A Survey of Load Balancing Techniques
for Data Intensive Computing
Zhiquan Sui and Shrideep Pallickara
1
Introduction
Data volumes have been increasing substantially over the past several years. Such data is often processed concurrently on a distributed collection of machines to ensure reasonable completion times. Load balancing is one of the most important issues in data intensive computing. Often, the choice of the load balancing strategy has implications not just for reduction of execution times, but also on energy usage, network overhead, and costs.
Applications that are faced with processing large data volumes have a choice of relying on frameworks (often cloud-based) that are increasingly popular or designing algorithms that are suited for their application domain. Here, we will cover both. Our focus is a survey of the frameworks, APIs, and schemes used to load balance processing of voluminous data on a collection of machines while processing large data volumes in settings such as analytics (MapReduce), stream based settings, and discrete event simulations.
In Sect.2we discuss several popular data intensive computing frameworks. APIs available to for the development of cloud-scale applications are discussed in Sect.3. In Sect.4, we describe both static and dynamic load balancing schemes and how the latter is used in different settings. Section5outlines our conclusions.
2
Data Intensive Computing Frameworks
2.1
Google MapReduce Framework
MapReduce [1] is a framework introduced by Google that is well suited for concurrent processing of large datasets (usually more than 1 Tb) on a collection
Z. Sui () • S. Pallickara
Department of Computer Science, Colorado State University, Fort Collins, CO, USA e-mail:[email protected];[email protected]
B. Furht and A. Escalante (eds.), Handbook of Data Intensive Computing,
DOI 10.1007/978-1-4614-1415-5 6, © Springer Science+Business Media, LLC 2011
Map Map Map Map Storage
Reduce Reduce Reduce
Final Results
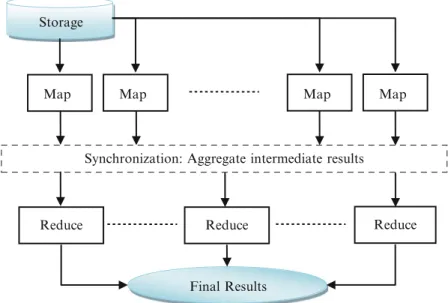
Fig. 6.1 A MapReduce computation
of machines. The framework is suited for problems where the same processing is applied to apportioned sections of the data: these include grep, histogramming words, sort, web log analysis, and so on. MapReduce underpins several capabilities within Google. For example, Google uses the MapReduce framework to index the web.
The basic concepts within this framework are Map and Reduce. A large task can be divided into two phases: Map and Reduce. The Map phase divides the large task into smaller pieces and dispatches each small piece of work onto one active node in the cluster. The Reduce phase collects the results from the Map phase and processes these results to get the final result. A typical MapReduce computation is shown in Fig.6.1. In general, the Map and Reduce functions divide the data that they operate on for load balancing purposes. However, slow or bogged down machines may lead to straggler computations within the system that might lead to longer completion time: the completion time is only as fast as the slowest computation. If one straggler computation is twice as slow as other computations in that phase, then the total elapsed time in this step would be twice that of the case without the straggler computation. In such a case, a straggler detection and avoidance mechanism becomes necessary. This is done by launching speculative tasks towards the end of a processing phase on other machines for those computations that have not yet finished. It is possible for computation imbalances to exist in a MapReduce computation depending on the rate at which the results are generated in the Map phase and the rate at which these results are processed (or consumed) within the Reduce phase. An imbalance in this rate could result in the reducing machines idling or for the mapped data to be backlogged or queued in the reducing phase. Other optimizations of MapReduce framework are introduced in Sect.4.2.2.
2.1.1 Hadoop Framework
Hadoop [2] is the most popular implementation of the MapReduce framework. It incorporates support for reliability and scalability while scheduling tasks within a distributed system. Hadoop identifies straggler machines within a cluster and then speculative re-launches tasks that were hosted on the machines. This model works well in homogeneous system where machines have very similar configurations in terms of hardware and software. In a heterogeneous setting involving machines with disparate configurations the scheme of launching speculative tasks does not result in the performance gains that one see in homogeneous settings. In [3], the authors improve the Hadoop framework and introduce a new algorithm called LATE. This algorithm adjusts the launch mechanism within Hadoop. First, it re-launches speculative tasks only on non-straggler machines. Intuitively, re-launching speculative tasks is waste of resources. Secondly, this approach focuses on re-launching tasks that will be the most delayed rather than the ones that are about to complete. By targeting tasks that will be the last to finish this algorithm targets tasks that will slow down the whole system. Last but not the least, the number of speculative tasks is reduced. This is important because launching speculative tasks has resource costs and includes additional overheads. The new algorithm works just as well as the basic Hadoop framework in homogeneous setting, but produces substantially better results in heterogeneous settings.
2.2
Microsoft Dryad Framework
Dryad [4] is a framework developed at Microsoft that uses graphs to express computations. The focus within Dryad is to evaluate SQL queries concurrently on a distributed collection of machines. Each query operation is a read-only operation that avoids the write-conflict problem: this, in turn, allows operations to be done in parallel. Each specified SQL query can be divided into several steps involving concurrent SQL query operations. The topology of the computational graph is con-figured before runtime and is levelized with each level being responsible for an SQL operation. The structure of Dryad is depicted in Fig.6.2. There are several different relationships between two adjacent levels. Users can choose the one corresponding to the logic of computation. Also users have to specify the functionality of each node. During execution, each node relies on the operations before it. Once it receives all data from nodes in the preceding stage it initiates processing.
The issue of load balancing in Dryad is exacerbated by the presence of levels within the computational graph. Stragglers within a level influence not just that level but also all subsequent levels in the graph. There can also be some optimizations in the Dryad framework. For example, a many-to-one mapping (or a fan-in) may result in a bottleneck because of the bandwidth available at the destination node. Here, the topology can be refined by replicating the destination node and distributing the input data. The Dryad framework address reliability issues by incorporating support for failure detection and re-launch mechanisms for affected computations.
Mapping Function 2 Mapping Function 1 Input Files R R R R Level 1 Operation R X X X X X X Level 2Operation X M M M M Level 3Operation M Output Files
Fig. 6.2 Structure of dryad jobs
2.3
Processing Data Streams
A data stream [5] is sequence of tuples generated at run time. The unique characteristic of this model [6,7] is that the data is unknown before execution. However, the operations are fixed. For example, in an online purchasing system, the operations that the users can perform are fixed. Users can only put the items into their carts, pay the bill for their choices, and so on. But the system can never predict which user will purchase which item at what time. This is a typical data stream based model. The users’ choices will be sent as tuples. The fixed operations have been programmed in the system. When thousands of such tuples come into the query network at the same time, the system becomes fairly busy and issues such as load balancing, consistency, and reliability need to be addressed.
There are several systems that address the load balancing issues within this model. Auroraand Medusa [8,9] are representative of such systems. Aurorais an intra-participant distributed system. During initializations the system relies on a simplistic distribution of the load. However, once a node is overloaded either in CPU utilization, memory usage or network bandwidth, it will try to migrate its load to all the other nodes. Medusa, on the other hand, is based on inter-participant federated operation. Each action in the Medusa system is made by a collection of users. The system relies on agoric computing [10] which focuses on applying schemes from the
area of economics (such as auctions) to managing computational resources. Each message stream in the system has a positive value which represents its price. Each node will “sell” their stream to the other participants so that it can earn some money from these transactions. The objective is to run this mechanism within the system so that it will anneal to a stable economic status. Intuitively, a heavy-loaded node will not have enough money to buy more message streams so the load balancing issue will be addressed as well.
Consistency is rather important for data stream based system. Users tend to be more than tolerant of network stability problems than they are of problems with their purchases. There are basically three mechanisms for recovery in the presence of failures: precise recovery, rollback recovery, and gap recovery. Gap recovery ignores lost information and as such is not acceptable in data stream based system. Precise recovery focuses on recovering transactions perfectly to what it was before failures and provides strict correctness for transactions so many important commercial activities rely on this kind of recovery. However, this mechanism has rather high performance costs and overheads exist even when there are no failures. Rollback recovery provides an equivalent but not necessarily the same output as precise recovery after failures. The output may have duplicated tuples after failures. Such as scheme works well in situations where the system cannot lose information but can withstand duplicated information. This mechanism has less overhead than precise recovery.
3
Developing Cloud-Scale Applications
In this section we describe two popular approaches to developing cloud-scale applications: the Google App Engine and Microsoft Azure.
3.1
The Google App Engine
The Google App Engine [11,12] is a popular framework for data intensive computations that allows users to run their web applications without having to worry about the maintenance of servers. All a user needs to do is to upload their application and the framework automatically provisions resources by profiling the application’s storage and data flow. Issues related to reliability and load balancing issues are handled transparently.
The Google App Engine allows developer to develop and deploy web appli-cations. The App Engine includes support for programming in Java and Python. Developers can develop applications that use Java features such as the Java Virtual Machine (JVM) and Java servlets besides languages such as Javascript and Ruby that rely on a JVM-based interpreter or compiler. The App Engine supplies one Python interpreter and a standard Python library, which supports development using Python.
The Google App Engine allows development of applications that have significant processing requirements due to the data volumes involved. The main functionalities of this framework include:
• Support for most popular web technologies.
• A consistent storage space that includes support for queries, transactions and sorting.
• Local simulation of the Google App Engine that supports developing and debugging applications prior to deployments in the cloud.
• A mechanism for scheduling tasks.
• Identity verification and email services using Gmail accounts. • Load balancing framework.
3.2
Microsoft Azure
The Azure Platform [13] from Microsoft is a framework for developing cloud applications. All data are stored in a distributed file system and accessible online; the data is replicated to account for failures that might take place. This precludes the need to store data locally. In the Azure model users do not buy software, rather they buy services are a charged based on usage.
Microsoft Azure Platform supports three types of roles: Web, Worker, and Virtual Machine (VM). Underpinning support for the web role is the Internet Information Services (IIS) 7 and ASP.Net. Users can use native code in PHP or Java to create applications. Compared to the Web role, the Worker role focuses on background processing and is not hosted by IIS. Users can use the.NET framework or some other application running in Windows with the Worker role. The VM role is used to deploy a custom Windows Server 2008 R2 image to Windows Azure. In the VM role, users have more control over their environment and can manage their own configurations of the OS, use Windows Services, schedule tasks and so on.
4
Load Balancing Schemes
In practice there are two broad classes of load balancing schemes: static and dynamic. The suitability of these schemes depends on the application characteristics and objectives that must be met.
4.1
Static Load Balancing Schemes
In the static scheme load balancing decisions are made before execution. The system also typically performs several experiments to collect information such as execution time on a single processor, memory usage and so on. In [14], the authors describe
several static load balancing algorithms that can be divided into three categories: greedy, searching algorithms, and machine learning algorithms. The objective is to dispatch a set of subtasks with dependencies within a cluster. These algorithms consider both execution time and energy cost.
Greedy algorithms basically set up a criteria followed by the dispatch. The criterion is a function that is the combination of execution time and battery usage. For the Min-Min algorithm, the first Min is to find the minimum fitness value of all the machines for each subtask. The second Min is to find the minimum fitness value among the results of the first step. The algorithm repeats these steps until all the subtasks have been dispatched. The Levelized Weight Tuning (LWT) algorithm and Bottom Up algorithm are similar. They both rely on the DAG (Directed Acyclic Graph) that represents the dependencies of the subtasks and dispatch subtasks level-by-level with the LWT algorithm relying on processing these levels in a top-to-bottom scheme with the BU algorithm being bottom-up.
Search algorithms look for the best solution using a search tree. However, when using search, there must be a pruning optimization to ensure that the complexity is acceptable. The Aalgorithm works well in this situation. The depth of the tree corresponds either to the number of sub-tasks for a given task or the number of available machines. In each level of the search tree, it stores a fixed number (100) of statuses. It expands (multiples of 100) these statuses and then selects the 100 best statuses in the next level. This process is repeated depending on the depth of the tree and a best solution is then found.
Machine learning algorithms are widely used in the load balancing area. Genetic algorithm tends to be the most convenient for static load. The main idea here is to randomly generate some dispatch patterns and generate new patterns from them. In each step the fittest patterns survives which then go on to generate new patterns in the next step. The suitability of the pattern is function of the metrics of interest such as execution time and energy cost. There are also some mutations in each step. One often ends with efficient patterns that would not have been generated otherwise. In each round the patterns tend to be more and more suitable (or fit). The algorithm stops when the fitness function does not change for several steps or is acceptable.
The overhead for static load balancing algorithms comes before the execution starts. For the algorithms described in [14], the most costly overhead is no more than 20% of the whole execution time.
4.2
Dynamic Load Balancing Schemes
Compared to static load balancing, the costs for dynamic load balancing are interleaved with the execution time; here, the scheduling decisions are being computed while the tasks are executing. These algorithms must have less complexity than static load balancing algorithms. Using a computationally intensive algorithm to come up with the best dispatch scheme may not be the best choice. This is because the best solution at given instant may not be the best solution when new events occur. At any given instant, it is much more useful to arrive at a good solution in a short time.
In this section, we will introduce different dynamic load balancing algorithms in different scenarios.
4.2.1 Dynamic Load Balancing Schemes in Stream Based Scenarios
Load balancing algorithms in stream based scenarios is quite different from those in discrete event simulations. Stream based scenarios usually involve a levelized network and each level of network is responsible for particular operations. Each task, which is like a stream in this network, contains a series of operations and each operation can be performed by one level in the network. The goal is to finish all the tasks that arrive in this network as soon as possible. A significant characteristic of the tasks is that they are unpredictable. Because the users submit the tasks most of time, the network does not know beforehand how many tasks will arrive over the next few seconds. Unlike discrete event simulation there is also no synchronization point during execution; thus there is no intuitive point at which migrations may be coordinated. In this case, traditional load balancing algorithms often fall short. However, machine learning algorithms tend to perform much better.
In [15], the authors introduce an ant-colony algorithm for dynamic load balanc-ing in stream-based scenarios. The classic ant-colony algorithm has been modified to account for the specificity of the problem. The algorithm relies on three types of ants with different functionalities. The ants are also more intelligent than the classic ants in ant-colony algorithm in that they keep store more information. However, the main idea still involves searching the path randomly and leaving pheromones in the path while passing by; the stronger the pheromone the more the number of ants that will be attracted to selecting that path. In this algorithm, each task will choose the current best solution and this might introduce bottlenecks into the whole system. Extremely selfish behavior might introduce greater latency to the other tasks. However, in this system, such behavior is acceptable. The goal of the algorithm is no longer to finish all the tasks in the shortest time but to make sure that the average latency is minimum. The first task should be served as fast as it can because nobody knows how many other tasks may arrive in the near future. Also, the algorithm usually takes time to learn the arrival patterns and does not work as effectively in the beginning. Such learning algorithms work extremely well for tasks where the arrival patterns are regular and the self-tuning characteristic of the machine-learning algorithm can accommodate slow changes to the arrival patterns. However, frequent changes to the task arrival patterns may lead to deteriorating performance in such a scheme. In general, machine learning algorithms underpin load balancing schemes in stream based scenarios.
4.2.2 Dynamic Load Balancing in Cloud Computing
In cloud computing, the frameworks introduced in Sects.2 and 3 are widely used. There are also some dynamic load balancing algorithms that build on these frameworks. One such dynamic load balancing algorithm that builds on the Hadoop
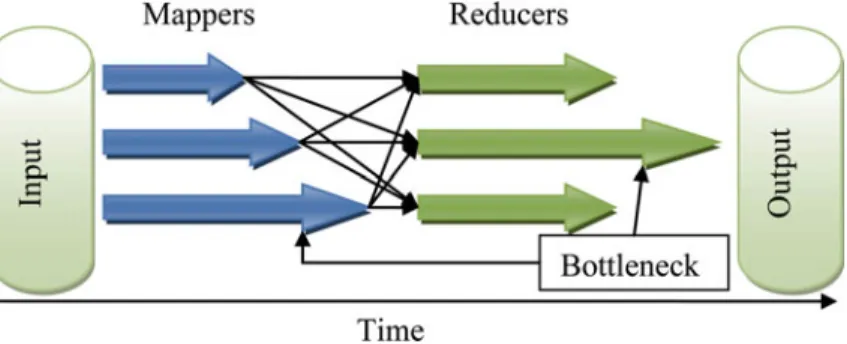
Fig. 6.3 MapReduce bottleneck example
framework is described in [16]. There exists a threshold in the balancer, which controls the rate at which a node should spread some of its work to the other nodes. This threshold determines how much imbalance would be tolerated before tasks would be redistributed for balancing purposes. The smaller the threshold is the more balanced the system is because the balancer will respond to small imbalances; however, this also results in more overhead due to the balancing operations. In contrast to traditional clusters, the communication overhead in cloud settings is slightly more expensive so the load migrations will only target neighboring nodes. Once a node exceeds the threshold, it sends a request to the controller called the NameNode. The NameNode in turn returns the most idle neighboring node’s information back to the node. The node then compares whether the migration is reasonable based on the information. If so, it will send the migration to the destination node.
Some more dynamic load balancing optimizations [17] have been applied to MapReduce framework. The authors have focused their effort on the detection of critical paths in the network. The optimization mechanisms are workflow priority, stage priority, and bottleneck elimination. The workflow priority optimization is to set a Workflow Priority which is specified by the users. The users can set this parameter depending on whether it is in the test or production phase, proximity to deadline, or the urgency for an output. The more important the application is the higher its priority is and the better its performance. Stage priority optimization is similar to workflow priority but is applicable to different stages within a task. Depending on how much work each stage has, users can also set the Stage Priority, and the system will then set aside corresponding resources for each of the stages. This scheme avoids bottlenecks and situations where several stages are waiting for the output of one stage. The bottleneck elimination strategy is to balance the load within each stage. A typical load imbalance is depicted in Fig.6.3. The optimization here is to redistribute the load from the active bottleneck nodes to the passive idle nodes. With this mechanism, the overall progress of the whole stage will be gained.
4.2.3 Dynamic Load Balancing Schemes in Discrete Event Simulation
Discrete event simulation is an effective technology for stochastic systems in domains such as economics, epidemic modeling, and weather forecasting. In discrete event simulations that rely on modeling phenomena that have geographical underpinnings (such as disease spread), the whole system models a region and the focus of the load balancing algorithm is to divide this region for different nodes. The simplest scheme is to divide the region into spatially equal pieces. However, this scheme usually results in imbalances because the distributing density of the population being modeled not uniform throughout the region.
Another policy may focus on dividing the region and make sure that the population is equal for each subdivided region. This policy while better than the equal sized spatial splits wills still results in an imbalance. Events are not equally distributed among all the entities and during the course of the simulation there is a lot of flux in the number of active individuals. Other commonly used schemes include random distributions and explicit spatial scattering [18] which has been explored in the context of a traffic simulation problem. The main idea in these schemes is to divide each complex computational region into smaller pieces. This works well in many situations but it also increases the communication footprint within the system. The communication overheads may become a bottleneck in situations where a large number of messages are being exchanged and also in situations where the network connecting the processing elements is bogged down resulting in higher latencies. In such situations dynamic load balancing is needed to reduce this imbalance.
The two core issues in dynamic load balancing are how to detect computational imbalances and how to migrate parts of the load to the other nodes. Detection of imbalance can be implemented either in a control node or in each of the individual nodes.
The controller-worker pattern [19] works well for a wide range of problems. In this pattern, the detection of imbalance is the responsibility of the controller. One approach to detecting the load imbalance is using the current execution time as the basis for what the future execution times would be. A system that relies on using load patterns being sent by each worker would be more accurate than just the execution time, however this can result in more processing and communication overheads.
The approach is to use a decentralized strategy. Here, there is no centralized controller in the system. Rather, the workers communicate directly with each other to determine whether their relative loads. In this scenario, each worker has a threshold that lets it judge whether it is (or has transitioned into) a heavily or lightly loaded worker. This threshold changes during the course of execution. For each time step the workers broadcast their own load and autonomously make decisions about whether they have breached threshold bounds.
The decision on migrating tasks is predicated on identify the task that needs to be migrated, the destination for the migrated task, and the process migration mechanisms that involve state synopsis and serialization. Identification of over-loaded workers and new destination nodes is easier in the controller-worker pattern
because the controller has information about all workers. However, there might be some restrictions on this migration. For instance, some simulations require that the geographical regions being modeled must be contiguous and, furthermore, in some cases the geometry of the modeled regions might be constrained which often can make the problem much harder. In [20], the authors describe an effi-cient regional split policy that splits the regions into strips which make it much easier for an overloaded region to migrate parts of its load to its neighbors. The scheme also incorporates an algorithm that balances the computational load at each synchronization point for all the workers. While algorithm may not give the most optimal solution, it makes fast decisions with excellent overall completion times.
In a decentralized scheme the lack for a centralized controller means that the overloaded node is responsible for finding a suitable node for load shedding. One effective rule for achieving load shedding is based on the fraction of the nodes that are heavily loaded or lightly loaded; here, a heavy loaded node would push its load onto a lightly loaded node in a system where most nodes are lightly loaded, while a lightly loaded node would pull load away from a heavily loaded node in a system where most nodes have a high load. The random destination algorithm is particularly effective in such settings. First, the algorithm is not compute intensive and does not introduce additional overheads and the probability of the load migration being successful is high. Secondly, even if the load migrates to a bad destination, the impact of this migration is limited to the next synchronization point at which point the destination will detect itself as heavily loaded or lightly loaded and take corrective measures.
The mechanism for migrating processes is works well for dynamic load bal-ancing in discrete event simulations. For spatially explicit problems an effective implementation of the regional split primitive makes dynamic subdivisions of regions easier. Even in the case of classic task dispatching problems, current VMs are generally provide excellent support for process migration.
5
Conclusion
Dynamic load balancing is an important mechanism for data intensive computing. In this chapter we discussed popular mechanisms in different scenarios. The choice of load balancing algorithm plays an important role in the overall system performance. Static and dynamic loading balancing algorithms have applicability in different settings and often cannot be interchanged without adversely impacting system performance. The emergence of streaming data and the corresponding increase in data volumes mean that more systems would need to rely on dynamic load balancing algorithms.
References
1. J. Dean and S. Ghemawat. 2008. MapReduce: simplified data processing on large clusters. Commun. ACM 51, 1 (January 2008), 107–113.
2.http://hadoop.apache.org/
3. M. Zaharia, A. Konwinski, A.D. Joseph, R.H. Katz, and I. Stoica. Improving MapReduce Performance in Heterogeneous Environments. In Proceedings of OSDI. 2008, 29–42. 4. M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. “Dryad: distributed data-parallel
programs from sequential building blocks,” presented at the Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems 2007, Lisbon, Portugal, 2007. 5. J.-H. Hwang, M. Balazinska, A. Rasin, U. Cetintemel, M. Stonebraker, and S. Zdonik.
2005. High-Availability Algorithms for Distributed Stream Processing. In Proceedings of the 21st International Conference on Data Engineering (ICDE ’05). IEEE Computer Society, Washington, DC, USA, 779–790.
6. B. Babcock, S. Babu, M. Datar, R. Motwani, and J. Widom. 2002. Models and issues in data stream systems. In Proceedings of the twenty-first ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems (PODS ’02). ACM, New York, NY, USA, 1–16.
7. D. Carney, U. C¸ etintemel, M. Cherniack, C. Convey, S. Lee, G. Seidman, M. Stonebraker, N. Tatbul, and S. Zdonik. 2002. Monitoring streams: a new class of data management applications. In Proceedings of the 28th international conference on Very Large Data Bases (VLDB ’02). VLDB Endowment 215–226.
8. M. Cherniack, H. Balakrishnan, M. Balazinska, D. Carney, U. C¸ etintemel, Y. Xing, and S. Zdonik. Scalable distributed stream processing. In Proc. of the First Biennial Conference on Innovative Data Systems Research (CIDR’03), Jan. 2003.
9. S.B. Zdonik, M. Stonebraker, M. Cherniack, U. C¸ etintemel, M. Balazinska, and H. Balakrishnan. “The Aurora and Medusa Projects”, presented at IEEE Data Eng. Bull., 2003, pp.3–10.
10. M.S. Miller and K.E. Drexler. “Markets and Computation: Agoric Open Systems,” in The Ecology of Computation, B.A. Huberman, Ed.: North-Holland, 1988.
11.http://code.google.com/intl/en/appengine/docs/
12. A. Bedra. “Getting Started with Google App Engine and Clojure,” Internet Computing, IEEE, vol.14, no.4, pp.85–88, July-Aug. 2010.
13.http://www.microsoft.com/windowsazure/
14. S. Shivle, R. Castain, H.J. Siegel, A.A. Maciejewski, T. Banka, K. Chindam, S. Dussinger, P. Pichumani, P. Satyasekaran, W. Saylor, D. Sendek, J. Sousa, J. Sridharan, P. Sugavanam, and J. Velazco. “Static mapping of subtasks in a heterogeneous ad hoc grid environment,” in Proc. of 13th HCW Workshop, IEEE Computer Society, 2004.
15. G.T. Lakshmanan and R. Strom. Biologically-inspired distributed middleware management for stream processing systems. ACM Middleware conference, 2008.
16.http://www.ibm.com/developerworks/cloud/library/cl-mapreduce/index.html
17. T. Sandholm and K. Lai. MapReduce optimization using regulated dynamic prioritization. In Proceedings of the11thInternational Joint Conference on Measurement and Modeling of Computer Systems (SIGMETRICS), pages 299–310, 2009.
18. S.Thulasidasan, S.P. Kasiviswanathan, S. Eidenbenz, P. Romero. “Explicit Spatial Scattering for Load Balancing in Conservatively Synchronized Parallel Discrete Event Simulations,” Principles of Advanced and Distributed Simulation (PADS), 2010 IEEE Workshop on, vol., no., pp.1–8, 17–19 May 2010.
19. Z. Sui, N. Harvey, and S. Pallickara. Orchestrating Distributed Event Simulations within the Granules Cloud Runtime, Technical Report CS-11 Colorado State University, June 2011. 20. E. Deelman. and B.K. Szymanski. “Dynamic load balancing in parallel discrete event
simulation for spatially explicit problems,” Parallel and Distributed Simulation, 1998. PADS 98. Proceedings. Twelfth Workshop on, vol., no., pp.46–53, 26–29 May 1998.