2019 International Conference on Computation and Information Sciences (ICCIS 2019) ISBN: 978-1-60595-644-2
An Improved Collaborative Filtering
Recommendation Algorithm Based
on User Forgetting Curve
Jun Guo, Wenlei Bai, Pengfei Xu, Baoying Liu and Daguang Gan
ABSTRACT
Collaborative filtering recommendation is one of the earliest and successful al-gorithms in the recommender system. The traditional collaborative filtering algo-rithm only relies on the user-item scoring matrix for recommendation, and fails to take into account the impact of user interest changes on recommendation weights. An improved similarity based collaborative filtering recommendation algorithm with user interest change is proposed in this paper. The proposed algorithm em-ployed an improved item similarity calculation model and the Ebbinghaus forgetting curve to mimic the user interest tracking. A series of experiments were completed on the Netflix dataset and MovieTweeings dataset, compared with several classic tradi-tional algorithms about the accuracy and coverage rate. The experimental results show that the accuracy of the proposed algorithm overwhelms the traditional algo-rithm with the improvement of 2%-5%.
1. INTRODUCTION
With the advent of the era of big data, various kinds of data information in the Internet space has exploded, and information overload has become a great challenge in the era of big data.
Jun Guo, School of Information Science and Technology, Northwest University, Xi’an, 710127, China
Wenlei Bai (co-first author), School of Information Science and Technology, Northwest Uni-versity, Xi’an, 710127, China
Pengfei Xu, School of Information Science and Technology, Northwest University, Xi’an, 710127, China
Under the explicit needs of users, search engines can discover the information users need by the efficient searching algorithm and show good information retrieval performance. But search engines could not work effectively without specific infor-mation. The birth of the recommender system has greatly alleviated this difficulty. The recommender system is essentially information filtering system, which learns the user’s interests through the user’s file or historical behavior record and predicts the user’s rating or preference for any given information.
The core of the recommender system is the recommendation algorithm [1]. Throughout the development process of the recommender system, the collaborative filtering (CF) algorithm is the earliest and most famous recommendation algorithm. In the past decades, the collaborative filtering algorithm has been successfully ap-plied to many fields of recommenders and performed well [2][3][4]. However, with the increase of the number of users and items, the recommender systems faced with the problems of data sparsity, time consuming and cold start, which make the rec-ommendation quality decline rapidly. To this end, various improved algorithms have appeared in past years [4][5][6][7][8][9] [10]. Although the great progress has achieved recently, the result is still far from the satisfaction. Therefore, this paper proposes an improved similarity based collaborative filtering recommendation em-bedded with user interest changes. The algorithm divides the recommendation weight into time-based data weights and data weights based on item similarity, which reflects the user interest changes and improves the algorithm recommendation accuracy. The experimental results on the Netflix contest open dataset show that the algorithm proposed in this paper can get better recommendation quality compared with the traditional algorithms.
2. ALGORITHM DESCRIPTION AND IMPLEMENTATION
2.1Improvement of Item Similarity
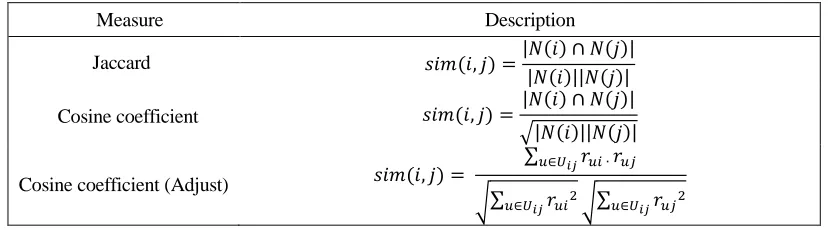
TABLE I. TRADITIONAL PROJECT SIMILARITY CALCULATION METHOD.
Measure Description
Jaccard 𝑠𝑖𝑚(𝑖, 𝑗) =|𝑁(𝑖) ∩ 𝑁(𝑗)|
|𝑁(𝑖)||𝑁(𝑗)|
Cosine coefficient 𝑠𝑖𝑚(𝑖, 𝑗) = |𝑁(𝑖) ∩ 𝑁(𝑗)|
√|𝑁(𝑖)||𝑁(𝑗)|
Cosine coefficient (Adjust) 𝑠𝑖𝑚(𝑖, 𝑗) =
∑𝑢∈𝑈𝑖𝑗𝑟𝑢𝑖 ∙ 𝑟𝑢𝑗
√∑𝑢∈𝑈𝑖𝑗𝑟𝑢𝑖2√∑𝑢∈𝑈𝑖𝑗𝑟𝑢𝑗2
In Table 1, i, j represent any two items in the item set, i≠j. sim(i, j) represents the similarity between items i and j; N(i) represents the user set who rate item i; Uij
represents the set of users who have rated the item i, j at the same time; rui represents
the score of the user u on the item i.
However, the above similarity calculation formula does not consider the fol-lowing issues:
a) Different users have different scoring scales.
b) When the sample size is very small, the item similarity calculation error is very large.
c) Active users should contribute less to similarity than inactive users. In view of the shortcomings of the above traditional algorithms, this paper proposes the following similarity calculation method.
𝑠𝑖𝑚(𝑖, 𝑗) = ∑𝑢∈𝑈𝑖𝑗𝜆𝑢(𝑟𝑢𝑖− 𝜇𝑢)(𝑟𝑢𝑗− 𝜇𝑢) √∑ 𝜆𝑢(𝑟𝑢𝑖− 𝜇𝑢)2
𝑢∈𝑈𝑖𝑗 √∑𝑢∈𝑈𝑖𝑗𝜆𝑢(𝑟𝑢𝑗− 𝜇𝑢)2
(1)
𝜆𝑢= log |𝐼| |𝐼𝑢|
(2)
𝑠𝑖𝑚(𝑖, 𝑗) =𝑚𝑖𝑛{|𝑈𝑖𝑗|, 𝛾}
𝛾 ∙ 𝑠𝑖𝑚(𝑖, 𝑗) (3)
Combining the above formulas (1),( 2), and( 3), we get the improved similarity calculation method in this paper.
2.2Simulation of User Interest Change
Ger-not changing over time linearly. The change shows a trend of fast down at first, as shown in Figure 1.
There are many similarities between user interest change and user forgetting curve, so the user forgetting law can be referenced to the collaborative filtering algo-rithm. The time weight function is used to show the user interest change. This paper uses the following formula to fit the forgetting curve:
Y = ⅇ−αx (x0) (4)
Where, x is the time decay parameter. α is a scale factor. For systems with sig-nificant changes in user interest, α should be larger. x is calculated by the following equation.
𝑥 =ⅆ𝑢𝑖
𝐿𝑢
(5)
dui represents the time difference between the user u first accesses item i and
the last accessed it. Lu represents the time difference between the user u first
ac-cessed the item and the latest access it.
The final time-based data weight calculation formula can be obtained by com-bining formula (4) and (5).
𝑊𝑇(𝑢, 𝑖) = 𝑒−𝛼∙ ⅆ𝑢𝑖𝐿𝑢 (6)
[image:4.612.117.486.352.492.2]
Figure 1. Ebbinghaus Forgetting Curve. Figure 2. User-Item Rating Data Style.
2.3 Recommended Weight Analysis
Suppose the user has accessed the resource set as Iu. By defining a recent time
window T, the item accessed by user u in duration T is set to IuT. For i∈Iu, the degree
of similarity of the item i to the user’s recent interest is calculated by the average of the similarity of the items in the i and the Iut.
W𝑆(𝑢, 𝑖) =∑𝑗∈𝐼𝑢𝑇𝑠𝑖𝑚(𝑖, 𝑗)
|𝐼𝑢𝑇|
(7)
By finding a suitable super-factor b, the equation (6) and (7) can be combined to improve the performance of the algorithm.
𝑊(𝑢, 𝑖) = 𝑏𝑊𝑆(𝑢, 𝑖) + (1 − 𝑏)𝑊𝑇(𝑢, 𝑖) (8)
3. EXPRIMENTS
3.1 Data Set
The authenticity and integrity of the experimental data is crucial to verify the effectiveness of the algorithm. By collecting a large number of online data sets, the Netflix movie dataset and the MovieTweetings movie dataset are selected as the benchmark dataset of the experiment. The data format is shown in Figure 2.
In order to avoid the cold-start problem, we screened 4,432 users in the Netflix movie dataset and 100,000 movies in 4,889 movies. The 969 users rated at least 10 movies. The experimental data set sparsity is approximately at 0.99528. Mov-ieTweetings movie dataset contains 917 users, 5848 movies, 28105 score records. The experimental dataset sparsity is 0.99476. In our experiments, 80% samples of the dataset is randomly selected as the training set, and rest 20% is the test set. The data in the training set is mainly used for the calculation of each step of the algo-rithm and the determination of the parameter s. The data in the test set is mainly used to measure the recommended quality of the algorithm.
3.2 Evaluation Metric
Accuracy: In the TOP-N recommendation list generated by the algorithm, the proportion of the items user has scored in the list. The calculation formula is as fol-lows:
Precision=∑𝑢∈𝑈∑|𝑅(𝑢)∩𝑇(𝑢)||𝑅(𝑢)|
𝑢∈𝑈 (9)
U denotes a set of users, R(u) is a recommendation list for the user based on the behavior of the user on the training set, and T(u) is the list of the users who rated on the test set.
3.3 Experimental Result
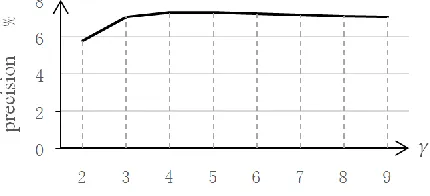
As shown in Figure 3, when γ is equal to 5, the accuracy is the highest 7.34%. Therefore, γ is set to 5.
The values of other parameters are obtained through similar experiments. Due to the limitation of space, we omit the details of the determination experiment for other parameters and give the final results: a=0.1, b=0.1, T=20.
[image:6.612.192.407.173.271.2]
Figure 3 Accuracy Curve vs. γ.
Experiment 2: Comparison experiment. The comparison experiment was carried out with random recommendation, user-based collaborative filtering (UCF) and tra-ditional item-based collaborative filtering (ICF). As shown in Figure 4 it can be seen that the proposed algorithm (ICF-ISIC) is better than the other algorithms by 2%-4% under the optimal parameter values.
Experiment 3: Supplement experiments. The algorithm is applied to the Mov-ieTweetings dataset and compared with traditional ICF and UCF. It can be seen from Fig. 5 that the proposed quality of the proposed algorithm is better than the tra-ditional collaborative filtering recommendation algorithm by 3%-5%. The algorithm is also applied to Wanfang Data platform and gets satisfactory results.
Figure 4 Experimental Results. Figure 5 Supplement experimental results.
4. CONCLUSIONS
[image:6.612.115.491.478.586.2]proposes an improved similarity based collaborative filtering recommendation algo-rithm embedded with user interest change. The penalty factor for active users is in-troduced to calculate the similarity matrix. The forgotten curve is fitted by exponen-tial function, which mimics the user interest change. The final recommendation weight is divided into time-based data weights and similarity based weights. Com-parison experimental results show that the proposed algorithm can improve the recommendation accuracy obviously.
ACKNOWLEDGEMENTS
This work was supported by the National Key Research and Development Program of China under Grant No. 2017YFB1400301,the National Natural Sci-ence Foundation of China Project No. 61902318.
REFERENCES
1. Xiang Liang. 2012. Recommended system practice [M]. Beijing: People's Posts and Telecom-muni-cations Press, 2012.
2. Ma W, Zhang M, Wang C, et al. 2018. Your tweets reveal what you like: Introducing cross-media content information into multi-domain recommendation//Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden, 2018:3484-3490.
3. J. Chen, C. Wang, and J. Wang. 2015. A personalized interest-forgetting markov model for recommendations//Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelli-gence. Austin, USA, 2015: 16-22.
4. Yang Xing-Yu, Li Hua-Ping, Zhang Yu-Bo. 2018. Collaborative filtering algorithm based on clustering and random forests. Computer Engineering and Applications, 2018, 54(16):152-157 (in Chinese).
5. Cha Jiu, Li Zhen-Bo, Xu Gui-Qiong. 2014. An optimised collaborative filtering algorithm based on combined similarity. Computer Applications and Software, 2014, 31(12):323-328(in Chinese). 6. Zhang Jing-Long, Huang Meng-Xing, Zhang Yu, et al. 2018. Collaborative filtering
recommen-dation algorithm based on tag optimization. Application Research of Computers, 2018, 35(10):2916-2919 (in Chinese).
7. Xing Chun-Xiao, Gao Feng-Rong, Zhan Si-Nan, et al. 2007. A Collaborative Filtering Recom-mendation Algorithm Incorporated with User Interest Change. Journal of Computer Research
and Development, 2007.44(2): 296-301(in Chinese).
8. Wang H, Wang N, Yeung D Y. 2015. Collaborative deep learning for recommender sys-tems//Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Dis-covery and Data Mining. Sydney, Australia, 2015:1235-1244.
9. Zhang F, Yuan NJ, Lian D, et al. 2016. Collaborative knowledge base embedding for recom-mender systems//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, USA, 2016:353-362.