Volume 8, No. 5, May-June 2017
International Journal of Advanced Research in Computer Science RESEARCH PAPER
Available Online at www.ijarcs.info
ISSN No. 0976-5697
Efficient Speech Recognition with Hidden Markov Models
Pooja Gautam
Research Scholar Computer Science BBAU University Lucknow Uttar Pradesh India
Ms. Sarita Soni
Assistant Professor Computer Science BBAU University Lucknow Uttar Pradesh India
Abstract: This proposition breaks down how HMM can benefit a broad vocabulary, speaker independent, perpetual talk affirmation system. We propose talk affirmation structure that relies on upon hid Markov models (HMMs), an accurate framework that sponsorships both acoustic and transient illustrating. Despite their front line execution, HMMs make different tricky exhibiting doubts that purpose of restriction their potential sufficiency. For instance, game plan of customized talk affirmation (ASR) structure can every now and again finish high accuracy for most talked vernaculars of interest if a great deal of talk material can be accumulated and used to set up a game plan of tongue specific acoustic phone models. Nevertheless, arranging extraordinary ASR systems with alongside zero tongue specific talk data for resource compelled vernaculars is so far a testing research subject. Inside seeing natural hullabaloo, speakers tend to alter their talk creation with a ultimate objective to shield reasonable correspondence. Over the traverse of working up this system, we explored assorted ways to deal with use HMM for acoustic illustrating: conjecture and request. We found that judicious HMM yield awesome results because of a nonappearance of partition, furthermore portrayal HMM gave superb results. We will affirm that, according to theory, the yield institutions of a portrayal sort out shape extremely correct appraisals of the back probabilities and we will show how these can without a lot of an extend be changed over to probabilities for standard HMM affirmation estimations.
Keywords:Speech Recognition, ASR, Hidden Markov models, probability estimation.
I. INTRODUCTION
Speech Recognition
What is the cutting edge country of the workmanship in discourse notoriety? This is an intricate question, in light of the fact that a machine's precision relies on upon the circumstances underneath which it is assessed: under adequately limit circumstances any framework can accomplish human-like exactness, however it's a ton harder to accomplish redress precision underneath trendy conditions. The circumstances of assessment — and consequently the exactness of any gadget — can run close by the resulting measurements:
• Vocabulary size and confusability.As a far reaching standard, it is anything but difficult to segregate among a little arrangement of words, yet bungles costs positively increment on the grounds that the vocabulary length develops. for instance, the 10 digits "0" to "9" might be perceived basically immaculately (Doddington 1989), however vocabulary sizes of two hundred, 5000, or 100000 may likewise have blunder costs of three%, 7%, or forty five%. of course, even a little vocabulary can be difficult to perceive in the event that it conveys confusable words. for instance, the 26 letters of the English letters in order (managed as 26 "words") are difficult to separate since they fuse such a great deal of confusable expressions (most famously, the E-set: "B, C, D, E, G, P, T, V, Z"); an eight% blunders rate is viewed as top for this vocabulary
• Speaker dependence vs. independence.by definition, a speaker subordinate gadget is implied for use by methods for a solitary speaker, however a speaker unbiased gadget is expected to be utilized by utilizing any speaker. Speaker autonomy is hard to procure because of the reality a contraption's parameters develop to be tuned to the speaker(s) that it was prepared on, and these parameters have a tendency to be incredibly speaker-exact. Mistakes expenses are by and large three to five occurrences preferred
for speaker fair frameworks over for speaker subordinate ones. Middle of the road among speaker based and unprejudiced structures, there are additionally multi-speaker frameworks expected to be utilized by a little gathering of individuals, and speaker-versatile structures which track themselves to any speaker given a little sum in their discourse as enlistment records.
• Remoted, discontinuous, or non-stop speech.remoted discourse technique unmarried expressions; irregular discourse strategy full sentences in which words are falsely isolated by hush; and persistent discourse way clearly talked sentences. disengaged and irregular discourse notoriety is truly spotless on the grounds that expression limits are noticeable and the expressions tend to be neatly articulated. constant discourse is additional hard, be that as it may, because of the reality word obstructions are suspicious and their elocutions are more debased by utilizing coarticulation, or the slurring of discourse sounds, which as an occasion reasons an expression like "should you" to sound like "ought to jou". In a run of the mill assessment, the expression mistakes cites for separated and persistent discourse were three% and 9%, individually (Bahl et al 1981).
method for its perplexity than by means of its vocabulary length.
• study vs. spontaneous speech.
structures might be assessed on discourse this is both perused from arranged scripts, or discourse that is expressed suddenly. Unconstrained discourse is immeasurably more troublesome, as it tends to be peppered with disfluencies like "uh" and "um", fake begins, inadequate sentences, stammering, hacking, and giggling; and additionally, the vocabulary is basically boundless, so the machine should be fit for arrangement shrewdly with obscure words (e.g., identifying and hailing their nearness, and including them to the vocabulary, which may require a couple collaboration with theindividual).
detrimental situations. A machine's execution additionally can be corrupted by methods for more than a couple of unfriendly conditions. these incorporate natural commotion (e.g., clamor in a vehicle or an assembling unit); acoustical contortions, unique receivers (e.g., close-talk me, or telephone); controlled recurrence data transfer capacity (in telephone transmission); and balanced talking way (yelling, crying, talking rapidly, et cetera.)
On the way to compare and examine exclusive structures underneath nicely-described situations, some of standardized databases had been created with specific traits. for instance, one database that has been broadly used is the DARPA aid control database — a big vocabulary (a thousand words), speaker-impartial, non-stop speech information-base, together with 4000 training sentences inside the area of naval useful resource management, study from a script and recorded below benign environmental conditions; trying out is generally performed the usage of a grammar with a perplexity of 60. under these controlled situations, ultra-modern performance is about ninety seven% phrase popularity accuracy (or less for easier systems). We used this database, in addition to two smaller ones, in our very own research.
II. NEURALNETWORKS
• Connectionism, or the break down of fabricated neural frameworks, ended up being at first empowered with the guide of neurobiology, in any case it has considering that end up being a totally interdisciplinary range, crossing pc science, electric outlining, number-crunching, material science, mind research, and semantics as honestly. a couple of examiners are by the by scrutinizing the neurophysiology of the human personality, however an extensive measure interest is by and by being based on the general properties of neural count, using unraveled neural models. these properties include:
• Trainability.Frameworks may be taught to shape relationship among any information and yield outlines. this will be used, for instance, to train the framework to arrange talk outlines into phoneme classes.
• Generalization.Frameworks don't simply hold the preparation information; as a choice, they take a gander at the essential styles, so they can whole up from the guideline data to new cases. that is noteworthy in talk affirmation, on account of the truth acoustical styles are by no means whatsoever, precisely the equal.
• Nonlinearity.Systems can figure nonlinear, nonparametric capacities in their enter, allowing them to
perform self-assertively convoluted adjustments of records. this is helpful in light of the fact that discourse is an unmistakably nonlinear method.
• Robustness. Systems are tolerant of each physical harm and uproarious data; in all actuality boisterous records can help the systems to shape better speculations. that is a valuable capacity, because of the reality discourse examples are famously boisterous.
• Uniformity. Systems give a uniform computational worldview that could without trouble consolidate requirements from stand-out styles of information sources. This makes it clean to apply every essential and differential discourse contributions, as an example, or to blend acoustic and obvious signals in a multimodal contraption.
There are many types of connectionist designs, with various structures, instruction strategies, and bundles, yet they're all basically in view of some not strange measures. A counterfeit neural group incorporates a possibly huge scope of straightforward preparing components (alluded to as units, hubs, or neurons), which affect each other's lead through a group of excitatory or inhibitory weights. each unit most likely registers a nonlinear weighted total of its data sources, and proclaims the final product over its active associations with various units.
III.FUNDAMENTALSOFSPEECHRECOGNITION
Discourse notoriety is multileveled test fame extend, wherein acoustical cautions are analyzed and based directly into a pecking order of sub word gadgets (e.g., phonemes), words, expressions, and sentences. each level may likewise offer extra worldly requirements, e.g., perceived expression elocutions or jail state arrangements, that could present appropriate reparations in light of blunders or instabilities at lower levels. This chain of command of requirements can decent be misused by methods for joining determinations probabilistically in any regard bring down levels, and settling on discrete choices best at the best degree.
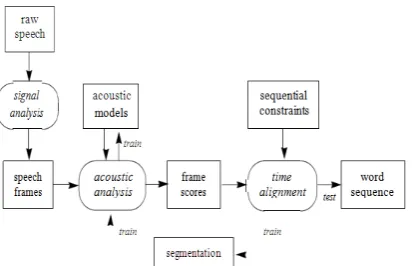
The shape of a widespread speech reputation device is illustrated in parent 2.1. The factors are as follows:
Raw speech.Discourse is for the most part examined at an exorbitant recurrence, e.g., 16 KHz over a mouthpiece or eight KHz over a cellphone. This yields a progression of sufficiency values throughout the years
• sign evaluation.uncooked discourse should be at first changed and compacted, in order to rearrange ensuing handling. Many flag assessment methodologies are to be had that may extricate advantageous elements and pack the data with the guide of a part of ten without dropping any basic records. the different greatest well known:
• Fourier evaluation (FFT)yields discrete frequencies as the years progressed, which might be deciphered outwardly. Frequencies are as often as possible apportioned utilizing a Mel scale, that is direct inside the low range however logarithmic inside the inordinate range, relating to physiological attributes of the human ear.
Figure 1 construction of a standard speech appreciation system.
• Linear Predictive Coding (LPC) yields coefficients of a linear equation that approximate the modern day records of the raw speech values.
• Cepstral analysis calculates the inverse Fourier rework of the logarithm of the energy spectrum of the signal. In exercise, it makes little distinction which method is used1. Afterwards, strategies together with Linear Discriminate evaluation (LDA) may also optionally be carried out to similarly lessen the dimensionality of any illustration, and to de-correlate the coefficients.
IV.CLASSIFICATION OF SPEECH RECOGNITION SYSTEM
Speech popularity systems can be separated in numerous exceptional lessons through describing the type of speech utterance, sort of speaker version, kind of channel and the type of vocabulary that they have the ability to understand. Speech reputation is becoming more complex and a difficult mission because of this variability within the sign. those demanding situations are in short explained underneath.
A.Types of Speech Utterance
An articulation is the vocalization (talking) of a word or expressions that speak to an unmarried intending to the pc. Expressions might be an unmarried expression, a few words, a sentence, or significantly more than one sentences. The styles of discourse articulation are:
1) Isolated Words
Remoted state recognizers by and large require every expression to have calm on both aspects of the example window. It would not imply that it acknowledges single expressions, however requires a solitary articulation at any given moment. This is great for circumstances wherein the individual is required to give best single word reactions or directions, however could be exceptionally unnatural for different expression inputs. it is relatively straightforward and most straightforward to put in drive since word snags are evident and the words have a tendency to be as a general rule said that is the real advantage of this kind. The detriment of this sort is choosing particular hindrances impacts the outcomes.
2) Connected Words
connected word structures (or more noteworthy proficiently 'connected articulations') are much the same as remoted expressions, however enable separate articulations to be 'run-together' with a base delay among them
3) Continuous Speech
constant discourse recognizers allow clients to talk clearly, even as the PC decides the substance. basically, it is PC transcription. It incorporates a radiant arrangement of "co explanation", where bordering words run together without stops or some other obvious division between words. constant discourse prevalence frameworks are most difficult to make because of the reality they have to use one of a kind methods to decide expression restrictions. As vocabulary develops bigger, confusability between exceptional word arrangements develops.
4) Spontaneous Speech
This type of discourse is common and now not practiced. An ASR framework with unconstrained discourse need to have the capacity to fight with a dispersion of home grown discourse highlights which incorporates words being run all in all or even gentle stammers. Unconstrained (unrehearsed) discourse may likewise comprise of errors, fake-begins offevolved, and nonwords..
B. Types of Speaker Model
All speakers have their uncommon voices, in light of their one of a kind physical edge and persona. Discourse acknowledgment contraption is comprehensively characterized into two fundamental classes construct absolutely in light of speaker models particularly speaker set up and speaker impartial.
1) Speaker dependent models
Speaker subordinate structures are intended for a specific speaker. They are commonly more prominent exact for the specific speaker, yet a great deal substantially less right for other sound framework. those frameworks are regularly less convoluted to grow, less expensive and more prominent precise, yet no longer as bendy as speaker versatile or speaker free structures.
2) Speaker independent models
Speaker free structures are intended for kind of sound framework. It perceives the discourse styles of a major establishment of individuals. This contraption is most extreme intense to expand, greatest sumptuous and offers less precision than speaker organized frameworks. be that as it may, they might be additional adaptable.
Types of Vocabulary
The size of vocabulary of a speech reputation machine affects the complexity, processing requirements and the accuracy of the system. some packages best require a few phrases (e.g. numbers most effective), others require very huge dictionaries (e.g. dictation machines). In ASR systems the kinds of vocabularies can be labeled as follows.
• Small vocabulary - tens of phrases
• Medium vocabulary - masses of phrases
• Big vocabulary - heaps of words
• Very-massive vocabulary - tens of hundreds of words
• Out-of-Vocabulary- Mapping a phrase from the
vocabulary into the unknown word
Other than the above characteristics, the environment variability, channel variability, speak me style, sex, age, speed of speech also makes the ASR gadget more complex. however the green ASR structures have to deal with the variety in the signal
V.SPEECHFEATUREEXTRACTIONTECHNIQUES
discourse from other. because of the reality each discourse has restrictive individual attributes installed in articulations. these attributes can be separated from a broad assortment of capacity extraction systems proposed and viably abused for discourse acknowledgment challenge. however removed component need to meet a couple of criteria while managing the discourse sign, for example,
• clean to degree extracted speech capabilities
• It need to no longer be vulnerable to mimicry
• It ought to show little fluctuation from one speakme environment to another
• It have to be solid over time
• It need to occur often and certainly in speech
The most extensively used function extraction strategies are explained underneath.
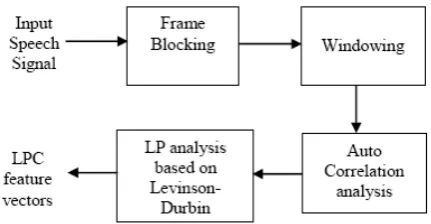
A.Linear Predictive Coding (LPC)
[image:4.595.54.270.452.564.2]One of the most effective sign evaluation techniques is the technique of linear prediction. LPC [3][4] of speech has turn out to be the principal approach for estimating the basic parameters of speech. It presents each an correct estimate of the speech parameters and it is also an green computational model of speech. The number one idea behind LPC is that a speech pattern can be approximated as a linear combination of past speech samples. through minimizing the sum of squared variations (over a finite interval) between the real speech samples and expected values, a completely unique set of parameters or predictor coefficients can be determined. those coefficients form the basis for LPC of speech [10]. The evaluation gives the functionality for computing the linear prediction version of speech through the years. The predictor coefficients are consequently transformed to a stronger set of parameters known as cepstral coefficients. the following discern 2 shows the steps involved in LPC characteristic extraction.
Figure 2. Steps involved in LPC Feature removal
B. Mel Frequency Cepstral Coefficients (MFCC)
The MFCC [3][4]is the most obvious example of a feature set this is appreciably used in speech reputation. because the frequency bands are located logarithmically in MFCC [6], it approximates the human contraption response more prominent nearly than another device. technique for processing MFCC depends on the speedy day and age examination, and subsequently from each casing a MFCC vector is registered. for you to separate the coefficients the discourse test is taken as the enter and hamming window is connected to diminish the discontinuities of a sign. At that point DFT may be utilized to produce the Mel channel bank. In venture with Mel recurrence distorting, the width of the triangular channels fluctuates thus the log general power in a basic band over the middle recurrence is secured. Subsequent to distorting the quantities of coefficients are
gotten. sooner or later the Inverse Discrete Fourier Transformer is used for the cepstral coefficients calculation [3][4]. It transforms the log of the quefrench area coefficients to the frequency domain where N is the duration of the DFT. MFCC can be computed by means of using the system(2).
Mel(f) = 2595 ∗ log 10(1 + f/700)
VI.RELATEDWORK
Li Deng et al, in "Machine Learning Paradigms for Speech Recognition: An Overview" 2013[1],the creators depict Automatic Speech Recognition (ASR) has verifiably been a main impetus behind many machine learning (ML) strategies, including the pervasively utilized concealed Markov demonstrate, discriminative learning, organized succession learning, Bayesian learning, and versatile learning. Besides, ML can and periodically uses ASR as a vast scale, reasonable application to thoroughly test the adequacy of a given strategy, and to motivate new issues emerging from the intrinsically successive and dynamic nature of discourse. Then again, despite the fact that ASR is accessible economically for a few applications, it is generally an unsolved issue - for all applications, the execution of ASR is not keeping pace with human execution. New understanding from present day ML technique demonstrates awesome guarantee to propel the best in class in ASR innovation. This diagram article furnishes perusers with a review of present day ML strategies as used in the flow and as pertinent to future ASR research and frameworks. The expectation is to cultivate additionally cross-fertilization between the ML and ASR people group than has happened before. The article is sorted out as per the real ML ideal models that are either mainstream as of now or have potential for making noteworthy commitments to ASR innovation. The standards introduced and explained in this outline include: generative and discriminative learning; managed, unsupervised, semi-administered, and dynamic learning; versatile and multi-undertaking learning; and Bayesian learning. These learning ideal models are inspired and examined with regards to ASR innovation and applications. They at long last present and dissect late advancements of profound learning and learning with scanty portrayals, concentrating on their immediate significance to progressing ASR innovation.Makhoul, J. in "Speech processing at BBN" 2006 [2], the creators portray This overview of discourse preparing exercises covers a period that started around 1971. Territories of significance - specialized and additionally verifiable - incorporate discourse acknowledgment and comprehension, discourse coding, speaker acknowledgment, and discourse adjustment. Some of today's best-respected procedures in discourse and dialect handling stem from BBN's initial work.
between the ASR acoustic models prepared commonly on clamor clean unbiased (modular) discourse and the real parameters of loud LE discourse. In this review, novel unsupervised recurrence space and cepstral area balances that expansion ASR imperviousness to LE are proposed and joined in an acknowledgment conspire utilizing a codebook of loud acoustic models. In the recurrence space, brief time discourse spectra are changed towards nonpartisan ASR acoustic models in a most extreme probability form. At the same time, flow of cepstral tests are resolved from the quantile gauges and standardized to a steady range. A codebook interpreting methodology is connected to decide the boisterous models best coordinating the real blend of discourse and uproarious foundation. The proposed calculations are assessed next to each other with ordinary pay conspires on associated Czech digits introduced in different levels of foundation auto commotion. The subsequent framework gives a flat out word mistake rate (WER) diminishment on 10-dB flag to-clamor proportion information of 8.7% and 37.7% for female nonpartisan and LE discourse, separately, and of 8.7% and 32.8% for male unbiased and LE discourse, individually, when contrasted with the standard recognizer utilizing perceptual straight forecast (PLP) coefficients and cepstral mean and fluctuation standardization.
Dahl, G.E. et al, in "Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition" 2012 [4], the creators portray They propose a novel setting subordinate (CD) display for vast vocabulary discourse acknowledgment (LVSR) that use late advances in utilizing profound conviction systems for telephone acknowledgment. They portray a pre-prepared profound neural system concealed Markov display (DNN-HMM) crossover design that prepares the DNN to create dissemination over senones (tied triphone states) as its yield. The profound conviction organize pre-preparing calculation is a vigorous and frequently accommodating approach to introduce profound neural systems generatively that can help in enhancement and lessen speculation mistake. They delineate the key segments of their model, portray the technique for applying CD-DNN-HMMs to LVSR, and break down the impacts of different displaying decisions on execution. Probes a testing business look dataset show that CD-DNN-HMMs can altogether outflank the customary setting subordinate Gaussian blend display (GMM)- HMMs, with an outright sentence precision change of 5.8% and 9.2% (or relative mistake lessening of 16.0% and 23.2%) over the CD-GMM-HMMs prepared utilizing the base telephone blunder rate (MPE) and greatest probability (ML) criteria, separately.
Siniscalchi, S.M. et al, in "Experiments on Cross-Language Attribute Detection and Phone Recognition With Minimal Target-Specific Training Data" 2012 [5],
the creators depict A best in class programmed discourse acknowledgment (ASR) framework can frequently accomplish high precision for most talked dialects of intrigue if a lot of discourse material can be gathered and used to prepare an arrangement of dialect particular acoustic telephone models. Notwithstanding, planning great ASR frameworks with practically no dialect particular discourse information for asset restricted dialects is as yet a testing research subject. As an outcome, there has been an expanding enthusiasm for investigating learning sharing
among countless so that an all inclusive arrangement of acoustic telephone units can be characterized to work for numerous or notwithstanding for all dialects. This work goes for showing that an as of late proposed programmed discourse characteristic translation system can assume a key part in planning dialect widespread acoustic models by sharing discourse units among all objective dialects at the acoustic phonetic property level. The dialect widespread acoustic models are assessed through telephone acknowledgment. It will be demonstrated that great cross-dialect trait discovery and ceaseless telephone acknowledgment execution can be proficient for dialects utilizing negligible preparing information from the objective dialects to be perceived. Besides, a telephone based foundation show (PBM) approach will be displayed to enhance characteristic recognition exactnesses.
Peng Li et al, in "Design of a Low-Power Coprocessor for Mid-Size Vocabulary Speech Recognition Systems" 2011[6], the creators portray Speech acknowledgment frameworks have picked up ubiquity in customer hardware. This paper exhibits a specially crafted coprocessor for yield likelihood count (OPC), which is the most calculation escalated preparing venture in consistent shrouded Markov demonstrate (CHMM)- based discourse acknowledgment calculations. To spare equipment asset and diminish control utilization, a polynomial option based strategy is utilized to figure include log rather than the conventional look-into table-based technique. What's more, the ideal tradeoff between discourse handling delay, vitality utilization, and equipment assets is investigated for the coprocessor. The proposed coprocessor has been actualized and tried in Xilinx Spartan-3A DSP XC3SD3400A, and furthermore approved utilizing the standard-cell-based approach in IBM 0.13 m innovation. To actualize a whole discourse acknowledgment framework, SAMSUNG S3C44b0X (containing an ARM7) is utilized as the smaller scale controller to execute whatever remains of discourse handling. Tried with a 358-state 3-blend 27-include 800-word HMM, S3C44b0X works at 40 MHz and coprocessor at 10 MHz to meet the continuous necessity, and the acknowledgment precision is 95.2%. Control utilization of the miniaturized scale controller is 10 mW, and that of the coprocessor 15.2 mW. The general discourse acknowledgment framework accomplishes the most reduced vitality utilization per word acknowledgment among many announced outlines. Trial and examination demonstrate that the discourse acknowledgment framework in light of the proposed coprocessor is particularly reasonable for fair size vocabulary (100-1000 words) acknowledgment errands.
multi-channel source detachment front-end. In correlation with different models the new proof pdf holds a more full depiction of the accessible information and gives a more powerful connection between source partition and acknowledgment. The predominance of the limited Gauss-Uniform blend pdf over customary methodologies is exhibited for an associated digits acknowledgment errand under differing test conditions.
Garcia-Moral, A.I. et al, in "Data Balancing for Efficient Training of Hybrid ANN/HMM Automatic Speech Recognition Systems" 2011 [8], the creators portray Hybrid discourse recognizers, where the estimation of the emanation pdf of the conditions of shrouded Markov models (HMMs), for the most part done utilizing Gaussian blend models (GMMs), is substituted by fake neural systems (ANNs) have a few points of interest over the established frameworks. In any case, to acquire execution upgrades, the computational prerequisites are vigorously expanded due to the need to prepare the ANN. Withdrawing from the perception of the momentous skewness of discourse information, this paper proposes filtering out the preparation set and adjusting the measure of tests per class. With this technique, the preparation time has been lessened 18 times while getting exhibitions like or far better than those with the entire database, particularly in uproarious conditions. Nonetheless, the use of these diminished sets is not clear. To stay away from the bungle amongst preparing and testing conditions made by the alteration of the dissemination of the preparation information, an appropriate scaling of the a posteriori probabilities acquired and a resizing of the setting window should be executed as exhibited in this paper.
Jendoubi, S. et al, in "Belief Hidden Markov Model for speech recognition" 2013[9], the creators depict Speech Recognition inquiries to foresee the talked words consequently. These frameworks are known to be extremely costly as a result of utilizing a few pre-recorded hours of discourse. Thus, assembling a model that limits the cost of the recognizer will be extremely fascinating. In this paper, they introduce another approach for perceiving discourse in light of conviction HMMs rather than probabilistic HMMs. Tests demonstrates that their conviction recognizer is unfeeling to the absence of the information and it can be prepared utilizing just a single praiseworthy of every acoustic unit and it gives a decent acknowledgment rates. Subsequently, utilizing the conviction HMM recognizer can extraordinarily limit the cost of these frameworks.
Bo Li et al, in "A Spectral Masking Approach to Noise-Robust Speech Recognition Using Deep Neural Networks" 2014 [10], the creators depict Improving the commotion heartiness of programmed discourse acknowledgment frameworks has been a testing errand for a long time. As of late, it was found that Deep Neural Networks (DNNs) yield extensive execution increases over customary GMM-HMM frameworks, when utilized as a part of both half breed and couple frameworks. Be that as it may, they are still a long way from the level of human desires particularly under unfriendly situations. Propelled by the division preceding acknowledgment procedure of the human sound-related framework, they propose a hearty ghastly concealing framework where control phantom space veils are anticipated utilizing a DNN prepared on a similar channel bank highlights utilized for acoustic demonstrating. To additionally enhance execution, Linear Input Network
(LIN) adjustment is connected to both the cover estimator and the acoustic model DNNs. Since the estimation of LINs for the veil estimator requires stereo information, which is not accessible amid testing, they proposed utilizing the LINs evaluated for the acoustic model DNNs to adjust the cover estimators. Besides, they utilized a similar arrangement of weights acquired from pre-preparing for the information layers of both the cover estimator and the acoustic model DNNs to guarantee a superior consistency for sharing LINs. Exploratory outcomes on benchmark Aurora2 and Aurora4 assignments showed the viability of their framework, which yielded Word Error Rates (WERs) of 4.6% and 11.8% individually. Besides, the straightforward averaging of rear ends from frameworks with and without ghastly concealing can additionally lessen the WERs to 4.3% on Aurora2 and 11.4% on Aurora4.
Wright, S.J. et al, in "Optimization Algorithms and Applications for Speech and Language Processing" 2013 [11], the creators depict Optimization systems have been utilized for a long time in the plan and arrangement of computational issues emerging in discourse and dialect handling. Such methods are found in the Baum-Welch, amplified Baum-Welch (EBW), Rprop, and GIS calculations, for instance. Furthermore, the utilization of regularization terms has been seen in different uses of scanty enhancement. This paper traces a scope of issues in which enhancement plans and calculations assume a part, giving some extra subtle elements on certain application issues in machine interpretation, speaker/dialect acknowledgment, and programmed discourse acknowledgment. A few methodologies created in the discourse and dialect preparing groups are depicted in a way that makes them more unmistakable as advancement systems. Our study is not comprehensive and is supplemented by different papers in this volume.
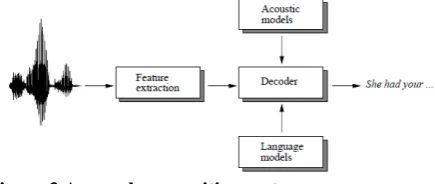
Speech reputation using HMM version
[image:6.595.322.540.613.705.2]As the speed of pc frameworks gets quicker and the measurements of discourse corpora turns out to be enormous, all the more computationally broad factual example fame calculations which require a tremendous amount of tutoring realities have come to be prominent for programmed discourse notoriety. A hidden Markov version (HMM) is a stochastic technique, into which some temporal facts may be incorporated. in this bankruptcy, the basics of speech recognition algorithms that make use of HM are defined. parent 2.1 suggests a block diagram of an ordinary speech reputation device. First, feature vectors are extracted from a speech
Figure 3 A speech recognition system
dialect variant is utilized to symbolize etymological know-how. in this section everything of the piece chart is portrayed in component.
Limitations of HMMs
Notwithstanding their ultra-modern overall performance, HMMs are handicapped through numerous well-known weaknesses, specifically:
•the first-Order Assumption — which says that each one probabilities depend altogether on the contemporary state — is fake for discourse bundles. One result is that HMMs experience difficulty displaying co verbalization, since acoustic circulations are in truth emphatically tormented by late nation records. Whatever other result is that periods are displayed mistakenly by methods for an exponentially rotting dissemination, instead of by methods for an additional exact Poisson or diverse ringer formed appropriation.
•The Independence Assumption —which says that there's no relationship among connecting enter outlines — is likewise false for discourse applications. concurring with this suspicion, HMMs observe most straightforward one casing of discourse at once. with an end goal to profit by the setting of neighboring casings, HMMs should take in those edges into the forefront outline (e.g., with the guide of presenting two or three surges of records a decent approach to make the most delta coefficients, or the utilization of LDA to change over these streams into a solitary stream).
Result and Analysis
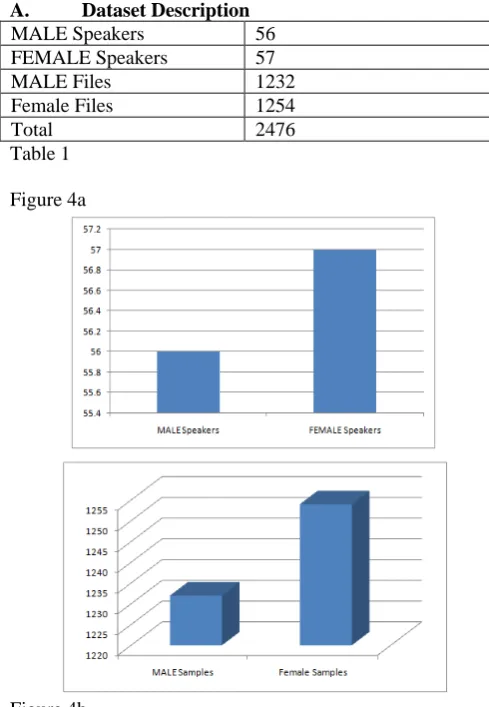
A. Dataset Description
MALE Speakers 56
FEMALE Speakers 57
MALE Files 1232
Female Files 1254
[image:7.595.322.546.61.354.2]Total 2476
Table 1
Figure 4a
Figure 4b
Fig: 4 Speech Samples of fifty six MALE and female audio system files in 2476 general
Figure 5 Recognition rate =98.99 error count =25 correct count =2461 total_count=2486
Fig: 6HMM Training with recognition rate, showing upto 99% accuracy
VII. CONCLUSIONANDFUTUREWORK
A speech recognition system requires solutions to the problems of both acoustic modeling and temporal modeling. The winning speech recognition generation, Hidden Markov fashions, gives answers to each of these problems: acoustic modeling is furnished by way of discrete, non-stop, or semicontinuous density fashions; and temporal modeling is supplied via states related by using transitions, arranged right into a strict hierarchy of phonemes, phrases, and sentences.
while an HMM’s answers are effective, they suffer from some of drawbacks. in particular, the acoustic models be afflicted by quantization errors and/or terrible parametric modeling assumptions; the usual most chance schooling criterion leads to terrible discrimination between the acoustic models; the Independence Assumption makes it hard to make the most more than one enter frames; and the primary-Order Assumption makes it hard to model co articulation and length. for the reason that HMMs have so many drawbacks, it makes feel to recall opportunity answers.
In destiny we can work on a custom-designed coprocessor for output possibility calculation that's the most computation-extensive processing step in continuous hidden Markov version based speech recognition algorithms. To keep hardware useful resource and reduce strength intake, a polynomial addition-based totally technique is used to compute add-log rather than the traditional look-up table-based method. This thesis examines how synthetic neural networks can advantage a massive vocabulary, speaker independent, continuous speech recognition gadget. Presently, maximum speech popularity systems are based on hidden Markov fashions (HMMs), a statistical framework
1 1.5 2 2.5 3 3.5 4 4.5 5
0.93 0.94 0.95 0.96 0.97 0.98 0.99 1
training
A
c
c
u
ra
c
[image:7.595.31.276.389.743.2]that helps each acoustic and temporal modeling. notwithstanding their modern day performance, HMMs make a number of suboptimal modeling assumptions that restrict their capacity effectiveness.
VIII. REFERENCES
[1]. Li Deng; Li,"Machine Learning Paradigms for Speech Recognition: An Overview",IEEE,Audio, Speech, and Language Processing, IEEE Transactions on,2013
[2]. Makhoul, J.,"Speech processing at BBN",IEEE,Annals of the History of Computing, IEEE,2006
[3]. Boril, H.; Hansen, J.H.L.,"Unsupervised Equalization of Lombard Effect for Speech Recognition in Noisy Adverse Environments",IEEE,Audio, Speech, and Language Processing, IEEE Transactions on,2010
[4]. Dahl, G.E.; Dong Yu; Li Deng; Acero, A.,"Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition",IEEE,Audio, Speech, and Language Processing, IEEE Transactions on,2012
[5]. Siniscalchi, S.M.; Dau-Cheng Lyu; Svendsen, T.; Chin-Hui Lee,"Experiments on Cross-Language Attribute Detection and Phone Recognition With Minimal Target-SpecifBourlard, H. and Morgan, N. (1990). A Continuous Speech Recognition System Embedding MLP into HMM. In Advances in Neural Information Processing Systems 2, Touretzky, D. (ed.), Morgan Kaufmann Publishers.
[6]. Peng Li; Hua Tang,"Design of a Low-Power Coprocessor for Mid-Size Vocabulary Speech Recognition Systems",IEEE,Circuits and Systems I: Regular Papers, IEEE Transactions on,2011
[7]. Kü hne, M.; Togneri, R.; Nordholm, S.,"A New Evidence Model for Missing Data Speech Recognition With Applications in Reverberant Multi-Source Environments",IEEE,Audio, Speech, and Language Processing, IEEE Transactions on,2011
[8]. Garcia-Moral, A.I.; Solera-Urena, R.; Pelaez-Moreno, C.; Diaz-de-Maria, F.,"Data Balancing for Efficient Training of Hybrid ANN/HMM Automatic Speech Recognition Systems",IEEE,Audio, Speech, and Language Processing, IEEE Transactions on,2011
[9]. Jendoubi, S.; Ben Yaghlane, B.; Martin, A.,"Belief Hidden Markov Model for speech recognition",IEEE,Modeling, Simulation and Applied Optimization (ICMSAO), 2013 5th International Conference on,2013
[10].Bo Li; Khe Chai Sim,"A Spectral Masking Approach to Noise-Robust Speech Recognition Using Deep Neural Networks",IEEE,Audio, Speech, and Language Processing, IEEE/ACM Transactions on,2014