond) network architecture[J]. Acm Sigcomm Computer Communication Review, 2007, 37(4): 181-192.
[20]Ahlgren B, D’Ambrosio M, Dannewitz C, et a1.Design
considerations for a network of information[C]//Proceedings of the 2008 ACM CoNEXT Conference(CoNEXT’08),Madrid, Spain,Dec 9-12,2008.NewYork,NY,USA:ACM,2008:66.