MULTI LEVEL SEMANTIC
EXTRACTION FOR CRICKET VIDEO
BY TEXT PROCESSING
Dr. SUNITHA ABBURU
Professor & Director, Department of Computer Applications Adhiyamaan College of Engineering,
Hosur,pin-635109, Tamilnadu,India.
Abstract
Semantic video analysis, indexing and retrieval are necessary for effective utilization of video repositories. The semantics can be extracted from the semantic carriers such as voice and video text. Super imposed text is the proper source to extract semantics of the video which will increase the efficiency of retrieval system. This paper proposes a semiautomatic method to generate annotation for cricket videos and an automated tool- DLER, to extract the semantics of cricket video. The DLER tool provides a fast and robust approach for text Detection, Localization, Extraction, and Reorganization in video frames, which is flexible and customer friendly. The DLER integrates all the pre-processing steps and the OCR steps in to a single unit. The annotator can pick the ROI, increase or decrease the threshold, contrast, brightness or inverse the image based on the type of the broadcasted video. The tool has been implemented and tested with cricket video and the results of the experiments are promising. Finally conclusion and future work has been discussed.
Keywords: Video Semantics, Annotation, Text recognition.
1. Introduction
The stored multimedia data poses a number of challenges in the management of multimedia information, including data and knowledge representation, indexing and retrieval, intelligent searching techniques, information browsing and query processing. The advance in video, communications and storage technology have made video the most popular type of media in various applications. Thus, semantic video analysis and management, including video understanding, indexing and retrieval are necessary for the effective utilization of video repositories. The rapid growth of video data leads to an urgent demand for efficient and true semantic based browsing and retrieving system. To meet such needs, video contents must be analyzed and semantics must be extracted. The natural language representation of a video sequence can most directly be extracted from semantic information carriers such as voice, closed caption text, scene text, and super imposed text. Voice and closed captions provide index information on the spoken content. Text in video frames is a form of semantic content. It is very useful for describing the contents of video data, and it enables applications such as text-based image indexing, Keyword-based video indexing and search. Text is ubiquitous in videos, and generally provides brief and important supplemental content information about the video being displayed .Video text provides high-level semantic information. However, due to the complex background in video, it is of great difficulty to extract text efficiently.
The common indexing and retrieval process is as follows, multimedia objects in the database are preprocessed to extract features and they are indexed based on these features. During retrieval, queries are processed and main features are extracted. Then the semantic similarity between the query and the multimedia object features are computed and the retrieval technique is based on ranking video objects. Current approaches to content based video retrieval differ in terms of which video features are extracted. There are two major categories of features, low level features and high level semantics.
result of query processing. This is due to the gap between low level features and high level semantics of the objects. Improvement in the effectiveness of the retrieval process is possible by understanding the information at the semantic level. However, most of the multimedia data bases are queried by specifying semantic content in which subjective descriptions are given in a query.
Logical features: Domain knowledge is required to capture the semantics of the video. A simple approach to manage the semantic content of multimedia objects is to annotate an image, video with text. Annotations are free text descriptions. The multimedia objects may be fully annotated or partially annotated. The performance of the retrieval system depends upon the amount of information available in the database about the multimedia objects. The amount of annotation to be provided depends upon the users’ community and their queries. Query range from least complex (who, where, when) to most complex (why) types. Annotation based approach is adopted by [6] [17]. However, it is not clear how much annotation is sufficient for a specific database and what the best subset of objects to annotate. In these studies a textual description representing semantic context is assumed to be defined for an image by a human. These studies focus on ‘retrieval-by-content’, which cannot be extracted from an image through image processing.
Advantage of annotation based method is that it can be easily implemented. Another important advantage is that ‘misevaluation’ of contents will hardly occur, which is a serious problem with primitive features. In these studies semantic contents are extracted from the image, video by manual annotator. The perception of two different humans may be different. They may give different descriptions for a single multimedia object, which further may lead to ambiguity. The inherent ambiguity in natural language is studied by E.M. Voorhees in [18]. Automatic annotation may not attain extremely high accuracy with the present technology. Edward Chang, Kingshy Goh [4] discusses some refinement methods that can improve annotation accuracy. Due to these difficulties with manual and fully automated generation of annotations, we proposed a semi automated method for generation of metadata. In the field of automatic video summarization, sports video has been a popular application because of its popularity to users and simplicity due to repeated patterns [3], [7].
The paper is organized as follows: Section 2 presents related research work. Section 3 describes proposed method fortext extraction from video frames. Section 4 contains a practical implementation of DLER
tool. Finally conclusions and future works are drawn in section 5.
2. Related Work
Text contains semantic information and thus can contribute significantly to video retrieval and understanding. Therefore, video text recognition is crucial to the research in all video indexing and summarization domains. Depending on the features utilized, the approaches may be roughly classified into four groups: region-based [13], edge-based [1][2], texture-based [5][19] and MPEG-based [14]. Region-based methods use the properties of the color. [22] presents two approaches for locating text in complex color images, and validates that the combination of the two approaches is shown to be more effective. In [8], a text detection and localization method for video is proposed using color histogram and heuristics. In [15], authors present an approach for text extraction from video frames, which can handle complex image backgrounds, deal with different font sizes, font styles, and font appearances such as normal and inverse video. In [10], the algorithms make use of typical characteristics of text in videos in order to enable and enhance the segmentation performance. Edge-based approaches are also considered useful for overlay text detection since text regions contain rich edge information. The commonly adopted method is to apply an edge detector to the video frame and then identify regions with high edge density and strength. This method performs well if there is no complex background and it becomes less reliable as the scene contains more edges in the background. Xin Zhang et al discuss [21] combines two methods, called color-edge combined algorithm, to remove text background. One of the combined methods is based on the exponential changes of text color, called Transition Map model, the other one uses the text edges of different gray level image. After removing complex background, text location is determined using the vertical and horizontal projection method.Shuicai Shi et al [16], present a fast and robust approach for text detection, localization, extraction, and reorganization in video frames with complex background. Noboru Babaguchi [12] Introduces a strategy of inter model collaboration aims to improve the reliability and efficiency in contents analysis of video focusing on temporal correspondence between visual and CC streams.
3. Text Extraction from Video Frames
Text in the video frames can be classified broadly into two categories, superimposed (caption, artificial or overlay) text and scene text.
the context of video and will not convey complete semantics of the video.This kind of text may be useful in the applications such as navigation, surveillance and scene understanding.
Fig 1 scene text
Superimposed Text: Superimposed text see Fig.2 is mechanically added to the video frames to summarize the visual context by supplement concise description of the visual or spoken information, such as titles of news and movie video stories, sports videos contain text describing the scores and team or player
Fig. 2 Super Imposed Text
names. Superimposed text is the most reliable source of semantic data, which gives more accurate content information to generate the annotation. In contrast to that, super imposed text is mechanically superimposed on the video scene and used to help viewers’ understanding. Since the super imposed text is highly compact and structured, it can be used for video indexing and retrieval. In the sports video player names, player personal details, score, world records, hat tricks etc., often appear and summarize the visual content.
Since the state-of-the-art optical character recognition techniques are far more robust than the existing speech analysis techniques and visual object analysis techniques, and on the other hand, text-based search has been successfully applied in many applications, text detection in video frames is of course a good approach for video content analysis and management, which attracts significant research interests [9] [11]. However, texts in different videos may take on a wide variety of forms. The characters may be large or small. The color may be white, blue or red. What is worse, low resolution, various font styles, together with complex background making the text detection a hard task. Video text recognition is generally divided into four steps: detection, localization, extraction, and recognition. In recent years, we see growing interest by researchers on detection, localization, extraction, and recognition text in video frames, due to increased interest in multimedia technology. The detection step roughly identifies text regions and non-text regions. The localization step determines the accurate boundaries of text rows. The text extraction step removes background pixels in the text rows and the text pixels are left for the recognition. The recognition step can be executed by OCR software.
The text present in the video frame must be converted into ASCII form. From the past few years researchers are finding techniques to recognize the superimposed text. However, super imposed text extraction for video optical character recognition (OCR) becomes more challenging, compared to the text extraction for OCR tasks of document images. Commercial OCR recognizes text in printed documents, text in these documents appears in uniform color on a clear background and the document is scanned in high resolution. For OCR systems to recognize characters efficiently a binary image (i.e., black characters on a white background) must be submitted. The binarization process is known as pre-OCR process.
concentrate only on content and separated from its context, may not convey the complete semantics. Semantic information extracted from a video object not only conveys information about that video object, but at the same time, it becomes semantic carrier for the next video object. In the real world, all video objects are logically related. To represent the complete semantics of the video, a logical connection must be considered, which is maintained by rule based approach. Some information content must be carried for the subsequent video objects. Hence, complete semantics of a video object can be extracted into two different levels. The first level of information that is content can be extracted directly from a video object either using super imposed text. The second level of information can be gathered from the previous video objects which act as semantic carriers for the current video object see Fig.3. To identify and represent complete semantics of a video, semantic information extracted from various video objects must be combined and maintained. For example, for every over, bowler details, over details etc must be maintained up to the end of that over and complete match. Batsman details must be carried for all video objects up to the dismissal of the batsman. Cumulative details like the match score, player score, number of wickets etc., must be maintained up to the end of the match.
To maintain this information, we have extracted the video semantics at two levels. The first level of information can be extracted directly from the video object using super imposed text. The second level of information is gathered from the previous video object, which are logically connected. The main aim is to extract and analyze the semantics of cricket video using which information can be posted into video data model and maintenance of concept based video indexing. The semantics are extracted by analyzing the text content using the rule based approach.
4. Proposed Method – A Practical Implementation of DLER Tool.
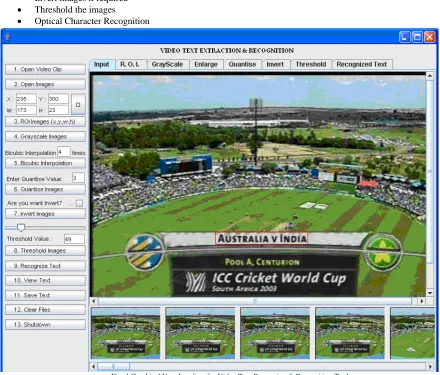
The primary aim of this paper is to propose novel techniques for Video text detection, localization, extraction, and recognition. The text extraction in video frames is difficult because of complex background, unknown text character color, and various stroke widths.Although many methods have been proposed for preprocessing, we propose a fully automatic method, a simple approach for preprocessing which integrates all the steps involved in Detection, Localization, Extraction, and Recognition as a simple and single tool see Fig 4. The DLER tool is customer friendly and integrates all preliminary steps in to a single tool. The frame work is as follows, Fig. 5.
Images extraction from video objects
Identifying the candidate regions
Converting into grayscale images
Resolution improvement by Bi-cubic interpolation
Applying brightness and contrast
Invert images if required
Threshold the images
Optical Character Recognition
Fig. 4 Graphical User Interface for Video Text Processing & Recognition Tool
Region of interest (ROI): The super imposed text which is displayed on broadcasted cricket video usually on a plain background and at a specific region. This feature mostly reduces the complexity of our text detection. Text displayed on the screen in cricket sports video attains positional notation, score, events, wickets, balls etc, information appear in a specific location in a specific format. Generally the score and other information is displayed on the bottom ¼ or top ¼ of the frame region [20]. The TV program editor would impose the text in the broadcast cricket video based on the importance of the event or special records, editor may super impose the text with different font in different style in different locations. Texts displayed at different regions have different semantics. Other important text information can appear in other regions of the video frame, which conveys important semantics. To extract such kind of text displayed on the broadcast video, the DLER tool should be flexible which allows the annotator to give the region of interest. The ROI can be provided once at the time of video processing or to extract more information annotator must have provision to select the ROI. Using this
DLER tool, the approach is simple the annotator can select the RIO by mouse drag and select the super imposed text as ROI.
Threshold: An expression for brightness and contrast modification of image is G(x, y) = a + (x, y) + b (1)
where a is gain and b is bias, image quality can be improved using linear mapping where we map a particular range of gray levels [f1,f2] onto a new range [g1,g2], this is increases the gain factor until two
Fig. 5 Image Processing and OCR Process
adjacent levels f1 and f2 are mapped onto the extremes of a 8 bit range, consequently gray levels up to and including f1 are mapped onto 0, whereas gray levels greater than f1 are mapped on to 255, where f1 acts as a threshold. And the mapping operation is termed as thresholding. Image thresholding is a segmentation technique
1 1
2 1 2
1 ( , )
) ,
( f f x y f
f f
g g g y x
G
(2)
because it classifies pixels into two categories, those at which some property measures from image falls below a threshold and those at which that property equals or exceeds the threshold. Because there are two possible output values, thresholding creates a binary image. The most common form of image thresholding makes use of pixel gray level. Gray level thresholding applies to every pixel the rule is
G(x, y) =0, f(x,y) < T
=1, f(x,y) T (3)
Invert: For OCR systems to recognize characters efficiently, the characters of the video text must be in black and the remaining pixels in white. In some cases the preprocessing of image may give an image with white characters on black background, where image inversion or negation operation is to be preformed. Negation or inversion is a special case of linear mapping where negative gain factor is applied to gray levels to get a negation of image.
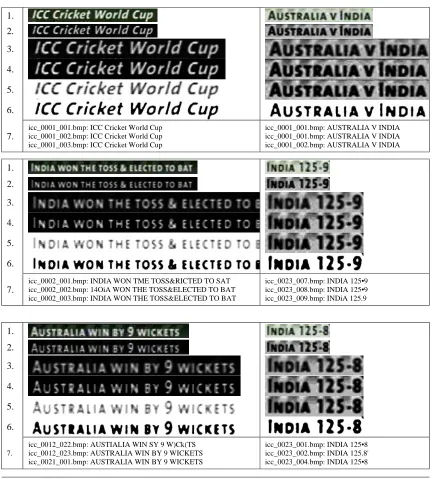
mean gray level of all other pixel. Since various types of images with various qualities are encountered to improve the image quality, auto threshold may not work well for all images. So the solution is relying on intrusion by a human operator, who can vary the threshold until acceptable results are achieved. Bicubic Interpolation will produce results a little sharper than those from linear interpolation. DLER has been implemented, tested and the experimental results are promising, shown in table 1.
Table 1. Experimental Results: Image Processing & OCR Process
1. 2. 3. 4. 5. 6.
7.
icc_0001_001.bmp: ICC Cricket World Cup icc_0001_002.bmp: ICC Cricket World Cup icc_0001_003.bmp: ICC Cricket World Cup
icc_0001_001.bmp: AUSTRALIA V INDIA icc_0001_001.bmp: AUSTRALIA V INDIA icc_0001_002.bmp: AUSTRALIA V INDIA
1. 2. 3. 4. 5. 6.
7.
icc_0002_001.bmp: INDIA WON TME TOSS&RICTED TO SAT icc_0002_002.bmp: 14OiA WON THE TOSS&ELECTED TO BAT icc_0002_003.bmp: INDIA WON THE TOSS&ELECTED TO BAT
icc_0023_007.bmp: INDIA 125•9 icc_0023_008.bmp: INDIA 125•9 icc_0023_009.bmp: INDiA 125.9
1. 2. 3. 4. 5. 6.
7.
icc_0012_022.bmp: AUSTIALIA WIN SY 9 W)Ck(TS icc_0012_023.bmp: AUSTRALIA WIN BY 9 WICKETS icc_0021_001.bmp: AUSTRALIA WIN BY 9 WICKETS
icc_0023_001.bmp: INDIA 125•8 icc_0023_002.bmp: INDIA 125.8' icc_0023_004.bmp: INDIA 125•8
1. Original Image. 2. Grayscale Image. 3. Bicubic Interpolation. 4. Quantisation. 5. Invert. 6. Thresholding. 7. OCR Results.
5. Conclusion and Future Work
proposed a semiautomatic method to generate the annotation for the cricket videos. We have proposed and implemented DLER tool which integrates the text detection, localization, and extraction and recognition procedures in to a single tool. The beauty of the DLER is flexibility and user friendly. The annotator can pick the ROI to locate super imposed text, increase or decrease the threshold value contrast brightness of inverse the image based the type of the broadcasted video. This annotator can make the judgement based on the quality, background of the image. The DLER tool has been implemented and tested with a variety of video objects, and the results of experiments are promising. Further research could be conducted on multimodal processing to fully automate the semantic extraction process. Audio can be another source of the video semantics and more accurate semantics can be extracted by multimodal processing.
Acknowledgment
This work has been partly done in the labs of Adhiyamaan College of Engineering where the author is currently working as a Professor& Director in the department of Master of Computer applications. The author would like to express her sincere thanks to Adhiyamaan College of Engineering for their support rendered during the implementation of this module.
References
[1] Carcia C, Apostolidis X, “Text detection and segmentation in complex color images”, IEEE International Conference on Acoustics, Speech and Signal Processing, Istanbul, 2000, pp. 2326-2329.
[2] Chen DT, Odobez JM, Thiran JP, “A localization/verification scheme for finding text in images and video frames based on contrast independent feature and machine learning methods”, Signal Processing: Image Communication. 2004(19), pp. 205-217.
[3] Dimitrova.N, et al, “Applications of video content analysis and retrieval,” IEEEMultimedia, vol. 9, pp. 43–55, 2002.
[4] Edward Chang, et al , “ CBSA: Content – Based Soft Annotation For Multimodal Image Retrieval Using Bayes Point Machines”, IEEE Transactions on Circuits and Systems for Video Technology, vol.13, no.1, pp 26-34 , Jan 2003.
[5] Gllavata J, Ewerth R, Freisleben B, “Text detection in images based on unsupervised classification of high-frequency wavelet coefficients”, International Conference on Pattern Recognition. Cambridge, UK, 2004, pp. 425-428.
[6] Jurgen Assfalg, et al, “Semantic Annotation of sports videos”, IEEE, Multimedia, Jun 2002.
[7] Kim. E, et al ,“A video summarization method for basketball game,” Lecture Notes onComputer Science, vol. 3767, pp. 765–775, 2005.
[8] Kim H.K. Efficient automatic text location method and content based indexing and structuring of video database, J. Visual Communication, Image Representation 7 (4) (1996)336–344.
[9] Kim Wonjun, Kim Changick, “A new approach for overlay text detection and extraction from complex video scene”, IEEE Transactions on Image Processing, v 18, n 2, 2009, pp. 401-411.
[10] Lienhart R. W. Effelsberg, Automatic text segmentation and text recognition for video indexing, Technical Report TR-98-009, Praktische Informatik IV, University of Mannheim, 1998.
[11] Minhua Li, Wang, Chunheng, “An adaptive text detection approach in images and video frames”, Proceedings of the International Joint Conference on Neural Networks, 2008, pp. 72-77.
[12] Noboru Babaguchi, Yoshihiko Kawai and Tadahiro Kitahashi, “Event Based Indexing Of Broadcasted Sports Video By Intermodal Collaboration”, IEEE, Transaction on Multimedia, vol 4, no.1, pp 68-75, Mar 2002.
[13] Pei SC, Chuang YT, “Automatic Text Detection Using Multi-layer Colorquantization in Complex Color Images”, IEEE International Conference on Multimedia and Expo, Taipei, 2004, pp. 619-622.
[14] Qian, Xueming, et al, “Text detection, localization, and tracking in compressed video”, Signal Processing: Image Communication, 2007, 22(9), pp.752-768.
[15] Shim J.C. C. Dorai, R. Bolle, Automatic text extraction from video for content-based annotation and retrieval, Proceedings of International Conference on Pattern Recognition, Vol. 1, Brisbane, Qld, Australia, 1998, pp. 618–620.
[16] Shuicai Shi; et al, A Smart Approach for Text Detection, Localization and Extraction in Video Frames , International Conference on Information Technology and Computer Science, 2009. ITCS 2009. 25-26 July 2009,pp 158 – 161.
[17] Vijay Khatri, Sudha Ram and Richard T. Snodgrass ,” Augmenting a Conceptual Model With Geospatiotemporal Annotations”, IEEE Transactions on Knowledge and Data Engineering, vol.16, no.11, pp.1324-1338, Nov 2004.
[18] Voorhees E.M., “Using WordNet to Disambiguate word senses for Text Retrieval:, Proc. ACM SIGIR Conf., pp.171-180, 1993. [19] Wang YK, Chen JM, “Detecting Video Texts Using Spatial-Temporal Wavelet Transform”, The 18th
International Conference on Pattern Recognition, Hong Kong, 2006, pp. 754-757.
[20] Xingquan zhu ,et al , “Video Data Mining : Semantic Indexing and event Detection from the Association Perspective“, IEEE Transactions on Knowledge and Engineering: vol 17, no.5, May 2005.
[21] Zhang Xin, et al, A combined algorithm for video text extraction, Seventh International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), 2010,10-12 Aug. 2010, PP 2294 – 2298.