Federated Aggregated Search
Andr´es Marenco Z´u˜niga (s1155636)
University of Twente
Faculty of Electrical Engineering, Mathematics and Computer Science (EEMCS)
Databases Chair
Graduation committee: Dr.ir. Robin Aly Dr.ir. Djoerd Hiemstra
Federated Aggregated Search
by Andr´es Marenco Z´u˜niga
The traditional search engine paradigm has changed from retrieving simple text doc-uments, to selecting a broader combination of diverse document types (i.e. images, videos, maps...) that could satisfy the user’s information need. Each type of docu-ment, stored in specialized databases known as ‘verticals’, and found in either local or federated locations, is nowadays integrated into ‘aggregated search engines’.
Due to this domain coverage of each vertical, when a query enters the system, only the ones which are most likely to contain the desired information should be selected. To perform this selection, a text representation of each vertical is created by directly sampling a set of documents from the vertical’s search engine.
However, many times the vertical representation is not descriptive enough. Reasons such as the heterogeneous nature of the documents or the lack of cooperation of the ver-tical could negatively affect the generation of the representation. Thus, we focus on the problem of creating an aggregated search engine which integrates federated collections in an uncooperative environment.
With the help of Wikipedia as a complementary external source of information, we investigate the use of three techniques found in the literature aimed to enrich the vertical representation: a) using onlyWikipediaarticles as representation;b) using a combination of Wikipedia articles and the sample obtained from the vertical; and c) expanding the contents of each sampled document.
We discovered how by applyinglatent Dirchlet allocation to model the hidden topics of documents directly sampled from each vertical it is possible to identify Wikipedia articles with the same theme coverage as the vertical. Then, we demonstrate how by using onlyWikipediaarticles for representation of some particular verticals, the selection task is improved.
As a second point, we explored the use of the modeled topics together withWikipedia categories to boost the score of the verticals that could be associated with the query string. Although in this case our results are inconclusive, the experiments suggest that by applying query classification and then matching obtained categories with the verticals’ categories it is possible to increase the effectiveness of the vertical selection task.
First, I would like to thank my supervisors Dr.ir. Robin Aly and Dr.ir. Djoerd Hiemstra for all the time they took to guide me during my research process and for their advices when difficulties were found in the implementation of the project and the analysis of the results.
Thanks to the Ministry of Science, Technology and Telecommunications of Costa Rica (MICITT) and to the National Council for Scientific and Technological Research of Costa Rica (CONICIT) for their financial support during my studies in the Netherlands. I would also like to thank all my friends which helped me making an easier adaptation to a different country far away from home.
And finally I want to say thanks to my parents, that always supported me in one way or another so that I could reach my goals.
Abstract iii
Acknowledgements v
1 Introduction 1
1.1 Federated search . . . 1
1.2 Aggregated search . . . 2
1.3 Cooperative and uncooperative environments . . . 2
1.4 Challenges in aggregated search systems . . . 3
1.5 Research questions . . . 4
1.6 Thesis outline . . . 5
2 Literature 7 2.1 Background . . . 7
2.2 Vertical representation . . . 8
2.2.1 Query-based sampling . . . 9
2.2.2 Capture-recapture size estimation . . . 9
2.2.3 Sample-resample size estimation . . . 10
2.3 Vertical selection . . . 10
2.3.1 ReDDE . . . 11
2.3.2 Document-centric model . . . 12
2.4 Result presentation . . . 12
2.5 Keywords extraction . . . 13
2.6 Topic modeling . . . 13
2.6.1 Latent Dirichlet allocation . . . 14
2.7 Summary . . . 15
3 Vertical representation enrichment 17 3.1 Introduction . . . 17
3.2 Method . . . 17
3.2.1 Wikipedia articles representation . . . 18
3.2.2 Combined representation: Wikipedia articles and vertical sample 20 3.2.3 Sampled documents expansion . . . 21
3.3 Conclusion . . . 22
4.2 Method . . . 26
4.3 Conclusion . . . 28
5 Experiments 29 5.1 Experimental setup . . . 29
5.1.1 TREC FedWeb dataset . . . 30
5.1.2 Vertical collection indexing . . . 30
5.1.3 Wikipedia collection indexing . . . 32
5.1.4 Vertical selection baseline . . . 32
5.1.5 Evaluation metrics . . . 33
5.2 Vertical representation enrichment . . . 34
5.2.1 Wikipedia articles representation . . . 35
5.2.2 Combined representation: Wikipedia articles and vertical sample 35 5.2.3 Sampled documents expansion . . . 36
5.2.4 Results . . . 36
5.3 Vertical type boosting . . . 42
5.3.1 Results . . . 42
5.4 Discussion . . . 44
6 Conclusions 47 6.1 Vertical representation enrichment . . . 47
6.2 Vertical type boosting . . . 48
6.3 Future work . . . 48
Bibliography 51
A TREC FedWeb search engines and queries 56
B Vertical representation enrichment evaluation data 65
C Vertical type boosting evaluation data 69
1.1 Federated search . . . 2
1.2 Aggregated search . . . 3
1.3 Indexing stage in cooperative and uncooperative environments . . . 4
2.1 Vertical representation . . . 8
2.2 Result presentation . . . 13
2.3 Graphical model representation of LDA . . . 14
3.1 Wikipedia articles representation . . . 18
3.2 Example of LDA generated topics . . . 18
3.3 Combined representation: Wikipedia articles and vertical sample . . . . 20
3.4 Sampled documents expansion . . . 21
4.1 Topics labeling with Wikipedia categories . . . 26
4.2 Vertical type boosting . . . 26
5.1 Vertical collection indexing process . . . 31
5.2 Wikipedia collection indexing process . . . 32
5.3 Implementation of document-centric model in Lucene . . . 33
5.4 Indexing with Wikipedia articles representation . . . 35
5.5 Indexing with combined representation . . . 36
5.6 Indexing with sampled documents expansion . . . 36
5.7 Evaluation for Wikipedia articles representation . . . 37
5.8 Evaluation for combined representation . . . 38
5.9 Evaluation for sampled documents expansion . . . 39
5.10 Evaluation for vertical type boosting . . . 43
4.1 Wikipedia categories per level . . . 26
5.1 TREC FedWeb 2013 dataset summary . . . 30
5.2 Number of unique terms per vertical . . . 31
5.3 Vertical selection baseline evaluation . . . 32
5.4 Evaluation for Wikipedia articles representation . . . 37
5.5 Evaluation for combined representation . . . 38
5.6 Evaluation for sampled documents expansion . . . 39
5.7 Evaluation for enriching verticals with few terms . . . 41
5.8 Evaluation for enriching verticals with many terms . . . 41
5.9 Number of unique terms per vertical in W001 . . . 42
5.10 Evaluation for vertical type boosting . . . 43
5.11 Evaluation of training setd0 and test setd1 . . . 44
5.12 Evaluation of training setd1 and test setd0 . . . 44
A.1 TREC FedWeb search engines . . . 59
A.2 TREC FedWeb 2013 selected test queries . . . 60
A.3 TREC FedWeb 2013 vertical ideal ranking . . . 63
B.1 Unique terms count for the baseline index (documents only) . . . 66
B.2 Unique terms count for the W001 enriched index . . . 67
C.1 Data set partition for cross-validation . . . 69
C.2 Training ofd0 for vertical type boosting . . . 70
C.3 Training ofd0 for vertical type boosting (combined) . . . 70
C.4 Training ofd1 for vertical type boosting . . . 71
C.5 Training ofd1 for vertical type boosting (combined) . . . 71
Introduction
As many sources of diverse types of information have become available for the common user, the traditional search paradigm keeps facing the growing problem of crawling the hidden web [33]. Unbounded number of pages dynamically generated and documents unreachable due to robot exclusion protocols increases the complexity of determining the complete set of documents accessible on the web.
To avoid this situation, federated search [40] (ordistributed information retrieval) is presented as a solution to search the web from a different perspective. Instead of trying to crawl all the possible documents available in the multiple servers, the users’ query is simply redirected to the search engine interface provided by each data collection and the obtained results are merged into one single list.
However, as the information becomes more heterogeneous (images, video, news...), the collections integration requires more flexible solutions. To fulfill this information need, aggregated search [25] (also known asvertical search) is proposed.
With aggregated search, users now have the ability of querying with a simple web interface, different types of local and remote repositories (verticals) and obtain a single result page.
This thesis will be focused on the design and evaluation of an aggregated search system capable of integrating federated collections.
1.1
Federated search
Federated search is defined as the technique used for executing queries in distributed collections containing homogeneous types of documents.
As the search is performed in several external collections, it is important to make an efficient control of those resources. Therefore, the query is only dispatched to the most relevant ones for the user. For example, information about programming languages can be found in many computer science databases, but it might not be useful to search it in a collection specialized in biology.
In order to accomplish a proper collection selection, the federated search system must contain a correct representation of each resource with enough descriptive data to determine what type of information can be found on each one of them.
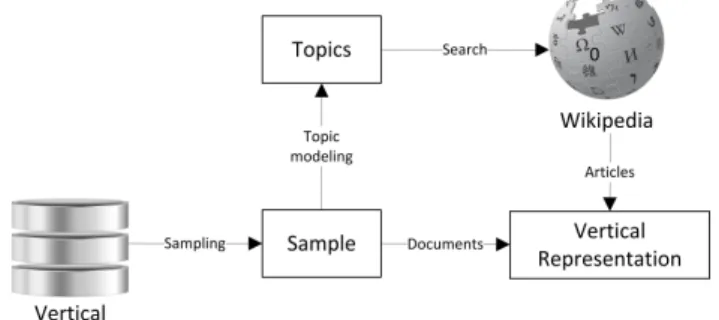
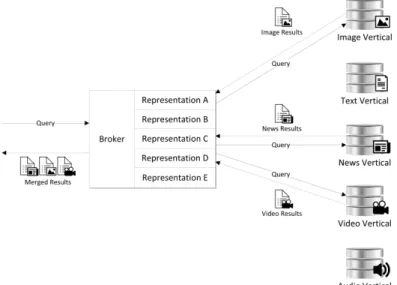
Figure 1.1, shows how a query enters the system and it is submitted by the broker to the appropriate collections. The results are finally merged in a single list and presented to the user.
Figure 1.1: Federated search
A common example is metasearch engines [29] such as Search.com1 and MetaCrawler (discontinued), where several sources are centralized (without maintaining a document index) in a simple interface that dispatches the query and returns a merged list of relevant results.
1.2
Aggregated search
As mentioned by Kopliku et al. [24], aggregated search is not a new research area. Ini-tially introduced by Murdock and Lalmas [30] and later extended by Diaz et al. [16], the concept is defined as one of the paradigms of federated search where several hetero-geneous collections (in this caseverticals) are integrated.
Each vertical is focused on a specific domain (news, blogs...) or on a specific docu-ment type (images, videos...). Those verticals are usually presented with a stand-alone search interface which allows the users perform specialized queries on the collection. However, in many cases the user might be interested in obtain results from several ver-ticals (e.g., searching for a musical band could return results from the “videos” vertical and from the “news” vertical).
Figure 1.2 shows how the information flow between the query and the verticals is equivalent as the information flow from federated search, but the output is a merged list with different types of documents.
Nowadays, every major search engine has some level of the described aggregation.
1.3
Cooperative and uncooperative environments
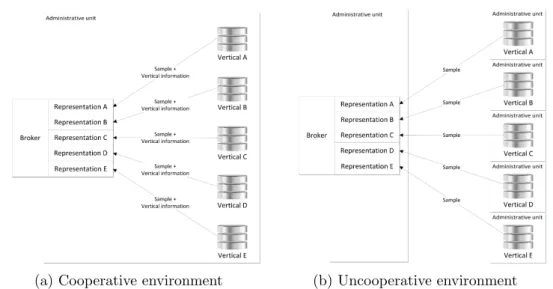
Depending on the available knowledge on the involved collections, both federated and aggregated search systems can be categorized in two opposite environments: cooperative and uncooperative [40] (see Figure 1.3).
1
Figure 1.2: Aggregated search
As the name suggests, the first one is found where the system have the facilities to obtain all the required information about the collection (such as metadata and collection size). The availability of this information simplifies many of the initial steps on creating the system and configuring the sources.
However, it is not always possible to have access to all the required information. This lack of knowledge leads to uncooperative environments and consequently exposes different challenges that should be properly addressed in order to develop an effective federated system.
1.4
Challenges in aggregated search systems
Lalmas [25] defines three main challenges that should be addressed while building an aggregated search system: vertical representation, vertical selection and result presen-tation (see also Chapter 2). Those challenges are briefly described as follows:
Vertical representation is the base of the system, where the content of each vertical is properly described. To achieve this description, a sample of the vertical can be obtained following techniques found in federated search [40]. However, the heterogeneous nature of the verticals’ content can occasionally lead to poor representations due to the difficulty of obtaining enough text description for some documents (for instance, an image file usually does not contains a full-text summarization of it).
The vertical selection challenge focuses on choosing the most suitable verticals to submit the user’s query. Here, the heterogeneity of the sources together with a wide variety of verticals suggests that in some situations the user might be aiming for an specific document type, but for other cases he might expect a mixture of different types of results.
(a) Cooperative environment (b) Uncooperative environment
Figure 1.3: Indexing stage in cooperative and uncooperative environments
Finally, the results have to be displayed to the user. Since many relevant answers can be obtained from several vertical types, it is important to identify the most convenient place to locate them in the web page, in order to improve the click-through behavior [45].
1.5
Research questions
As described in Section 1.4, poor vertical representations can lead to poor vertical selec-tion. Approaches such as the use of external text sources as an addition to the sampled documents [25] have been proposed to help improving those ‘incomplete’ samples. In concrete, three techniques can be found in the literature:
• Arguello et al. [2] explores the use of Wikipedia as an alternative to sampling directly from the vertical by associating the articles’ categories with the vertical intent.
• Lalmas [25] suggests that the direct vertical sample and the external sample (as proposed by Arguello et al. [2]) do not have to be necessarily exclusive, as both of them can be used as a complement to obtain a more complete coverage of the vertical.
• In the text classification field, several studies [22, 23, 50] show howWikipedia and WordNet can be used to enrich text representations of individual documents.
Based on the described scenario, the first research question (RQ) can be formulated:
RQ1: Which of the defined techniques for text enrichment is more suitable to enhance the vertical representation in aggregated search?
(‘image’, ‘video’...) that can be directly related to the collection. Furthermore, query logs can be exploited as a source of evidence since it describes the users’ vertical in-tent. However, the current research project is restricted by the lack of several vertical information such as the usage logs. This aspect determines [RQ2] as:
RQ2: How to use the vertical representation and the query string to boost the users’ desired content type in the vertical selection stage?
1.6
Thesis outline
The next chapter summarizes the main findings in the literature about the federated and aggregated search area that are considered relevant for this research project.
Chapter 3 presents the selected methodology to answer [RQ1]. In order to evaluate the performance of different vertical representation’s set-ups, a well-known selection algorithm can be configured using only the sampled documents as a baseline. From this point, we will measure the increase in effectiveness of employing each external source as a complement for the representation.
Chapter 4 shows the followed approach for [RQ2]. Similarly as in the first research question, we will test the performance using a baseline (obtained from the previous step), and adding to it the different query type features that could improve the selection results.
Literature
This chapter presents an overview of the literature on the current topics. Section 2.1 outlines a small background about the field. Then, the previous work on the main components of an aggregated search system is summarized in Sections 2.2, 2.3 and 2.4. Section 2.5 describes methods for recognition of keywords in text documents. Section 2.6 introduces a model to identify latent topics in a set of documents. Finally, Section 2.7 discusses about the findings of the chapter.
2.1
Background
Information retrieval (IR) is the science of answering an information need by searching in collections of documents and determining the most relevant ones. To achieve this ranking, many models have been proposed aimed to solve specific cases.
A widely known technique in IR used as a base for more complex models due to its proven robust performance in solving diverse problems (such as document ranking and keywords extraction) is the term frequency-inverse document frequency (TF-IDF) weighting scheme.
As the name suggests, the statistic is calculated by the product of two different values: term frequency (TF) and the inverse document frequency (IDF).
Different alternatives for the computation of the term frequency can be found in the literature. However, the simplest choice is using the raw frequency of the term tin the documentd(the count of term occurrences):
tf(t, d) =f(t, d) (2.1)
The inverse document frequency was proposed by Sp¨arck [44] in 1972, based on the intuition that a term that occurs in many documents should not be as important as a term that barely appears. This heuristic nature of the formula has been extensively discussed [34] where different authors try to provide a theoretical background for its efficacy.
Although many variations of theIDF formula have been described, the basic equa-tion is defined as:
idf(t, D) =log |D|
|{d∈D:t∈d}| (2.2)
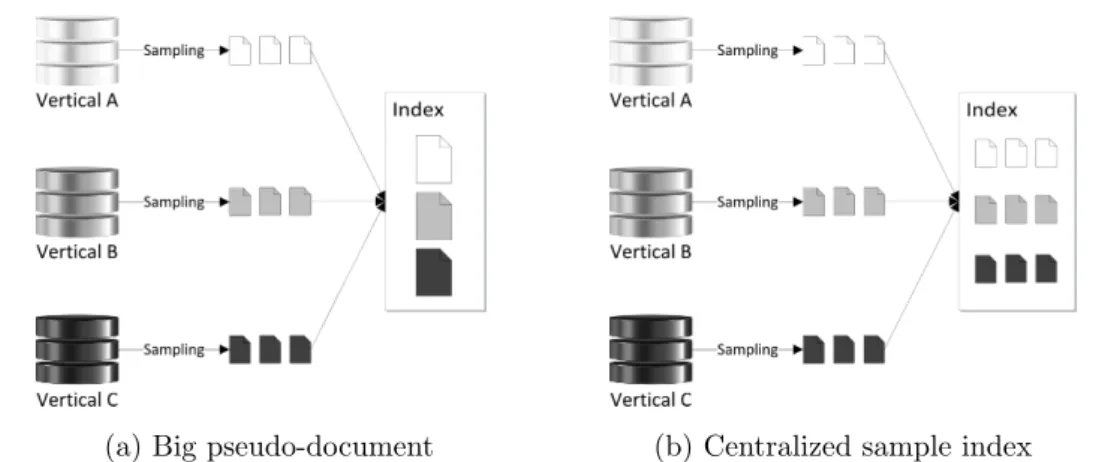
(a) Big pseudo-document (b) Centralized sample index
Figure 2.1: Vertical representation
, wheret is the analyzed term, and Dis the collection where documentdbelongs. Finally, as empirically shown by Salton and Yang [35], both factors can be combined as follows:
tf idf(t, d, D) =tf(t, d)×idf(t, D) (2.3)
2.2
Vertical representation
The central point for a strong performance of the aggregator is maintaining a precise vertical representation. While manual representation is one option, a more common ap-proach is using automatically generated representations based on a sample of documents from the vertical.
To obtain this sample, techniques like query-based sampling [13] or random walk sampling [7] can be particularly useful in uncooperative environments. Those methods can create a resource description by continuously submitting queries to the vertical and downloading some of the obtained search results until a defined stop condition is reached. Moreover, to facilitate the extraction of search result records (SRRs), Trieschnigg et al. [48, 49] reported the use of automatically generated XPath expressions that can help identify the result items.
The acquired documents can therefore be indexed in two different directions: a) as a big pseudo-document for each vertical (Figure 2.1a) to be used by lexicon-based tech-niques; orb) in a centralized sample index (CSI) with all the sampled documents from all the verticals (Figure 2.1b), which approximates to a theoretical centralized collection index (CCI) containing the complete set of documents from all the verticals (as it is unpractical to create the complete index).
2.2.1 Query-based sampling
Query-based sampling (QBS) [13, 14] is a method proposed to obtain resource descrip-tions without cooperation of the given resource. It is the state-of-the-art solution for obtaining collection representations in federated search and can be expressed as follows:
1. Select a one-term query.
2. Submit the selected query to the vertical.
3. Retrieve the topndocuments from the result set.
4. Update the vertical description based on the content of the retrieved documents.
5. Stop if stop criterion has been reached. Otherwise, return to step 1.
Initially, a one-query term needs to be selected. Callan and Connell [13] investigated two different selection strategies: a) learned resource description (lrd) where each term is randomly selected from the resource description being learned; andb) other resource description (ord) where the terms are randomly taken from a reference dictionary. They report how ord produced faster learning, but it can provide terms that are not found in the target collection. Furthermore, Tigelaar and Hiemstra [47] discuss how using random terms from lrd is indeed a good strategy. However, using the least frequent terms in the sample can create better representations on big collections.
On the document retrieval step, Tigelaar and Hiemstra [46] also reported stable results using only the snippets (title and summary of the result item) as the sample instead of downloading the complete documents.
The stop criterion is usually empirically defined by the number of downloaded doc-uments or by the number of submitted queries. Adaptive query-based sampling [5] is proposed as another option to determine the stop point by using predictive likelihood as an indication of when a good representation has been reached.
Finally, as showed by Shokouhi et al. [41], query-based sampling suffers from a bias, where some documents are preferred over others. Although different sampling methods like random walk sampling [7] can solve this situation, it is unclear if an unbiased sample is the best option for resource description, as the bias might produce more representative samples.
2.2.2 Capture-recapture size estimation
As mentioned earlier, the size of the vertical is an important factor in many selection models. Liu et al. [26] introduced thecapture-recapture algorithm in order to obtain an estimation of it by following previous statistical methods used to calculate the population size of wild animals.
Having two random and independent samples aand b from the collection, the esti-mated size ˆN can be calculated as follows:
ˆ
N = |a||b|
|a∩b| (2.4)
This technique has been extended by Shokouhi et al. [41] with theirmultiple capture-recaptureandcapture-historymethods, which show significant improvements in accuracy and more efficient use of resources.
2.2.3 Sample-resample size estimation
A different approach to size estimation is presented by Si and Callan [42] as sample-resample.
Assuming that the acquired sample is random and that the search engine (of the vertical) reports the number of documents that match a query term (even if it is only approximately), the distribution of documents with a term t in the sample should be similar as the distribution of documents with the same termtin the complete collection:
ˆ
N = dtDt
|S| (2.5)
, where dt is the number of documents containing the term t in the sample, Dt is the
number of documents containing the term tin the collection (as reported by the search engine), and |S|is the sample size.
Therefore, the final estimated size is computed as the average of the individual estimation of several random one-term queries (to reduce the variance).
2.3
Vertical selection
Due to restrictions such as a limited bandwidth and reduced response times, it is not practical to submit every search to each one of the available verticals, Therefore, the initial step after receiving the query is selecting the verticals that are most likely to answer the user’s information need.
This vertical selection can be executed with pre-retrieval and post-retrieval predic-tors. For the first one, an early approach is to treat the verticals as big bag-of-words [40] (see Figure 2.1a) and rank them based on the similarity between the query and the vertical representation using lexicon-based techniques such as CORI [12]. However, document-surrogate methods that consider the distribution of the documents such as ReDDE [42] tend to be more effective.
Furthermore, Arguello et al. [2] describe how a hint to help identifying the appro-priate vertical type is the query string given by the user, as it could contain keywords (‘image’, ‘photo’...) that can be directly related to the vertical.
Another feature for the selection task usually available in cooperative environments is the vertical query log. This source of evidence exploits the previously submitted queries to identify what is the vertical intent given by the users.
Thus, a well-suited solution for pre-retrieval vertical selection is using machine learn-ing techniques to build a model based on the previous elements: vertical representation (and the ranking of the vertical), query logs and query-based predictors [2].
2.3.1 ReDDE
The relevant document distribution estimation (ReDDE) method for resource selection was presented by Si and Callan [42] as an alternative to the CORI algorithm [12] which considers the database size and the content similarity to rank the available collections.
Initially, the number of documents relevant to a queryqin the verticalvis estimated as:
R(v, q) =X
d∈v
P(R|d)P(d|v)|v| (2.6)
, where |v| is the number of documents in the vertical v, P(d|v) is the probability of a documentdbeing generated by the vertical v, and P(R|d) is the estimated probability of relevance for a documentd.
Since it is not possible to access all documents for all the verticals, P(d|v) can be approximated as:
R(v, q)≈ X
d∈Sv
P(R|d) |v|
|Sv|
(2.7)
, whereSv is the sample of documents for the verticalv.
CalculatingP(R|d) is still an open problem in information retrieval [40]. In ReDDE it is approximated according to its position in a ranked list of the documents in the CCI. The method considers a positive constant value for the top documents in the ranking as follows:
P(R|d) = (
α ifrCCI(d)< βPi|vi|
0 Otherwise (2.8)
, where|vi|is the number of documents in the verticali,αis a query dependent constant
andβ is a percentage threshold. Si and Callan [42] obtained a good performance setting this value to 0.003 (which is equivalent to the top 3000 documents in a collection of 1,000,000 documents).
However, as mentioned in Section 2.2, having this CCI is unfeasible. Therefore, the CCI ranking is approximated by using a CSI (see Figure 2.1b) as:
rCCI(d) =
X
dj:rCSI(dj)<rCSI(d)
|v| |Sv|
(2.9)
Using equations 2.8 and 2.9, the number of relevant documents in a collection (equa-tion 2.7) can be calculated.
Finally, the resulting values still contains a dependent constant α (from Equa-tion 2.9). Since the distribuEqua-tion of relevant documents in the collecEqua-tion is sufficient to rank the vertical, this can be calculated by normalizing these values as shown below:
Goodness(v, q) = PR(v, q)
iR(vi, q)
2.3.2 Document-centric model
Proposed by Balog [6] for the TREC 2013 Federated Web Search track (see also Sub-section 5.1.1), thedocument-centric model for resource selection determines the ranking of the verticals by first ordering the individual sampled documents in theCSI and then aggregating their scores.
To compute the probability of a vertical v to contain documents relevant to a query
q,P(v|q), the formula is initially rewritten using Bayes rule as:
P(v|q)∝P(v)P(q|v) (2.11) Thus, the first component to calculate is P(v), or the collection prior. This prior is the probability of a vertical to contain an answer to any arbitrary query. Using the sampled documents as an approximation of the collection size, the collection prior is estimated as:
P(v) = P|v|
v0|v0|
(2.12)
The second component needed for the score is the probability of a query q being generated by the vertical v,P(q|v), which is calculated as follows:
P(q|v) =X
d∈v
P(d|v)Y
t∈q
{(1−λ)P(t|d) +λP(t)}n(t,q) (2.13)
, where dis a document in vertical v, t is a term in the query q,n(t, q) is the number of times the term appears in the query, P(t|d) is the maximum-likelihood estimate of observing t given d, P(t) is the maximum-likelihood estimate of observing t given a background language model (in this case, estimated from all the sampled documents) and λ is a smoothing parameter. Finally, assuming all the documents in a vertical are equally important,P(d|v) is set as 1/|v|, where|v|is the number of sampled documents.
2.4
Result presentation
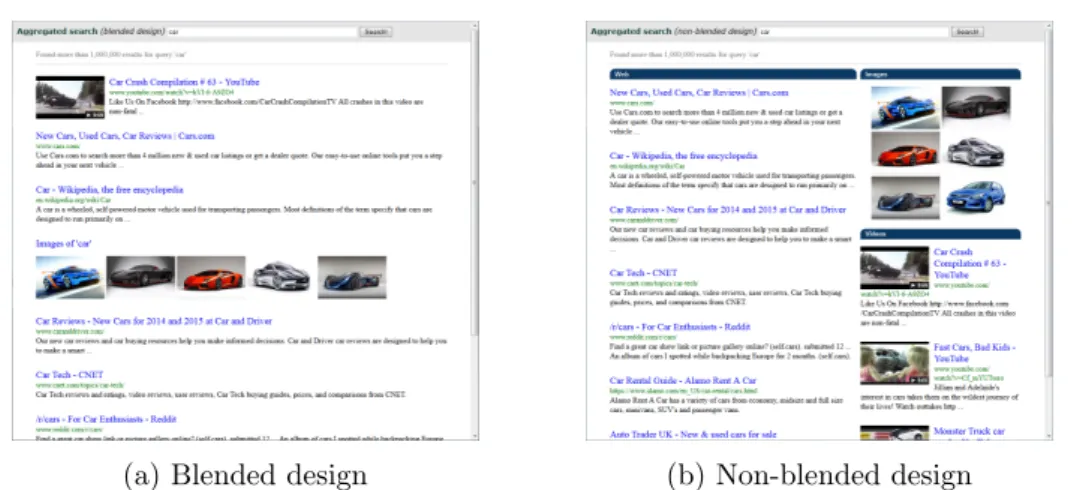
As described by Lalmas [25], there are two main designs for displaying the aggregated results: a)blended lists where the results of the same vertical are “slotted” between the traditional web results (see Figure 2.2a); and b) non-blended lists where results from each vertical are presented in a separated panel (see Figure 2.2b). The first approach is the preferred design for traditional search engines.
In a blended list, the slots are ranked with respect to the other slots. Different criteria can be used for ranking (mainly with machine learning techniques). For example, a trending news should be ranked very high.
In order to evaluate the ordering of the results, methodologies such as the one pro-posed by Arguello et al. [4] can provide a reliable metric of the user’s preferences.
The non-blended design presents results from each vertical in a different panel. As shown in Figure 2.2b, the main web results are displayed in the largest panel and the extra verticals are placed in a predefined location. If there is no result for a vertical, it is simply not displayed.
(a) Blended design (b) Non-blended design
Figure 2.2: Result presentation
to carefully estimate the positions of the results while using blended interfaces. On the other hand, in a non-blended approach the user’s click behavior is not affected by the location of the panels. Therefore, when it is not possible to measure the relevance of the verticals, the non-blended design is more appropriate.
Also, the study shows how videos tend to have higher click-through rates. In a general sense, the results indicates that some verticals will tend to be more “popular” than others.
2.5
Keywords extraction
Keywords extraction is defined as the application of diverse algorithms to a document in order to identify its most important words (or phrases) that could help summarize its content.
Early approaches with high success rate, such as TF-IDF, base their extraction pro-cess in the relation between the terms of the document and the collection of documents where it belongs.
A more complex technique is studied by Ercan and Cicekli [17] where they use lexical chains in order to exploit the semantical meaning of the words in the corpus.
Fuxman et al. [18] propose the use of the “wisdom of the crowds” by analyzing query logs of search engines to identify words related to a specific topic.
A different approach for the task is reported by Matsuo and Ishizuka [27], where word co-occurrence statistical information in a single document is used to identify keywords without the need of a complete collection.
2.6
Topic modeling
K β φk
α θm
Nm
zm,n
M wm,n
Figure 2.3: Graphical model representation of LDA as described by Blei [9]
Currently, one of the most effective approach for topic modeling is the latent Dirich-lent allocation (LDA) [10]. This model has successfully been applied in diverse types of research such as web spam filtering [8] and software bug classification [31].
2.6.1 Latent Dirichlet allocation
Blei et al. [10] presented latent Dirichlet allocation (LDA) as a generative model to identify the latent topic structure in a set of text documents. It can be seen as a step forward of previous techniques such asprobabilistic latent semantic analysis(pLSA) [21], with the difference of LDA using the Dirichlet distribution as a prior for the topic distribution.
Figure 2.3 shows the graphical model representation of LDA. This plate notation allows to recognize the dependencies among the variables, where:
• α is the parameter of the Dirichlet prior for the topic distribution per document;
• β is the parameter of the Dirchlet prior for the word distribution per topic;
• K is the number of hidden topics;
• M is the number of documents;
• Nm is the number of words in document m;
• θm is the topic probability distribution for documentm;
• φk is the word probability distribution for topick;
• zm,n is the topic of the word nfor the document m; and
• wm,n is the wordn for the documentm
.
1. For each documentdm(m∈[1, M]), select a multinomial distributionθm ∼Dir(α)
from a prior Dirichlet distribution with parameter α;
2. For each topic k ∈ [1, K], select a multinomial distribution φk ∼Dir(β) from a
prior Dirichlet distribution with parameterβ; 3. For each word positionn∈[1, Nm] in documentdm:
(a) Select a topic zm,n from the multinomial distributionzm,n ∼M ulti(θm);
(b) Select a wordwm,n from theV-dimensional multinomial distributionwm,n ∼
M ulti(φzm,n), where V is the size of the vocabulary.
In order to determine the distributions used for the analysis, Bayesian inference is required. A widely accepted method the achieve this task inLDA is Gibbs sampling [9, 19]. After a certain number of iterations, an accurate selection of words per topic can be accomplished.
2.7
Summary
In this chapter we reviewed the literature relevant for the project. Initially, a background on information retrieval was introduced as the main field of the thesis. Then, the central components of an aggregated search system were described:
Different approaches used to obtain a vertical representation and algorithms to es-timate the vertical size in uncooperative environments were presented. Since we will use an already sampled collection (see also Subsection 5.1.1), we do not need to imple-ment the component. The docuimple-ments in the given collection were obtained with the query-based sampling algorithm.
Two vertical selection models were analyzed. We chose the document-centric model as it is an algorithm already proven to work in the sampled collection (see also Subsec-tion 5.1.4).
Result presentation is mentioned as an important part of an aggregated search sys-tem. However, the current project does not focus on the display of results and therefore the component will not be needed.
Keywords extraction is shown as an interesting solution aimed to identify the most relevant terms of a document. We will implement it as a part of the individual enrich-ment of docuenrich-ments proposed for [RQ1].
Vertical representation
enrichment
This chapter describes the chosen method to answer [RQ1]. Initially, the problem is introduced in Section 3.1. Then, Section 3.2 shows the different approaches selected for vertical representation enrichment. Finally, Section 3.3 concludes the chapter with a discussion about the techniques.
3.1
Introduction
Poorly represented verticals are an important issue that affects the performance of the aggregated search system. As mentioned in Section 1.4, one of the main challenges in the creation of the system is overcome the lack of accurate text descriptions on many of the sampled documents due to the heterogeneous nature of the verticals.
Thus, the goal of [RQ1] is centered on improving the quality of the vertical repre-sentation by enriching it with an external source (in this case, Wikipedia), following the methods found in the literature.
Since each of the proposed techniques confront the problem with a different strategy, an evaluation of all of them under the same conditions to determine which one is more suitable for the described task becomes an interesting research topic.
The next section will detail each one of the approaches (as described in the literature) as well as the methodology followed during this thesis.
3.2
Method
This research question explores the use of three different approaches aimed to improve the vertical representation: a) using only documents sampled fromWikipedia;b) joining the sampled documents from the vertical with Wikipedia articles; and c) applying doc-ument expansion techniques to increase the text in each one of the sampled docdoc-uments. Each method will be described and analyzed in the following subsections. The implemented experimental setup and the evaluation of the enrichment techniques will be presented in Section 5.2.
Figure 3.1: Wikipedia articles representation
T1: networks random systems disordered neural boolean information critical mat phase transition lyapunov cond mutual exponents percolation localization
T2: supernova remnant snr emission shell radio galactic snr thermal evolution ph astro study ray physics
. . .
T200: algorithm cs problem complexity data structures time log approximation computational dis-tributed graph computing number
Figure 3.2: Example of LDA generated topics. List obtained after modeling 200 topics from arXiv.org
3.2.1 Wikipedia articles representation
Arguello et al. [2] investigate a set of features that could affect the performance of vertical selection in aggregated search. In particular, they describe how the corpus of the vertical (the sample) can be constructed following two different alternatives: a) directly sampling the resource by applying the techniques described in Section 2.2; orb) create the sample using an external source (in this case, Wikipedia) by identifying the articles that are related with the concepts covered in the vertical.
The argument sustains that the use of Wikipedia documents instead of the ones obtained directly from the vertical can be beneficial as they are always rich in text, with a consistent format and semantically coherent. However, if the mapping of articles to the vertical is not done properly the technique raises the risk of adding documents that will misrepresent the resource.
The approach described in [2] for external sampling is simplistic: as each article in Wikipedia belongs to one or more categories, it is possible to match them with the vertical using ad hoc regular expressions. For instance, a vertical about the ‘autos’ domain can relate with any article categorized with the terms ‘vehicle’ or ‘car’.
Although their results showed how the direct sample obtained from the vertical always outperformed the Wikipedia sample, the authors recognized that their solution for identification of related articles is not optimal.
In order to provide a more reliable mapping, we propose the application of topic modeling techniques on the direct sample of documents so that we can discover the conceptual coverage of each resource.
As shown in Figure 3.1, the topics of each vertical will be modeled (using latent Dirichlent allocation) in order to determine their individual theme coverage. Figure 3.2 illustrates how a ‘topic’ can be understood as a group of terms related to the same theme (i.e., the words from T2 can be part of an ‘ASTROPHYSICS topic’).
Algorithm 3.1 Wikipedia articles representation
1: Inputs:
collection,numOf Iterations,numOf T opics,numOf Articles,
ignoreDisambiguation
2: for each vertical incollection do 3: sample←sampling(vertical)
4: topicsList← LDA(sample,numOf Iterations,numOf T opics) 5: pruneTopics(topicsList)
6: for each topicin topicsListdo 7: termsList←∅
8: for each termintopicdo 9: if length(term) >1 then
10: termsList←termsList+term
11: end if
12: end for
13: if termsList6=∅then
14: query← joinTerms(termsList,OR)
15: articles←WikiSearch(query,numOf Articles,ignoreDisambiguation) 16: addToRepresentation(vertical,articles)
17: end if 18: end for 19: end for
Still, the modeling process is not perfect. As it is based on the analysis of terms without considering semantics, it is possible to encounter ‘bogus’ topics. To overcome the described problem, the topics are manually reviewed in a ‘pruning’ step which discards the wrongfully identified ones, using the following rules:
1. Although stopwords can be removed from the sample, factors such as the language of the text could affect this removal process. Therefore, if all the terms in the topic can be considered as unimportant, the topic is deleted.
2. The sample is obtained from the web, which implies the need of a parsing mech-anism to extract the relevant text. If for some documents the parsing step failed and elements such as HTML tags and other ‘noise’ are identified as a topic, the complete topic should be rejected.
A further ‘cleaning’ step for the remaining topics is also defined: if a term in a mod-eled topic is a one-character word, it is removed as it does not help in the identification of related articles.
Figure 3.3: Combined representation: Wikipedia articles and vertical sample
The topndocuments are selected from the ranking (ignoring disambiguation pages) and added in the vertical representation. Finally, the initial sample obtained from the vertical is disregarded. Algorithm 3.1 shows in pseudo-code the overall process.
3.2.2 Combined representation: Wikipedia articles and vertical sam-ple
As proposed by Lalmas [25], the directly sampled documents and the articles obtained from an external source do not have to be exclusive: while the first ones undoubtedly represent the resource contents, the latter provides a complement for the representation that could lead to a broader coverage of the included themes.
Algorithm 3.2 Combined representation: Wikipedia articles and vertical sample
1: Inputs:
collection,numOf Iterations,numOf T opics,numOf Articles,
ignoreDisambiguation
2: for each vertical incollection do 3: sample←sampling(vertical)
4: topicsList← LDA(sample,numOf Iterations,numOf T opics) 5: pruneTopics(topicsList)
6: addToRepresentation(vertical,sample) 7: for each topicin topicsListdo
8: termsList←∅
9: for each termintopicdo 10: if length(term) >1 then
11: termsList←termsList+term
12: end if
13: end for
14: if termsList6=∅then
15: query← joinTerms(termsList,OR)
16: articles←WikiSearch(query,numOf Articles,ignoreDisambiguation) 17: addToRepresentation(vertical,articles)
Figure 3.4: Sampled documents expansion
Figure 3.3 presents the described approach as an extension of the previous method. In this case, the sampled documents obtained from the vertical are also included as a part of the vertical representation. As expected, Algorithm 3.1 and Algorithm 3.2 are essentially the same, with the extra step in 3.2 of indexing the sampled documents (line 6).
Even though with this technique one of the advantages of using onlyWikipedia arti-cles (the uniformity of all the documents in the representation) is lost, maintaining the original documents can help mitigating the inclusion of articles that might misrepresent the vertical.
3.2.3 Sampled documents expansion
Document expansion follows a different approach for vertical representation enrichment. Encouraged by different studies in the text classification field [22, 23, 50], it is possible to analyze each one of the directly sampled documents and extend their content using external sources. In a general sense, two steps needs to be executed in order to complete the document expansion:
1. Determine the main concepts covered in the document, and
2. Match the documents to the entries in the external source by relating the discov-ered concepts.
Hotho et al. [22] make use of WordNet synonyms and hypernyms as an additional resource to improve the task of text document clustering. For step 1, they consider each document as a bag of words, then weight each term withTF-IDF and apply pruning to rare terms using a pre-defined threshold. Then, step 2 is fulfilled by simply searching each remaining term in WordNet and including the obtained concepts in the bag of words.
all the returned concepts, which implies no disambiguation; b) relying in the ranking of concepts done by WordNet and taking only the first concept; andc) defining the se-mantic vicinity of the concept to determine the appropriate synonym. Hotho et al. [22] report how the later strategy produces better results.
Wang et al. [50] and Hu et al. [23] work in a different direction by initially creating a thesaurus withWikipedia. This ‘concept index’ is then used in step 1 by searching term sequences that exactly matches a concept (this is called acandidate concept). Finally, the process is completed by adding to the document all the concepts related to the candidate concept.
We propose a simplified method based on Wikipedia (see Figure 3.4). Step 1 will be executed with the help of keywords extraction techniques. Following Hotho et al. [22] initial idea, it is possible to determine the most important terms in each sampled doc-ument by applyingTF-IDF and considering only the top m words.
Finally, the keywords are searched inWikipedia and the topnarticles are appended to the original document. Our strategy for disambiguation is based on the assumption that each document focuses in only one topic which implies that the top extracted keywords are semantically related. Therefore, querying groups of keywords provides a context for the search. Algorithm 3.3 illustrates the pseudo-code implementation of the described approach.
Algorithm 3.3 Sampled documents expansion
1: Inputs:
collection,numOf Keywords,numOf Articles,
ignoreDisambiguation
2: for each vertical incollection do 3: sample←sampling(vertical) 4: for each docinsample do
5: keywords← tfidf(doc,numOf Keywords)
6: articles← WikiSearch(keywords,numOf Articles,ignoreDisambiguation) 7: doc←doc+articles
8: end for
9: addToRepresentation(vertical,sample) 10: end for
3.3
Conclusion
The limitation of descriptive text for the vertical representation was described as one main issues in aggregated search that directly affects vertical selection algorithms and by consequence, the overall performance of the system.
To overcome the situation, three Wikipedia based approaches for text enrichment found in the literature were presented:
1. Using only Wikipedia articles as the description of the vertical;
3. Maintaining the original sampled documents, but expanding each document with Wikipedia information.
However, Wikipedia is a big encyclopedia, and determining the appropriate docu-ments for each case is not a trivial task.
For approaches 1 and 2, Arguello et al. [2] presented a manual mechanism to fulfill the articles identification. We propose an alternative solution based on a topic modeling technique (LDA) to recognize the theme coverage in each vertical and with it, complete the match with the related articles.
Approach 3 is found in the text classification field. We pretend to port a previous solution with high success rate in the mentioned field to the vertical enrichment problem: expand each sampled document by merging it withWikipedia articles usingTF-IDF as a keywords extraction algorithm to identify relevant terms.
Vertical type boosting
The present chapter describes [RQ2]. Section 4.1 introduces the problem intended to solve with vertical type boosting. Then, Section 4.2 shows the selected methodology for the research question. The chapter concludes in Section 4.3 with an overall review of the approach.
4.1
Introduction
Lalmas [25] points out how the query string provided by the user constitutes an impor-tant source of evidence: since each vertical is specialized on a certain type of documents, one or more terms in the query might be directly related to the vertical classification.
As described by Arguello et al. [2], the interpretation of those query-string features are the simplest solution to improve vertical selection. The analysis can be implemented in two directions:
1. By identifying a correlation between a set of fixed concepts that describe the vertical (i.e. ‘movies’, ‘sports’ or ‘shopping’) and the terms in the query with the help of regular expressions; or
2. By annotating the vertical with a series of geographic features that could determine when a phrase refers to a place.
Furthermore, machine learning models constructed with the described features can successfully be ported from trained verticals to unlabeled verticals [3].
However, although for some cases the technique might provide improvements for the selection task, it depends on the query having the specific concepts used to describe the vertical.
A different solution is presented in the web query classification field [37–39]. Each query can be analyzed with a text classifier in order to associate it to the previously identified vertical concepts, resulting in a strong indication of the type of information required by the user.
This chapter proposes [RQ2] as an intent to improve vertical selection using the latter solution by classifying the query string in order to target the desired information type and boosting the scores of the related verticals in the final ranking.
Figure 4.1: Topics labeling with Wikipedia categories
Figure 4.2: Vertical type boosting
4.2
Method
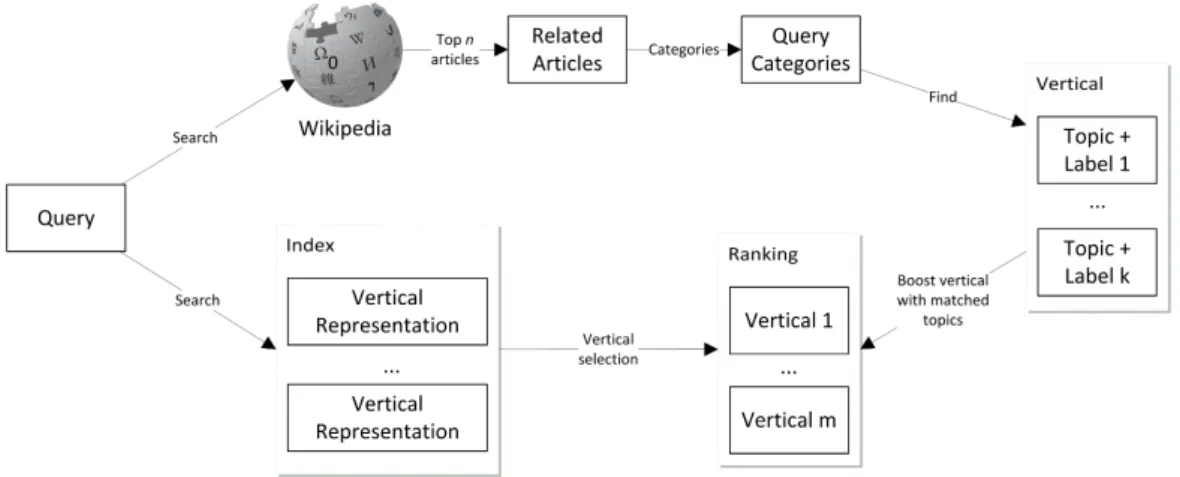
Arguello et al. [2] follows the query classification idea into what they describe as cat-egorical features. Initially, an external collection of documents is indexed, and each document in that collection is classified in at most three category levels resembling the ontology from the Online Directory Project1.
Then, the user’s query is searched into the external collection, and the categories of the top returned documents are considered as the query classification. Finally, the verticals related to the encountered categories are selected.
We propose an approach for vertical type boosting based on query classification using Wikipedia categories and the topics model created in [RQ1] as the main source of information.
It is important to notice how since in Wikipedia each article is already designated to at least one category, the initial step described in [2] is unnecessary. However, the
Level Categories
1 20
2 621
3 7,532
4 58,163 All 1,184,218
Table 4.1: Wikipedia categories per level
1
complete categorization is very broad: as shown in Table 4.1 the total number of available categories exceeds the million entries.
Another aspect to consider is that although in Wikipedia each category belongs to another categories, and it is possible to reach one of the top levels to use a smaller number of entries, that would lead to generalization problems: concepts such as ‘rock music’ and ‘oil painting’ could be oversimplified to ‘arts’. Therefore, in our approach we rely on the direct categories of the articles.
The starting point of the process is then classifying the verticals (see Figure 4.1). Each one of the previously generated topics provided a list of connected terms which describes a subject covered in the vertical, and a weight (φkin Figure 2.3) which indicates
the overall portion of the vertical assigned to the topic.
Thus, we use Algorithm 3.1 as a base to identify the top articles related to a topic and with them, determining the categories of each vertical. As shown in Algorithm 4.1, the ‘labels’ given to the verticals and their corresponding topics are stored in a database for future usage (see Figure 4.1).
Algorithm 4.1 Topics labeling with Wikipedia categories
1: Inputs:
vertical,numOf Articles,ignoreDisambiguation
2: for each topicinvertical.topicsListdo 3: termsList←∅
4: for each termin topicdo 5: if length(term) >1then
6: termsList←termsList+term
7: end if
8: end for
9: if termsList6=∅then
10: query← joinTerms(termsList,OR)
11: articlesList←WikiSearch(query,numOf Articles,ignoreDisambiguation) 12: for each articleinarticlesList do
13: categories← findCategories(article) 14: store(vertical,topic,categories) 15: end for
16: end if 17: end for
After completing the vertical categorization, the next step is the analysis of the query string (see Figure 4.2). In this manner, when a user query enters the system, it follows two directions:
1. It is used to execute the vertical ranking with the CSI and the vertical selection model; and
The vertical type boosting process is finally described in Algorithm 4.2 where the verticals associated with the query string are boosted based on the weight of the matched topics, using the following formula:
boost(verticalScore, topicW eight) =verticalScore×(1 +topicW eight) (4.1)
Algorithm 4.2 Vertical type boosting
1: Inputs:
query,numOf QueryArticles,ignoreDisambiguation
2: verticalRanking ←verticalSelection(query) 3: queryArticles← WikiSearch(query,
numOf QueryArticles,
ignoreDisambiguation) 4: queryCategories←∅
5: for each articleinqueryArticlesdo
6: queryCategories←queryCategories + findCategories(article) 7: end for
8: for each vertical inverticalRanking do
9: topicCategories← getTopicsWithCategories(vertical) 10: for each topicin topicCategoriesdo
11: if topic.categories∩queryCategories6=∅then
12: vertical.score← boost(vertical.score,topic.weight) 13: end if
14: end for 15: end for
4.3
Conclusion
Vertical type boosting is presented in this chapter as a feature to improve base ranking methods by analyzing the characteristics of the query string given by the user.
We described how by exploiting this query string, the topics model generated for each vertical in [RQ1] and theWikipediaarticles categorization, it is possible to identify the desired document type and target the most relevant verticals according to their content coverage. Two main steps need to be followed:
1. The topics model created ‘unnamed’ groups of semantically related words. Each topic can then be ‘labeled’ using the algorithm proposed in Subsection 3.2.1 and selecting the categories of the related articles.
2. Each query string is initially searched in Wikipedia and the top documents and their categories are used to establish the query intent, which by consequence iden-tifies the relevant verticals. The scores of those verticals after the basic selection model are then boosted according to the topics weight.
Experiments
The current chapter describes the experiments performed during this thesis. Section 5.1 shows the experimental setup which includes the selected dataset, the indexing pro-cess, the configuration of the baseline and the metrics applied to evaluate the results. Section 5.2 and Section 5.3 details the implementation of the approaches used to an-swer each research question as well as their evaluation. Finally, Section 5.4 presents a discussion about the chapter.
5.1
Experimental setup
From previous chapters, it can be inferred that a pre-requirement for the aggregated search system is the selection of the verticals to be integrated. Then, each vertical needs to be sampled following approaches as the ones described in Section 2.2. However, several technical problems can be raised during this process (in particular, many servers can trigger blocking mechanisms when a crawling behavior from a single client is detected). To simplify the sampling process, the TREC FedWeb 2013 collection [15] was chosen due to its broad variety of heterogeneous sampled documents. Furthermore, the TREC FedWeb provides a comparison point of the performance of different selection models.
Next, the documents need to be indexed. Many open source alternatives such as Apache Lucene1 and Terrier2 are available for research and experimentation.
Subsec-tion 5.1.2 details the selected approach for this purpose.
On the other hand, since most of the experiments involvesWikipedia, it is unpractical to use its online version. To solve this situation, a complete dump of the encyclopedia was downloaded and indexed as described in Subsection 5.1.3.
The last point is the implementation of a vertical selection model. This algorithm works as a baseline for any further experiment in the development of the current thesis. Subsection 5.1.4 explains the steps followed in its creation.
1
http://lucene.apache.org/ 2
http://terrier.org/
FedWeb 2013
Verticals 157
Content types 24
Sample queries 2000 Sampled documents 1,878,613 Sampled snippets 1,958,934 Evaluation queries 50
Table 5.1: TREC FedWeb 2013 dataset summary. The reported number of documents includes only the ones that could be indexed, which might differ from the total number of documents in the complete sample
5.1.1 TREC FedWeb dataset
The Federated Web Search (FedWeb)3 is a track of the Text REtrieval Conference (TREC)4 which investigates basic challenges in federated and aggregated search.
The TREC FedWeb 2013 track provides a large collection of documents gathered directly from 157 heterogeneous online search engines with content types such as: news, images, videos, etc. The verticals were crawled using query-based sampling (described in Subsection 2.2.1) by submitting 2000 sample queries to each search engine [15]. The top 10 search result records (the snippets) and documents were extracted with the help of theSearchResultFinder plugin [48, 49] and some additional XPath expressions. The dataset statistics is summarized in Table 5.1.
Also, 50 real life queries were selected and submitted to each one of the verticals. Then, the individual top 10 results was judged according to the information need, the context and the expected results of the query. The weights w given to each relevance level for the documents are: wN on = 0 (not relevant),wRel = 0.25 (minimal relevance),
wHRel= 0.5 (highly relevant),wKey= 0.75 (top relevance) andwN av = 1 (navigational).
The graded relevance is finally converted to a discrete relevance level multiplying it by 100 and taking the nearest integer value.
The complete list of verticals, queries and relevance judgments can be found in Appendix A.
5.1.2 Vertical collection indexing
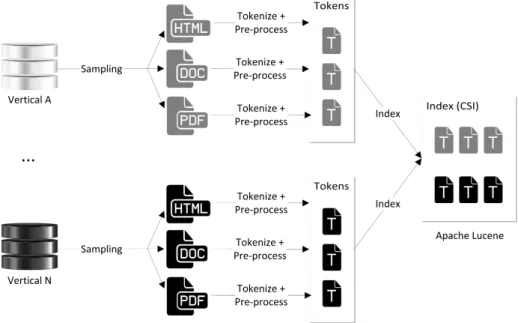
The central part of the aggregated search system is the index. To provide this service, Apache Lucene 4.9.0 (from this point on referred only as Lucene) was selected due to its proven reliability in diverse full-text search applications. The experiments were developed in Java as it provides maximum compatibility with Lucene. Additionally a PostgreSQL5 database was used for storage of any complementary data needed.
In order to speed up the execution of many different experiments with the same data, the indexing process of the sampled documents was divided in several stages making use of specific intermediate files for each task.
3
http://sites.google.com/site/trecfedweb/ 4
http://trec.nist.gov/ 5
Figure 5.1: Vertical collection indexing process
Number of Number of unique terms verticals
0-499,999 17
500,000-999,999 15 1,000,000-1,999,999 33 2,000,000-3,999,999 38 4,000,000-5,999,999 24 6,000,000-7,999,999 16 8,000,000-9,999,999 8 more than 10,000,000 6
Table 5.2: Number of unique terms per vertical. The complete list can be found in Appendix B
As shown in Figure 5.1, the obtained sample (in this case, the FedWeb 2013 col-lection) is initially tokenized. This tokenization step involves the identification of the relevant data from: a) HTML files, using specific XPath expressions for each vertical that helped reduce noise produced by HTML tags; b) PDF files, using Apache PDF-Box6 to recognize the text and metadata of the document; and c) DOC files, using Apache POI7 as document parser. The pre-processing step starts with the removal of stopwords (the default set of Lucene’s english stopwords). Finally, the obtained tokens are stemmed applying aPorter Stemmer [32].
The result of the vertical collection indexing is summarized in Table 5.2, which groups the count of unique terms found on each vertical.
6
http://pdfbox.apache.org 7
Figure 5.2: Wikipedia collection indexing process
Run nDCG@20
Snippets only (S) 0.12589 Documents only (D) 0.24244 Documents+Snippets (DS) 0.24582
Table 5.3: Vertical selection baseline evaluation
5.1.3 Wikipedia collection indexing
As mentioned earlier, many of the experiments presented during this thesis involves a substantial usage of Wikipedia. Multiple interactions with an online server implies issues such as a heavy bandwidth load and poor performance. To solve this situation, a complete dump of the encyclopedia was downloaded from Wikimedia8 to use it as a local database.
However, one problem raises: all the entries in the the database dump are written in a wiki markup language (Wikitext), which difficults the extraction of the text. Therefore, JWPL 1.1.0 9 was selected as a parser library to identify the text and categories from each Wikipedia entry.
Then, since the goal of using Wikipedia is executing full-text queries, all the entries identified as an article (ignoring redirects and disambiguation pages) are indexed in a newLucene index (different than the one used for the vertical representation), using the default vector space model to determine the relevance of the documents and applying the same pre-processing steps (stepwords removal and stemming) as in the collection indexing. Additionally, all the articles and their related categories are stored for future usage in aPostgreSQL database.
Figure 5.2 shows the complete indexing process, from downloadingWikipedia, to the storage and indexing of the entries.
5.1.4 Vertical selection baseline
The vertical selection algorithm chosen as a baseline for all the experiments is the document-centric model described in Subsection 2.3.2 due to its proven good perfor-mance in the TREC FedWeb 2013 collection [15]. The formula was implemented follow-ing Lucene’s architectural model as shown in Figure 5.3.
Based on the official run configuration stated by Balog [6], the smoothing parameter
λis set to 0.1. A relevance cut-off parameter for the ranking is set to 200 documents.
8
http://dumps.wikimedia.org/ 9
Figure 5.3: Implementation of document-centric model in Lucene. Following the given formula and Lucene’s architecture, eachsimilarity component calculates (1−λ)P(t|d) +
λP(t). The term query computes {similarity}n(t,q). Product query does the product
function on all the individual terms. Finally, the document-centric model component aggregates the document’s scores multiplied byP(d|v) and multiplies the result by the collection prior.
Using the described setup, the baseline was calculated with three different runs: snippets only,documents only, anddocuments+snippets (see Table 5.3). However, there is a difference between the obtained results and the ones reported in the FedWeb 2013 overview paper [15]. This discrepancy in the values can be explained by different ap-proaches in the tokenization, pre-processing and indexing of the sample.
The evaluation shows how the documents only and the documents+snippets runs obtain a similar performance. Thus, for simplicity in the management of the sample and creation of the index, the selected run to use as a baseline for all the experiments in this research is thedocuments-only (D).
5.1.5 Evaluation metrics
Normalized discounted cumulative gain (nDCG)
Thenormalized discounted cumulative gainis a metric commonly applied in information retrieval to evaluate the effectiveness of ranking algorithms. Following the FedWeb 2013 guidelines [15], we use the nDCG variant proposed by Burges et al. [11].
The formula is initially composed by the discounted cumulative gain (DCG), which states that highly relevant documents ranked in bottom positions should be penalized. Thus, the results are aggregated until a kposition as follows:
DCG@k=
k
X
i=1
2reli−1
log2(i+ 1)
(5.1)
, wherereli is the relevance level of the result at ranki.
However, since the number of retrieved results can vary with each query, the DCG on its own does not provide a ‘fair’ evaluation. Therefore, the result is normalized to a position k against its maximum possible value to the same position (known as ideal DCG orIDCG), as shown below:
nDCG@k= DCG@k
IDCG@k (5.2)
Significance tests
Comparing differences in average results of two approaches is useful to get an initial idea of their performances. However, the measure does not tell if the difference is caused by a real improvement of one algorithm, or if it is caused by random factors in the individual evaluations.
Hiemstra and Kraaij [20] describe how in information retrieval, significance tests can statistically prove when one technique outperforms the other. In particular, three different tests can be applied: the Student’s paired t-test, the paired Wilcoxon’s signed rank test and the paired sign test. On the mentioned tests, Smucker et al. [43] have found how both the Wilcoxon and sign test can lead to false detections of significance. Therefore, to evaluate the results of our techniques, we use the Student’s paired t-test. An initial assumption to perform the test is that the values are normally distributed. Although the parameter for comparison is the nDCG@20, which is discrete and by definition does not satisfy the stated requirement, due to the high number of evaluated queries (50) we can assume that the values approximate to a normal distribution.
Our null hypothesis is that there is no difference between the two algorithms and we will try to disprove it with a significance level (the p-value) of 0.05. If the test is below this threshold, we can assure with a 95% certainty that one algorithm is better than the other.
5.2
Vertical representation enrichment
Figure 5.4: Indexing with Wikipedia articles representation
5.2.1 Wikipedia articles representation
Following Algorithm 3.1, the creation of theWikipediaarticles representation starts with sampling each vertical (line 3). In our case, the FedWed 2013 collection provides such sample. However, the initial collection indexing described in Subsection 5.1.2 generated some important intermediate files: the tokens representing each one of the documents (see Figure 5.1). Since those tokens can be interpreted as a clean version (without noise like HTML tags or stopwords and stemming each term) of the original documents, they will be used in the further steps of the process (see Figure 5.4).
TheLDAalgorithm is then executed (line 4) by analyzing all the tokens files, grouped by vertical, usingMALLET [28]: a Java library with topic modeling capabilities which has been successfully applied in previous research [1, 8, 31]. We discovered 200 latent topics (numOf T opics = 200) per vertical after 1000 iterations (numOf Iterations = 1000). The extra parameters for MALLET were set to their default values.
All the terms for each topic are joined to form the query string (line 14). In Lucene terminology, the OR functionality is achieved with the Occur.SHOULD constant. This query is then searched in the Wikipedia index (described in Subsection 5.1.3) ignoring all the disambiguation pages (ignoreDisambiguation=true).
As the number of retrieved documents numOf Articles variate the final outcome, we experiment different runs with the following rank cut-offs: 1, 5, 10, 25, 50, 75, 100, 150 and 200.
5.2.2 Combined representation: Wikipedia articles and vertical sam-ple
Using a mixture ofWikipedia articles and documents directly sampled from the vertical is an extension of the previously described approach. Algorithm 3.2 presents it with the same overall steps as Algorithm 3.1.
As shown in Figure 5.5, on one side of the process the tokens files are analyzed through the topics modeling technique and the top related articles are included in the index. However, on the other side of the algorithm, an extra step is taken: the original sample is also included in the vertical representation (line 6).
The current experiment examines the results obtained with the same variations of
Figure 5.5: Indexing with combined representation
Figure 5.6: Indexing with sampled documents expansion
5.2.3 Sampled documents expansion
Document expansion, as described in Subsection 3.2.3, is based on maintaining the same number of sampled documents, but extending their individual set of terms with the help of an external resource (see Figure 5.6).
Algorithm 3.3 demonstrates the selected expansion process. Each sampled document (the tokens file) of each vertical is initially analyzed with theTF-IDF weighting scheme in order to extract the document’s keywords (line 5).
Next, the top keywords are used in a full-text search in theWikipediaindex. Finally, the top articles (again, settingtrueto theignoreDisambiguationparameter) are merged with the tokens file in a resulting expanded document. This document is then indexed as a part of the vertical representation.
We experiment with the retrieval of the top 1, 3 and 5 Wikipedia numOf Articles
after searching the top 3 and 5 numOf Keywordsof each individual document.
5.2.4 Results
Total Documents per
Run nDCG@20 documents vertical
W1 0.12464 28,459 181.26
W5 0.11648 137,546 876.08
W10 0.15949 269,064 1,713.78
W25 0.11269 648,376 4,129.78
W50 0.14043 1,248,490 7,952.16
W75 0.14942 1,823,112 11,612.17
W100 0.14030 2,380,391 15,161.72
W150 0.12357 3,449,136 21,969.01
W200 0.12887 4,383,652 27,921.35
Baseline (D) 0.24244 1,878,613 11,965.68
Table 5.4: Evaluation for Wikipedia articles representation (Wn). The runs includes the
topnWikipedia articles obtained for each of the modeled topics. The baseline performs significantly better in all cases (p <0.05)
Total Documents per
Run nDCG@20 documents vertical
DW1 0.23193 1,907,072 12,146.95
DW5 0.21618 2,016,159 12,841.77
DW10 0.19451§ 2,147,677 13,679.47
DW25 0.17942§ 2,526,989 16,095.47
DW50 0.19355§ 3,127,103 19,917.85
DW75 0.20530 3,701,725 23,577.86
DW100 0.19872 4,259,004 27,127.41
DW150 0.16998§ 5,327,749 33,934.70
DW200 0.17922 6,262,265 39,887.03
Baseline (D) 0.24244 1,878,613 11,965.68
Table 5.5: Evaluation for combined representation (DWn). The runs includes the topn
Wikipedia articles obtained for each of the modeled topics added to the initial sampled documents. The (§) shows a significant better performance of the baseline (p <0.05)
![Figure 2.3: Graphical model representation of LDA as described by Blei [9]](https://thumb-us.123doks.com/thumbv2/123dok_us/9888085.490032/24.892.230.615.158.387/figure-graphical-model-representation-lda-described-blei.webp)