A ZERO SHIFTED SPIHT BASED SVC
Bibhuprasad Mohanty1 Assistant Professor,
Institute of Technical Education and Research SoA University, Bhubaneswar Odisha
1
Pramod Kumar Verma2 Scientist,
Defence Electronics Application Laboratory (DEAL) PO Box 54, Raipur Road,
Dehradun-248001
Prasant Kumar Patra3 Assistant Professor, School of Electronics KIIT University,Bhubaneswar
Odisha
Abstract :
In this work, we proposed a modified version of 3D SPIHT based video codec. The codec employs the SPIHT coding algorithm using 3-D spatio-temporal orientation trees in video coding, analogous to the 2-D spatial orientation trees in image coding. We have improved the coding efficiency of the 3D SPIHT based codec by adding a preprocessing step that we call zero-shifting. The video codec is fully embedded, so that different degrees of video quality can be obtained with a single compressed bit stream. The codec has been tested using both high motion and low motion standard QCIF video sequences at 10 frames per second. The cost for this embeddedness is the coding delay (latency) to accept 16 frames into a buffer. At low bitrates the proposed scheme outperforms the existing scheme and achieves a gain of 1.5 to 5dB in PSNR, depending on the type of video. We have implemented a Scalable Video Codec that produces a bitstream which supports spatial scalability. This layered based codec is proposed by partitioning the spatial domain frame into four groups and encoding them separately with 3D SPIHT kernel to produce the bit stream. This bitstream not only has spatial scalability features but also keeps the full SNR embeddedness property for only lowest resolution level. In fact, our scalable video codec can be realized for a parallel architecture which in turn will be suitable for efficient hardware realization.
Key Words : Discrete Wavelet Transform; SPIHT; spatio-temporal orientation tree; GOF.
1. Introduction
Vol. 2(11), 2010, 6278-6283 that are common in hybrid video coding systems[Cho and Pearlman,(2002)]. Several partitioning based video coders using 3D SPIHT have been proposed in the literature to achieve error resilience. One such method, called Spatial and Temporal Tree Preserving 3-D SPIHT (STTP-SPIHT) algorithm [Creusere,(1997)], divided the wavelet coefficients into some number n of different S-T tree groups and each group is independently encoded with 3-D SPIHT to generate n number of sub streams. The advantage of STTP-SPIHT is that errors in one SPIHT-encoded sub stream do not adversely affect other sub streams and as a result, any decoding failure only affects the associated region in the GOF and not to the whole. In this work, we propose a novel preprocessing technique, named Zero-Shifting which provides significant improvement in PSNR with little additional computational complexity. We implemented a scheme, for partitioning a 3-D wavelet transform into independent coding units, so as to facilitate the layered coding scheme.
The paper is organized as follows: section 2 describes briefly the existing scalability option and its requirements; section 3 reviews the 3D wavelet packet transform and 3D SPIHT coder briefly. The motivation for the proposed methods is in section 4 and the experimental results are discussed in section 5. The conclusion of this paper is in section 6.
2. Scalability in Existing Standards and Requirement
The fundamental concept of SVC is accomplished by structuring the data of a compressed video bit stream into layers. The base layer represents low resolution picture and is completely decodable by any decoder, while one or more enhancement layers provides improved quality for reproduction of pictures with full resolution. Early standards such as ITU-T H.261 [8] and ISO/IEC MPEG-1 [9] did not provide any scalability mechanisms. ISO/IEC MPEG-2 [9], which is identical to ITU-T H.262, was the first general-purpose video compression standard which also includes a number of tools providing scalability. MPEG-2 was the first standard to include implementations of layered coding. Though the above standard support spatial, temporal, and SNR scalability, the number of scalable bit stream layers is generally restricted to a maximum of three in any of the existing MPEG-2 profiles [9]. The video codec of the ISO/IEC MPEG-4 standard [10] provides even more flexible scalability tools, including spatial and temporal scalability within a more generic framework, SNR scalability with fine granularity and scalability (FGS). Advanced Video Coding (AVC) [1], can be run in different temporal scalability modes, due to its flexibility in the definition of prediction frame references. Considering the needs of today’s and future video applications, the requirement of a successful future SVC standard critically depends on the following [Schwarz et al.,(2007)]:
• Similar coding efficiency and little increase in decoding complexity compared to single-layer coding. • Support of temporal, spatial, and quality scalability.
• Support of simple bit stream adaptations after encoding.
3. 3D-Wavelet Packet Transform and 3D-SPIHT
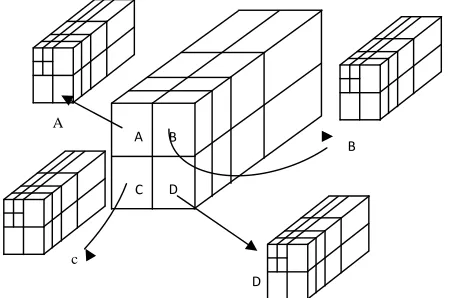
A B
C D
A
c
B
Fig. 1 Relationship in a 3D SPIHT [4]
4. The Proposed Video Codec
4.1.The zero shifting scheme
The method of zero shifting is a simple and easy-to-implement technique which reinforces the embedded property of the SPIHT coding. By downward scaling the pixel values by 2(N-1) -1 (N=8 for a grey scale image or for Y-domain of the video), the spatial domain magnitude becomes bipolar (-2(N-1) -1 to +2(N-1)) . In the transformed domain, the wavelet lifting scheme produces the high pass sub band by taking the weighted differences of the pixel values after prediction. Similarly, the low pass sub band is produced in updating step. This low pass sub band is further decomposed iteratively for each level of decomposition to provide finally, one lowest frequency band and rest high frequency bands. The highest number bit plane in SPIHT coding is decided by the maximum value of the coefficient. As the maximum coefficient decreases by the method of zero shifting, SPIHT algorithm takes less time for encoding for less number of bitplanes. Further, the lower values in the spatial domain (which originally ranges from 0 to 2N-1) are shifted to higher absolute range in the bipolar sense. The lower spatial values are information pertaining to the details of the image like, boundary, edges, etc. These coefficients become significant at earlier threshold and accordingly ordered earlier in the bit stream. Since SPIHT algorithm always encode a sign bit for significant coefficient, no extra bit budget is necessary for being bipolar. By terminating the decoding process even at lower bit rate, the quality improves, subjectively and objectively, because of the inclusion of some detail information at lower rate.
4.2.The SP-SPIHT
For scalable video codec, we propose a new scheme, very similar to Creusere’s work with images [6], but different in the sense that the parent child relation of the conventional zerotree structure are no longer preserved. It is because the coefficients are distributed according to the wavelet sub band and are input to the same encoder stream. Here, the original video frames are partitioned into four independent coding units so that it helps in designing a layered codec easily. We call this scheme spatial partitioning 3-D SPIHT (SP–SPIHT).
Vol. 2(11), 2010, 6278-6283 independent embedded sub streams are created where the base layer is formed by encoding the cube marked ‘A’, which can be decoded for low resolution video content. Combination of Sub streams from cube “B” “C” and “D” to base layer enhance and refines the decoded output to get high resolution video content. Conversely, the entire GOF can be subjected to temporal decomposition and then can be made separated before spatial decomposition took place.
4.3.The System Configuration
Since human visual system is more sensitive to the luminance(Y) than the chrominance (U, V), an improvement in the quality of luminance domain is more desirable. The Y domain is pre processed by scaling down by 127 and is then subjected to single level of spatial decomposition. The LL, LH, HL, and HH sub bands so formed are made to split into 4 groups, A, B, C, and D as shown in figure 2. Each group is then independently packet decomposed 4 levels of temporal and spatial levels and is encoded with 3D SPIHT kernel. The decoder, on the other hand, simply accepts each bitstream coming from the encoder, progressively builds up the three lists going through the sorting and refinement pass exactly same way as they were created by the encoder, and scales up by 127 after the 3Ddecomposition. The scheme facilitates the spatial scalability by layered coding at the cost of the SNR scalability. However, the base layer (group A) is still embedded and can be decoded for lower resolution.
5. Result and Discussion
We have developed a matlab code for designing a codec for video sequence using 3D SPIHT kernel. All the experiment simulation are carried out on Intel(R) Core(TM) 2 Duo CPU E4600 @ 2.40 GHz computer with 1 Gb RAM.
5.1.Choice of video sequences
We choose carefully different test video sequences, which covers a variety of camera and object motion. One is class A video sequence with high motion content, viz., carphone and foreman and the other one is class B of low motion content, like mother-daughter and hall monitor. As is evident from results, class B video sequences are more pronounced in subjective and objective quality than class A sequence. Even though the perceptual visual qualities of both the sequences are still acceptable, the blurring and other noisy artifacts are less severe in class B sequences. We evaluated the performance of our SVC based on 3D-SPIHT by encoding two different QCIF and CIF video sequences at a frame rate of 10 fps. We have considered GOF size of 16 with 4 levels of temporal decomposition, and 4 and 5 levels of spatial decomposition for QCIF and CIF video respectively.
5.2.Choice of wavelet filters for 3D-DWT
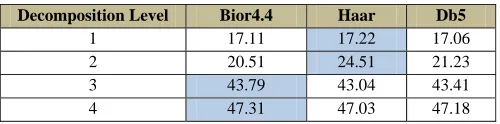
As most of the literatures found ‘bior 4.4’ as most suitable filter for the purpose, our simulation results indicates that, ‘haar’ filter has an edge over the other two popular type filters in term of timing. Using the short tap ‘haar’ filter for temporal direction avoids coding delay and memory usage However, the Table 1 clearly establishes the PSNR of ‘bior4.4’ is better than other filter type.
Table 1. PSNR comparison of filters
Decomposition Level Bior4.4 Haar Db5
1 17.11 17.22 17.06
2 20.51 24.51 21.23
3 43.79 43.04 43.41
4 47.31 47.03 47.18
Hence, for the subsequent analysis/synthesis purpose we use ‘bior 4.4’ in the spatial case and ‘haar’ for temporal decomposition.
32 64 96 128 160 192 224 256256 22
25 28 31 34 37 40 40
Bitrate
PSN
R
(
d
B)
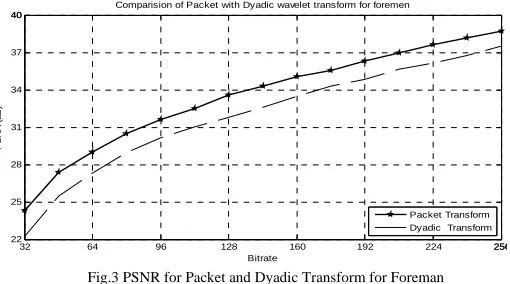
Comparision of Packet with Dyadic wavelet transform for foremen
Packet Transform Dyadic Transform
Fig.3 PSNR for Packet and Dyadic Transform for Foreman
The proposed method of zero shifting exhibited an improvement in PSNR at lower bitrates (Figure 4 for foreman as an example ) and there are no visual artifacts at perceptual quality of reconstructed video frames. The significant improvement in PSNR for both the class of video sequence attributes to the fact that by shifting the pixel values to a lower range, the significant mapping got better at lower threshold hence important information pertaining to the significance is available at the lowerbitrates and reconstruction is made better.
48 56 64 72 80 88 96 104 112 120 12
25 26 27 28 29 30 31 32 33 34
Bitrate (kbps)
PSN
R
(D
B
)
PSNR vs Bitrate curve for foreman QCIF sequence
without zeroshift with zeroshift
Fig. 4. PSNR performance with zero shifting for Foreman
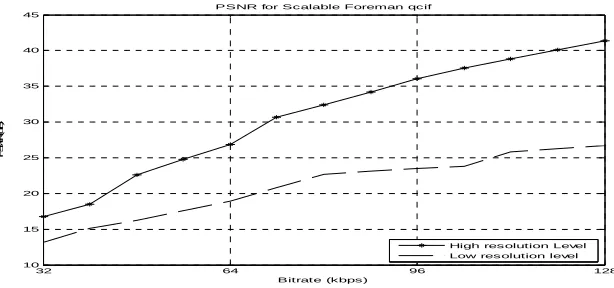
The scalable codec has been designed for two level of spatial scalability with an option for layered coding of the process. Extensive experimental simulation has been carried out with both the class of videos. We have shown here only one result to justify our motivation. As evident from the experiment, the scalable encoding algorithm has provided comparable performances at each resolution compared to an equivalent single resolution compression algorithm. As expected, the lower spatial-resolution videos (base layer only) demonstrate (figure 5) better PSNR with the proposed method of zero shifting.
32 64 96 128
10 15 20 25 30 35 40
Bitrate (kbps)
P
S
N
R
(d
B
)
PSNR of SVC with zero shifting for foreman
with Zero Shifting without zero shifting
Fig.5. PSNR of SVC with and without zero shifting
Vol. 2(11), 2010, 6278-6283 spatial- resolutions due to the flattening of the power-spectral density. The codec is inherently quality scalable at the base level and provides higher PSNR as the bit rate increases.
32 64 96 128
10 15 20 25 30 35 40 45
Bitrate (kbps)
P
S
N
R
(d
B
)
PSNR for Scalable Foreman qcif
High res olution Level Low resolution level
Fig. 6. PSNR of Scalable zero shifted Foreman
6. Conclusion
We have presented a scheme of low complexity and low bit rate video codec based on 3D SPIHT. To facilitate layered coding we have partitioned spatially the video frame. The scheme is preferred for the reason that if any of the streams is terminated prematurely, then its reduced resolution coefficient is surrounded by the full resolution coefficient at every scale. Unfortunately, due to spatial partitioning the inter scale correlation reduces and hence the performances decreases. But for the method of zero shifting the codec performs better under the constrained as mentioned earlier. In future, multithreading concept can be incorporated to improve the timing performance coding system.
7. References
[1] Coding of audio visual objects—Part 10: Advanced video coding, Int. Standards Org./Int. Electrotech. Comm. (ISO/IEC),
ISO/IEC 96-10 (identical to ITU-T Recommendation H.264).
[2] Said A., Pearlman W.A.(1996) : A new, fast, and efficient image codec based on set partitioning in hierarchical trees. IEEE
Trans. Circuits Syst. Video Technol. 6, pp. 243–250.
[3] Ohm J.R.(1994): Three dimensional subband coding with motion compensation, IEEE Trans. Image Processing, vol.3, no. 5, pp.
559-571.
[4] Kim B.-J., Xiong Z., and Pearlman W. A(2000): Low bit-rate scalable video coding with 3D set partitioning in hierarchical trees
(3D SPIHT), IEEE Trans. on Circuits and Systems for Video Technology, vol. 10, no. 8, pp. 1374-1387.
[5] Cho S. and Pearlman W. A.(2002): A full-featured, error resilient, scalable wavelet video codec based on the Set Partitioning in Hierarchical Trees (SPIHT) algorithm, IEEE trans. on Circuits & Systems for Video Technology, vol. 12, pp. 157-171.
[6] Creusere C. D.(1997): A new method of robust image compression based on the embedded zerotree wavelet algorithm, IEEE
Trans. Image Processing, vol. 6, pp. 1436–1442.
[7] Schwarz H., Marpe D.V., and Wiegand T.(2007): Overview of the Scalable Video Coding Extension of the H.264/AVC
Standard, IEEE transactions on circuits and systems for video technology, vol. 17, no. 9.
[8] Video codec for audiovisual services at p _ 64 kbit/s, Int. Telecommun. Union-Telecommun. (ITU-T), Geneva, Switzerland,
Recommendation H.261.
[9] Coding of moving pictures and associated audio for digital storage media at up to about 1.5 Mbit/s, Part 2: Video, Int. Standards Org./Int. Electrotech. Comm. (ISO/IEC), ISO/IEC11,172-2.
[10] Generic coding of moving pictures and associated audio information— Part 2: Video, Int. Standards Org./Int. Electrotech.
Comm. (ISO/IEC), ISO/IEC 13 818-2 (identical to ITU-T Recommendation H.262.