warwick.ac.uk/lib-publications
Manuscript version: Author’s Accepted Manuscript
The version presented in WRAP is the author’s accepted manuscript and may differ from the
published version or Version of Record.
Persistent WRAP URL:
http://wrap.warwick.ac.uk/107947
How to cite:
Please refer to published version for the most recent bibliographic citation information.
If a published version is known of, the repository item page linked to above, will contain
details on accessing it.
Copyright and reuse:
The Warwick Research Archive Portal (WRAP) makes this work by researchers of the
University of Warwick available open access under the following conditions.
Copyright © and all moral rights to the version of the paper presented here belong to the
individual author(s) and/or other copyright owners. To the extent reasonable and
practicable the material made available in WRAP has been checked for eligibility before
being made available.
Copies of full items can be used for personal research or study, educational, or not-for-profit
purposes without prior permission or charge. Provided that the authors, title and full
bibliographic details are credited, a hyperlink and/or URL is given for the original metadata
page and the content is not changed in any way.
Publisher’s statement:
Please refer to the repository item page, publisher’s statement section, for further
information.
1
Dense 3D Object Reconstruction
from a Single Depth View
Bo Yang, Stefano Rosa, Andrew Markham, Niki Trigoni, Hongkai Wen
*Abstract—In this paper, we propose a novel approach,3D-RecGAN++, which reconstructs the complete 3D structure of a given object
from a single arbitrary depth view using generative adversarial networks. Unlike existing work which typically requires multiple views of the same object or class labels to recover the full 3D geometry, the proposed 3D-RecGAN++ only takes the voxel grid representation of a depth view of the object as input, and is able to generate the complete 3D occupancy grid with a high resolution of2563
by recovering the occluded/missing regions. The key idea is to combine the generative capabilities of 3D encoder-decoder and the conditional adversarial networks framework, to infer accurate and fine-grained 3D structures of objects in high-dimensional voxel space. Extensive experiments on large synthetic datasets and real-world Kinect datasets show that the proposed 3D-RecGAN++ significantly outperforms the state of the art in single view 3D object reconstruction, and is able to reconstruct unseen types of objects.
Index Terms—3D Reconstruction, Shape Completion, Shape inpainting, Single Depth View, Adversarial Learning, Conditional GAN.
F
1
I
NTRODUCTIONT
Oreconstruct the complete and precise 3D geometry of an object is essential for many graphics and robotics applications, from AR/VR [1] and semantic understanding, to object deformation [2], robot grasping [3] and obstacle avoidance. Classic approaches use the off-the-shelf low-cost depth sensing devices such as Kinect and RealSense cameras to recover the 3D shape of an object from captured depth images. Those approaches typically require multiple depth images from different viewing angles of an object to estimate the complete 3D structure [4] [5] [6]. However, in practice it is not always feasible to scan all surfaces of an object before reconstruction, which leads to incomplete 3D shapes with occluded regions and large holes. In addition, acquiring and processing multiple depth views require more computing power, which is not ideal in many applications that require real-time performance.We aim to tackle the problem of estimating the complete 3D structure of an object using a single depth view. This is a very challenging task, since the partial observation of the object (i.e., a depth image from one viewing angle) can be theoretically associated with an infinite number of possible 3D models. Traditional reconstruction approaches typically use interpolation techniques such as plane fitting, Laplacian hole filling [7] [8], or Poisson surface estimation [9] [10] to infer the underlying 3D structure. However, they can only recover very limited occluded or missing regions,e.g., small holes or gaps due to quantization artifacts, sensor noise and insufficient geometry information.
Interestingly, humans are surprisingly good at solving such ambiguity by implicitly leveraging prior knowledge.
• Bo Yang, Stefano Rosa, Andrew Markham and Niki Trigoni are with the Department of Computer Science, University of Oxford, UK.
E-mail:{bo.yang,stefano.rosa,andrew.markham,niki.trigoni}@cs.ox.ac.uk • Corresponding to Hongkai Wen, who is with the Department of Computer
Science, University of Warwick, UK. E-mail: [email protected]
For example, given a view of a chair with two rear legs occluded by front legs, humans are easily able to guess the most likely shape behind the visible parts. Recent advances in deep neural networks and data driven approaches show promising results in dealing with such a task.
In this paper, we aim to acquire the complete and high-resolution 3D shape of an object given a single depth view. By leveraging the high performance of 3D convolutional neural nets and large open datasets of 3D models, our ap-proach learns a smooth function that maps a 2.5D view to a complete and dense 3D shape. In particular, we train an end-to-end model which estimates full volumetric occupancy from a single 2.5D depth view of an object.
While state-of-the-art deep learning approaches [11] [12] [3] for 3D shape reconstruction from a single depth view achieve encouraging results, they are limited to very small resolutions, typically at the scale of 323 voxel grids. As a result, the learnt 3D structure tends to be coarse and inaccurate. In order to generate higher resolution 3D objects with efficient computation, Octree representation has been recently introduced in [13] [14] [15]. However, increasing the density of output 3D shapes would also inevitably pose a great challenge to learn the geometric details for high resolution 3D structures, which has yet to be explored.
Recently, deep generative models achieve impressive success in modeling complex high-dimensional data dis-tributions, among which Generative Adversarial Networks (GANs) [16] and Variational Autoencoders (VAEs) [17] emerge as two powerful frameworks for generative learn-ing, including image and text generation [18] [19], and latent space learning [20] [21]. In the past few years, a number of works [22] [23] [24] [25] applied such generative models to learn latent space to represent 3D object shapes, in order to solve tasks such as new image generation, object classification, recognition and shape retrieval.
In this paper, we propose 3D-RecGAN++, a simple yet effective model that combines a skip-connected 3D
decoder with adversarial learning to generate a complete and fine-grained 3D structure conditioned on a single 2.5D view. Particularly, our model firstly encodes the 2.5D view to a compressed latent representation which implicitly rep-resents general 3D geometric structures, then decodes it back to the most likely full 3D shape. Skip-connections are applied between the encoder and decoder to preserve high frequency information. The rough 3D shape is then fed into a conditional discriminator which is adversarially trained to distinguish whether the coarse 3D structure is plausible or not. The encoder-decoder is able to approximate the corresponding shape, while the adversarial training tends to add fine details to the estimated shape. To ensure the final generated 3D shape corresponds to the input single partial 2.5D view, adversarial training of our model is based on a conditional GAN [26] instead of random guessing. The above network excels the competing approaches [3] [12] [27], which either use a single fully connected layer [3], a low capacity decoder without adversarial learning [12], or the multi-stage and ineffective LSTMs [27] to estimate the full 3D shapes.
Our contributions are as follows:
(1) We propose a simple yet effective model to recon-struct the complete and accurate 3D recon-structure using a single arbitrary depth view. Particularly, our model takes a simple occupancy grid map as input without requiring object class labels or any annotations, while predicting a compelling shape within a high resolution of 2563 voxel grid. By
drawing on both 3D encoder-decoder and adversarial learn-ing, our approach is end-to-end trainable with high level of generality.
(2) We exploit conditional adversarial training to refine the 3D shape estimated by the encoder-decoder. Our con-tribution here is that we use the mean value of a latent vector feature, instead of a single scalar, as the output of the discriminator to stabilize GAN training.
(3) We conduct extensive experiments for single category and multi-category object reconstruction, outperforming the state of the art. Importantly, our approach is also able to generalize to previously unseen object categories. At last, our model also performances robustly on real-world data, after being trained purely on synthetic datasets.
(4) To the best of our knowledge, there are no good open datasets which have the ground truth for occluded/missing parts and holes for each 2.5D view in real-world scenar-ios. We therefore collect and release our real-world testing dataset to the community.
A preliminary version of this work has been published in ICCV 2017 workshops [28]. Our code and data are available at:https://github.com/Yang7879/3D-RecGAN-extended
2
R
ELATEDW
ORKWe review different pipelines for 3D reconstruction or shape completion. Both conventional geometry based techniques and the state of the art deep learning approaches are cov-ered.
(1)3D Model/Shape Completion. Monszpartet al. use plane fitting to complete small missing regions in [29], while shape symmetry is applied in [30] [31] [32] [33] [34] to fill in holes. Although these methods show good results,
relying on predefined geometric regularities fundamentally limits the structure space to hand-crafted shapes. Besides, these approaches are likely to fail when missing or occluded regions are relatively big. Another similar fitting pipeline is to leverage database priors. Given a partial shape input, an identical or most likely 3D model is retrieved and aligned with the partial scan in [35] [36] [37] [38] [39] [40]. However, these approaches explicitly assume the database contains identical or very similar shapes, thus being unable to gener-alize to novel objects or categories.
(2)Multiple RGB/Depth Images Reconstruction. Tradi-tionally, 3D dense reconstruction in SfM and visual SLAM requires a collection of RGB images [41]. Geometric shape is recovered by dense feature extraction and matching [42], or by directly minimizing reprojection errors [43] from color images. Shape priors are also concurrently leveraged with the traditional multi-view reconstruction for dense object shape estimation in [44] [45] [46]. Recently, deep neural nets are designed to learn the 3D shape from multiple RGB images in [47] [48] [49] [50] [51] [52]. However, resolution of the recovered occupancy shape is usually up to a small scale of323. With the advancement of depth sensors, depth images are also used to recover the object shape. Classic approaches usually fuse multiple depth images through iterative closest point (ICP) algorithms [4] [53] [54], while recent work [14] learns the 3D shape using deep neural nets from multiple depth views.
(3) Single RGB Image Reconstruction. Predicting a complete 3D object model from a single view is a long-standing and extremely challenging task. When reconstruct-ing a specific object category, model templates can be used. For example, morphable 3D models are exploited for face recovery [55] [56]. This concept was extended to reconstruct simple objects in [57]. For general and complex object re-construction from a single RGB image, recent works [58] [59] [60] aim to infer 3D shapes using multiple RGB images for weak supervision. Shape prior knowledge is utilized in [61] [62] [63] for shape estimation. To recover high resolution 3D shapes, Octree representation is introduced in [13] [14] [15] to save computation, while an inverse discrete cosine transform (IDCT) technique is proposed in [64]. Lin et al. [65] designed a pseudo-renderer to predict dense 3D shapes, while 2.5D sketches and dense 3D shapes are sequentially estimated from a single RGB image in [66].
(4) Single Depth View Reconstruction. The task of reconstruction from a single depth view is to complete the occluded 3D structures behind the visible parts. 3D ShapeNets [11] is among the early work using deep neural nets to estimate 3D shapes from a single depth view. Firman
et al. [67] trained a random decision forest to infer unknown voxels. Originally designed for shape denoising, VConv-DAE [1] can also be used for shape completion. To facilitate robotic grasping, Varley et al. proposed a neural network to infer the full 3D shape from a single depth view in [3]. However, all these approaches are only able to generate low resolution voxel grids which are less than403
3
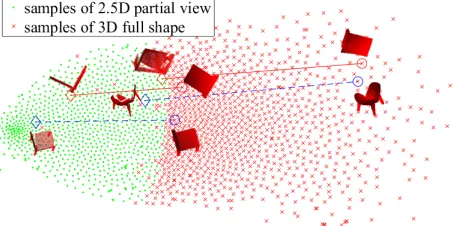
Fig. 1: t-SNE embeddings of 2.5D partial views and 3D complete shapes of multiple object categories.
annotations for supervised scene completion and semantic label prediction. Both [27] and [69] were originally designed for shape inpainting instead of directly reconstructing the complete 3D structure from a partial depth view. The re-cent 3D-PRNN [70] predicts simple shape primitives using RNNs, but the estimated shapes do not have finer geometric details.
(5) Deep Generative Frameworks. Deep generative frameworks, such as VAEs [17] and GANs [16], have achieved impressive success in image super-resolution [71], image generation [19], text to image synthesis [72], etc. VAE and GAN are further combined in [73] and achieve compelling results in learning visual features. Recently, gen-erative networks are applied in [74] [75] [76] [25] to generate low resolution 3D structures. However, incorporating gen-erative adversarial learning to estimate high resolution 3D shapes is not straightforward, as it is difficult to generate samples for high dimensional and complex data distribu-tions [77] and this may lead to the instability of adversarial generation.
3
3D-R
ECGAN++
3.1 Overview
Our method aims to estimate a complete and dense 3D structure of an object, which only takes an arbitrary single 2.5D depth view as input. The output 3D shape is auto-matically aligned with the corresponding 2.5D partial view. To achieve this task, each object model is represented by a high resolution 3D voxel grid. We use the simple occupancy grid for shape encoding, where1represents an occupied cell and0an empty cell. Specifically, the input 2.5D partial view, denoted asx, is a643occupancy grid, while the output 3D
shape, denoted asy, is a high resolution2563 probabilistic voxel grid. The input partial shape is directly calculated from a single depth image given camera parameters. We use the ground truth dense 3D shape with aligned orientation as same as the input partial 2.5D depth view to supervise our network.
To generate ground truth training and evaluation pairs, we virtually scan 3D objects from ShapeNet [78]. Figure 1 is the t-SNE visualization [79] of partial 2.5D views and the corresponding full 3D shapes for multiple general chair and bed models. Each green dot represents the t-SNE embedding of a 2.5D view, whilst a red dot is the embedding of the cor-responding 3D shape. It can be seen that multiple categories inherently have similar 2.5D to 3D mapping relationships. Essentially, our neural network is to learn a smooth function,
encoder decoder
conditional discriminator
U-net
input 2.5D view
true full 3D shape
re
al
re
const
ruc
ti
on
fa
ke
re
const
ruc
ti
on
x
concat
concat
[image:4.612.318.562.46.211.2]loss up-sampling y
Fig. 2: Overview of the network architecture for training.
encoder decoder U-net
input
2.5D view
x
up-samplingy
Fig. 3: Overview of the network architecture for testing.
denoted asf, which maps green dots to red dots as close as possible in high dimensional space as shown in Equation 1. The functionf is parametrized by neural layers in general.
y=f(x)
x∈Z643, where Z={0,1} (1)
After generating training pairs, we feed them into our network. The first part of our network loosely follows the idea of a 3D encoder-decoder with the U-net connections [80]. The skip-connected encoder-decoder serves as an ini-tial coarse generator which is followed by an up-sampling module to further generate a higher resolution 3D shape within a2563voxel grid. This whole generator learns a
cor-relation between partial and complete 3D structures. With the supervision of complete 3D labels, the generator is able to learn a functionf and infer a reasonable 3D shape given a brand new partial 2.5D view. During testing, however, the results tend to be grainy and without fine details.
To address this issue, in the training phase, the re-constructed 3D shape from the generator is further fed into a conditional discriminator to verify its plausibility. In particular, a partial 2.5D input view is paired with its corresponding complete 3D shape, which is called the ‘real reconstruction’, while the partial 2.5D view is paired with its corresponding output 3D shape from generator, which is called the ‘fake reconstruction’. The discriminator aims to discriminate all ‘fake reconstruction’ from ‘real recon-struction’. In the original GAN framework [16], the task of the discriminator is to simply classify real and fake in-puts, but its Jensen-Shannon divergence-based loss function is difficult to converge. The recent WGAN [77] leverages Wasserstein distance with weight clipping as a loss function to stabilize the training procedure, whilst the extended work WGAN-GP [81] further improves the training process using a gradient penalty with respect to its input. In our 3D-RecGAN++, we apply WGAN-GP as the loss function on top of the mean feature of our conditional discriminator, which guarantees fast and stable convergence. The overall network architecture for training is shown in Figure 2, while the testing phase only needs the well trained generator as shown in Figure 3.
[image:4.612.61.293.47.160.2]phase, our 3D-RecGAN++ firstly leverages a skip-connected encoder-decoder together with an up-sampling module to generate a reasonable ‘fake reconstruction’ within a high resolution occupancy grid, then applies adversarial learning to refine the ‘fake reconstruction’ to make it as similar to ‘real reconstruction’ by jointly updating parameters of the generator. In the testing phase, given a novel 2.5D view as input, the jointly trained generator is able to recover a full 3D shape with satisfactory accuracy, while the discriminator is no longer used.
3.2 Architecture
Figure 4 shows the detailed architecture of our proposed 3D-RecGAN++. It consists of two main networks: the generator as in Figure 4a and the discriminator as in Figure 4b.
The generator consists of a skip-connected encoder-decoder and an up-sampling module. Unlike the vanilla GAN generator which generates data from arbitrary la-tent distributions, our 3D-RecGAN++ generator synthesizes data from 2.5D views. Particularly, the encoder has five 3D convolutional layers, each of which has a bank of4×4×4
filters with strides of1×1×1, followed by a leaky ReLU activation function and a max pooling layer with2×2×2
filters and strides of2×2×2. The number of output channels of max pooling layer starts with 64, doubling at each sub-sequent layer and ends up with 512. The encoder is lastly followed by two fully-connected layers to embed semantic information into a latent space. The decoder is composed of five symmetric up-convolutional layers which are followed by ReLU activations. Skip-connections between encoder and decoder guarantee propagation of local structures of the input 2.5D view. The skip-connected encoder-decoder is fol-lowed by the up-sampling module which simply consists of two layers of up-convolutional layers as detailed in Figure 4a. This simple up-sampling module directly upgrades the output 3D shape to a higher resolution of 2563 without
requiring complex network design and operations. It should be noted that without the two fully connected layers and skip-connections, the vanilla encoder-decoder would be un-able to learn reasonun-able complete 3D structures as the latent space is limited and the local structure is not preserved. The loss function and optimization methods are described in Section 3.4.
The discriminatoraims to distinguish whether the esti-mated 3D shapes are plausible or not. Based on the condi-tional GAN, the discriminator takes both real reconstruction pairs and fake reconstruction pairs as input. In particular, it consists of six 3D convolutional layers, the first of which concatenates the generated 3D shape (i.e., a2563
voxel grid) and the input 2.5D partial view (i.e., a 643 voxel grid), reshaped as a256×256×4tensor. The reshaping process is done straightforwardly using Tensorflow ‘tf.reshape()’. Basically, this is to inject the condition information with a matched tensor dimension, and then leave the network itself to learn useful features from this condition input. Each convolutional layer has a bank of 4 ×4×4 filters with strides of 2×2 ×2, followed by a ReLU activation function except for the last layer which is followed by a sigmoid activation function. The number of output channels of the convolutional layers starts with 8, doubling at each
subsequent layer and ends up with 256. The output of the last neural layer is reshaped as a latent vector which is the latent feature of discriminator, denoted asm.
3.3 Mean Feature for Discriminator
At the early training stage of GAN, as the high dimensional real and fake distributions may not overlap, the discrimina-tor can separate them perfectly using a single scalar output, which is analyzed in [82]. In our experiments, due to the extremely high dimensionality (i.e.,2563+ 643dimensions)
of the input data pair, the WGAN-GP always crashes in the early 3 epochs if we use a standard fully-connected layer followed by a single scalar as the final output for the discriminator.
To stabilize training, we propose to use the mean feature m (i.e., mean of a vector feature m) for discrimination. As the mean vector feature tends to capture more infor-mation from the input overall, it is more difficult for the discriminator to easily distinguish between fake or real inputs. This enables useful information to back-propagate to the generator. The final output of the discriminatorD()is defined as:
m=E(m) (2)
Mean feature matching is also studied and applied in [83] [84] to stabilize GAN. However, Bao et al. [83] mini-mize the L2 loss of the mean feature, as well as the
orig-inal Jensen-Shannon divergence-based loss [16], requiring hyper-parameter tuning to balance the two losses. By com-parison, in our 3D-RecGAN++ setting, the mean feature of discriminator is directly followed by the existing WGAN-GP loss, which is simple yet effective to stabilize the adversarial training.
Overall, our discriminator learns to distinguish the dis-tributions of mean feature of fake and real reconstructions, while the generator is trained to make the two mean feature distributions as similar as possible.
3.4 Objectives
The objective function of 3D-RecGAN++ includes two main parts: an object reconstruction loss`enfor the generator; the
objective function`ganfor the conditional GAN.
(1)`enFor the generator, inspired by [85], we use
mod-ified binary cross-entropy loss function instead of the stan-dard version. The stanstan-dard binary cross-entropy weights both false positive and false negative results equally. How-ever, most of the voxel grid tends to be empty, so the net-work easily gets a false positive estimation. In this regard, we impose a higher penalty on false positive results than on false negatives. Particularly, a weight hyper-parameterα is assigned to false positives, with (1-α) for false negative results, as shown in Equation 3.
`en=
1
N
N
X
i=1
−αy¯ilog(yi)−(1−α)(1−y¯i) log(1−yi)
(3)
wherey¯i is the target value {0,1}of a specificithvoxel in
the ground truth voxel gridy¯, andyi is the corresponding
5 concat 643 1 channel 323 64 channels 163 128 channels 83 256 channels 43 512 channels 32768 2000 32768 43 512 channels 8
3 256 channels 16
3
128 channels 32 3
64 channels 64 3
16 channels 128 3
8 channels 256 3 1 channel concat concat concat concat 43 conv lrelu 23 maxpool
43 conv lrelu 23
maxpool 43 conv
lrelu 23
maxpool 43 conv
lrelu 23 maxpool flatten dense relu dense relu
43 deconv relu reshape
43 deconv relu
43 deconv relu
43 deconv relu
43 deconv relu
43 deconv relu
y
x
256x256x4 1 channel fake reconstruction real reconstruction ground truth 128x128x130 8 channels 643 1 channely
2563 1 channel 256x256x260 1 channel43 conv
lrelu 43 conv lrelu 4 3 conv lrelu 4 3 conv lrelu 4
3 conv lrelu
43 conv lrelu flatten 64x64x65 16 channels 32x32x33 32 channels 16x16x17 64 channels 8x8x9 128 channels 4x4x5 256 channels
x
loss 20480 reshape 2563 1 channel up-sampling module(a) Generator for 3D shape estimation from a single depth view.
mean feature flatten 4x4x5 256 channels concat 643 1 channel 323 64 channels 163 128 channels 83 256 channels 43 512 channels 32768 2000 32768 43 512 channels 8
3 256 channels 16
3 128 channels 32
3
64 channels 64 3
16 channels 128 3
8 channels 256 3 1 channel concat concat concat concat 43 conv
lrelu 23 maxpool
43 conv
lrelu 23 maxpool
43 conv
lrelu 23 maxpool
43 conv
lrelu 23 maxpool
flatten dense relu
dense relu
43 deconv
relu
reshape
43 deconv
relu
43 deconv
relu
43 deconv
relu
43 deconv
relu
43 deconv
relu y x 256x256x4 1 channel fake reconstruction real reconstruction ground truth 128x128x130 8 channels 643 1 channel y 2563 1 channel 256x256x260 1 channel
43 conv
lrelu 43 conv
lrelu 4
3 conv
lrelu 4
3 conv
lrelu 4
3 conv
lrelu 43 conv
lrelu 64x64x65 16 channels 32x32x33 32 channels 16x16x17 64 channels loss 8x8x9 128 channels x 20480 reshape 2563 1 channel up-sampling module m m
[image:6.612.46.558.47.333.2](b) Discriminator for 3D shape refinement.
Fig. 4: Detailed architecture of 3D-RecGAN++, showing the two main building blocks. Note that, although these are shown as two separate modules, they are trained end-to-end.
(2) `gan For the discriminator, we leverage the state of
the art WGAN-GP loss functions. Unlike the original GAN loss function which presents an overall loss for both real and fake inputs, we separately represent the loss function `ggan in Equation 4 for generating fake reconstruction pairs and `d
gan in Equation 5 for discriminating fake and real
reconstruction pairs. Detailed definitions and derivation of the loss functions can be found in [77] [81], but we modify them for our conditional GAN settings.
`ggan=−E
D(y|x)
(4)
`dgan=E
D(y|x) −E
D(y|x¯ )
+λE
∇yˆD(y|xˆ )
2−1
2
(5)
whereyˆ=y¯+ (1−)y, ∼U[0,1],xis the input partial depth view,yis the corresponding output of the generator, ¯
yis the corresponding ground truth.λcontrols the trade-off between optimizing the gradient penalty and the original objective in WGAN.
For the generator in our 3D-RecGAN++ network, there are two loss functions, `en and `ggan, to optimize. As we
discussed in Section 3.1, minimizing`en tends to learn the
overall 3D shapes, whilst minimizing`g
gan estimates more
plausible 3D structures conditioned on input 2.5D views. To minimize `d
gan is to improve the performance of
discrimi-nator to distinguish fake and real reconstruction pairs. To jointly optimize the generator, we assign weightsβ to `en
and(1−β)to`g
gan. Overall, the loss functions for generator
and discriminator are as follows:
`g=β`en+ (1−β)`ggan (6)
`d=`dgan (7)
3.5 Training
We adopt an end-to-end training procedure for the whole network. To simultaneously optimize both generator and discriminator, we alternate between one gradient decent step on the discriminator and then one step on the generator. For the WGAN-GP,λis set as 10 for gradient penalty as in [81].αends up as 0.85 for our modified cross entropy loss function, whileβis 0.2 for the joint loss function`g.
The Adam solver [86] is used for both discriminator and generator with a batch size of 4. The other three Adam parameters are set to default values. Learning rate is set to
5e−5
for the discriminator and1e−4
for the generator in all epochs. As we do not use dropout or batch normalization, the testing phase is exactly the same as the training stage. The whole network is trained on a single Titan X GPU from scratch.
3.6 Data Synthesis
For the task of 3D dense reconstruction from a single depth view, obtaining a large amount of training data is an obsta-cle. Existing real RGB-D datasets for surface reconstruction suffer from occlusions and missing data and there is no ground truth of complete and high resolution 2563 3D
shapes for each view. The recent work [12] synthesizes data for 3D object completion, but the object resolution is only up to1283.
are selected for our experiments. As some CAD models in ShapeNet may not be watertight, in our ray tracing based voxelization algorithm, if a specific point is inside of more than 5 faces along X, Y and Z axes, that point is deemed to be interior of the object and set as ‘1’, otherwise ‘0’.
For each category, to generatetraining data, around 220 CAD models are randomly selected. For each CAD model, we create a virtual depth camera to scan it from 125 different viewing angles, 5 uniformly sampled views for each of roll, pitch and yaw space ranging from0∼2πindividually. Note that, the viewing angles for all 3D models are the same for simplicity. For each virtual scan, both a depth image and the corresponding complete 3D voxelized structure are generated with regard to the same camera angle. That depth image is simultaneously transformed to a point cloud using virtual camera parameters [87] followed by voxelization which generates a partial 2.5D voxel grid. Then a pair of partial 2.5D view and the complete 3D shape is synthesized. Overall, around 26K training pairs are generated for each 3D object category.
For each category, to synthesizetesting data, around 40 CAD models are randomly selected. For each CAD model, two groups of testing data are generated. Group 1, each model is virtually scanned from 125 viewing angles which are the same as used in training dataset. Around 4.5k testing pairs are generated in total. This group of testing dataset is denoted as same viewing (SV) angles testing dataset. Group 2, each model is virtually scanned from 216 different viewing angles, 6 uniformly sampled views from each of roll, pitch and yaw space ranging from0∼2πindividually. Note that, these viewing angles for all testing 3D models are completely different from training pairs. Around 8k testing pairs are generated in total. This group of testing dataset is denoted as cross viewing (CV) angles testing dataset. Similarly, we also generate around 1.5k SV and 2.5k CV validation datasplit from another 12 CAD models, which are used for hyperparameter searching.
As our network is initially designed to predict an aligned full 3D model given a depth image from an arbitrary view-ing angle, these two SV and CV testview-ing datasets are gen-erated separately to evaluate the viewing angle robustness and generality of our model.
Besides the large quantity of synthesized data, we also collect a real-world dataset in order to test the proposed network in a realistic scenario. We use a Microsoft Kinect camera to manually scan a total of 20 object instances belonging to 4 classes {bench, chair, couch, table}, with 5 instances per class from different environments, including offices, homes, and outdoor university parks. For each object we acquire RGB-D images of the object from multiple angles by moving the camera around the object. Then, we use the dense visual SLAM algorithm ElasticFusion [54] in order to reconstruct the full 3D shape of each object, as well as the camera pose in each scan.
[image:7.612.314.562.43.159.2]We sample 50 random views from the camera trajectory, and for each one we obtain the depth image and the rel-ative camera pose. In each depth image the 3D object is segmented from the background, using a combination of floor removal and manual segmentation. We finally generate ground truth information by aligning the full 3D objects with the partial 2.5D views.
Fig. 5: An example of ElasticFusion for generating real world data. Left: reconstructed object; sampled camera poses are shown in black. Right: Input RGB, depth image and seg-mented depth image.
It should be noted that, due to noise and quantization artifacts of low-cost RGB-D sensors, and the inaccuracy of the SLAM algorithm, the full 3D ground truth is not 100% accurate, but can still be used as a reasonable approxima-tion. The real-world dataset highlights the challenges related to shape reconstruction from realistic data: noisy depth estimates, missing depth information, depth quantization. In addition, some of the objects are acquired outdoors (e.g., bench), which is challenging for the near-infrared depth sensor of the Micorsoft Kinect. However, we argue that a real-world benchmark for shape reconstruction is necessary for a thorough validation of future approaches. Figure 5 shows an example of the reconstructed object and camera poses in ElasticFusion.
4
E
VALUATIONIn this section, we evaluate our 3D-RecGAN++ with com-parison to the state of the art approaches and an ablation study to fully investigate the proposed network.
4.1 Metrics
To evaluate the performance of 3D reconstruction, we con-sider two metrics. The first metric is the mean Intersection-over-Union (IoU) between predicted 3D voxel grids and their ground truth. The IoU for an individual voxel grid is formally defined as follows:
IoU = PN
i=1
I(yi> p)∗I( ¯yi)
PN
i=1
h
I I(yi> p) +I( ¯yi)
i
where I(·)is an indicator function,yiis the predicted value
for the ith voxel, y¯
i is the corresponding ground truth, p
is the threshold for voxelization, N is the total number of voxels in a whole voxel grid. In all our experiments, p is searched using the validation data split per category for each approach. Particularly,pis searched in the range
[0.1,0.9]with a step size0.05using the validation datasets. The higher the IoU value, the better the reconstruction of a 3D model.
The second metric is the mean value of standard Cross-Entropy loss (CE) between a reconstructed shape and the ground truth 3D model. It is formally defined as:
CE=−1
N
N
X
i=1
¯
yilog(yi) + (1−y¯i) log(1−yi)
7
where yi,y¯i andN are the same as defined in above IoU.
The lower CE value is, the closer the prediction to be either ‘1’ or ‘0’, the more robust and confident the 3D predictions are.
We also considered the Chamfer Distance (CD) or Earth Mover’s Distance (EMD) as an additional metric. However, it is computationally heavy to calculate the distance between two high resolution voxel grids due to the large number of points. In our experiments, it takes nearly 2 minutes to calculate either CD or EMD between two 2563
shapes on a single Titan X GPU. Although the2563dense shapes can be downsampled to sparse point clouds on object surfaces to quickly compute CD or EMD, the geometric details are inevitably lost due to the extreme downsampling process. Therefore, we did not use CD or EMD for evaluation in our experiments.
4.2 Competing Approaches
We compare against three state of the art deep learning based approaches for single depth view reconstruction. We also compare against the generator alone in our network,
i.e., without the GAN, named 3D-RecAE for short.
(1)3D-EPN.In [12], Daiet al. proposed a neural network, called “3D-EPN”, to reconstruct the 3D shape up to a323
voxel grid, after which a high resolution shape is retrieved from an existing 3D shape database, called “Shape Synthe-sis”. In our experiment, we only compared with their neural network (i.e., 3D-EPN) performance because we do not have an existing shape database for similar shape retrieval during testing. Besides, occupancy grid representation is used for the network training and testing.
(2) Varley et al. In [3], a network was designed to complete the 3D shape from a single 2.5D depth view for robot grasping. The output of their network is a403
voxel grid.
Note that, the low resolution voxel grids generated by 3D-EPN and Varleyet al. are all upsampled to2563 voxel grids using trilinear interpolation before calculating the IoU and CE metrics. The linear upsampling is a widely used post-processing technique for fair comparison in cases where the output resolution is not identical [13]. However, as both 3D-EPN and Varley et al. are trained using lower resolution voxel grids for supervision, while the below Han et al. and our 3D-RecGAN++ are trained using 2563
shapes for supervision, it is not strictly fair comparison in this regard. Considering both 3D-EPN and Varleyet al. are among the early works and also solid competing approaches regarding the single depth view reconstruction task, we therefore include them as baselines.
(3)Hanet al.In [27], a global structure inference network and a local geometry refinement network are proposed to complete a high resolution shape from a noisy shape. The network is not originally designed for single depth view reconstruction, but its output shape is up to a 2563
voxel grid and is comparable to our network. For fair comparison, the same occupancy grid representation is used for their network. It should be noted that [27] involves convoluted designs, thus the training procedure is slower and less efficient due to many LSTMs integrated.
(4)3D-RecAE.As for our 3D-RecGAN++, we remove the discriminator and only keep the generator to infer the com-plete 3D shape from a single depth view. This comparison illustrates the benefits of adversarial learning.
4.3 Single-category Results
(1)Results.All networks are separately trained and tested on four different categories, {bench, chair, couch, table}, with the same network configuration. Table 1 shows the IoU and CE loss of all methods on the testing dataset with same viewing angles on2563voxel grids, while Table 2 shows the
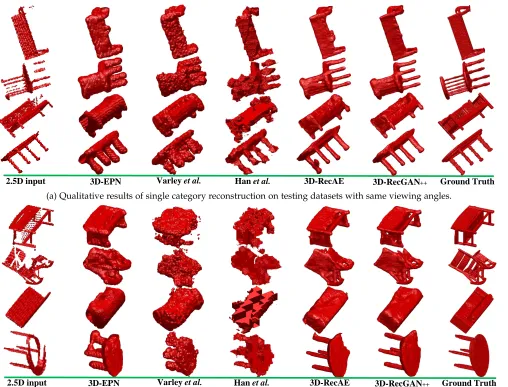
IoU and CE loss comparison on testing dataset with cross viewing angles. Figure 6 shows the qualitative results of single category reconstruction on testing datasets with same and cross viewing angles. The meshgrid function in Matlab is used to plot all 3D shapes for better visualization.
(2)Analysis.Both 3D-RecGAN++ and 3D-RecAE signif-icantly outperform the competing approaches in terms of IoU and CE loss on both the SV and CV testing datasets for dense 3D shape reconstruction (2563voxel grids). Although our approach is trained on depth input with a limited set of viewing angles, it still performs well to predict aligned 3D shapes from novel viewing angles. The 3D shapes generated by 3D-RecGAN++ and 3D-RecAE are much more visually compelling than others.
Compared with 3D-RecAE, 3D-RecGAN++ achieves bet-ter IoU scores and smaller CE loss. Basically, adversarial learning of the discriminator serves as a regularizer for fine-grained 3D shape estimation, which enables the output of 3D-RecGAN++ to be more robust and confident. We also notice that the increase of 3D-RecGAN++ in IoU and CE scores is not dramatic compared with 3D-RecAE. This is primarily because the main object shape can be reasonably predicted by 3D-RecAE, while the finer geometric details estimated by 3D-RecGAN++ are usually smaller parts of the whole object shape. Therefore, 3D-RecGAN++ only obtains a reasonable better IoU and CE scores than 3D-RecAE. The
4throw of Figure 6a shows a good example in terms of finer
geometric details prediction of 3D-RecGAN++. In fact, in all the remaining experiments, 3D-RecGAN++ is constantly, but not significantly, better than 3D-RecAE.
TABLE 1: Per-category IoU and CE loss on testing dataset with same viewing angles (2563voxel grids).
IoU CE Loss bench chair couch table bench chair couch table 3D-EPN [12] 0.423 0.488 0.631 0.508 0.087 0.105 0.144 0.101 Varleyet al. [3] 0.227 0.317 0.544 0.233 0.111 0.157 0.195 0.191 Hanet al. [27] 0.441 0.426 0.446 0.499 0.045 0.081 0.165 0.058
3D-RecAE (ours) 0.577 0.641 0.749 0.675 0.036 0.063 0.067 0.043
3D-RecGAN++ (ours) 0.580 0.647 0.753 0.679 0.034 0.060 0.066 0.040
TABLE 2: Per-category IoU and CE loss on testing dataset with cross viewing angles (2563voxel grids).
IoU CE Loss bench chair couch table bench chair couch table 3D-EPN [12] 0.408 0.446 0.572 0.482 0.086 0.112 0.163 0.103 Varleyet al. [3] 0.185 0.278 0.475 0.187 0.108 0.171 0.210 0.186 Hanet al. [27] 0.439 0.426 0.455 0.482 0.047 0.090 0.163 0.060
3D-RecAE (ours) 0.524 0.588 0.639 0.610 0.045 0.079 0.117 0.058
Per cat
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
(a) Qualitative results of single category reconstruction on testing datasets with same viewing angles.
Per cat
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
[image:9.612.57.565.39.426.2](b) Qualitative results of single category reconstruction on testing datasets with cross viewing angles.
Fig. 6: Qualitative results of single category reconstruction on testing datasets with same and cross viewing angles.
4.4 Multi-category Results
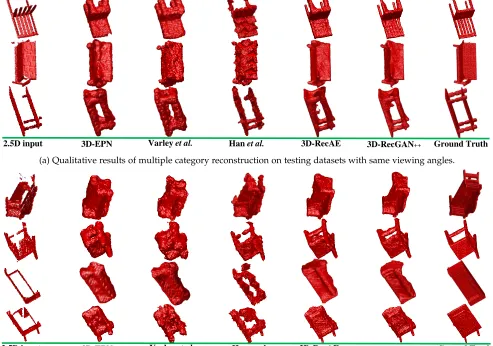
(1)Results. All networks are also trained and tested on multiple categories without being given any class labels. The networks are trained on four categories:{bench, chair, couch, table}; and then tested separately on individual categories. Table 3 shows the IoU and CE loss comparison of all methods on testing dataset with same viewing angles for dense shape reconstruction, while Table 4 shows the IoU and CE loss comparison on testing dataset with cross viewing angles. Figure 7 shows the qualitative results of all approaches on testing datasets of multiple categories with same and cross viewing angles.
(2)Analysis.Both 3D-RecGAN++ and 3D-RecAE signif-icantly outperforms the state of the art by a large margin in all categories which are trained together on a single model. Besides, the performance of our network trained on multiple categories, does not notably degrade compared with training the network on individual categories as shown in previous Table 1 and 2. This confirms that our network has enough capacity and capability to learn diverse features from multiple categories.
4.5 Cross-category Results
(1)Results.To further investigate the generality of net-works, we train all networks on{bench, chair, couch, table},
TABLE 3: Multi-category IoU and CE loss on testing dataset with same viewing angles (2563voxel grids).
IoU CE Loss bench chair couch table bench chair couch table 3D-EPN [12] 0.428 0.484 0.634 0.506 0.087 0.107 0.138 0.102 Varleyet al. [3] 0.234 0.317 0.543 0.236 0.103 0.132 0.197 0.170 Hanet al. [27] 0.425 0.454 0.440 0.470 0.045 0.087 0.172 0.065
3D-RecAE (ours) 0.576 0.632 0.740 0.661 0.037 0.060 0.069 0.044
3D-RecGAN++ (ours) 0.581 0.640 0.745 0.667 0.030 0.051 0.063 0.039
TABLE 4: Multi-category IoU and CE loss on testing dataset with cross viewing angles (2563voxel grids).
IoU CE Loss bench chair couch table bench chair couch table 3D-EPN [12] 0.415 0.452 0.531 0.477 0.091 0.115 0.147 0.111 Varleyet al. [3] 0.201 0.283 0.480 0.199 0.105 0.143 0.207 0.174 Hanet al. [27] 0.429 0.444 0.447 0.474 0.045 0.089 0.172 0.063
3D-RecAE (ours) 0.530 0.587 0.640 0.610 0.043 0.068 0.096 0.055
3D-RecGAN++ (ours) 0.540 0.594 0.643 0.621 0.038 0.061 0.091 0.048
and then test them on another 6 totally different categories:
9
multi cat
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
(a) Qualitative results of multiple category reconstruction on testing datasets with same viewing angles.
multi cat
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
[image:10.612.59.545.44.232.2](b) Qualitative results of multiple category reconstruction on testing datasets with cross viewing angles.
[image:10.612.59.552.83.429.2]Fig. 7: Qualitative results of multiple category reconstruction on testing datasets with same and cross viewing angles.
TABLE 5: Cross-category IoU on testing dataset with same viewing angles (2563voxel grids).
car faucet firearm guitar monitor plane 3D-EPN [12] 0.450 0.442 0.339 0.351 0.444 0.314 Varleyet al. [3] 0.484 0.260 0.280 0.255 0.341 0.295 Hanet al. [27] 0.360 0.402 0.333 0.353 0.450 0.306
3D-RecAE (ours) 0.557 0.530 0.422 0.440 0.556 0.390
3D-RecGAN++ (ours) 0.555 0.536 0.426 0.442 0.562 0.394 TABLE 6: Cross-category CE loss on testing dataset with same viewing angles (2563voxel grids).
car faucet firearm guitar monitor plane 3D-EPN [12] 0.170 0.088 0.036 0.036 0.123 0.066 Varleyet al. [3] 0.173 0.122 0.029 0.030 0.130 0.042 Hanet al. [27] 0.167 0.077 0.018 0.015 0.088 0.031
3D-RecAE (ours) 0.110 0.057 0.018 0.016 0.072 0.036
3D-RecGAN++ (ours) 0.102 0.053 0.016 0.014 0.067 0.031
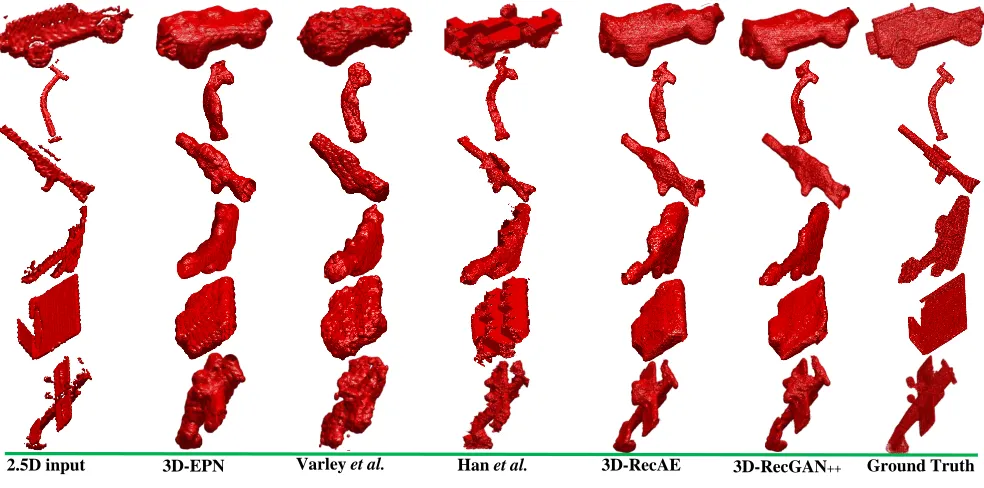
while Table 7 and 8 shows the IoU and CE loss comparison on the testing dataset with cross viewing angles. Figure 8 shows the qualitative results of all methods on 6 unseen categories with same and cross viewing angles.
We further evaluate the generality of our 3D-RecGAN++ on a specific category. Particularly, we conduct four groups of experiments. In the first group, we train our 3D-RecGAN++ on bench, then separately test it on the
re-TABLE 7: Cross-category IoU on testing dataset with cross viewing angles (2563voxel grids).
car faucet firearm guitar monitor plane 3D-EPN [12] 0.446 0.439 0.324 0.359 0.448 0.309 Varleyet al. [3] 0.489 0.260 0.274 0.255 0.334 0.283 Hanet al. [27] 0.349 0.402 0.321 0.363 0.455 0.299
3D-RecAE (ours) 0.550 0.521 0.411 0.441 0.550 0.382
3D-RecGAN++ (ours) 0.553 0.529 0.416 0.449 0.555 0.390 TABLE 8: Cross-category CE loss on testing dataset with cross viewing angles (2563voxel grids).
car faucet firearm guitar monitor plane 3D-EPN [12] 0.160 0.087 0.033 0.036 0.127 0.065 Varleyet al. [3] 0.171 0.123 0.028 0.030 0.136 0.043 Hanet al. [27] 0.171 0.076 0.018 0.016 0.088 0.031
3D-RecAE (ours) 0.101 0.059 0.017 0.017 0.079 0.036
3D-RecGAN++ (ours) 0.100 0.055 0.014 0.015 0.074 0.031
[image:10.612.64.548.255.438.2]cross cat 125
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
(a) Qualitative results of cross category reconstruction on testing datasets with same viewing angles.
cross cat 216
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
[image:11.612.60.552.42.286.2](b) Qualitative results of cross category reconstruction on testing datasets with cross viewing angles.
Fig. 8: Qualitative results of cross category reconstruction on testing datasets with same and cross viewing angles.
and then tested on the testing dataset with same viewing angles over2563voxel grids.
(2) Analysis. The proposed 3D-RecGAN++ achieves much higher IoU and smaller CE loss across the unseen categories than competing approaches. Our network not only learns rich features from different object categories, but also is able to generalize well to completely new types of categories. Our intuition is that the network may learn geometric features such as lines, planes, curves which are common across various object categories. As our network involves skip-connections between intermediate neural lay-ers, it is not straightforward to visualize and analyze the
learnt latent features.
It can be also observed that our model trained onbench tends to be more general than others. Intuitively, the bench category tends to have general features such as four legs, seats, and/or a back, which are also common among other categories {chair, couch, table}. However, not all chairs or couches consist of such general features that are shared across different categories.
11
Real multi cat
2.5D input 3D-EPN Varley et al. Han et al. 3D-RecAE 3D-RecGAN++ Ground Truth
Preproc
essing
[image:12.612.60.559.41.418.2]Raw depth image
Fig. 9: Qualitative results of real-world objects reconstruction from different approaches. The object instance is segmented from the raw depth image in preprocessing step.
[image:12.612.47.303.513.610.2]categories.
TABLE 9: Cross-category IoU and CE loss of 3D-RecGAN++ trained on individual category and then tested on the testing dataset with same viewing angles (2563voxel grids).
IoU CE Loss bench chair couch table bench chair couch table
Group 1
(trained on bench) 0.580 0.510 0.507 0.599 0.034 0.110 0.164 0.062 Group 2
(trained on chair) 0.508 0.647 0.469 0.564 0.048 0.060 0.184 0.069 Group 3
(trained on couch) 0.429 0.504 0.753 0.437 0.070 0.105 0.066 0.126 Group 4
(trained on table) 0.510 0.509 0.402 0.679 0.049 0.111 0.260 0.040
4.6 Real-world Experiment Results
(1)Results.Lastly, in order to evaluate the domain adap-tation capability of the networks, we train all networks on synthesized data of categories{bench, chair, couch, table}, and then test them on real-world data collected by a Mi-crosoft Kinect camera. Table 10 compares the IoU and CE loss of all approaches on the real-world dataset. Figure 9 shows some qualitative results for all methods.
(2) Analysis. There are two reasons why the IoU is significantly lower compared with testing on the synthetic
dataset. First, the ground truth objects obtained from Elastic-Fusion are not as solid as the synthesized datasets. However, all networks predict dense and solid voxel grids, so the in-terior parts may not match though the overall object shapes are satisfactorily recovered as shown in Figure 9. Secondly, the input 2.5D depth view from real-world dataset is noisy and incomplete, due to the limitation of the RGB-D sensor (e.g., reflective surfaces, outdoor lighting). In some cases, the input 2.5D view does not capture the whole object and only contains a part of the object, which also leads to inferior reconstruction results (e.g., the5th row in Figure 9) and a
lower IoU scores overall. However, our proposed network is still able to reconstruct reasonable 3D dense shapes given the noisy and incomplete 2.5D input depth views, while the competing algorithms (e.g., Varleyet al.) are not robust to real-world noise and unable to generate compelling results.
TABLE 10: Multi-category IoU and CE loss on real-world dataset (2563voxel grids).
IoU CE Loss bench chair couch table bench chair couch table 3D-EPN [12] 0.162 0.190 0.508 0.140 0.090 0.158 0.413 0.187 Varleyet al. [3] 0.118 0.152 0.433 0.075 0.073 0.155 0.436 0.191 Hanet al. [27] 0.166 0.164 0.235 0.146 0.083 0.167 0.352 0.194
3D-RecAE (ours) 0.173 0.203 0.538 0.151 0.065 0.156 0.318 0.180
4.7 Impact of Adversarial Learning
(1)Results.In all above experiments, the proposed RecGAN++ tends to outperform the ablated network 3D-RecAE which does not include the adversarial learning of GAN part. In all visualization of experiment results, the 3D shapes from 3D-RecGAN++ are also more compelling than 3D-RecAE. To further quantitatively investigate how the ad-versarial learning improves the final 3D results comparing with 3D-RecAE, we calculate the mean precision and recall from the previous multi-category experiment results in Sec-tion 4.4. Table 11 compares the mean precision and recall of 3D-RecGAN++ and 3D-RecAE on individual categories using the network trained on multiple categories.
(2) Analysis. It can be seen that the results of 3D-RecGAN++ tend to constantly have higher precision scores than 3D-RecAE, which means 3D-RecGAN++ has less false positive estimations. Therefore, the estimated 3D shapes from 3D-RecAE are likely to be ’fatter’ and ’bigger’, while 3D-RecGAN++ tends to predict ’thinner’ shapes with much more shape details being exposed. Both 3D-RecGAN++ and 3D-RecAE can achieve high recall scores (i.e., above 0.8), which means both 3D-RecGAN++ and 3D-RecAE are capable of estimating the major object shapes without too many false negatives. In other words, the ground truth 3D shape tends to be a subset of the estimated shape result.
TABLE 11: Multi-category mean precision and recall on testing dataset with same viewing angles (2563voxel grids).
mean precision mean recall bench chair couch table bench chair couch table
3D-RecAE 0.668 0.740 0.800 0.750 0.808 0.818 0.907 0.845
3D-RecGAN++ 0.680 0.747 0.804 0.754 0.804 0.820 0.910 0.853 Overall, with regard to experiments on per-category, multi-category, and cross-category experiments, our 3D-RecGAN++ outperforms others by a large margin, although all other approaches can reconstruct reasonable shapes. In terms of the generality, Varleyet al. [3] and Hanet al. [27] are inferior because Varleyet al. [3] use a single fully connected layers, instead of 3D ConvNets, for shape generation which is unlikely to be general for various shapes, and Hanet al. [27] apply LSTMs for shape blocks generation which is inef-ficient and unable to learn general 3D structures. However, our 3D-RecGAN++ is superior thanks to the generality of the 3D encoder-decoder and the adversarial discriminator. Besides, the 3D-RecAE tends to over estimate the 3D shape, while the adversarial learning of 3D-RecGAN++ is likely to remove the over-estimated parts, so as to leave the estimated shape to be clearer with more shape details.
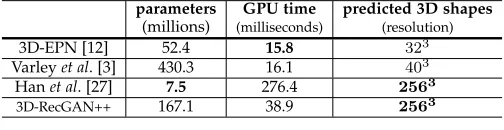
4.8 Computation Analysis
Table 12 compares the computation efficiency of all ap-proaches regarding the total number of model parameters and the average time consumption to recover a single object. The model proposed by Han et al. [27] has the least number of parameters because most of the parameters are shared to predict different blocks of an object. Our 3D-RecGAN++ has reasonable 167.1 millions parameters, which is on a similar scale to VGG-19 (i.e., 144 millions) [88].
To evaluate the average time consumption for a single object reconstruction, we implement all networks in Tensor-flow 1.2 and Python 2.7 with CUDA 8.0 and cuDNN 7.1
as the back-end driver and library. All models are tested on a single Titan X GPU in the same hardware and software environments. 3D-EPN [12] takes the shortest time to predict a323object on GPU, while our 3D-RecGAN++ only needs
around 40 milliseconds to recover a dense2563object. Com-paratively, Hanet al. takes the longest GPU time to generate a dense object because of the time-consuming sequential processing of LSTMs. The low resolution objects predicted by 3D-EPN and Varleyet al. are further upsampled to2563
[image:13.612.312.564.209.274.2]using existing SciPy library on a CPU server (Intel E5-2620 v4, 32 cores). It takes around 7 seconds to finish the upsampling for a single object.
TABLE 12: Comparison of model parameters and average time consumption to reconstruction a single object.
parameters
(millions)
GPU time
(milliseconds)
predicted 3D shapes
(resolution)
3D-EPN [12] 52.4 15.8 323
Varleyet al. [3] 430.3 16.1 403
Hanet al. [27] 7.5 276.4 2563
3D-RecGAN++ 167.1 38.9 2563
5
D
ISCUSSIONAlthough our 3D-RecGAN++ achieves the state of the art performance in 3D object reconstruction from a single depth view, it has limitations. Firstly, our network takes the volumetric representation of a single depth view as input, instead of taking a raw depth image. Therefore, a preprocessing of raw depth images is required for our network. However, in many application scenarios such as robot grasping, such preprocessing would be trivial and straightforward given the depth camera parameters. Sec-ondly, the input depth view of our network only contains a clean object information without cluttered background. One possible solution is to leverage an existing segmentation algorithm such as Mask-RCNN [89] to clearly segment the target object instance from the raw depth view.
6
C
ONCLUSION13
R
EFERENCES[1] A. Sharma, O. Grau, and M. Fritz, “VConv-DAE : Deep Volumetric Shape Learning Without Object Labels,”ECCV, 2016.
[2] Z. Wang, S. Rosa, L. Xie, B. Yang, S. Wang, N. Trigoni, and A. Markham, “Defo-Net: Learning Body Deformation Using Gen-erative Adversarial Networks,”ICRA, 2018.
[3] J. Varley, C. Dechant, A. Richardson, J. Ruales, and P. Allen, “Shape Completion Enabled Robotic Grasping,”IROS, 2017.
[4] R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davison, P. Kohli, J. Shotton, S. Hodges, and A. Fitzgibbon, “KinectFusion: Real-time dense surface mapping and tracking,”
ISMAR, 2011.
[5] M. Nießner, M. Zollh ¨ofer, S. Izadi, and M. Stamminger, “Real-time 3D reconstruction at scale using voxel hashing,”ACM Transactions on Graphics, vol. 32, no. 6, pp. 1–11, 2013.
[6] F. Steinbrucker, C. Kerl, J. Sturm, and D. Cremers, “Large-Scale Multi-Resolution Surface Reconstruction from RGB-D Sequences,”
ICCV, 2013.
[7] A. Nealen, T. Igarashi, O. Sorkine, and M. Alexa, “Laplacian Mesh Optimization,”SIGGRAPH, 2006.
[8] W. Zhao, S. Gao, and H. Lin, “A robust hole-filling algorithm for triangular mesh,”The Visual Computer, vol. 23, no. 12, pp. 987–997, 2007.
[9] M. Kazhdan, M. Bolitho, and H. Hoppe, “Poisson Surface Recon-struction,”Symposium on Geometry Processing, 2006.
[10] M. Kazhdan and H. Hoppe, “Screened poisson surface reconstruc-tion,”ACM Transactions on Graphics, vol. 32, no. 3, pp. 1–13, 2013. [11] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao,
“3D ShapeNets: A Deep Representation for Volumetric Shapes,”
CVPR, 2015.
[12] A. Dai, C. R. Qi, and M. Nießner, “Shape Completion using 3D-Encoder-Predictor CNNs and Shape Synthesis,”CVPR, 2017. [13] M. Tatarchenko, A. Dosovitskiy, and T. Brox, “Octree
Generat-ing Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs,”ICCV, 2017.
[14] G. Riegler, A. O. Ulusoy, H. Bischof, and A. Geiger, “OctNetFusion: Learning Depth Fusion from Data,”3DV, 2017.
[15] H. Christian, S. Tulsiani, and J. Malik, “Hierarchical Surface Pre-diction for 3D Object Reconstruction,”3DV, 2017.
[16] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative Adver-sarial Nets,”NIPS, 2014.
[17] D. P. Kingma and M. Welling, “Auto-Encoding Variational Bayes,”
ICLR, 2014.
[18] Z. Hu, Z. Yang, X. Liang, R. Salakhutdinov, and E. P. Xing, “Controllable Text Generation,”ICML, 2017.
[19] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive Growing of GANs for Improved Quality, Stability, and Variation,”ICLR, 2018.
[20] X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel, “InfoGAN: Interpretable Representation Learning by In-formation Maximizing Generative Adversarial Nets,”NIPS, 2016. [21] T. D. Kulkarni, W. F. Whitney, P. Kohli, and J. B. Tenenbaum, “Deep
Convolutional Inverse Graphics Network,”NIPS, 2015.
[22] E. Grant, P. Kohli, and M. V. Gerven, “Deep Disentangled Repre-sentations for Volumetric Reconstruction,”ECCV Workshops, 2016. [23] R. Girdhar, D. F. Fouhey, M. Rodriguez, and A. Gupta, “Learning a Predictable and Generative Vector Representation for Objects,”
ECCV, 2016.
[24] H. Huang, E. Kalogerakis, and B. Marlin, “Analysis and synthe-sis of 3D shape families via deep-learned generative models of surfaces,”Computer Graphics Forum, vol. 34, no. 5, pp. 25–38, 2015. [25] J. Wu, C. Zhang, T. Xue, W. T. Freeman, and J. B. Tenenbaum, “Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling,”NIPS, 2016.
[26] M. Mirza and S. Osindero, “Conditional Generative Adversarial Nets,”arXiv, 2014.
[27] X. Han, Z. Li, H. Huang, E. Kalogerakis, and Y. Yu, “High-Resolution Shape Completion Using Deep Neural Networks for Global Structure and Local Geometry Inference,”ICCV, 2017. [28] B. Yang, H. Wen, S. Wang, R. Clark, A. Markham, and N. Trigoni,
“3D Object Reconstruction from a Single Depth View with Adver-sarial Learning,”ICCV Workshops, 2017.
[29] A. Monszpart, N. Mellado, G. J. Brostow, and N. J. Mitra, “RAPter: Rebuilding Man-made Scenes with Regular Arrangements of Planes,”ACM Transactions on Graphics, vol. 34, no. 4, pp. 1–12, 2015.
[30] N. J. Mitra, L. J. Guibas, and M. Pauly, “Partial and Approximate Symmetry Detection for 3D Geometry,”SIGGRAPH, 2006. [31] M. Pauly, N. J. Mitra, J. Wallner, H. Pottmann, and L. J. Guibas,
“Discovering structural regularity in 3D geometry,”ACM Transac-tions on Graphics, vol. 27, no. 3, p. 1, 2008.
[32] I. Sipiran, R. Gregor, and T. Schreck, “Approximate Symmetry Detection in Partial 3D Meshes,”Computer Graphics Forum, vol. 33, no. 7, pp. 131–140, 2014.
[33] P. Speciale, M. R. Oswald, A. Cohen, and M. Pollefeys, “A Symme-try Prior for Convex Variational 3D Reconstruction,”ECCV, 2016. [34] S. Thrun and B. Wegbreit, “Shape from symmetry,”ICCV, 2005. [35] Y. M. Kim, N. J. Mitra, D.-M. Yan, and L. Guibas, “Acquiring
3D Indoor Environments with Variability and Repetition,”ACM Transactions on Graphics, vol. 31, no. 6, 2012.
[36] Y. Li, A. Dai, L. Guibas, and M. Nießner, “Database-Assisted Ob-ject Retrieval for Real-Time 3D Reconstruction,”Computer Graphics Forum, vol. 34, no. 2, pp. 435–446, 2015.
[37] L. Nan, K. Xie, and A. Sharf, “A Search-Classify Approach for Cluttered Indoor Scene Understanding,” ACM Transactions on Graphics, vol. 31, no. 6, pp. 1–10, 2012.
[38] T. Shao, W. Xu, K. Zhou, J. Wang, D. Li, and B. Guo, “An interactive approach to semantic modeling of indoor scenes with an RGBD camera,”ACM Transactions on Graphics, vol. 31, no. 6, pp. 1–11, 2012.
[39] Y. Shi, P. Long, K. Xu, H. Huang, and Y. Xiong, “Data-driven contextual modeling for 3d scene understanding,”Computers & Graphics, vol. 55, pp. 55–67, 2016.
[40] J. Rock, T. Gupta, J. Thorsen, J. Gwak, D. Shin, and D. Hoiem, “Completing 3D Object Shape from One Depth Image,”CVPR, 2015.
[41] R. Hartley and A. Zisserman,Multiple View Geometry in Computer Vision. Cambridge University Press, 2004.
[42] R. A. Newcombe, S. J. Lovegrove, and A. J. Davision, “DTAM: Dense Tracking and Mapping in Real-time,”ICCV, 2011. [43] S. Baker and I. Matthews, “Lucas-Kanade 20 Years On : A
Unify-ing Framework : Part 1,”International Journal of Computer Vision, vol. 56, no. 3, pp. 221–255, 2004.
[44] S. Y. Bao, M. Chandraker, Y. Lin, and S. Savarese, “Dense Object Reconstruction with Semantic Priors,”CVPR, 2013.
[45] A. Dame, V. A. Prisacariu, C. Y. Ren, and I. Reid, “Dense Recon-struction Using 3D Object Shape Priors,”CVPR, 2013.
[46] F. Engelmann, J. Stuckler, and B. Leibe, “Joint Object Pose Estima-tion and Shape ReconstrucEstima-tion in Urban Street Scenes Using 3D Shape Priors,”GCPR, 2016.
[47] C. B. Choy, D. Xu, J. Gwak, K. Chen, and S. Savarese, “3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction,”ECCV, 2016.
[48] X. Di, R. Dahyot, and M. Prasad, “Deep Shape from a Low Number of Silhouettes,”ECCV, 2016.
[49] Z. Lun, M. Gadelha, E. Kalogerakis, S. Maji, and R. Wang, “3D Shape Reconstruction from Sketches via Multi-view Convolu-tional Networks,”3DV, 2017.
[50] D. J. Rezende, S. M. A. Eslami, S. Mohamed, P. Battaglia, M. Jader-berg, and N. Heess, “Unsupervised Learning of 3D Structure from Images,”NIPS, 2016.
[51] A. Kar, C. H¨ane, and J. Malik, “Learning a Multi-View Stereo Machine,”NIPS, 2017.
[52] M. Ji, J. Gall, H. Zheng, Y. Liu, and L. Fang, “SurfaceNet: An End-to-end 3D Neural Network for Multiview Stereopsis,”ICCV, 2017. [53] T. Whelan, J. McDonald, M. Kaess, M. Fallon, H. Johannsson, and J. J. Leonard, “Kintinuous: Spatially Extended Kinectfusion,”RSS Workshops, 2012.
[54] T. Whelan, S. Leutenegger, R. F. Salas-moreno, B. Glocker, and A. J. Davison, “ElasticFusion : Dense SLAM Without A Pose Graph,”
RSS, 2015.
[55] V. Blanz and T.Vetter, “Face Recognition based on Fitting a 3D Morphable Model,”IEEE Transactions on Pattern Analysis and Ma-chine Intelligence, vol. 25, no. 9, pp. 1063–1074, 2003.
[56] P. Dou, S. K. Shah, and I. A. Kakadiaris, “End-to-end 3D face reconstruction with deep neural networks,”CVPR, 2017. [57] A. Kar, S. Tulsiani, J. Carreira, and J. Malik, “Category-specific
object reconstruction from a single image,”CVPR, 2015.
[59] S. Tulsiani, T. Zhou, A. A. Efros, and J. Malik, “Multi-view Su-pervision for Single-view Reconstruction via Differentiable Ray Consistency,”CVPR, 2017.
[60] X. Yan, J. Yang, E. Yumer, Y. Guo, and H. Lee, “Perspective Transformer Nets: Learning Single-View 3D Object Reconstruction without 3D Supervision,”NIPS, 2016.
[61] C. Kong, C.-H. Lin, and S. Lucey, “Using Locally Corresponding CAD Models for Dense 3D Reconstructions from a Single Image,”
CVPR, 2017.
[62] A. Kurenkov, J. Ji, A. Garg, V. Mehta, J. Gwak, C. Choy, and S. Savarese, “DeformNet: Free-Form Deformation Network for 3D Shape Reconstruction from a Single Image,”NIPS, 2017.
[63] J. K. Murthy, G. V. S. Krishna, F. Chhaya, and K. M. Krishna, “Reconstructing Vechicles from a Single Image: Shape Priors for Road Scene Understanding,”ICRA, 2017.
[64] A. Johnston, R. Garg, G. Carneiro, I. Reid, and A. v. d. Hengel, “Scaling CNNs for High Resolution Volumetric Reconstruction from a Single Image,”ICCV Workshops, 2017.
[65] C.-H. Lin, C. Kong, and S. Lucey, “Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction,”AAAI, 2018. [66] J. Wu, Y. Wang, T. Xue, X. Sun, W. T. Freeman, and J. B. Tenenbaum,
“MarrNet: 3D Shape Reconstruction via 2.5D Sketches,” NIPS, 2017.
[67] M. Firman, O. M. Aodha, S. Julier, and G. J. Brostow, “Structured Prediction of Unobserved Voxels From a Single Depth Image,”
CVPR, 2016.
[68] S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and T. Funkhouser, “Semantic Scene Completion from a Single Depth Image,”CVPR, 2017.
[69] W. Wang, Q. Huang, S. You, C. Yang, and U. Neumann, “Shape In-painting using 3D Generative Adversarial Network and Recurrent Convolutional Networks,”ICCV, 2017.
[70] C. Zou, E. Yumer, J. Yang, D. Ceylan, and D. Hoiem, “3D-PRNN: Generating Shape Primitives with Recurrent Neural Networks,”
ICCV, 2017.
[71] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi, “Photo-Realistic Single Image Super-Resolution Using a Genera-tive Adversarial Network,”CVPR, 2017.
[72] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee, “Generative Adversarial Text to Image Synthesis,”ICML, 2016. [73] A. B. L. Larsen, S. K. Sonderby, H. Larochelle, and O. Winther,
“Autoencoding beyond pixels using a learned similarity metric,”
ICML, 2016.
[74] M. Gadelha, S. Maji, and R. Wang, “3D Shape Induction from 2D Views of Multiple Objects,”3DV, 2017.
[75] E. Smith and D. Meger, “Improved Adversarial Systems for 3D Object Generation and Reconstruction,”CoRL, 2017.
[76] A. A. Soltani, H. Huang, J. Wu, T. D. Kulkarni, and J. B. Tenen-baum, “Synthesizing 3D Shapes via Modeling Multi-View Depth Maps and Silhouettes with Deep Generative Networks,”CVPR, 2017.
[77] M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein GAN,”
ICML, 2017.
[78] A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, J. Xiao, L. Yi, and F. Yu, “ShapeNet: An Information-Rich 3D Model Repository,”
arXiv, 2015.
[79] L. v. d. Maaten and G. Hinton, “Visualizing Data using t-SNE,”
Journal of Machine Learning Research, vol. 9, no. Nov, pp. 2579–2605, 2008.
[80] O. Ronneberger, P. Fischer, and T. Brox, “U-Net : Convolutional Networks for Biomedical Image Segmentation,”MICCAI, 2015. [81] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and
A. Courville, “Improved Training of Wasserstein GANs,” NIPS, 2017.
[82] M. Arjovsky and L. Bottou, “Towards Principled Methods for Training Generative Adversarial Networks,”ICLR, 2017. [83] J. Bao, D. Chen, F. Wen, H. Li, and G. Hua, “CVAE-GAN:
Fine-Grained Image Generation through Asymmetric Training,”ICCV, 2017.
[84] Y. Mroueh, T. Sercu, and V. Goel, “McGAN: Mean and Covariance Feature Matching GAN,”ICML, 2017.
[85] A. Brock, T. Lim, J. M. Ritchie, and N. Weston, “Generative and Discriminative Voxel Modeling with Convolutional Neural Networks,”NIPS Workshops, 2016.
[86] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimiza-tion,”ICLR, 2015.
[87] K. Khoshelham and S. O. Elberink, “Accuracy and Resolution of Kinect Depth Data for Indoor Mapping Applications,” Sensors, vol. 12, pp. 1437–1454, 2012.
[88] K. Simonyan and A. Zisserman, “Very Deep Convolutional Net-works for Large-Scale Image Recognition,”ICLR, 2015.
[89] K. He, G. Gkioxari, P. Dollar, and R. Girshick, “Mask R-CNN,”
ICCV, 2017.
Bo Yangis currently a DPhil candidate in the
department of Computer Science at University of Oxford. His research interests lie in deep learn-ing, computer vision and robotics.
Stefano Rosareceived his Ph.D. in
Mechatron-ics Engineering from Politecnico di Torino, Italy, in 2014. He is currently a research fellow in the Department of Computer Science at University of Oxford, UK, working on long-term navigation, Human-Robot Interaction and intuitive physics.
Andrew Markham is an Associate Professor
at the Department of Computer Science, Uni-versity of Oxford. He obtained his BSc (2004) and PhD (2008) degrees from the University of Cape Town, South Africa. He is the Director of the MSc in Software Engineering. He works on resource-constrained systems, positioning sys-tems, in particular magneto-inductive positioning and machine intelligence.
Niki Trigoniis a Professor at the Oxford
Uni-versity Department of Computer Science and a fellow of Kellogg College. She obtained her DPhil at the University of Cambridge (2001), became a postdoctoral researcher at Cornell University (2002-2004), and a Lecturer at Birk-beck College (2004-2007). At Oxford, she is cur-rently Director of the EPSRC Centre for Doc-toral Training on Autonomous Intelligent Ma-chines and Systems, a program that combines machine learning, robotics, sensor systems and verification/control. She also leads the Cyber Physical Systems Group http://www.cs.ox.ac.uk/activities/sensors/index.html, which is focusing on intelligent and autonomous sensor systems with applications in positioning, healthcare, environmental monitoring and smart cities. The groups research ranges from novel sensor modalities and low level signal processing to high level inference and learning.
Hongkai Wenis an Assistant Professor at the