WORKING PAPERS SERIES
WP99-01
Using Bayesian Variable Selection
Methods to Choose Style Factors in
Global Stock Return Models
Using Bayesian Variable Selection Methods to Choose
Style Factors in Global Stock Return Models
12 June 2000
Anthony D. Hall,
School of Finance and Economics,
University of Technology, Sydney, Australia,
Soosung Hwang
Department of Banking and Finance,
City University Business School, UK,
And
Stephen E. Satchell
*Faculty of Economics and Politics and Trinity College,
University of Cambridge, UK
Abstract
This paper applies Bayesian variable selection methods from the statistics literature to
give guidance in the decision to include/omit factors in a global (linear factor) stock
return model. Once one has accounted for country and sector, it is possible to see which
style or styles best explains current asset returns. This study does not find compelling
evidence for global styles as useful explanatory factors, once country and sector have
been accounted for.
Keywords
: Bayesian Variable Selection, Global Portfolio, Factor Mimicking Portfolio.
JEL Codes
: C11, G11, G12.
1. Introduction
There is considerable literature on the choice of factors in explaining asset returns at the
global level, see Capaul, Rowley and Sharpe (1993), Arshanapalli, Coggin and Doukas
(1998) and Fama and French (1998). Many models, however, have been global tactical
asset allocation (GTAA) models, concentrating on country wide, or global, factors to try
to explain the returns on equity indices. Some research has concentrated on global or
regional models at the individual stock level, we call such models stock return models.
Some literature, see Heston and Rouwenhorst (1995) and Kuo and Satchell (1998), has
concentrated on ranking different taxonomies in explaining the variability of the data.
The findings are that the factors that matter, in declining order of importance, are
country factors, followed by sector factors, followed by style factors.
The purpose of this paper is to use Bayesian variable selection methods to
further explore this question. This methodology gives a posterior probability that a
particular style variable should be included, conditional on the sample data. In the
particular case of the linear factor model, where residual errors are uncorrelated by
assumption, this procedure simplifies to a closed form expression. It is found that this
technique seems ideal for the problem in hand; it allows updating of “priors”
recursively, so that style rotation can be taken into account; namely, the phenomenon
that a particular style may have a risk-premium that changes through time. The factor
selection procedure is illustrated by considering a set of style factors for the
2. Bayesian SUR Model for the Selection of Factors in Linear
Factor Models
1Consider the following
m
regression equation system with
T
observations,
m
i
for
i i i
i
1
,
2
,...,
=
+
=
X
e
r
!
(1)
where
r
iis a
(
T
"
1
)
vector of the
T
observations of the dependent variable,
X
iis a
)
(
ip
T
"
matrix of independent variables,
i!
is a
(
p
i"
1
)
vector of the regression
coefficients, and
e
iis the vector of errors for the
T
observations of the
i
th regression. If
the above system is a seemingly unrelated regressions (SUR) model, it can be assumed
that the vector of the errors,
e
i, is distributed as
(
T)
N
I
e
~
0
,
#
where
$
%
&
'
(
)
*
$
$
$
=
e
e
e
me
1,
2,...,
, and is a positive definite
(
m
"
m
)
matrix to be estimated.
Introduce a new vector,
(
i)
p i
i i
i
+
+
+
1,
2,
.
=
$
+
, whose element is a binary
indicator variable,
i n+
, that is,
+
ni=
1
if
,
0
i n
!
and
+
ni=
0
if
=
0
i n
!
, where
n
and
i
correspond to the
n
th element of the
i
th regression. The interpretation of
+
ni=
1
is that
it indicates if factor
n
is indeed in the model for the return of asset
i
. Then equation (1),
conditioning on
i+
, is after removing the redundant terms with
!
ni=
0
,
i i i i
i
i
e
X
r
=
+!
++
(2)
Define
=
-
=1,
i p n i n iq
++
then
i i +
X
is a
(
T
"
q
+i)
matrix and
!
+iiis a
(
"
1
)
iq
+vector.
Therefore, by stacking the
m
linear regressions, the SUR model can be presented as
e
X
r
~
~
~
~
=
+
+
+
!
(3)
where
%
%
%
%
%
&
'
(
(
(
(
(
)
*
=
mr
r
r
r
...
~
2 1,
%
%
%
%
%
&
'
(
(
(
(
(
)
*
=
m m + + + +X
0
0
0
X
0
0
0
X
X
.
.
.
.
.
.
.
~
2 1 2 1,
%
%
%
%
%
&
'
(
(
(
(
(
)
*
=
m m + + + +!
!
!
!
...
~
2 1 2 1, and
~
e
~
N
(
0
,
.
#
T)
.
Note that
X
~
+is a
(
-
)
="
imq
imT
1 +matrix and
!
~
+is a vector of
-= m i
i
q
1 +
elements.
As the above remarks indicate,
~
r
are asset returns and the independent
variables,
X
~
+, are factors in asset pricing models. Assume that the sets of factors are the
same across all equations, i.e.,
X
/
X
1=
X
2=
,
...,
=
X
m. It can also be assumed that the
binary indicator variable vector,
i+
, is the same across all
m
regression systems, i.e.
m
+
+
+
+
/
1=
2=
,
...,
=
and
q
/
q
+1=
q
+2=
,
...,
=
q
+m.
2Assume also that
is diagonal,
i.e.,
(
2)
,
0
~
ii
N
0
e
and
cov
(
e
i,
e
j)
=
0
for
i
,
j
. These assumptions, which are standard
in linear factor models, simplify the above SUR model to an ordinary least square
(OLS) model in an univariate setting in the sense that generalized least square (GLS)
estimation is numerically equal to OLS estimation. Equation (3) can be rewritten as
i
i i i1
+
=
X
e
r
+!
+(4)
Now
X
+is a
(
T
"
q
+)
matrix and
i+
!
is a vector of
q
+elements.
2 The interpretation here is that, if
(
)
$
=
1
,
0
,
,
0
+
, for example, then only factor one is included in themodel for all equations, i.e., for all i. If i
=
(
1
,
0
,
,
0
)
$
The purpose of this study is to obtain the posterior probabilities of
+
for this
linear factor model. The posterior joint probability density function is, by
Bayes
’
law,
),
,
,
(
)
,
,
|
(
)
(
)
,
,
(
)
,
,
|
(
)
,
,
(
2 2 2 2 2+
!
+
!
+
!
+
!
+
!
i i i i i i i i i i i i i i0
0
0
0
0
+ + + + +r
r
r
r
|
2
=
(5)
where
2
represents
“
is proportional to
”
. The posterior joint density function,
)
|
,
,
(
i2 ii
! 0
++
r
, in equation (5) needs the joint priors on the parameters, i.e.,
)
,
,
(
2+
!
i i0
. Note that since,
)
(
)
|
(
)
,
|
(
)
,
,
(
2 2 2+
+
+
!
+
!
i i i
0
0
0
+ +=
,
equation (5) can be rewritten as
)
(
)
|
(
)
,
|
(
)
,
,
|
(
)
|
,
,
(
2 2 2 2+
+
+
!
+
!
+
!
i i i i i i i
0
0
0
0
+ ++
r
2
r
.
(6)
A structure such as (5) and (6) is called a hierarchical Bayes model.
Now make the following assumptions for the hierarchical Bayes model.
Firstly, the conditional
of
r
for given parameters,
(
|
,
2,
)
+
!
ii i
r
+0
is assumed to
have the following normal distribution,
)
,
(
~
)
,
,
|
(
2 2n i i i i i
N
r
!
+0
+
X
+!
+0
.(7)
For the priors, the following assumptions are used; these are the same as used in Smith
1) In the following analysis, two different priors for
(
|
2,
)
+
!
ii
0
are considered;
the first prior is
)
)
(
,
0
(
~
)
,
|
(
2 2$
31+ +
+
0
i0
iX
X
i
c
N
!
+
(8)
which is the same as that used in Smith and Kohn (1996), where they allow
c
to
take values in the range
10
4
c
4
1000
. The second prior is, by setting
T i i i i i
)
,
,
|
(
)
,
|
(
!
+0
+
2
r
!
+0
+
as in O
’
Hagan (1995), so that
),
)
(
,
)
((
~
)
,
|
(
2$
31$
2$
31+ + +
+ +
+
0
X
X
X
r
0
iX
X
i i
i
T
N
!
+
(9)
where
T
is the number of observations. The maximum likelihood estimator of
i+
!
is
i
r
X
X
X
+$
+ 31 +$
)
(
and its variance is
2(
)
31$
++
0
iX
X
. The variance of these two priors is
larger than that of the likelihood estimator because
c
and
T
are larger than 1 and
thus the prior is less informative about
i+
!
than the likelihood.
2) The prior for
0
i2is the commonly used noninformative prior discussed in Geisser
(1965). Under the assumption that the prior for
0
i2is taken as independent of
+
,
that is,
(
0
i2|
+
)
=
(
0
i2)
,
then
.
1
)
(
2 2i i
0
0
+
2
(10)
3) Finally, assume that
( )
+
are independent of one another and set
2
1
)
1
(
n=
=
+
1
n
.
(11)
The above assumptions on priors imply that
,
),
,
|
(
)
,
|
(
)
,
|
,
(
i
j
where
i+
and
j
+
are elements in the vector
+~
(see equation (3)) so that equation (12)
demonstrates that the elements of
~
+are conditionally independent. It also follows from
the above that for any two asset returns vectors,
r
iand
r
j,
.
,
)
,
,
~
|
(
)
,
,
~
|
(
)
,
,
~
|
,
(
i
j
r
ir
j +=
r
i +r
j +,
(13)
Detailed explanations of the derivation of the posterior probabilities for the linear factor
model in (4) with the priors above can be found in Appendix A. The results show that
using the priors (8), (10), and (11), the posterior probabilities of are
-5
5
6 3 3 = 3 3 3+
+
=
=
S T i q m i T i q m iS
c
S
c
r
p
r/2 /2
1 2 / * 2 / 1 *
)
(
)
1
(
)
(
)
1
(
)
(
* +(14)
where
i i T ic
c
S
r
X
X
X
X
%
r
&
'
(
)
*
$
$
+
3
=
$ +(
+ +)
31 +1
)
(
. If the prior (9) is used instead of (8),
then the result is as before, except that instead of
(
1
c
)
3q+/2+
,
(
1
T
)
3q+/2+
is used and
the definition of
S
i(
)
is changed appropriately.
3.
Empirical Tests
3.1
Equity Returns
The Morgan Stanley Capital International (MSCI) universe is used as the data
set. Firstly, the 1523 equities available in the MSCI universe are taken and then equities
selected which are available over the sample period, that is, from October 1988 to
September 1998. The number of equities available during the period is 1154.Therefore,
a total number of 120 monthly returns from October 1988 to September 1998 is used for
The MSCI universe has information on countries (20 countries) and sectors (9
sectors) for each equity. The strategy is to take out the country and sector effects prior
to analysing style. However, in many cases, weights on sector
–
country grids are very
small and there are very large differences in the weights. In addition, a large number of
countries and sectors (20 x 9 grids) can make the calculation more complicated without
giving meaningful results. In this study, the number of sectors and countries is reduced
by pooling. Twenty countries are pooled into 9 geographical groups as follows:
Canada, France, Germany, Japan, UK, Us, Other Europe (Belgium, Denmark, Finland,
Ireland, Italy, Netherlands, Norway, Spain, Swedan, and Switzerland), Australsia
(Australia and New Zealand), and Asia (Hong Kong, Malaysia, and Singapore). Sectors
are also re-grouped as Basic Industries, Capital Goods, Consumer Goods, Energy,
Financial, and Other (Resources, Transport, Utilities and Other sectors). These produce
6 new sectors. With these pooling procedures, there are 54 (9 times 6) country-sector
grids.
Firstly, cross-sectional weights on each equity at time
t
are calculated as
follows
-
==
t i l k N i
t i l k t
i l k
s
s
w
kl, , , 1
, , , ,
, ,
where
k
and
l
represent the
k
th country and the
l
th sector, respectively,
N
klis the
number of equities in the
(
k
3
l
)
country-sector grid, and
S
k,l,i,trepresents market value
(in US dollar terms) of equity
i
at time
t
. Note that
-=
=
kl N
i 1
w
k,l,i,t1
for all
.
, , , 1
, , , ,
, , , ,
, klit
N
i
t i l k t
i l k t i l
k
r
w
r
R
kl
-=3
=
Note that for the case of the equally weighted excess return of an equity that belongs to
k
th country and
l
th sector at time
t
, the study uses
kl ti l
k
N
w
,,,=
1
/
.
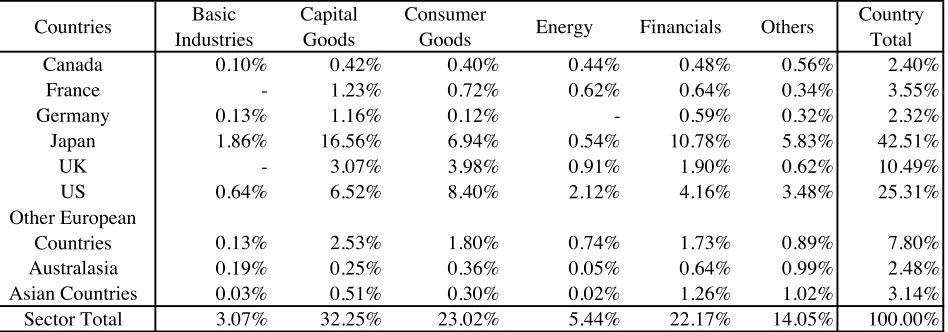
Table 1 reports some basic information on the equities used in this study. Note
that the returns are averaged over the sample period, i.e.,
-
Tt=1r
k,l,tPanel A of Table 1
shows that there are 295 Japanese equities which is 25.6% of all equities by number.
However, they cover 42.5% in value, see panel B. There are 265 US equities, whose
value is 25.3%. Therefore, the data include more Japanese equities that are also large in
value on average. Note that equities of the other countries are relatively small. Panel B
shows that Japanese equities in the finance sector are more than twice as large as the US
equities in the same sector. Also note that the Japanese Capital Goods sector is the
largest sector in both number and value.
Panel C shows equally weighted and value weighted returns on a
country/sector grid. The weighted average returns of Japanese equities are very small,
i.e., 0.1% a month, mainly due to the sluggish Japanese economy during the sample
period. Also, note that the equities of Canada and Australasia have relatively low
returns. All the other countries
’
weighted average returns are around 1.3 to 1.6% a
month. Panel D shows a similar pattern in equally weighted returns; equally weighted
returns on Japanese equities are negative, -0.03% a month, while those of other
countries are broadly similar, i.e., 0.7 to 1.4% a month.
The number and value of equities in Capital Goods and Consumer Goods are
large, more than half of the number and value of total equities. During the sample
(see panel C). The Basic Industries weighted return was -0.02%. However, the
difference between sectors is relatively smaller than that between countries.
There is a big difference in both the number and value of equities among
countries and sectors. This arises, at least partially, because the sector definitions have
gradually become out of date. For example, the value of the Capital Goods sector is
more than ten times larger than that of the basic industries sector. A similar
phenomenon can be found in country portfolios. This is the main reason why value
weighted returns are used in this study. However, the Bayesian variable selection
method described has been applied in the previous section to both equally weighted
returns and value weighted returns for comparison purposes.
3.2
Factor Mimicking Portfolios (FMPs)
In linear factor models, one needs either the factors themselves, or their
equilibrium risk premiums or a portfolio that mimics one or the other. Since the true
factors are typically unobservable, only the last of these three cases is discussed. The
decision to concentrate on building models using factor mimicking portfolios as
regressors is in line with the more sophisticated practitioner models that are based on
these procedures.
For the purposes of this paper, a factor-mimicking portfolio is a portfolio of
assets whose returns are designed to be highly correlated with the (unobservable) factor
values. Portfolios constructed from eigenvectors in principal component analysis are
examples of factor mimicking portfolios. Factor mimicking portfolios are a useful and
hedge portfolio. Even in cases when the factor is directly observable or pre-specified, it
is often convenient to use factor mimicking portfolios. For example, if a particular
factor does not correspond to a set of traded positions, it may be hard to argue that a
pricing theory applies to it, although (by construction) it would apply to a factor
mimicking portfolio. For a more detailed discussion on the general theory of factor
mimicking portfolios, see Huberman, Shmuel, and Stambaugh (1987) and Lehman and
Modest (1988).
The returns to the factor-mimicking portfolios mimic the factor values in a
certain sense. The relationship between the factor values and the corresponding factor
premiums arises from theories such as Arbitrage Pricing Theory, which essentially
links, in a no-arbitrage world, the exposure of the stocks to the factors, and the risk
premiums associated with the factors to the overall risk premium of the asset.
Suppose stock returns
r
i,tcan be modelled as
t i m
f
t f f i t
i
r
,1 , ,
,
=
9
+
-
!
8
+
7
=
where
!
i,fis some measure of the exposure of stock
i
to factor
f
,
8
f,tis some
measure of the value of factor
f
at time
t
and
7
i,tis noise. For each factor
f
, the
universe is ranked by an attribute of
f
. For instance,
f
might be the Return on Equity
factor and the universe of stocks would be ranked by their Return on Equity attribute
data. For the attributes used in this study, see definitions in Appendix B. Then an
equally weighted portfolio is formed that is long the top
n
-tile ranked by the
f
attribute, and short the bottom
n
-tile, ranked by the
f
attribute. The resulting hedge
portfolio is the factor mimicking portfolio of factor
f
. The order of the
n
-tile should
appropriate than the use of, for example, deciles (
n
=10), because of the greater
diversification produced. In this particular model thirds have been used.
Important issues arise as to whether it is sensible to rank stocks by accounting
attribute across countries and accounting regime. Initially, accounting regime
differences are ignored; however, the second approach is to normalise the accounting
data by country so that each
“
country
”
has an attribute with mean zero and variance one.
The above procedure can be seen as a natural way to make the factor
mimicking portfolios approximately uncorrelated. If the true factors are uncorrelated,
then sorting by the attributes and constructing long and short positions relative to factor
1, say, should produce a portfolio with little to no systematic exposure to factor 2.
Actually, the attributes themselves may be strongly correlated and, as a consequence,
fully uncorrelated portfolios cannot be expected. However, it is considered that this
procedure is preferable to using factor analysis or principal components, since then one
usually loses any understanding of what the factors signify.
The same data are used as was used in the previous subsection; 1523 equities in
the MSCI universe from October 1988 to September 1998. First, the values of
attributes for each equity as defined in Appendix B are calculated. The four styles used
in this study are value (VL), growth (GR), total debt/book value ratio (DE), and size
(SZ). Then the equities are ranked to the values of attributes in descending order. The
four FMP values are returns of a portfolio which
“
longs
”
the top one-third and
“
shorts
”
the bottom one-third of the ranked equities. The FMP calculated for the four styles are
FVL (value), FGR (growth), FDE (total debt/book value ratio), and FSZ (size). Note
that the returns of the FMPs are calculated each month. Thus, the number of equities
while the number of equities available used in the previous subsection is fixed, i.e.,
1154 throughout the sample period.
Table 2 reports some properties of the FMPs for two cases; first, when
accounting regime differences are not considered (call the FMPs calculated in this way
“
non-standardised FMP
”
, see panel A), and second, when accounting regime
differences are considered (call the FMPs calculated in this way
“
standardised FMP
”
,
panel B). Note that FSZ is not changed by the accounting difference since there is no
accounting attribute to be used for the calculation of FSZ. However, for the other FMPs,
the two cases give different properties to the FMPs.
The standard errors of the non-standardised FVL and FGR are larger than those
of the standardised FMPs. In addition, note that the non-standardised FMPs tend to have
larger skewness and kurtosis. This is because the equities of a country may have
relatively very high (or low) values in a style if the country's accounting attributes are
not considered. For example, equities in emerging markets tend to be more geared than
those in mature markets since there is more growth potential in emerging markets. In
this case, the FGR may be highly associated with Asian equities, which usually show
high growth ratios and thus are likely to belong to the top third in growth. Therefore,
non-standardised accounting information across countries may systematically bias
FMPs. This also explains why the correlation coefficients of the non-standardised
FMPs are higher than those of the standardised FMPs, as can be seen in panels A2 and
B2. By standardising accounting attributes, one country's dominance in the calculation
of FMPs can be removed. This procedure is also consistent with the assumption that
both the non-standardised FMPs and the standardised FMPs are used and the results
compared.
3.3
Posterior Probability of
This section calculates the posterior probability of
,that is,
( )
r
in
equation (14). Note that it uses a constant and the four FMPs as independent variables.
Therefore, the possible number of the combinations of independent variables is sixteen.
Some of the independent variable sets, except the constant, for example, are
“
FVL
”
,
“
FGR
”
,
“
FVL+FGR
”
,
“
FGR+FDE+FSZ
”
, or
“
NONE
”
, see Table 3. Therefore, the
posterior probability of takes (16
"
1) vector, i.e.,
*takes 16 values.
During the calculation with equation (14) the authors faced numerical
difficulties in obtaining a sensible number for the posterior probability of . This is
because the product of small posterior probabilities (the number is 1154) in each equity
becomes very close to zero, while the product of large posterior probabilities in each
equity becomes very large. Attempts were made to scale the values in sensible ways,
but typically, the posterior probability of
“
NONE
”
becomes one and all the other
posterior probability turn out to be zero. Accordingly, the problem was respecified by
letting
be the (16
"
1) vector of specifications for asset
i
. Thus the calculations are
carried out for each equity rather than for all equities. Thus, the posterior probability
vector for equity
i
,
iis
-6
3 3
3 3
+
+
=
=
S
T i i q
T i q i
i
S
c
S
c
p
ii
2 / 2
/
2 / * 2 / *
)
(
)
1
(
)
(
)
1
(
)
|
(
*
+ +
where all notation is the same as in equation (14). For the constant
c
, we set
c
=
T
=120,
which is in the range given by Smith and Kohn (1996); see priors for
(
|
2,
)
+
!
ii
0
in
the previous section. The numbers shown in Tables 3, 4, and 5 are the averaged
posterior probabilities of countries, sectors, and country-sector grids. Such a procedure
helps circumvent the numeric problems associated with a system , as opposed to the
equity-specific
i’
s that were calculated.
First, the results of the non-standardised FMPs are reported and then the results
of the standardised FMPs. The results on the equally weighted returns follow next.
Table 3 reports the results of the non-standardised FMPs. For the non-standardised
FMPs evidence was not found of global style effects for all countries and sectors; see
panels A and B of Table 3. Panel A shows that styles cannot explain countries since
“
NONE
”
has the highest posterior probability for all 9 countries. Indeed it is usually at
least four times as high as the next highest probability. Panel B reports similar results.
This suggests that the methodology effectively removes the country/sector effects.
Moving down a level to the individual country/sector combinations in panel C
of Table 3, there seems to be weak evidence of individual combinations being sensitive
to style; some configurations are listed. The financial sectors in Germany may be
explained by a style, that is, growth. Two sectors are explained in Japan by growth and
the combination of growth and debt. In Asian Countries, two sectors (Basic Industries
and Energy) are explained by value and growth, respectively. On the other hand,
Canada, France, UK, US, Other European Countries, and Australasia are unaffected by
Summarising the results, this study did not find strong evidence of the role of
style, but the possibility cannot be ignored that some results may come from global
accounting differences, especially for Asian definitions of book value and debt.
The posterior probabilities are recalculated using standardised FMP
’
s to allow
for the different accounting regimes across countries. Table 4 shows that global style
effects are not found in all countries and sectors; see panels A and B of Table 4. All
posterior probabilities are similar to those reported in panels A and B of Table 3. Panel
C of Table 4 also suggests that the standardised FMPs only have limited explanatory
power in the individual country/sector combinations.
The selection of FMPs and their posterior probabilities in the individual
country/sector combinations are different from those reported in Table 3. For example,
growth explains Japanese equities better than the other combination of FMPs with
non-standardised FMPs. However, with non-standardised FMPs, size is the appropriate style for
Japanese equities. Similar differences can be found in other countries.
The calculations are reworked by computing excess return, with respect to
equally, rather than capital, weighted averages. This should reduce the importance of
Japan relative to the rest as we have already seen that, in the same period, firm size is
larger in Japan than for the rest of the world. These results are presented in Table 5.
These are not discussed at length, except to note that the results are very similar to those
in Table 4; there is little evidence for the importance of global styles.
We conclude that global style is not a risk factor in explaining global stock
3.4
Time-varying Properties of Posterior Probability of
Tables 3 to 5 report the posterior probabilities of for each country/sector grid
over the entire sample period, i.e., October 1988 to September 1998. The selections of
FMPs are assumed to be time-invariant in those Tables. As in most economic and
financial variables, we do not exclude time-varying properties of the posterior
probabilities of . In this subsection, posterior probabilities are calculated using rolling
windows and the time-varying properties of the posterior probabilities are investigated.
The study uses 60 monthly equity returns and FMP returns to calculate the
posterior probabilities. The first sample period covers October 1988 to September 1993.
The second sample period covers November 1988 to October 1993, and so on.
Standardised value-weighted returns are used so that the results in this subsection can be
compared with those in Table 4, which is obtained with the entire sample. Thus the
constant can be compared with time-varying
t.
In the first sample period, prior probabilities of
were set to one-half, but
from the second sample period the previous period
’
s posterior probabilities were used as
prior probabilities for the calculation of current posterior probabilities. Therefore, the
posterior probabilities are calculated using the following equation;
-6 3 3 3 3 3 3 3 3+
+
=
=
=
S T i t q i t i t T i t q i t i t i t i tS
c
p
S
c
p
p
i i 2 / 2 / 1 1 2 / * 2 / 1 * 1 *)
(
)
1
)(
|
(
)
(
)
1
)(
|
(
)
|
(
* + +r
r
r
(16)
where
(
)
it t t t t T i t i t
c
c
S
r
X
X
X
X
%
r
&
'
(
)
*
$
$
+
3
=
3 ,1 , , ,
1
’
)
(
,
c
=
T
=60, and
r
it
and
X
t,vectors of
60 monthly returns of equity
i
and the selected combinations of FMPs up to time
t
,
respectively. With the total number of 120 monthly observations, 61 posterior
A problem in using the previous period
’
s posterior probabilities as prior
probabilities occurs when any of the previous period
’
s posterior probabilities is zero or
close to zero. In this case, equation (16) shows that all current and future posterior
probability with the zero prior probability becomes zero. To avoid this, the prior
probability (previous posterior probability) was scaled as follows;
-6 3 3 3 3 3 3=
=
=
=
S i t i t i t i t i t i tp
Max
Min
p
Max
Min
p
)
98
.
0
),
02
.
0
),
|
(
(
(
)
98
.
0
),
02
.
0
),
|
(
(
(
)
|
(
1 * 1 1 * 1 1 * 1 *r
r
r
(17)
That is, prior probabilities were set to 2% when they were less than 2%, and to 98%
when they were larger than 98%, and then the prior probabilities were recalculated
using equation (17). For example, when one previous posterior probability was 100%
and all the others (15 combinations of FMPs in this study) were 0%, the recalculated
prior probabilities were 76.56% and 1.56%, respectively.
Posterior probabilities were calculated for each of the 1154 equities in the
sample, although they are not reported. Figure 1 reports only one sector in each country.
Note that the posterior probabilities are averaged cross-sectionally across equities and
combinations of FMPs whose posterior probabilities are close to zero throughout time
were not reported.
The Figure shows there are several combinations of FMPs which explain
country/sector through time. Thus, even though posterior probabilities are changing
throughout time, the number of the combinations of FMPs themselves are less than half
of the original sixteen combinations. As already seen in the previous section,
“
NONE
”
dominates all the other combinations of styles throughout time, except for Japanese
Capital Goods, where size and recent value perform well relative to other country/sector
In most cases the posterior probability of
“
NONE
”
starts around 40% and then
becomes larger as time passes. This is because the first posterior probabilities are
calculated by setting all prior probabilities to one-half, but the other posterior
probabilities after the first ones are obtained by using the previous period's posterior
probabilities as prior probabilities.
Note that Capital Goods for Germany, Japan, and UK are not explained with
the same combinations of FMPs. When
“
NONE
”
is excluded, Japanese Capital Goods
are explained by size, among others, but UK Capital Goods are explained by growth.
Although the other country/sector grids are not reported, it is found that growth and size
perform well, except for
“
NONE
”
in UK and Japan, respectively. The selection of
FMPs does depend on countries, even though equities are in the same sector.
One property which is represented in Figure 1 is that the posterior probabilities
are time-varying rather than constant throughout time, but they do not show any
dramatic changes over time.
4.
Conclusions
In this paper Bayesian variable selection methods have been used to identify
style in a global linear factor model. It was found that equities are not well explained by
any combination of styles. One interpretation of our results is that global style is not an
appropriate choice of factor for modelling risk. However, if styles cannot explain risk,
they may still be useful in forecasting returns, i.e., in stock selection. The view has
been expressed that styles may reflect anomalous behaviour and may result from the
irrational behaviour of the investor. The results of this study are not in conflict with this
Another explanation is that styles represent changing macroeconomic and other
effects and that using fixed parameter linear factor models over a sample period simply
averages out positive and negative impacts of styles. If such a view is to be entertained,
one should look at linear factor models with time-varying betas. We hope to do this in
Appendix A. Derivation of Posterior Probabilities for the Linear
Factor Model
The task is to compute the posterior probability of
+
, that is,
pdf(
+
|
r
i)
. The posterior
probability of
+
is obtained by integrating the posterior joint density function
pdf(
!
+i,
0
i2,
+
|
r
i
)
with respect to
!
+iand
0
i2: :
=
2 2 2)
|
,
,
(
)
|
(
i i i i i i i id
d
0 !+ +
0
+0
!
+
!
+
r
r
(A.1)
Substituting equation (6) into equation (A.1), produces
: :
2
2 2 2 2 2)
,
,
|
(
)
|
(
i i i
i i i i i i i i
d
)d
|
)pdf(
,
|
pdf(
)
pdf(
0 !+ +
0
+0
0
+0
!
+
+
!
+
!
+
+
r
r
(A.2)
First, consider the first prior for
pdf(
|
i,
)
i
+
!
+0
2as in equation (8). Note that
)
,
,
|
(
2+
!
i i ir
+0
is the conventional likelihood function as in (7) and the prior pdf
’
s
for
pdf(
|
i,
)
i
+
!
20
+
and
pdf(
i|
+
)
2
0
are given in equations (8) and (10), respectively.
We use a result of Smith and Kohn (1996);
2 / 2 / 2 2 2 2
)
(
)
1
(
)
,
,
|
(
)
|
(
2 T i q i i i i i i i i iS
c
d
)d
|
)pdf(
,
|
pdf(
)
pdf(
+
=
2
: :
+
!
+
+
!
+
!
+
+
+ +0 !
r
+0
+0
0
+0
r
(A.3)
where
c
is a fixed positive constant and
i T i i
c
c
S
r
I
X
(
X
X
)
X
)
r
1
(
)
(
1 + + + +$
$
+
3
$
=
3+
.
If it is assumed that
p
(
+
n=
1
)
=
;
nfor
n=1,…,
q
+,
then the probability for a vector of
particular values,
<.
)
1
(
)
(
)
(
)
(
1 1 * *5
= 3 < <3
=
=
=
+ + +;
;
q n n n n np
p
+
+
+
(A.4)
In the
m
regression equation system with the same independent variables and a
diagonal variance-covariance matrix as in equation (3), the posterior probability of
+
is
.
)
(
)
1
(
)
(
)
(
)
|
(
)
(
)
(
)
|
(
)
(
)
(
)
|
(
)
|
(
1 2 / 2 / 1 15
5
5
= 3 3 = =+
+
+
2
+
+
2
+
+
=
+
+
=
+
m i T i q m i i m i iS
c
p
p
p
p
p
p
p
p
p
p
+r
r
r
r
r
r
(A.5)
On the other hand
+
+
+
=
:
p
p
d
p
(
r
)
(
r
)
(
)
/2 1 2 /
)
(
)
1
(
)
(
i Tm i q S
S
c
p
3 = 3 6+
+
+
=
-
5
++
(A.6)
Therefore, with equations (A.5) and (A.6),
where
S
is the set of all possible
+$
s. Note that if
;
n=
1
/
2
,
n
=
1
,
...,
q
+,
then
(
1
/
2
)
.
)
|
(
* q+p
+
=
+
r
=
In this case,
p
(
+
)
and
p
(
+
*)
cancel out and the formula
simplifies to
-5
5
6 = 3 3 = 3 < 3 <+
+
+
+
=
+
=
+
S m i T i q m i T i qS
c
S
c
p
+ + + 1 2 / 2 / 1 2 / 2 /)
(
)
1
(
)
(
)
1
(
)
|
(
*r
(A.8)
Secondly, if it is assumed that
(
2,
)
~
(
$
)
31$
,
2$
)
31)
+ + +
+ +
+
0
(
X
X
X
r
0
i(
X
X
ii i
T
N
!
+
, then
-5
5
6 = 3 3 = 3 < 3 <+
+
+
+
=
+
=
+
S m i T i q m i T i qS
T
S
T
p
+ + + 1 2 / 2 / 1 2 / 2 /)
(
)
1
(
)
(
)
1
(
)
|
(
*r
(A.9)
Appendix B. Definitions of Style Variables
)
(
)
(
t
Price
Share
t
Dividend
DP
t=
)
(
)
(
t
Price
Share
t
Share
Per
Earnings
EP
t=
)
(
)
(
t
Price
Share
t
Share
Per
Sales
Net
SB
t=
)
(
)
(
t
Price
Share
t
Share
Per
Value
Book
BP
t=
( )
)
(
t
Price
Share
t
Share
Per
Flow
Cash
CP
t=
(
12
)
)
(
3
=
t
Share
Per
Value
Book
t
Share
Per
Earnings
RE
t( )
(
)
%%
&
'
((
)
*
3
=
24
log
t
Share
Per
Value
Book
t
Share
Per
Value
ook
B
EG
t5
t t t t t tCP
BP
SP
EP
DP
VL
=
+
+
+
+
2
t t tEG
RE
GR
=
+
( )
( )
t
Share
Per
Value
Book
t
Share
Per
Debt
Total
DE
t=
( )
(
Share
Price
t
Share
Number
t
)
References
Arshanapalli, B., T. D. Coggin, and J. Doukas, 1998. Multifactor Asset Pricing Analysis
of International Value Investment Strategies.
Journal of Portfolio Management
24(4), 10-23.
Capaul, C., I. Rowley, and W. F. Sharpe, 1993. International Value and Growth Stock
Returns.
Financial Analysts Journal
, January-February, 27-36.
Fama, E. F., and K. R. French, 1998. Value versus Growth: The International Evidence.
Journal of Finance
53(6), 1975-1999.
Geisser, S., 1965. A Bayes Approach for Combining Correlated Estimates.
Journal of
American Statistical Association
60, 602-607.
Heston, S. L. and K. G. Rouwenhorst, 1995. Industry and Country Effects in
International Stock Returns.
Journal of Portfolio Management
21, 53-58.
Huberman, G., A. Shmuel, and R. F. Stambaugh, 1987. Mimicking Portfolios and Exact
Arbitrage Pricing.
Journal of Finance
42, 1-10.
Kuo, G. W. and S. E. Satchell, 1998. Global Equity Styles and Industry Effects:
Portfolio Construction via Dummy Variables. DAE Working Paper #9807,
Lehman, B. N. and D. M. Modest, 1988. The Empirical Foundations of the Arbitrage
Pricing Theory.
Journal of Financial Economics
21(2), 213-54.
O
’
Hagan, A., 1995. Fractional Bayes Factors for Model Comparison.
Journal of Royal
Statistical Association, Series B
57, 99-138.
Smith, M. and R. Kohn, 1996. Nonparametric Regression via Bayesian Variable
Selection.
Journal of Econometrics
75, 317-344.
Smith, M. and R. Kohn, 1998. Nonparametric Seemingly Unrelated Regression. Mimeo,
Table 1 Number of Equities and Weights on Countries and Sectors
A. Number of Equities on Country-Sector Grids
Countries Basic Industries
Capital Goods
Consumer
Goods Energy Financials Others
Country Total
Canada 5 7 11 13 7 15 58
France 0 15 16 3 11 7 52
Germany 2 25 8 0 10 6 51
Japan 12 130 75 6 35 37 295
UK 0 42 27 3 19 7 98
US 10 76 71 14 40 54 265
Other European
Countries 9 62 40 4 33 32 180
Australasia 3 8 10 2 10 20 53
Asian Countries 3 22 19 2 28 28 102
Sector Total 44 387 277 47 193 206 1,154
B. Weights on Country-Sector Grids Averaged over October 1988 - September 1998
Countries Basic Industries
Capital Goods
Consumer
Goods Energy Financials Others
Country Total Canada 0.10% 0.42% 0.40% 0.44% 0.48% 0.56% 2.40%
France - 1.23% 0.72% 0.62% 0.64% 0.34% 3.55% Germany 0.13% 1.16% 0.12% - 0.59% 0.32% 2.32% Japan 1.86% 16.56% 6.94% 0.54% 10.78% 5.83% 42.51% UK - 3.07% 3.98% 0.91% 1.90% 0.62% 10.49% US 0.64% 6.52% 8.40% 2.12% 4.16% 3.48% 25.31% Other European
C. Value Weighted Returns on Country-Sector Grids Averaged over October 1988 - September 1998
Countries Basic Industries
Capital Goods
Consumer
Goods Energy Financials Others
Country Total
Canada 0.07 1.07 0.75 0.39 1.10 0.47 0.72
France - 1.12 1.69 1.98 1.19 1.43 1.43
Germany 1.01 1.32 1.00 - 1.38 1.62 1.34
Japan -0.52 0.32 0.42 -0.32 -0.23 -0.07 0.10
UK - 1.16 1.60 1.45 1.50 0.83 1.40
US 1.01 1.51 1.67 1.16 1.77 1.13 1.51
Other European
Countries 0.76 1.23 1.54 1.29 1.19 1.61 1.33 Australasia 0.08 0.40 0.90 0.88 0.99 0.79 0.77 Asian Countries 0.69 1.69 1.26 0.60 1.67 1.56 1.58 Sector Total -0.02 0.81 1.24 1.11 0.66 0.65 0.84
D. Equally Weighted Returns on Country-Sector Grids Averaged over October 1988 - September 1998
Countries Basic Industries
Capital Goods
Consumer
Goods Energy Financials Others
Country Total
Canada -0.07 0.79 0.67 1.22 1.33 0.30 0.73
France - 1.11 1.40 1.68 0.84 1.10 1.17
Germany 0.91 0.91 0.81 - 1.30 1.29 1.01
Japan -0.41 0.11 0.03 -0.43 -0.23 -0.23 -0.03
UK - 0.73 1.32 0.77 1.19 1.14 1.01
US 0.60 1.38 1.59 0.87 1.82 0.99 1.37
Other European
Countries 0.60 1.01 1.12 1.13 1.02 1.10 1.03 Australasia -0.03 0.68 0.77 0.95 0.85 0.78 0.74 Asian Countries 0.73 1.39 0.70 0.40 1.14 1.04 1.06 Sector Total 0.23 0.76 0.91 0.85 1.00 0.74 0.82 Notes: Other European Countries include Belgium, Denmark, Finland, Ireland, Italy, Netherlands, Norway, Spain, Sweden, and Switzerland. Australia includes New Zealand. Asian Countries include Hong Kong,
Table 2 Properties of Factor Mimicking Portfolios
A. Factor Mimicking Portfolios Non-Standardised for Accounting Difference
between Countries
A1. First Four Moments of Factor Mimicking Portfolios
FVL FGR FDE FSZ
Mean -1.7531 0.5459 -0.0511 -0.3827 Standard Error 3.2556 2.7048 1.6730 5.6489 Skewness -0.2733 -0.3728 0.2717 0.6669 Excess Kurtosis 4.6677 1.8442 1.0137 2.7503
A2. Correlation Matrix of Factor Mimicking Portfolios
FVL FGR FDE FSZ
FVL 1.000
FGR 0.316 1.000
FDE 0.193 -0.118 1.000
FSZ -0.677 -0.703 0.094 1.000
B. Factor Mimicking Portfolios Standardised for Accounting Difference
between Countries
B1. First Four Moments of Factor Mimicking Portfolios
FVL FGR FDE FSZ
Mean -1.7583 0.1458 -0.1434 -0.3827 Standard Error 1.4566 1.1220 1.7095 5.6489 Skewness -0.9160 -0.0168 -0.1586 0.6669 Excess Kurtosis 1.6765 0.3800 1.1309 2.7503
B2. Correlation Matrix of Factor Mimicking Portfolios
FVL FGR FDE FSZ
FVL 1.000
FGR -0.201 1.000
FDE 0.081 0.126 1.000