International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 12, December 2013)
477
Horizontal Aggregations in SQL to Prepare Data Sets Using
PIVOT Operator
R.Saravanan
1, J.Sivapriya
2, M.Shahidha
31
Assisstant Professor, Department of IT,SMVEC, Puducherry, India
2,3UG student, Department of IT, Puducherry, India
Abstract--Preparing dataset is a very difficult process in cases where it has to be given as input for data mining which involves complex queries, joining tables, and aggregating columns. Existing SQL aggregations have limitations to prepare data sets because they return one column per aggregated group. Our project aims at implementing a new class of functions called horizontal aggregation. Horizontal aggregation build data set with a horizontal denormalized layout, which is the standard layout required by most data mining algorithms. PIVOT operator, offered by RDBMS is used to calculate aggregate operations. Our project aims at aggregating columns using PIVOT operator. Pivot operator is used to reorganize and summarize the selected columns and rows of data in a table to produce the desired reports. Using PIVOT operator horizontally aggregated data set is achieved which will act as input for any application involving data set. This horizontal aggregation will improve the performance of clustering process in data mining.
Keywords--aggregation, dataset preparation, horizontal, pivoting, SQL.
I. INTRODUCTION
The term data set may also be used more loosely, to refer to the data in a collection of closely related tables, corresponding to a particular experiment or event. The data set lists values for each of the variables, such as height and weight of an object, for each member of the data set. Each value is known as a datum. The data set may comprise data for one or more members, corresponding to the number of rows.
II. HORIZONTAL AGGREGATION
Building a suitable data set for data mining purposes is a time-consuming task. This task generally requires writing long SQL statements or customizing SQL code if it is automatically generated by some tool. There are two main ingredients in such SQL code: joins and aggregations. The most widely-known aggregation is the sum of a column over groups of rows. There exist many aggregation functions and operators in SQL.
Unfortunately, all these aggregations have limitations to build data sets for data mining purposes. Horizontal aggregations represent an extended form of traditional SQL aggregations, which return a set of values in a horizontal layout instead of a single value per row. Horizontal aggregations provide several unique features and advantages. First, they represent a template to generate SQL code from a data mining tool. This SQL code reduces manual work in the data preparation phase in a data mining project. Second, since SQL code is automatically generated it is likely to be more efficient than SQL code written by an end user. Third, the data set can be created entirely inside the DBMS. Horizontal aggregations just require a small syntax extension to aggregate functions called in a SELECT statement.
III. SUMMARIZATION AND AGGREGATION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 12, December 2013)
478
Attribute relevance is commonly determined by dimensionality reduction and feature selection techniques [1]. Most data mining techniques, especially for classification and regression, are designed to perform variable (feature) selection. A straightforward optimization is to compute as many dimensions in the same statement exploiting the same GROUP-BY clause, when possible. A typical query to derive dimensions from a transaction table is as follows:SELECT
customer_id
,count(*) AS cntItems ,sum(salesAmt) AS totalSales
,sum(case when salesAmt<0 then 1 end) AS cntReturns
FROM sales
GROUP BY customer_id;
IV. HORIZONTAL AGGREGATION FOR PREPARING TABULAR
DATA SET
In a data mining project, a significant portion of time is devoted to building a data set suitable for analysis. In a relational database environment, building such data set usually requires joining tables and aggregating columns with SQL queries. Existing SQL aggregations are limited since they return a single number per aggregated group, producing one row for each computed number[7]. These aggregations help, but a significant effort is still required to build data sets suitable for data mining purposes, where a tabular format is generally required. This work proposes very simple, yet powerful, extensions to SQL aggregate functions to produce aggregations in tabular form, returning a set of numbers instead of one number per row. We call this new class of functions horizontal aggregations. Horizontal aggregations help building answer sets in tabular form (e.g. point-dimension, observation-variable, instance feature), which is the standard form needed by most data mining algorithms. Two common data preparation tasks are explained, including transposition/aggregation and transforming categorical attributes into binary dimensions. They propose two strategies to evaluate horizontal aggregations using standard SQL. The first strategy is based only on relational operators and the second one uses the "case" construct. Experiments with large data sets study the proposed query optimization strategies.
They propose two basic strategies to evaluate horizontal aggregations. The first strategy relies only on relational operations [7]. That is, only doing select, project, join and aggregation queries; we call it the SPJ strategy. The second form relies on the SQL "case" construct. They call it the CASE strategy. Each table has an index on its primary key for efficient join processing. They do not consider additional indexing mechanisms to accelerate query evaluation.
Aggregation is a rank of function to give aggregated columns in a straight outline. Managing large datasets except DBMS support can be a difficult job. Trying different subsets of data points and dimensions is more convenient, faster and easier to do inside a relational database with SQL queries than outside with alternative handler. There are several advantages for horizontal aggregation.
1)Horizontal aggregation represent a template to generate SQL code from a data mining tool. This SQL code reduces manual work in the data preparation phase of projects related to data mining. 2)It automatically generated code, which is more
efficient than end user written SQL code. Thus datasets for the data mining projects can be created in lesser time.
3)The data sets can be created entirely inside the DBMS K-means clustering algorithms are used to cluster the attribute, that attribute is the result of horizontal aggregation.
SPJ strategy
The SPJ strategy is interesting from a theoretical point of view because it is based on relational operators only. The basic idea is to create one table with a vertical aggregation for each result column, and then join all those tables to produce FH (horizontal layout). They aggregate from F into
N projected tables with N
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 12, December 2013)
479
CASE strategyFor this strategy, the "case" programming construct available in SQL can be used. The case statement returns a value selected from a set of values based on Boolean expressions. From a relational database theory point of view this is equivalent to doing a simple projection/aggregation query where each non-key value is given by a function that returns a number based on some conjunction of conditions [1]. They propose two basic sub-strategies to compute FH. In a similar manner to SPJ, the first one directly aggregates from F and the second one computes the vertical aggregation in a temporary table FV and then horizontal aggregations are indirectly computed from FV. Then they represent the direct aggregation strategy. Horizontal aggregation queries can be evaluated by directly aggregating from F and transposing rows at the same time to produce FH. First, they need to get the unique combinations of Dh;:::;Dk that define the matching Boolean expression for resulting columns. The SQL code to compute horizontal aggregations directly from F is as follows:
Observe V agg () is a standard SQL aggregation that has a "case" statement as argument. Horizontal aggregations need to set the result to null when there are no qualifying rows for the specific horizontal group to be consistent with the SPJ strategy and also with the extended relational model PIVOT_strategy.
It is possible to start pivoting in standard SQL, though the syntax is cumbersome and its performance is generally poor. One method to express pivoting uses scalar sub queries in the projection list. Each pivoted column is created through a separate (but nearly identical) sub query. For database uses that do not support PIVOT, users could employ this technique to perform pivoting operations.
V. POSSIBLE PIVOTSYNTAX
Alas, this approach has limitations that restrict the power of pivoting. Each column has redundant syntax, which is cumbersome as the number of pivoted columns increases. These syntaxes are also potentially tough to optimize. For this syntax, the query optimizer is presented with a number of sub-queries, making it harder to identify that this whole operation represents a “Pivot” on a single table. In practice, this is not an easy operation, making pivot-specific optimizations very difficult. The common problem is that the intent of the query is difficult to infer from the syntax or common relational algebra representation.
Therefore, we propose the following syntax for PIVOT as an additional option under the rule of the ANSI SQL grammar. This syntax is easier to read and better captures the intent of the desired operation. Repetition is eliminated, making queries easier to read, write, and maintain. It shows that this approach also enables additional query optimization techniques.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 12, December 2013)
[image:4.612.45.294.142.486.2]480
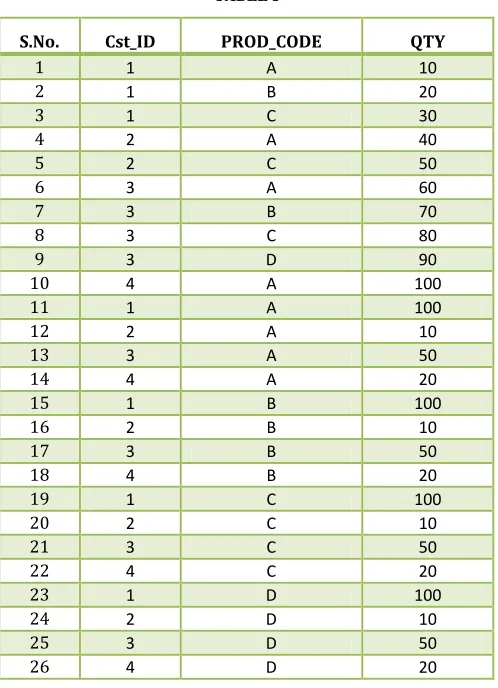
TABLE IS.No. Cst_ID PROD_CODE QTY
1 1 A 10
2 1 B 20
3 1 C 30
4 2 A 40
5 2 C 50
6 3 A 60
7 3 B 70
8 3 C 80
9 3 D 90
10 4 A 100
11 1 A 100
12 2 A 10
13 3 A 50
14 4 A 20
15 1 B 100
16 2 B 10
17 3 B 50
18 4 B 20
19 1 C 100
20 2 C 10
21 3 C 50
22 4 C 20
23 1 D 100
24 2 D 10
25 3 D 50
26 4 D 20
In the above table S.No represents the serial number, CST_ID represents the customer id, PROD_CODE represents the product code and QTY represents the quantity.
Consider a sample query for the table to calculate the sum of the column “QTY “over the rows:
SELECT * FROM
(SELECT cst_id, prod_code, qty FROM PIVOT_TEST) PIVOT (
SUM (qty) AS SUM_QTY FOR (prod_code) IN („A‟ AS a, ‟B‟ AS b, ‟C‟ AS c, ‟D‟ AS d) )
ORDER BY CST_ID;
The resulting horizontally aggregated table is represented in TABLE II.
The table consists of id (record number), cst_id, product code and quantity as the columns before aggregation. After using the aggregate function sum the result is horizontally aggregated using PIVOT operator in SQL.
This provides data set that is horizontally oriented i.e. with transposing rows into columns. There are originally 26 records in the table and after aggregation it is made as 4 rows and 4 columns as a result of the query.
This makes the data set effective while mining data. Clustering is an important step while mining data. This can be done effectively if data is aggregated horizontally. There exist two DBMS limitations with horizontal aggregations: reaching the maximum number of columns in one table and reaching the maximum column name length when columns are automatically named. To elaborate on this, a horizontal aggregation can return a table that goes beyond the maximum number of columns in the DBMS when the columns have a large number of distinct combinations of values, or when there are multiple horizontal aggregations in the same query. On the other hand, the second important issue is automatically generating unique column names. If there are many subgrouping columns R1; . . .;Rk or columns are of string data types, this may lead to generate very long column names, which may exceed DBMS limits. However, these are not important limitations because if there are many dimensions that is likely to correspond to a sparse matrix (having many zeroes or nulls) on which it will be difficult or impossible to compute a data mining model.
Also, the large column name length can be solved as explained below. The problem of the columns going beyond the maximum number of columns can be solved by vertically partitioning the horizontally aggregated table so that each partition table does not exceed the maximum number of columns allowed by the DBMS.
Evidently, each partition table must have say L1; . . . ; Lj as its primary key. Alternatively, the column name length issue can be solved by generating column identifiers with integers and creating a “dimension” description table that maps identifiers to full descriptions, but the meaning of each dimension is lost. An alternative is the use of abbreviations, which may require manual input.
VI. CONCLUSION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 12, December 2013)
481
Basically, a horizontal aggregation returns a set of numbers instead of a single number for each group, resembling a multidimensional vector. We proposed an abstract, but minimal, extension to SQL standard aggregate functions to compute horizontal aggregations which just requires specifying subgrouping columns inside the aggregation function call. From a query optimization perspective, we proposed three query evaluation methods. Our proposed horizontal aggregations can be used as a database method to automatically generate efficient SQL queries with three sets of parameters: grouping columns, subgrouping columns, and aggregated column.REFERENCES
[1] Ordonez, C. and Zhibo Chen. 2012, Horizontal Aggregation in SQL to prepare Data Sets for Data Mining Analysis. . IEEE Transactions on Knowledge and Data Engineering (TKDE), pages 1041- 4347
[2] Ordonez, C. 2011.“Data Set Preprocessing and Transformation in a Database System,”Intelligent Data Analysis, vol. 15, no. 4, pp. 613-631.
[3] Ordonez, C. 2004 “Horizontal Aggregations for Building Tabular Data Set,” Proc. Ninth ACM SIGMOD Workshop Data Mining and Knowledge Discovery (DMKD ‟04), pp. 35-42.
[4] C. Ordonez, C. “Vertical and horizontal percentage aggregations.” In Proc. ACM SIGMOD Conference, pages 866–871.
[5] Dontu.Jagannadh, Gayathri, T. and Nagendranadh, M.V.S.S. 2012 Horizontal aggregations for mining relational databases. International Journal of Computer Science and Information Technologies, Vol. 3 (2) , pages 3483-3487
[6] Nisha, S. and Lakshmipathi, B. 2012 Optimization of horizontal aggregation in SQL by using K-means algorithm.
[7] Umamaheswari, Mahesh,Horizontal, B. Layout Preparation Using Automatic Machine Learning Algorithms, ISSN: 2320-1363 [8] Cunningham, C.,Graefe, G.and Galindo-Legaria, C.A.2004. PIVOT
and UNPIVOT: Optimization and execution strategies in an RDBMS. In Proc. VLDB Conference, pages 998–1009.
[9] http://www.oracle-base.com/articles/11g/pivot-and-unpivot-operators-11gr1.php#pivot
[10] http://cs.gmu.edu/cne/modules/dau/stat/clustgalgs/clust5_bdy.html
TABLE II