Metadata Support for Customization in
Environmental Information Management Systems
David Hicks and Klaus Tochtermann1Abstract
Modern information management technology is an effective means by which to provide access to large amounts of distributed and diverse information. Often information management systems provide functionality which is based on metadata, i.e. data describing data, in order to support users in searching for and retrieving data required to perform a specific task. This is especially true for environmental information systems. Support for customization and personalisation of these metadata according to the personal needs of a user can further increase the potential benefit and effectiveness of information management systems. The paper reports on experiences we encountered in current environmental information management projects. Based on these experiences, the paper introduces a customization architecture for information management systems which allows users to customize such systems according to their personal needs.
1 Introduction
The world of information today is an increasingly diverse, distributed, and fragmented one. As the amount of information available in digital form continues to increase, so does the number of systems that are employed to make that information available. Knowledge workers today must be prepared to interact with a range of different systems in order to find and access the information they need in performing their tasks. Information items managed by remote systems distributed across networks, as well as those available from local sources, represent an important part of the overall information needs of a user. For example, an individual preparing an environmental impact report might need to gather information from several sources, interacting with a geographic information server at one site to obtain maps and related geographic data, a government
1
D.L. Hicks, K. Tochtermann, Forschungsinstitut für anwendungsorientierte Wissensverarbeitung, PO Box 2060, D-89081 Ulm, E-Mail: hicks | [email protected].
environmental information server at another site to obtain the required statistical data, and an image server at yet another site to obtain satellite imagery.
The majority of environmental information management systems that support knowledge workers in this task provide some sort of metadata, i.e. data describing data, for the environmental data objects they manage [Hicks and Tochtermann, 1998]. Environmental data objects such as map images, satellite photos, empirical data sets, etc. are often very large in size. In order to provide effective access to this type of information, it is important for the environmental information management systems to support a access strategy in which the knowledge worker can first retrieve the metadata for an information object, and then later retrieve the larger basic data item only if it is of interest, based on the metadata description [UDK, 1998]. The fact that different tasks of knowledge workers require different metadata fields results normally in a relatively high number (up to 40) of metadata fields describing a single environmental data object. Due to this knowledge workers often become overloaded by an excess of metadata fields when performing a specific task. A solution to this problem of current environmental digital libraries or environmental digital catalogues this is the ability for knowledge workers to customize their information space and to personalize the data objects with which they work. This is an important capability, one that is valuable in the performance of complex tasks [Van House, 1995]. For example, it might be convenient for the user described above to have the capability to attach annotations to a satellite image obtained from an image server in order to communicate personal observations to a coworker. The importance of user customization and personalization capabilities has often been noted in the literature. Nürnberg et. al. point out the need to allow easy personalization of the information accessed by web client applications [Nürnberg, et al. 1995]. Additionally they point out that the new digital processes that will characterize future information systems (e.g. agents, user profiling) will likely require even greater personalization and customization functionality. Marshall notes the importance of supporting personal annotation in the digital library [Marshall 1997]. According to Roescheisen, value is added to an information space through the process of personalization [Roescheisen et al. 1995].
The research described here addresses the information customization issue. It describes a metadata-based architecture for supporting the customization of data objects. The term data object in this context is intended to represent any individual item of information which is used by a knowledge worker during the course of performing their job. Examples of data objects include a document, a document part (e.g. a page or chapter), an image, a text file, a hypertext markup language (HTML) file, and a catalogue item. The term customization is used in this context to denote modifications and changes to a data object made by an individual or group of knowledge workers that facilitate the performance of a task. Example customizations include making an annotation to an image file or changing the value of a field from a catalogue item. The primary goal of the customization
architecture described here is to establish a customization environment that is suitable for the increasingly distributed global information space in which knowledge workers must perform their tasks.
The remainder of the paper is set out as follows: Section 2 presents two scenarios describing some of difficulties we are facing in current environmental information management projects. The scenarios are used to define concrete requirements for customization support in environmental information management. Section 3 surveys a general architecture for customization support. The architecture meets the requirements outlined in section 2. Section 4 concludes the paper with further work to be done in that area and with a brief outlook of a first prototype implementation.
2 Experiences gained in current environmental information management projects
This section presents experiences we gained in two current environmental information management projects. From these experiences we derive a list of requirements which should be met by systems focusing on customization support in digital libraries.
The first environmental information management project stresses that customization of metadata is an essential prerequisite to adapt an environmental database to personal user needs. The second environmental information management project illustrates that structuring concepts are required in environmental hypertext information retrieval networks which support environmental managers in companies in searching and retrieving environmental regulations.
2.1 Customization support for an environmental database
An environmental database, known as the "Basic Data for Environmental Report Production" database (Datenbank Grunddaten zur Umweltberichterstattung), has been developed by the German Federal Environmental Agency. The users of the database can be grouped into four different categories. The first group consists of experts from the German Federal Environmental Agency who use the database in the creation of environmental reports [Tochtermann et al.1998]. There are plans to also make the information in the database available to experts from outside that agency. By the year 2000, the database will contain a unique archive of information about the current state of the environment in Germany. In addition, it will contain time series showing the expected development of the environment in Germany by the year 2020. There are also plans to provide access to this archive to the public at the World Fair EXPO 2000. For the sake of completeness it is worth mentioning
that the filling of the database and the cataloguing of its entries is done by yet another group of experts.
To assist the different user categories in the identification and selection of relevant information, each object in the database is catalogued using approximately 40 metadata fields such as temporal coverage, geographical relationships, etc. Several strategies exist for cataloguing the environmental information contained in the database, each of which impacts the result of a search operation. Also, as the following example shows, each of the user groups has its own expectations of a search result yielded by a specific database query. In the case of cataloging geographic relationships, one strategy is to categorize objects into the most detailed geographic category possible. For example, if an object is related to Munich, Munich is entered for the geographic relationship for it even though Germany or even Europe would have also been valid. When a user performs a search for environmental information related to Europe, the objects catalogued as related to Munich will not be part of the search results (unless a geographical information system was part of the database). For some users this might be surprising since Munich is part of Europe and would therefore be expected to be part of the search results.
The experiences we made lead to the following list of requirements for environmental information management systems.
There is a need to allow users to define their own individual policies for assigning geographical relationships without the need to change the original metadata fields in the database.
As noted above, the database currently provides approximately 40 metadata fields to describe each object. The reason for supporting these extensive descriptions is that for different types of users, different metadata fields are required. For example, an expert concerned with scenario writing and forecasting might be interested in all objects that are related to a particular modeling technique. An expert for environmental report production might be interested only in the latest information and thus might need to find all objects that were published after a given point in time. In both cases a large number of the metadata fields used to catalogue objects is not relevant to the process of identifying related information in the database. Experts would prefer to limit the metadata fields they work with to those that are helpful in finding relevant information. This leads to the requirements to allow users to customize the metadata records from the database so they include only the information they need to perform their job efficiently.
Finally, users should have the possibility to further customize metadata records from the database by adding new fields to the records to hold expert knowledge they have about the records but which was not available during the initial cataloguing of the objects.
2.2 Customization support for environmental regulations
A research effort to develop an easy-to-use hypertext system to facilitate access to environmental protection regulations has been under development at the FAW (Research Institute for Applied Knowledge Processing). This system was commissioned by the Daimler-Benz AG and is known as H.I.R.N. (Hypertext Information Retrieval Network). H.I.R.N. is designed to serve as a central repository and provide access to environmental regulation information for all of the departments within a company, regardless of where the department is located [Riekert and Kadric, 1998].
Currently, the H.I.R.N. system provides basic customization functionality. The concept of personal profiles allows users to group environmental regulations they are most interested in. Profiles, however, do not yet support a functionality to allow individual users to customize environmental regulations. Examples of operations that could be supported include allowing users to (1) establish relationships to documents that describe the tasks or duties which result from a regulation; (2) define the corporate region to which a regulation applies (e.g. nation, state, district); or (3) add individual interpretations of a regulation.
A new experience we encountered was, that customization support should provide structuring mechanisms. For example, such a mechanism could be used to group all of the environmental regulations that result in tasks that must be carried out by a particular department for the company to remain environmentally compliant. This helps to focus the attention of users within the department on the regulations they need to be most concerned with. Additionally, people within the department could use the ability to customize environmental regulations as they formulate specific actions that need to be taken to perform these tasks. Structuring mechanisms might also be used to organize regulations according to corporate regions in which they are valid. This would help geographically dispersed departments to focus on just those regulations that are important for the region in which they are located. Finally, structuring mechanisms could also be used to facilitate departments within the company. For example, a top level structure could be defined in which interpretations of regulations are defined from a corporate perspective. Individual departments could define successor structures that contain departmental interpretations of regulations that refine or differ from the corporate perspective.
3 Overview of the Customization Architecture
Ideally all of the systems that knowledge workers must interact with would provide support for the individualized customization of the data objects they contain. However, customization of data objects can be a difficult capability to provide. This is especially true for network based systems with a large number of distributed
users. Though the services provided by current systems certainly vary, few if any support this capability [Phelps and Wilensky, 1997; Hicks and Tochtermann, 1998]. In providing customization capabilities, system developers cannot simply allow users to modify a data object directly since this would change the data object for everyone. The resultant situation would be one of chaos rather than effective support for knowledge workers. A strategy that is capable of supporting multiple users is clearly required. However, considering the large if not unlimited number of users that most network based systems can potentially have, this would be a difficult if not intractable task, one for which most installations are not likely to have the incentive or resources to attempt.
These observations significantly influenced the development of the customization architecture. Specifically, they lead to the use of a metadata based approach. An important characteristic of metadata is that it can exist and be maintained for a data object completely independent of the data object itself. For example, consider a digital catalogue system. The information described in a digital catalogue might exist locally (with respect to the catalogue), it could be managed by a remote system of some kind, or indeed it might not even be available in digital form. In any case, it is possible for the descriptions contained in the catalogue to be defined and maintained separately from the information they refer to. The customization architecture exploits this characteristic of metadata to enable the customization of data objects in a way that places no restrictions on where data objects are stored or by which system they are managed. Similarly, write or update access to the data objects being customized is not assumed or required.
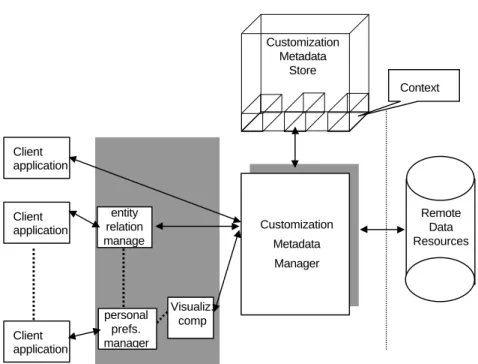
To achieve this, a strategy is employed within the architecture in which metadata is used to represent customizations that are made to data objects. Functionality to support the customization process is supplied by a central server process called the customization metadata manager (CMDM) (cf. figure 1).
In general, in response to client application requests, the CMDM creates and updates metadata information representing customizations that are made to data objects. The metadata corresponding to data object customizations is maintained by the CMDM in a customization metadata store. Note, however, the customization metadata store does not contain the actual data objects themselves. They continue to be managed by the system where they were originally located ("Remote Data Resources" in figure 1). Only the metadata information that represents changes that have been made to data objects as part of the customization process are contained in the metadata store. When the CMDM receives a request by an application to retrieve a data object, it first retrieves the data object from the system where it is located; next consults the customization metadata store for any changes that have been defined for the data object; applies any changes that are found; and then returns the data object to the requesting application.
In the case that the remote system is a digital catalog system and that data objects are catalog items, the customization can be exploited for improving the
results of a search query in the sense that the search will be based on personalized catalog items: For example, if a user performs a keyword search in a customized digital catalog system, the CMDM first searches the customized catalog items that are stored in the customization metadata store. Since only the changes to the catalog items are stored in the customization metadata store, the CMDM then consults the (remote) digital catalog system where the corresponding catalog item are located, applies the changes that are found in the customization metadata store and returns the customized catalog items to the requesting application. After the search in the customization metadata store the search is performed in the (remote) digital catalog system to take into account also those catalog items which are not customized. The application of this access strategy allows users to retrieve the customized metadata for a data object first, and then later retrieve the larger data object (e.g., a satellite image) only if it is of interest, based on the metadata description [Hicks and Tochtermann 1998].
Figure 1: Customization Metadata Manager
The customization metadata store is structured into contexts. A context is a mechanism that can be used to group logically associated customizations that are made to data objects. Contexts provide a way for individuals or groups of
entity relation manage r personal prefs. manager Visualiz. comp Customization Metadata Store Customization Metadata Manager Client application Client application Client application Remote Data Resources Context
knowledge workers to structure an information space according to their needs and preferences - to create an information space containing the customizations that pertain to the specific individual (or group) and the task they are performing. To facilitate the protection and sharing of information contexts have an owner and a set of access rights. It is possible for a user to have more than one context, providing the capability for individuals to organize the data object customizations they make according to the task or project they are working on. It is important to note that it is possible for changes to be defined for the same data object in more than one context, indicating different customizations that have been made to the data object within separate contexts. For example, two different users may define personal customizations for the same HTML file. Each user's customizations would be stored in their corresponding personal context. When an object is referenced by a user, only the changes defined by that particular user will be applied to the object. An important capability of the CMDM is the ability to layer contexts. This allows contexts to be organized in such a way that the customizations contained in one context overlay or override those from another.
3.1 Application to the environmental information management projects
This section briefly outlines how the requirements of section 2 can be met by the concepts introduced in the previous section.
In the context of the "Basic Date for Environmental Report Production" database, the concept of the customization metadata manager supports users in defining their own policies for the assignment of relationships to data objects and for the definition of individual entries for a specific field of a catalog item. Also, the customization concept can be used to hide those metadata fields which are of limited interest for knowledge workers or to add new metadata fields to hold additional expert knowledge.
In the context of the H.I.R.N. project, the concept of context can be used as structuring mechanisms to facilitate departments within an organization. Each departments could define its own context that contain departmental interpretations of regulations that refine or differ from the corporate perspective.
4 Prototype Implementation and Future Research
This section presents the first steps of a prototype implementation and closes with an outlook of future research.
4.1 Prototype Implementation
A prototype implementation of the customization architecture is currently under development. The functionality provided by the CMDM prototype will be used and tested by an application which capitalizes on the "Basic Data for Environmental Report Production" database. Therefore, we apply the concepts of the CMDM on catalog items only and not on data objects such as documents or document parts. The CMDM will use a relational database for the storage of the customized metadata. It is planned to use Java and JDBC for the development of the user interface and the connection of the user interface and the CMDM. In this context, signing mechanisms for Java applets as they are described in [Pursche et al. 1999] will be of particular importance. In addition, the prototype CMDM will serve as a platform for the development of customization capabilities for supporting a user workspace application.
4.2 Future Research
In current environmental information management projects we experienced that similar objects could often be cataloged using the same or at least almost the same metadata. To our knowledge, existing digital library systems, however, do not support a clustering mechanism which allows a number of objects to have the same metadata. The advantages of such clustering mechanisms are many-fold: redundancy can be avoided, cataloging of similar objects becomes more efficient, searching and retrieving of objects becomes more efficient, and an accuracy check process of a digital catalog which is often required before it is made available for the public becomes more efficient.
Another research area is the closer integration of research in information management (i.e., the management of information objects and the relations among them) and knowledge management (i.e., the management of knowledge of people and the relations among their knowledge). It is anticipated that such an integration provides a high potential for the further improvement of the working environments of knowledge workers. First steps in that direction were already made in the H.I.R.N. system where users can make available their personal knowledge (e.g., personal interpretation of an environmental regulation, personal knowledge of a relation to another environmental regulation) to a given information object to all other users.
Acknowledgments
This research was conducted as part of the PADDLE project (Personalizable Adaptable Digital Library Environments) funded by the program "Verteilte
Verarbeitung und Vermittlung Digitaler Dokumente" of the Deutsche Forschungsgemeinschaft (DFG).
References
Hicks, D. L., and Tochtermann, K. 1998. "Environmental Digital Library Systems". In Proceedings of the First GI (German Computer Science Society) Workshop on the Use of Hypermedia in Environmental Applications, Ulm, Germany, May 15-16, 1998.
Marshall, C. 1997. "Annotation: from paper books to the digital library". In Proceedings of ACM Digital Libraries'97, Philadelphia, Pennsylvania, USA, July 23-26, 1997. pp. 131-140.
Nürnberg, P.J., Furuta, R., Leggett, J. J., Marshall, C. C., and Shipman, F. M. 1995. "Digital Libraries: Issues and Architectures". In Proceedings of ACM Digital Libraries'95, Austin, Texas, USA, July 23-26, 1995. pp. 147-153.
Phelps, T. and Wilensky, R. 1997. "Multivalent Annotations". In "Research and Advanced Technology for Digital Libraries", Proceedings of the First European Conference, ECDL'97, Pisa, Italy, September 1997, Springer, pp. 287-303.
Pursche K., Tochtermann K. and Fuchs Ch. 1999. "Zertifizierung und Signierung von Java Applets für deren Nutzung in Internet-basierten Umweltinformationssystemen". In Proceedings of the GI-Workshop "Management von Umweltinformationen in vernetzten Umgebungen", Nürnberg, Germany, März 25-26, 1999.
Riekert, W.-F. and Kadric, L. E. 1998. "A Hypertext-based Information Retrieval Network for Environmental Protection Regulations". Proceedings of the 11th Internation Symposium on "Computer Science for Environmental Protection", Straßburg, France, Metropolis Verlag 1997.
Roescheisen, M., Winograd, T., and Paepcke, A. 1995. "Content ratings and other third-party value-added information - defining an enabling platform". D-Lib Magazine, August 1995. Available from "http://www.dlib.org/dlib/august95/stanford/08roscheisen.html".
Tochtermann, K., Riekert, W.-F., Kadric, L., Kramer, R., Schmidt, R., Geiger, W., Peter, N., Reissfelder, M., Doberkat, E.-E., Sobottka, H.-G., Keitel, A., Zitzmann, W., Schuetz, Th., and Burkhardt, J. 1998. "HUDA: A toolbox for environmental report production". Proceedings of the 12th International Symposium on "Computer Science for Environmental Protection", Bremen, Germany, Metropolis Verlag 1998.
Van House, N. A. 1995. "User Needs Assessment and Evaluation for the UC Berkeley Electronic Environmental Library Project: a Preliminary Report". In Proceedings of ACM Digital Libraries'95, Austin, Texas, USA, July 23-26, 1995. pp. 71-76. UDK (1998): http://www.uis-extern.um.bwl.de/www-udk/RPT_DATA/about_d.html.