International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 12, December 2015)
49
A Study on Several Issues of Reliability Modelling for a Real
Dataset using different Software Reliability Models
Ashwini Kumar Srivastava
1, Vijay Kumar
21Department of Computer Application, Shivharsh Kisan P.G. College Basti, U.P., India 2Department of Mathematics & Statistics, D.D.U. Gorakhpur University Gorakhpur, U.P., India Abstract—In this paper, we consider five two-parameter
reliability models and investigate the suitability on a single real data set. For this ground, we estimate the parameters of these proposed models using method of Maximum Likelihood. we check the validity of these models on same real data set by using modus operandi which are easy to understand and implement, and are based on intuitive and graphical techniques such as Q-Q plot test, Kolmogorov–Smirnov (K-S) test. These tests are used to investigate whether an assumed models adequately fits a set of proposed data. We present power comparison between these models for Model Selection obtaining by frequently used model selection techniques like Akaike information criterion (AIC) and Bayesian information criterion(BIC) to obtain feasible reliability model which are most suitable for software reliability modeling on this data set. We used different tools which are developed in R language and environment for model analysis, estimation of parameters using method of maximum likelihood, model validation and model selection.
Keywords—Software Reliability model, probability density function (pdf'), cumulative distribution function (cdf), model validation, Q-Q test, goodness of fit test, model selection, AIC, BIC.
I. INTRODUCTION
In recent years, new classes of reliability models have been proposed based on modifications of the existing model. Several exponentiated models have been studied quite extensively, since the work of [18] on Exponentiated Weibull model due to the existence of simple elegant closed form solutions to many life-testing problems. It can easily be justified under the assumption of constant failure rate but in the real world, the failure rates are not always constant. Hence, indiscriminate use of exponentiated lifetime model seems to be inappropriate and unrealistic. A classical generalization of the exponentiated family is known as Weibull family.
Weibull model is one of the most commonly used lifetime distributions in reliability and lifetime data analysis. It is flexible in modeling failure time data, as the corresponding hazard rate function can be increasing, constant or decreasing.
But in many applications in reliability and survival analysis, the hazard rate function can be of bathtub shape. The hazard rate function plays a central rule to the work of reliability engineers, [15] and [5] and references therein. Models with a bathtub hazard rate function are needed in reliability analysis and decision making when the life time of the system is to be modeled.
In software reliability modeling, failure data forms the basis for the model building. This kind of model is also called data dependent model. It involves the following steps:
Step 1: Model description and estimation of its parameters;
Step 2: Model validation; and Step 3: Model selection.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 12, December 2015)
50
II. MODEL ANALYSIS
We have selected the following models for analysis of software reliability data.
1. Gumbel Model
In reliability theory, the Gumbel model [9] is used to model the distribution of the maximum (or the minimum) of a number of samples of various distributions. The potential applicability of the Gumbel model to represent the distribution of maxima relates to extreme value theory which indicates that it is likely to be useful if the distribution of the underlying sample data is of the normal or exponential type. The Gumbel model is a particular case of the generalized extreme value distribution or Fisher-Tippett model [7]. It is also known as the Log-Weibull model. The two-parameter Gumbel model has one location and one scale parameter[13]. The random variable x follows Gumbel model with the location and scale parameter as - < < and σ > 0 respectively, if it has the following cummulative distribution function(cdf)
F(x; , ) = exp exp - x- ; x ( , ) (1)
Here and σ are the parameters, respectively and the Gumbel model has the following probability density function:
1
f(x; , ) = exp u exp(-exp(u)) ; x ( , )
-(x- ) where, u= .
(2)
The shape of the Gumbel model does not depend on the distribution parameters.
Some of the specific characteristics of the Gumbel model are:
The shape of the Gumbel model is skewed to the left. The pdf of Gumbel model has no shape parameter. This means that the Gumbel’s pdf has only one shape, which does not change.
The pdf of Gumbel model has location parameter μ which is equal to the mode but differs from median and mean. This is because the Gumbel model is not symmetrical about its μ.
As μ decreases, the pdf is shifted to the left. As μ increases, the pdf is shifted to the right.
FIGURE I: PLOTS OF PDF OF GUMBEL MODEL FOR =1 AND
DIFFERENT VALUES OF
The R functions dgumbel( ) and pgumbel( ) can be used for the computation of pdf and cdf, respectively. Some of the typical Gumbel density functions for different values of and for σ = 1 are depicted in Figure1. It is clear from the Figure1 that the density function of the Gumbel model can take different shapes. The two-parameter Gumbel model will be denoted by GM(μ, σ).
2.Exponentiated Gumbel Model
The Exponentiated Gumbel (EG) model has been proposed as a generalization of the classical Gumbel model[9]. Since the Gumbel model yields narrower confidence intervals than the some other extreme value models but has also the risk of under-estimating the return level. Hence, the choice of model is not insignificant [14].
Recently, a generalization of the Gumbel model, also called the Exponentiated Gumbel (EG) model, was introduced by [19]. The cumulative distribution function of Exponentiated Gumbel model with two parameters is given by
x
F(x) exp exp ; x , 0, 0.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 12, December 2015)
51
FIGURE II: PLOTS OF PDF OF EG MODEL FOR =1 AND DIFFERENT
VALUES OF .
Where α > 0 is the shape and σ > 0 is the scale parameter. The probability density function is given by
x x
f (x) exp exp exp ;
x , ( , ) 0.
(4)
Some of the typical EG density functions for different values of α and for σ= 1 are depicted in Figure 2.
The R functions dexpo.gumbel( ) and pexpo.gumbel( ) can be used for the computation of pdf and cdf, respectively. It is clear from the Figure 2 that the density function of the Exponentiated Gumbel model can take different shapes. The two-parameter Exponentiated Gumbel model will be denoted by EG(,).
3. Dhillon Model
A new reliability model with two parameters, which is flexible like the Weibull model, and with the capacity to also describe a U-shape hazard function, is described in [8]. This model is revisited by [4] and shown that it has an inverted U-shape similar to the log-logistic hazard function, but with a different curvature, especially after the peak. For α > 0 and β > 0, the two-parameter Dhillon model has the distribution function;
1F(x) 1 exp
log
x 1
;
x 0,
0,
0.
(5)
Here α and β are the shape and scale parameters respectively. The Dhillon model has the probability density function
11
f (x) log x 1
x 1
exp log x 1 ;
where, x 0, 0, 0.
(6)
It is observed that the probability density function (pdf) of a Dhillon model is a decreasing function and it is a right skewed unimodal function for α ≥ 1. Different forms of the density functions are plotted in Figure 3. The R functions dDhillon( ) and pDhillon( ) can be used for the computation of pdf and cdf, reapectively. Some of the typical DL density functions for different values of β and for = 1 are depicted in Figure 3.
FIGURE III: PLOTS OF PDF OF DHILLON MODEL FOR =1 AND
DIFFERENT VALUES OF
.It is clear from the Figure 3 that the density function of the Dhillon model can take different shapes. The two-parameter Dhillon model will be denoted by DL(α, β).
4.Exponentiated-Logistic model
Exponentiated-logistic model introduced by Ali et al.[3]. The distribution function of Exponentiated-logistic model with two parameters is given by
xF x, , 1 exp ;( , ) 0, x 0.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 12, December 2015)
52
Where > 0 is the shape and > 0 is the scale parameter. The probability density function is given by
x x (1 )f x, , exp 1 exp ;
Where ( , ) 0, x 0.
(8)
The R functions dexpo.logis( ) and pexpo.logis( ) can be used for the computation of pdf and cdf, respectively. Some of the typical EL density functions for different values of and for =1 are depicted in Figure 4.
FIGURE IV: PLOTS OF PDF OF EL MODEL FOR =1 AND DIFFERENT
VALUES OF
.It is clear from the Figure 4 that the density function of the EL model can take different shapes. The two-parameter Exponentiated-Logistic model will be denoted by EL(, ).
5. Exponentiated Log-Logistic Model
The Exponentiated Log-Logistic (ELL) model has been proposed as a generalization of the usual exponential distribution and [20] proposed exponentiated type models extending the Frchet, gamma, Gumbel and Weibull models. [21, 22] studied the reliability test plan for exponentiated log-logistic model. [23] introduced the Kumaraswamy-log-logistic model, which includes exponentiated log-Kumaraswamy-log-logistic model. Since the cdf of the log-logistic model is given by
LL
x /
F (x; , ) ; ( , ) 0, x 0
1 x /
.
Where
0
is the shape and
0
is the scale parameter.The cdf of the exponentiated log-logistic (ELL) model is defined by raising FLL(x) to the power of
, namely
LL
F(x) F (x) . The distribution function of ELL model with two parameters is given by
x
F(x; , ) ; ( , ) 0, x 0 1 x
(9)
Where
0
and 0 are the shape parameters. The probability density function is given by
1 x
f (x; , ) ; ( , ) 0, x 0
x 1 x
(10)
The R functions dexpo.log.logistic( ) and pexpo.log.logistic( ) can be used for the computation of pdf and cdf, respectively. Some of the typical ELL density functions for different values of β and for α = 1 are depicted in Figure 5.
FIGURE V: PLOTS OF PDF OF EEL MODEL FOR =1 AND DIFFERENT
VALUES OF
.International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 12, December 2015)
53
III. REAL DATASET FOR MODEL ANALYSIS
For numerical illustration, we have considered the real dataset DATASET2.DAT reported in the ―Handbook of Software Reliability Engineering‖ M. R. Lyu, Editor, McGraw-Hill, New York, [17]. It contains lines of code installed on over 100,000 controllers. The 36 months of defect-discovery times for a release of Controller Software consisting of about 500,000 defects are those that were present in the code of the particular release of the software, and were discovered as a result of failures reported by users of that release, or possibly of the follow-on release of the product[12].
IV. COMPUTATION OF MLE FOR PROPOSED MODELS
[image:5.612.45.298.466.631.2]The estimation of the parameters of proposed models are achieved by the method of maximum likelihood(ML) estimation. We have started the iterative procedure by maximizing the log-likelihood function of corresponding model directly with an initial guess for first parameter is 1.0 and second parameter is 0.1 for away from the solution[26, 28]. We have used maxLik( ) function in R with Quasi-Newton-Raphson method[25, 27]. The iterative process stopped only after various no. of iterations depend on used data set[11]. The Table1 shows the ML estimates and Log-Likelihood value of the both parameters for proposed models.
TABLE I.
ML ESTIMATES WITH CORRESPONDING LOG-LIKELIHOOD
S.N. Model
MLE
Log- Likelihood Parameter 1 Parameter 2
1 GM(μ, σ) 212.9489 151.8883 -734.5817
2 EG(,) 4.050777 152.123838 -734.5817
3 DL(α, β) 0.00536029 1.35806644 -733.4651
4 EL(, ) 5.318121 138.915672 -736.1956
5 ELL(α, β) 125.485114 0.9657097 -765.6982
V. MODEL VALIDATION FOR PROPOSED MODELS
Most statistical methods assume an underlying model in the derivation of their results. However, when we presume that the data follow a specific model, we are making an assumption. If such a model does not hold, then the conclusions from such analysis may be invalid.
Although hazard plotting and the other graphical methods can guide the choice of the parametric distribution, one cannot of course be sure that the proper model has been selected. Hence model validation is still necessary to check whether we have achieved the goal of choosing the right model[17]. In this paper we outline some of the methods used to check model appropriateness.
A. Kolmogorov–Smirnov Test
The Kolmogorov–Smirnov test (K–S test) is a nonparametric test for the equality of continuous and that can be used to compare a sample with a reference probability model. The Kolmogorov–Smirnov statistic quantifies a distance between the empirical distribution function of the sample and the cumulative distribution function of the reference distribution[10].
The Empirical Distribution Function(EDF)
An estimate of F(x) = P[ X ≤ x] is the proportion of sample points that fall in the interval [-, x]. This estimate is called the empirical distribution function(EDF). The EDF of an observed sample xl, x2,. . . , xn is defined by
1:n
n i:n i 1:n
n:n
0 for x X
i
F (x) for X x X ; i 1, . . ., n 1
n
1 for x X
where xl:n, x2:n, . . . , xn:n is the ordered sample.
The Kolmogorov–Smirnov (K-S) test is a nonparametric goodness-of-fit test and is used to determine whether an underlying probability distribution (Fn(x)) differs from a hypothesized distribution (F0(x)).
Kolmogorov-Smirnov (K-S) distance
The K-S distance between two distribution functions is defined as
n n 0 i
1 i n
D max F (x) F (x )
,
and n 0 i n
1 i n
D max F (x ) F (x)
,
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 12, December 2015)
54
n
n n
1 i n
D max D , D
The distribution of the K-S statistic does not depend on F0 as long as F0 is continuous.
To study the goodness-of-fit of the proposed models, we compute the Kolmogorov-Smirnov statistic between the empirical distribution function and the fitted distribution function when the parameters are obtained by method of maximum likelihood and mentioned in Table 1. We shall use the ks.gumbel( ), ks.expo.gumbel( ), ks.Dhillon( ), ks.expo.logis( ) and ks.expo.log.logistic( ) functions in R for corresponding models to perform the test[12, 13] and result of K-S test is shown in Table 2.
TABLE II.
KS-DISTANCE AND ITS CORRESPONDING P-VALUE
S.N. Model KS-Distance p-value
1 GM(μ, σ) 0.0712 0.6267
2 EG(,) 0.0707 0.6364
3 DL(α, β) 0.0956 0.2618
4 EL(, ) 0.0742 0.5749
5 ELL(α, β) 0.1663 0.004315
[image:6.612.342.542.469.648.2]Since, the high p-value clearly indicates that the proposed model can fit very well and used to analyze the given data set, and we have also plotted the comparative graph for supporting Table 2 in Figure 6.
FIGURE VI: PLOTS OF KS-DISTANCE AND ITS P-VALUE WITH CORRESPONDING PROPOSED MODELS.
From Figure 6, the p-value of the model ELL(α, β) is too low, thus we can say that on the behalf of this test only GM(μ, σ), EG(, σ), DL(α, β) and EL(, ) models fit to the given data set.
B. The Q-Q Plots Test
The Q-Q plot test is used to investigate whether an assumed model adequately fits a set of data. It helps the analyst to assess how well a given theoretical distribution fits the data.
Let ˆF(x) be an estimate of F(x) based on xl, x2,. . . , xn. The scatter plot of the points
1 1:n
ˆF (p ) versus x
i : n , i = 1 , 2, . . . ,n ,
is called a Q-Q plot. Thus, the Q-Q plots show the estimated versus the observed quantiles. If the model fits the data well, the pattern of points on the Q-Q plot will exhibit a 45-degree straight line. Note that all the points of a Q-Q plot are inside the square
1 1
1:n n:n 1:n n:n
ˆ ˆ
F (p ) , F (p ) x , x
.
We shall use the qq.gumbel( ), qq.expo.gumbel( ), qq.Dhillon( ), qq.expo.logis( ) and qq.expo.log.logistic( ) functions in R for corresponding models to perform the test and draw Quantile-Quantile (Q-Q) plot using MLEs as estimate for using data set given in Figure 7-11.
FIGURE VII: Q-Q PLOTS FOR GUMBEL MODEL
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7
GM(μ,σ) EG(α,σ) DL(α, β) EL(α, β) ELL(α, β)
KS-Distance
[image:6.612.51.290.497.689.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 12, December 2015)
[image:7.612.340.541.136.317.2]55
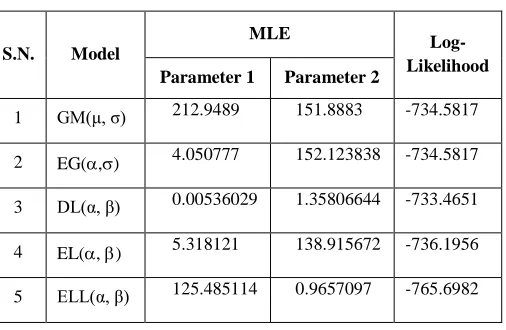
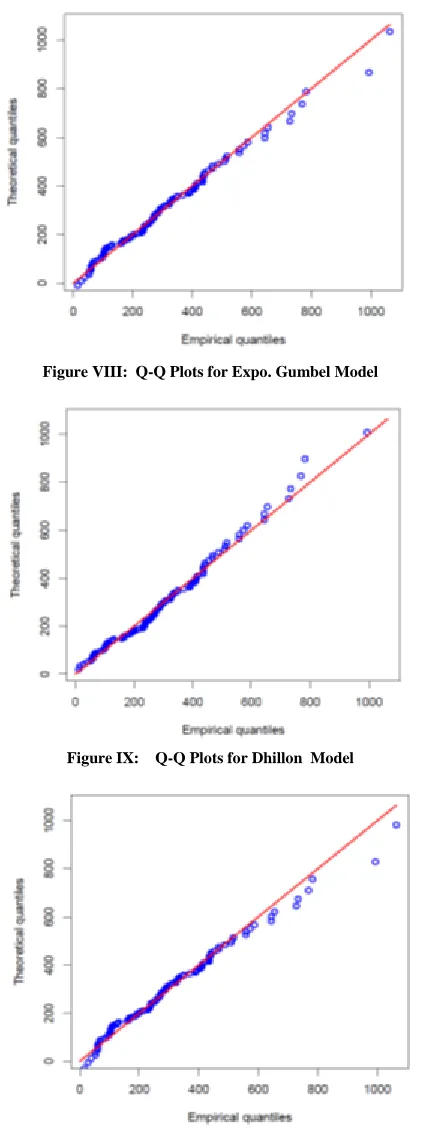
[image:7.612.63.281.138.704.2]Figure VIII: Q-Q Plots for Expo. Gumbel Model
Figure IX: Q-Q Plots for Dhillon Model
Figure X: Q-Q Plots for EL Model
FIGURE XI: Q-Q PLOTS FOR ELL MODEL
VI. MODEL SELECTION FOR PROPOSED MODELS
Modeling is an art as well as a science and is directed toward finding a good approximating model of the information in empirical data as the basis for statistical inference from those data. Modeling and model selection are essentially concerned with the ―art of approximation‖ [2].
Model choice is an integral and critical part of data analysis, an activity which has become increasingly more important as the ever increasing computing power makes it possible to fit more realistic, flexible and complex models. There is a huge literature concerning this subject [6, 16]. We will discuss some commonly used model selection methods such as Akaike’s Information Criterion(AIC) [1], and Bayesian Information Criterion(BIC) [24] .
A. Akaike’s Information Criterion(AIC)
Akaike’s information criterion (AIC) can be motivated in two ways. The most popular motivation seems to be based on balancing goodness of fit and a penalty for model complexity. AIC is defined such that the smaller the value of AIC the better the model. A measure of goodness of fit such that the smaller the better is minus one times the likelihood associated with the fitted model, while a measure of complexity is p, the number of estimated parameters in the fitted model. AIC is defined to be
AIC= - 2 loglikelihood + 2 p (11)
[image:7.612.66.553.144.708.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 12, December 2015)
56
B. Bayesian Information Criterion(BIC)
Schwarz[24] proposed the Bayesian information criterion as
BIC = - 2 loglikelihood + p log(n) (12)
Where p is the number of parameters estimated in the model. BIC is defined such that the smaller the value of BIC the better the model. Comparing (12) with (11), we see that BIC is similar to AIC except that the factor 2 in the penalty term is replaced by log( n ) but the penalty term in BIC is greater than the penalty term in AIC. Thus, in these circumstances, BIC penalizes complex models more heavily than AIC, thus favoring simpler models than AIC. In practice, BIC is generally used in a frequentist sense, thus ignoring the concepts of prior and posterior probabilities. We shall use the abic.gumbel( ), abic.expo.gumbel( ), abic.Dhillon( ), abic.expo.logis( ) and abic.expo.log.logistic( ) functions in R for corresponding models to perform the test of AIC and BIC . The Table 3 shows the values of different information measures (AIC, BIC) for model selection.
TABLE III.
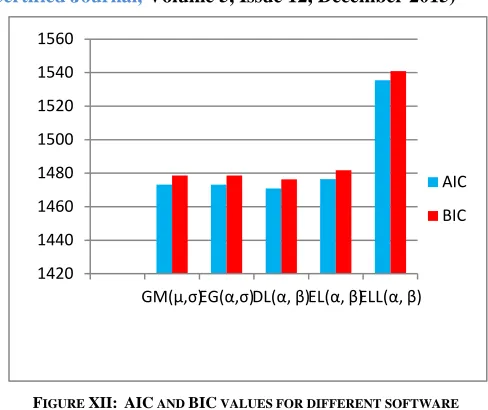
AIC AND BIC VALUE OF CORRESPONDING MODEL
S.N. Model AIC BIC
1 GM(μ, σ) 1473.163 1478.582
2 EG(,) 1473.163 1478.583
3 DL(α, β) 1470.93 1476.349
4 EL(, ) 1476.391 1481.81
5 ELL(α, β) 1535.396 1540.816
[image:8.612.321.565.125.330.2]and, we have also plotted the comparative graph of AIC and BIC with corresponding proposed models based on ML estimates for supporting Table 3 in Figure 12.
FIGURE XII: AIC AND BIC VALUES FOR DIFFERENT SOFTWARE RELIABILITY MODELS
Since, in both model selection techniques AIC and BIC require smaller the value for better the result(model). Then as can seen from Table 3 and Figure 12, the GM(μ, σ), EG(, σ), DL(α, β) and EL(, ) models much better for software reliability modeling to the given data set.
VII. CONCLUSION
An attempt has been made to incorporate the proposed models for software reliability data. We have presented the statistical tools for empirical modeling of the data in general. These tools are developed in R language and environment for model analysis, estimation of parameters using method of maximum likelihood, model validation and model selection. To check the validity of the model, we have plotted a graph of estimated versus the observed quantiles using Q-Q test for different software reliability models and also we have to present power comparison between p-values of these models obtaining by K-S test for receiving real data sets which are excellent good fit for Reliability analysis. We have also discussed the issue of model selection for the given data set. Thus, from both used techniques of model validation as well as model selection on a data set, the Exponentiated Log-Logistic model ELL(, )is not fit for given the data set for software reliability modeling.
1420 1440 1460 1480 1500 1520 1540 1560
GM(μ,σ) EG(α,σ) DL(α, β) EL(α, β) ELL(α, β) AIC
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 12, December 2015)
57
Acknowledgment
The authors are thankful to editor and the referees
for their valuable suggestions, which improved the
paper to a great extent.
REFERENCES
[1] Akaike, H. (1973). Information theory and an extension of the maximum likelihood principle. 2nd International Symposium on Information Theory, 267–281.
[2] Akaike, H. (1974). A New Look at the Statistical Model Identification, IEEE Transactions on Automatic Control, AC-19, 716—723.
[3] Ali, M.M., Pal, M. and Woo, J. (2007). Some Exponentiated Distributions, The Korean Communications in Statistics, 14(1), 93-109.
[4] Avinadav T. and Raz T. (2008). A New Inverted U-Shape Hazard Function, IEEE transactions on reliability, VOL. 57, NO. 1, 32-40. [5] Bebbington, M., Lai, C.D. and Zitikis, R. (2007). A flexible Weibull
extension, Reliab. Eng. Syst. Safety, 92, 719-726.
[6] Burnham, K. P. and Anderson D. R. (2002). Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach (2nd ed.).Springer, New York.
[7] Coles, Stuart (2001). An Introduction to Statistical Modeling of Extreme Values, Springer-Verlag. ISBN 1-85233-459-2.
[8] Dhillon, B.S. (1981). Life Distributions, IEEE Transactions on Reliability, vol. 30, no. 5, , pp.457-460.
[9] Gumbel, E.J.(1954). Statistical theory of extreme values and some practical applications. Applied Mathematics Series, 33. U.S. Department of Commerce, National Bureau of Standards.
[10] Hazewinkel, Michiel, ed. (2001), "Kolmogorov-Smirnov test", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4 [11] Ihaka, R. and Gentleman, R.R. (1996). R: A language for data
analysis and graphics, Journal of Computational and Graphical Statistics, 5, 299–314.
[12] Kenney, G.Q.,(1993). Estimating Defects in Commercial Software During Operational Use, IEEE Transactions on Reliability, vol. 42, no. 1, pp.107-115.
[13] Kumar, R., Srivastava, A.K. and Kumar, V. (2012). Analysis of Gumbel Model for Software Reliability Using Bayesian Paradigm, International Journal of Advanced Research in Artificial Intelligence, Vol. 1 (9), 39-45.
[14] Kumar, R., Srivastava, A.K. and Kumar, V. (2013). Exponentiated Gumbel Model for Software Reliability Data Analysis using MCMC simulation method, International Journal of Computer Applications, Vol.62(20), 24-32, ISSN: 0975–8887.
[15] Lai, C.D. and Xie, M. (2006). Stochastic Ageing and Dependence for Reliability, Springer.
[16] Linhart, H. and Zucchini, W. (1986). Model Selection, Wiley, ISBN: 0471837229
[17] Lyu M.R., (1996). Handbook of Software Reliability Engineering, IEEE Computer Society Press, McGraw Hill, 1996.
[18] Mudholkar, G.S. and Srivastava, D.K. (1993). Exponentiated Weibull family for analyzing bathtub failure-rate data, IEEE Transactions on Reliability, 42(2), 299–302.
[19] Nadarajah S. (2006). The Exponentiated Gumbel distribution with climate application, Environmetrics 17:13-23
[20] Nadarajah, S. and Kotz, S. (2006). The exponentiated type distributions. Acta Applicandae Mathematicae 92, 97-111.
[21] Rosaiah, K., Kantam, R.R.L. and Kumar, Ch. S. (2006). Reliability test plans for exponentiated log- logistic distribution, Economic Quality Control, 21(2), 165-175.
[22] Rosaiah, K., Kantam, R.R.L. and Santosh Kumar, Ch. (2007). Exponentiated log-logistic distribution - an economic reliability test plan. Pakistan Journal of Statistics, 23 (2), 147 -156.
[23] Santana, T.V.F., Ortega, E.M.M., Cordeiro, G.M. and Silva, G.O. (2012). The Kumaraswamy-Log-Logistic Distribution, Journal of Statistical Theory and Applications, 11(3), 265-291.
[24] Schwarz (1978). Handbook of Statistics: Bayesian Thinking, Modeling and Computation, Elsevier Ltd.
[25] Srivastava, A.K. (2012). A Study of Statistical Properties & Model Validation for Exponential Extension Model, COMPUSOFT, An international journal of advanced computer technology, Vol. 1(2), 1-7, ISSN: 2320 – 0790.
[26] Srivastava, A.K. (2013). Statistical Analysis and Model Validation of Gompertz Model on different Real Data Sets for Reliability Modelling, Journal of Advanced Computing and Communication Technologies Vol. 1(2), 1-8, ISSN: 2347 – 2804.
[27] Srivastava, A.K. and Kumar, V.(2011). ―Analysis of Software Reliability Data using Exponential Power Model‖, International Journal of Advanced Computer Science and Applications, Vol. 2(2), 38-45, ISSN:2156-5570.
[28] Srivastava, A.K. and Kumar, V.(2011). ―Markov Chain Monte Carlo Methods for Bayesian Inference of the Chen Model‖, International Journal of Computer Information Systems, Vol. 2(2), 07-14, ISSN: 2229-5208.